利用前缀树获取最小目录
一、任务名:
开发最小目录工具
二、任务描述
开发工具,从桶清单文件中列举出所有最小目录,并列举出每一个最小目录中包含的文件总数与文件总量。
最小目录的解释:
有以下几个目录
a/b/1.txt
a/b/2/txt
a/3.txt
a/b/c/
则,最小目录有:
a/b
a/
最小目录包含的对象数为:
a/b:2
a/:1
三、开发思路
这个工作实际上属于目录解析的范畴,与目录解析相关的问题可以通过前缀树来解决
1)前缀树节点开发
有树要先有节点,每一级目录可以视为一个节点。
这个节点包含接下来要去往的目录节点,而这种目录节点可能有很多个,我们必须能快速通过目录名来查找节点,因此选则HashMap,将目录名作为Key,目录节点作为value,nexts=HashMap<Key,Node>。
又因为,每一个目录节点均有可能称为最小目录,那么我们遍历节点的时候应该能够拿出节点中的文件数和文件总大小,故这两个属性也要设置
最后,你不能只知道下面的名字,而不知道自己的名字,所以每个节点也应该有自己的Name
因此Node的构建为PrefixTreeNode:
import java.util.HashMap;/*** @author sq* @date 2023/8/28* @Description ${}*/
public class PrefixTreeNode {String Name;//该节点名称long file_num = 0l;//该节点叶子结点个数long file_size = 0l;//该节点叶子接地点总大小HashMap<String, PrefixTreeNode> nexts = null; //该节点的子节点列表public PrefixTreeNode() {}public String getName() {return Name;}public void setName(String name) {Name = name;}public long getFile_num() {return file_num;}public void setFile_num(long file_num) {this.file_num = file_num;}public long getFile_size() {return file_size;}public void setFile_size(long file_size) {this.file_size = file_size;}public HashMap<String, PrefixTreeNode> getNexts() {return nexts;}public void setNexts(HashMap<String, PrefixTreeNode> nexts) {this.nexts = nexts;}public PrefixTreeNode(String name, HashMap<String, PrefixTreeNode> nexts) {Name = name;this.nexts = nexts;}
}2)前缀树开发
前缀树其实只需要有一个节点,然后写出构建函数和遍历函数,基本上就可以使用了
①前缀树的构建是将输入的目录字符串通过"/"进行分解,得到字符串数组。
在分解之前就可以判断一下是不是最小目录,如果最后不是以/结尾,那么到文件所在的目录就是最小目录。文件不用加入前缀树。
②前缀树的遍历就是树的正常遍历,用DFS(Depth First Search)比较容易做,遍历每一个节点,如果有文件数和文件大小就输出,没有就去下一层,直到没有下一层
前缀树的代码如下所示:
/*** @author sq* @date 2023/8/28* @Description ${}*/import java.io.FileWriter;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.util.HashMap;
import java.util.List;public class PrefixTree {PrefixTreeNode root = null;long sum_num = 0l;long sum_size = 0l;//构建前缀树public PrefixTree() {}public PrefixTree(PrefixTreeNode root) {this.root = root;}public PrefixTreeNode getRoot() {return root;}public void setRoot(PrefixTreeNode root) {this.root = root;}public long getSum_num() {return sum_num;}public void setSum_num(long sum_num) {this.sum_num = sum_num;}public long getSum_size() {return sum_size;}public void setSum_size(long sum_size) {this.sum_size = sum_size;}//构建前缀树函数public void InsertToPrefixTree(String filePath, long fileSize, PrefixTreeNode root) throws UnsupportedEncodingException {//0. size如果为0 则为目录(可优化的点)//1.对filePath进行URL解码String decodedFilePath = URLDecoder.decode(filePath, "UTF-8");//2.识别filePath是否以“/”结尾,如果是说明该路径仅为目录,没有文件对象。boolean contains_file_flag = false;if (!decodedFilePath.endsWith("/")) {contains_file_flag = true;}//3.将目录进行拆分String[] split = decodedFilePath.split("/");//“/”//4.对split数组进行遍历,构建前缀树PrefixTreeNode head = root;if (split.length == 1 && contains_file_flag == true) {//当该函数为文件节点时,不加入目录的前缀树,但对当前节点的file_num与file_size进行修改head.file_num++;head.file_size += fileSize;return;}//5.如果是目录则安好一般情况处理for (int i = 0; i < split.length; i++) {if (head.nexts == null) {//初始化一个hashmaphead.nexts = new HashMap<>();}if (!head.nexts.containsKey(split[i])) {//若前缀树中不存在该节点,加入该节点PrefixTreeNode newNode = new PrefixTreeNode();head.nexts.put(split[i], newNode);}//获取下一个节点对该节点进行一些操作//将该节点名称进行设置head.nexts.get(split[i]).Name = split[i];//判断该目录的下一个节点是不是文件对象,如果是,则该节点为一个最小目录if (i + 1 == split.length - 1 && contains_file_flag == true) {head.nexts.get(split[i]).file_num++;head.nexts.get(split[i]).file_size += fileSize;break;//不需要加入叶子节点}//去遍历下一个节点head = head.nexts.get(split[i]);}}//遍历前缀树函数public void TraversePrefixTreeWriteToFile(PrefixTreeNode root, StringBuffer Name, FileWriter writer) throws IOException {//遍历节点的nextsif (root.nexts == null) {//如果该目录下没有nexts,则直接返回return;}HashMap<String, PrefixTreeNode> nexts = root.nexts;for (String s : nexts.keySet()) {StringBuffer directoryName = new StringBuffer(Name);if (!String.valueOf(directoryName).equals("")) {directoryName.append("/");}directoryName.append(s);//1.如果该目录下包含文件,则输出该目录上级所有目录,并输出该目录下filenum: file_sizeif (nexts.get(s).file_num != 0) {//2.将结果写入文件,去掉最开头的/writer.write(directoryName + "," + nexts.get(s).file_num + "," + String.valueOf(nexts.get(s).file_size));writer.write("\n");System.out.println(directoryName + "," + nexts.get(s).file_num + "," + String.valueOf(nexts.get(s).file_size));}//3.以该节点为根节点进行遍历TraversePrefixTreeWriteToFile(nexts.get(s), directoryName, writer);}}public void TraversePrefixTree(PrefixTreeNode root, StringBuffer Name) {//遍历节点的nextsif (root.nexts == null) {//如果该目录下没有nexts,则直接返回return;}HashMap<String, PrefixTreeNode> nexts = root.nexts;for (String s : nexts.keySet()) {StringBuffer directoryName = new StringBuffer(Name);if (!String.valueOf(directoryName).equals("")) {directoryName.append("/");}directoryName.append(s);//1.如果该目录下包含文件,则输出该目录上级所有目录,并输出该目录下filenum: file_sizeif (nexts.get(s).file_num != 0) {//2.将结果写入文件,去掉最开头的/System.out.println(directoryName + "/ 目录包含" + String.valueOf(nexts.get(s).file_num) + "个文件,总大小:" + String.valueOf((double) nexts.get(s).file_size / 1024) + " MB");}//3.以该节点为根节点进行遍历TraversePrefixTree(nexts.get(s), directoryName);}}public void TraversePrefixTreeValid(PrefixTreeNode root, StringBuffer Name) throws IOException {//遍历节点的nextsif (root.nexts == null) {//如果该目录下没有nexts,则直接返回return;}HashMap<String, PrefixTreeNode> nexts = root.nexts;for (String s : nexts.keySet()) {StringBuffer directoryName = new StringBuffer(Name);if (!String.valueOf(directoryName).equals("")) {directoryName.append("/");}directoryName.append(s);//1.如果该目录下包含文件,则输出该目录上级所有目录,并输出该目录下filenum: file_sizeif (nexts.get(s).file_num != 0) {//2.将结果写入文件,去掉最开头的/sum_num += nexts.get(s).file_num;sum_size += nexts.get(s).file_size;System.out.println(directoryName + "/ 目录包含" + String.valueOf(nexts.get(s).file_num) + "个文件,总大小:" + String.valueOf((double) nexts.get(s).file_size / 1024) + " MB");}//3.以该节点为根节点进行遍历TraversePrefixTreeValid(nexts.get(s), directoryName);}}}3)对所构建的前缀树进行测试
从csv文件中读取每一行的目录名,和文件大小,按行调用前缀树的构建。总体代码如下:
import com.obs.prefixTree.PrefixTree;
import com.obs.prefixTree.PrefixTreeNode;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;/*** @author sq* @date 2023/8/28* @Description ${}*/
public class PrefixTreeBuilderfromCsvTest {public static void main(String[] args) throws IOException {//获取要处理的桶清单文件以及要写入的文件String csvFile = "0000018A3A73BC14454759A9F377424D_1.csv";String fileName = "result.csv";//1.初始化前缀树//1.1创建一颗只有根节点的树PrefixTree tree=new PrefixTree(new PrefixTreeNode("",null));//2.按行遍历csv文件String line = "";String csvSplitBy = ",";boolean header_flag = true;int key_index = -1;int size_index = -1;int bucket_index=-1;try (BufferedReader br = new BufferedReader(new FileReader(csvFile))) {while ((line = br.readLine()) != null) {String[] data = line.split(csvSplitBy);if (header_flag) {for (int i=0;i<data.length;i++) {if(data[i].equals("Bucket")){bucket_index=i;}if(data[i].equals("Key")){key_index=i;}if(data[i].equals("Size")){size_index=i;}}header_flag = false;continue;}tree.getRoot().setName(data[bucket_index]);//如果不是第一行,则按照正常数据处理构造前缀树tree.InsertToPrefixTree(data[key_index],Long.parseLong(data[size_index]),tree.getRoot());}} catch (IOException e) {e.printStackTrace();}//3.遍历前缀树FileWriter writer = new FileWriter(fileName);//3.1加入表头writer.write("Directory" +","+ "FileNumber"+","+"FileSize"); // 写入内容writer.write("\n"); // 换行//3.2记录根节点对象数,对象大小//3.2.1写入到文件writer.write(tree.getRoot().getName() +","+ tree.getRoot().getFile_num()+","+tree.getRoot().getFile_size()); // 写入内容writer.write("\n"); // 换行//3.2.2输出到控制台System.out.println(tree.getRoot().getName() +","+ tree.getRoot().getFile_num()+","+tree.getRoot().getFile_size());//3.3 遍历前缀树写入文件tree.TraversePrefixTreeWriteToFile(tree.getRoot(), new StringBuffer(tree.getRoot().getName()), writer);//4.关闭写入流writer.close();}}最后想说一下,树的构建和遍历都不要死记硬背,隶属与递归的问题,都可以使用自然智慧,在尝试中得到普遍逻辑。
相关文章:

利用前缀树获取最小目录
一、任务名: 开发最小目录工具 二、任务描述 开发工具,从桶清单文件中列举出所有最小目录,并列举出每一个最小目录中包含的文件总数与文件总量。 最小目录的解释: 有以下几个目录 a/b/1.txt a/b/2/txt a/3.txt a/b/c/ 则&…...

Java【手撕双指针】LeetCode 18. “四数之和“, 图文详解思路分析 + 代码
文章目录 前言一、四数之和1, 题目2, 思路分析3, 代码 前言 各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你: 📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等 📗 Java数据结构: 顺序表, 链表, 堆…...

OpenCV处理图像和计算机视觉任务时常见的算法和功能
当涉及到OpenCV处理图像和计算机视觉任务时,有许多常见的具体算法和功能。以下是一些更具体的细分: 图像处理算法: 图像去噪:包括均值去噪、高斯去噪、中值滤波等,用于减少图像中的噪声。 直方图均衡化:用…...

Flutter实现StackView
1.让界面之间可以嵌套且执行动画。 2.界面的添加遵循先进后出原则。 3.需要使用AnimateView,请看我上一篇博客。 演示: 代码: Stack: import package:flutter/cupertino.dart;///栈,先进后出 class KqWidgetStack {final Lis…...

c++ future与promise
C11 标准中 头文件中包含了以下几个类和函数: Providers 类:std::promise, std::package_taskFutures 类:std::future, shared_future.Providers 函数:std::async()其他类型:std::future_error, std::future_errc, st…...

在x86机器上的Docker运行arm64容器
1. 引言 工作中常用电脑主机CPU为x86架构,有时由于产品需要,我们需要编译aarch64架构的SDK或者应用程序供使用或者测试。 一种比较快捷的方式是使用aarch64的CPU构建相应操作系统,实现真机运行。但在无arm架构CPU环境下,我们可否…...

centos7删除乱码文件
centos7删除乱码文件1. 小白教程,一看就会,一做就成。 1.解释 当文件名为乱码的时候,无法通过键盘输入文件名,所以在终端下就不能直接利用rm,mv等命令管理文件了。 但是每个文件都有一个i节点号,可以通过…...

uni-app里使用webscoket
实现思路和vue中是一样的。如果想看思路可以看这篇文章:websocket 直接上可以运行的代码: 一、后端nodeJS代码: 1、新建项目文件夹 2、初始化项目: npm init -y 3、项目里安装ws npm i ws --save 4、nodeJS代码࿱…...

jdk17+springboot使用webservice,踩坑记录
这几天wms对接lbpm系统,给我的接口是webservice的,老实说,这个技术很早,奈何人家只支持这个。 环境说明:JDK17 springboot2.6.6。网上很多教程是基于jdk8的,所以很多在17上面跑不起来。折腾两天,…...

计算机网络文件拆分—视频流加载、断点续传
视频流加载 视频流加载的原理是通过网络传输和播放器解码来实现的。 首先,视频文件会被分成一系列小的数据包,通常是以流的形式传输,这些数据包通过网络传输到用户设备。在传输过程中,可以采用各种协议,如HTTP、RTSP…...

JVM 给对象分配内存空间
指针碰撞空闲列表TLAB 为对象分配空间的任务实际上便等同于把一块确定大小的内存块从Java堆中划分出来。 指针碰撞:(Bump The Pointer) 堆的内存是绝对规整的,内存主要分为两部分,所有使用过的内存被放在一边&#x…...

Excel·VBA二维数组组合函数、组合求和
目录 1,二维数组组合函数举例 2,组合求和 之前的文章《ExcelVBA数组组合函数、组合求和》和《ExcelVBA数组排列函数》,都是针对一维数组的组合和排列 二维数组组合:对一个m行*n列的二维数组,每行抽取1个元素进行组合&a…...
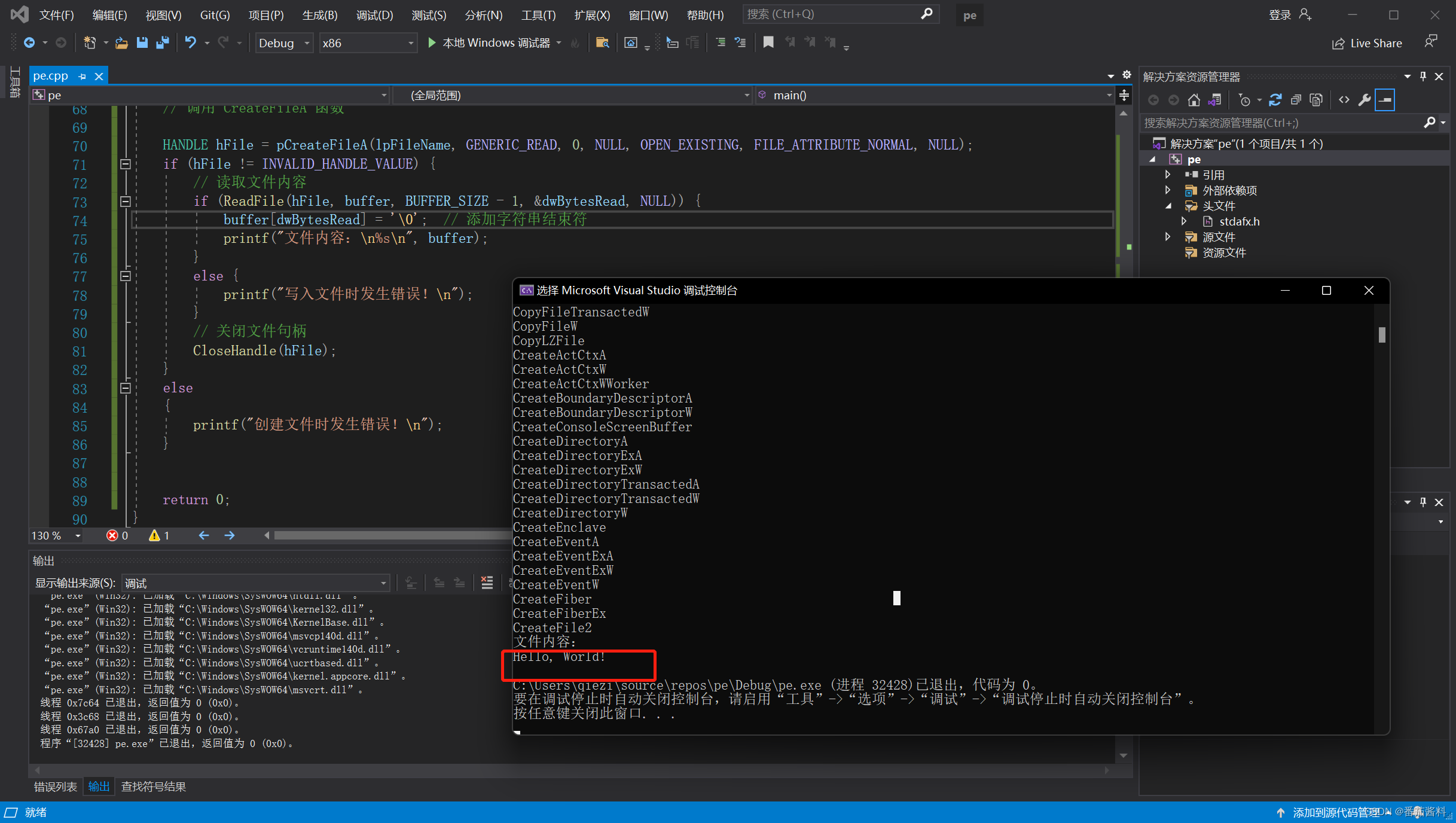
调用自实现MyGetProcAddress获得CreateFileA函数并调用创建写入文件
写文件如下 #include <iostream> #include <Windows.h>typedef HANDLE(WINAPI* CreateFileAFunc)(LPCSTR, DWORD, DWORD, LPSECURITY_ATTRIBUTES, DWORD, DWORD, HANDLE);DWORD MyGetProcAddress(_In_ HMODULE hModule,_In_ LPCSTR lpProcName ){PIMAGE_DOS_HEADE…...

Leetcode 191.位1的个数
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 1 的个数(也被称为汉明重量)。 提示: 请注意,在某些语言(如 Java)中…...
安防监控视频平台EasyCVR视频汇聚平台调用接口出现跨域现象的问题解决方案
视频监控汇聚EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有GB28181、RTSP/Onvif、RTMP等,以及厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等,能对外分发RTSP、RTMP、FLV、HLS、WebRTC等格式的视…...

Python中的一些常用操作
文章目录 一. Python操作之-- 使用Python 提取PDF文件中的表格数据!二:三: Python中的 staticmethodclassmethod方法四: 反斜杠 \五: 终端的解释器提示符号修改六: python使用json.dumps输出中文七…...

go语言调用python脚本
文章目录 代码gopython 在 go语言中调用 python 程序,你可能会用到 代码 亲测 go 测试 go 文件 func TestR(t *testing.T) {// 设置要执行的Python脚本和参数scriptPath : "../nansen.py"arg1 : "nansen"// 执行Python脚本cmd : exec.Comm…...

2.3 【MySQL】命令行和配置文件中启动选项的区别
在命令行上指定的绝大部分启动选项都可以放到配置文件中,但是有一些选项是专门为命令行设计的,比方说defaults-extra-file 、 defaults-file 这样的选项本身就是为了指定配置文件路径的,再放在配置文件中使用就没啥意义了。 如果同一个启动选…...

外部库/lib/maven依赖项 三者关系
外部库(存放项目初始配置的jar包)(它的文件夹里并没有包含lib文件夹的引的外部的依赖的jar包) lib(存放外部导入到项目的依赖的jar包) maven依赖项(管理项目所有的jar包依赖) 三者存放jar包的关系 项目所依赖的全部的jar包 maven依赖项的jar包 外部库中的jar包 lib中的…...
在线制作作息时间表
时光荏苒,岁月如梭,人们描述时光易逝的句子,多如星河。 一寸光阴一寸金,寸金难买寸光阴。 人生就是一段时间而已,所以我明白了一个道理 人生之中最大的浪费就是时间的浪费 因此我想我们教给我们孩子重要的一课应该也是…...

Heightmapper完全指南:5步将全球地形数据变成3D模型
Heightmapper完全指南:5步将全球地形数据变成3D模型 【免费下载链接】heightmapper interactive heightmaps from terrain data 项目地址: https://gitcode.com/gh_mirrors/he/heightmapper 还在为3D地形建模发愁吗?Heightmapper让你的地形创作效…...

硬件工程师的‘第一板’:从最小系统设计到PCB Layout的STM32实战指南
STM32最小系统设计实战:从原理到PCB的工程化思维 作为一名硬件工程师,第一次独立完成PCB设计时的忐忑至今记忆犹新。那块承载着STM32最小系统的绿色电路板,不仅是我职业生涯的"第一板",更是一次从理论到实践的完整跨越。…...

终极B站缓存视频转换指南:快速将m4s无损转换为MP4
终极B站缓存视频转换指南:快速将m4s无损转换为MP4 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经因为B站视频突然下架而感…...

V-REP/CoppeliaSim机器人仿真进阶:Graph模块3D轨迹可视化与数据导出实战解析
1. Graph模块基础与3D轨迹可视化原理 在机器人仿真中,轨迹可视化就像给机械臂装上了"运动摄像机"。V-REP/CoppeliaSim的Graph模块就是这个摄像机的核心部件,它能记录机械臂末端执行器在三维空间中的每一个细微动作。我刚开始用这个功能时&…...

别再傻傻分不清了!全桥、半桥、推挽电源拓扑,到底哪个更适合你的项目?
全桥、半桥与推挽拓扑实战选型指南:从理论到工程落地的关键抉择 在电力电子设计领域,拓扑结构的选择往往决定着整个项目的成败。当我第一次面对500W工业电源设计需求时,曾天真地认为"功率越大拓扑越高级"——这个错误认知让我付出了…...

G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制
G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

告别硬编码:模板引擎的加载逻辑与层叠继承艺术
更多内容请见: 《Python Web项目集锦》 - 专栏介绍和目录 文章目录 前言:被低估的视图半壁江山 第一章:破除迷信——Django 模板的设计哲学 1.1 限制的威力:为什么没有乘法器和复杂表达式? 1.2 两种角色的对立统一 第二章:寻宝游戏——模板加载器的底层引擎 2.1 TEMPLATE…...
)
别再死记PRBS7/15了!用Python+NumPy手搓一个可配置的PRBS码生成器(附完整代码)
用Python构建可配置PRBS生成器:从LFSR原理到信号仿真实战 在数字通信和高速电路设计中,工程师们经常需要生成特定的测试信号来验证系统性能。伪随机二进制序列(PRBS)因其近似真实数据流的特性,成为信号完整性测试的黄金…...

技术管理者最痛:如何让团队从“要我做”变成“我要做”?
在软件测试领域,技术管理者常常陷入一种无形的焦虑:测试用例的执行越来越像机械的流水线,回归测试变成了纯粹的体力劳动,而探索性测试和深度质量分析这些真正有价值的活动,却总是无人主动认领。你尝试过推行自动化覆盖…...

MQTT 协议 超详细精讲
一、MQTT 协议简介全称:Message Queuing Telemetry Transport(消息队列遥测传输协议)定位:专为物联网、嵌入式设备、低带宽、弱网环境设计的轻量级发布 / 订阅式消息传输协议,是数字孪生、智能家居、工业物联网最常用的…...