用变压器实现德-英语言翻译【01/8】:嵌入层
一、说明
本文是“用变压器实现德-英语言翻译”系列的第一篇文章。它引入了小规模的嵌入来建立感知系统。接下来是嵌入层的变压器使用。下面简要概述了每种方法,然后是德语到英语的翻译。
二、技术背景
嵌入层的目标是使模型能够详细了解单词、标记或其他输入之间的关系。此嵌入层可以被视为将数据从高维空间转换为低维空间,也可以视为将数据从低维空间映射到高维空间。
2.1 从单热向量到嵌入向量
在自然语言处理中,令牌派生自可能包含章节、段落或句子的数据语料库。这些以各种方式分解成更小的部分,但最常见的标记化方法是按单词。语料库中所有独特的单词都被称为词汇表。
词汇表中的每个单词都被分配一个整数,因为它更容易被计算机处理。有多种方法可以分配这些整数,但同样,最简单的方法是按字母顺序分配它们。
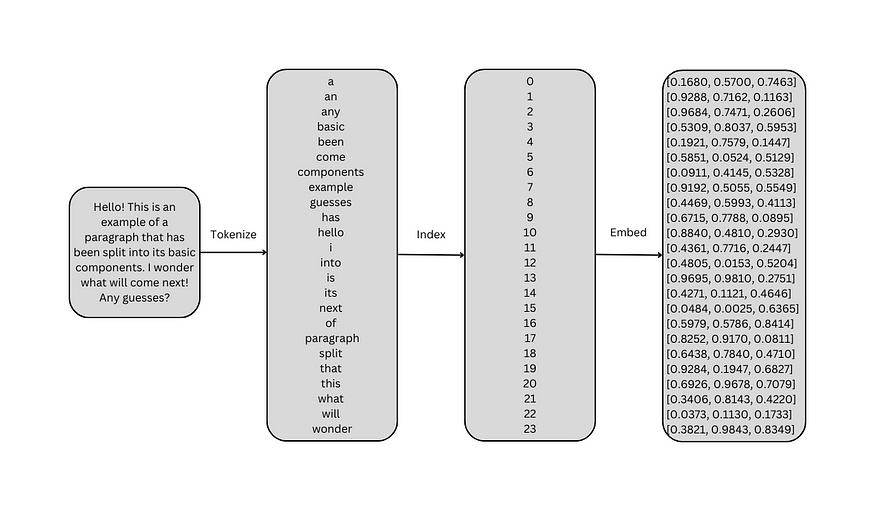
下图演示了将较大的语料库分解为其组件并为每个组件分配整数的过程。请注意,为简单起见,标点符号被去掉,文本设置为小写。

通过为每个单词分配索引而创建的数字顺序意味着一种关系。由于这不是意图,因此索引通常用于为每个单词创建一个独热编码向量。单热向量与词汇表的长度相同。在这种情况下,每个向量有 24 个元素。它被称为“一热”向量,因为只有一个元素被“打开”或设置为 1;所有其他令牌都处于“关闭”状态或设置为 0。1 的索引对应于分配给单词的整数值。通常,模型学习预测向量中给定索引的最高概率。
当一个模型只有十几个标记或类可供预测时,独热编码向量通常是一种方便的表示形式。但是,大型语料库可以有数十万个代币。不是使用充满零的稀疏向量,这些向量没有传达太多意义,而是使用嵌入层将向量映射到较小的维度。可以训练这些嵌入式向量来传达有关每个单词及其与其他单词的关系的更多信息。
本质上,每个单词都由一个d_model维向量表示,其中d_model可以是任何数字。它只是指示嵌入维度的数量。如果d_model是 2 或 3,则可以可视化每个单词之间的关系,但通常根据任务使用 256、512 和 1024 的值。
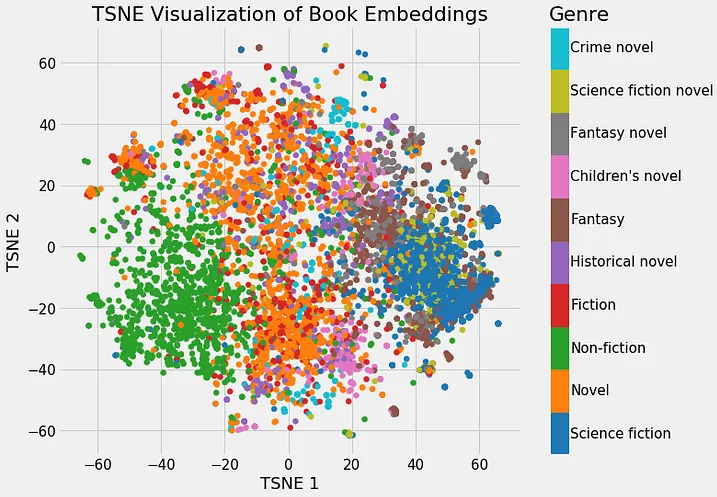
下面可以看到一个优化嵌入的示例,其中类似类型的书籍彼此靠近嵌入:
2.2 嵌入向量
嵌入矩阵的大小为 (vocab_size, d_model)。这允许将大小为 (seq_length, vocab_size) 的单热向量矩阵乘以它以获得新的嵌入式表示。序列长度由 seq_length 表示,即序列中的标记数。请记住,到目前为止,可视化中的“序列”是整个词汇表。在实践中,将使用词汇的子集,例如“基本段落”。该序列将被标记化、索引并转换为独热编码向量矩阵。然后,这些独热编码向量将能够与嵌入矩阵相乘。
嵌入序列的大小为 (seq_length, vocab_size) x (vocab_size, d_model) = (seq_length, d_model)。这意味着句子中的每个单词现在都由d_model维向量表示,而不是vocab_size元素的独热编码向量。下面可以看到此矩阵乘法的示例。索引序列的形状为 (3,24),嵌入矩阵的形状为 (24, 3)。一旦它们相乘,输出就是一个 (3,3) 矩阵。每个单词都由其 3 元素嵌入向量表示。

当独热编码矩阵与嵌入层相乘时,将返回嵌入层的相应向量,而不进行任何更改。下面是独热编码向量和嵌入矩阵的整个词汇表之间的矩阵乘法。输出是嵌入矩阵。

这表明有一种更简单的方法可以在不使用矩阵乘法的情况下获取这些相同的值,因为矩阵乘法可能会占用大量资源。分配给每个单词的整数可用于直接索引嵌入矩阵,而不是从 one-hot 编码向量转到 d_model 维嵌入(从较大维度到较小维度)。这就像从一维转到d_model维,提供有关令牌的更多信息。
下图显示了如何在不乘法的情况下获得完全相同的结果:
2.3 从头开始嵌入
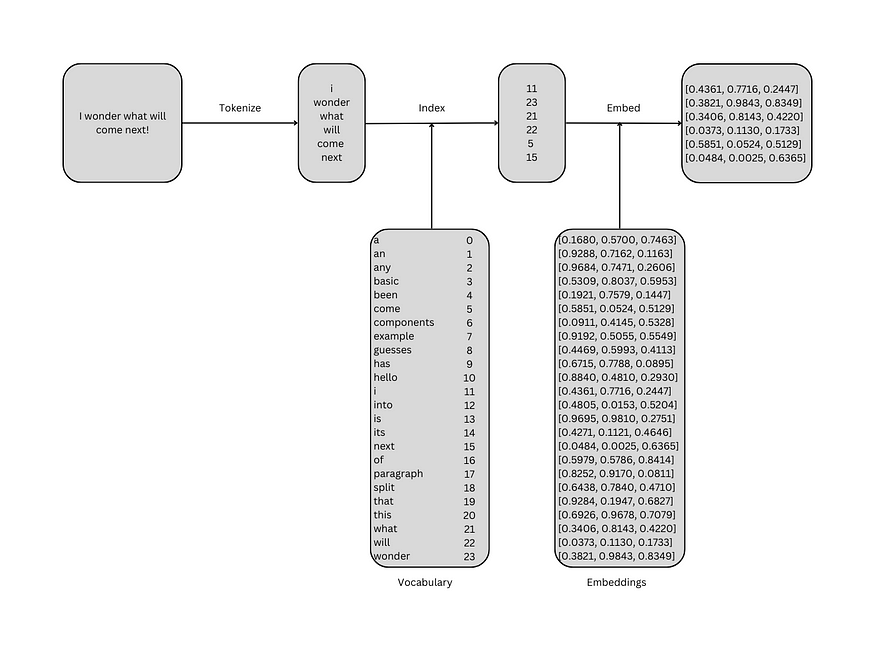
可以在 Python 中创建上述图的简单实现。嵌入序列需要一个分词器、单词及其索引的词汇表,以及词汇表中每个单词的三维嵌入。分词器将序列拆分为其标记,在本示例中为小写单词。下面的简单函数从序列中删除标点符号,将其拆分为标记,并将它们小写。
# importing required libraries
import math
import copy
import numpy as np# torch packages
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor# visualization packages
from mpl_toolkits import mplot3d
import matplotlib.pyplot as pltexample = "Hello! This is an example of a paragraph that has been split into its basic components. I wonder what will come next! Any guesses?"def tokenize(sequence):# remove punctuationfor punc in ["!", ".", "?"]:sequence = sequence.replace(punc, "")# split the sequence on spaces and lowercase each tokenreturn [token.lower() for token in sequence.split(" ")]tokenize(example)['hello', 'this', 'is', 'an', 'example', 'of', 'a', 'paragraph', 'that',
'has', 'been', 'split', 'into', 'its', 'basic', 'components', 'i',
'wonder', 'what', 'will', 'come', 'next', 'any', 'guesses']创建分词器后,可以为示例创建词汇表。词汇表包含构成数据的唯一单词列表。虽然示例中没有重复项,但仍应将其删除。一个简单的例子是下面的句子:“我很酷,因为我很矮。词汇将是“我,是,酷,因为,短”。然后,这些词将按字母顺序排列:“我,因为,酷,我,短”。最后,它们将被分配一个整数:“am: 0, 因为: 1, cool: 2, i: 3, short: 4”。此过程在下面的函数中实现。
def build_vocab(data):# tokenize the data and remove duplicatesvocab = list(set(tokenize(data)))# sort the vocabularyvocab.sort()# assign an integer to each wordstoi = {word:i for i, word in enumerate(vocab)}return stoi# build the vocab
stoi = build_vocab(example)stoi {'a': 0,'an': 1,'any': 2,'basic': 3,'been': 4,'come': 5,'components': 6,'example': 7,'guesses': 8,'has': 9,'hello': 10,'i': 11,'into': 12,'is': 13,'its': 14,'next': 15,'of': 16,'paragraph': 17,'split': 18,'that': 19,'this': 20,'what': 21,'will': 22,'wonder': 23}此词汇现在可用于将任何标记序列转换为其整数表示形式。
sequence = [stoi[word] for word in tokenize("I wonder what will come next!")]
sequence[11, 23, 21, 22, 5, 15]下一步是创建嵌入层,它只不过是一个大小为 (vocab_size, d_model) 的随机值矩阵。这些值可以使用torch.rand生成。
# vocab size
vocab_size = len(stoi)# embedding dimensions
d_model = 3# generate the embedding layer
embeddings = torch.rand(vocab_size, d_model) # matrix of size (24, 3)
embeddingstensor([[0.7629, 0.1146, 0.1228],[0.3628, 0.5717, 0.0095],[0.0256, 0.1148, 0.1023],[0.4993, 0.9580, 0.1113],[0.9696, 0.7463, 0.3762],[0.5697, 0.5022, 0.9080],[0.2689, 0.6162, 0.6816],[0.3899, 0.2993, 0.4746],[0.1197, 0.1217, 0.6917],[0.8282, 0.8638, 0.4286],[0.2029, 0.4938, 0.5037],[0.7110, 0.5633, 0.6537],[0.5508, 0.4678, 0.0812],[0.6104, 0.4849, 0.2318],[0.7710, 0.8821, 0.3744],[0.6914, 0.9462, 0.6869],[0.5444, 0.0155, 0.7039],[0.9441, 0.8959, 0.8529],[0.6763, 0.5171, 0.9406],[0.1294, 0.6113, 0.5955],[0.3806, 0.7946, 0.3526],[0.2259, 0.4360, 0.6901],[0.6300, 0.2691, 0.9785],[0.2094, 0.9159, 0.7973]])创建嵌入后,可以使用索引序列为每个标记选择适当的嵌入。原始序列的形状为 (6, ),值为 [11, 23, 21, 22, 5, 15]。
# embed the sequence
embedded_sequence = embeddings[sequence]embedded_sequencetensor([[0.7110, 0.5633, 0.6537],[0.2094, 0.9159, 0.7973],[0.2259, 0.4360, 0.6901],[0.6300, 0.2691, 0.9785],[0.5697, 0.5022, 0.9080],[0.6914, 0.9462, 0.6869]])现在,六个标记中的每一个都被一个 3 元素向量替换;新形状为 (6, 3)。
由于这些令牌中的每一个都有三个组件,因此它们可以在三个维度上映射。虽然此图显示了一个未经训练的嵌入矩阵,但经过训练的嵌入矩阵会像前面提到的书籍示例一样将相似的单词彼此靠近。
# visualize the embeddings in 3 dimensions
x, y, z = embedded_sequences[:, 0], embedded_sequences[:, 1], embedded_sequences[:, 2]
ax = plt.axes(projection='3d')
ax.scatter3D(x, y, z) 
2.4 使用 PyTorch 模块进行嵌入
由于 PyTorch 将用于实现转换器,因此 nn.可以分析嵌入模块。PyTorch将其定义为:
一个简单的查找表,用于存储固定字典和大小的嵌入。
此模块通常用于存储词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的词嵌入。
这准确地描述了在前面的示例中使用索引而不是独热向量时所执行的操作。
至少,nn。嵌入需要vocab_size和嵌入维度,随着d_model的发展,将继续对其进行标注。提醒一下,这是模型维度的缩写。
下面的代码创建了一个形状为 (24, 3) 的嵌入矩阵。
# vocab size
vocab_size = len(stoi) # 24# embedding dimensions
d_model = 3# create the embeddings
lut = nn.Embedding(vocab_size, d_model) # look-up table (lut)# view the embeddings
lut.state_dict()['weight']tensor([[-0.3959, 0.8495, 1.4687],[ 0.2437, -0.3289, -0.5475],[ 0.9787, 0.7395, 2.0918],[-0.4663, 0.4056, 1.2655],[-1.0054, 1.4883, -0.1254],[-0.1028, -1.1913, 0.0523],[-0.2654, -1.0150, 0.4967],[-0.4653, -1.9941, -1.7128],[ 0.3894, -0.9368, 1.5543],[-1.1358, -0.2493, 0.6290],[-1.4935, 1.1509, -1.8723],[-0.0421, 1.2857, -0.4009],[-0.2699, -0.8918, -1.0352],[-1.3443, 0.4688, 0.1536],[ 0.3638, 0.1003, -0.2809],[ 1.4208, -0.0393, 0.7823],[-0.4473, -0.4605, 1.2681],[ 1.1315, -1.4704, 0.2809],[ 0.4270, -0.2067, -0.7951],[-1.0129, 0.0706, -0.3417],[ 1.4999, -0.2527, 0.4287],[-1.9280, -0.6485, 0.4660],[ 0.0670, -0.5822, 0.0996],[-0.7058, 0.2849, 1.1725]], grad_fn=<EmbeddingBackward0>)如果将与之前相同的索引序列 [11, 23, 21, 22, 5, 15] 传递给它,则输出将是一个 (6, 3) 矩阵,其中每个标记由其三维嵌入向量表示。索引必须采用张量的形式,数据类型为整数或长整型。
indices = torch.Tensor(sequence).long()embeddings = lut(indices)embeddings输出将是:
tensor([[ 0.7584, 0.2332, -1.2062],[-0.2906, -1.2168, -0.2106],[ 0.1837, -0.9425, -1.9011],[-0.7708, -1.1671, 0.2051],[ 1.5548, 1.0912, 0.2006],[-0.8765, 0.8829, -1.3169]], grad_fn=<EmbeddingBackward0>)三、变压器中的嵌入层
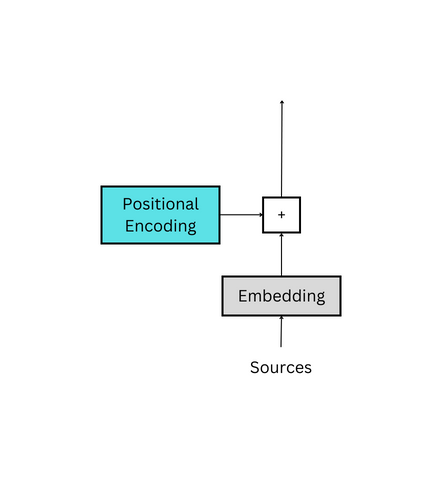
在原始论文中,嵌入层用于编码器和解码器。对nn的唯一补充。嵌入模块是一个标量。嵌入权重乘以 √(d_model)。这有助于在下一步中将嵌入添加到位置编码时保留基本含义。这实质上使位置编码相对较小,并减少了其对嵌入的影响。这个堆栈溢出线程更多地讨论了它。
为了实现这一点,可以创建一个类;它将被称为嵌入,并利用PyTorch的nn。嵌入模块。此实现基于带注释的转换器。
class Embeddings(nn.Module):def __init__(self, vocab_size: int, d_model: int):"""Args:vocab_size: size of vocabularyd_model: dimension of embeddings"""# inherit from nn.Modulesuper().__init__() # embedding look-up table (lut) self.lut = nn.Embedding(vocab_size, d_model) # dimension of embeddings self.d_model = d_model def forward(self, x: Tensor):"""Args:x: input Tensor (batch_size, seq_length)Returns:embedding vector"""# embeddings by constant sqrt(d_model)return self.lut(x) * math.sqrt(self.d_model) 四、 前向传递
此嵌入类的工作方式与 nn 相同。嵌入。下面的代码演示了它与前面示例中使用的单个序列的用法。
lut = Embeddings(vocab_size, d_model)lut(indices)tensor([[-1.1189, 0.7290, 1.0581],[ 1.7204, 0.2048, 0.2926],[-0.5726, -2.6856, 2.4975],[-0.7735, -0.7224, -2.9520],[ 0.2181, 1.1492, -1.2247],[ 0.1742, -0.8531, -1.7319]], grad_fn=<MulBackward0>)到目前为止,每个嵌入中只使用了一个序列。但是,模型通常使用一批序列进行训练。这实质上是一个序列列表,这些序列被转换为它们的索引,然后嵌入。这可以在下图中看到。
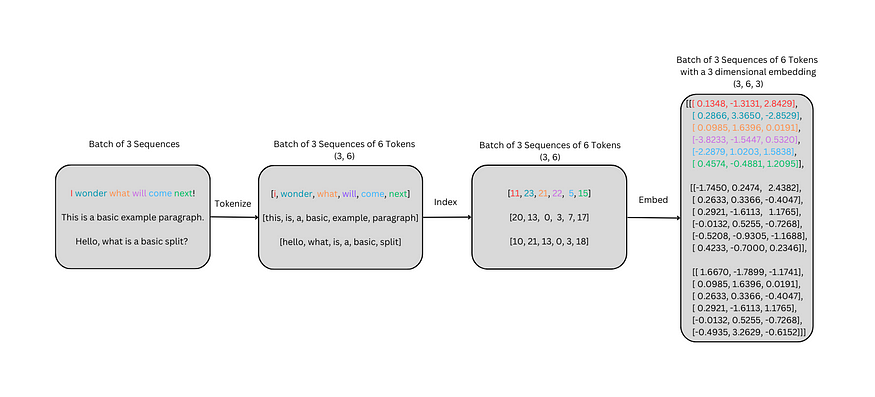
# list of sequences (3, )
sequences = ["I wonder what will come next!","This is a basic example paragraph.","Hello, what is a basic split?"]虽然前面的示例很简陋,但它适用于序列批次。上图中显示的示例是具有三个序列的批处理;标记化后,每个序列由六个标记表示。标记化序列的形状为 (3, 6),与 (batch_size, seq_length) 相关。基本上,三个,六个字的句子。
# tokenize the sequences
tokenized_sequences = [tokenize(seq) for seq in sequences]
tokenized_sequences[['i', 'wonder', 'what', 'will', 'come', 'next'],['this', 'is', 'a', 'basic', 'example', 'paragraph'],['hello', 'what', 'is', 'a', 'basic', 'split']]然后可以使用词汇表将这些标记化序列转换为其索引表示形式。
# index the sequences
indexed_sequences = [[stoi[word] for word in seq] for seq in tokenized_sequences]indexed_sequences[[11, 23, 21, 22, 5, 15], [20, 13, 0, 3, 7, 17], [10, 21, 13, 0, 3, 18]]最后,这些索引序列可以转换为可以通过嵌入层传递的张量。
# convert the sequences to a tensor
tensor_sequences = torch.tensor(indexed_sequences).long()lut(tensor_sequences)tensor([[[ 0.1348, -1.3131, 2.8429],[ 0.2866, 3.3650, -2.8529],[ 0.0985, 1.6396, 0.0191],[-3.8233, -1.5447, 0.5320],[-2.2879, 1.0203, 1.5838],[ 0.4574, -0.4881, 1.2095]],[[-1.7450, 0.2474, 2.4382],[ 0.2633, 0.3366, -0.4047],[ 0.2921, -1.6113, 1.1765],[-0.0132, 0.5255, -0.7268],[-0.5208, -0.9305, -1.1688],[ 0.4233, -0.7000, 0.2346]],[[ 1.6670, -1.7899, -1.1741],[ 0.0985, 1.6396, 0.0191],[ 0.2633, 0.3366, -0.4047],[ 0.2921, -1.6113, 1.1765],[-0.0132, 0.5255, -0.7268],[-0.4935, 3.2629, -0.6152]]], grad_fn=<MulBackward0>)输出将是一个 (3, 6, 3) 矩阵,它与 (batch_size、seq_length、d_model) 相关。本质上,每个索引令牌都被其相应的三维嵌入向量所取代。
在进入下一节之前,了解此数据的形状(batch_size、seq_length d_model)非常重要:
- batch_size与一次提供的序列数相关,通常为 16、32 或 64。
- seq_length与标记化后每个序列中的单词或标记数相关。
- d_model与嵌入每个令牌后的模型大小相关。
有关位置编码的文章是本系列的下一篇。
请不要忘记点赞和关注更多!:)
五、引用
- 图片来源:Will Koehrsen
- PyTorch 的嵌入模块
- 堆栈溢出讨论
- 带注释的变压器
- 变压器从零开始
相关文章:
用变压器实现德-英语言翻译【01/8】:嵌入层
一、说明 本文是“用变压器实现德-英语言翻译”系列的第一篇文章。它引入了小规模的嵌入来建立感知系统。接下来是嵌入层的变压器使用。下面简要概述了每种方法,然后是德语到英语的翻译。 二、技术背景 嵌入层的目标是使模型能够详细了解单词、标记或其他输入之间的…...

【vue3.0中ref与reactive的区别及使用】
什么是ref与reactive ref与reactive都是Vue3.0中新增的API,用于响应式数据的处理。 1. ref ref是一个函数,可以用于将一个普通的数据类型转换成响应式数据。ref返回一个包含value属性的对象,通过修改value属性的值,可以触发组件…...
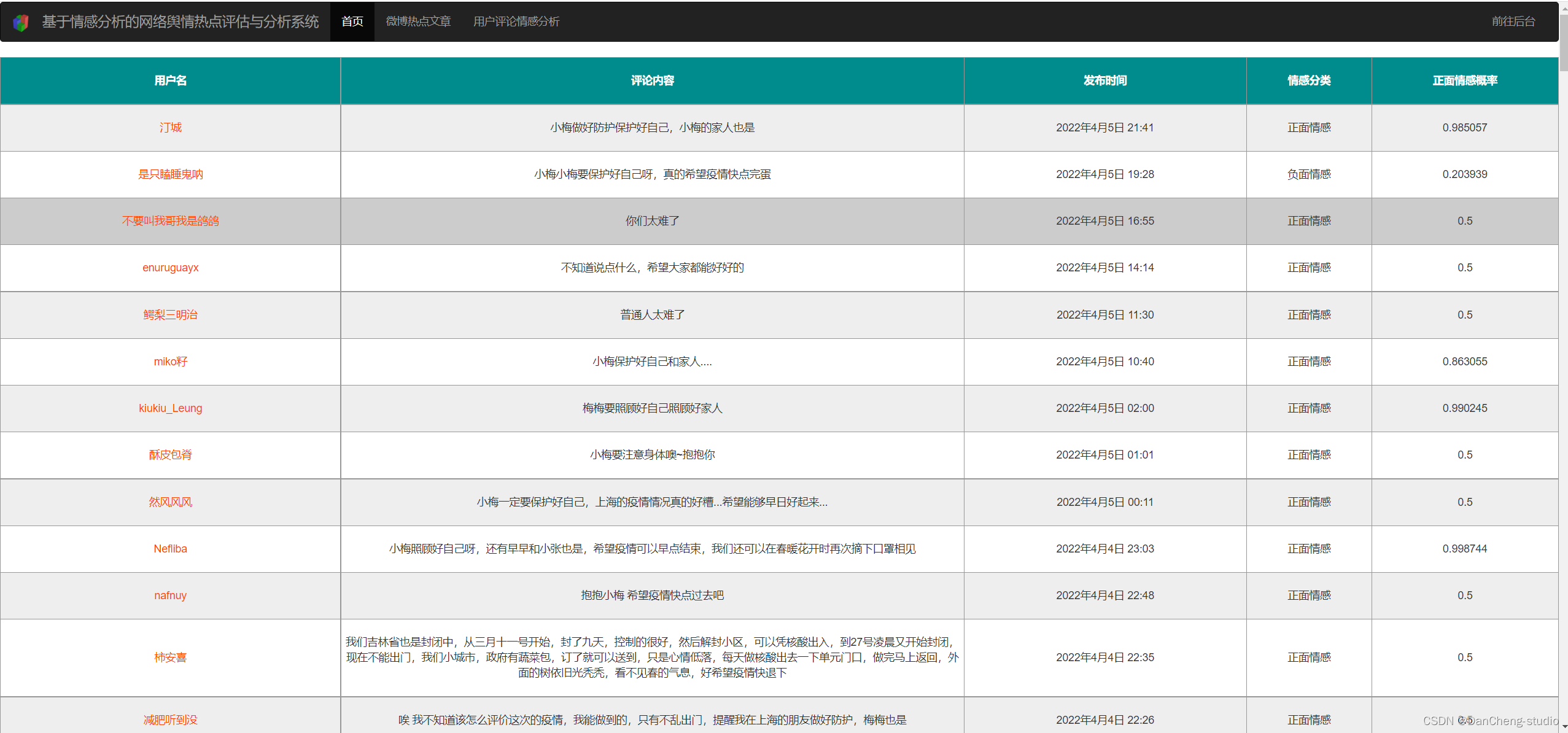
计算机竞赛 基于情感分析的网络舆情热点分析系统
文章目录 0 前言1 课题背景2 数据处理3 文本情感分析3.1 情感分析-词库搭建3.2 文本情感分析实现3.3 建立情感倾向性分析模型 4 数据可视化工具4.1 django框架介绍4.2 ECharts 5 Django使用echarts进行可视化展示5.1 修改setting.py连接mysql数据库5.2 导入数据5.3 使用echarts…...

C++ 动态分配内存|动态数组
int** arr new int* [n]; for (int i 0; i < n; i) {arr[i] new int[2]; } 以上代码是用C动态分配了一个二维数组arr,其中arr是一个指向int指针的指针,n是一个整数。代码的目的是创建一个包含n个大小为2的整数数组的二维数组。 首先,…...

React Diff算法原理
文章目录 前言Diff算法原理 前言 👉点此(想要了解Diff算法) Diff算法原理 React Diff算法是React用于更新虚拟DOM树的一种算法。它通过比较新旧虚拟DOM树的差异,然后只对有差异的部分进行更新,从而提高性能。 Reac…...
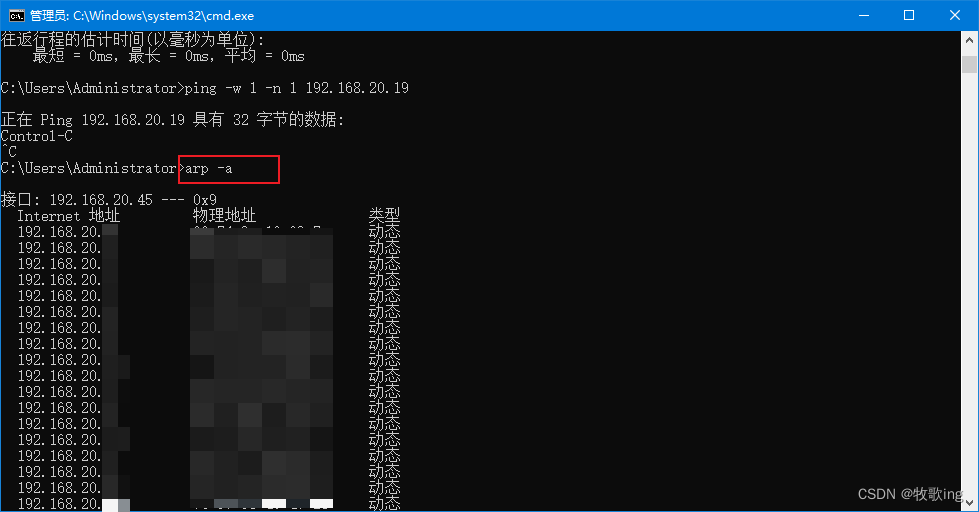
查局域网所有占用IP
查局域网所有占用IP 按:winr 出现下面界面,在文本框中输入 cmd 按确定即可出现cmd命令界面 在cmd命令窗口输入你想要ping的网段,下面192.168.20.%i即为你想要ping的网段,%i代表0-255 for /L %i IN (1,1,254) DO ping -w 1 -n 1…...

【MySQL】引擎类型
与其他DBMS一样,MySQL有一个 具体管理和处理数据的内部引擎 。在使用create table语句时,该引擎具体创建表,而在使用select或进行其他数据库处理时,该引擎在内部处理你的请求。多数时候,引擎都隐藏在DBMS内࿰…...

springMVC之HttpMessageConverter
文章目录 前言一、RequestBody二、RequestEntity三、ResponseBody四、SpringMVC处理json五、SpringMVC处理ajax六、RestController注解七、ResponseEntity总结 前言 HttpMessageConverter,报文信息转换器,将请求报文转换为Java对象,或将Java…...

计算机网络aaaaaaa
差错检测 在一段时间内,传输错误的比特占所传输比特总数的比率称为误码率BER(Bit Error Rate) 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111111111111111111…...
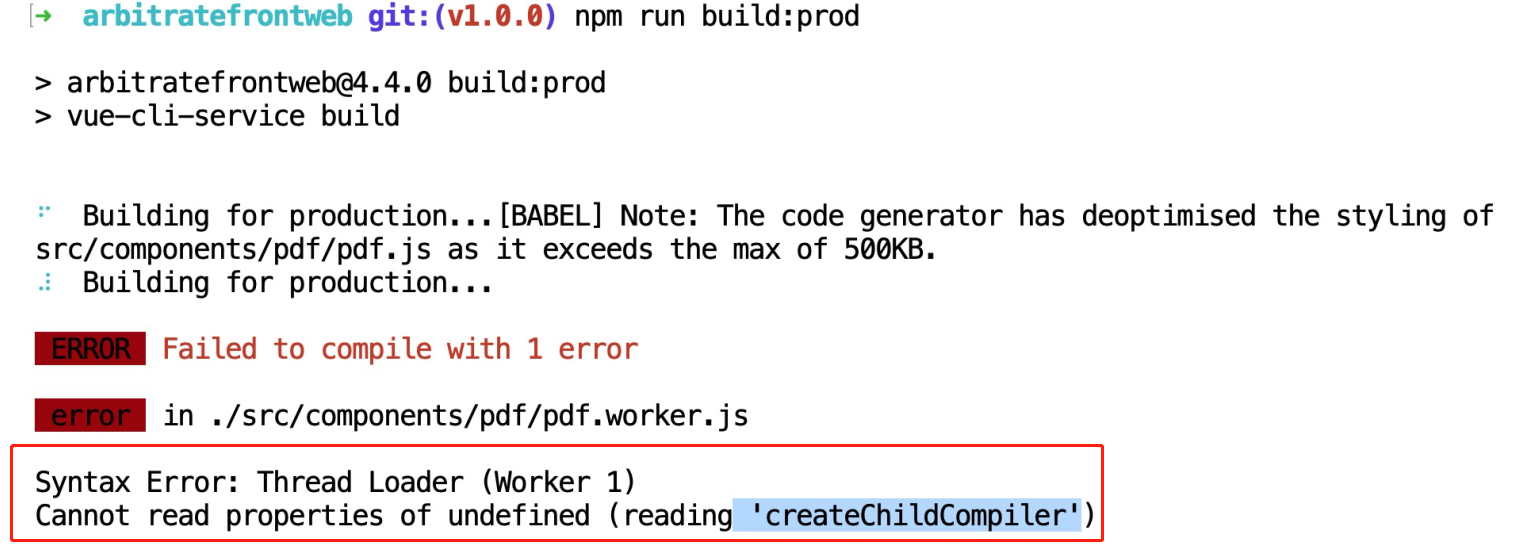
pdf.js构建时,报Cannot read property ‘createChildCompiler‘ of undefined #177的解决方法
在本地和CI工具进行构建时,报如下错误。 Cannot read property createChildCompiler of undefined #177解决方法: 找到vue.config.js,在 module.exports {parallel: false, //新增的一行chainWebpack(config) {....config.module.rule(&…...

Spring Boot(Vue3+ElementPlus+Axios+MyBatisPlus+Spring Boot 前后端分离)【六】
😀前言 本篇博文是关于Spring Boot(Vue3ElementPlusAxiosMyBatisPlusSpring Boot 前后端分离)【六】,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章…...

idea配置注释模板
一、类的模板 设置里面依次找到图中标注的地方 填入 /** ${describe} author 填入你的名字 date ${YEAR}-${MONTH}-${DAY} ${TIME} version 1.0.0 */配置完成后,新创建的类就会自动生成类开头的注释 二、方法的注释模板 如图创建模板 步骤6中填入 *** $descrip…...

Unity编辑器扩展:提高效率与创造力的关键
Unity编辑器扩展:提高效率与创造力的关键 前言 一、理解Unity编辑器二、扩展Unity编辑器的意义三、扩展Unity编辑器的必要性四、Unity编辑器的扩展方式五、扩展Unity编辑器的步骤六、Unity编辑器扩展的应用案例七、总结 前言 Unity是一款广泛使用的游戏开发引擎&am…...

Java之对象引用实践
功能概述 从JDK1.2版本开始,程序可以通过4种类型的对象的引用来管控对象的生命周期。这4种引用分别为,强引用、软引用、弱引用和虚引用。本文中针对各种引用做了相关测试,并做对应分析。 功能实践 场景1:弱引用、虚引用、软引用…...
IntelliJ IDEA快捷键大全 + 动图演示!
来自:https://mp.weixin.qq.com/s/434xV02QkDiAFC1yFCAtZw 一、构建/编译 二、文本编辑 三、光标操作 四、文本选择 五、代码折叠 六、多个插入符号和范围选择 七、辅助编码 八、上下文导航 九、查找操作 十、符号导航 十一、代码分析 十二、运行和调试 …...
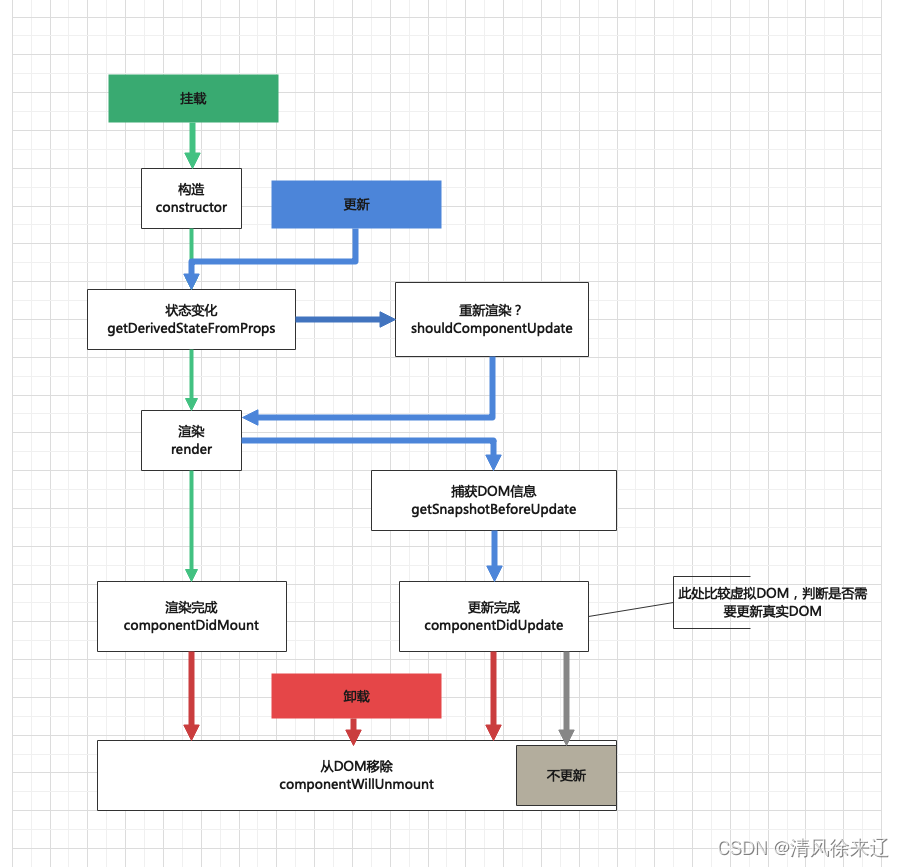
React 生命周期
React的生命周期 一、什么是React的生命周期二、传统生命周期2.1、挂载(Mounting)2.2、更新(Updating)2.3、卸载(Unmounting)2.4、API2.4.1、render2.4.1.1、Updating 阶段,render调用完还有可能…...

5G智能网关如何解决城市停车痛点难点
2023年上半年,我国汽车新注册登记1175万辆,同比增长5.8%,88个城市汽车保有量超过100万辆,北京、成都等24个城市超过300万辆。随着车辆保有量持续增加,停车难问题长期困扰城市居民,也导致城市路段违停普遍、…...

docker 学习-- 04 实践搭建 1(宝塔)
docker 学习-- 04 实践 1(宝塔) docker 学习-- 01 基础知识 docker 学习-- 02 常用命令 docker 学习-- 03 环境安装 docker 学习-- 04 实践 1(宝塔) docker 学习-- 04 实践 2 (lnpmr环境) 通过上面的学…...

MySQL的mysql-bin.00xx binlog日志文件的清理
目录 引言手工清理配置自动清理 引言 公司一个项目生产环境mysql数据盘占用空间增长得特别快,经过排查发现是开启了mysql的binlog日志。如果把binlog日志关闭,如果操作万一出现问题,就没有办法恢复数据,很不安全,只能…...

Java实现SM2前后端加解密
Sm2加解密原理,非对称加密,公钥加密,私钥解密。公私钥对成对生成,加密端解密端各自保存。用公钥加密必须要用对应的私钥才能解密,保证安全性。 这里我们实现的功能是前端加密,后端解密,这样前端…...
Transformer与NLP资源全指南:从原理到工程实践的高效学习路径
1. 项目概述:为什么我们需要一个Transformer与NLP的“Awesome”清单?如果你在过去几年里深度参与过自然语言处理(NLP)领域的工作或学习,那么“Transformer”这个词对你来说,可能已经从一种新颖的架构&#…...
)
地理学者必抢的AI协同时代入场券:NotebookLM+QGIS工作流搭建指南(仅限首批内测用户验证版)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM地理学研究辅助的范式革命 从静态文献到动态知识图谱 NotebookLM 通过语义切片与向量对齐技术,将地理学经典文献(如《人文地理学导论》《自然地理学原理》ÿ…...

AI智能体记忆系统构建指南:从向量检索到混合搜索的工程实践
1. 项目概述:构建一个能“记住”的智能体最近在折腾AI智能体(Agent)开发的朋友,估计都遇到过同一个头疼的问题:这玩意儿怎么跟金鱼似的,聊两句就忘?你让它帮你整理一份周报,它吭哧吭…...

如何让GPT-3开口说话?揭秘微调技巧,打造你的专属AI模型!
本文详细介绍了微调技术在AI模型中的应用,通过将通用模型如GPT-3进行微调,可以使其适应特定任务,如ChatGPT或GitHub Copilot。微调与普通提示词工程最大的区别在于,它能真正让模型学会数据,而非仅仅是“看到”数据。文…...

Aviator表达式引擎:从编译优化到规则引擎实战
1. Aviator表达式引擎初探 第一次接触Aviator是在一个电商风控项目中,当时系统需要处理大量实时交易规则判断。传统的if-else代码已经膨胀到难以维护的程度,每次业务规则变更都需要重新发布。这时候技术负责人推荐了Aviator,一个基于Java的高…...

第11章:C++ PGO与LTO优化
第11章:C++ PGO与LTO优化 本章定位:第四卷《实战卷》第三篇"性能优化"第 11 章。 在第 10 章"找热点"和第 11 章"改代码"之后,本章讨论"什么也不改、只调编译选项"能再榨出 5%-30% 的性能:LTO 让编译器看到全程序,PGO 让它看到运…...

HoYo.Gacha终极指南:如何轻松管理你的米哈游抽卡记录
HoYo.Gacha终极指南:如何轻松管理你的米哈游抽卡记录 【免费下载链接】HoYo.Gacha ✨ 一个非官方的工具,用于管理和分析你的 miHoYo 抽卡记录。(原神 | 崩坏:星穹铁道 | 绝区零)An unofficial tool for managing and a…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...

Eviews面板数据建模保姆级教程:从Hausman检验到模型选择,一次讲透固定效应与随机效应
Eviews面板数据建模实战指南:从数据导入到模型选择的完整流程 面板数据分析作为计量经济学中的重要工具,能够同时捕捉时间和个体维度的信息。对于刚接触Eviews的研究者来说,如何正确建立面板模型往往令人困惑——从数据准备到模型选择&#x…...

Compose-Skill:为Jetpack Compose应用注入AI能力的组件化技能库
1. 项目概述:一个为Compose应用注入AI能力的技能库最近在折腾Jetpack Compose项目时,我一直在想,能不能让UI开发也“智能”一点?比如,用户输入一段模糊的描述,界面就能自动生成对应的组件布局;或…...