无涯教程-分类算法 - 简介
分类可以定义为根据观测值或给定数据点预测类别的过程。分类的输出可以采用"黑色"或"白色"或"垃圾邮件"或"非垃圾邮件"的形式。
在数学上,分类是从输入变量(X)到输出变量(Y)近似映射函数(f)的任务,它属于有监督的机器学习,在该机器学习中,还提供了目标以及输入数据集。
分类问题的一个示例可以是电子邮件中的垃圾邮件检测,只能有两类输出:"垃圾邮件"和"非垃圾邮件";因此,这是一个二进制类型分类。
要实现此分类,无涯教程首先需要训练分类器,在此示例中,"垃圾邮件"和"非垃圾邮件"电子邮件将用作培训数据,成功训练分类器后,可以将其用于检测未知电子邮件。
对于分类问题,有两种类型的学习者-
懒惰学习
顾名思义,这类学习者在存储训练数据后等待测试数据出现,仅在获取测试数据后才进行分类。他们花在培训上的时间更少,但花在预测上的时间却更多。懒惰学习者的示例有K近邻和基于案例的推理。
渴望学习
与懒惰的学习者相反,热心的学习者在存储训练数据后无需等待测试数据出现就构造分类模型,他们花更多的时间在训练上,而花更少的时间在预测上。渴望学习的人的示例有决策树,朴素贝叶斯和人工神经网络(ANN)。
构建分类器
Scikit-learn是用于机器学习的Python库,可用于在Python中构建分类器。在Python中构建分类器的步骤如下-
第1步 - 导入包
为了使用scikit-learn构建分类器,无涯教程需要将其导入。可以使用以下脚本导入它-
import sklearn
第2步 - 导入数据集
导入必要的包后,需要一个数据集来创建分类预测模型,可以从sklearn数据集中导入它,也可以根据需要使用其他一个,将使用sklearn的乳腺癌威斯康星州诊断数据库。可以在以下脚本的帮助下导入它-
from sklearn.datasets import load_breast_cancer
以下脚本将加载数据集;
data=load_breast_cancer()
还需要组织数据,可以在以下脚本的帮助下完成数据-
label_names=data[target_names] labels=data[target] feature_names=data[feature_names] features=data[data]
对于数据库,以下命令将打印标签的名称"malignant(恶性)" 和"benign(良性)" 。
print(label_names)
上面命令的输出是标签的名称-
[malignant benign]
这些标签分别映射为二进制值0和1。恶性癌由0表示,良性癌由1表示。
这些标签的特征名称和特征值可以通过以下命令查看-
print(feature_names[0])
上面命令的输出是标签0的特征的名称,即恶性癌症-
mean radius
类似地,标签的特征名称可以如下产生:
print(feature_names[1])
上面命令的输出是标签1的特征的名称,即良性癌症-
mean texture
可以在以下命令的帮助下为这些标签打印函数-
print(features[0])
这将给出以下输出-
[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-011.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+026.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+011.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-014.601e-01 1.189e-01]
可以在以下命令的帮助下为这些标签打印函数-
print(features[1])
这将给出以下输出-
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02 7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01 5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01 2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01 2.750e-01 8.902e-02]
第3步 - 数据整理
由于需要在看不见的数据上测试模型,因此将数据集分为两部分:训练集和测试集,可以使用 sklearn python包的 train_test_split()函数将数据拆分为集合。以下命令将导入函数-
from sklearn.model_selection import train_test_split
现在,下一条命令会将数据分为训练和测试数据。在此示例中,无涯教程将40%的数据用于测试目的,将60%的数据用于培训目的-
train, test, train_labels, test_labels=train_test_split(features,labels,test_size=0.40, random_state=42)
第4步 - 模型判断
将数据划分为训练和测试后,程需要构建模型,为此,将使用朴素贝叶斯(Bayes)算法,以下命令将导入 GaussianNB 模块-
from sklearn.naive_bayes import GaussianNB
现在,按如下所示初始化模型-
gnb=GaussianNB()
接下来,在以下命令的帮助下,无涯教程可以训练模型-
model=gnb.fit(train, train_labels)
现在,出于判断目的,需要进行预测。可以通过如下方式使用predict()函数来完成:
preds=gnb.predict(test) print(preds)
这将给出以下输出-
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 01 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 01 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 01 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 01 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 00 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 10 0 1 1 0 1]
上面输出的0和1系列是恶性和良性肿瘤类别的预测值。
第5步 - 寻找准确性
通过比较两个数组 test_labels 和 preds ,无涯教程可以找到上一步中模型构建的准确性。将使用 accuracy_score()函数确定准确性。
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965
上面的输出显示NaïveBayes分类器的准确度为95.17%。
分类算法 - 入门教程 - 无涯教程网无涯教程网提供分类可以定义为根据观测值或给定数据点预测类别的过程。分类的输出可以采用"黑色"或"... https://www.learnfk.com/python-machine-learning/machine-learning-with-python-classification-algorithms-introduction.html
https://www.learnfk.com/python-machine-learning/machine-learning-with-python-classification-algorithms-introduction.html
相关文章:
无涯教程-分类算法 - 简介
分类可以定义为根据观测值或给定数据点预测类别的过程。分类的输出可以采用"黑色"或"白色"或"垃圾邮件"或"非垃圾邮件"的形式。 在数学上,分类是从输入变量(X)到输出变量(Y)近似映射函数(f)的任务,它属于有监督…...
python venv 打包,更换路径后,仍然读取到旧路径 ,最好别换路径,采用docker封装起来
机械盘路径 /home/yeqiang/code/xxx 移动到 /opt/xxx 编辑/opt/xxx/venv/bin/activate VIRTUAL_ENV"/home/yeqiang/code/xxx/venv" 改为 VIRTUAL_ENV"/opt/xxx/venv" 下面还有这么多,参考: (venv) yeqiangyeqiang-MS-7B23:/…...
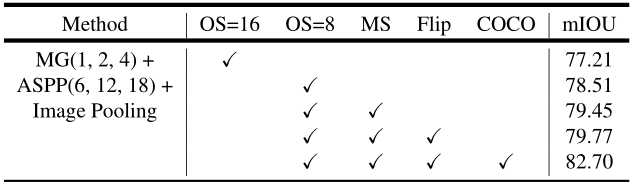
MATLAB算法实战应用案例精讲-【自然语言处理】语义分割模型-DeepLabV3
目录 1、DeepLab系列简介 1.1.DeepLabV1 1.1.1创新点: 1.1.2. 动机: 1.1.3. 应对策略: 1.2.DeepLabV2 1.2.1.创新点: 1.2.2.动机 1.2.3. 应对策略: 1.3.DeepLabV3 1.3.1创新点: 1.3.2. 动机&am…...

road to master
零、学习计划 数据库相关 索引 我以为我对数据库索引很了解,直到我遇到了阿里面试官 - 知乎 (zhihu.com)给我一分钟,让你彻底明白MySQL聚簇索引和非聚簇索引 - 知乎 (zhihu.com)聚集索引(聚类索引)与非聚集索引(非聚类…...
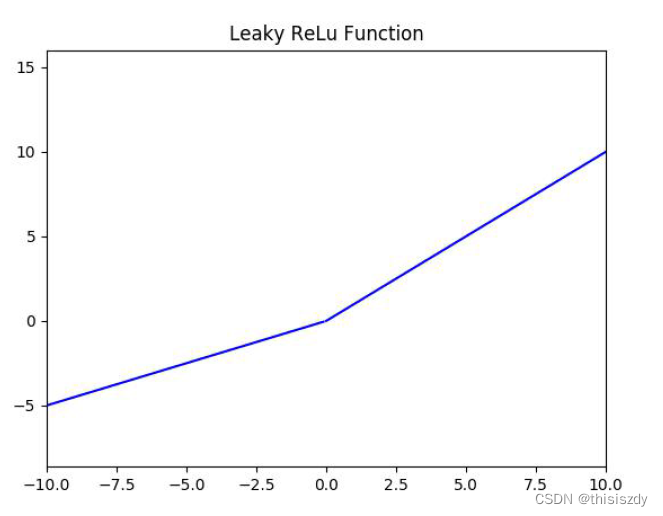
<深度学习基础> 激活函数
为什么需要激活函数?激活函数的作用? 激活函数可以引入非线性因素,可以学习到复杂的任务或函数。如果不使用激活函数,则输出信号仅是一个简单的线性函数。线性函数一个一级多项式,线性方程的复杂度有限,从…...

评价指标BLUE了解
BLEU (Bilingual Evaluation Understudy,双语评估基准)是一组度量机器翻译和自然语言生成模型性能的评估指标。BLEU指标是由IBM公司提出的一种模型评估方法,以便在机器翻译领域中开发更好的翻译模型。BLEU指标根据生成的句子与人工参考句子之间的词、短语…...

5G网关如何提升智慧乡村农业生产效率
得益于我国持续推进5G建设,截至今年5月,我国5G基站总数已达284.4万个,覆盖全国所有地级市、县城城区和9成以上的乡镇镇区,实现“镇镇通5G”,全面覆盖了从城市到农村的延伸。 依托5G网络的技术优势,智慧乡村…...
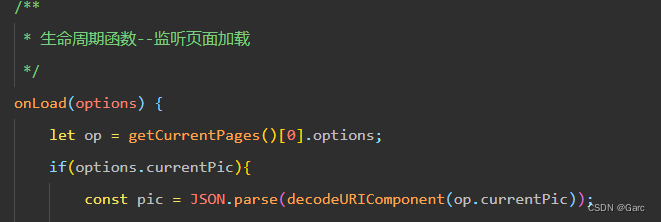
微信小程序分享后真机参数获取不到和部分参数不能获取问题问题解决
微信小程序的很多API,都是BUG,近期开发小程序就遇到了分享后开发工具可以获取参数,但是真机怎么都拿不到参数的问题 一、真机参数获取不到问题解决 解决方式: 在onLoad(options) 中。 onLoad方法中一定要有options 这个参数。…...
Confluence使用教程(用户篇)
1、如何创建空间 可以把空间理解成一个gitlab仓库,空间之间相互独立,一般建议按照部门(小组的人太少,没必要创建空间)或者按照项目分别创建空间 2、confluence可以创建两种类型的文档:页面和博文 从内容上来…...
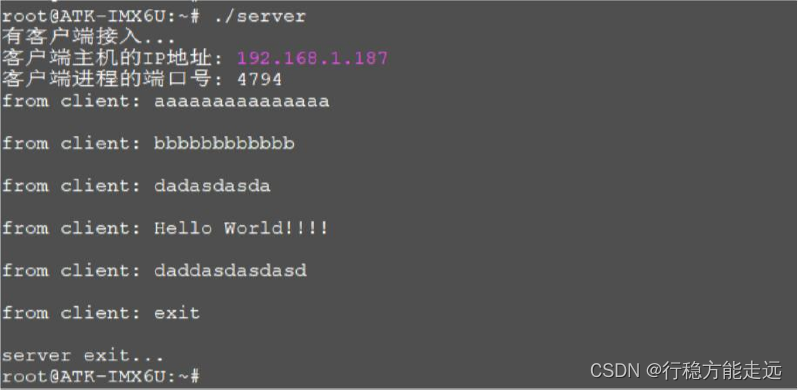
网络基础知识socket编程
目录 网络通信概述网络互连模型:OSI 七层模型TCP/IP 四层/五层模型数据的封装与拆封 IP 地址IP 地址的编址方式IP 地址的分类特殊的IP 地址如何判断2 个IP 地址是否在同一个网段内 TCP/IP 协议TCP 协议TCP 协议的特性TCP 报文格式建立TCP 连接:三次握手关…...
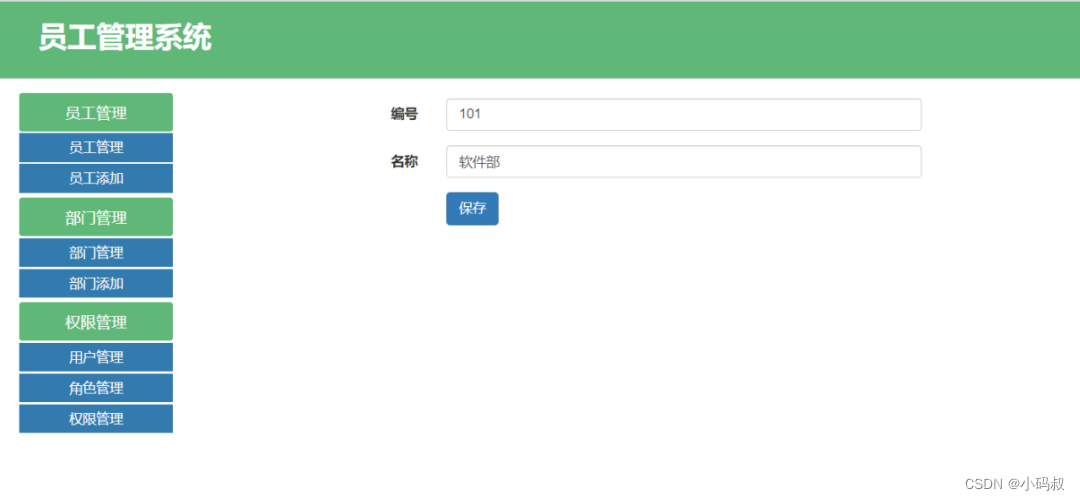
基于SpringBoot的员工(人事)管理系统
基于SpringBoot的员工(人事)管理系统 一、系统介绍二、功能展示三.其他系统实现五.获取源码 一、系统介绍 项目名称:基于SPringBoot的员工管理系统 项目架构:B/S架构 开发语言:Java语言 前端技术:BootS…...

【计算机网络】序列化与反序列化
文章目录 1. 如何处理结构化数据?序列化 与 反序列化 2. 实现网络版计算器1. Tcp 套接字的封装——sock.hpp创建套接字——Socket绑定——Bind将套接字设置为监听状态——Listen获取连接——Accept发起连接——Connect 2. 服务器的实现 ——TcpServer.hpp初始化启动…...
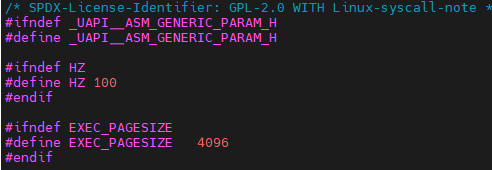
Linux内核学习(七)—— 定时器和时间管理(基于Linux 2.6内核)
目录 一、内核中的时间概念 二、节拍率:HZ 实时时钟 系统定时器 三、定时器 系统定时器是一种可编程硬件芯片,能以固定频率产生定时器中断,它所对应的中断处理程序负责更新系统时间,也负责执行需要周期性运行的任务。 一、内…...
常用命令总结)
Tortoise Git(乌龟git)常用命令总结
查看全局和本地 Git 配置 打开命令行终端(如 Git Bash),分别执行以下命令查看全局和本地的 Git 配置信息: git config --global -l git config --local -l确保配置中没有任何与 SSH 相关的设置 移除全局和本地 SSH 相关配置&…...

SSM商城项目实战:物流管理
SSM商城项目实战:物流管理 在SSM商城项目中,物流管理是一个重要的功能模块。通过物流管理,可以实现订单的配送、运输和签收等操作。本文将介绍如何在SSM商城项目中实现物流管理功能的思路和步骤代码。 实现SSM商城项目中物流管理的思路总结如…...
nlp系列(7)三元组识别(Bert+CRF)pytorch
模型介绍 在实体识别中:使用了Bert模型,CRF模型 在关系识别中:使用了Bert模型的输出与实体掩码,进行一系列变化,得到关系 Bert模型介绍可以查看这篇文章:nlp系列(2)文本分类&…...

Druid配置类、Dubbo配置类、Captcha配置类、Redis配置类、RestTemplate配置类
DruidConfig配置类package com.xdclass.app.config;import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.beans.factory.annotation.V…...
:使用pyecharts创建带有数据缩放滑块和位置指示器的K线图)
Pyecharts教程(十二):使用pyecharts创建带有数据缩放滑块和位置指示器的K线图
Pyecharts教程(十二):使用pyecharts创建带有数据缩放滑块和位置指示器的K线图 作者:安静到无声 个人主页 目录 Pyecharts教程(十二):使用pyecharts创建带有数据缩放滑块和位置指示器的K线图前言代码讲解总结完整代码推荐专栏前言 本博客将详细解释如何使用Python中的pyech…...

MySQL 基本操作
目录 数据库的列类型 数据库基本操作 SQL语言规范 SQL语句分类 查看表,使用表 管理数据库 创建数据库和表 删除数据库和表 向数据表中添加数据 查询数据表中数据 修改数据表的数据 删除数据表中数据 修改表明和表结构 扩展表结构(增加字段&…...
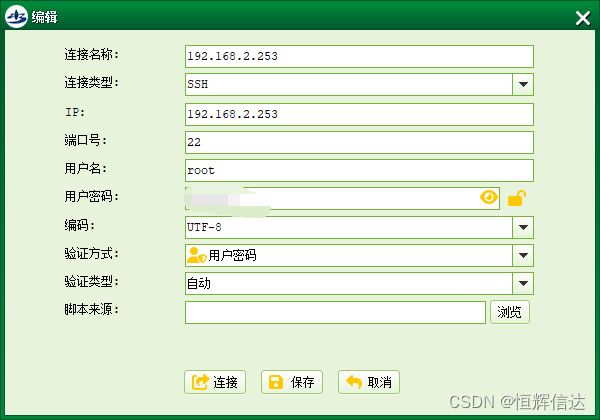
HHDESK一键改密功能
HHDESK新增实用功能——使用SSH连接,对服务器/端口进行密码修改。 1 测试 首页点击资源管理——客户端,选择需要修改的连接; 可以先对服务器及端口进行测试,看是否畅通; 右键——测试——ping; 以及右…...

Huxley框架PDF生成利器:基于HTML模板的优雅解决方案
1. 项目概述:一个为Huxley框架量身定制的PDF生成利器如果你正在使用Huxley框架开发应用,并且遇到了需要生成PDF报告、发票、合同或者任何形式文档的需求,那么你很可能已经体会过那种“万事俱备,只欠PDF”的纠结。市面上的PDF生成库…...

轻量级网页自动化工具 xiaoclaw:基于 CDP 的高效实践指南
1. 项目概述:一个轻量级、可编程的网页自动化工具最近在折腾一些需要自动处理网页数据的小项目,比如定时抓取某个网站的价格变动、自动填写表单、或者模拟一些重复性的点击操作。一开始想用传统的Selenium,但总觉得它有点“重”,启…...

黑金AX301开发板+HS-04模块:FPGA超声波测距从原理到数码管显示的保姆级教程
黑金AX301开发板实战:基于HS-04模块的FPGA超声波测距系统设计 当超声波传感器遇到FPGA,我们能创造出怎样的精准测距系统?本文将带你从硬件连接到Verilog编码,完整实现一个基于黑金AX301开发板和HS-04超声波模块的测距系统。不同于…...

bsnes性能优化技巧:CPU、SA1和SuperFX超频配置完全手册
bsnes性能优化技巧:CPU、SA1和SuperFX超频配置完全手册 【免费下载链接】bsnes bsnes is a Super Nintendo (SNES) emulator focused on performance, features, and ease of use. 项目地址: https://gitcode.com/gh_mirrors/bs/bsnes bsnes是一款专注于性能…...

从提示词到技能笔记:构建可复用AI工作流的核心方法
1. 项目概述:从“提示词”到“技能笔记”的认知跃迁最近在折腾AI应用开发的朋友,估计没少被“提示词工程”这个词刷屏。从最初的简单指令,到如今动辄上千字的复杂结构化提示,我们与AI的交互方式正在经历一场深刻的变革。但不知道你…...

5G时代LTE-A为何依然能打:从技术原理到实战场景的深度解析
1. 项目概述:一场意料之外的“降维打击”最近和几个做无线通信的朋友聊天,聊到一个挺有意思的现象:在很多公开的测试和实际部署场景里,当5G和LTE-A(LTE-Advanced,通常指4G)被放在同一个竞技场里…...

ubuntu25 安装ORG flow
下载ORG flow https://github.com/infiniflow/ragflow 上传至home文件夹下 进入文件夹/ragflow-main/docker下 安装docker: sudo snap install docker 安装gnome-terminal sudo apt install gnome-terminal sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL …...
_PVC 底层原理 + 动态供应踩坑 + 数据备份恢复实战)
容器存储进阶:PersistentVolume(PV)_PVC 底层原理 + 动态供应踩坑 + 数据备份恢复实战
容器存储进阶:PersistentVolume(PV)/PVC 底层原理 + 动态供应踩坑 + 数据备份恢复实战 前言:在Kubernetes容器集群中,PersistentVolume(PV)与PersistentVolumeClaim(PVC)是实现容器持久化存储的核心组件,但生产环境中,多数运维人员往往卡在基础配置层面,而忽略了动…...

Photoshop AVIF插件:专业图像工作者的下一代格式解决方案
Photoshop AVIF插件:专业图像工作者的下一代格式解决方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 在当今数字图像处理领域,AVIF格…...
)
综合实战——开发一个“智能标书辅助生成系统“(01需求分析与架构设计)
综合实战——开发一个“智能标书辅助生成系统“ 前言:为什么选择"标书生成"作为实战项目? 在正式开始之前,先回答一个关键问题:为什么选这个场景? 标书(Bid/Proposal)生成是企业中一个真实且高价值的AI应用场景: 痛点明确:写一份标书需要3-5天,且大量内容…...