<C++> STL_容器适配器
1.容器适配器
适配器是一种设计模式,该种模式是将一个类的接口转换成客户希望的另外一个接口。
容器适配器是STL中的一种重要组件,用于提供不同的数据结构接口,以满足特定的需求和限制。容器适配器是基于其他STL容器构建的,通过改变其接口和行为,使其适应不同的应用场景。
STL中有三种常见的容器适配器:stack、queue和priority_queue。
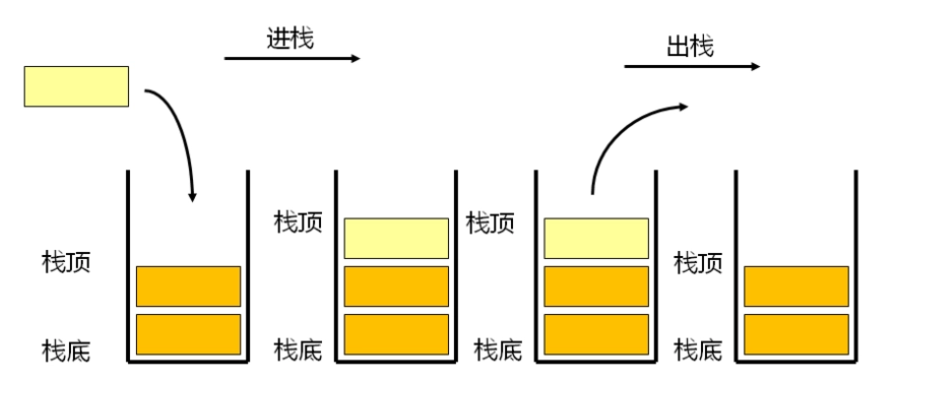
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque,比如:


而priority_queue默认使用vector

2.stack的介绍和使用
stack的介绍
-
stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
-
stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
-
stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
-
empty:判空操作
-
back:获取尾部元素操作
-
push_back:尾部插入元素操作
-
pop_back:尾部删除元素操作
-
-
标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器, 默认情况下使用deque。
stack的使用
当你使用 std::stack 时,你可以使用以下一些重要的成员函数:
push(const T& value): 将元素value压入栈顶。pop(): 弹出栈顶元素,不返回其值。top(): 返回栈顶元素的引用,但不将其从栈中移除。size(): 返回栈中元素的数量。empty(): 检查栈是否为空,返回布尔值。swap(stack& other): 将当前栈与另一个栈other进行交换。
#include <iostream>
#include <stack>int main() {std::stack<int> myStack;// 将元素压入栈顶myStack.push(10);myStack.push(20);myStack.push(30);std::cout << "栈顶元素: " << myStack.top() << std::endl; // 输出:30std::cout << "栈的大小: " << myStack.size() << std::endl; // 输出:3myStack.pop(); // 弹出栈顶元素if (!myStack.empty()) {std::cout << "弹出元素后的栈顶元素: " << myStack.top() << std::endl; // 输出:20}std::stack<int> anotherStack;anotherStack.push(50);myStack.swap(anotherStack); // 交换两个栈的内容std::cout << "交换后 myStack 的大小: " << myStack.size() << std::endl; // 输出:1return 0;
}
stack的模拟实现
#pragma once
#include <deque>namespace phw {template<class T, class Container = std::deque<T>>class stack {public:void push(const T &x) {_con.push_back(x);}void pop() {_con.pop_back();}T &top() {return _con.back();}const T &top() const {return _con.back();}size_t size() const {return _con.size();}bool empty() const {return _con.empty();}void swap(stack<T, Container> &st) {_con.swap(st._con);}private:Container _con;};
}// namespace phw
3.queue的介绍和使用
queue的介绍
-
队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端 提取元素。
-
队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的 成员函数来访问其元素。元素从队尾入队列,从队头出队列。
-
底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
-
empty:检测队列是否为空
-
size:返回队列中有效元素的个数
-
front:返回队头元素的引用
-
back:返回队尾元素的引用
-
push_back:在队列尾部入队列
-
pop_front:在队列头部出队列
-
-
标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标 准容器deque。
queue的使用
push(const T& value): 将元素value添加到队列的尾部。pop(): 弹出队列的头部元素,不返回其值。front(): 返回队列头部元素的引用。back(): 返回队列尾部元素的引用。size(): 返回队列中元素的数量。empty(): 检查队列是否为空。swap(queue& other): 交换两个队列的内容。
示例:
#include <iostream>
#include <queue>int main() {std::queue<int> myQueue;// 向队列尾部添加元素myQueue.push(10);myQueue.push(20);myQueue.push(30);std::cout << "队列头部元素: " << myQueue.front() << std::endl; // 输出:10std::cout << "队列尾部元素: " << myQueue.back() << std::endl; // 输出:30std::cout << "队列大小: " << myQueue.size() << std::endl; // 输出:3myQueue.pop(); // 弹出队列头部元素std::cout << "弹出元素后的队列头部元素: " << myQueue.front() << std::endl; // 输出:20std::queue<int> anotherQueue;anotherQueue.push(50);myQueue.swap(anotherQueue); // 交换两个队列的内容std::cout << "交换后 myQueue 的大小: " << myQueue.size() << std::endl; // 输出:1return 0;
}
queue的模拟实现
#pragma once
#include <deque>namespace phw//防止命名冲突
{template<class T, class Container = std::deque<T>>class queue {public://队尾入队列void push(const T &x) {_con.push_back(x);}//队头出队列void pop() {_con.pop_front();}//获取队头元素T &front() {return _con.front();}const T &front() const {return _con.front();}//获取队尾元素T &back() {return _con.back();}const T &back() const {return _con.back();}//获取队列中有效元素个数size_t size() const {return _con.size();}//判断队列是否为空bool empty() const {return _con.empty();}//交换两个队列中的数据void swap(queue<T, Container> &q) {_con.swap(q._con);}private:Container _con;};
}// namespace phw
4.priority_queue的介绍和使用
priority_queue的介绍
std::priority_queue 用于实现优先队列数据结构。优先队列是一种特殊的队列,其中的元素按照一定的优先级顺序进行排列,而不是按照插入的顺序。
std::priority_queue 使用堆(heap)数据结构来维护元素的顺序,通常用于需要按照一定规则获取最高优先级元素的场景。在默认情况下,std::priority_queue 会以降序排列元素,即最大的元素会被放置在队列的前面。你也可以通过提供自定义的比较函数来改变排序顺序。
priority_queue的使用
构造函数
默认构造函数: 创建一个空的优先队列。
std::priority_queue<T> pq; // 创建一个空的优先队列,T 是元素类型
带有比较函数的构造函数: 可以指定一个自定义的比较函数,用于确定元素的优先级顺序。
std::priority_queue<T, Container, Compare> pq;
T是元素类型。Container是底层容器类型,默认情况下使用std::vector。Compare是比较函数类型,用于确定元素的顺序。默认情况下,使用operator<来比较元素。
示例:
#include <iostream>
#include <queue>int main() {// 构造一个默认的优先队列,元素类型为 int,使用默认比较函数 operator<std::priority_queue<int> pq1;// 构造一个优先队列,元素类型为 int,使用自定义的比较函数 greater,实现最小堆std::priority_queue<int, std::vector<int>, std::greater<int>> pq2;// 构造一个优先队列,元素类型为 std::string,使用默认比较函数 operator<std::priority_queue<std::string> pq3;// 构造一个优先队列,元素类型为 double,使用 lambda 表达式作为比较函数,实现最大堆auto cmp = [](double a, double b) { return a < b; };std::priority_queue<double, std::vector<double>, decltype(cmp)> pq4(cmp);return 0;
}
成员函数
-
push(): 向优先队列中插入元素。
pq.push(value); // 插入元素 value -
pop(): 移除队列顶部的元素(即最高优先级元素)。
pq.pop(); // 移除队列顶部元素 -
top(): 获取队列顶部的元素(即最高优先级元素)。
T highestPriority = pq.top(); // 获取最高优先级元素 -
empty(): 检查队列是否为空。
bool isEmpty = pq.empty(); // 如果队列为空则返回 true,否则返回 false -
size(): 获取队列中的元素数量。
int numElements = pq.size(); // 获取队列中的元素数量
示例:
#include <iostream>
#include <functional>
#include <queue>
using namespace std;
int main(){priority_queue<int> q;q.push(3);q.push(6);q.push(0);q.push(2);q.push(9);q.push(8);q.push(1);while (!q.empty()){cout << q.top() << " ";q.pop();}cout << endl; //9 8 6 3 2 1 0return 0;
}
自定义比较函数
你可以通过提供自定义的比较函数来改变元素的排序顺序。比较函数应该返回 true,如果第一个参数应该排在第二个参数之前。
struct MyComparator {bool operator()(const T& a, const T& b) {// 自定义比较逻辑}
};std::priority_queue<T, Container, MyComparator> pq;
priority_queue的模拟实现
priority_queue的底层实际上就是堆结构,实现priority_queue之前,我们先认识两个重要的堆算法。(下面这两种算法我们均以大堆为例)
堆的向上调整算法
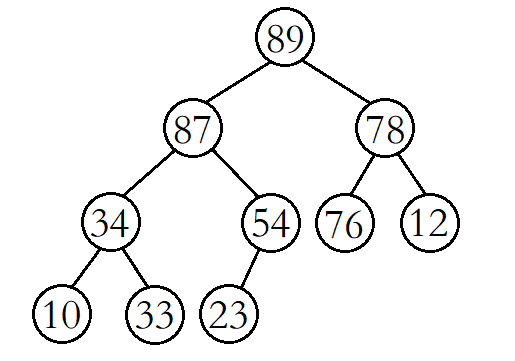
以大堆为例,堆的向上调整算法就是在大堆的末尾插入一个数据后,经过一系列的调整,使其仍然是一个大堆。
调整的基本思想如下:
1、将目标结点与其父结点进行比较。
2、若目标结点的值比父结点的值大,则交换目标结点与其父结点的位置,并将原目标结点的父结点当作新的目标结点继续进行向上调整;若目标结点的值比其父结点的值小,则停止向上调整,此时该树已经是大堆了。
例如,现在我们在该大堆的末尾插入数据88。
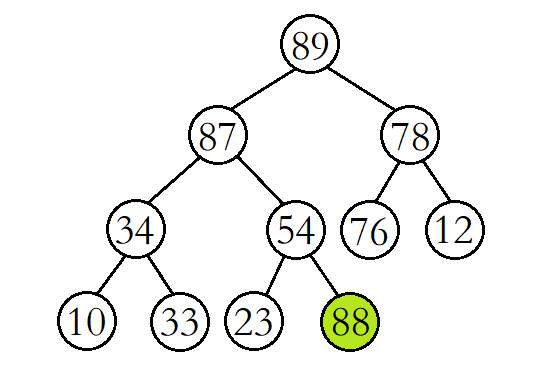
我们先将88与其父结点54进行比较,发现88比其父结点大,则交换父子结点的数据,并继续进行向上调整。
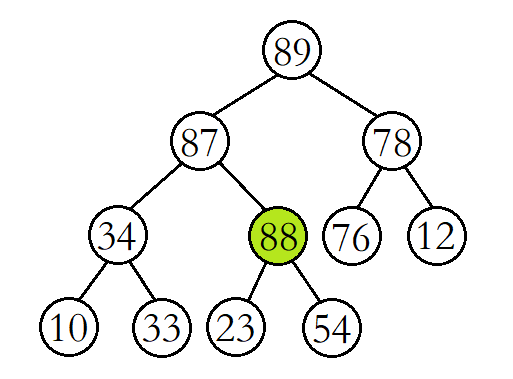
此时将88与其父结点87进行比较,发现88还是比其父结点大,则继续交换父子结点的数据,并继续进行向上调整。
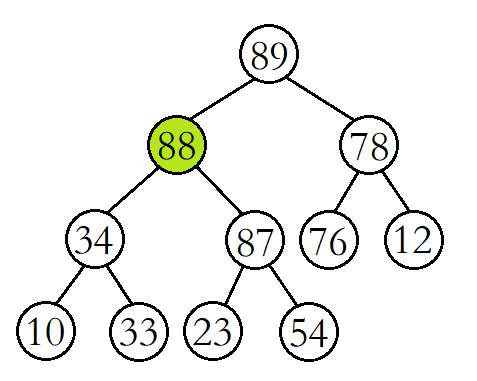
这时再将88与其父结点89进行比较,发现88比其父结点小,则停止向上调整,此时该树已经就是大堆了。
堆的向上调整算法代码:
void AdjustUp(int child) {int parent = (child - 1) / 2;while (child > 0) {// 默认less ,也就是parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向上进行调整child = parent;parent = (child - 1) / 2;} else// 已成堆{break;}}
}
堆的向下调整算法
以大堆为例,使用堆的向下调整算法有一个前提,就是待向下调整的结点的左子树和右子树必须都为大堆。
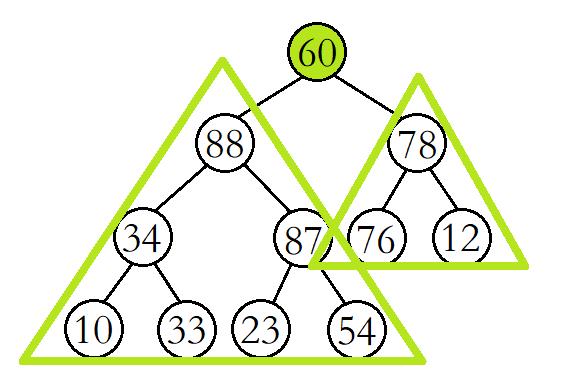
调整的基本思想如下:
1、将目标结点与其较大的子结点进行比较。
2、若目标结点的值比其较大的子结点的值小,则交换目标结点与其较大的子结点的位置,并将原目标结点的较大子结点当作新的目标结点继续进行向下调整;若目标结点的值比其较大子结点的值大,则停止向下调整,此时该树已经是大堆了。
例如,将该二叉树从根结点开始进行向下调整。(此时根结点的左右子树已经是大堆)
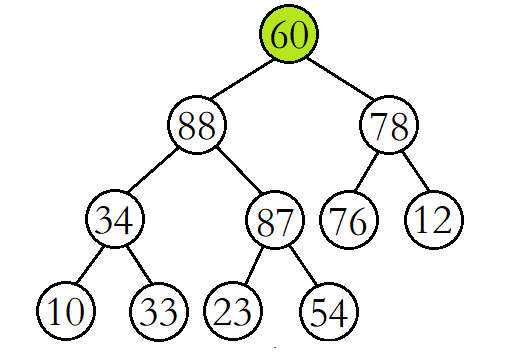
将60与其较大的子结点88进行比较,发现60比其较大的子结点小,则交换这两个结点的数据,并继续进行向下调整。
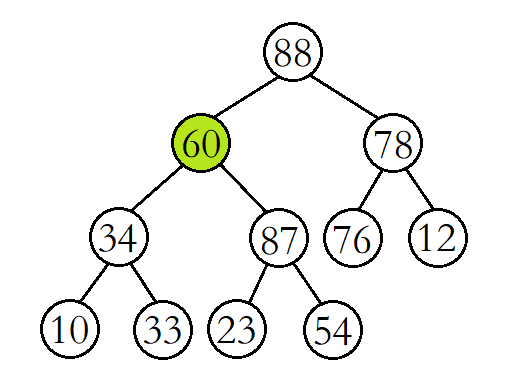
此时再将60与其较大的子结点87进行比较,发现60比其较大的子结点小,则再交换这两个结点的数据,并继续进行向下调整。
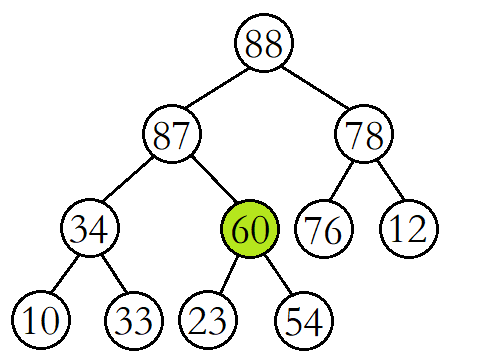
这时再将60与其较大的子结点54进行比较,发现60比其较大的子结点大,则停止向下调整,此时该树已经就是大堆了。

堆的向下调整算法代码:
void AdjustDown(int n, int parent) {int child = 2 * parent + 1;while (child < n) {//_comp(_con[child], _con[child + 1])表示child<child+1if (child + 1 < n && _comp(_con[child], _con[child + 1])) {child++;}// parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向下进行调整parent = child;child = 2 * parent + 1;} else// 已成堆{break;}}
}
模拟实现代码:
// 优先级队列使用vector作为其底层存储数据的容器,priority_queue就是堆
// 默认情况是大堆#include <iostream>
#include <vector>
using namespace std;
namespace phw {// 仿函数less(使内部结构为大堆)template<class T>struct less {bool operator()(const T &x, const T &y) {return x < y;}};// 仿函数greater(使内部结构为小堆)template<class T>struct greater {bool operator()(const T &x, const T &y) {return x > y;}};// 优先级队列template<class T, class Container = vector<T>, class Compare = greater<T>>class priority_queue {public:// 堆的向上调整void AdjustUp(int child) {int parent = (child - 1) / 2;while (child > 0) {// 默认less ,也就是parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向上进行调整child = parent;parent = (child - 1) / 2;} else// 已成堆{break;}}}// 堆的向下调整void AdjustDown(int n, int parent) {int child = 2 * parent + 1;while (child < n) {//_comp(_con[child], _con[child + 1])表示child<child+1if (child + 1 < n && _comp(_con[child], _con[child + 1])) {child++;}// parent<childif (_comp(_con[parent], _con[child]))// 通过所给比较方式确定是否需要交换结点位置{// 将父结点与孩子结点交换swap(_con[child], _con[parent]);// 继续向下进行调整parent = child;child = 2 * parent + 1;} else// 已成堆{break;}}}// 插入元素到队尾(并排序)void push(const T &x) {_con.push_back(x);AdjustUp(_con.size() - 1);// 将最后一个元素进行一次向上调整}// 弹出队头元素(堆顶元素)void pop() {swap(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(_con.size(), 0);// 将第0个元素进行一次向下调整}// 访问队头元素(堆顶元素)T &top() {return _con[0];}const T &top() const {return _con[0];}// 获取队列中有效元素个数size_t size() const {return _con.size();}// 判断队列是否为空bool empty() const {return _con.empty();}private:Container _con;// vector容器Compare _comp; // 比较方式};
}// namespace phw
(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(_con.size(), 0);// 将第0个元素进行一次向下调整}// 访问队头元素(堆顶元素)T &top() {return _con[0];}const T &top() const {return _con[0];}// 获取队列中有效元素个数size_t size() const {return _con.size();}// 判断队列是否为空bool empty() const {return _con.empty();}private:Container _con;// vector容器Compare _comp; // 比较方式};
}// namespace phw
相关文章:
<C++> STL_容器适配器
1.容器适配器 适配器是一种设计模式,该种模式是将一个类的接口转换成客户希望的另外一个接口。 容器适配器是STL中的一种重要组件,用于提供不同的数据结构接口,以满足特定的需求和限制。容器适配器是基于其他STL容器构建的,通过…...

【25考研】- 整体规划及高数一起步
【25考研】- 整体规划及高数一起步 一、整体规划二、专业课870计算机应用基础参考网上考研学长学姐: 三、高数一典型题目、易错点及常用结论(一)典型题目(二)易错点(三)常用结论1.令tarctanx, 则…...

【Unity】常见的角色移动旋转
在Unity 3D游戏引擎中,可以使用不同的方式对物体进行旋转。以下是几种常见的旋转方式: 欧拉角(Euler Angles):欧拉角是一种常用的旋转表示方法,通过绕物体的 X、Y 和 Z 轴的旋转角度来描述物体的旋转。在Un…...

今天的小结
1、冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历待排序的元素列表,比较相邻的元素并交换它们的位置,直到整个列表排序完成。冒泡排序的基本思想是通过不断交换相邻元素,将最大&#…...

了解 Socks 协议:它的过去、现在与未来
在网络世界的江湖中,有一名叫做 Socks 协议的高手,它凭借着一招“代理”绝技,在网络安全领域独步天下。今天,就让我们来了解一下这位神秘高手的过去、现在和未来。 在过去,互联网世界的江湖可谓是风起云涌,…...

小谈静态类和单例模式
静态类(Static Class)和单例(Singleton)都是在编程中用于实现特定类型的设计模式或代码组织方式。它们在不同的情境下有不同的用途和特点。 静态类(Static Class) 静态类是一种类,它的方法和属…...

LeetCode解法汇总823. 带因子的二叉树
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给出一个含…...

TypeScript的变量声明的各种方式
TypeScript是一种静态类型的JavaScript超集,它为JavaScript代码提供了类型检查和更好的代码组织结构。在TypeScript中,变量声明是非常重要的,因为它们定义了变量的类型和范围。本文将详细介绍TypeScript的变量声明,并通过代码案例…...

c++ lambda
Lambda Lambda 表达式一般用于定义匿名函数,使得代码更加灵活简洁,优点: 声明式编程风格:就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或者函数对象。以更直接的方式去写程序,好的可读性和可…...

泊松回归和地理加权泊松回归
01 泊松回归 泊松回归(Poisson Regression)是一种广义线性模型,用于建立离散型响应变量(计数数据)与一个或多个预测变量之间的关系。它以法国数学家西蒙丹尼泊松(Simon Denis Poisson)的名字命名,适用于计算“事件发生次数”的概率,比如交通事故发生次数、产品缺陷数…...
【数学建模竞赛】各类题型及解题方案
评价类赛题建模流程及总结 建模步骤 建立评价指标->评价体系->同向化处理(都越多越好或越少越少)->指标无量纲处理 ->权重-> 主客观->合成 主客观评价问题的区别 主客观概念主要是在指标定权时来划分的。主观评价与客观评价的区别…...

【12期】谈一谈redis两种持久化机制的区别?
Redis两类持续性的方法 RDB方案可以在规定时间间隔内创建数据集的时间点快照。 AOF方案记录了服务器执行的所有写操作命令,并在服务器启动时通过重新执行这些命令来还原数据集。AOF文件完全遵循Redis协议格式保存,新命令会被追加到文件末尾。此外&#…...
一)
Lambda 编程(Kotlin)一
学习记录,以下为个人理解 知识点: Lambda的定义:允许你把代码块当作参数传递给函数Lambda的语法约定:如果lambda 表达式是函数调用的最后一个实参,它可以放到括号的外边当lambda表达式时函数唯一的实参时,…...
网络字节序——TCP接口及其实现简单TCP服务器
网络字节序——TCP接口及其实现简单TCP服务器 文章目录 网络字节序——TCP接口及其实现简单TCP服务器简单TCP服务器的实现1. 单进程版:客户端串行版2. 多进程版:客户端并行版netstat查看网络信息3.多线程版:并行执行log.hpp 守护进程fg、bg s…...

RxJS如何根据事件创建Observable对象?
RxJS提供了一些用来创建Observable对象的函数,我们可以根据事件、定时器、Promise,AJAX等来创建Observable对象。 下面是根据事件创建Observable对象的几个例子。 this.outsideClick$ fromEvent(document, click).subscribe((event: MouseEvent) > …...

网站常见安全漏洞 | 青训营
Powered by:NEFU AB-IN 文章目录 网站常见安全漏洞 | 青训营 网站基本组成及漏洞定义服务端漏洞SQL注入命令执行越权漏洞SSRF文件上传漏洞 客户端漏洞开放重定向XSSCSRF点击劫持CORS跨域配置错误WebSocket 网站常见安全漏洞 | 青训营 网站常见安全漏洞-网站基本组成及漏洞定义…...
vue2使用 vis-network 和 vue-vis-network 插件封装一个公用的关联关系图
效果图: vis组件库:vis.js vis-network中文文档:vis-network 安装组件库: npm install vis-network vue-vis-network 或 yarn add vis-network vue-vis-network 新建RelationGraph.vue文件: <template><…...

给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。
LeetCode第73题矩阵置零 1.思路: 想到一个开辟一点空间来解决方法,使用哈希集。就是使用一个哈希集(row和col)来储存数组中的元素为0的下标。然后再遍历,整个二维数组,在哈希集中存在对应的下标,…...
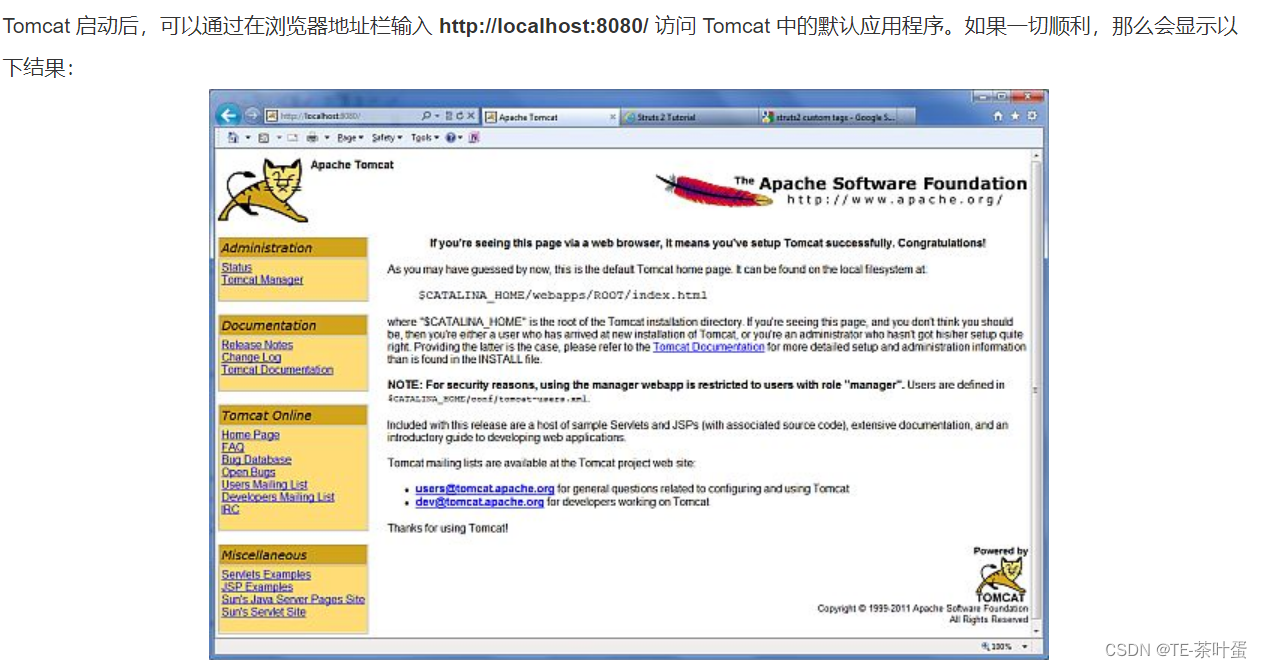
java-初识Servlet,Tomcat,JDBC
文章目录 前言一、ServletServlet 生命周期Servlet 实例Servlet 过滤器 二、TomcatJDBCJDBC连接数据库实例 总结 前言 java入门须知的重要概念/名词/技术 等 一、Servlet Servlet是Java Web开发中的一个核心组件,它是基于Java语言编写的服务器端程序,…...
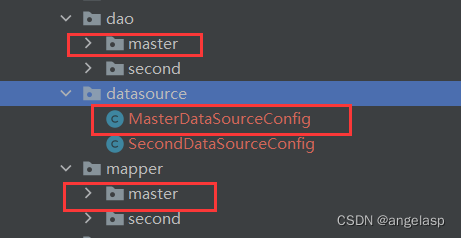
SpringBoot+mybatis+pgsql多个数据源配置
一、配置文件 jdk环境:1.8 配置了双数据源springbootdruidpgsql,application.properties配置修改如下: #当前入库主数据库 spring.primary.datasource.typecom.alibaba.druid.pool.DruidDataSource spring.primary.datasource.driver-class…...

ceph的块存储如何骗过服务器,让服务器把它当做真实的硬盘
ceph的块存储,就是一块远程网络硬盘。操作系统为啥会读写这块假硬盘呢? 一台服务器要使用CEPH提供的块存储,也是需要ceph的驱动软件来和ceph通讯吧 是的,你的理解完全正确。一台服务器想要使用 Ceph 提供的块存储,必须…...

ARMv8 AArch32虚拟内存系统与异常处理机制详解
1. AArch32虚拟内存系统架构概述AArch32是ARMv8架构中的32位执行状态,其虚拟内存系统架构(VMSAv8-32)是现代嵌入式系统和虚拟化平台的核心组件。这套系统通过精巧的硬件设计实现了内存隔离、访问控制和地址转换等关键功能。VMSAv8-32最显著的特点是采用了两阶段地址…...

vue3+python基于Django框架的铁路博物馆展览系统的设计与实现67350649
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术栈核心功能模块关键技术实现部署方案项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目背景 …...

如何用智能弹幕助手告别直播中的重复劳动?B站直播效率提升300%的秘密
如何用智能弹幕助手告别直播中的重复劳动?B站直播效率提升300%的秘密 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 还在为直播时手忙脚乱而烦…...

原来赛事专用匹克球工厂还有这么多门道?你了解吗?
引言在匹克球运动蓬勃发展的当下,赛事专用匹克球的品质至关重要。而赛事专用匹克球工厂背后,其实隐藏着诸多门道。泉州凯瑞麟体育用品有限公司作为行业内的佼佼者,在这方面有着独特的技术与经验。核心材料与技术创新赛事专用匹克球对核心材料…...

2026免费照片去水印软件app排行榜 | 照片去水印怎么去?最新推荐工具对比
照片水印去除需求在2026年越来越普遍,无论是整理个人相册还是做内容素材处理,找到一款趁手的去水印工具能节省大量时间。本文对标当前免费照片去水印软件app的主流选择进行了全面测评,并整理了一份排行榜式的推荐清单,帮你快速定位…...

物理标签退场,视觉原生上位:UWB vs 镜像视界无感定位・空间智能重构
物理标签退场,视觉原生上位:UWB vs 镜像视界无感定位・空间智能重构在空间智能加速重构物理世界的当下,全域感知技术正经历一场从“物理标签”到“视觉原生”的底层范式革命。长期以来,以UWB(超宽带)为代表…...

摆脱论文困扰!!2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

使用电脑快速测试 PROFINET 设备通讯
Anybus PROFINET主站仿真工具介绍日常对客户进行技术支持的时候,我们发现工厂自动化领域的不同部门不同职能的人员对于工业通讯设备都面临着一些使用的困难,例如设备研发人员,尤其是嵌入式研发部门,对于工厂自动化使用的工业通讯协…...

LicenseFinder高级配置指南:自定义许可证规则与决策继承
LicenseFinder高级配置指南:自定义许可证规则与决策继承 【免费下载链接】LicenseFinder Find licenses for your projects dependencies. 项目地址: https://gitcode.com/gh_mirrors/li/LicenseFinder LicenseFinder是一款强大的开源许可证管理工具…...