python scrapy框架
scrapy概述
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
scrapy安装
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
最开始安装了低版本 报错builtins.AttributeError: module 'OpenSSL.SSL' has no attribute 'SSLv3_METHOD' 升级到最新版本2.10.0 没有问题
scrapy使用
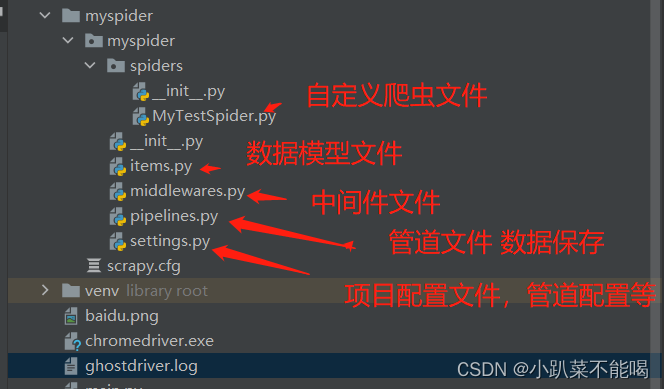
scrapy创建项目及结构
创建项目
scrapy startproject 项目名称
scrapy自定义爬虫类
创建爬虫文件
scrapy genspider 爬虫文件名称 网页地址
scrapy genspider MyTestSpider www.baidu.com
一般情况下不需要添加http协议, 因为start urls的值是根据allowed domains修改的 ,所以添加了http的话,那么start urls就需要我们手动去修改
import scrapyclass MytestSpider(scrapy.Spider):# 爬虫的名字 用于运行爬虫的时候 使用的值name = 'MyTestSpider'# 允许访问的域名allowed_domains = ['www.baidu.com']# 起始的ur]地址 指的是第一次要访问的域名start_urls = ['http://www.baidu.com/']def parse(self, response):pass
scrapy response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接是xpath方法来解析response中的内容
response.extract 提取seletor对象的data属性值
response.extract_first 提取seletor列表的第一个值
scrapy启动爬虫程序
scrapy crawl 爬虫名称
scrapy crawl MyTestSpider

scrapy原理
1、引擎向spiders要url
2、引擎学将要爬取的url给调度器
3、调度器会将url生成请求对象放到指定的队列中,从队列中发起一个请求
4、引擎将请求交给下载器进行处理
5、下载器发送请求获取互联网数据
6、将数据返回给下载器
7、下载器将数据返回给引擎
8、引擎将数据给spiders
9、spiders解析数据,交给引擎,如果发起第二次请求,会再次交给调度器
10、引擎将数据交给管道
 scrapy爬虫案例
scrapy爬虫案例
创建项目
scrapy startproject movie
创建spider
scrapy genspider mv https://www.dytt8.net/html/gndy/china/index.html
import scrapyclass MvSpider(scrapy.Spider):name = "mv"allowed_domains = ["www.dytt8.net"]start_urls = ["https://www.dytt8.net/html/gndy/china/index.html"]def parse(self, response):pass
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass MovieItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()name = scrapy.Field()src = scrapy.Field()
编写管道
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass MoviePipeline:# 执行之前执行def open_spider(self, spider):self.fp = open('movie.json','w',encoding='utf-8')def process_item(self, item, spider):self.fp.write(str(item))return item# 执行之后执行def close_spider(self,spider):self.fp.close()settings.py开启管道
BOT_NAME = "movie"SPIDER_MODULES = ["movie.spiders"]
NEWSPIDER_MODULE = "movie.spiders"ROBOTSTXT_OBEY = TrueITEM_PIPELINES = {"movie.pipelines.MoviePipeline": 300,
}REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
编写爬虫程序
import scrapy
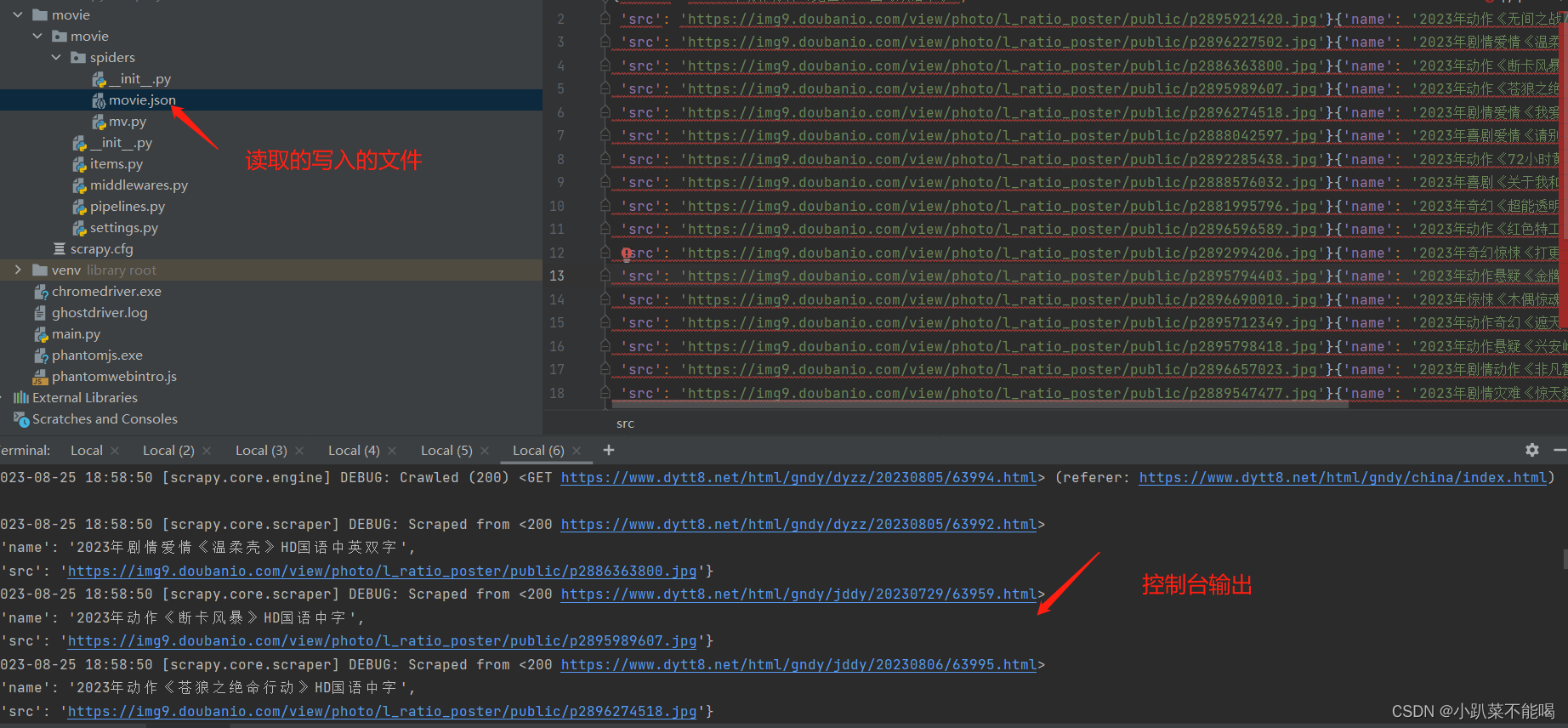
from movie.items import MovieItemclass MvSpider(scrapy.Spider):name = "mv"allowed_domains = ["www.dytt8.net"]start_urls = ["https://www.dytt8.net/html/gndy/china/index.html"]def parse(self, response):a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')for a in a_list:name = a.xpath('./text()').extract_first()href = a.xpath('./@href').extract_first()#第二页的地址是url = 'https://www.dytt8.net' + href# 对第二页的链接发起访问yield scrapy.Request(url=url, callback=self.parse_second,meta={'name':name})def parse_second(self,response):src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()# 接受到请求的那个meta参数的值name = response.meta['name']movie = MovieItem(src=src, name=name)# 返回给管道yield movie运行并查看结果
进入spider目录下,执行 scrapy crawl mv
相关文章:
python scrapy框架
scrapy概述 Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试 scrapy安装 pip install scrapy -i https://pypi.tuna.tsinghua…...

滑动窗口系列3-Leetcode134题加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。 给定两个整数数组 gas 和 cost &…...
LOIC(low orbit ion cannon)
前言 重要的话说三遍: 该程序仅用于学习用途,请勿用于非法行为上!!! 该程序仅用于学习用途,请勿用于非法行为上!!! 该程序仅用于学习用途,请勿用于非法行为上…...

从格灵深瞳中报稳定盈利,看AI公司的核心竞争力
2023年过半,人工智能产业话题不断。大模型和AIGC掀起热潮,让众多AI公司开始进入新一轮竞赛。但与此同时,不少AI公司依然处于亏损中,研发投入和商业产出难以实现正循环。如何形成健康的商业模式,仍是一大挑战。 AI公司…...

理解 Databend Cluster key 原理及使用
Databend Cluster Key 是指 Databend 可以按声明的 key 排序存储,主要用于用户对时间响应比较高,同时愿意为这个 cluster key 进行额排序操作的用户。 Databend 只支持一个 Cluster key,Cluster key中可以包含多列及表达式。 基本语法 -- 语…...
C++day3(类、this指针、类中的特殊成员函数)
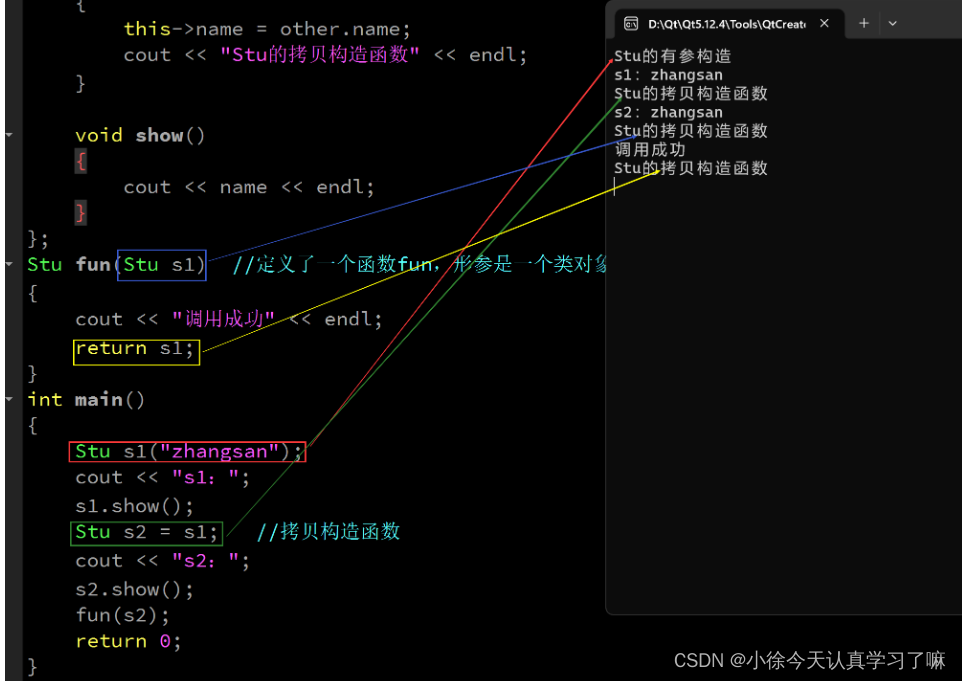
一、Xmind整理: 二、上课笔记整理: 1.类的应用实例 #include <iostream> using namespace std;class Person { private:string name; public:int age;int high;void set_name(string n); //在类内声明函数void show(){cout << "na…...

Qt中的配置文件:实现个性化应用程序配置与保存加载
一、前言 在现代软件开发中,用户对于应用程序的个性化配置和设置变得越来越重要。为了满足用户需求并提供更好的用户体验,开发人员常常需要实现一种机制,以便在每次启动应用程序时能够记住用户上次的配置。这样用户就可以方便地恢复到他们熟悉的环境,无需重新进行所有设置…...

Navicat激活时出现rsa public key not find错误
Navicat激活时出现rsa public key not find错误 在激活时,先不打开应用,先用管理员身份打开注册机Navicat_Keygen_Patch_v5.6_By_DFoX.exe,Navicat v15——>MySql——>Simplified Chinese——>Patch,执行完这些步骤之后…...

FFmpeg5.0源码阅读——URLContext和URLProtocol
摘要:本文描述FFmpeg中URLContext和URLProtocal的实现。 关键字:URLContext、URLProtocal FFmpeg中URLProtocol是具体的协议的抽象,其中定义了对应协议的抽象,其中包含了具体协议的操作函数指针。而URLContext是对协议操作的抽…...

Qt的输出
目录 基本分类 C风格输出 C风格 可以抑制输出 方法一 方法二 在Qt中进行log输出, 一般不使用c中的printf, 也不是使用C中的cout, Qt框架提供了专门用于日志输出的类, 头文件名为 QDebug。 基本分类 qDebug:调试信息提示 qInfo :输出信息 qWarnin…...

长胜证券:久违普涨再现 大盘回升有望加速
获得利好支撑后,大盘开始继续反弹。 沪指周二一路震动反弹,站上3100点整数关口后继续上攻并打破10日均线限制。深成指同样低开高走,全日体现明显强于沪指。 到收盘,沪指报收3135.89点,上涨1.2%;深成指报收…...
)
WPF .NET 7.0学习整理(一)
参照文档进行不系统的整理,看到那写到那O.o 依赖属性 DependencyProperty:使用专有字段支持属性的标准模式的替代方法。 DependencyObject:定义了可以注册和拥有依赖属性的基类。 public static readonly DependencyProperty IsSpinningPr…...

数据分析简介
判断采集数据的有效性和进行数据校准是数据处理中重要的步骤。以下是一些常见的方法和步骤可以帮助你进行数据有效性的判断和数据校准: 数据有效性判断: 数据范围:检查数据是否落在合理的范围内。根据具体情况,确定真实数据的上下限ÿ…...

解读未知:文本识别算法的突破与实际应用
解读未知:文本识别算法的突破与实际应用 1.文本识别算法理论 背景介绍 文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面…...
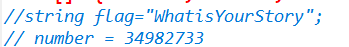
[第七届蓝帽杯全国大学生网络安全技能大赛 蓝帽杯 2023]——Web方向部分题 详细Writeup
Web LovePHP 你真的熟悉PHP吗? 源码如下 <?php class Saferman{public $check True;public function __destruct(){if($this->check True){file($_GET[secret]);}}public function __wakeup(){$this->checkFalse;} } if(isset($_GET[my_secret.flag]…...
el-backtop返回顶部的使用
2023.8.26今天我学习了如何使用el-backtop组件进行返回页面顶部的效果,效果如: <el-backtop class"el-backtop"style"right: 20px; bottom: 150px;"><i class"el-icon-caret-top"></i></el-backtop&…...

Go 官方标准编译器中所做的优化
本文是对#102 Go 官方标准编译器中实现的优化集锦汇总[1] 内容的记录与总结. 优化1-4: 字符串和字节切片之间的转化 1.紧跟range关键字的 从字符串到字节切片的转换; package mainimport ( "fmt" "strings" "testing")var cs10086 s…...
C语言程序设计——小学生计算机辅助教学系统
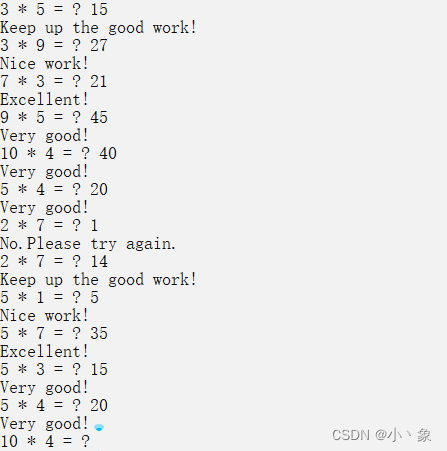
题目:小学生计算机辅助教学系统 编写一个程序,帮助小学生学习乘法。然后判断学生输入的答案对错与否,按下列任务要求以循序渐进的方式分别编写对应的程序并调试。 任务1 程序首先随机产生两个1—10之间的正整数,在屏幕上打印出问题…...

SQL自动递增的列恢复至从0开始
在许多数据库管理系统中,当你删除表格中的所有数据时,自动递增的列(也称为自增列、标识列或序列)的计数器通常不会重置为 0。这是出于性能和数据完整性方面的考虑,以避免因删除数据而导致的自增列值冲突。即使你删除了…...

介绍一下CDN
CDN(内容分发网络,Content Delivery Network)是一个由多个服务器组成的分布式网络,它的目的是将内容高效地传送到用户。下面是CDN的工作原理及其主要特点: 内容分发:当用户首次请求某一特定内容时ÿ…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...
)
保姆级教程:手把手教你搞定ESXi 6.7安装前的BIOS设置(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7安装前的BIOS设置终极指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我记得自己第一次在Dell PowerEdge服务器上安装ESXi时,光是搞清楚BIOS里那些晦涩的选项就花了整整一…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...

MaxEnt建模总失败?别急着换数据,先检查ArcGIS裁剪栅格这1个像素的坑
MaxEnt建模失败?ArcGIS栅格裁剪的1像素陷阱与精准修复指南当你花费数小时整理好WorldClim气候数据、本地DEM高程和物种分布数据,满心期待地点击MaxEnt的运行按钮时,屏幕上突然跳出"Error projecting, two layers have different geograp…...