机器学习基础17-基于波士顿房价(Boston House Price)数据集训练模型的整个过程讲解
机器学习是一项经验技能,实践是掌握机器学习、提高利用机器学习
解决问题的能力的有效方法之一。那么如何通过机器学习来解决问题呢?
本节将通过一个实例来一步一步地介绍一个回归问题。
本章主要介绍以下内容:
- 如何端到端地完成一个回归问题的模型。
- 如何通过数据转换提高模型的准确度。
- 如何通过调参提高模型的准确度。
- 如何通过集成算法提高模型的准确度。
1 定义问题
在这个项目中将分析研究波士顿房价(Boston House Price)数据集,这个数据集中的每一行数据都是对波士顿周边或城镇房价的描述。数据是1978年统计收集的。数据中包含以下14个特征和506条数据(UCI机器学习仓库中的定义)。
· CRIM:城镇人均犯罪率。
· ZN:住宅用地所占比例。
· INDUS:城镇中非住宅用地所占比例。
· CHAS:CHAS虚拟变量,用于回归分析。
· NOX:环保指数。
· RM:每栋住宅的房间数。
· AGE:1940年以前建成的自住单位的比例。
· DIS:距离5个波士顿的就业中心的加权距离。
· RAD:距离高速公路的便利指数。
· TAX:每一万美元的不动产税率。
· PRTATIO:城镇中的教师学生比例。
· B:城镇中的黑人比例。
· LSTAT:地区中有多少房东属于低收入人群。
· MEDV:自住房屋房价中位数。
通过对这些特征属性的描述,我们可以发现输入的特征属性的度量单位是不统一的,也许需要对数据进行度量单位的调整。
2 导入数据
首先导入在项目中需要的类库。代码如下:
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import KFold, cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
接下来导入数据集到Python中,这个数据集也可以从UCI机器学习仓库下载,在导入数据集时还设定了数据属性特征的名字。
代码如下:
#导入数据
path = 'D:\down\\BostonHousing.csv'
data = pd.read_csv(path)
3 理解数据
对导入的数据进行分析,便于构建合适的模型。首先看一下数据维度,例如数据集中有多少条记录、有多少个数据特征。
代码如下:
print('data.shape=',data.shape)
执行之后我们可以看到总共有506条记录和14个特征属性,这与UCI提供的信息一致。
data.shape= (506, 14)
再查看各个特征属性的字段类型。代码如下:
#特征属性字段类型
print(data.dtypes)
可以看到所有的特征属性都是数字,而且大部分特征属性都是浮点
数,也有一部分特征属性是整数类型的。执行结果如下:
crim float64
zn float64
indus float64
chas int64
nox float64
rm float64
age float64
dis float64
rad int64
tax int64
ptratio float64
b float64
lstat float64
medv float64
dtype: object
接下来对数据进行一次简单的查看,在这里我们查看一下最开始的30条记录。代码如下:
print(data.head(30))
执行结果如下:
crim zn indus chas nox ... tax ptratio b lstat medv
0 0.00632 18.0 2.31 0 0.538 ... 296 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 ... 242 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 ... 242 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 ... 222 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0 0.458 ... 222 18.7 396.90 5.33 36.2
5 0.02985 0.0 2.18 0 0.458 ... 222 18.7 394.12 5.21 28.7
6 0.08829 12.5 7.87 0 0.524 ... 311 15.2 395.60 12.43 22.9
7 0.14455 12.5 7.87 0 0.524 ... 311 15.2 396.90 19.15 27.1
8 0.21124 12.5 7.87 0 0.524 ... 311 15.2 386.63 29.93 16.5
9 0.17004 12.5 7.87 0 0.524 ... 311 15.2 386.71 17.10 18.9
10 0.22489 12.5 7.87 0 0.524 ... 311 15.2 392.52 20.45 15.0
11 0.11747 12.5 7.87 0 0.524 ... 311 15.2 396.90 13.27 18.9
12 0.09378 12.5 7.87 0 0.524 ... 311 15.2 390.50 15.71 21.7
13 0.62976 0.0 8.14 0 0.538 ... 307 21.0 396.90 8.26 20.4
14 0.63796 0.0 8.14 0 0.538 ... 307 21.0 380.02 10.26 18.2
15 0.62739 0.0 8.14 0 0.538 ... 307 21.0 395.62 8.47 19.9
16 1.05393 0.0 8.14 0 0.538 ... 307 21.0 386.85 6.58 23.1
17 0.78420 0.0 8.14 0 0.538 ... 307 21.0 386.75 14.67 17.5
18 0.80271 0.0 8.14 0 0.538 ... 307 21.0 288.99 11.69 20.2
19 0.72580 0.0 8.14 0 0.538 ... 307 21.0 390.95 11.28 18.2
20 1.25179 0.0 8.14 0 0.538 ... 307 21.0 376.57 21.02 13.6
21 0.85204 0.0 8.14 0 0.538 ... 307 21.0 392.53 13.83 19.6
22 1.23247 0.0 8.14 0 0.538 ... 307 21.0 396.90 18.72 15.2
23 0.98843 0.0 8.14 0 0.538 ... 307 21.0 394.54 19.88 14.5
24 0.75026 0.0 8.14 0 0.538 ... 307 21.0 394.33 16.30 15.6
25 0.84054 0.0 8.14 0 0.538 ... 307 21.0 303.42 16.51 13.9
26 0.67191 0.0 8.14 0 0.538 ... 307 21.0 376.88 14.81 16.6
27 0.95577 0.0 8.14 0 0.538 ... 307 21.0 306.38 17.28 14.8
28 0.77299 0.0 8.14 0 0.538 ... 307 21.0 387.94 12.80 18.4
29 1.00245 0.0 8.14 0 0.538 ... 307 21.0 380.23 11.98 21.0
接下来看一下数据的描述性统计信息。代码如下:
#pandas 新版本
pd.options.display.precision=1
#pandas老版本
#pd.set_option("precision", 1)
在描述性统计信息中包含数据的最大值、最小值、中位值、四分位值
等,分析这些数据能够加深对数据分布、数据结构等的理解。结果如下
crim zn indus chas ... ptratio b lstat medv
count 5.1e+02 506.0 506.0 5.1e+02 ... 506.0 506.0 506.0 506.0
mean 3.6e+00 11.4 11.1 6.9e-02 ... 18.5 356.7 12.7 22.5
std 8.6e+00 23.3 6.9 2.5e-01 ... 2.2 91.3 7.1 9.2
min 6.3e-03 0.0 0.5 0.0e+00 ... 12.6 0.3 1.7 5.0
25% 8.2e-02 0.0 5.2 0.0e+00 ... 17.4 375.4 6.9 17.0
50% 2.6e-01 0.0 9.7 0.0e+00 ... 19.1 391.4 11.4 21.2
75% 3.7e+00 12.5 18.1 0.0e+00 ... 20.2 396.2 17.0 25.0
max 8.9e+01 100.0 27.7 1.0e+00 ... 22.0 396.9 38.0 50.0
接下来看一下数据特征之间的两两关联关系,这里查看数据的皮尔逊相关系数。代码如下:
crim zn indus chas nox ... tax ptratio b lstat medv
crim 1.00 -0.20 0.41 -5.59e-02 0.42 ... 0.58 0.29 -0.39 0.46 -0.39
zn -0.20 1.00 -0.53 -4.27e-02 -0.52 ... -0.31 -0.39 0.18 -0.41 0.36
indus 0.41 -0.53 1.00 6.29e-02 0.76 ... 0.72 0.38 -0.36 0.60 -0.48
chas -0.06 -0.04 0.06 1.00e+00 0.09 ... -0.04 -0.12 0.05 -0.05 0.18
nox 0.42 -0.52 0.76 9.12e-02 1.00 ... 0.67 0.19 -0.38 0.59 -0.43
rm -0.22 0.31 -0.39 9.13e-02 -0.30 ... -0.29 -0.36 0.13 -0.61 0.70
age 0.35 -0.57 0.64 8.65e-02 0.73 ... 0.51 0.26 -0.27 0.60 -0.38
dis -0.38 0.66 -0.71 -9.92e-02 -0.77 ... -0.53 -0.23 0.29 -0.50 0.25
rad 0.63 -0.31 0.60 -7.37e-03 0.61 ... 0.91 0.46 -0.44 0.49 -0.38
tax 0.58 -0.31 0.72 -3.56e-02 0.67 ... 1.00 0.46 -0.44 0.54 -0.47
ptratio 0.29 -0.39 0.38 -1.22e-01 0.19 ... 0.46 1.00 -0.18 0.37 -0.51
b -0.39 0.18 -0.36 4.88e-02 -0.38 ... -0.44 -0.18 1.00 -0.37 0.33
lstat 0.46 -0.41 0.60 -5.39e-02 0.59 ... 0.54 0.37 -0.37 1.00 -0.74
medv -0.39 0.36 -0.48 1.75e-01 -0.43 ... -0.47 -0.51 0.33 -0.74 1.00[14 rows x 14 columns]
通过上面的结果可以看到,有些特征属性之间具有强关联关系(>0.7或<-0.7),如:
· NOX与INDUS之间的皮尔逊相关系数是0.76。
· DIS与INDUS之间的皮尔逊相关系数是-0.71。
· TAX与INDUS之间的皮尔逊相关系数是0.72。
· AGE与NOX之间的皮尔逊相关系数是0.73。
· DIS与NOX之间的皮尔逊相关系数是-0.77。
4 数据可视化
单一特征图表
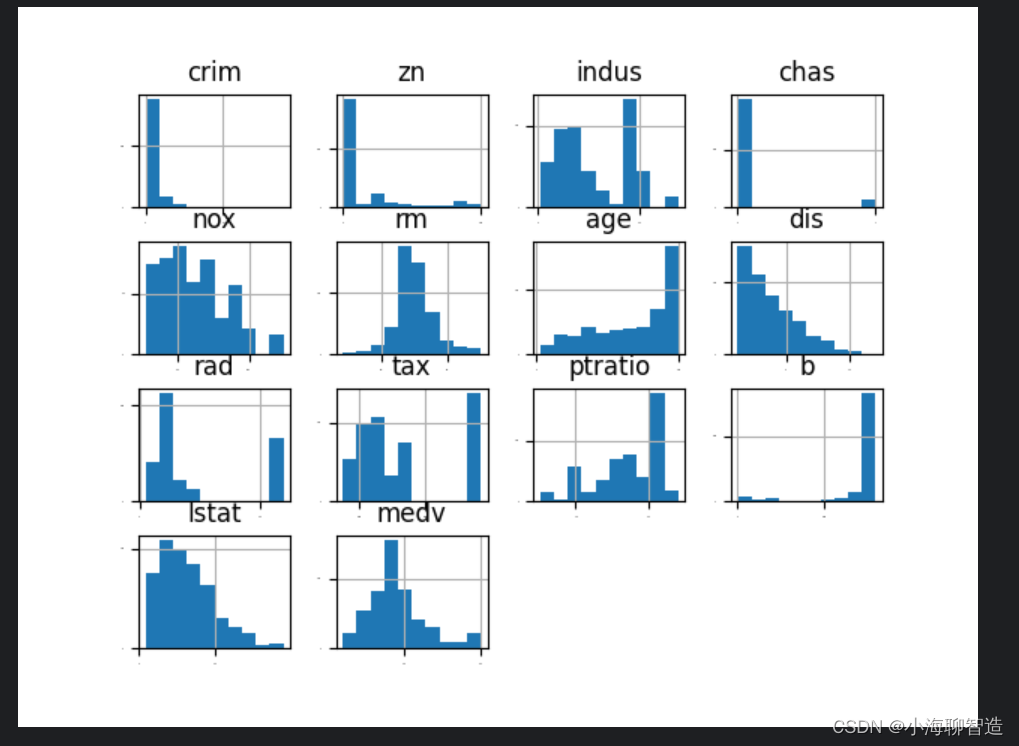
首先查看每一个数据特征单独的分布图,多查看几种不同的图表有助于发现更好的方法。我们可以通过查看各个数据特征的直方图,来感受一下数据的分布情况。代码如下:
data.hist(sharex=False,sharey=False,xlabelsize=1,ylabelsize=1)
pyplot.show()
执行结果如下图所示,从图中可以看到有些数据呈指数分布,如
CRIM、ZN、AGE和B;有些数据特征呈双峰分布,如RAD和TAX。
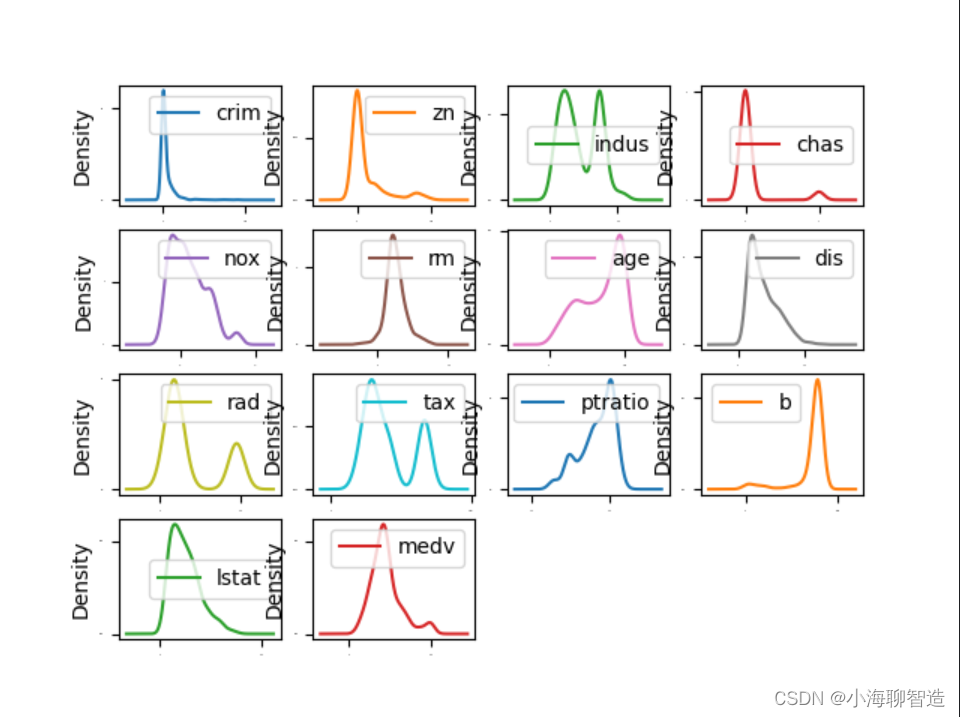
通过密度图可以展示这些数据的特征属性,密度图比直方图更加平滑地展示了这些数据特征。代码如下:
data.plot(kind='density',subplots=True,layout=(4,4),sharex=False,fontsize=1)
pyplot.show()在密度图中,指定layout=(4,4),这说明要画一个四行四列的图
形。执行结果如图所示
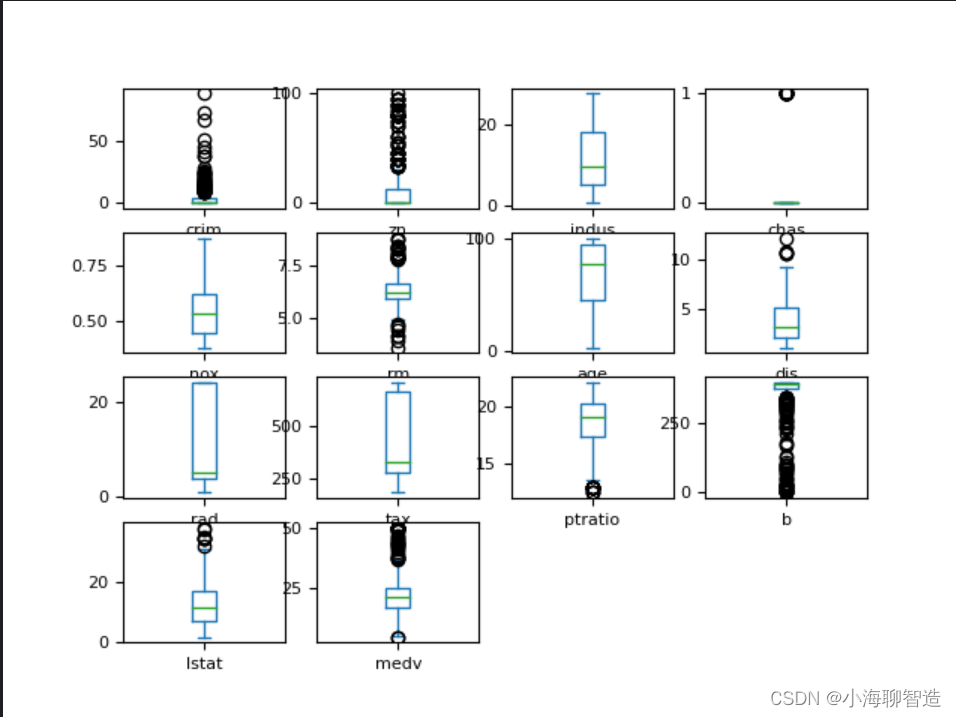
通过箱线图可以查看每一个数据特征的状况,也可以很方便地看出数据分布的偏态程度。代码如下:
data.plot(kind='box',subplots=True,layout=(4,4),sharex=False,fontsize=8)
pyplot.show()
执行结果:
多重数据图表
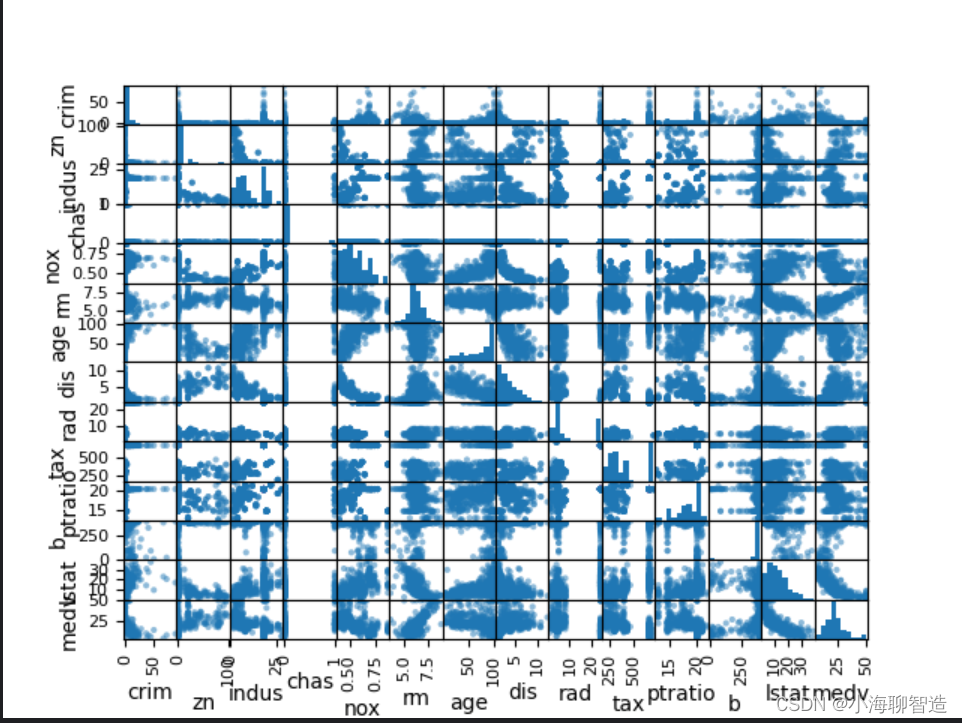
接下来利用多重数据图表来查看不同数据特征之间的相互影响关系。首先看一下散点矩阵图。代码如下:
#散点矩阵图
scatter_matrix(data)
pyplot.show()
通过散点矩阵图可以看到,虽然有些数据特征之间的关联关系很强,但是这些数据分布结构也很好。即使不是线性分布结构,也是可以很方便进行预测的分布结构,执行结果如图所示。
再看一下数据相互影响的相关矩阵图。代码如下:
#相关矩阵图
names = ['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax','ptratio', 'b', 'lstat']
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(data.corr(), vmin =-1,vmax =1, interpolation='none')
fig.colorbar(cax)
ticks = np.arange(0,13,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
pyplot.show()执行结果如图所示,根据图例可以看到,数据特征属性之间的两
两相关性,有些属性之间是强相关的,建议在后续的处理中移除这些特征属性,以提高算法的准确度。
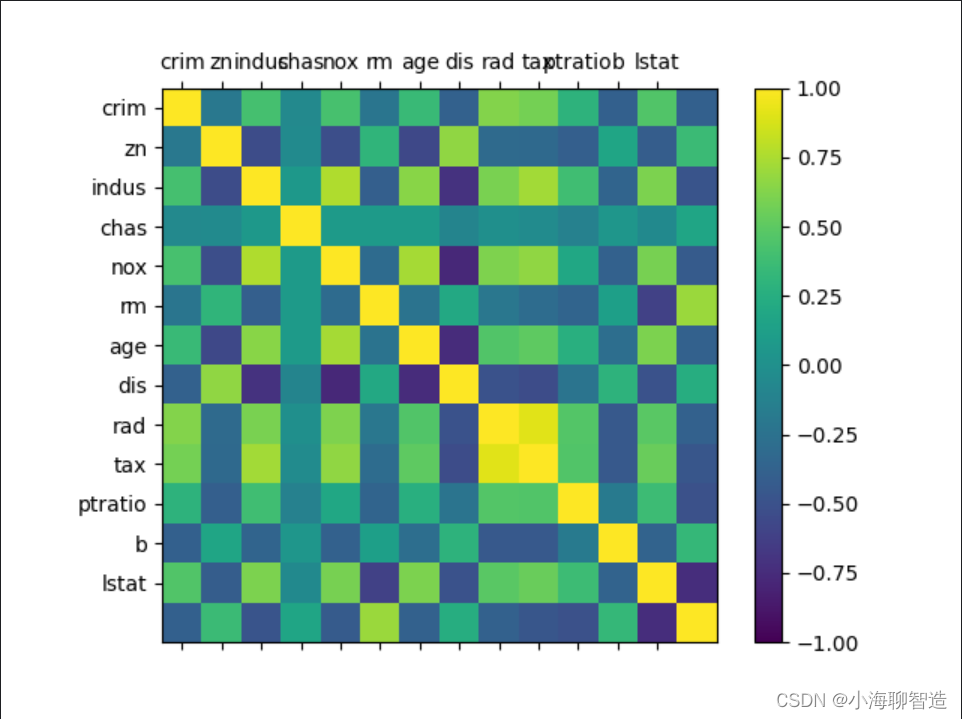
通过数据的相关性和数据的分布等发现,数据集中的数据结构比较复杂,需要考虑对数据进行转换,以提高模型的准确度。可以尝试从以下几个方面对数据进行处理:
· 通过特征选择来减少大部分相关性高的特征。
· 通过标准化数据来降低不同数据度量单位带来的影响。
· 通过正态化数据来降低不同的数据分布结构,以提高算法的准确度。
可以进一步查看数据的可能性分级(离散化),它可以帮助提高决策树算法的准确度。
5.分离评估数据集
分离出一个评估数据集是一个很好的主意,这样可以确保分离出的数据集与训练模型的数据集完全隔离,有助于最终判断和报告模型的准确度。在进行到项目的最后一步处理时,会使用这个评估数据集来确认模型的准确度。这里分离出 20%的数据作为评估数据集,80%的数据作为训练数据集。
代码如下:
#分离数据集,分离出 20%的数据作为评估数据集,80%的数据作为训练数据集
array = data.values
X = array[:, 0:13]
Y = array[:, 13]
validation_size = 0.2
seed = 7
X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size = validation_size,random_state=seed)6评估算法
分析完数据不能立刻选择出哪个算法对需要解决的问题最有效。我们直观上认为,由于部分数据的线性分布,线性回归算法和弹性网络回归算法对解决问题可能比较有效。另外,由于数据的离散化,通过决策树算法或支持向量机算法也许可以生成高准确度的模型。
到这里,依然不清楚哪个算法会生成准确度最高的模型,因此需要设计一个评估框架来选择合适的算法。我们采用10折交叉验证来分离数据,通过均方误差来比较算法的准确度。均方误差越趋近于0,算法准确度越高。
代码如下:
seed = 7
num_folds = 10
scoring = 'neg_mean_squared_error'
对原始数据不做任何处理,对算法进行一个评估,形成一个算法的评估基准。这个基准值是对后续算法改善优劣比较的基准值。我们选择三个线性算法和三个非线性算法来进行比较。
线性算法:线性回归(LR)、套索回归(LASSO)和弹性网络回归(EN)。
非线性算法:分类与回归树(CART)、支持向量机(SVM)和K近邻算法(KNN)。
算法模型初始化的代码如下:
#评估算法models = {}models['LR'] = LogisticRegression()
models['LASSO'] = Lasso()
models['EN'] = ElasticNet()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVR()X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size = validation_size,random_state=seed)results = []for key in models:kflod = KFold(n_splits=num_folds,random_state=seed,shuffle=True)result = cross_val_score(models[key], X_train, Y_train.astype('int'), cv=kflod,scoring= scoring)results.append(result)print("%s: %.3f (%.3f)" % (key, result.mean(), result.std()))
从执行结果来看,套索回归(LASSO)具有最优的 MSE,接下来是弹性网络回归(EN))算法。执行结果如下:
LR: -59.150 (17.584)
LASSO: -27.313 (13.573)
EN: -28.251 (13.577)
KNN: -62.158 (28.251)
CART: -31.000 (19.562)
SVM: -68.676 (33.776)
再查看所有的10折交叉分离验证的结果。代码如下:
#评估算法箱线图fig = pyplot.figure()
fig.suptitle("Algorithm Comparison")
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()执行结果如图所示,从图中可以看到,线性算法的分布比较类
似,并且分类与回归树(CART)算法的结果分布非常紧凑。
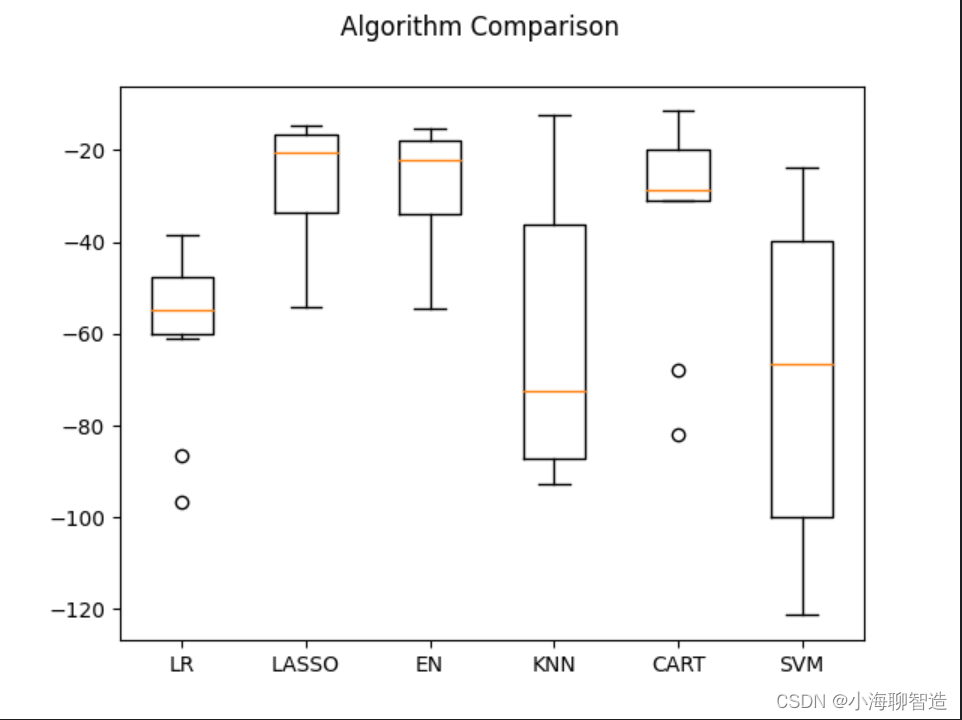
评估算法——正态化数据
在这里猜测也许因为原始数据中不同特征属性的度量单位不一样,导致有的算法的结果不是很好。接下来通过对数据进行正态化,再次评估这些算法。在这里对训练数据集进行数据转换处理,将所有的数据特征值转化成“0”为中位值、标准差为“1”的数据。对数据正态化时,为了防止数据泄露,采用 Pipeline 来正态化数据和对模型进行评估。为了与前面的结果进行比较,此处采用相同的评估框架来评估算法模型。
代码如下:
#评估算法--正态化数据pipelines ={}pipelines['ScalerLR'] = Pipeline([('Scaler',StandardScaler()),('LR',LinearRegression())])
pipelines['ScalerLASSO'] = Pipeline([('Scaler',StandardScaler()),('LASSO',Lasso())])
pipelines['ScalerEN'] = Pipeline([('Scaler',StandardScaler()),('EN',ElasticNet())])
pipelines['ScalerKNN'] = Pipeline([('Scaler',StandardScaler()),('KNN',KNeighborsRegressor())])pipelines['ScalerCART'] = Pipeline([('Scaler',StandardScaler()),('CART',DecisionTreeRegressor())])
pipelines['ScalerSVM'] = Pipeline([('Scaler',StandardScaler()),('SVM',SVR())])X_train,X_validation,Y_train,Y_validation = train_test_split(X,Y,test_size = validation_size,random_state=seed)results = []for key in pipelines:kflod = KFold(n_splits=num_folds,random_state=seed,shuffle=True)cv_result = cross_val_score(pipelines[key], X_train, Y_train, cv=kflod,scoring= scoring)results.append(cv_result)print("%s: %.3f (%.3f)" % (key, cv_result.mean(), cv_result.std()))
执行后发现K近邻算法具有最优的MSE。执行结果如下:
ScalerLR: -22.006 (12.189)
ScalerLASSO: -27.206 (12.124)
ScalerEN: -28.301 (13.609)
ScalerKNN: -21.457 (15.016)
ScalerCART: -27.813 (20.786)
ScalerSVM: -29.570 (18.053)
接下来再来看一下所有的10折交叉分离验证的结果。代码如下:
#评估算法箱线图fig = pyplot.figure()
fig.suptitle("Algorithm Comparison")
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
执行结果,生成的箱线图如图所示,可以看到K近邻算法具有最优的MSE和最紧凑的数据分布。
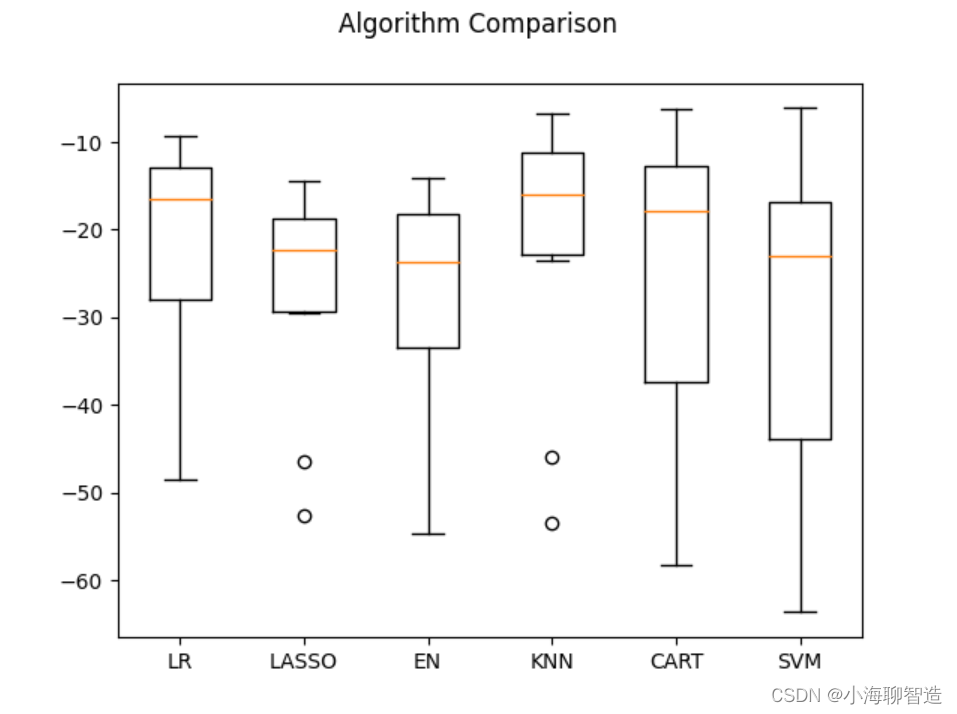
目前来看,K 近邻算法对做过数据转换的数据集有很好的结果,但是是否可以进一步对结果做一些优化呢?
K近邻算法的默认参数近邻个数(n_neighbors)是5,下面通过网格搜索算法来优化参数。代码如下:
#调参改善算法-knn
scaler = StandardScaler().fit(X_train) # fit生成规则
#scaler = StandardScaler.fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid ={'n_neighbors':[1,3,5,7,9,11,13,15,19,21]}
model = KNeighborsRegressor()kflod = KFold(n_splits=num_folds,random_state=seed,shuffle=True)
grid = GridSearchCV(estimator =model,param_grid=param_grid,scoring=scoring,cv = kflod)grid_result = grid.fit(X=rescaledX,y = Y_train)print('最优:%s 使用%s'%(grid_result.best_score_,grid_result.best_params_))cv_results = zip(grid_result.cv_results_['mean_test_score'],grid_result.cv_results_['params'])for mean,param in cv_results:print(mean,param)
最优结果——K近邻算法的默认参数近邻个数(n_neighbors)是1。执
行结果如下:
最优:-19.497828658536584 使用{'n_neighbors': 1}
-19.497828658536584 {'n_neighbors': 1}
-19.97798367208672 {'n_neighbors': 3}
-21.270966658536583 {'n_neighbors': 5}
-21.577291737182684 {'n_neighbors': 7}
-21.00107515055706 {'n_neighbors': 9}
-21.490306228582945 {'n_neighbors': 11}
-21.26853270313177 {'n_neighbors': 13}
-21.96809222222222 {'n_neighbors': 15}
-23.506900689142622 {'n_neighbors': 19}
-24.240302870416464 {'n_neighbors': 21}
确定最终模型
我们已经确定了使用极端随机树(ET)算法来生成模型,下面就对该算法进行训练和生成模型,并计算模型的准确度。代码如下:
#训练模型caler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
gbr = ExtraTreeRegressor()
gbr.fit(X=rescaledX,y=Y_train)
#评估算法模型rescaledX_validation = scaler.transform(X_validation)
predictions = gbr.predict(rescaledX_validation)
print(mean_squared_error(Y_validation,predictions))
执行结果如下:
14.392352941176469
本项目实例从问题定义开始,直到最后的模型生成为止,完成了一个完整的机器学习项目。通过这个项目,理解了上一节中介绍的机器学习项目的模板,以及整个机器学习模型建立的流程。
相关文章:
机器学习基础17-基于波士顿房价(Boston House Price)数据集训练模型的整个过程讲解
机器学习是一项经验技能,实践是掌握机器学习、提高利用机器学习 解决问题的能力的有效方法之一。那么如何通过机器学习来解决问题呢? 本节将通过一个实例来一步一步地介绍一个回归问题。 本章主要介绍以下内容: 如何端到端地完成一个回归问题…...

哈希的应用——布隆过滤器
✅<1>主页::我的代码爱吃辣 📃<2>知识讲解:数据结构——位图 ☂️<3>开发环境:Visual Studio 2022 💬<4>前言:布隆过滤器是由布隆(Burton Howard Bloom&…...

LNMT的多机部署和双机热备
目录 一、环境 二、配置tomcat 三、配置nfs共享 四、配置nginx 1、两台都需要折磨配置 2、在http下面插入这两条信息 五、配置keepalived 1、安装 2、重新启动一下keepalived查看IP 六、验证双机热备 1、查看调度器备的IP,ip漂移说明keepalived生效 2、访…...

软件测试/测试开发丨Pytest和Allure报告 学习笔记
点此获取更多相关资料 本文为霍格沃兹测试开发学社学员学习笔记分享 原文链接:https://ceshiren.com/t/topic/26755 Pytest 命名规则 类型规则文件test_开头 或者 _test 结尾类Test 开头方法/函数test_开头注意:测试类中不可以添加__init__构造函数 注…...
十七、命令模式
一、什么是命令模式 命令(Command)模式的定义:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。 命令…...

服务器安装 anaconda 及 conda: command not found [解决方案]
[解决方案] conda: command not found Anaconda3 安装conda: command not found Anaconda3 安装 由于连接的服务器,无法直接在anaconda官网上下载安装文件,所以使用如下方法: wget https://repo.anaconda.com/archive/Anaconda3-2023.03-Li…...
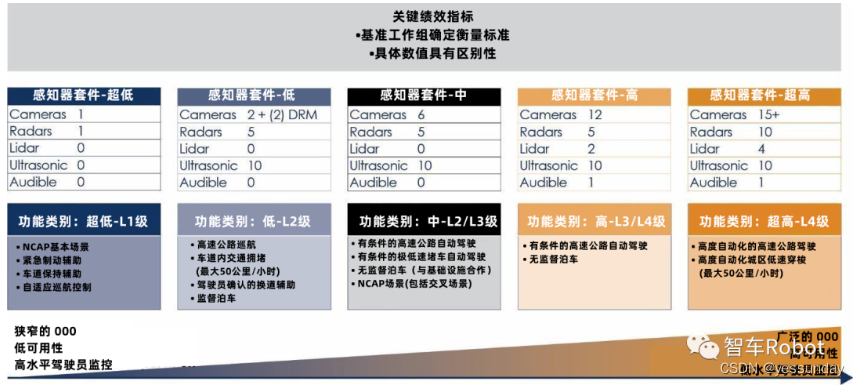
自动驾驶和辅助驾驶系统的概念性架构(二)
摘要: 本篇为第二部分主要介绍底层计算单元、示例工作负载 前言 本文档参考自动驾驶计算联盟(Autonomous Vehicle Computing Consortium)关于自动驾驶和辅助驾驶计算系统的概念系统架构。该架构旨在与SAE L1-L5级别的自动驾驶保持一致。本文主要介绍包括功能模块图…...
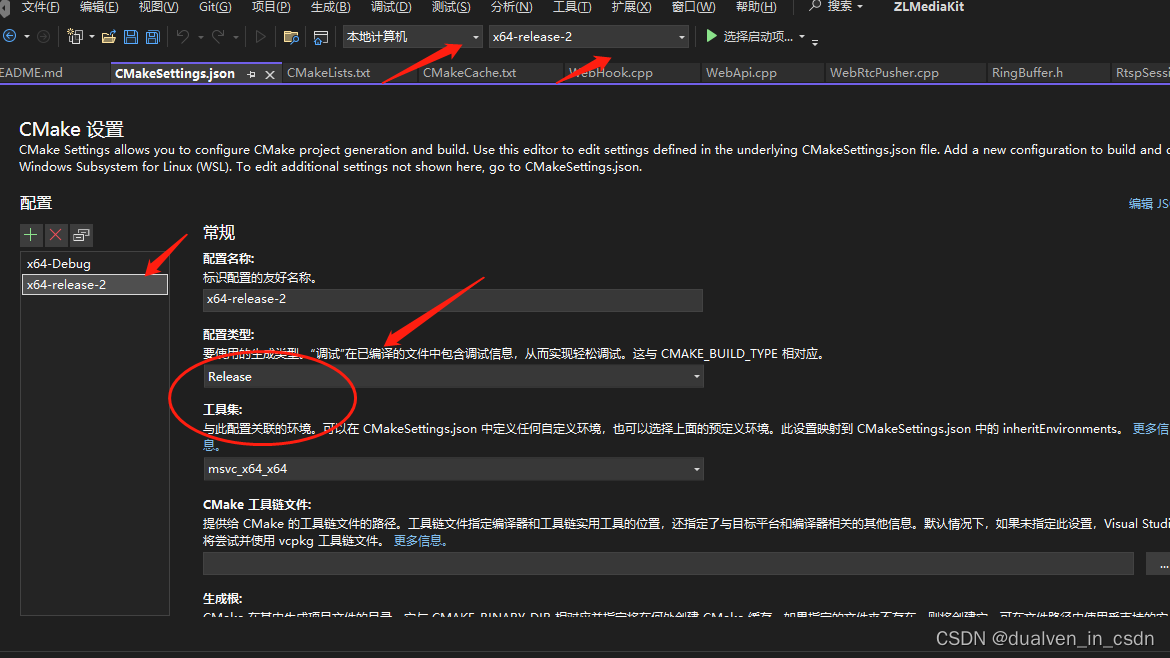
【c++】VC编译出的版本,发布版本如何使用
目录 使用release类型进行发布 应用程序无法正常启动 0xc000007b 版本对应 vcruntime140d 应用版本 参考文章 使用release类型进行发布 应用程序无法正常启动 0xc000007b "应用程序无法正常启动 0xc000007b" 错误通常是一个 Windows 应用程序错误…...

自然语言处理(五):子词嵌入(fastText模型)
子词嵌入 在英语中,“helps”“helped”和“helping”等单词都是同一个词“help”的变形形式。“dog”和“dogs”之间的关系与“cat”和“cats”之间的关系相同,“boy”和“boyfriend”之间的关系与“girl”和“girlfriend”之间的关系相同。在法语和西…...
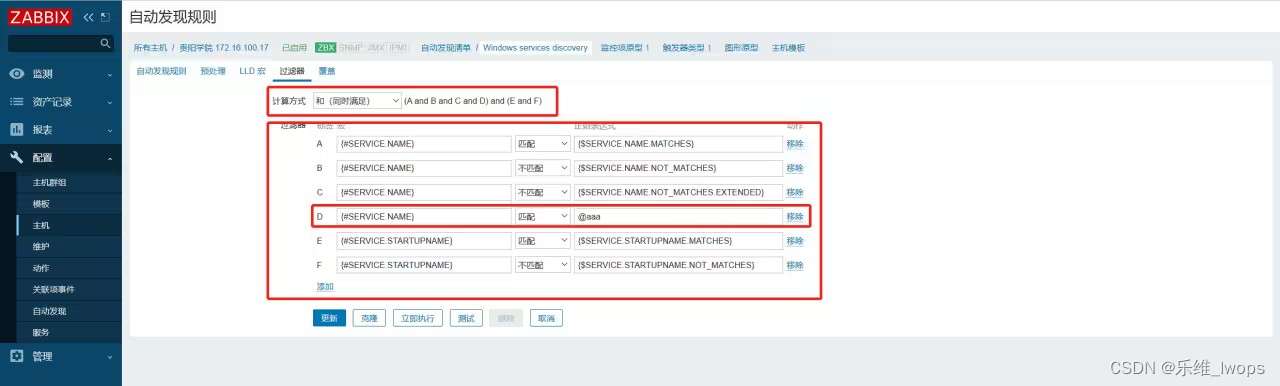
Zabbix“专家坐诊”第202期问答汇总
问题一 Q:请问一下 zabbix 里面怎么能创建出和sh文件有关联的监控项? A: 1.使用 Zabbix Agent 主动模式:如果你在目标主机上安装了 Zabbix Agent,并且想要监控与 sh 文件相关的指标,可以创建一个自定义的…...
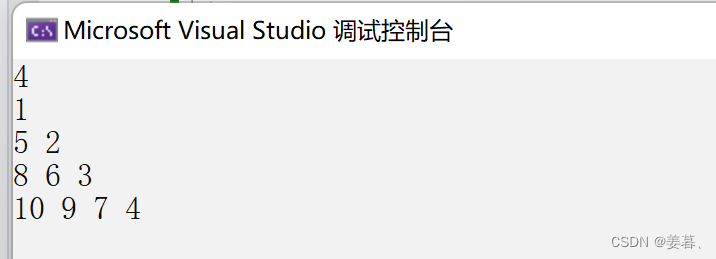
【c语言】输出n行按如下规律排列的数
题述:输出n行按如下规律排列的数 输入: 4(应该指的是n) 输出: 思路: 利用下标的规律求解,考察数组下标的灵活应用,我们可以看出数从1开始是斜着往下放的,那么我们如何利用两层for循环求解这道题ÿ…...

023 - STM32学习笔记 - 扩展外部SDRAM(二) - 扩展外部SDRAM实验
023- STM32学习笔记 - 扩展外部SDRAM(一) - 扩展外部SDRAM实验 本节内容中要配置的引脚很多,如果你用的开发板跟我的不一样,请详细参照STM32规格书中说明对相关GPIO引脚进行配置。 先提前对本届内容的变成步骤进行总结如下&…...

机器学习 | Python实现XGBoost极限梯度提升树模型答疑
机器学习 | MATLAB实现XGBoost极限梯度提升树模型答疑 目录 机器学习 | MATLAB实现XGBoost极限梯度提升树模型答疑问题系列问题回答问题系列 关于XGBoost有几个问题想请教一下。1.XGBoost的API有哪些种调用方法?2.参数如何调? 问题回答 XGBoost的API有2种调用方法,一种是我们…...
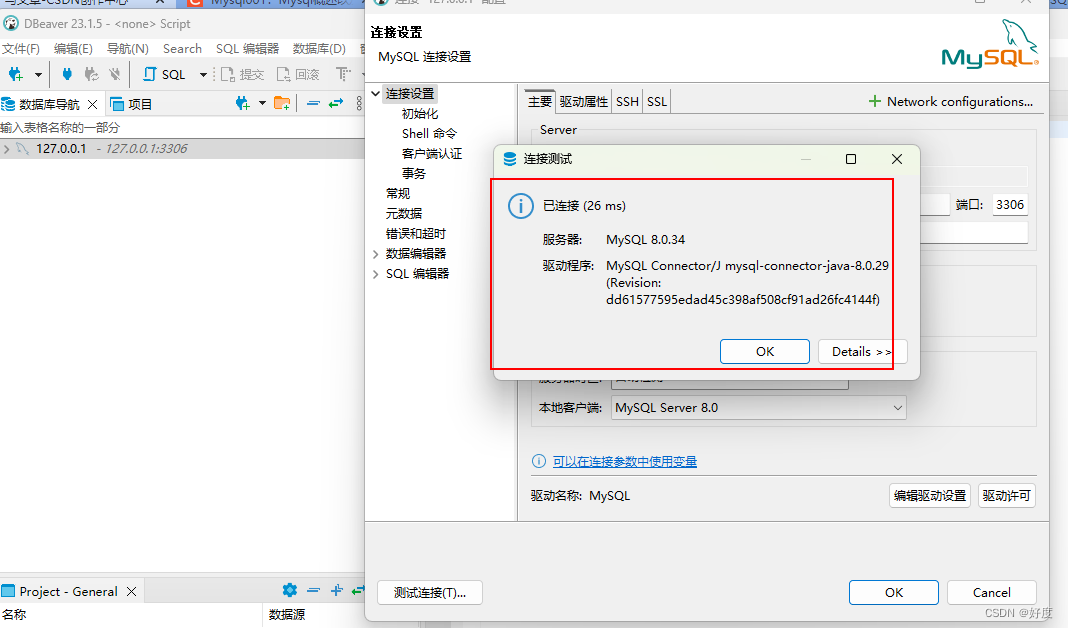
关于使用远程工具连接mysql数据库时,提示:Public Key Retrieval is not allowed
我在使用DBeaver工具连接 数据库时,提示:Public Key Retrieval is not allowed, 我在前一天还是可以连接的,但是今天突然无法连接了, 但是最后捣鼓了一下又可以了。 具体方法:首先先把mysql服务停了&#x…...

leetcode做题笔记117. 填充每个节点的下一个右侧节点指针 II
给定一个二叉树: struct Node {int val;Node *left;Node *right;Node *next; } 填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。 初始状态下,所有 next 指针都…...
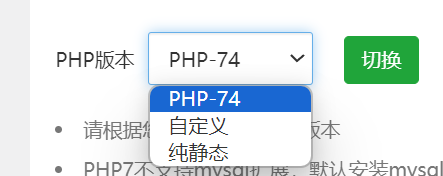
解决博客不能解析PHP直接下载源码问题
背景: 在网站设置反向代理后,网站突然不能正常访问,而是会直接下载访问文件的PHP源码 解决办法: 由于在搞完反向代理之后,PHP版本变成了纯静态,所以网站不能正常解析;只需要把PHP版本恢复正常…...

voc 转coco
import os import random import shutil import sys import json import glob import xml.etree.ElementTree as ET""" 修改下面3个参数 1.val_files_num : 验证集的数量 2.test_files_num :测试集的数量 3.voc_annotations : voc的annotations路径 …...

【C语言每日一题】03. 对齐输出
题目来源:http://noi.openjudge.cn/ch0101/03/ 03 对齐输出 总时间限制: 1000ms 内存限制: 65536kB 问题描述 读入三个整数,按每个整数占8个字符的宽度,右对齐输出它们。 输入 只有一行,包含三个整数,整数之间以一…...

七大排序完整版
目录 一、直接插入排序 (一)单趟直接插入排 1.分析核心代码 2.完整代码 (二)全部直接插入排 1.分析核心代码 2.完整代码 (三)时间复杂度和空间复杂度 二、希尔排序 (一)对…...

C语言的数据类型简介
一、基本类型 (1)六种基本类型 **字符串常量和字符常量的不同 1)‘a’为字符常量,”a”为字符串常量 2)每个字符串的结尾,编译器会自动添加一个结束标志位‘\0’ “a”包含两个字符’a’和’\0’ &#x…...

Graphormer一文详解:RDKit+PyG+Gradio技术栈整合与Supervisor服务管理
Graphormer一文详解:RDKitPyGGradio技术栈整合与Supervisor服务管理 1. 项目概述 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等分…...

OpenSubdiv高级特性:特征自适应细分与硬件曲面细分
OpenSubdiv高级特性:特征自适应细分与硬件曲面细分 【免费下载链接】OpenSubdiv An Open-Source subdivision surface library. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSubdiv OpenSubdiv是一款强大的开源细分曲面库,为3D建模和动画提…...

当触控板遇见鼠标:一场被重构的滚动革命
当触控板遇见鼠标:一场被重构的滚动革命 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 在MacBook Pro的触控板上轻扫手指,网页随指尖方向自然滚动&#…...
Qwen-Image-2512-Pixel-Art-LoRA 模型原理浅析:理解LoRA在图像生成中的作用
Qwen-Image-2512-Pixel-Art-LoRA 模型原理浅析:理解LoRA在图像生成中的作用 最近在玩AI画图的朋友,可能都遇到过这样的烦恼:想让一个通用的大模型画出特定风格,比如复古的像素风,结果要么画得不像,要么就得…...

DDS信号发生器设计避坑指南:基于FPGA的AD9767驱动常见问题与优化技巧
FPGA驱动AD9767实战避坑手册:从时序优化到DDS精度提升的进阶技巧 当你在深夜调试FPGA与AD9767的接口时,示波器上那些不规则的毛刺和频率偏差是否曾让你抓狂?作为一款经典的高速14位DAC芯片,AD9767在信号发生、通信系统等领域应用广…...

Java 零基础全套视频教程,String StringBuffer StringBuilder 类,笔记142-146
Java 零基础全套视频教程,String StringBuffer StringBuilder 类,笔记142-146 一、参考资料 【尚硅谷Java零基础全套视频教程(宋红康主讲,java入门自学必备)】 https://www.bilibili.com/video/BV1PY411e7J6/?p142&share_sourcecopy_web…...

AntimicroX完全指南:游戏手柄映射的艺术与科学
AntimicroX完全指南:游戏手柄映射的艺术与科学 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.com/GitHub_Trend…...

基于Moondream2的工业质检系统:缺陷检测与分类
基于Moondream2的工业质检系统:缺陷检测与分类 1. 为什么传统质检方式正在被重新思考 产线上的质检员每天要盯着成百上千件产品,眼睛酸涩、注意力下降,漏检率悄悄爬升。一台设备表面划痕只有0.1毫米宽,人眼在连续工作两小时后&a…...

千问3.5-2B在办公提效场景:会议白板照片文字提取+要点总结实战
千问3.5-2B在办公提效场景:会议白板照片文字提取要点总结实战 1. 办公场景的痛点与解决方案 1.1 会议记录的传统困境 每次开完会,最让人头疼的就是整理会议记录了。特别是那些在白板上写满讨论要点的会议,你需要: 对着白板照片…...

电子工程师职业发展:技术深度与行业视野的平衡
1. 电子工程师的职业困境与突破路径作为一名在电子行业摸爬滚打十余年的老兵,我见过太多才华横溢的同行最终陷入职业瓶颈。有趣的是,阻碍我们发展的往往不是技术本身,而是那些容易被忽视的"软性因素"。记得刚入行时,我也…...