Python 基本文件操作及os库
内置函数文件操作
python内置函数提供了简单的文件操作支持。
open()
open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法为:
open(file,mode='r',buffering=-1,encoding=None,errors=None,newline=None,closefd=True,opener=None,
)参数说明:
- file:file 是一个类路径对象(path-like object),表示将要打开的文件的路径
- mode:默认为 'r',用于指定打开文件的模式,可见下文介绍。
- buffering:设置缓冲策略
- encoding:是用于解码或编码文件的编码的名称,这只能在文本模式下使用,默认编码依赖于平台,但 Python 支持的任何编码都可以传递。
- errors:指定如何处理编码和解码错误,不能在二进制模式下使用。
- newline:控制如何换行
- closefd:如果 closefd 为 False 且给出的不是文件名而是文件描述符,那么当文件关闭时,底层文件描述符将保持打开状态。如果给出的是文件名,则 closefd 必须为 True (默认值),否则将触发错误。
- opener: 可以通过传递可调用的 opener 来使用自定义开启器。然后通过使用参数( file,flags )调用 opener 获得文件对象的基础文件描述符。 opener 必须返回一个打开的文件描述符(使用 os.open as opener 时与传递 None 的效果相同)。
file 是一个类路径对象(path-like object),表示将要打开的文件的路径(绝对路径或者相对当前工作目录的路径),也可以是要封装文件对应的整数类型文件描述符。(如果给出的是文件描述符,则当返回的 I/O 对象关闭时它也会关闭,除非将 closefd 设为 False 。)
路径类对象(path-like object)代表一个文件系统路径的对象。类路径对象可以是一个表示路径的 str 或者 bytes 对象,还可以是一个实现了 os.PathLike 协议的对象。一个支持 os.PathLike 协议的对象可通过调用 os.fspath() 函数转换为 str 或者 bytes 类型的文件系统路径;os.fsdecode() 和 os.fsencode() 可被分别用来确保获得 str 或 bytes 类型的结果。
可用的模式有:
- 'r':读文件 (默认)
- 'w':打开以进行写入,首先截断文件
- 'x':创建一个新文件并打开它进行写入,如果存在则失败
- 'a':打开进行写入,如果文件存在,则追加到文件末尾
- 'b':二进制模式
- 't':文本模式 (默认)
- '+':打开文件进行更新(读写)
- 'U':通用换行模式(已弃用)
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
Python 区分二进制和文本I/O。以二进制模式打开的文件(包括 mode 参数中的 'b' )返回的内容为 bytes 对象,不进行任何解码。在文本模式下(默认情况下,或者在 mode 参数中包含 't' )时,文件内容返回为 str ,首先使用指定的 encoding (如果给定)或者使用平台默认的的字节编码解码。
buffering 是用于设置缓冲策略的可选整数。规则有:
缓冲是用于设置缓冲策略的可选整数。规则有:
- 传递 0 以关闭缓冲(仅在二进制模式下允许)
- 传递 1 以选择行缓冲(仅在文本模式下可用)
- 传递大于1的整数以指示固定大小块缓冲区的字节大小
- 如果取负值,寄存区的缓冲大小则为系统默认
如果未给出缓冲参数(使用默认的或者负值),默认缓冲策略的工作方式如下:
- 二进制文件缓冲在固定大小的块中; 缓冲区的大小使用启发式选择,试图确定底层设备的默认缓冲区块大小(block size)和 回溯到
io.DEFAULT_BUFFER_SIZE和回溯到io。默认缓冲区大小。在许多系统上,缓冲区的长度通常为4096或8192字节。 - “交互式”文本文件( satty() 返回 True的文件)使用行缓冲。其他文本文件使用上述策略用于二进制文件。
errors 是一个可选的字符串参数,用于指定如何处理编码和解码错误 - 这不能在二进制模式下使用。可以使用各种标准错误处理程序(列在 错误处理方案 ),但是使用 codecs.register_error() 注册的任何错误处理名称也是有效的。标准名称包括:
- 如果存在编码错误,'strict' 会引发 ValueError 异常。 默认值 None 具有相同的效果。
- 'ignore' 忽略错误。请注意,忽略编码错误可能会导致数据丢失。
- 'replace' 会将替换标记(例如 '?' )插入有错误数据的地方。
- 'surrogateescape' 将把任何不正确的字节表示为
U+DC80至U+DCFF范围内的下方替代码位。 当在写入数据时使用 - surrogateescape 错误处理句柄时这些替代码位会被转回到相同的字节。 这适用于处理具有未知编码格式的文件。
- 只有在写入文件时才支持 'xmlcharrefreplace'。编码不支持的字符将替换为相应的XML字符引用
&#nnn;。 - 'backslashreplace' 用Python的反向转义序列替换格式错误的数据。
- 'namereplace' (也只在编写时支持)用
\N{...}转义序列替换不支持的字符。
newline 控制 universal newlines 模式如何生效(它仅适用于文本模式)。它可以是 None,'','\n','\r' 和 '\r\n'。它的工作原理:
- 从流中读取输入时,如果 newline 为 None,则启用通用换行模式。输入中的行可以以 '\n','\r' 或 '\r\n' 结尾,这些行被翻译成 '\n' 在返回呼叫者之前。如果它是 '',则启用通用换行模式,但行结尾将返回给调用者未翻译。如果它具有任何其他合法值,则输入行仅由给定字符串终止,并且行结尾将返回给未调用的调用者。
- 将输出写入流时,如果 newline 为 None,则写入的任何 '\n' 字符都将转换为系统默认行分隔符 os.linesep。如果 newline 是 '' 或 '\n',则不进行翻译。如果 newline 是任何其他合法值,则写入的任何 '\n' 字符将被转换为给定的字符串。
file对象
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "w")
print "文件名: ", fo.name
print "是否已关闭 : ", fo.closed
print "访问模式 : ", fo.mode
print "末尾是否强制加空格 : ", fo.softspace‘’’
文件名: foo.txt
是否已关闭 : False
访问模式 : w
末尾是否强制加空格 : 0
’’’常见的 file 对象方法:
f.read([size]):size 未指定则返回整个文件,如果文件大小 >2 倍内存则有问题,f.read()读到文件尾时返回""(空字串)。f.readline():返回一行。f.readlines([size]):返回包含size行的列表, size 未指定则返回全部行。for line in f: print line:通过迭代器访问。f.write("hello\n"):如果要写入字符串以外的数据,先将他转换为字符串。f.tell():返回一个整数,表示当前文件指针的位置(就是到文件头的字节数)。f.seek(偏移量,[起始位置]):用来移动文件指针。- 偏移量: 单位为字节,可正可负
- 起始位置: 0 - 文件头, 默认值; 1 - 当前位置; 2 - 文件尾
f.close()关闭文件
file 对象常用的函数:
| 函数 | 方法及描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() | 返回文件下一行。 |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 "\n" 字符。 |
| file.readlines(sizeint]) | 读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。 |
| file.seek(offset[,whence]) | 设置文件当前位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 截取文件,截取的字节通过size指定,默认为当前文件位置。 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
close()
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "w")
print "文件名: ", fo.name# 关闭打开的文件
fo.close()‘''
文件名: foo.txt
‘''write()
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
fileObject.write(string)
在这里,被传递的参数是要写入到已打开文件的内容。
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "w")
fo.write( “I love Python!\nVery good!\n")# 关闭打开的文件
fo.close()‘’'
$ cat foo.txt
I love Python!
Very good!
‘''writelines()
方法用于向文件中写入一序列的字符串。
换行需要制定换行符 \n。
# 打开文件
fo = open("test.txt", "w")
print "文件名为: ", fo.name
seq = ["Python实用教程 1\n", "Python实用教程 2"]
fo.writelines( seq )# 关闭文件
fo.close()read()
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str
# 关闭打开的文件
fo.close()‘’'
读取的字符串是 : I love Pyt
‘''readline()和readlines()
readline() 函数用于读取文件中的一行,包含最后的换行符“\n”。此函数的基本语法格式为:
file.readline([size])
其中,file 为打开的文件对象;size 为可选参数,用于指定读取每一行时,一次最多读取的字符(字节)数。
‘’‘
假设文件的内容是
Python实用教程
https://blog.csdn.net/spiritx/article/details/132154074
’’’f = open("my_file.txt")
读取一行数据
byt = f.readline()
print(byt)‘’’
Python实用教程’’’
由于 readline() 函数在读取文件中一行的内容时,会读取最后的换行符“\n”,再加上 print() 函数输出内容时默认会换行,所以输出结果中会看到多出了一个空行。
不仅如此,在逐行读取时,还可以限制最多可以读取的字符(字节)数,例如:
#以二进制形式打开指定文件
f = open("my_file.txt",'rb')
byt = f.readline(6)
print(byt)‘’’
b’Python'
’‘’和上一个例子的输出结果相比,由于这里没有完整读取一行的数据,因此不会读取到换行符。
readlines() 函数用于读取文件中的所有行,它和调用不指定 size 参数的 read() 函数类似,只不过该函数返回是一个字符串列表,其中每个元素为文件中的一行内容。
f = open("my_file.txt",'r')
byt = f.readlines()
print(byt)‘’‘
Python实用教程
https://blog.csdn.net/spiritx/article/details/132154074
’’’next()
文件使用迭代器时会使用到,在循环中,next()方法会在每次循环中调用,该方法返回文件的下一行,如果到达结尾(EOF),则触发 StopIteration
# 打开文件
fo = open(“foo.txt", "r+")
print "文件名为: ", fo.namefor index in range(5):line = fo.next()print "第 %d 行 - %s" % (index, line)# 关闭文件
fo.close()tell()和seek()
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
就用我们上面创建的文件foo.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "读取的字符串是 : ", str# 查找当前位置
position = fo.tell()
print "当前文件位置 : ", position# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print "重新读取字符串 : ", str
# 关闭打开的文件
fo.close()’’’
读取的字符串是 : I love Pyt
当前文件位置 : 10
重新读取字符串 : I love Pyt
‘''使用with语句打开文件
Python引入了with语句来自动帮我们调用close()方法。
with open() as写文件:
with open('test.txt','w') as f:f.write('Hello, python!')with open() as 读文件:
with open('example.txt', 'r') as file:content = file.read()print(content)
使用with语句可以打开文件,并在文件使用完毕后自动关闭文件。这种方式可以避免因为程序异常退出而导致文件没有关闭的问题,从而保证文件的安全性和可靠性。
os库中的文件目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。
常见方法列表
| 方法 | 方法及描述 |
|---|---|
| os.access(path,mode) | 检验权限模式 |
| os.chdir(path) | 改变当前工作目录 |
| os.chflags(path,flags) | 设置路径的标记为数字标记。 |
| os.chmod(path,mode) | 更改权限 |
| os.chown(path,uid,gid) | 更改文件所有者 |
| os.chroot(path) | 改变当前进程的根目录 |
| os.close(fd) | 关闭文件描述符 fd |
| os.closerange(fd_low,fd_high) | 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| os.dup(fd) | 复制文件描述符 fd |
| os.dup2(fd,fd2) | 将一个文件描述符 fd 复制到另一个 fd2 |
| os.fchdir(fd) | 通过文件描述符改变当前工作目录 |
| os.fchmod(fd,mode) | 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。 |
| os.fchown(fd,uid,gid) | 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。 |
| os.fdatasync(fd) | 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。 |
| os.fdopen(fd[,mode[,bufsize]]) | 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| os.fpathconf(fd,name) | 返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| os.fstat(fd) | 返回文件描述符fd的状态,像stat()。 |
| os.fstatvfs(fd) | 返回包含文件描述符fd的文件的文件系统的信息,像 statvfs() |
| os.fsync(fd) | 强制将文件描述符为fd的文件写入硬盘。 |
| os.ftruncate(fd,length) | 裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。 |
| os.getcwd() | 返回当前工作目录 |
| os.getcwdu() | 返回一个当前工作目录的Unicode对象 |
| os.getenv() | 读取环境变量 |
| os.getlogin() | 返回进程的控制终端上登录的用户的名称。 |
| os.putenv() | 设置环境变量 |
| os.isatty(fd) | 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。 |
| os.lchflags(path,flags) | 设置路径的标记为数字标记,类似 chflags(),但是没有软链接 |
| os.lchmod(path,mode) | 修改连接文件权限 |
| os.lchown(path,uid,gid) | 更改文件所有者,类似 chown,但是不追踪链接。 |
| os.link(src,dst) | 创建硬链接,名为参数 dst,指向参数 src |
| os.listdir(path) | 返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| os.lseek(fd,pos,how) | 设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效 |
| os.lstat(path) | 像stat(),但是没有软链接 |
| os.major(device) | 从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。 |
| os.makedev(major,minor) | 以major和minor设备号组成一个原始设备号 |
| os.mkedirs(path[,mode]) | 递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。 |
| os.minor(device) | 从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。 |
| os.mkdir(path[,mode]) | 以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。 |
| os.mkfifo(path[,mode]) | 创建命名管道,mode 为数字,默认为 0666 (八进制) |
| os.mknod(filename[,mode=0600,device]) | 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。 |
| os.open(file,flags[,mode]) | 打开一个文件,并且设置需要的打开选项,mode参数是可选的 |
| os.openpty() | 打开一个新的伪终端对。返回 pty 和 tty的文件描述符。 |
| os.pathconf(path,name) | 返回相关文件的系统配置信息。 |
| os.pipe() | 创建一个管道. 返回一对文件描述符(r, w) 分别为读和写 |
| os.popen(command[,mode[,bufsize]]) | 从一个 command 打开一个管道 |
| os.read(fd,n) | 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。 |
| os.readlink(path) | 返回软链接所指向的文件 |
| os.remove(path) | 删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。 |
| os.removedirs(path) | 递归删除目录。 |
| os.rename(src,dst) | 重命名文件或目录,从 src 到 dst |
| os.renames(old,new) | 递归地对目录进行更名,也可以对文件进行更名。 |
| os.rmdir(path) | 删除path指定的空目录,如果目录非空,则抛出一个OSError异常。 |
| os.stat(path) | 获取path指定的路径的信息,功能等同于C API中的stat()系统调用。 |
| os.stat_float_times([newvalue]) | 决定stat_result是否以float对象显示时间戳 |
| os.statvfs(path) | 获取指定路径的文件系统统计信息 |
| os.symlink(src,dst) | 创建一个软链接 |
| os.system() | 运行shell命令 |
| os.exit() | 终止当前进程 |
| os.tcgetgrp(fd) | 返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组 |
| os.tcsetpgrp(fd,pg) | 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。 |
| os.tempnam([dir[,prefix]]) | 返回唯一的路径名用于创建临时文件。 |
| os.tmpfile() | 返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。 |
| os.tmpnam() | 为创建一个临时文件返回一个唯一的路径 |
| os.ttyname(fd) | 返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。 |
| os.unlink(path) | 删除文件 |
| os.utime(path,times) | 返回指定的path文件的访问和修改的时间。 |
| os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]]) | 输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| os.write(fd,str) | 写入字符串到文件描述符 fd中. 返回实际写入的字符串长度 |
| os.path | 获取文件的属性信息。 |
os.sep:取代操作系统特定的路径分隔符os.name:指示你正在使用的工作平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。os.linesep:给出当前平台的行终止符。例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'os.curdir:返回当前目录('.')
os.path
| 方法 | 说明 |
|---|---|
| os.path.abspath(path) | 返回绝对路径 |
| os.path.basename(path) | 返回文件名 |
| os.path.commonprefix(list) | 返回list(多个路径)中,所有path共有的最长的路径 |
| os.path.dirname(path) | 返回文件路径 |
| os.path.exists(path) | 如果路径 path 存在,返回 True;如果路径 path 不存在或损坏,返回 False。 |
| os.path.lexists(path) | 路径存在则返回 True,路径损坏也返回 True |
| os.path.expanduser(path) | 把 path 中包含的 ~ 和 ~user 转换成用户目录 |
| os.path.expandvars(path) | 根据环境变量的值替换 path 中包含的 $name 和 ${name} |
| os.path.getatime(path) | 返回最近访问时间(浮点型秒数) |
| os.path.getmtime(path) | 返回最近文件修改时间 |
| os.path.getctime(path) | 返回文件 path 创建时间 |
| os.path.getsize(path) | 返回文件大小,如果文件不存在就返回错误 |
| os.path.isabs(path) | 判断是否为绝对路径 |
| os.path.isfile(path) | 判断路径是否为文件 |
| os.path.isdir(path) | 判断路径是否为目录 |
| os.path.islink(path) | 判断路径是否为链接 |
| os.path.ismount(path) | 判断路径是否为挂载点 |
| os.path.join(path1[, path2[, ...]]) | 把目录和文件名合成一个路径 |
| os.path.normcase(path) | 转换path的大小写和斜杠 |
| os.path.normpath(path) | 规范path字符串形式 |
| os.path.realpath(path) | 返回path的真实路径 |
| os.path.relpath(path[, start]) | 从start开始计算相对路径 |
| os.path.samefile(path1, path2) | 判断目录或文件是否相同 |
| os.path.sameopenfile(fp1, fp2) | 判断fp1和fp2是否指向同一文件 |
| os.path.samestat(stat1, stat2) | 判断stat tuple stat1和stat2是否指向同一个文件 |
| os.path.split(path) | 把路径分割成 dirname 和 basename,返回一个元组 |
| os.path.splitdrive(path) | 一般用在 windows 下,返回驱动器名和路径组成的元组 |
| os.path.splitext(path) | 分割路径,返回路径名和文件扩展名的元组 |
| os.path.splitunc(path) | 把路径分割为加载点与文件 |
| os.path.walk(path, visit, arg) | 遍历path,进入每个目录都调用visit函数,visit函数必须有3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有文件名,args则为walk的第三个参数 |
| os.path.supports_unicode_filenames | 设置是否支持unicode路径名 |
os.path.abspath(path) # 返回绝对路径
os.path.abspath(__file__) # 得到当前文件的绝对路径os.path.dirname(path) # 返回文件路径
os.path.dirname(__file__) # 得到当前文件所在目录os.path.join(path1,path2) # 把目录和文件名合成一个路径
os.path.join('/test/','tttttttt.txt')os.path.exists('eeeee.txt') # 判断当前路径是否存在# 判断是否是目录
print(os.path.isdir("test”))# 判断是否是文件
print(os.path.isfile("a.txt”))# 返回文件访问时间戳
print(os.path.getatime("a.txt”))# 拼接路径
print(os.path.join("/tmp","a.txt")) # 返回结果就是/tmp/a.txt# 分隔路径
print(os.path.split("/tmp/a.txt”)) # 返回结果是一个元组两个元素,('/tmp', 'a.txt’)# 分隔后缀
print(os.path.splitext("a.txt”)) # 返回结果是一个元组两个元素,('a', '.txt')import os # 获取文件路径
file_path = "/Users/username/Documents/test.txt"
dir_path = os.path.dirname(file_path) print("文件路径为:", file_path)
print("文件所在目录为:", dir_path) ‘’’
文件路径为: /Users/username/Documents/test.txt
文件所在目录为: /Users/username/Documents
’’’file_path = "/Users/username/Documents/test.txt"
file_name = os.path.basename(file_path) print("文件路径为:", file_path)
print("文件名为:", file_name) ‘’’
文件路径为: /Users/username/Documents/test.txt
文件名为: test.txt
’’’# 获取文件扩展名
file_path = "/Users/username/Documents/test.txt"
file_ext = os.path.splitext(file_path)[1] print("文件路径为:", file_path)
print("文件扩展名为:", file_ext)
‘’’
文件路径为: /Users/username/Documents/test.txt
文件扩展名为: .txt
’‘’os.path.getmtime(path):文件或文件夹的最后修改时间,从新纪元到访问时的秒数。os.path.getatime(path):文件或文件夹的最后访问时间,从新纪元到访问时的秒数。os.path.getctime(path):文件或文件夹的创建时间,从新纪元到访问时的秒数。
>>> os.path.getmtime('D:\\pythontest\\ostest\\hello.py')
1481695651.857048
>>> os.path.getatime('D:\\pythontest\\ostest\\hello.py')
1481687717.8506615
>>> os.path.getctime('D:\\pythontest\\ostest\\hello.py')
1481687717.8506615os.path.getsize(path):文件或文件夹的大小,若是文件夹返回0。
>>> os.path.getsize('D:\\pythontest\\ostest\\hello.py')
58L
>>> os.path.getsize('D:\\pythontest\\ostest')
0Los.path.exists(path):文件或文件夹是否存在,返回True 或 False。
>>> os.listdir(os.getcwd())
['hello.py', 'test.txt']
>>> os.path.exists('D:\\pythontest\\ostest\\hello.py')
True
>>> os.path.exists('D:\\pythontest\\ostest\\Hello.py')
True
>>> os.path.exists('D:\\pythontest\\ostest\\Hello1.py')
False重点方法详细说明
rename()
rename() 方法需要两个参数,当前的文件名和新文件名。
语法:
os.rename(current_file_name, new_file_name)
例子:
下例将重命名一个已经存在的文件test1.txt。
import os# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )remove()
可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
语法:
os.remove(file_name)
例子:
下例将删除一个已经存在的文件test2.txt。
import os# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")mkdir()
语法:
os.mkdir("newdir")
例子:
下例将在当前目录下创建一个新目录test。
import os# 创建目录test
os.mkdir("test")rmdir()
删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir('dirname')
例子:
以下是删除" /tmp/test"目录的例子。目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
import os# 删除”/tmp/test”目录
os.rmdir( "/tmp/test" )makedirs()
可生成多层递归目录
getcwd()和chdir()
使用os.getcwd()函数来获取当前工作目录。当前工作目录是指Python程序当前所在的目录。
使用os.chdir()函数来改变当前工作目录。
import os # 获取当前工作目录
current_dir = os.getcwd()
print("当前工作目录为:", current_dir) # 改变当前工作目录
os.chdir("/Users/username/Documents")
new_dir = os.getcwd()
print("新的工作目录为:", new_dir) ‘’’
当前工作目录为: /Users/username/Desktop
新的工作目录为: /Users/username/Documents
’‘’listdir()
os.listdir(path):将路径下所有文件存到list中
>>> import os
>>> os.getcwd()
'D:\\pythontest\\ostest'
>>> os.listdir(os.getcwd())
['hello.py', 'test.txt']chflags()
用于设置路径的标记为数字标记
语法格式如下:
os.chflags(path, flags)
参数:
-
path -- 文件名路径或目录路径。
-
flags -- 可以是以下值:
- stat.UF_NODUMP: 非转储文件
- stat.UF_IMMUTABLE: 文件是只读的
- stat.UF_APPEND: 文件只能追加内容
- stat.UF_NOUNLINK: 文件不可删除
- stat.UF_OPAQUE: 目录不透明,需要通过联合堆栈查看
- stat.SF_ARCHIVED: 可存档文件(超级用户可设)
- stat.SF_IMMUTABLE: 文件是只读的(超级用户可设)
- stat.SF_APPEND: 文件只能追加内容(超级用户可设)
- stat.SF_NOUNLINK: 文件不可删除(超级用户可设)
- stat.SF_SNAPSHOT: 快照文件(超级用户可设)
该方法没有返回值。
import os,statpath = "/tmp/foo.txt"# 为文件设置标记,使得它不能被重命名和删除
flags = stat.SF_NOUNLINK
retval = os.chflags( path, flags)
print "返回值: %s" % retvalchmod()
用于更改文件或目录的权限。
语法格式如下:
os.chmod(path, mode)
参数:
-
path -- 文件名路径或目录路径。
-
flags -- 可用以下选项按位或操作生成, 目录的读权限表示可以获取目录里文件名列表, ,执行权限表示可以把工作目录切换到此目录 ,删除添加目录里的文件必须同时有写和执行权限 ,文件权限以用户id->组id->其它顺序检验,最先匹配的允许或禁止权限被应用。
- stat.S_IXOTH: 其他用户有执行权0o001
- stat.S_IWOTH: 其他用户有写权限0o002
- stat.S_IROTH: 其他用户有读权限0o004
- stat.S_IRWXO: 其他用户有全部权限(权限掩码)0o007
- stat.S_IXGRP: 组用户有执行权限0o010
- stat.S_IWGRP: 组用户有写权限0o020
- stat.S_IRGRP: 组用户有读权限0o040
- stat.S_IRWXG: 组用户有全部权限(权限掩码)0o070
- stat.S_IXUSR: 拥有者具有执行权限0o100
- stat.S_IWUSR: 拥有者具有写权限0o200
- stat.S_IRUSR: 拥有者具有读权限0o400
- stat.S_IRWXU: 拥有者有全部权限(权限掩码)0o700
- stat.S_ISVTX: 目录里文件目录只有拥有者才可删除更改0o1000
- stat.S_ISGID: 执行此文件其进程有效组为文件所在组0o2000
- stat.S_ISUID: 执行此文件其进程有效用户为文件所有者0o4000
- stat.S_IREAD: windows下设为只读
- stat.S_IWRITE: windows下取消只读
该方法没有返回值。
import os, sys, stat# 假定 /tmp/foo.txt 文件存在,设置文件可以通过用户组执行os.chmod("/tmp/foo.txt", stat.S_IXGRP)# 设置文件可以被其他用户写入
os.chmod("/tmp/foo.txt", stat.S_IWOTH)print "修改成功!!"fstat()和stat()
返回文件描述符fd的状态,类似 stat()。
语法格式如下:
os.fstat(fd)
返回文件描述符fd的状态。
fstat 方法返回的结构:
-
st_dev: 设备信息
-
st_ino: 文件的i-node值
-
st_mode: 文件信息的掩码,包含了文件的权限信息,文件的类型信息(是普通文件还是管道文件,或者是其他的文件类型)
-
st_nlink: 硬连接数
-
st_uid: 用户ID
-
st_gid: 用户组 ID
-
st_rdev: 设备 ID (如果指定文件)
-
st_size: 文件大小,以byte为单位
-
st_blksize: 系统 I/O 块大小
-
st_blocks: 文件的是由多少个 512 byte 的块构成的
-
st_atime: 文件最近的访问时间
-
st_mtime: 文件最近的修改时间
-
st_ctime: 文件状态信息的修改时间(不是文件内容的修改时间)
import os, sys# 打开文件
fd = os.open( "foo.txt", os.O_RDWR|os.O_CREAT )# 获取元组
info = os.fstat(fd)print "文件信息 :", info# 获取文件 uid
print "文件 UID :%d" % info.st_uid# 获取文件 gid
print "文件 GID :%d" % info.st_gid# 关闭文件
os.close( fd)‘''
文件信息 : (33261, 3753776L, 103L, 1, 0, 0, 102L, 1238783197, 1238786767, 1238786767)
文件 UID :0
文件 GID :0
‘''walk()
一个遍历目录数的函数,它以一种深度优先的策略(depth-first)访问指定的目录。
os.walk(top=path,topdown=True,oneerror=None)
- 参数 top 表示需要遍历的目录树的路径。
- 参数 topdown 默认为 True ,表示首先返回根目录树下的文件,然后,再遍历目录树的子目录。 当topdown 的值为 False 时,则表示先遍历目录树的子目录,返回子目录下的文件,最后返回根目录下的文件。
- 参数 oneerror 的默认值为 None ,表示忽略文件遍历时产生的错误;如果不为空,则提供一个自定义函数提示错误信息,后边遍历抛出异常。
os.walk() 函数的返回值是一个生成器(generator),每次遍历的对象都是返回的是一个三元组 (root,dirs,files):该元组有3个元素,这3个元素分别表示每次遍历的路径名,目录列表和文件列表。
- root 代表当前遍历的目录路径,string类型。
- dirs 代表root路径下的所有子目录名称;list类型,列表中的每个元素是string类型,代表子目录名称。
- files 代表root路径下的所有子文件名称;list类型,列表中的每个元素是string类型,代表子文件名称。
‘’'
/home/root/1.txt2.txt3.txt/zhang/zhang_1.mp4zhang_2.mp4zhang_3.mp4/litest.txthai.mp4
‘’'import os
from os.path import joinhome_path = "/home"for (root, dirs, files) in os.walk(home_path):print(root)print(dirs)print(files)print("=" * 50)‘’'
/home
['root', 'zhang', 'li']
['test.txt', 'hai.mp4']
==================================================
/home/root
[]
['1.txt', '2.txt', '3.txt']
==================================================
/hoome/zhang
[]
['zhang_1.mp4', 'zhang_2.mp4', 'zhang_3.mp4']
==================================================
/home/li
[]
[]
==================================================
‘’'
一共三行:
第1行代表当前遍历的目录,我们称为root目录,
第2行代表root目录下的子目录列表,我们称为dirs子目录列表,
第3行代表root目录下的子文件列表,我们称为files子文件列表,
注意:上面的列表为空就代表当前遍历的root目录下没有子目录或者没有子文件。
遍历home目录下获取所有的目录和文件的绝对路径
import os
from os.path import joinhome_path = "/home"for (root, dirs, files) in os.walk(home_path):for dir in dirs:print(join(root, dir))for file in files:print(join(root, file))‘’'
/home
/home/root
/home/zhang
/home/li
/home/test.txt
/home/hai.mp4
/home/root/1.txt
/home/root/2.txt
/home/root/3.txt
/home/zhang/zhang_1.mp4
/home/zhang/zhang_2.mp4
/home/zhang/zhang_3.mp4
‘''import osdef walk(path):if not os.path.exists(path):return -1for root,dirs,names in os.walk(path):for filename in names:print(os.path.join(root,filename)) # 路径和文件名连接构成完整路径if __name__=='__main__':path = "C:\\Users\\Administrator\\Desktop\\2017-9-1"walk(path)‘’'
C:\Users\Administrator\Desktop\2017-9-1\2017-9-1.txt
C:\Users\Administrator\Desktop\2017-9-1\2017-9-1storage.txt
C:\Users\Administrator\Desktop\2017-9-1\apk.conf
C:\Users\Administrator\Desktop\2017-9-1\数据采集导入质量统计_2017-09-01.docx
C:\Users\Administrator\Desktop\2017-9-1\test1\2017-9-1.txt
C:\Users\Administrator\Desktop\2017-9-1\test2\2017-9-1.txt
‘''system()
运行shell命令
eg:执行ls -a > 1.txt命令
import osos.system(‘ls -a > 1.txt’)popen()
是 Python 中用于执行一个 shell 命令并获取输出结果的方法。它返回一个 file-like object,可以像文件一样进行读取操作。下面是一个使用 os.popen 的例子:
import os# 执行 shell 命令并获取输出结果
output = os.popen("ls -l").read()# 打印输出结果
print(output)上面的例子执行了 ls -l 命令,并将结果存储在 output 变量中。然后使用 print 函数将结果打印出来。
语法格式如下:
os.popen(command[, mode[, bufsize]])
参数:
- command -- 使用的命令。
- mode -- 模式权限可以是 'r'(默认) 或 'w'。
- bufsize -- 指明了文件需要的缓冲大小:0意味着无缓冲;1意味着行缓冲;其它正值表示使用参数大小的缓冲(大概值,以字节为单位)。负的bufsize意味着使用系统的默认值,一般来说,对于tty设备,它是行缓冲;对于其它文件,它是全缓冲。如果没有改参数,使用系统的默认值。
返回一个文件描述符号为fd的打开的文件对象
os.environ
os.environ 是一个用于获取和设置操作系统环境变量的模块。
import os# 获取全部环境变量
env_variables = os.environ
print(env_variables)# 获取指定环境变量的值
python_path = os.environ.get('PYTHONPATH')
print(python_path)# 修改环境变量的值
os.environ['MY_VARIABLE'] = 'my_value'os.name
导入的依赖特定操作系统的模块的名称,返回’posix’表示Linux,'nt’表示Windows,'java’表示Java虚拟机
import osname = os.name
if name == 'posix':print ("this is Linux or Unix")
elif name == 'nt':print ("this is windows")
else:print ("this is other system")os的一些表现形式参数
os中定义了一组文件、路径在不同操作系统中的表现形式参数,如:
>>> os.sep
'\\'
>>> os.extsep
'.'
>>> os.pathsep
';'
>>> os.linesep
'\r\n'相关文章:

Python 基本文件操作及os库
内置函数文件操作 python内置函数提供了简单的文件操作支持。 open() open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。 语法为: open(file,moder,buffering-1,encodingNone,errorsNone,newlineNone,closefdT…...

YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
前言:Hello大家好,我是小哥谈。ShuffleNetV2 是一种轻量级的神经网络架构,适用于移动设备和嵌入式设备等资源受限的场景,旨在在计算资源有限的设备上提供高效的计算和推理能力,它通过引入通道重排操作和逐点组卷积来减…...
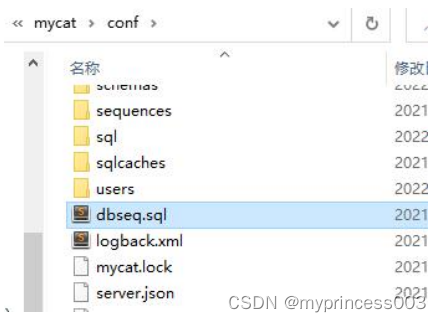
三、mycat分库分表
第五章 分库分表 一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业 务将表进行分类,分布到不同 的数据库上面,这样也就将数据或者说压力分担到不同 的库上面,如下图: 系统被切分成了&…...
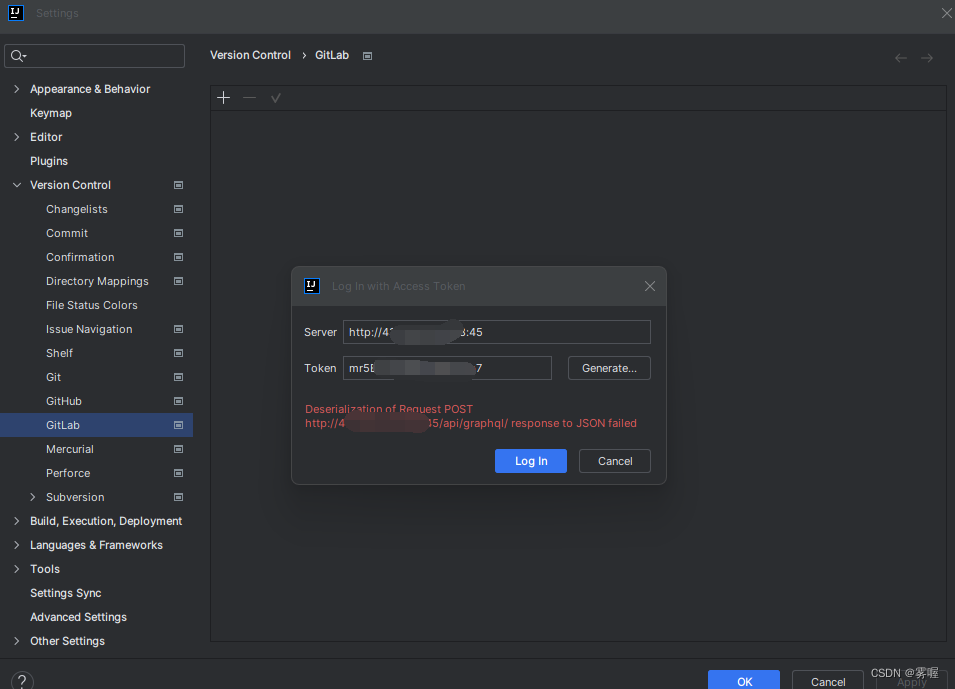
gitlab提交项目Log in with Access Token错误
目录 报错信息 问题描述 解决方案 报错信息 问题描述 在提交项目到gitlab时,需要添加账户信息 ,但是报了这样一个错,原因应该就是路径问题,我在填写server地址的时候,就出现了路径问题,我把多余的几个/…...

openGauss学习笔记-56 openGauss 高级特性-DCF
文章目录 openGauss学习笔记-56 openGauss 高级特性-DCF56.1 架构介绍56.2 功能介绍56.3 使用示例 openGauss学习笔记-56 openGauss 高级特性-DCF DCF全称是Distributed Consensus Framework,即分布式一致性共识框架。DCF实现了Paxos、Raft等解决分布式一致性问题典…...

Xcode 14 pod init报错
文章目录 1.报错2.解决方法(本人亲测有效) 1.报错 [!] Oh no, an error occurred. Search for existing GitHub issues similar to yours: https://github.com/CocoaPods/CocoaPods/search?q%5BXcodeproj%5DUnknownobjectversion%2856%29.&typeIs…...
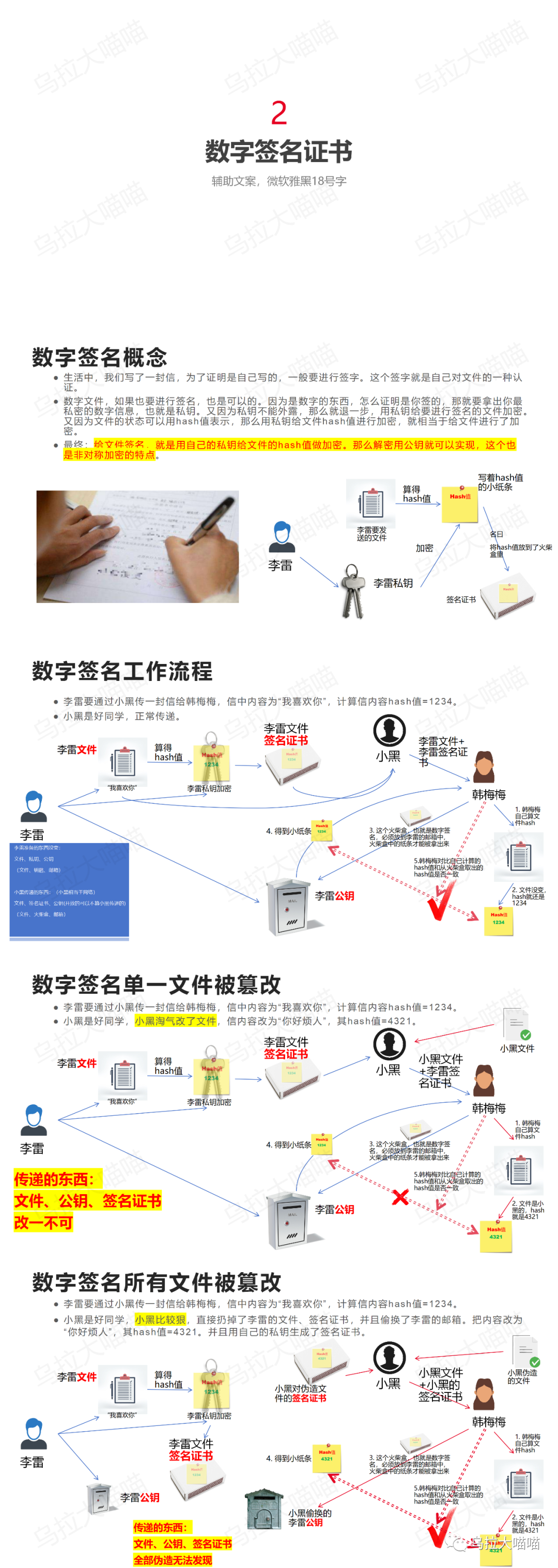
飞腾PSPA可信启动--2 数字签名证书
今天继续第二章,数字签名证书的介绍。 此章节录制了讲解视频,可以在B站进行观看:...

微前端:重塑大型项目的前沿技术
引言 随着互联网技术的飞速发展,前端开发已经从简单的页面制作逐渐转变为复杂的应用开发。在这个过程中,传统的前端开发模式已经难以满足大型项目的需求。微前端作为一种新的前端架构模式,应运而生,它旨在解决大型项目中的前端开…...
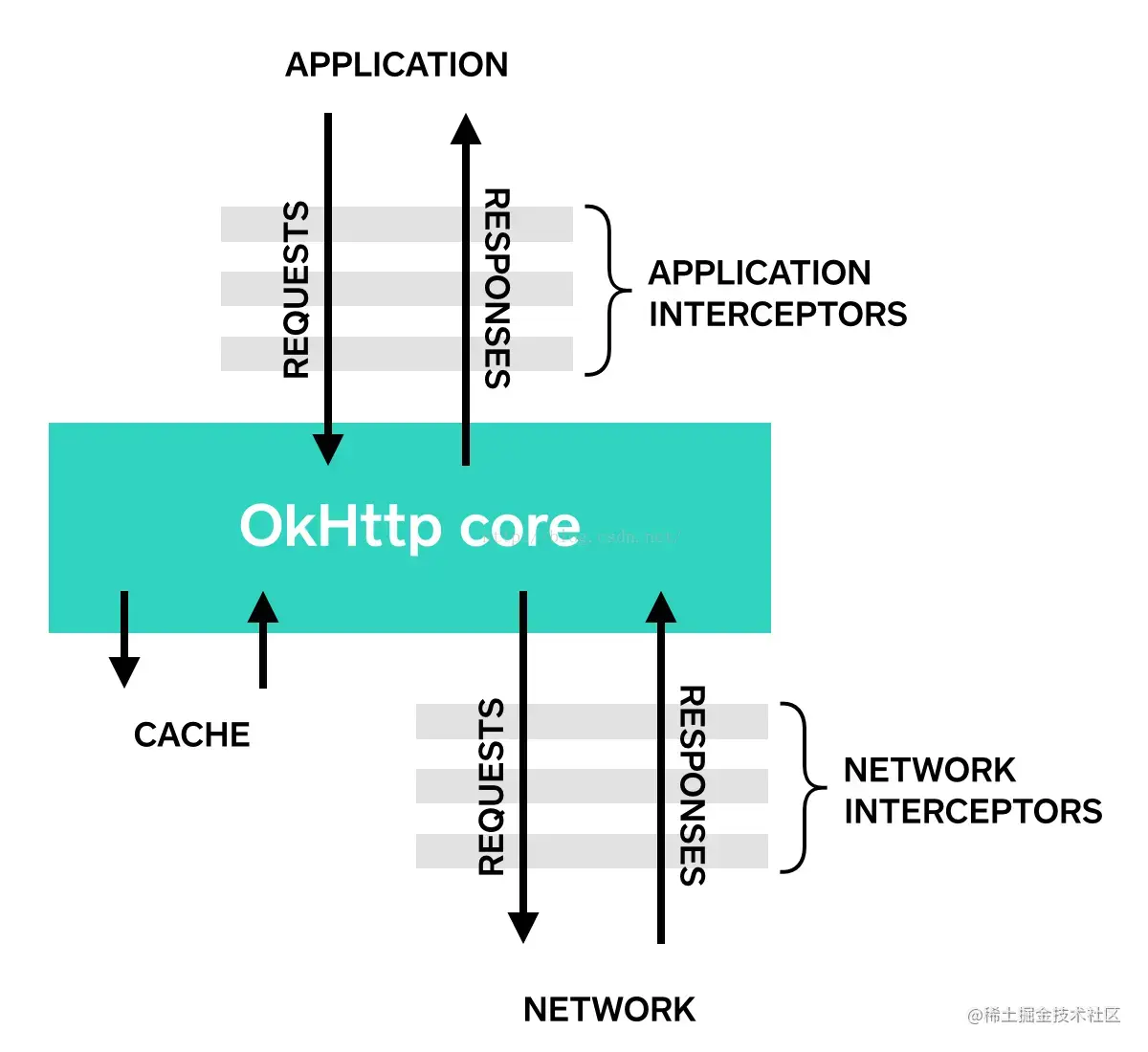
官方推荐使用的OkHttp4网络请求库全面解析(Android篇)
作者:cofbro 前言 现在谈起网络请求,大家肯定下意识想到的就是 okhttp 或者 retrofit 这样的三方请求库。诚然,现在有越来越多的三方库帮助着我们快速开发,但是对于现在的程序员来说,我们不仅要学会如何去用ÿ…...

Spooling的原理
脱机技术 程序猿先用纸带机把自己的程序数据输入到磁带中,这个输入的过程是由一台专门的外围控制机实现的。之后CPU直接从快速的磁带中读取想要的这些输入数据。输出也类似。 假脱机技术(Spooling技术) 即用软件的方式来模拟脱机技术。要…...

Homebrew 无法安装过时的PHP版本
使用brew安装过时的PHP版本时,提示“Error: php7.4 has been disabled because it is a versioned formula!”错误。 因为过时的PHP版本官方已经不再维护,所以Hombrew将该PHP版本移出了repository,所以安装不了。 解决方案 # 1. 添加tap fo…...
python爬取bilibili,下载视频
一. 内容简介 python爬取bilibili,下载视频 二. 软件环境 2.1vsCode 2.2Anaconda version: conda 22.9.0 2.3代码 链接:https://pan.baidu.com/s/1WuXTso_iltLlnrLffi1kYQ?pwd1234 三.主要流程 3.1 下载单个视频 代码 import requests impor…...
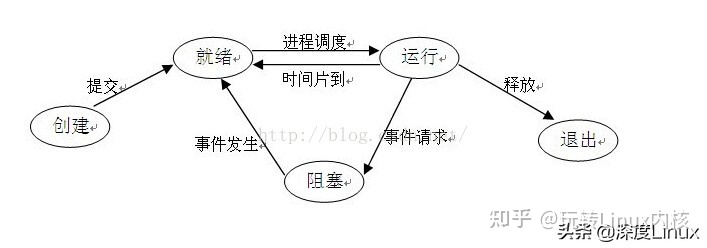
java八股文面试[多线程]——进程与线程的区别
定义 1、进程:进程是一个具有独立功能的程序关于某个数据集合的以此运行活动。 是系统进行资源分配和调度的独立单位,也是基本的执行单元。是一个动态的概念,是一个活动的实体。它不只是程序的代码,还包括当前的活动。 进程结构…...

SpringBootWeb 登录认证[Cookie + Session + Token + Filter + Interceptor]
目录 1. 登录功能 1.1 需求 1.2 接口文档 1.3 登录 - 思路分析 1.4 功能开发 1.5 测试 2. 登录校验 2.1 问题分析 什么是登录校验? 我们要完成以上登录校验的操作,会涉及到Web开发中的两个技术: 2.2 会话技术 2.2.1 会话技术介绍…...
d3dcompiler_43.dll丢失怎么修复,分享几种修复d3dcompiler_43.dll的方法
不少人可能看到d3dcompiler_43.dll这个文件会感觉到陌生,是的,因为这个文件一般来说是很少丢失的,但是还是会出现d3dcompiler_43.dll丢失的情况的,今天主要是来给大家详细的说说d3dcompiler_43.dll丢失怎么修复的相关方法。 一.分…...
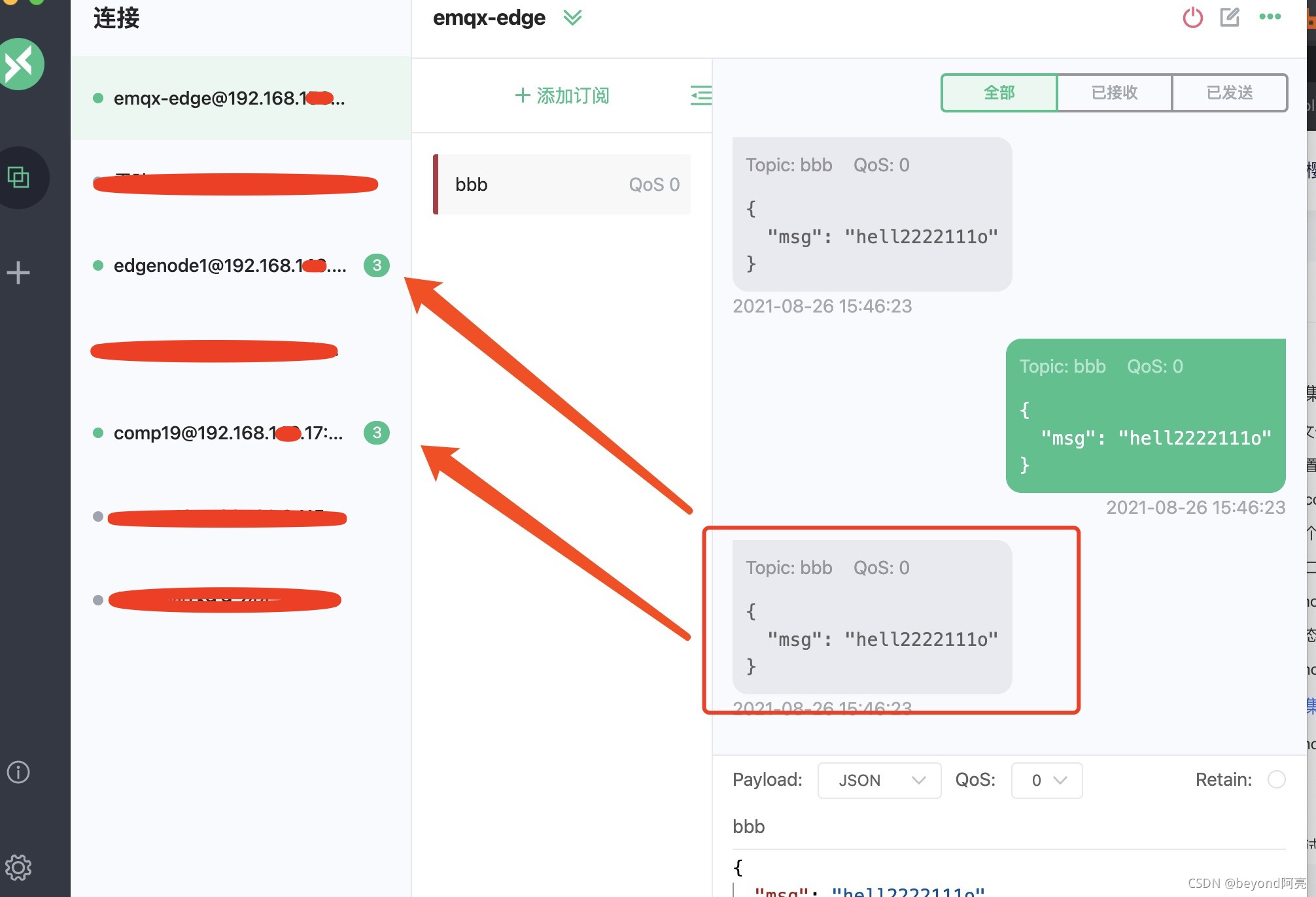
mqtt集群搭建并使用nginx做负载均衡_亲测得结论
mqtt集群搭建 RabbitMQ集群搭建和测试总结_亲测 搭建好RabbitMQ集群,并开启mqtt插件功能,mqtt集群也就搭建好了 nginx配置mqtt负载均衡 #修改rabbitmq1节点ip为1.19的nginx配置 vim /etc/nginx/nginx.confhttp { } #在http外添加如下配置 stream {upstream rabbitmqtt {ser…...
JavaScript—DOM(文档对象模型)
目录 DOM是什么? DOM有什么作用? 一、事件 理解事件 事件怎么写(要做什么就写什么)? 实战演练 1、页面加载完毕以后,打印一句话 2、如果有一个a标签,并给其添加一个点击事件 3、事件默…...

mysql Index
创建索引 方法1 create table 表( col1 int, col2 int, … index | key index_name (列名) 方法2 alter table 表名 ADD index alter table student_table add index index_name(stu_id); 方法3 create index index_name on 表名(列) 删除索引 方式1 alter table xx drop prima…...

八路参考文献:[八一新书]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022.
八路参考文献:[八一新书]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022....
Leetcode Top 100 Liked Questions(序号75~104)
75. Sort Colors 题意:红白蓝的颜色排序,使得相同的颜色放在一起,不要用排序 我的思路 哈希 代码 Runtime 4 ms Beats 28.23% Memory 8.3 MB Beats 9.95% class Solution { public:void sortColors(vector<int>& nums) {vector…...

从绿光到深紫外:手把手教你选对BBO、LBO、CLBO晶体,搞定激光倍频实验
从绿光到深紫外:非线性晶体选型与倍频实验实战指南 当实验室的1064nm激光器发出那束熟悉的近红外光时,许多研究者脑海中会立刻浮现两个问题:如何高效获得532nm的翠绿光束?又该如何进一步压缩波长至266nm的深紫外区域?…...

终极Unity资产提取指南:5分钟掌握AssetRipper专业工作流
终极Unity资产提取指南:5分钟掌握AssetRipper专业工作流 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper AssetRipper是业界…...

告别复制粘贴!手把手教你封装可复用的Echarts-for-weixin图表组件
微信小程序Echarts组件化实战:打造高复用图表解决方案 在数据驱动的产品设计中,图表可视化已成为微信小程序不可或缺的组成部分。面对多页面复用、动态数据更新等实际需求,直接使用原生ec-canvas组件往往会导致代码冗余和维护困难。本文将分享…...

地平线6正式上线!UU远程云电脑工作日也能全高画质飙车
《极限竞速:地平线6》5月18日正式全球发售!该作将舞台设在超燃的日本东京,从东京涩谷的霓虹璀璨,到秋名山的晨雾缭绕与漂移快感;从北海道的茫茫雪原越野,到富士山下的樱花赛道浪漫驰骋,每一处场景都细节拉满…...

从Java到AI大模型:小白程序员必备转型指南,收藏学习不迷路!
本文为传统Java开发者提供了从入门到精通AI大模型的四步转型路径。首先利用成熟AI接口,其次掌握Langchain和LlamaIndex开发工具,再次深入Agent机制设计自动化流程,最后搭建本地专属模型。作者结合自身经验,分享了实战项目和避坑指…...
方法顺序不确定性解析与解决方案)
Java反射getMethods()方法顺序不确定性解析与解决方案
1. 项目概述:一个看似简单却暗藏玄机的API行为如果你写过Java反射相关的代码,大概率用过Class.getMethods()这个方法。它的官方文档描述简洁明了:“返回一个包含 Method 对象的数组,这些对象反映了此 Class 对象表示的类或接口的所…...

模型越来越强,为什么真正拉开差距的却是向量引擎
模型越来越强,为什么真正拉开差距的却是向量引擎2026年的 AI 圈很吵。 但吵来吵去,核心其实只有一个问题。 模型更会说了。 为什么很多系统还是不好用。 答案往往不在模型参数里。 答案在入口、记忆、工具连接和上下文治理里。 你会发现一个很有意思的现…...
)
IT工程/项目计划概要~项目结束表(模版)
项目计划概要Ⅰ)项目启动(PROJECT INITIATION)1.EXCO(Executive Committee)审批2.已确认的意向书(Consent Letter)3.预风险评估4.合同(Contract)签署确认5.行业合规(Compliance)文档6.项目启动表7.项目章程签署确认Ⅱ)项目计划8.业…...

cimgui生成器完全解析:从Lua脚本到C接口的魔法转换 [特殊字符]
cimgui生成器完全解析:从Lua脚本到C接口的魔法转换 🎯 【免费下载链接】cimgui c-api for imgui (https://github.com/ocornut/imgui) Look at: https://github.com/cimgui for other widgets 项目地址: https://gitcode.com/gh_mirrors/ci/cimgui …...

NovelReader插件化扩展指南:如何添加新的翻页效果
NovelReader插件化扩展指南:如何添加新的翻页效果 【免费下载链接】NovelReader 仿照"任阅"的追书、看书的小说阅读器。重写"任阅"的代码,优化代码逻辑和代码结构,降低内存使用率。重写小说阅读器,支持网络阅…...