python爬取bilibili,下载视频
一. 内容简介
python爬取bilibili,下载视频
二. 软件环境
2.1vsCode
2.2Anaconda
version: conda 22.9.0
2.3代码
链接:https://pan.baidu.com/s/1WuXTso_iltLlnrLffi1kYQ?pwd=1234
三.主要流程
3.1 下载单个视频
代码
import requests
import os
from lxml import etree
import redef videoDownload1(url_):# 设置用户代理,cookieheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}# 发送请求,得到响应对象response_ = requests.get(url_, headers=headers_)str_data = response_.text # 视频主页的html代码,类型是字符串# 使用xpath解析html代码,,得到想要的urlhtml_obj = etree.HTML(str_data) # 转换格式类型# 获取视频的名称res_ = html_obj.xpath('//title/text()')[0]# 视频名称的获取title_ = re.findall(r'(.*?)_哔哩哔哩', res_)[0]# 影响视频合成的特殊字符的处理,目前就遇到过这三个,实际上很有可能不止这三个,遇到了就用同样的方法处理就好了title_ = title_.replace('/', '')title_ = title_.replace(' ', '')title_ = title_.replace('&', '')title_ = title_.replace(':', '')# 使用xpath语法获取数据,取到数据为列表,索引[0]取值取出里面的字符串,即包含视频音频文件的url字符串url_list_str = html_obj.xpath('//script[contains(text(),"window.__playinfo__")]/text()')[0]# 纯视频的urlvideo_url = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 纯音频的urlaudio_url = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 设置跳转字段的headersheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36','Referer': url_}# 获取纯视频的数据response_video = requests.get(video_url, headers=headers_, stream=True)bytes_video = response_video.content# 获取纯音频的数据response_audio = requests.get(audio_url, headers=headers_, stream=True)bytes_audio = response_audio.content# 获取文件大小, 单位为KBvideo_size = int(int(response_video.headers['content-length']) / 1024)audio_size = int(int(response_audio.headers['content-length']) / 1024)# 保存纯视频的文件title_1 = title_ + '!' # 名称进行修改,避免重名title_1 = title_1.replace(':', '_')with open(f'{title_1}.mp4', 'wb') as f:f.write(bytes_video)# print(f'{title_1}纯视频文件下载完毕...,大小为:{video_size}KB, {int(video_size/1024)}MB')with open(f'{title_1}.mp3', 'wb') as f:f.write(bytes_audio)# print(f'{title_1}纯音频文件下载完毕...,大小为:{audio_size}KB, {int(audio_size/1024)}MB')# 利用第三方工具ffmpeg 合成视频, 需要执行终端命令ffmpeg_path = r".\ffmpeg\bin\ffmpeg.exe"# os.system(f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy .\video\{title_}.mp4 -loglevel quiet')folder_path = f"./video/{title_}" # 替换为你想要创建的文件夹路径if not os.path.exists(folder_path):os.mkdir(folder_path)# print(f"The folder '{folder_path}' already exists.")command = f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy ./video/{title_}/{title_}.mp4 -loglevel quiet'os.system(command)# 显示合成文件的大小print(f'{title_} 下载完成')# 移除纯视频文件,os.remove(f'{title_1}.mp4')# 移除纯音频文件,os.remove(f'{title_1}.mp3')3.2 下载选集视频
选集视频的播放链接很好找,就是后面的p=几啥的,拼一下就可以拿到整个的播放链接了
代码
import requests
import os
from lxml import etree
import re# 获取网页源码
def getUrls2(url):# 发送请求,得到响应对象# 设置用户代理,cookieheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}response_ = requests.get(url, headers=headers)str_data = response_.text # 视频主页的html代码,类型是字符串# 使用xpath解析html代码,,得到想要的urlhtml_obj = etree.HTML(str_data) # 转换格式类型urls = []# 获取了li的数量,lis = html_obj.xpath("//ul[@class='list-box']/li")question_mark_index = url.find('?')# 如果找到了 '?',就截取该位置之前的子串if question_mark_index != -1:cleaned_url = url[:question_mark_index]else:cleaned_url = url# print(cleaned_url)# 拼接apifor i in range(1,len(lis)+1):# print(i)strs = cleaned_url + "?p=" + str(i)urls.append(strs)# print(content)return urls
import requests
import os
from lxml import etree
import redef videoDownload3(url_,i,name):# 设置用户代理,cookieheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}# 发送请求,得到响应对象response_ = requests.get(url_, headers=headers_)str_data = response_.text # 视频主页的html代码,类型是字符串# 使用xpath解析html代码,,得到想要的urlhtml_obj = etree.HTML(str_data) # 转换格式类型# 获取视频的名称res_ = html_obj.xpath('//title/text()')[0]# 视频名称的获取title_ = re.findall(r'(.*?)_哔哩哔哩', res_)[0]fileName = name# 影响视频合成的特殊字符的处理,目前就遇到过这三个,实际上很有可能不止这三个,遇到了就用同样的方法处理就好了title_ = title_.replace('/', '')title_ = title_.replace(' ', '')title_ = title_.replace('&', '')title_ = title_.replace(':', '')title_ = title_.replace('-', '')title_ = title_.replace('—', '')# 使用xpath语法获取数据,取到数据为列表,索引[0]取值取出里面的字符串,即包含视频音频文件的url字符串url_list_str = html_obj.xpath('//script[contains(text(),"window.__playinfo__")]/text()')[0]# 纯视频的urlvideo_url = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 纯音频的urlaudio_url = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 设置跳转字段的headersheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36','Referer': url_}# 获取纯视频的数据response_video = requests.get(video_url, headers=headers_, stream=True)bytes_video = response_video.content# 获取纯音频的数据response_audio = requests.get(audio_url, headers=headers_, stream=True)bytes_audio = response_audio.content# 获取文件大小, 单位为KBvideo_size = int(int(response_video.headers['content-length']) / 1024)audio_size = int(int(response_audio.headers['content-length']) / 1024)# 保存纯视频的文件title_1 = title_ + '!' # 名称进行修改,避免重名title_1 = title_1.replace(':', '')with open(f'{title_1}.mp4', 'wb') as f:f.write(bytes_video)# print(f'{title_1}纯视频文件下载完毕...,大小为:{video_size}KB, {int(video_size/1024)}MB')with open(f'{title_1}.mp3', 'wb') as f:f.write(bytes_audio)# print(f'{title_1}纯音频文件下载完毕...,大小为:{audio_size}KB, {int(audio_size/1024)}MB')# 利用第三方工具ffmpeg 合成视频, 需要执行终端命令ffmpeg_path = r".\ffmpeg\bin\ffmpeg.exe"# os.system(f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy .\video\{title_}.mp4 -loglevel quiet')folder_path = f"./video/{fileName}" # 替换为你想要创建的文件夹路径if not os.path.exists(folder_path):os.mkdir(folder_path)# print(f"The folder '{folder_path}' already exists.")command = f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy ./video/{fileName}/{i}.{title_1}.mp4 -loglevel quiet'file_path = f"./video/{fileName}/{i}.{title_}.mp4"if os.path.exists(file_path):passelse:os.system(command)# 显示合成文件的大小print(f'{i}.{title_} 下载完成')# 移除纯视频文件,os.remove(f'{title_1}.mp4')# 移除纯音频文件,os.remove(f'{title_1}.mp3')3.3 下载合集视频
合集的里面数据的访问api
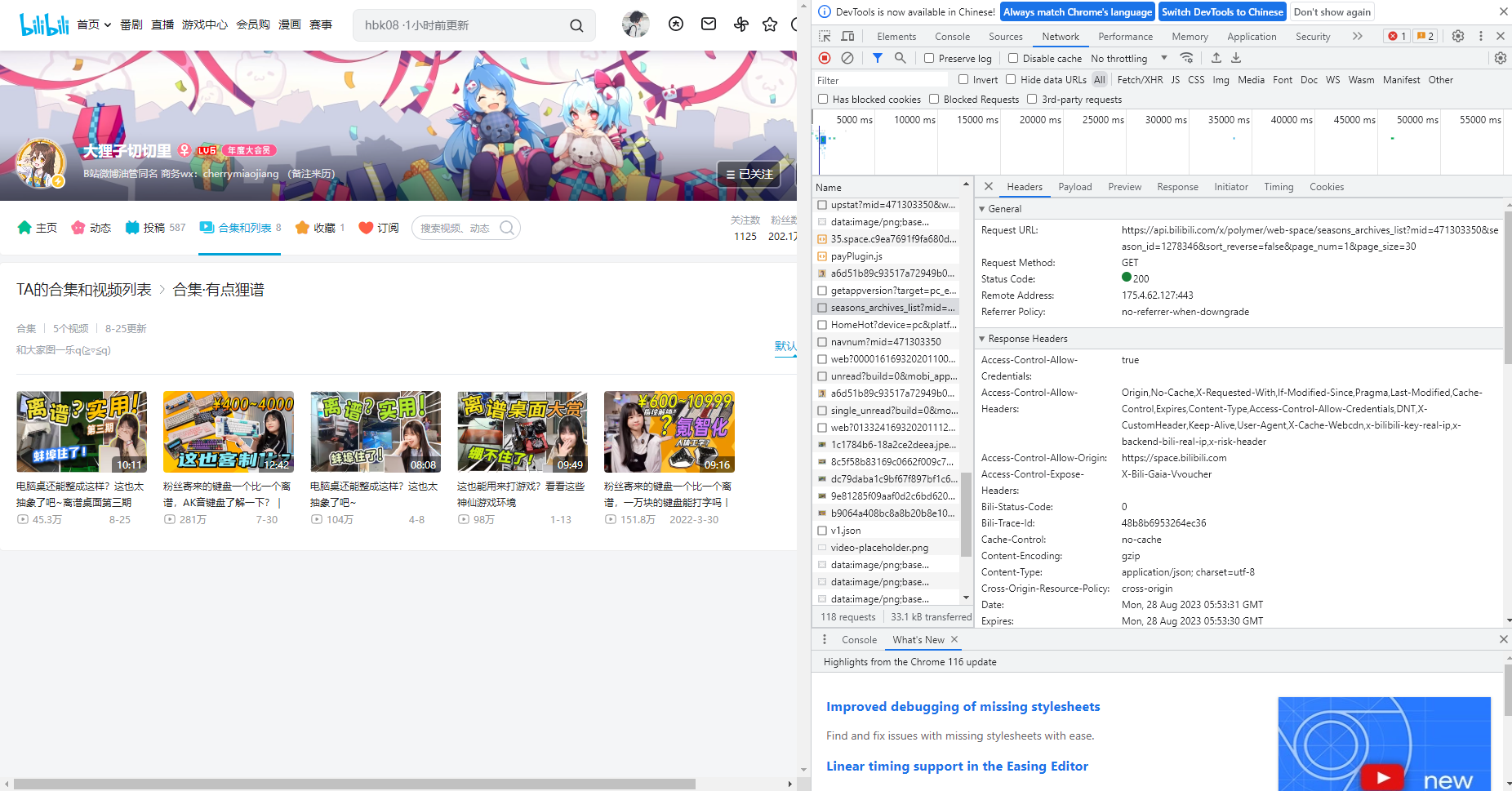
合集里面的数据,就是从这个里面拿到播放id,给json中的处理拿出来,拼接视频播放链接
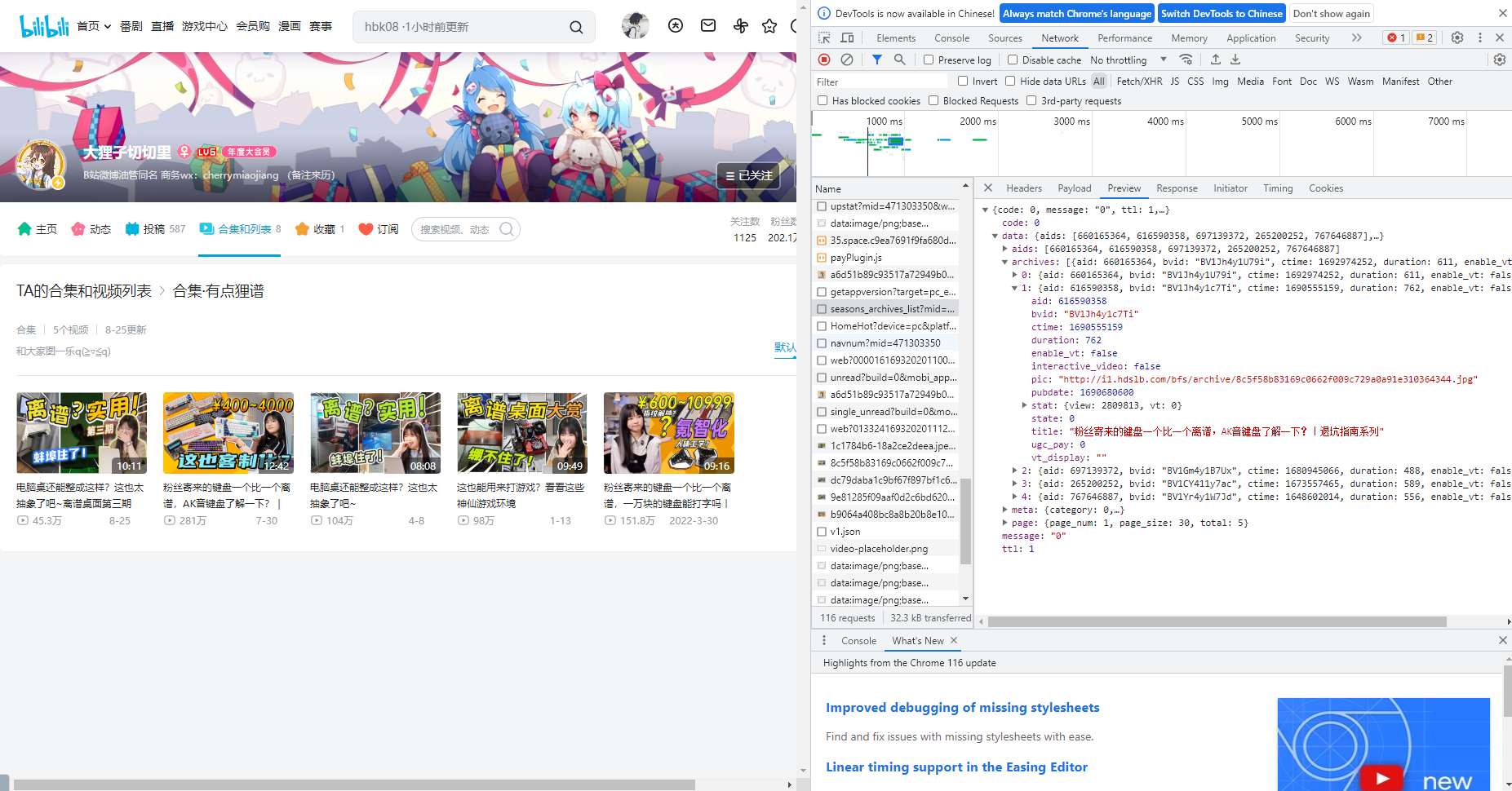
代码
# 获取网页源码
def getUrls3(url):# 发送请求,得到响应对象# 设置用户代理,cookieheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}# 使用正则表达式提取数字pattern = r'\d+'numbers = re.findall(pattern, url)mid = numbers[0]season_id = numbers[1]page_num = 1url = f"https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid={mid}&season_id={season_id}&sort_reverse=false&page_num={page_num}&page_size=30"response = requests.get(url)if response.status_code == 200:json_data = response.json()# print(json_data["data"]["page"]["total"])total = int(json_data["data"]["page"]["total"])page_size = int(json_data["data"]["page"]["page_size"])page = int(total / page_size) + 1name = json_data["data"]["meta"]["name"]# print(total,page)urls = []# for i in range(1,page+1):# print(i) url = f"https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid={mid}&season_id={season_id}&sort_reverse=false&page_num={i}&page_size=30"response = requests.get(url)if response.status_code == 200:json_data = response.json()archives = json_data["data"]["archives"]num = 0for j in archives:bvid = archives[num]["bvid"]videoUrl = f"https://www.bilibili.com/video/{bvid}/"num = num + 1urls.append(videoUrl)return urls,nameimport requests
import os
from lxml import etree
import redef videoDownload2(url_,i):# 设置用户代理,cookieheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}# 发送请求,得到响应对象response_ = requests.get(url_, headers=headers_)str_data = response_.text # 视频主页的html代码,类型是字符串# 使用xpath解析html代码,,得到想要的urlhtml_obj = etree.HTML(str_data) # 转换格式类型# 获取视频的名称res_ = html_obj.xpath('//title/text()')[0]# 视频名称的获取title_ = re.findall(r'(.*?)_哔哩哔哩', res_)[0]fileName = html_obj.xpath('//h1[@class="video-title"]/text()')[0]# 影响视频合成的特殊字符的处理,目前就遇到过这三个,实际上很有可能不止这三个,遇到了就用同样的方法处理就好了title_ = title_.replace('/', '')title_ = title_.replace(' ', '')title_ = title_.replace('&', '')title_ = title_.replace(':', '')# 使用xpath语法获取数据,取到数据为列表,索引[0]取值取出里面的字符串,即包含视频音频文件的url字符串url_list_str = html_obj.xpath('//script[contains(text(),"window.__playinfo__")]/text()')[0]# 纯视频的urlvideo_url = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 纯音频的urlaudio_url = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 设置跳转字段的headersheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36','Referer': url_}# 获取纯视频的数据response_video = requests.get(video_url, headers=headers_, stream=True)bytes_video = response_video.content# 获取纯音频的数据response_audio = requests.get(audio_url, headers=headers_, stream=True)bytes_audio = response_audio.content# 获取文件大小, 单位为KBvideo_size = int(int(response_video.headers['content-length']) / 1024)audio_size = int(int(response_audio.headers['content-length']) / 1024)# 保存纯视频的文件title_1 = title_ + '!' # 名称进行修改,避免重名title_1 = title_1.replace(':', '_')with open(f'{title_1}.mp4', 'wb') as f:f.write(bytes_video)# print(f'{title_1}纯视频文件下载完毕...,大小为:{video_size}KB, {int(video_size/1024)}MB')with open(f'{title_1}.mp3', 'wb') as f:f.write(bytes_audio)# print(f'{title_1}纯音频文件下载完毕...,大小为:{audio_size}KB, {int(audio_size/1024)}MB')# 利用第三方工具ffmpeg 合成视频, 需要执行终端命令ffmpeg_path = r".\ffmpeg\bin\ffmpeg.exe"# os.system(f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy .\video\{title_}.mp4 -loglevel quiet')folder_path = f"./video/{fileName}" # 替换为你想要创建的文件夹路径if not os.path.exists(folder_path):os.mkdir(folder_path)# print(f"The folder '{folder_path}' already exists.")command = f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy ./video/{fileName}/{i}.{title_}.mp4 -loglevel quiet'file_path = f"./video/{fileName}/{i}.{title_}.mp4"if os.path.exists(file_path):passelse:os.system(command)# 显示合成文件的大小print(f'{i}.{title_} 下载完成')# 移除纯视频文件,os.remove(f'{title_1}.mp4')# 移除纯音频文件,os.remove(f'{title_1}.mp3')3.4 多线程
代码
import concurrent.futures
import requests# 定义一个下载函数
def download_video(URL):url, index, name = URL.split(" ", 2)videoDownload3(url,index,name)def THREAD(URLS):# 创建线程池,指定线程数量max_workers = 10 # 这里设置线程数量,根据需要进行调整with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:# 提交下载任务给线程池处理futures = [executor.submit(download_video, URL) for URL in URLS]# 等待所有任务完成for future in concurrent.futures.as_completed(futures):try:future.result() # 获取任务的结果(这里不需要结果)except Exception as e:print(f"An error occurred: {e}")3.5 结果
url_model = "https://space.bilibili.com/471303350/channel/collectiondetail?sid=1278346 3"
value = url_model.split(' ')
url = value[0]
model = value[1]if model == "1":videoDownload1(url)print("下载完成")
if model == "2":# 接口分析# 点进去的话接口# https://www.bilibili.com/video/BV1qW4y1a7fU/?spm_id_from=333.337.search-card.all.click# 点击视频的话就这样# https://www.bilibili.com/video/BV1qW4y1a7fU?p=1# https://www.bilibili.com/video/BV1qW4y1a7fU?p=2&vd_source=de2dcd0f37ff916ec3f8fb83c6366123# 可以发现不同的集的接口格式应该是这样的,p = 几就是第几集# https://www.bilibili.com/video/BV1qW4y1a7fU?p=1# 查看有多少集# 一种是视频选集那块会写有多少个# 获取源码urls = getUrls2(url)i = 1for index,url in enumerate(urls):videoDownload2(url,index)print("下载完成")
if model == "3":# 接口分析# 视频合计每个视频接口没有规律,然后再播放页中网页没有直接的播放链接,所以就用合集页的链接来分析# 网页里面的每个链接都是动态加载的,需要访问json数据获取,也或者用虚拟浏览器那种等页面加载完成后访问(这种以后可能会更新,感觉这个有点麻烦),# 这里是用json数据做的# https://space.bilibili.com/107762251/channel/collectiondetail?sid=877119# https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid=107762251&season_id=877119&sort_reverse=false&page_num=1&page_size=30# https://space.bilibili.com/389199842/channel/collectiondetail?sid=1275285# https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid=389199842&season_id=1275285&sort_reverse=false&page_num=1&page_size=30# 这是两个接口,前面那个数字是用户,后面那个数字代表的是合集,下载的接口其实是股东urls,name = getUrls3(url)# print(len(urls))for index,url in enumerate(urls):# print(url)videoDownload3(url,index,name)# print(urls)# 多线程# for index,url in enumerate(urls):# URLS.append(url + " " + str(index) + " " + name)# THREAD(URLS)那切里做展示,有些合集下载时候有点bug,还没找到问题,可以下载,但是保存路径有点问题,应该是和命令行冲突了,我就不改了

3.6 合集视频更新
原来会出现部分合集显示下载成功,但是文件夹里面没有东西,是因为有些合集名字在命令里面没办法执行,因为一些特殊符号什么的,所以把合集名字手动指定一下下载就可以了,然后多线程加上去,代码如下
拿视频链接的
# 获取网页源码
def getUrls3(url):# 发送请求,得到响应对象# 设置用户代理,cookieheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}# 使用正则表达式提取数字pattern = r'\d+'numbers = re.findall(pattern, url)mid = numbers[0]season_id = numbers[1]page_num = 1url = f"https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid={mid}&season_id={season_id}&sort_reverse=false&page_num={page_num}&page_size=30"response = requests.get(url)if response.status_code == 200:json_data = response.json()# print(json_data["data"]["page"]["total"])total = int(json_data["data"]["page"]["total"])page_size = int(json_data["data"]["page"]["page_size"])page = int(total / page_size) + 1name = json_data["data"]["meta"]["name"]# print(total,page)urls = []# for i in range(1,page+1):# print(i) url = f"https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid={mid}&season_id={season_id}&sort_reverse=false&page_num={i}&page_size=30"response = requests.get(url)if response.status_code == 200:json_data = response.json()archives = json_data["data"]["archives"]num = 0for j in archives:bvid = archives[num]["bvid"]videoUrl = f"https://www.bilibili.com/video/{bvid}/"num = num + 1urls.append(videoUrl)return urls,name下载视频的
import requests
import os
from lxml import etree
import redef videoDownload3(url_,index,name):# 设置用户代理,cookieheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36','Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"}# 发送请求,得到响应对象response_ = requests.get(url_, headers=headers_)str_data = response_.text # 视频主页的html代码,类型是字符串# 使用xpath解析html代码,,得到想要的urlhtml_obj = etree.HTML(str_data) # 转换格式类型# 获取视频的名称res_ = html_obj.xpath('//title/text()')[0]# 视频名称的获取title_ = re.findall(r'(.*?)_哔哩哔哩', res_)[0]# 影响视频合成的特殊字符的处理,目前就遇到过这三个,实际上很有可能不止这三个,遇到了就用同样的方法处理就好了title_ = title_.replace('/', '')title_ = title_.replace(' ', '')title_ = title_.replace('&', '')title_ = title_.replace(':', '')# 使用xpath语法获取数据,取到数据为列表,索引[0]取值取出里面的字符串,即包含视频音频文件的url字符串url_list_str = html_obj.xpath('//script[contains(text(),"window.__playinfo__")]/text()')[0]# 纯视频的urlvideo_url = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 纯音频的urlaudio_url = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]# 设置跳转字段的headersheaders_ = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36','Referer': url_}# 获取纯视频的数据response_video = requests.get(video_url, headers=headers_, stream=True)bytes_video = response_video.content# 获取纯音频的数据response_audio = requests.get(audio_url, headers=headers_, stream=True)bytes_audio = response_audio.content# 获取文件大小, 单位为KBvideo_size = int(int(response_video.headers['content-length']) / 1024)audio_size = int(int(response_audio.headers['content-length']) / 1024)# 保存纯视频的文件title_1 = title_ + '!' # 名称进行修改,避免重名title_1 = title_1.replace(':', '_')with open(f'{title_1}.mp4', 'wb') as f:f.write(bytes_video)# print(f'{title_1}纯视频文件下载完毕...,大小为:{video_size}KB, {int(video_size/1024)}MB')with open(f'{title_1}.mp3', 'wb') as f:f.write(bytes_audio)# print(f'{title_1}纯音频文件下载完毕...,大小为:{audio_size}KB, {int(audio_size/1024)}MB')# 利用第三方工具ffmpeg 合成视频, 需要执行终端命令ffmpeg_path = r".\ffmpeg\bin\ffmpeg.exe"# os.system(f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy .\video\{title_}.mp4 -loglevel quiet')folder_path = f"./video/{name}" # 替换为你想要创建的文件夹路径if not os.path.exists(folder_path):os.mkdir(folder_path)# print(f"The folder '{folder_path}' already exists.")command = f'{ffmpeg_path} -i {title_1}.mp3 -i {title_1}.mp4 -c copy ./video/{name}/{index}.{title_}.mp4 -loglevel quiet'os.system(command)# 显示合成文件的大小print(f'{title_} 下载完成')# 移除纯视频文件,os.remove(f'{title_1}.mp4')# 移除纯音频文件,os.remove(f'{title_1}.mp3')多线程
import concurrent.futures
import requests# 定义一个下载函数
def download_video(URL):url, index, name = URL.split(" ", 2)videoDownload3(url,index,name)def THREAD(URLS):# 创建线程池,指定线程数量max_workers = 10 # 这里设置线程数量,根据需要进行调整with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:# 提交下载任务给线程池处理futures = [executor.submit(download_video, URL) for URL in URLS]# 等待所有任务完成for future in concurrent.futures.as_completed(futures):try:future.result() # 获取任务的结果(这里不需要结果)except Exception as e:print(f"An error occurred: {e}")执行
url_model = "https://space.bilibili.com/389199842/channel/collectiondetail?sid=1275285 3"
value = url_model.split(' ')
url = value[0]
model = value[1]if model == "1":videoDownload1(url)print("下载完成")
if model == "2":# 接口分析# 点进去的话接口# https://www.bilibili.com/video/BV1qW4y1a7fU/?spm_id_from=333.337.search-card.all.click# 点击视频的话就这样# https://www.bilibili.com/video/BV1qW4y1a7fU?p=1# https://www.bilibili.com/video/BV1qW4y1a7fU?p=2&vd_source=de2dcd0f37ff916ec3f8fb83c6366123# 可以发现不同的集的接口格式应该是这样的,p = 几就是第几集# https://www.bilibili.com/video/BV1qW4y1a7fU?p=1# 查看有多少集# 一种是视频选集那块会写有多少个# 获取源码urls = getUrls2(url)i = 1for index,url in enumerate(urls):videoDownload2(url,index)print("下载完成")
if model == "3":# 接口分析# 视频合计每个视频接口没有规律,然后再播放页中网页没有直接的播放链接,所以就用合集页的链接来分析# 网页里面的每个链接都是动态加载的,需要访问json数据获取,也或者用虚拟浏览器那种等页面加载完成后访问(这种以后可能会更新,感觉这个有点麻烦),# 这里是用json数据做的# https://space.bilibili.com/107762251/channel/collectiondetail?sid=877119# https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid=107762251&season_id=877119&sort_reverse=false&page_num=1&page_size=30# https://space.bilibili.com/389199842/channel/collectiondetail?sid=1275285# https://api.bilibili.com/x/polymer/web-space/seasons_archives_list?mid=389199842&season_id=1275285&sort_reverse=false&page_num=1&page_size=30# 这是两个接口,前面那个数字是用户,后面那个数字代表的是合集,下载的接口其实是股东urls,name = getUrls3(url)name = "qml项目"URLS = []# print(len(urls))for index,url in enumerate(urls):# print(url)URLS.append(url + " " + str(index+1) + " " + name)THREAD(URLS)print("全部下载完成!!!")# print(urls)# for index,url in enumerate(urls):# URLS.append(url + " " + str(index) + " " + name)# THREAD(URLS)
四.参考
http://t.csdn.cn/6Pt7v 想下载B站视频却不知如何下手?一文教你爬B站!
相关文章:
python爬取bilibili,下载视频
一. 内容简介 python爬取bilibili,下载视频 二. 软件环境 2.1vsCode 2.2Anaconda version: conda 22.9.0 2.3代码 链接:https://pan.baidu.com/s/1WuXTso_iltLlnrLffi1kYQ?pwd1234 三.主要流程 3.1 下载单个视频 代码 import requests impor…...
java八股文面试[多线程]——进程与线程的区别
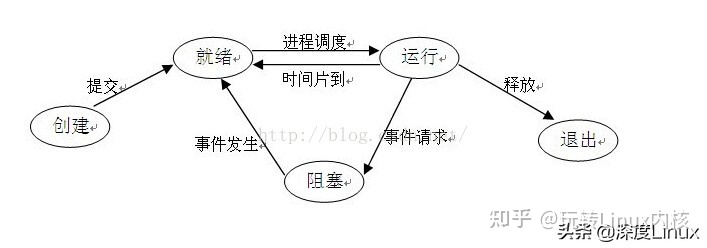
定义 1、进程:进程是一个具有独立功能的程序关于某个数据集合的以此运行活动。 是系统进行资源分配和调度的独立单位,也是基本的执行单元。是一个动态的概念,是一个活动的实体。它不只是程序的代码,还包括当前的活动。 进程结构…...

SpringBootWeb 登录认证[Cookie + Session + Token + Filter + Interceptor]
目录 1. 登录功能 1.1 需求 1.2 接口文档 1.3 登录 - 思路分析 1.4 功能开发 1.5 测试 2. 登录校验 2.1 问题分析 什么是登录校验? 我们要完成以上登录校验的操作,会涉及到Web开发中的两个技术: 2.2 会话技术 2.2.1 会话技术介绍…...
d3dcompiler_43.dll丢失怎么修复,分享几种修复d3dcompiler_43.dll的方法
不少人可能看到d3dcompiler_43.dll这个文件会感觉到陌生,是的,因为这个文件一般来说是很少丢失的,但是还是会出现d3dcompiler_43.dll丢失的情况的,今天主要是来给大家详细的说说d3dcompiler_43.dll丢失怎么修复的相关方法。 一.分…...
mqtt集群搭建并使用nginx做负载均衡_亲测得结论
mqtt集群搭建 RabbitMQ集群搭建和测试总结_亲测 搭建好RabbitMQ集群,并开启mqtt插件功能,mqtt集群也就搭建好了 nginx配置mqtt负载均衡 #修改rabbitmq1节点ip为1.19的nginx配置 vim /etc/nginx/nginx.confhttp { } #在http外添加如下配置 stream {upstream rabbitmqtt {ser…...
JavaScript—DOM(文档对象模型)
目录 DOM是什么? DOM有什么作用? 一、事件 理解事件 事件怎么写(要做什么就写什么)? 实战演练 1、页面加载完毕以后,打印一句话 2、如果有一个a标签,并给其添加一个点击事件 3、事件默…...

mysql Index
创建索引 方法1 create table 表( col1 int, col2 int, … index | key index_name (列名) 方法2 alter table 表名 ADD index alter table student_table add index index_name(stu_id); 方法3 create index index_name on 表名(列) 删除索引 方式1 alter table xx drop prima…...

八路参考文献:[八一新书]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022.
八路参考文献:[八一新书]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022....
Leetcode Top 100 Liked Questions(序号75~104)
75. Sort Colors 题意:红白蓝的颜色排序,使得相同的颜色放在一起,不要用排序 我的思路 哈希 代码 Runtime 4 ms Beats 28.23% Memory 8.3 MB Beats 9.95% class Solution { public:void sortColors(vector<int>& nums) {vector…...

Shell编程之流程控制
目录 if判断 case语句 for循环 while循环 if判断 语法: if [ 条件判断表达式 ] then 程序 elif [ 条件判断表达式 ] then 程序 else 程序 fi 注意: [ 条件判断表达式 ],中括号和条件判断表达式之间必须有空格。if,elif…...
什么是Python爬虫分布式架构,可能遇到哪些问题,如何解决
目录 什么是Python爬虫分布式架构 1. 调度中心(Scheduler): 2. 爬虫节点(Crawler Node): 3. 数据存储(Data Storage): 4. 反爬虫处理(Anti-Scraping&…...
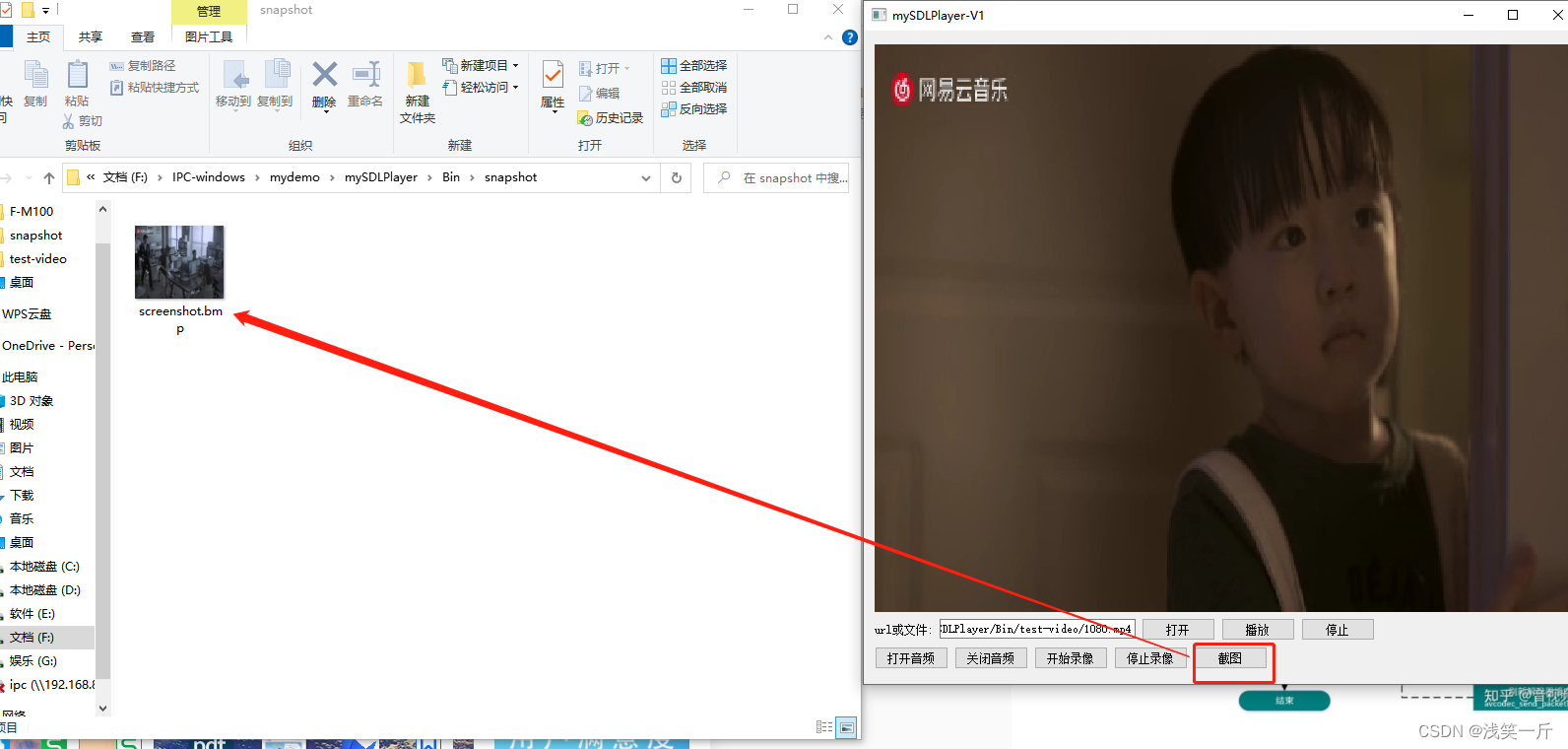
QT下使用ffmpeg+SDL实现音视频播放器,支持录像截图功能,提供源码分享与下载
前言: SDL是音视频播放和渲染的一个开源库,主要利用它进行视频渲染和音频播放。 SDL库下载路径:https://github.com/libsdl-org/SDL/releases/tag/release-2.26.3,我使用的是2.26.3版本,大家可以自行选择该版本或其他版…...
Microsoft Excel整合Python:数据分析的新纪元
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

【前端代码规范】
前端代码规范 vue3版本:【Vue&React】版本TS版本:【TS&JS】版本vite版本:【Webpack&Vite】版本Eslint版本:命名规则:【见名识意】项目命名:目录命名:JS/VUE文件CSS/SCSS文件命名:HTML文件命名:…...

postgresql-日期函数
postgresql-日期函数 日期时间函数计算时间间隔获取时间中的信息截断日期/时间创建日期/时间获取系统时间CURRENT_DATE当前事务开始时间 时区转换 日期时间函数 PostgreSQL 提供了以下日期和时间运算的算术运算符。 计算时间间隔 age(timestamp, timestamp)函数用于计算两…...

Android11去掉Setings里的投射菜单条目
Android11去掉【设置】--【已连接的设备】--【连接偏好设置】里的投射菜单条目,具体如下: commit 0c0583e6ddcdea21ec02db291d9a07d90f10aa59 Author: wzh <wzhincartech.com> Date: Wed Jul 21 16:37:13 2021 0800去掉投射菜单Change-Id: Id7f…...
)
fnm(Node.js 版本管理器)
fnm是什么? fnm是一款快速简单跨平台的 Node.js 版本管理器,使用 Rust 构建。 fnm怎么使用? 查看node 已安装列表 fnm list node 版本切换 fnm use 版本号 fnm use 16.0.0...
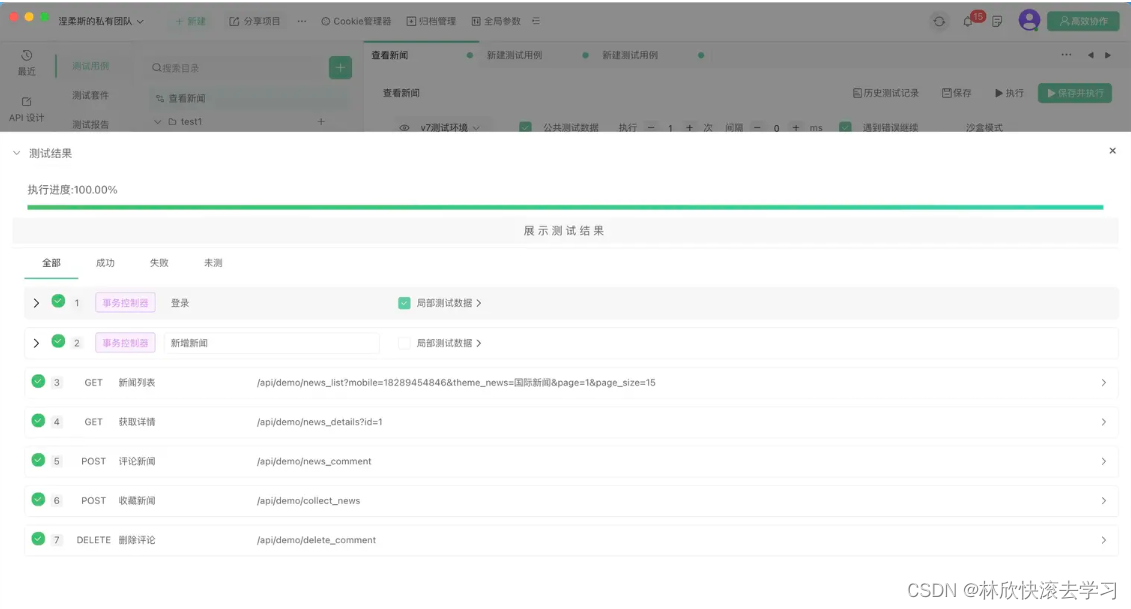
Apipost:为什么是开发者首选的API调试工具
文章目录 前言正文接口调试接口公共参数、环境全局参数的使用快速生成并导出接口文档研发协作接口压测和自动化测试结论 前言 Apipost是一款支持 RESTful API、SOAP API、GraphQL API等多种API类型,支持 HTTPS、WebSocket、gRPC多种通信协议的API调试工具。除此之外…...

Echarts图表坐标轴文字太长,省略显示,鼠标放上显示全部(vue)
注意:记得加上这个,触发事件, triggerEvent: true,重点:下面就是处理函数,在实例化图表的时候使用,传入参数是echarts的实例 // 渲染echartsfirstBarChart() {const that thislet columnar echarts.init…...

C语言控制语句——跳转关键字
循环和switch专属的跳转:break循环专属的跳转:continue无条件跳转:goto break 循环的break说明 某一条件满足时,不再执行循环体中后续重复的代码,并退出循环 需求:一共吃5碗饭, 吃到第3碗吃饱了, 结束吃饭…...

用MATLAB和Python搞定二维热传导仿真:从ADI算法到FFT快速求解器的保姆级对比
MATLAB与Python热传导仿真实战:从算法选择到性能调优 在工程仿真领域,热传导问题一直是个经典课题。无论是电子设备散热分析、建筑热工设计还是材料加工模拟,二维热传导方程的求解都是基础中的基础。对于需要在不同编程环境中实现这类仿真的工…...

ZVM嵌入式实时虚拟机:在ARMv8-A上实现Linux与Zephyr的混合关键性系统
1. 项目概述与核心价值如果你正在从事嵌入式系统开发,尤其是涉及汽车电子、工业控制或5G通信设备这类对实时性和可靠性要求极高的领域,那么你肯定对“既要、又要、还要”的困境深有体会。我们常常需要在同一块硬件上,既要运行一个功能丰富、生…...

17 ThingsBoard网关设备-子设备数据模型实战:核心价值+完整落地指南
ThingsBoard网关设备-子设备数据模型实战:核心价值完整落地指南 一、任务说明 1.1 场景必要性 在物联网(IoT)/工业物联网(IIoT)场景中,「网关设备-子设备」层级数据模型是解决异构设备批量接入、统一管理…...
)
告别手动!用Windows批处理脚本批量重命名MKV音轨(MkvToolnix v73实战)
告别手动!用Windows批处理脚本批量重命名MKV音轨(MkvToolnix v73实战) 每次整理下载的剧集资源时,最让人头疼的莫过于音轨信息错乱——明明视频是国语配音,音轨标签却显示为日语。手动修改不仅效率低下,还容…...
:含12类经典数学场景Prompt+错误模式对照表+自动校验脚本)
Perplexity数学知识查询稀缺资源包(限时开放48小时):含12类经典数学场景Prompt+错误模式对照表+自动校验脚本
更多请点击: https://intelliparadigm.com 第一章:Perplexity数学知识查询 Perplexity 是衡量语言模型预测能力的核心指标,其数学定义源于信息论中的交叉熵。它本质上是模型对测试语料困惑程度的指数化表达,值越低表示模型对序列…...

国产GPU与CAD软件兼容性认证实战:从驱动优化到Linux部署全解析
1. 项目概述:一次“硬核”的国产化适配实战最近,我们团队完成了一项在工业软件领域颇具里程碑意义的兼容性认证工作——摩尔线程GPU与中望二三维CAD Linux版产品。这听起来可能像是一则普通的官方新闻稿,但背后涉及的,是从硬件驱动…...

Gradiant宣布完成E轮融资,公司估值达20亿美元,助力加快AI、半导体以及工业水务基建领域布局
随着Gradiant依托AI基建和先进制造业务实现业绩大幅增长,新资金将用于支持战略性并购、新一代技术研发以及上市筹备工作 Gradiant今日宣布完成E轮融资,公司估值达到20亿美元。本轮融资由Safar Partners和Hostplus Superannuation Fund领投,C…...

深入STM32WLE5的LoRa核心:对比SX126x裸驱与LoRaWAN协议栈,哪个更适合你的项目?
STM32WLE5开发实战:裸驱与LoRaWAN协议栈的深度技术选型指南 当工程师面对STM32WLE5这颗集成了LoRa射频功能的跨界芯片时,第一个需要直面的灵魂拷问往往是:该用寄存器直接操作射频核心,还是拥抱现成的LoRaWAN协议栈?这个…...
)
手把手教你用STM32F103C8T6驱动NRF24L01模块(附完整代码与避坑指南)
STM32F103C8T6与NRF24L01无线通信实战:从硬件对接到代码调试全解析 在物联网和智能硬件快速发展的今天,无线通信技术已成为嵌入式系统设计中不可或缺的一环。NRF24L01作为一款性价比极高的2.4GHz无线收发模块,配合STM32F103C8T6这类主流微控制…...

Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图
Ubuntu20.04安装Mapviz避坑指南:解决Qt与OpenCV冲突,手把手配置天地图 在ROS开发中,地图可视化工具Mapviz因其强大的插件系统和高度可定制性备受青睐。然而,Ubuntu20.04环境下安装Mapviz时,Qt版本冲突和OpenCV链接错误…...