Densenet模型详解
模型介绍
DenseNet的主要思想是密集连接,它在卷积神经网络(CNN)中引入了密集块(Dense Block),在这些块中,每个层都与前面所有层直接连接。这种设计可以让信息更快速地传播,有助于解决梯度消失的问题,同时也能够增加网络的参数共享,减少参数量,提高模型的效率和性能。
Densenet原理
DenseNet 的原理可以总结为以下几个关键点:
-
密集连接的块: DenseNet 将网络分成多个密集块(Dense Block)。在每个密集块内,每一层都连接到前面所有的层,不仅仅是前一层。这种连接方式使得信息能够更加快速地传播,允许网络在更早的阶段融合不同层的特征。
-
跳跃连接: 每一层都从前面所有的层接收特征作为输入。这些输入通过堆叠而来,从而构成了一个密集的特征图。这种跳跃连接有助于解决梯度消失问题,因为每一层都可以直接访问之前层的梯度信息,使得训练更加稳定。
-
特征重用性: 由于每一层都与前面所有层连接,网络可以自动地学习到更加丰富和复杂的特征表示。这样的特征重用性有助于提高网络的性能,同时减少了需要训练的参数数量。
-
过渡层: 在密集块之间,通常会使用过渡层(Transition Layer)来控制特征图的大小。过渡层包括一个卷积层和一个池化层,用于减小特征图的尺寸,从而减少计算量。

Densenet的结构
关于 DenseNet 的结构时,我们主要关注网络中的三个主要组成部分:密集块(Dense Block)、过渡层(Transition Layer)以及全局平均池化层。
密集块
密集块是 DenseNet 最核心的部分,由若干层组成。在密集块中,每一层都与前面所有层直接连接。这种密集连接的方式使得信息可以更充分地传递和重用。每一层的输出都是前面所有层输出的连结,这也意味着每一层的输入包括了前面所有层的特征。这种连接方式通过堆叠层的方式,构建了一个密集的特征图。
过渡层
在密集块之间,可以使用过渡层来控制特征图的大小,从而减少计算成本。过渡层由一个卷积层和一个池化层组成。卷积层用于减小通道数,从而降低特征图的维度。池化层(通常是平均池化)用于减小特征图的尺寸。这些操作有助于在保持网络性能的同时降低计算需求。
全局平均池化层
在整个 DenseNet 结构的末尾,通常会添加一个全局平均池化层。这一层的作用是将最终的特征图转换为全局汇总的特征,这对于分类任务是非常有用的。全局平均池化层计算每个通道上的平均值,将每个通道转换为一个标量,从而形成最终的预测。
DenseNet 结构的特点不仅在每个密集块内进行特征的密集连接,还在不同密集块之间使用过渡层来控制网络的尺寸和复杂度。这使得 DenseNet 能够在高度复杂的任务中表现出色,同时保持相对较少的参数。
这些在论文当中也有体现:
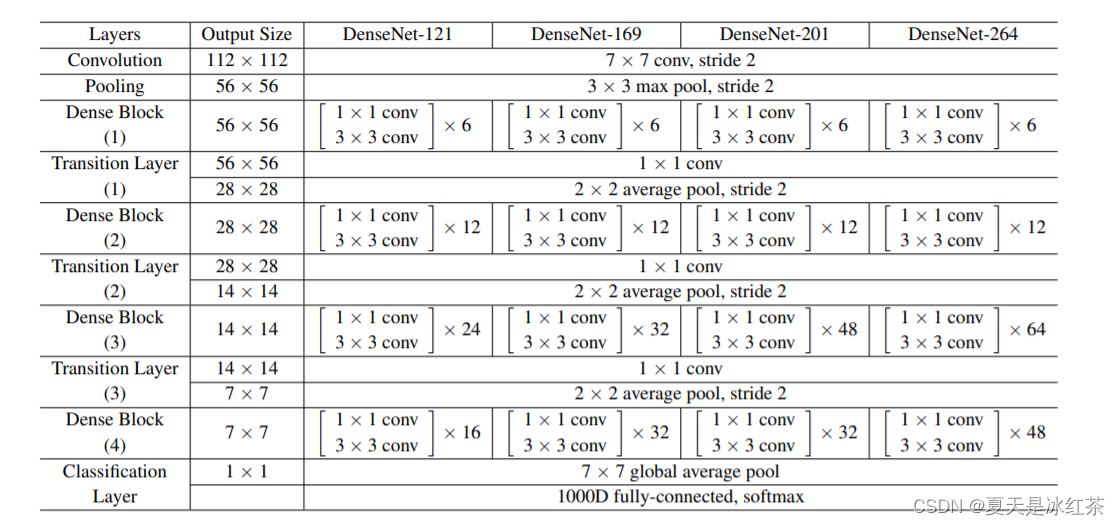
Densenet的优缺点比较
优点
-
密集连接促进信息传递和特征重用,提升了网络性能。
-
跳跃连接减少了梯度消失,有助于训练深层网络。
-
密集连接减少参数数量,提高了模型效率。
-
早期融合多尺度特征,增强了表征能力。
-
在小样本情况下表现更佳,充分利用有限数据。
缺点
-
密集连接可能导致内存需求增大。
-
连接多导致计算量增加,训练和推理时间较长。
-
可能因复杂性导致过拟合,需考虑正则化。
其实综合考虑,Densenet在图像识别和计算机视觉任务中仍然是一个好的选择。
Pytorch实现Densenet
import torch
import torchvision
import torch.nn as nn
import torchsummary
import torch.nn.functional as F
from torch.hub import load_state_dict_from_url
from collections import OrderedDict
from torchvision.utils import _log_api_usage_once
import torch.utils.checkpoint as cpmodel_urls = {"densenet121":"https://download.pytorch.org/models/densenet121-a639ec97.pth","densenet161":"https://download.pytorch.org/models/densenet161-8d451a50.pth","densenet169":"https://download.pytorch.org/models/densenet169-b2777c0a.pth","densenet201":"https://download.pytorch.org/models/densenet201-c1103571.pth",
}
cfgs = {"densenet121":(6, 12, 24, 16),"densenet161":(6, 12, 36, 24),"densenet169":(6, 12, 32, 32),"densenet201":(6, 12, 48, 32),
}class DenseLayer(nn.Module):def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, memory_efficient = False):super(DenseLayer,self).__init__()self.norm1 = nn.BatchNorm2d(num_input_features)self.relu1 = nn.ReLU(inplace=True)self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)self.norm2 = nn.BatchNorm2d(bn_size * growth_rate)self.relu2 = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)self.drop_rate = float(drop_rate)self.memory_efficient = memory_efficientdef bn_function(self, inputs):concated_features = torch.cat(inputs, 1)bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features)))return bottleneck_outputdef any_requires_grad(self, input):for tensor in input:if tensor.requires_grad:return Truereturn False@torch.jit.unuseddef call_checkpoint_bottleneck(self, input):def closure(*inputs):return self.bn_function(inputs)return cp.checkpoint(closure, *input)def forward(self, input):if isinstance(input, torch.Tensor):prev_features = [input]else:prev_features = inputif self.memory_efficient and self.any_requires_grad(prev_features):if torch.jit.is_scripting():raise Exception("Memory Efficient not supported in JIT")bottleneck_output = self.call_checkpoint_bottleneck(prev_features)else:bottleneck_output = self.bn_function(prev_features)new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)return new_featuresclass DenseBlock(nn.ModuleDict):def __init__(self,num_layers,num_input_features,bn_size,growth_rate,drop_rate,memory_efficient = False,):super(DenseBlock,self).__init__()for i in range(num_layers):layer = DenseLayer(num_input_features + i * growth_rate,growth_rate=growth_rate,bn_size=bn_size,drop_rate=drop_rate,memory_efficient=memory_efficient,)self.add_module("denselayer%d" % (i + 1), layer)def forward(self, init_features):features = [init_features]for name, layer in self.items():new_features = layer(features)features.append(new_features)return torch.cat(features, 1)class Transition(nn.Sequential):"""Densenet Transition Layer:1 × 1 conv2 × 2 average pool, stride 2"""def __init__(self, num_input_features, num_output_features):super(Transition,self).__init__()self.norm = nn.BatchNorm2d(num_input_features)self.relu = nn.ReLU(inplace=True)self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)self.pool = nn.AvgPool2d(kernel_size=2, stride=2)class DenseNet(nn.Module):def __init__(self,growth_rate = 32,num_init_features = 64,block_config = None,num_classes = 1000,bn_size = 4,drop_rate = 0.,memory_efficient = False,):super(DenseNet,self).__init__()_log_api_usage_once(self)# First convolutionself.features = nn.Sequential(OrderedDict([("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),("norm0", nn.BatchNorm2d(num_init_features)),("relu0", nn.ReLU(inplace=True)),("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))# Each denseblocknum_features = num_init_featuresfor i, num_layers in enumerate(block_config):block = DenseBlock(num_layers=num_layers,num_input_features=num_features,bn_size=bn_size,growth_rate=growth_rate,drop_rate=drop_rate,memory_efficient=memory_efficient,)self.features.add_module("denseblock%d" % (i + 1), block)num_features = num_features + num_layers * growth_rateif i != len(block_config) - 1:trans = Transition(num_input_features=num_features, num_output_features=num_features // 2)self.features.add_module("transition%d" % (i + 1), trans)num_features = num_features // 2# Final batch normself.features.add_module("norm5", nn.BatchNorm2d(num_features))# Linear layerself.classifier = nn.Linear(num_features, num_classes)# Official init from torch repo.for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):features = self.features(x)out = F.relu(features, inplace=True)out = F.adaptive_avg_pool2d(out, (1, 1))out = torch.flatten(out, 1)out = self.classifier(out)return outdef densenet(growth_rate=32,num_init_features=64,num_classes=1000,mode="densenet121",pretrained=False,**kwargs):import repattern = re.compile(r"^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$")if mode == "densenet161":growth_rate=48num_init_features=96model = DenseNet(growth_rate, num_init_features, cfgs[mode],num_classes=num_classes, **kwargs)if pretrained:state_dict = load_state_dict_from_url(model_urls[mode], model_dir='./model', progress=True) # 预训练模型地址for key in list(state_dict.keys()):res = pattern.match(key)if res:new_key = res.group(1) + res.group(2)state_dict[new_key] = state_dict[key]del state_dict[key]if num_classes != 1000:num_new_classes = num_classesweight = state_dict['classifier.weight']bias = state_dict['classifier.bias']weight_new = weight[:num_new_classes, :]bias_new = bias[:num_new_classes]state_dict['classifier.weight'] = weight_newstate_dict['classifier.bias'] = bias_newmodel.load_state_dict(state_dict)return modelfrom torchsummaryX import summaryif __name__ == "__main__":in_channels = 3num_classes = 10device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = densenet(growth_rate=32, num_init_features=64, num_classes=num_classes, mode="densenet121", pretrained=True)model = model.to(device)print(model)summary(model, torch.zeros((1, in_channels, 224, 224)).to(device))相关文章:
Densenet模型详解
模型介绍 DenseNet的主要思想是密集连接,它在卷积神经网络(CNN)中引入了密集块(Dense Block),在这些块中,每个层都与前面所有层直接连接。这种设计可以让信息更快速地传播,有助于解…...
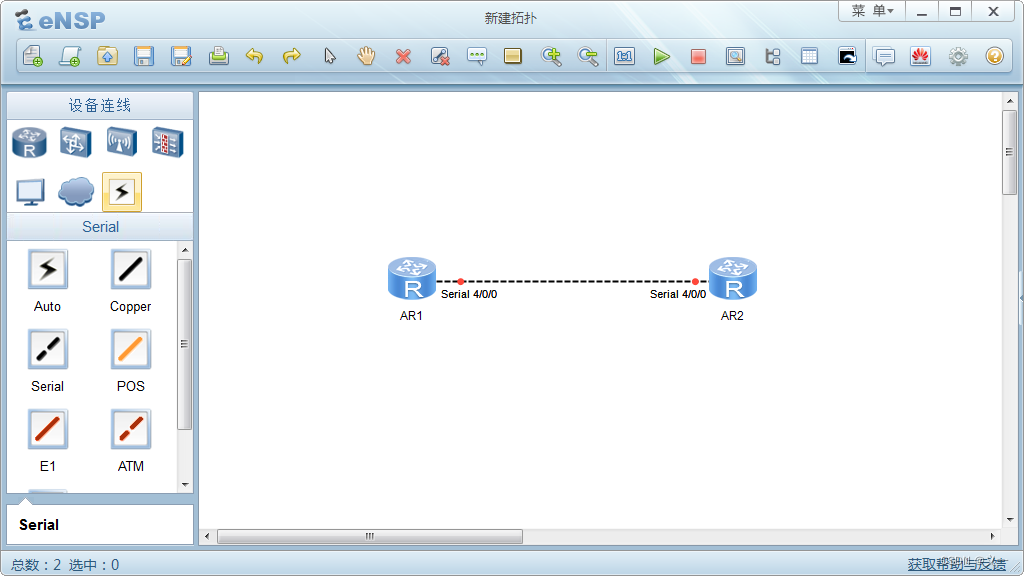
华为eNSP模拟器中,路由器如何添加serial接口
在ensp模拟器中新建拓扑后,添加2个路由器。 在路由器图标上单击鼠标右键,选择设置选项。 在【视图】选项卡的【eNSP支持的接口卡】窗口查找serial接口卡。 选择2SA接口卡,将其拖动到路由器空置的卡槽位。 如上图所示,已经完成路由…...

Linux脚本- 执行当前文件下前500个.c文件,并将每个文件对应的执行结果重定向到同名的.ok文件中
需求:执行当前文件下前500个.c文件,并将每个文件对应的执行结果重定向到同名的.ok文件中 以下是一个用于实现该功能的 Bash 脚本。 #!/bin/bash# 计数器,用于限制处理的文件数量 counter0# 遍历当前目录下的所有 .c 文件 for c_file in *.c…...

高速公路自动驾驶汽车超车控制方法研究
目录 摘要 ............................................................................................................ I Abstract ...................................................................................................... II 目录 ...............…...
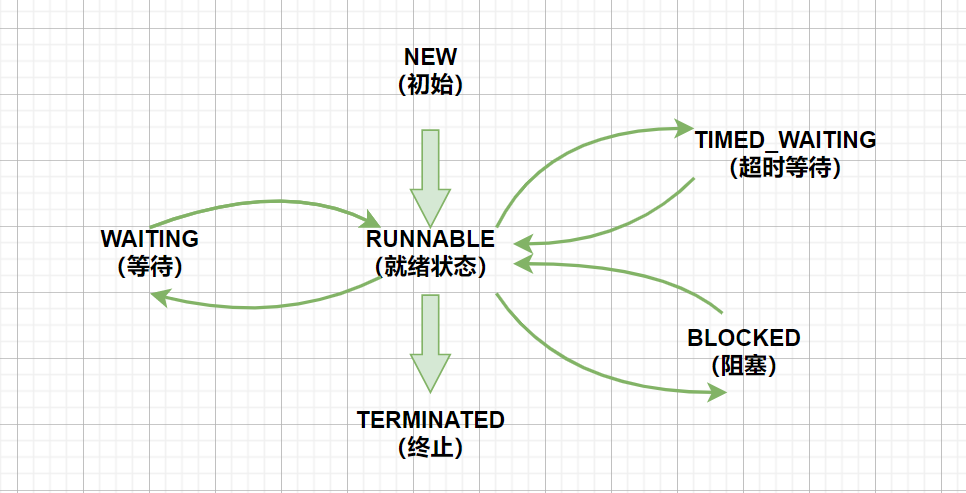
Java 多线程系列Ⅰ(创建线程+查看线程+Thread方法+线程状态)
多线程基础 一、创建线程的五种方法前置知识1、方法一:使用继承Thread类,重写run方法2、方法二:实现Runnable接口,重写run方法3、方法三:继承Thread,使用匿名内部类4、方法四:实现Runnable&…...
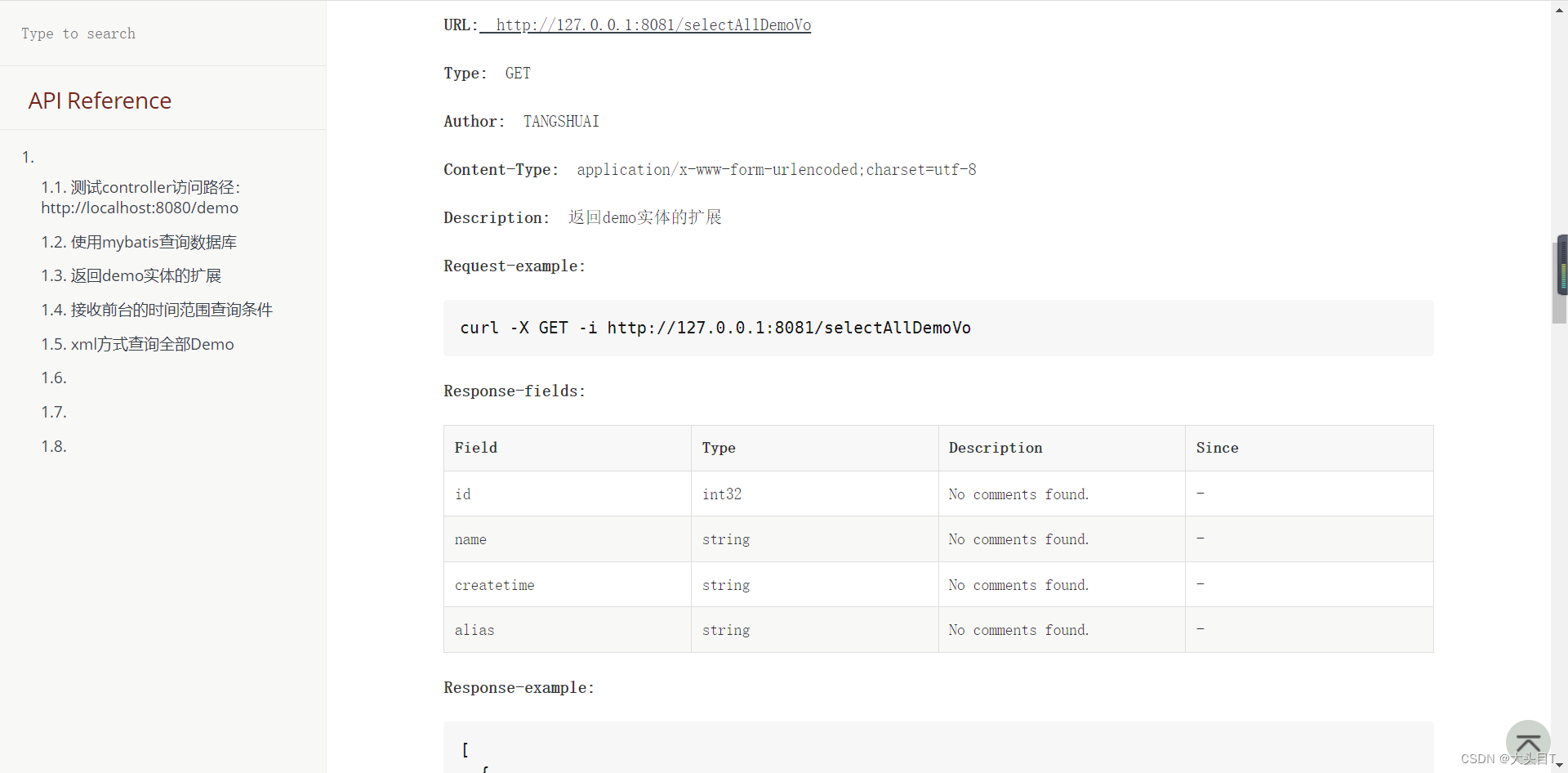
无入侵接口文档smart-doc
Smart-doc优点: 1.非侵入式生成接口文档 2.减少接口文档的手动更新麻烦&保证了接口文档和代码的一致 3.随时可生成最新的接口文档 4.保持团队代码风格一致:smart-doc支持javadoc,必须按照这个才能生成有注释的接口文档 最终效果 1.导入依赖 <pl…...
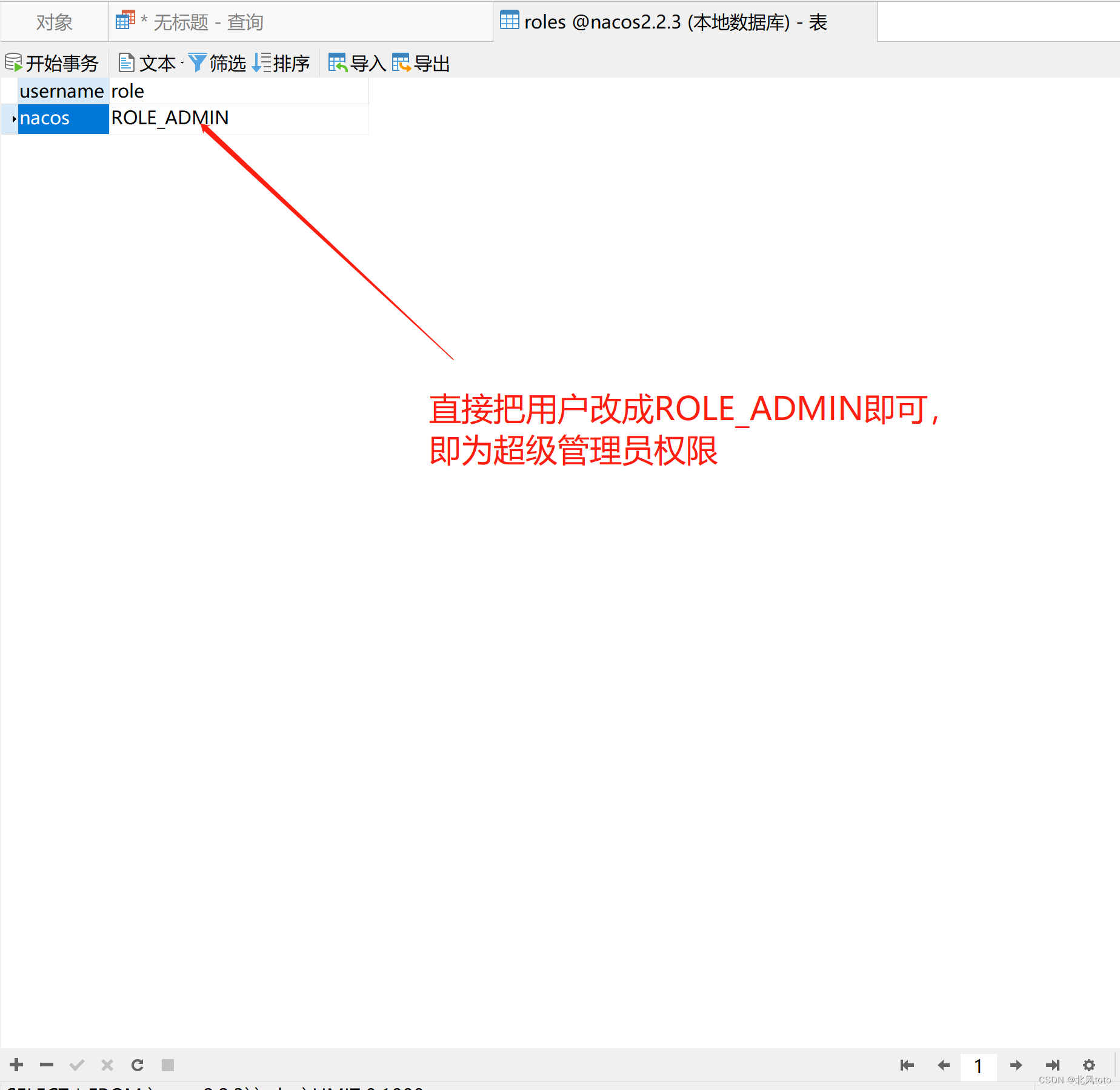
nacos配置超级管理员账户,只能mysql存储数据(或者其他数据库)
nacos本身是不允许授权超级管理员账号的,也就是角色名“ROLE_ADMIN”。作者在页面上试过了,不必再次尝试改的方式是直接改数据库里面的数据...
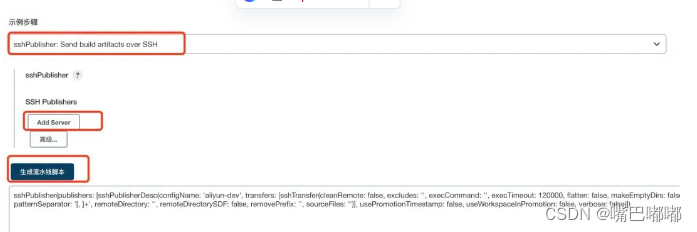
【前端自动化部署】,Devops,CI/CD
DevOps 提到Jenkins,想到的第一个概念就是 CI/CD 在这之前应该再了解一个概念。 DevOps Development 和 Operations 的组合,是一种方法论,并不特指某种技术或者工具。DevOps 是一种重视 Dev 开发人员和 Ops 运维人员之间沟通、协作的流程。…...

【C语言】探讨蕴藏在表达式求解中的因素
🚩纸上得来终觉浅, 绝知此事要躬行。 🌟主页:June-Frost 🚀专栏:C语言 🔥该篇将探讨 操作符 和 类型转换 对表达式求解的影响。 目录: 隐式类型转换算术转换操作符的属性❤️ 结语 隐…...


【Flutter】Flutter 使用 video_player 播放视频
【Flutter】Flutter 使用 video_player 播放视频 文章目录 一、前言二、video_player 简介三、安装和配置四、基本使用五、完整示例 六、高级功能七、总结 一、前言 大家好,我是小雨青年,今天我要和大家分享一款非常实用的 Flutter 包——video_player。…...

如何使用 ChatGPT 快速制作播客和其他长篇内容
使用ChatGPT快速制作播客和其他长篇内容是一个高效且具有一定创造性的过程。以下是一些详细的步骤和技巧,以帮助你充分利用ChatGPT来制作高质量的内容。 一、准备阶段 确定主题或话题:在开始制作之前,你需要明确你的播客或长篇内容将聚焦的主…...

JavaScript基础语法02——JS书写位置
哈喽,大家好,我是雷工! 今天继续学习JavaScript基础语法,JS的书写位置,俗话说:好记性不如烂笔头,边学边记,方便回顾。 1、行内JavaScript 代码写在标签内部 示例: <…...

LInux快捷命令
切换到行头:ctrla 或者 ctrlhome 切换到行尾:ctrale 或者 ctrlend 光标向左切换一个单词:ctrl← 光标向右切换一个单词:ctrl→ 历史命令搜索:history 历史命令匹配第一条执行:!x (x表示历史命令…...
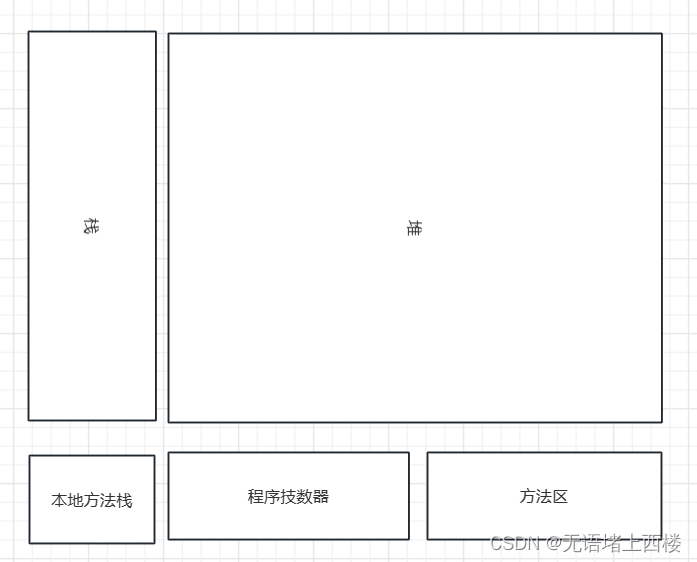
jvm的内存划分区域
jvm划分5个区域: java虚拟机栈、本地方法栈、堆、程序计数器、方法区。 各个区各自的作用: 1.本地方法栈:用于管理本地方法的调用,里面并没有我们写的代码逻辑,其由native修饰,由 C 语言实现。 2.程序计数…...

什么是数据中心IP,优缺点是什么?
如果根据拥有者或者说发送地址来分类的话,可以将代理分为三类:数据中心ip,住宅ip,移动ip 本文我们来了解数据中心ip的原理以及他们的优势劣势,才能选择适合自己的代理。 一、什么是数据中心ip代理? 数据中心ip是由数据中心拥有…...

模块化与组件化:开发中的双剑合璧
引言:模块化与组件化的重要性 在现代软件开发中,随着项目规模的增长和技术的复杂性增加,如何有效地组织和管理代码变得越来越重要。模块化与组件化作为两种主要的代码组织方法,为开发者提供了有效的工具,帮助他们创建…...
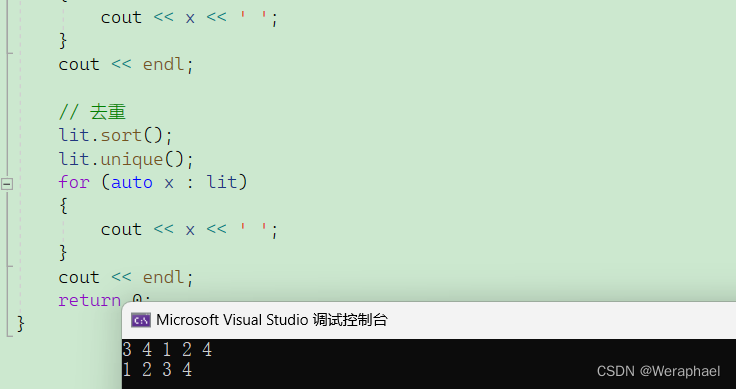
【C++初阶】list的常见使用操作
👦个人主页:Weraphael ✍🏻作者简介:目前学习C和算法 ✈️专栏:C航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞…...

排序之插入排序
文章目录 前言一、直接插入排序1、基本思想2、直接插入排序的代码实现3、直接插入排序总结 二、希尔排序1、希尔排序基本思想2、希尔排序的代码实现3、希尔排序时间复杂度 前言 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大…...
c# - - - 安装.net core sdk
如图,安装的是.Net Core 2.2版本 查看安装成功...

深入解析PyTorch-FCN架构:FCN32s、FCN16s、FCN8s模型对比分析
深入解析PyTorch-FCN架构:FCN32s、FCN16s、FCN8s模型对比分析 【免费下载链接】pytorch-fcn PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.) 项目地址: https://gitcode.com/gh_mirro…...

emacs-which-key替代方案对比:为什么它成为Emacs 30标准功能
emacs-which-key替代方案对比:为什么它成为Emacs 30标准功能 【免费下载链接】emacs-which-key Emacs package that displays available keybindings in popup 项目地址: https://gitcode.com/gh_mirrors/em/emacs-which-key emacs-which-key是一款能够在Ema…...

2026年六大GEO公司排名竞争力横评及企业选型实操指南针
根据易观发布的《中国 GEO 行业发展报告 2026》显示,2026年国内 GEO 市场规模已达 30 亿元,在短短 3 年内实现了 35 倍的爆发式增长,超过 68% 的中大型企业已将生成式引擎优化正式纳入年度预算。在当前由大模型驱动的信息分发范式下ÿ…...

用NE555和LM324做个红外倒车雷达:从仿真到焊接,一个模电新手的踩坑实录
从零打造红外倒车雷达:NE555与LM324实战手记 第一次拿起电烙铁时,我的手抖得像风中的芦苇。作为电子工程专业的大二学生,模电课的理论公式在面包板上变成了一团乱麻。直到导师建议我尝试做个红外倒车雷达——这个结合了振荡电路、信号放大和电…...

Android Studio中文插件终极指南:3分钟实现完整汉化体验
Android Studio中文插件终极指南:3分钟实现完整汉化体验 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Androi…...

RTOS如何通过确定性调度与内存管理增强嵌入式系统安全可靠性
1. 项目概述:为什么我们需要关注实时操作系统的安全与可靠?在嵌入式、工业控制、汽车电子乃至航空航天这些领域里,系统一旦“死机”或“反应迟钝”,后果往往不是重启一下那么简单。轻则产线停摆、设备损坏,重则可能危及…...

如何快速搭建微信智能机器人:7步实现多AI服务自动回复
如何快速搭建微信智能机器人:7步实现多AI服务自动回复 【免费下载链接】wechat-bot 🤖一个基于 WeChaty 结合 ChatGPT / Claude / Kimi / DeepSeek / Ollama等Ai服务实现的微信机器人 ,可以用来帮助你自动回复微信消息,或者社群分…...

Perplexity翻译查询功能实测对比:比DeepL快3.7倍、准确率提升22%的关键配置参数曝光
更多请点击: https://intelliparadigm.com 第一章:Perplexity翻译查询功能实测对比总览 Perplexity 作为一款以实时网络检索与推理能力见长的AI问答工具,其内置翻译查询功能并非独立模块,而是深度集成于自然语言理解流程中。在实…...

Steam Deck Tools 终极指南:让 Windows 掌机体验焕然一新
Steam Deck Tools 终极指南:让 Windows 掌机体验焕然一新 【免费下载链接】steam-deck-tools (Windows) Steam Deck Tools - Fan, Overlay, Power Control and Steam Controller for Windows 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck-tools …...

别再手动算镀膜了!用Ansys Zemax非序列模式,5分钟搞定二向分色分光镜仿真
5分钟极速仿真:Ansys Zemax非序列模式下二向分色分光镜的实战技巧 在光学系统设计中,二向分色分光镜的仿真往往成为效率瓶颈。传统方法需要手动计算镀膜参数、反复调试光线路径,消耗工程师大量时间。本文将揭示如何利用Ansys Zemax非序列模式…...