【python爬虫】4.爬虫实操(菜品爬取)
文章目录
- 前言
- 项目:解密吴氏私厨
- 分析过程
- 代码实现(一)
- 获取与解析
- 提取最小父级标签
- 一组菜名、URL、食材
- 写循环,存列表
- 代码实现(二)
- 复习总结
前言
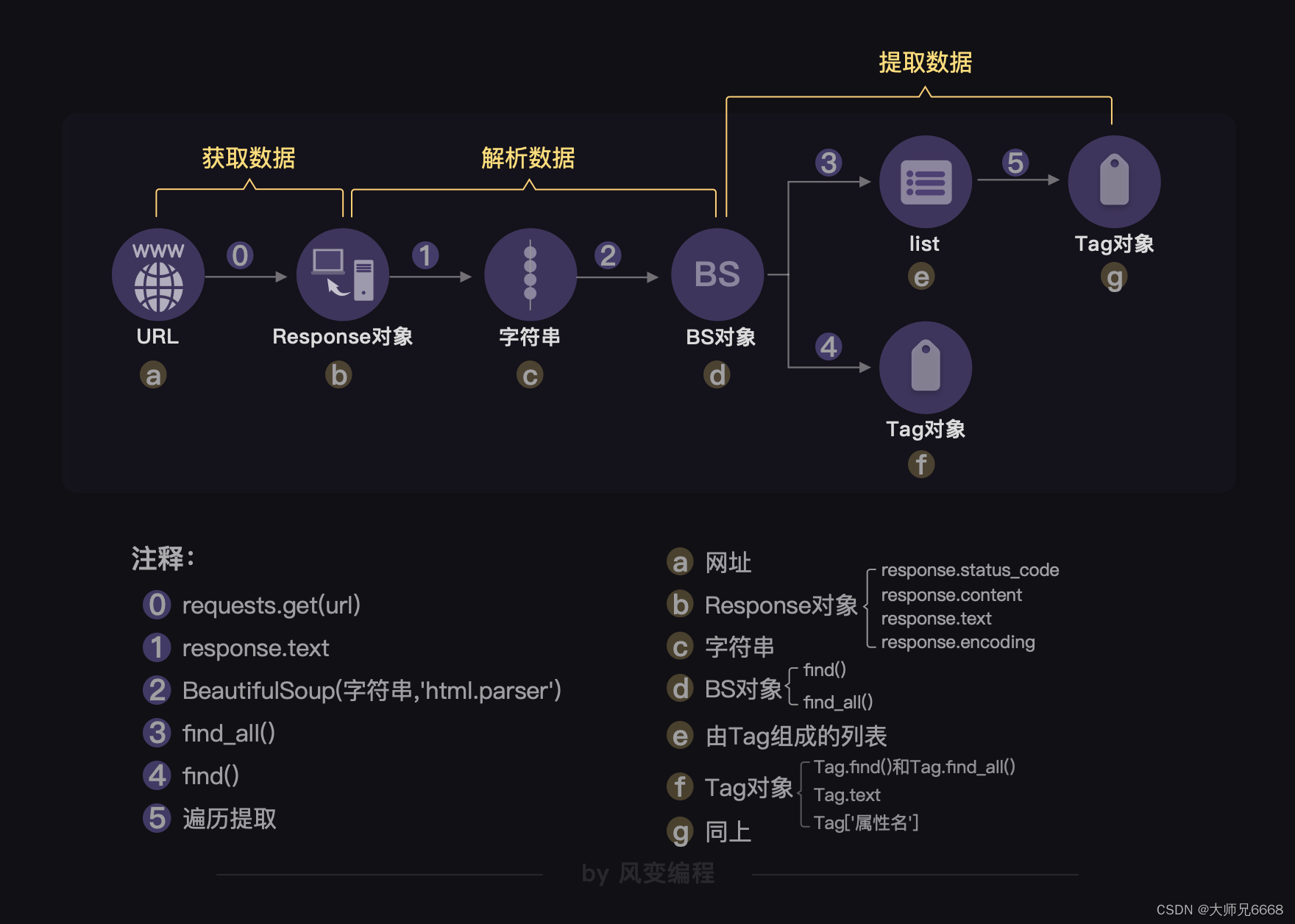
上一关,我们学习了用BeautifulSoup库解析数据和提取数据,解析数据的方法是:

提取数据的方法是用find() 与find_all()


最后,我们把事情串起来,就变成下图中的模样。它所对应的,正是爬虫四步中的前三步。
项目:解密吴氏私厨
我们继续说回到吴氏私厨的事。我在业余时,有一个爱好是烹饪美味的食物。几乎每个周末、节日,我都会邀请朋友、同事来我的家中做客,设宴款待。在快节奏的都市,这是一种奢侈而美好的享受。
我喜欢尝试新的东西,去做新的菜式,因为新鲜感能让朋友们对赴宴“吴氏私厨”总是心怀期待。

有朋友会好奇:为什么你可以会这么多种不同的菜式?这里面可有什么不为人知的秘密?我笑而不答,说你回头看我写的爬虫关卡就知道。
现在,我要将秘密揭晓。
答案就是我懂编程。在我看来,下厨和Python非常相像。学Python你只需要懂最基础的语法:列表字典、判断循环……然后合理地调用模块,就已经能做出很多有趣的事,代码跳跃在屏幕上,自有千般变化。
下厨你只需要懂最基础的操作手法:蒸炒炖焖煮、烧炸煎煲卤……然后去找合适的菜谱,大江南北,少有你烹不出的风味。
显然我懂厨房的基础手法,我只需要找合适的菜谱。
我写过一段Python代码,它能在每个周五爬取最新出的热门菜谱清单,发送到我的邮箱。内含:菜名、原材料、详细烹饪流程的URL。
我会选择里面看上去美味又没尝试过的,作为周末款待宾客的菜单。
下面,我要带你复现这个代码的编写过程。
项目目标:我们要去爬取热门菜谱清单,内含:菜名、原材料、详细烹饪流程的URL。而定时爬取和发送邮件,我会在第10关讲给你方案。
在这个项目里,我会带你体验BeautifulSoup库的实战应用,让你感受一个爬虫项目是如何一步步实现的。同时,也会有一些爬虫项目实战的经验分享。
分析过程
在这个项目里,我们选取的网站是“下厨房”。它有一个固定栏目,叫做“本周最受欢迎”,收集了当周最招人喜欢的菜谱。地址如下:
http://www.xiachufang.com/explore/
在进行爬取之前,我们先去看看它的robots协议。网址在此:
http://www.xiachufang.com/robots.txt
因为这个页面挺长的,所以我不再为你放截图。阅读这个robots协议,你会发现:我们要爬取的/explore/不在禁止爬取的列表内,但如果你要爬取/recipe/服务器就会不欢迎。在网页里,recipe是每一道菜的详情页面,记录了这道菜的做法。
如果你真要爬/recipe/里的信息,也能爬取到。只是人家都这样说了,我们就不要去爬它。
我们计划拿到的信息,就是下图页面上:菜名、所需材料、和菜名所对应的详情页URL。
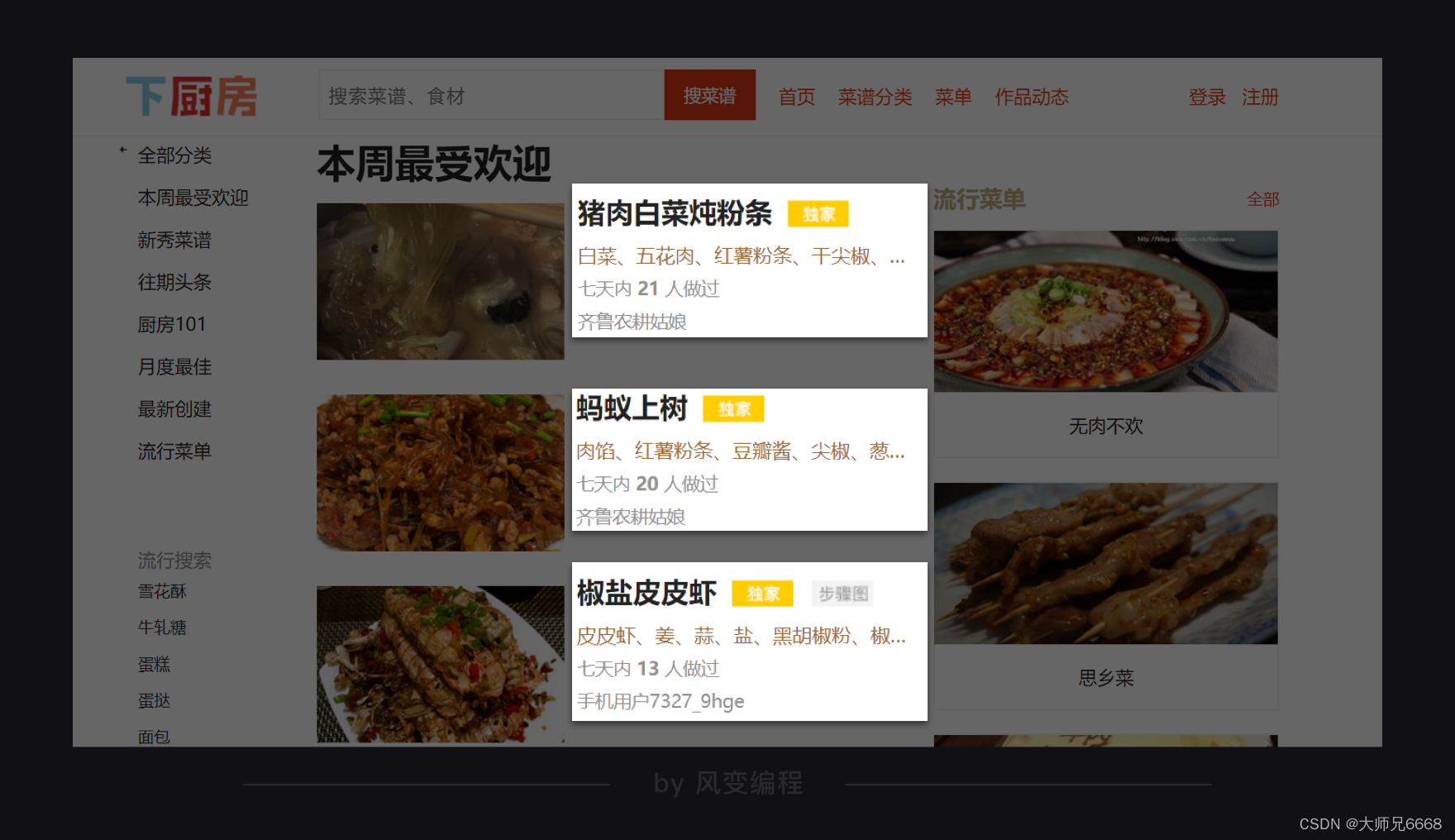
获取数据是容易的,使用requests.get()就能实现。不过由于网址反爬策略升级的问题,如果运行不成功的话,我们就需要添加headers参数并在本地运行。
headers参数今天我会直接提供在所有代码题当中,后面的课程再进行详细讲解。如果本地运行代码报错,请及时联系助教。
获取完数据后,我们需要用BeautifulSoup去解析数据。打开检查工具,我们先在Elements里查看这个网页是怎样的结构。
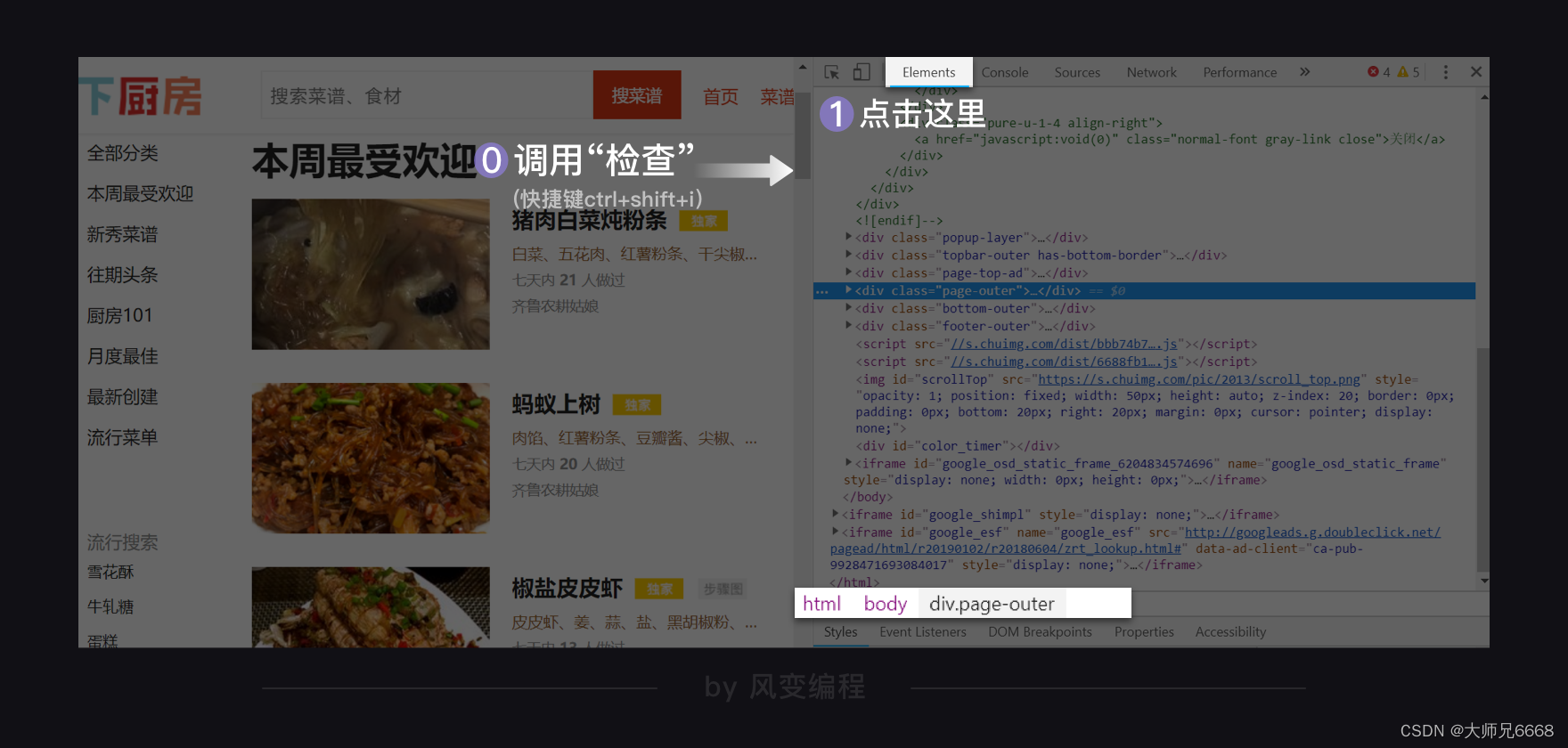
刚刚打开Elements,它会默认展开body,其余都关闭。我的鼠标悬停在<div class="page-outer">…<div> == $0上,所以你看到下方限制的路径,就是:html > body > div.page-outer。其中.所代表的正是class。
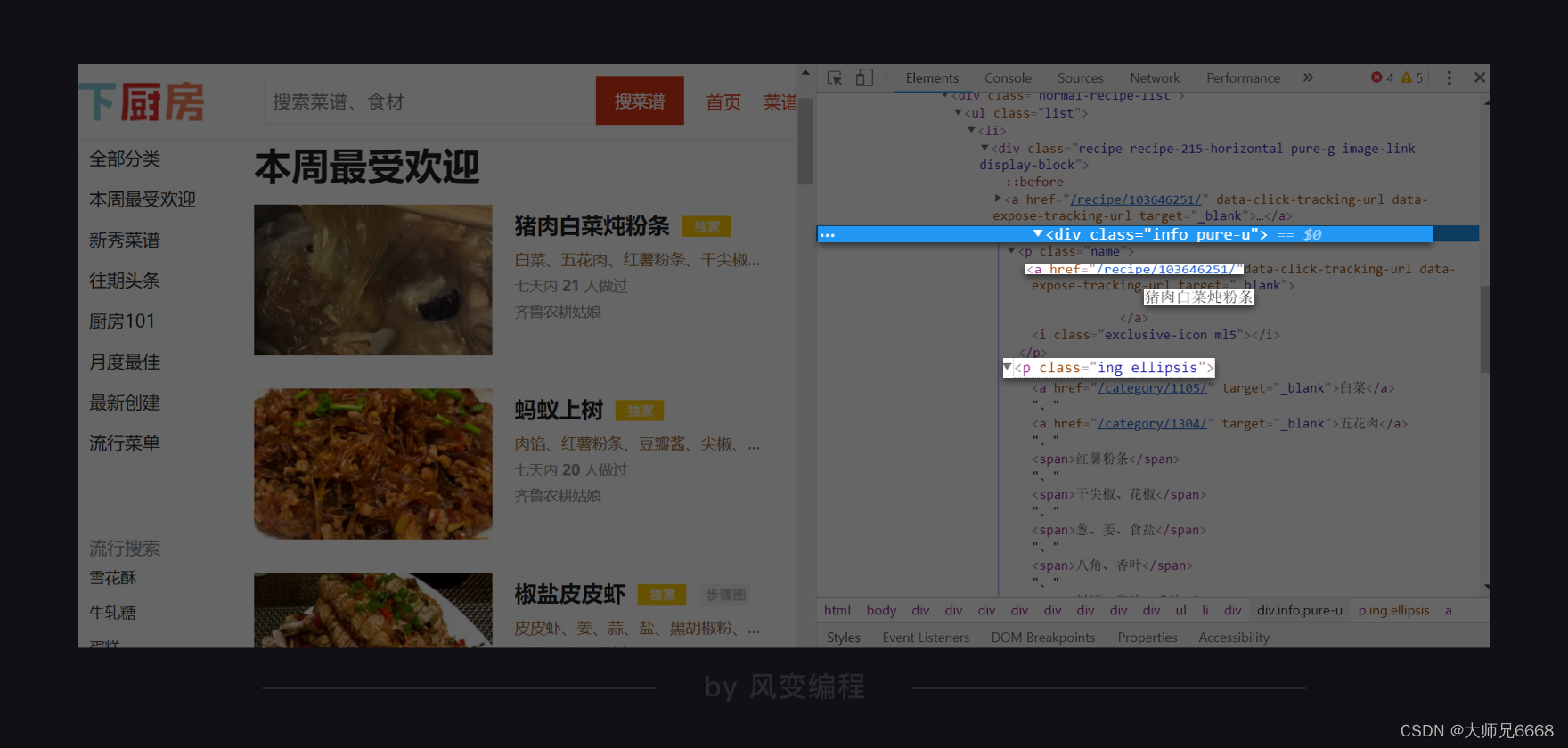
点击开发者工具左上角的小箭头,然后选中一个菜名,如我选的就是“猪肉炖粉条”,那么Elements那边就会自动标记出对应的代码。

如此,我们就定位到了菜名的所在位置,<a>标签内的文本,甚至还顺带找到了详情页URL的所在位置。如上图,<a>标签里有属性href,其值是/recipe/103646251/。点击它,你会跳转到这道菜的详情页。
所以到时候,我们可以去提取<a>标签。接着,先用text拿到它的文本,再使用[href]获取到半截URL,和http://www.xiachufang.com)做拼接即可。
步骤可以说是非常清晰了!用中学老师的话讲,这叫给未来的解析与提取打下坚实基础。
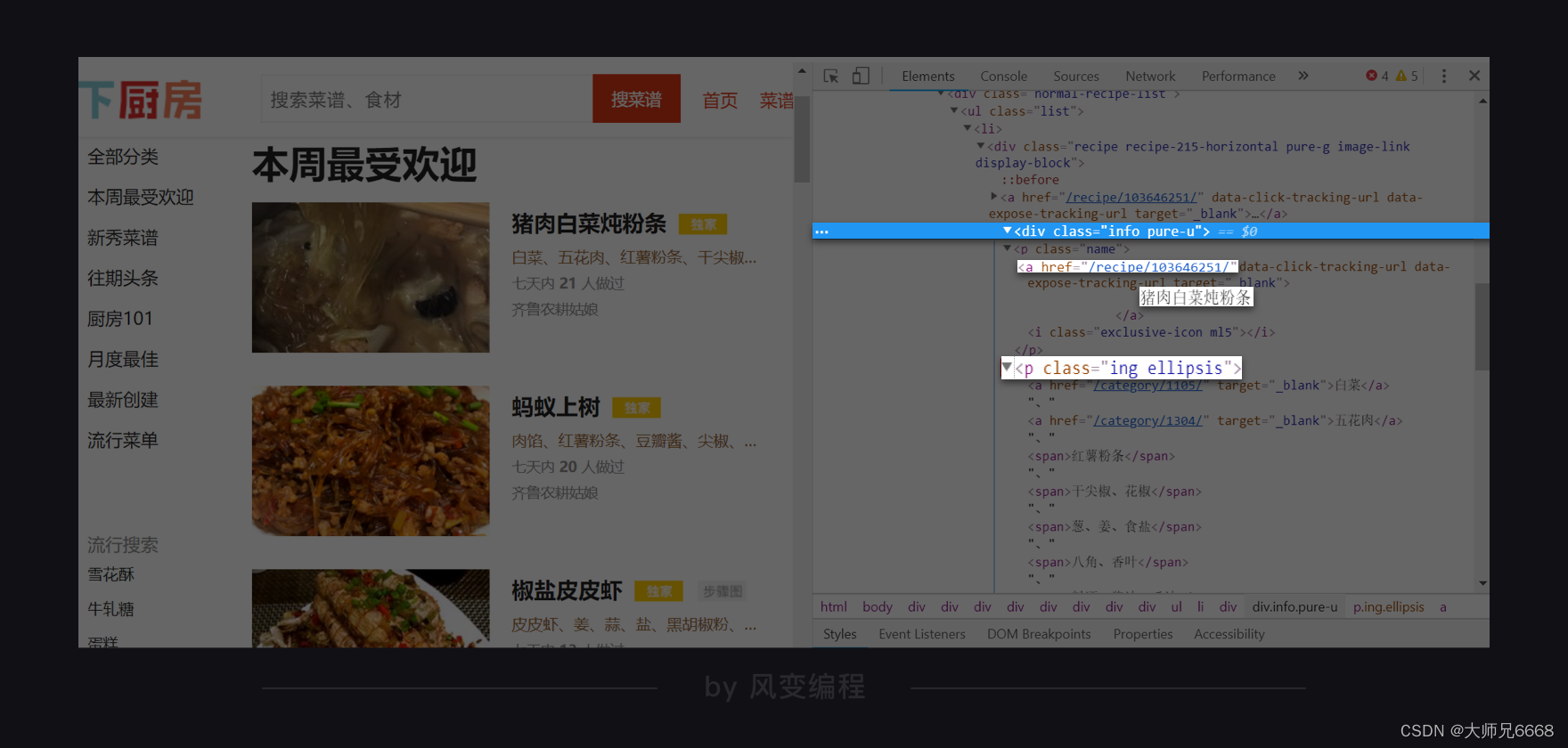
那趁热打铁。我们再去找找食材在哪里。和查找菜名一样的操作,去点击小箭头,去挑选一个食材。
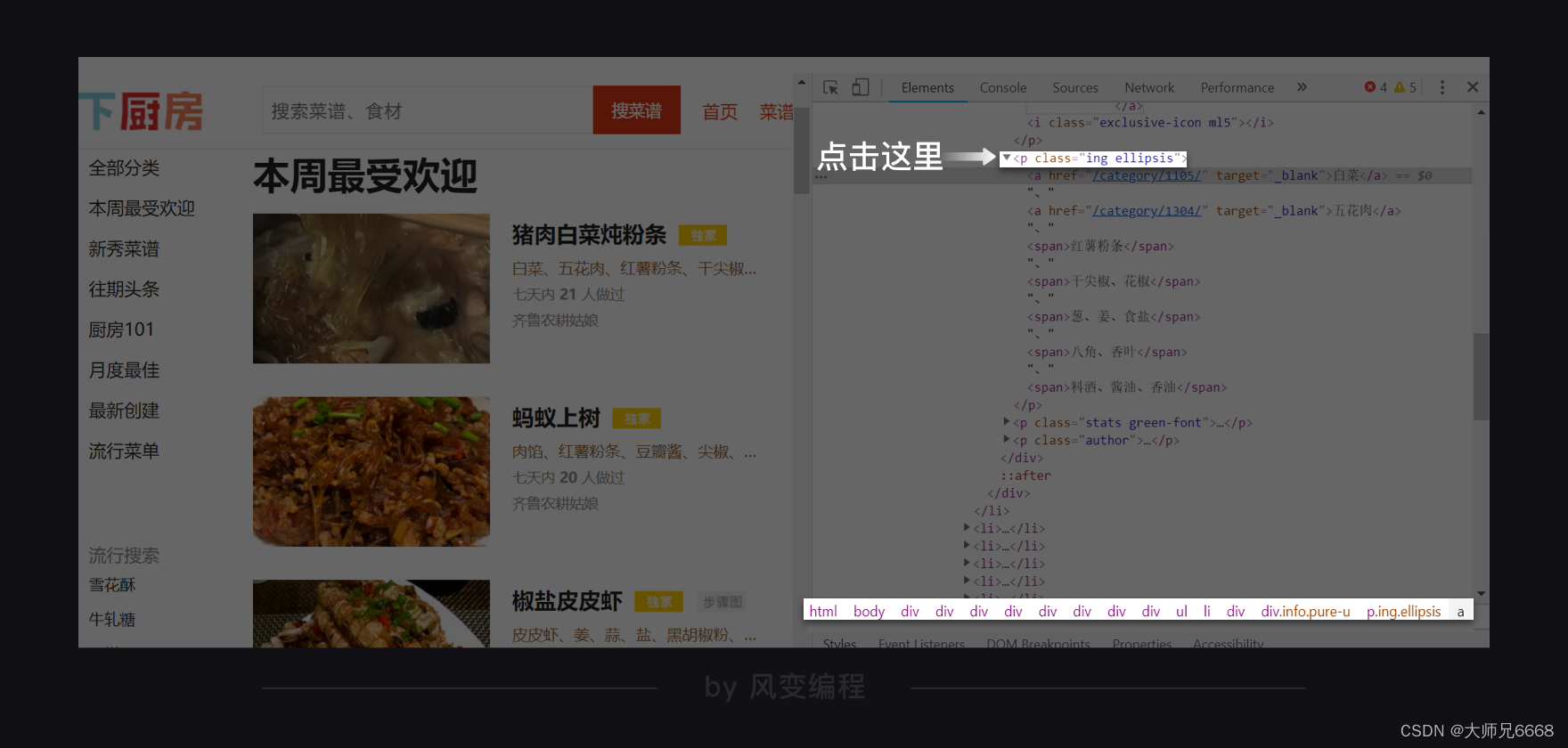
这说找一个,竟是全给找到了。猪肉白菜炖粉条,所需食材是:白菜、五花肉、红薯粉条、干尖椒、花椒、葱、姜、食盐、八角、香叶、料酒、酱油、香油……
它们有的是<a>标签里的纯文本,有的是<span>标签里的纯文本。它们的共同父级标签(相对于子标签,上级标签的意思,父标签包含子标签)是<p class="ing ellipsis">。
根据菜名的路径、URL的路径、食材的路径,我们可以找到这三者的最小共同父级标签,是:<div class="info pure-u">。
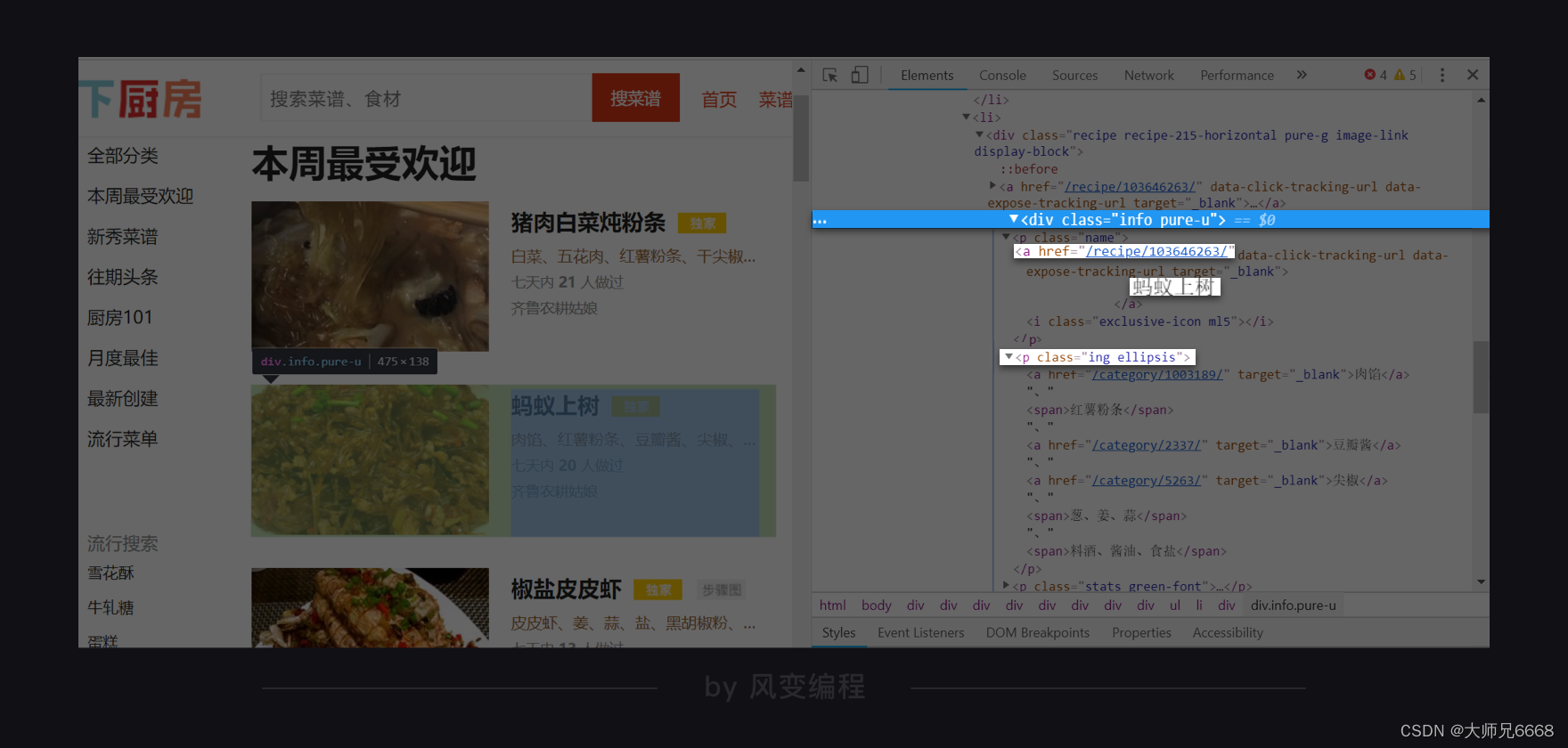
现在,我们就找到了所有待爬取的数据藏身何处。现在,去校验一下,其它菜名、URL、食材是不是也在同样位置。如下,猪肉白菜炖粉条:
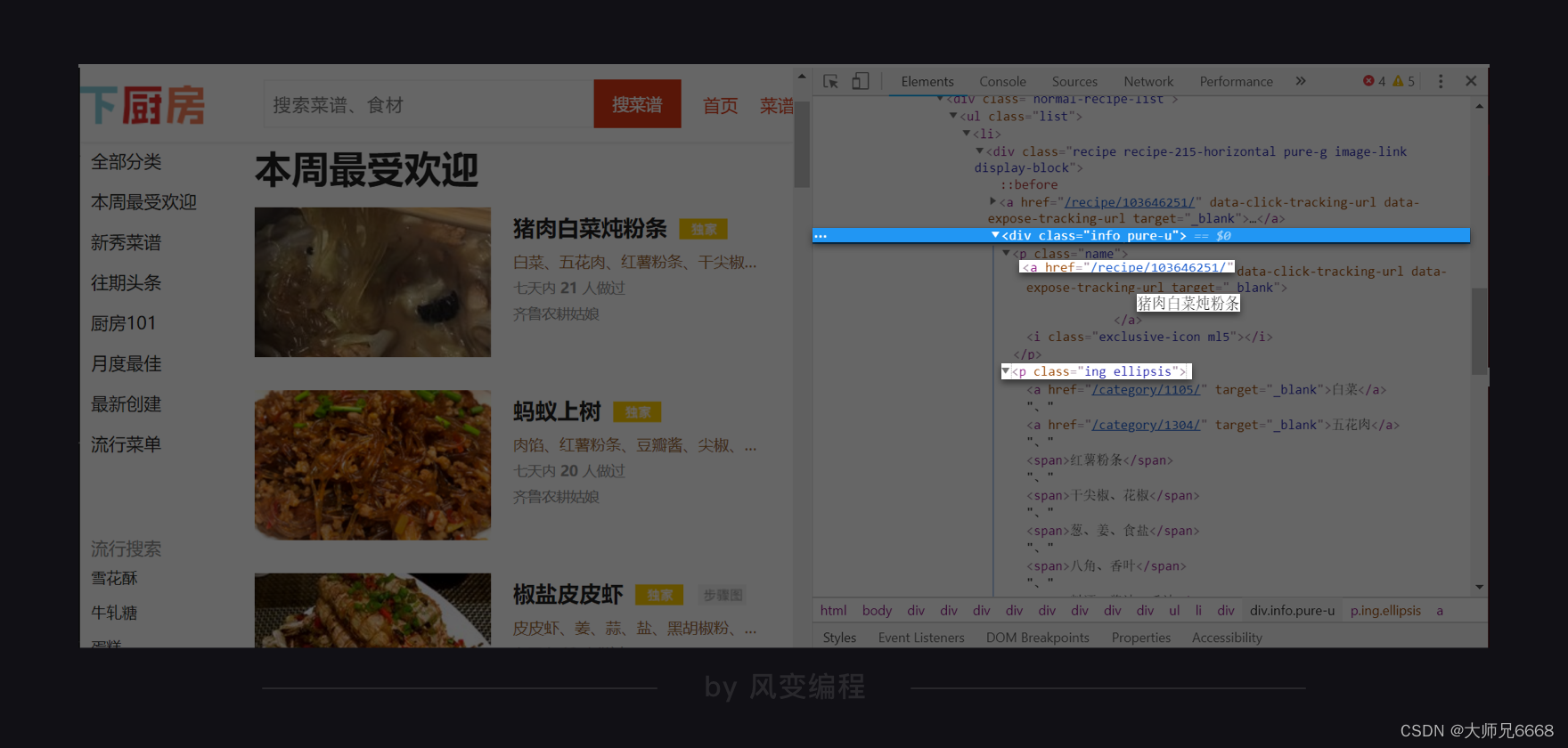
菜名是<a>标签内的文本,URL是<a>标签里属性href的值,食材藏身于<p class="ing ellipsis">。最后,它们三者的最小共同父级标签,是<div class="info pure-u">。
这说明,我们找的规律没错。那么基于此,我们可以产生两种写爬虫的思路:
思路一:我们先去爬取所有的最小父级标签<div class="info pure-u">,然后针对每一个父级标签,想办法提取里面的菜名、URL、食材。
思路二:我们分别提取所有的菜名、所有的URL、所有的食材。然后让菜名、URL、食材给一一对应起来(这并不复杂,第0个菜名,对应第0个URL,对应第0组食材,按顺序走即可)。
这两种思路,理论上来说都能够实现我们的目标。那么,我们应该选哪种?
小孩子才做选择,大人们则是全都要。下面,我们会详细介绍思路一,而把思路二留给你做练习。
在最后,提取到了数据我们要存储。但文件存储我们要到第6关才学习。所以,我们就先把数据存到列表里:每一组菜名、URL、食材是一个小列表,小列表组成一个大列表。如下:
[[菜A,URL_A,食材A],[菜B,URL_B,食材B],[菜C,URL_C,食材C]]
到这,我们可以去尝试写代码。
代码实现(一)
我们先使用思路一来写代码,即:先去爬取所有的最小父级标签<div class="info pure-u">,然后针对每一个父级标签,想办法提取里面的菜名、URL、食材。
获取与解析
我们选取的URL是http://www.xiachufang.com/explore/,我们用requests.get()来获取数据。
接着,使用BeautifulSoup来解析,这两步都不算是难事。所以我把它交给你当作开胃小菜。下面,请完成获取数据和解析数据两步,并将解析的结果打印出来。
获取数据:选取的URL是:http://www.xiachufang.com/explore/, 接着,使用BeautifulSoup对获取的数据进行解析。
参考代码如下:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/', headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 打印解析结果
print(bs_foods)
提取最小父级标签
我们来看这个父级标签:
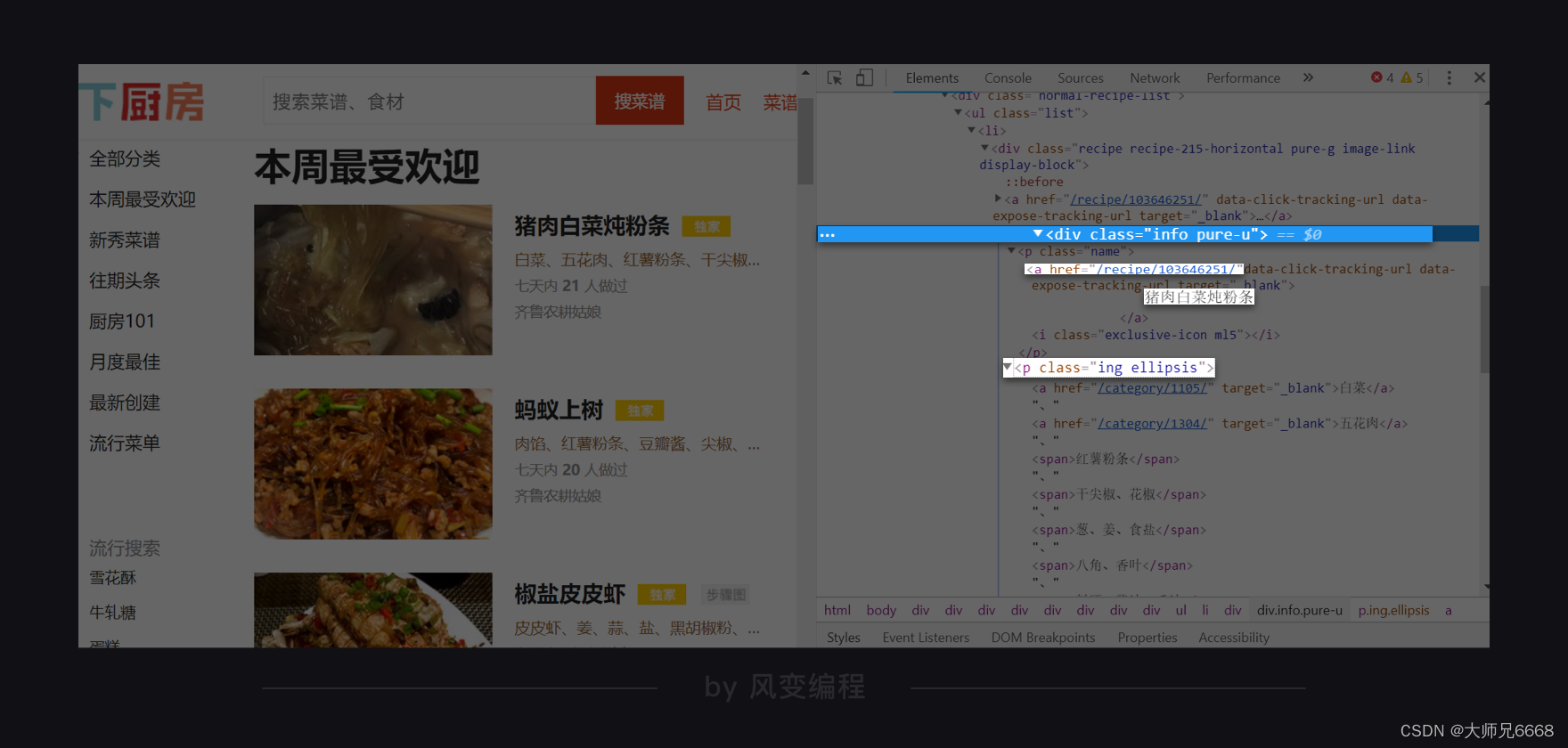
它的标签是<div>,有一个class属性,其值是info pure-u。我们可以使用find_all()语法,来找到它们。

现在,请尝试续写代码:使用find_all()语法查找最小父级标签,并把查找的结果打印出来。
参考代码如下:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 打印最小父级标签
print(list_foods)
非常幸运的是,这里一次就打印出了正确的东西。在实践操作当中,其实常常会因为标签选取不当,或者网页本身的编写没做好板块区分,你可能会多打印出一些奇怪的东西。
当遇到这种糟糕的情况,一般有两种处理方案:数量太多而无规律,我们会换个标签提取;数量不多而有规律,我们会对提取的结果进行筛选——只要列表中的若干个元素就好。
下面,我们可以进行下一步。针对查找结果中的每一个元素,再次查找位于里面的菜名、URL、食材。
一组菜名、URL、食材
我们不先急于提取出所有的菜名、URL和食材。我们先尝试提取一组,等成功了,再去写循环提取所有。我们来看图:
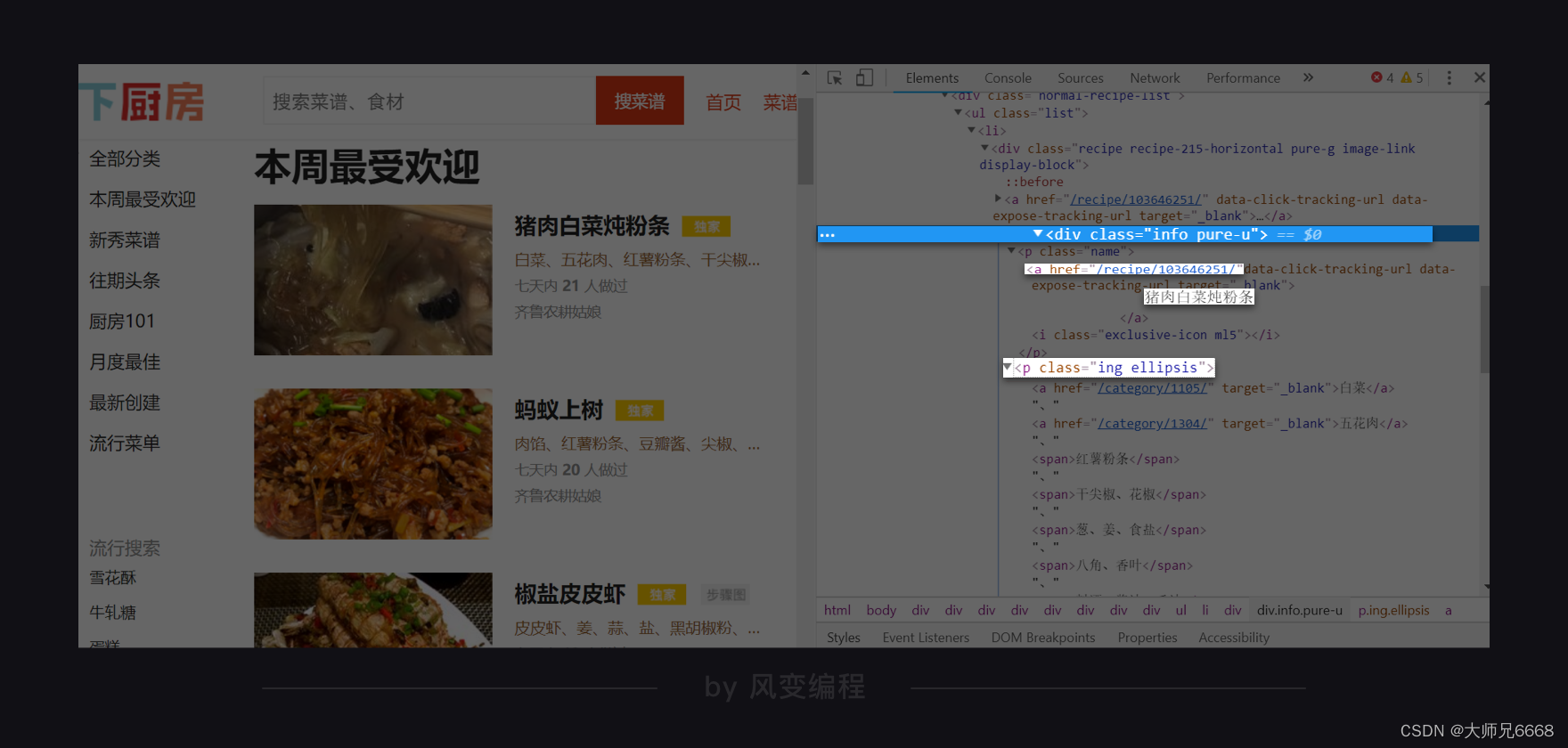
如何拿到URL和菜名?答案显而易见:我们可以查找父级标签中的第0个标签,里面就会有我们想要的信息。
只查找第0个标签,应该用什么语句?3、2、1,回答我。
用find()。我们对父级标签,使用find()方法来查找标签就对了,所用的参数就是<a>标签本身。
当拿到<a>标签之后呢,我们应该如何提取纯文本,以及某个属性的值?3、2、1,回答我。
现在,我们可以去做这样一个练习:续写下方代码,提取出第0个父级标签中的第0个<a>标签,并输出菜名和URL。
提示一:记得要提取的是第0个父级标签,而不是整个父级标签列表;
提示二:提取出的菜名的前后会有很多空格和换行,你可以使用字符串的strip()方法,把多余的内容裁剪掉(字符串.strip()),一起来体验一下它的用法吧:
string = ' python '# 去掉字符串string前后两端的空格
str = string.strip()
print(str)
运行结果:
python
提示三:提取出的URL需要和http://www.xiachufang.com做拼接。
以下,是我提供的参考答案。
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')# 提取第0个父级标签中的<a>标签
tag_a = list_foods[0].find('a')
# 输出菜名,使用strip()去掉了多余的空格
print(tag_a.text.strip())
# 输出URL
print('http://www.xiachufang.com'+tag_a['href'])
现在我们来看,如何提取食材。
你可能会想:我们去写一个find()去寻找
标签,再去写一个find_all()去寻找它里面的所有标签,然后写一个循环,使用text去提取每一个标签里的纯文本信息。
紧接着,用同样的手法,拿到所有标签里的纯文本信息。最后,把这些全都拼接起来。
天呐,这实在是麻烦坏了。
下面我要告诉你一个好消息:你完全不需要这样做,你只需要查找<p>标签,然后使用text提取<p>标签里的纯文本信息,就可以了!
不信,你可以做这样一个小测试,直接点击运行即可:
from bs4 import BeautifulSoupbs = BeautifulSoup('<p><a>惟有痴情难学佛</a>独无媚骨不如人</p>','html.parser')
tag = bs.find('p')
print(tag.text)
运行结果:
惟有痴情难学佛独无媚骨不如人
你会发现输出的结果是“惟有痴情难学佛独无媚骨不如人”。当我们在用text获取纯文本时,获取的是该标签内的所有纯文本信息,不论是直接在这个标签内,还是在它的子标签内。
需要强调的一点是,text可以这样做,但如果是要提取属性的值,是不可以的。父标签只能提取它自身的属性值,不能提取子标签的属性值。如下,就会报错:
from bs4 import BeautifulSoup# 以下此处多出来的\,是转义字符。
bs = BeautifulSoup('<p><a href=\'https://www.pypypy.cn\'></a></p>','html.parser')
tag = bs.find('p')
# 这样会报错,因为<p>标签没有属性href,href属于<a>标签
print(tag['href'])
有了这个知识,请你在之前代码的基础上,写出提取食材的代码,并打印出来。提示:只是用p标签做参数是不够的,因为这里不止一个p标签存在。你还要加class_参数。
以下,是我提供的参考答案。
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')# 提取第0个父级标签中的<a>标签
tag_a = list_foods[0].find('a')
# 菜名,使用strip()函数去掉了多余的空格
name = tag_a.text.strip()
# 获取URL
URL = 'http://www.xiachufang.com'+tag_a['href']# 提取第0个父级标签中的<p>标签
tag_p = list_foods[0].find('p',class_='ing ellipsis')
# 食材,使用strip()函数去掉了多余的空格
ingredients = tag_p.text.strip()
# 打印食材
print(ingredients)
写循环,存列表
这部分没什么需要讲解,所以我打算把它直接交给你来实操。
要求:写一个循环,提取当前页面的所有菜名、URL、食材,并将它存入列表。其中每一组菜名、URL、食材是一个小列表,小列表组成一个大列表。如下:
[[菜A,URL_A,食材A],[菜B,URL_B,食材B],[菜C,URL_C,食材C]]
现在,请开始练习,我会在稍后提供参考答案。
以下,是我提供的参考答案。
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')# 创建一个空列表,用于存储信息
list_all = []for food in list_foods:tag_a = food.find('a')# 菜名,使用strip()函数去掉多余的空格name = tag_a.text.strip()# 获取URLURL = 'http://www.xiachufang.com'+tag_a['href']tag_p = food.find('p',class_='ing ellipsis')# 食材,使用strip()函数去掉多余的空格ingredients = tag_p.text.strip()# 将菜名、URL、食材,封装为列表,添加进list_alllist_all.append([name,URL,ingredients])# 打印
print(list_all)
至此,一个项目就算从头到尾结束。
代码实现(二)
就像我们之前所说,这个项目还存在着另一个解决思路:我们分别提取所有的菜名、所有的URL、所有的食材。然后让菜名、URL、食材给一一对应起来。
对于这个实操,我不再一步一步为你讲解,而是换一种方式。我会为你简单描述大致思路,由你来自行写代码,结束之后再来和标准答案比照。
首先,获取数据,解析数据,略过。
去查找所有,包含菜名和URL的<p>标签。此处<p>标签是<a>标签的父标签。
为什么不直接选<a>标签?还记得我们怎么说的吗?在实践操作当中,其实常常会因为标签选取不当,或者网页本身的编写没做好板块区分,你可能会多打印出一些奇怪的东西。
当遇到这种糟糕的情况,一般有两种处理方案:数量太多而无规律,我们会换个标签提取;数量不多而有规律,我们会对提取的结果进行筛选——只要列表中的若干个元素就好。
这里如果是直接提取<a>标签,你就会遇到这种情况。如果你愿意,也可以试试看。
去查找所有,包含食材的<p>标签。
创建一个空列表,启动循环,循环长度等于<p>标签的总数——你可以借助range(len())语法。
在每一次的循环里,去提取一份菜名、URL、食材。拼接为小列表,小列表拼接成大列表。输出打印。
也就是说,换一种思路写代码:我们分别提取所有的菜名、所有的URL、所有的食材。然后让菜名、URL、食材给一一对应起来。
参考答案:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')# 查找包含菜名和URL的<p>标签
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含食材的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 创建一个空列表,用于存储信息
list_all = []
# 启动一个循环,次数等于菜名的数量
for x in range(len(tag_name)):# 提取信息,封装为列表。list_food = [tag_name[x].text.strip(),tag_name[x].find('a')['href'],tag_ingredients[x].text.strip()]# 将信息添加进list_all list_all.append(list_food)
# 打印
print(list_all)
一个项目,两种解法。恭喜你!全都掌握。当菜谱在手,大江南北,便少有你烹不出的风味。
恭喜你,成功入门爬虫~
复习总结
严格来说,我们这一关其实没有新的知识进入,它是一个比较纯粹的项目关卡,汇总代码如下:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')# 查找包含菜名和URL的<p>标签
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含食材的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 创建一个空列表,用于存储信息
list_all = []
# 启动一个循环,次数等于菜名的数量
for x in range(len(tag_name)):# 提取信息,封装为列表。list_food = [tag_name[x].text.strip(),tag_name[x].find('a')['href'],tag_ingredients[x].text.strip()]# 将信息添加进list_all list_all.append(list_food)
# 打印
print(list_all)# 以下是另外一种解法# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 创建一个空列表,用于存储信息
list_all = []for food in list_foods:tag_a = food.find('a')# 菜名,使用strip()函数去掉了多余的空格name = tag_a.text.strip()# 获取URLURL = 'http://www.xiachufang.com'+tag_a['href']tag_p = food.find('p',class_='ing ellipsis')# 食材,使用strip()函数去掉了多余的空格ingredients = tag_p.text.strip()# 将菜名、URL、食材,封装为列表,添加进list_alllist_all.append([name,URL,ingredients])# 打印
print(list_all)
这个项目里有许多东西,值得我们回过头来看,记录到小本本上,下面是我的总结:
确认目标-分析过程-代码实现,是我们做每一个项目的必经之路。未来在此基础上,还会有许多演化,但基础都是这些。
将想要的数据分别提取,再做组合是一种不错的思路。但是,如果数据的数量对不上,就会让事情比较棘手。比如,在我们的案例里,如果一个菜有多个做法,其数量也没规律,那么菜名和URL的数量就会对不上。
寻找最小共同父级标签是一种很常见的提取数据思路,它能有效规避这个问题。但有时候,可能需要你反复操作,提取数据。
所以在实际项目实操中,需要根据情况,灵活选择,灵活组合。我们本关卡所做的项目,只是刚刚好两种方式都可以爬取。
text获取到的是该标签内的纯文本信息,即便是在它的子标签内,也能拿得到。但提取属性的值,只能提取该标签本身的。
from bs4 import BeautifulSoupbs = BeautifulSoup('<p><a>惟有痴情难学佛</a>独无媚骨不如人</p>','html.parser')
tag = bs.find('p')
print(tag.text)
在爬虫实践当中,其实常常会因为标签选取不当,或者网页本身的编写没做好板块区分,你可能会多提取到出一些奇怪的东西。
当遇到这种糟糕的情况,一般有两种处理方案:数量太多而无规律,我们会换个标签提取;数量不多而有规律,我们会对提取的结果进行筛选——只要列表中的若干个元素就好。
以上,就是我要分享的全部信息。
爬虫,它是一项需要许多实操,才能灵活掌握的技能。欢迎你在后面,做更多的尝试。
在下一关,我们将会学习一种新的爬虫。具体是什么,容我卖个关子。期待你和我在周杰伦的歌声里相会!
我们下一关见!
相关文章:
【python爬虫】4.爬虫实操(菜品爬取)
文章目录 前言项目:解密吴氏私厨分析过程代码实现(一)获取与解析提取最小父级标签一组菜名、URL、食材写循环,存列表 代码实现(二)复习总结 前言 上一关,我们学习了用BeautifulSoup库解析数据和…...

深圳发墨西哥专线要多久才能清关?
深圳发往墨西哥专线的货物清关时间会受到多种因素的影响,包括货物的性质、数量、海关政策、运输方式以及货物的文件准备等。下面将详细介绍这些因素对清关时间的影响。 1.货物的性质和数量是影响清关时间的重要因素之一。 一般来说,墨西哥专线中普通商品…...
Java-泛型
文章目录 Java泛型什么是泛型?在哪里使用泛型?设计出泛型的好处是什么?动手设计一个泛型泛型的限定符泛型擦除泛型的通配符 结论 Java泛型 什么是泛型? Java泛型是一种编程技术,它允许在编译期间指定使用的数据类型。…...
【python爬虫】8.温故而知新
文章目录 前言回顾前路代码实现体验代码功能拆解获取数据解析提取数据存储数据 程序实现与总结 前言 Hello又见面了!上一关我们学习了爬虫数据的存储,并成功将QQ音乐周杰伦歌曲信息的数据存储进了csv文件和excel文件。 学到这里,说明你已经…...

vue3组合式api 父子组件数据同步v-model语法糖的用法
V-model 大多数情况是用在 表单数据上的, 但它不止这一个作用 父子组件的数据同步, 有一个 语法糖 v-model,这个方法简化了语法, 在elementplus中,都有很多地方使用, 所以我们要理解清楚 父组件 使用 v-mod…...
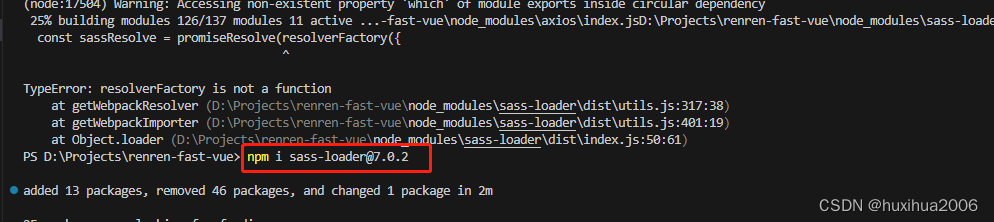
环境异常总结
1.vue项目 npm run dev 运行时报错:webpack-dev-server --inline --progress --config build/webpack.dev.conf.js 不是内部或外部命令 原因:webpack-dev-server存在问题 解决方案:指定 webpack-dev-server 低版本号 方法: 删除 …...
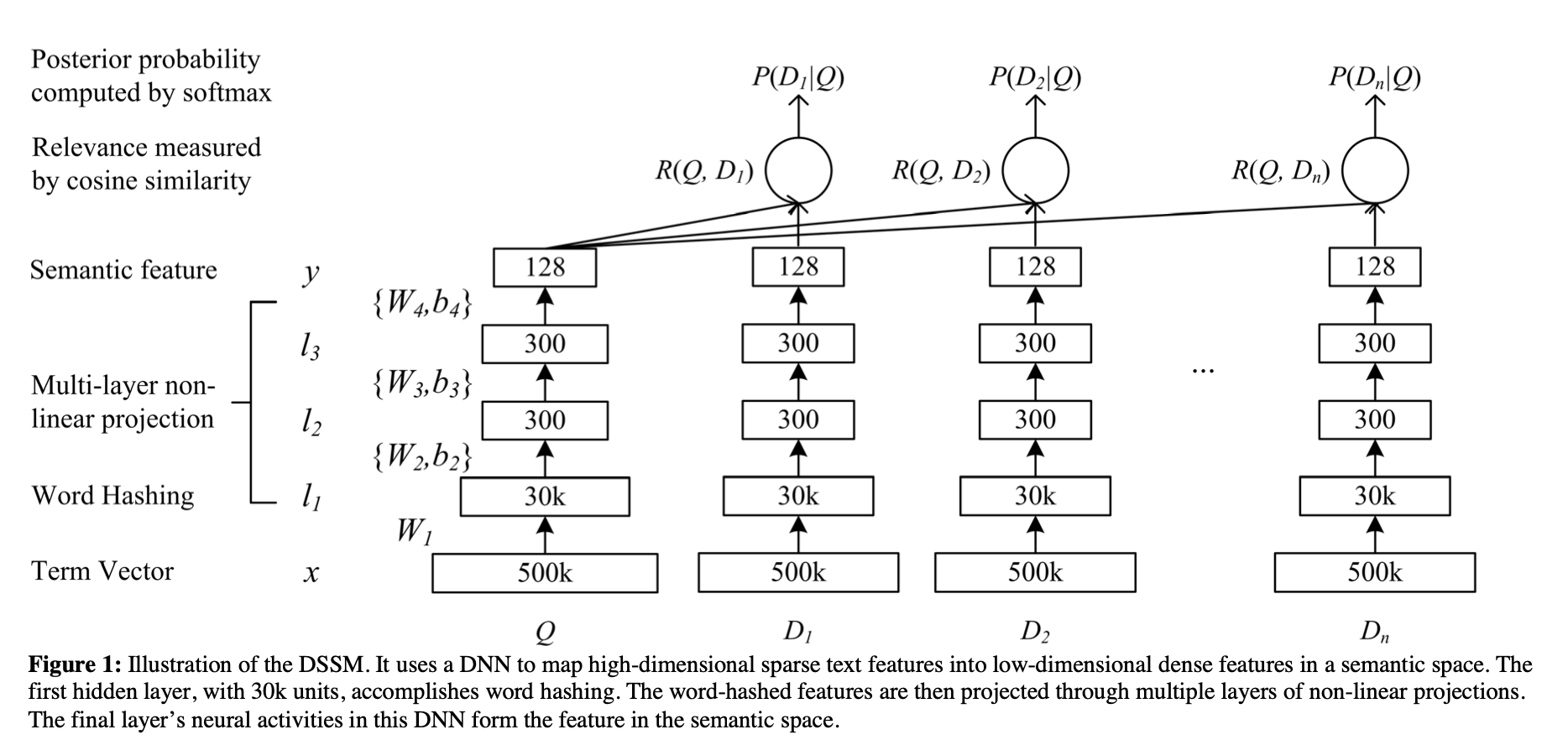
[论文笔记]DSSM
引言 这是DSSM论文的阅读笔记,后续会有一篇文章来复现它并在中文数据集上验证效果。 本文的标题翻译过来就是利用点击数据学习网页搜索中深层结构化语义模型,这篇论文被归类为信息检索,但也可以用来做文本匹配。 这是一篇经典的工作,在DSSM之前,通常使用传统机器学习的…...

Skip Connection——提高深度神经网络性能的利器
可以参考一下这篇知乎所讲 https://zhuanlan.zhihu.com/p/457590578 长跳跃连接用于将信息从编码器传播到解码器,以恢复在下采样期间丢失的信息...
EXCEL中点击单元格,所在行和列都改变颜色
在日常工作中,尤其是办公室工作人群,尝尝需要处理大量的数据,在对数据进行修改时,时长发生看错行的事情,导致数据越改越乱,因此,我常用的一种方法就是选中单元格时,所在行、列标记为…...
)
HAProxy(一)
四层负载均衡与七层负载均衡区别 四层负载均衡和七层负载均衡是两种不同的负载均衡方式,主要区别在于负载均衡的层级及其所支持的协议不同。 四层负载均衡,也称为传输层负载均衡,工作在 OSI 模型的传输层(第四层)&am…...
LeetCode--HOT100题(46)
目录 题目描述:114. 二叉树展开为链表(中等)题目接口解题思路代码 PS: 题目描述:114. 二叉树展开为链表(中等) 给你二叉树的根结点 root ,请你将它展开为一个单链表: 展开后的单链…...

深度探索JavaScript中的原型链机制
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...
一种基于WinDump自动抓包实现方法
本发明的技术方案包括以下步骤和组件: 配置抓包参数:设置抓包的IP、端口以及过滤包大小等参数,以控制抓取的数据范围。循环自动抓包:利用WinDump工具实现循环自动抓包功能,类似于记录日志的方式保留抓包数据。当抓包数…...

taro 支付宝/微信小程序/h5 上传 - base64的那些事儿
支付宝小程序临时path转base64 - 基础库2.0以下 function getImageInfo(path) {return new Promise(resolve > {my.getImageInfo({src: path,success: res > {resolve(res)}})}) } export async function getBase64InAlipay({ id, path }) {const { width, height } awa…...

java之SpringBoot基础、前后端项目、MyBatisPlus、MySQL、vue、elementUi
文章目录 前言JC-1.快速上手SpringBootJC-1-1.SpringBoot入门程序制作(一)JC-1-2.SpringBoot入门程序制作(二)JC-1-3.SpringBoot入门程序制作(三)JC-1-4.SpringBoot入门程序制作(四)…...
Vue-Router 一篇搞定 Vue3
前言 在 Web 前端开发中,路由是非常重要的一环,但是路由到底是什么呢? 从路由的用途上讲 路由是指随着浏览器地址栏的变化,展示给用户不同的页面。 从路由的实现原理上讲 路由是URL到函数的映射。它将 URL 和应用程序的不同部分…...

深度解读智能媒体服务的重组和进化
统一“顶设”的智能媒体服务。 邹娟|演讲者 大家好,首先欢迎各位来到LVS的阿里云专场,我是来自阿里云视频云的邹娟。我本次分享的主题为《从规模化到全智能:智能媒体服务的重组与进化》。 本次分享分为以上四部分,一是…...
亲测有效!Win7中如何安装高版本的NodeJS
正常情况下,Win7支持的Node.js最高版本是V13.14,但在开发过程中,有不少Vue项目或其他需要依赖Node环境的项目,对Node版本要求都比较高。对此,我们要么重装操作系统到Win8以上,要么就得想办法在Win7中安装高…...
用法)
Python基础__with open()用法
1、open与with open区别 open()完成后必须调用close()方法关闭文件,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的,由于文件读写时都有可能产生IOError,一旦出错&…...

深入理解 JavaScript 对象、属性、解构和增强语法
ECMA-262将对象定义为一组属性的无序集合。 1 内部属性描述 1.1 数据属性 [[Configurable]]:可配置性,直接定义在对象的属性该特性默认为true,表示可以对属性进行删除、修改等操作。[[Enumerable]]:可枚举性,直接定…...

揭秘Intel DCI与System Debugger:深入追踪CSME/BIOS在主机启动中的关键信息流
1. 认识Intel DCI与System Debugger 如果你曾经遇到过电脑开机卡在Logo界面、反复重启或者直接黑屏的情况,作为工程师的你一定想知道:到底哪里出了问题?这时候,Intel DCI(Direct Connect Interface)和Syste…...

STM32F103移植FreeRTOS实战:从零构建多任务系统
1. 项目概述:为什么要在STM32F103上跑RTOS? 如果你玩过一阵子STM32,特别是经典的“蓝桥杯”神板——STM32F103C8T6,那你大概率已经习惯了在 main 函数里写一个 while(1) 大循环,里面塞满了各种 HAL_Delay 和状态…...

如何用AI语音修复工具VoiceFixer:快速拯救受损音频的完整指南
如何用AI语音修复工具VoiceFixer:快速拯救受损音频的完整指南 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 还在为嘈杂的录音、失真的语音或老旧音频而烦恼吗?VoiceFixer是一…...

hot100 11盛最多水的容器
题目描述 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容…...

Arduino与树莓派协同开发:通信协议、实战项目与物联网应用
1. 项目概述:当开源硬件“大脑”遇上“小脑”如果你玩过乐高,大概能理解那种把不同功能的模块拼装起来,实现一个有趣功能的乐趣。在开源硬件的世界里,Arduino Uno和Raspberry Pi(树莓派)系列,就…...

别让“AI味”代码毁了你的项目:一份AI生成代码的质量评估与防御指南
别让“AI味”代码毁了你的项目:一份AI生成代码的质量评估与防御指南 前段时间,团队里一个新人在周会上展示了他用 AI 辅助完成的一个支付模块。代码跑通了,测试用例全绿,乍一看没什么问题。但我顺手点开一个 Service 层方法&#…...

探索现代媒体播放器的终极指南:免费专业播放解决方案
探索现代媒体播放器的终极指南:免费专业播放解决方案 【免费下载链接】mpv.net 🎞 mpv.net is a media player for Windows with a modern GUI. 项目地址: https://gitcode.com/gh_mirrors/mp/mpv.net 还在为Windows平台找不到一款既强大又易用的…...

DayZCommunityOfflineMode:构建专属末日世界的完整解决方案
DayZCommunityOfflineMode:构建专属末日世界的完整解决方案 【免费下载链接】DayZCommunityOfflineMode A community made offline mod for DayZ Standalone 项目地址: https://gitcode.com/gh_mirrors/da/DayZCommunityOfflineMode DayZCommunityOfflineMod…...

通过Taotoken CLI工具一键配置开发环境中的多工具API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境中的多工具API密钥 在团队协作开发或需要同时使用多个AI工具的项目中,手动为每个…...

高炉智变:12期实战带你玩转工业AI落地~系列文章11:可解释AI实践:SHAP+LIME打开高炉模型的“黑箱“
🎯 高炉智变11|可解释AI实践:SHAPLIME打开高炉模型的"黑箱" 📅 本文目录 一、前言:AI可解释性的重要性二、SHAP可解释性框架三、LIME局部解释方法四、高炉模型可解释性实践五、实战代码实现六、总结与预告 一…...