41、Flink之Hive 方言介绍及详细示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
33、Flink之hive介绍与简单示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
文章目录
- Flink 系列文章
- 一、Hive 方言介绍
- 1、使用 Hive 方言
- 1)、SQL 客户端
- 2)、Table API
- 2、DDL
- 1)、show
- 2)、catalog
- 2)、database
- 3)、table
- 4)、VIEW
- 5)、FUNCTION
- 3、DML & DQL
- 4、注意
本文介绍了flink sql中使用hive方言的具体示例,每个示例都是经过运行的,有些示例为了体现出关键命令的作用,保留了出错信息。
本文依赖环境是hadoop、zookeeper、hive、flink环境好用,具体示例是在1.13版本中运行的(因为hadoop集群环境是基于jdk8的,flink1.17版本需要jdk11)。
更多的内容详见后续关于hive的介绍。如果你的环境不能运行本文示例,请参考:42、Flink 的table api与sql之Hive Catalog
一、Hive 方言介绍
从 1.11.0 开始,在使用 Hive 方言时,Flink 允许用户用 Hive 语法来编写 SQL 语句。通过提供与 Hive 语法的兼容性,我们旨在改善与 Hive 的互操作性,并减少用户需要在 Flink 和 Hive 之间切换来执行不同语句的情况。
1、使用 Hive 方言
Flink 目前支持两种 SQL 方言: default 和 hive。你需要先切换到 Hive 方言,然后才能使用 Hive 语法编写。下面介绍如何使用 SQL 客户端和 Table API 设置方言。 还要注意,你可以为执行的每个语句动态切换方言。无需重新启动会话即可使用其他方言。
1)、SQL 客户端
SQL 方言可以通过 table.sql-dialect 属性指定。因此你可以通过 SQL 客户端 yaml 文件中的 configuration 部分来设置初始方言。
execution:planner: blinktype: batchresult-mode: tableconfiguration:table.sql-dialect: hive
或者在 SQL 客户端启动后设置方言。
----使用hive方言
Flink SQL> set table.sql-dialect=hive;
[INFO] Session property has been set.---使用默认的方言
Flink SQL> set table.sql-dialect=default;
Hive Session ID = 90f6200f-2af7-4045-93fc-9a1fbe77fcfd
[INFO] Session property has been set.2)、Table API
你可以使用 Table API 为 TableEnvironment 设置方言。
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner()...build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
// to use hive dialect
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
// to use default dialect
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);- 示例
import java.util.HashMap;
import java.util.Map;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabase;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseAlreadyExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.types.Row;/*** @author alanchan**/
public class TestCreateHiveTable {public static final String tableName = "alan_hivecatalog_hivedb_testTable";public static final String hive_create_table_sql = "CREATE TABLE " + tableName + " (\n" + " id INT,\n" + " name STRING,\n" + " age INT" + ") " + "TBLPROPERTIES (\n" + " 'sink.partition-commit.delay'='5 s',\n" + " 'sink.partition-commit.trigger'='partition-time',\n" + " 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")";/*** @param args* @throws DatabaseAlreadyExistException* @throws CatalogException*/public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";String name = "alan_hive";// default 数据库名称String defaultDatabase = "default";HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);tenv.registerCatalog("alan_hive", hiveCatalog);tenv.useCatalog("alan_hive");String newDatabaseName = "alan_hivecatalog_hivedb";tenv.useDatabase(newDatabaseName);// 创建表tenv.getConfig().setSqlDialect(SqlDialect.HIVE);tenv.executeSql(hive_create_table_sql);// 插入数据String insertSQL = "insert into alan_hivecatalog_hivedb_testTable values (1,'alan',18)";tenv.executeSql(insertSQL);// 查询数据String selectSQL = "select * from alan_hivecatalog_hivedb_testTable" ;Table table = tenv.sqlQuery(selectSQL);table.printSchema();DataStream<Tuple2<Boolean, Row>> result = tenv.toRetractStream(table, Row.class);result.print();env.execute();}}
2、DDL
本章节列出了 Hive 方言支持的 DDL 语句。我们主要关注语法。具体的hive语法可以参考hive的相关文档。比如本人关于hive的专栏:
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
1)、show
SHOW CATALOGS
SHOW CURRENT CATALOG
SHOW DATABASES
SHOW CURRENT DATABASE
SHOW TABLES
SHOW VIEWS
SHOW FUNCTIONS
SHOW MODULES
SHOW FULL MODULES
2)、catalog
关于hivecatalog的操作详见下文:
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
42、Flink 的table api与sql之Hive Catalog
----创建
CREATE CATALOG alan_hivecatalog WITH ('type' = 'hive','default-database' = 'testhive','hive-conf-dir' = '/usr/local/bigdata/apache-hive-3.1.2-bin/conf'
);
---使用
use alan_hivecatalog ;2)、database
----创建
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION fs_path][WITH DBPROPERTIES (property_name=property_value, ...)];
--------修改
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
ALTER (DATABASE|SCHEMA) database_name SET LOCATION fs_path;
----删除
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
------使用
USE database_name;
- 示例
----------------------sql语句
CREATE DATABASE IF NOT EXISTS alan_testdatabase
comment "This is a database comment"
with dbproperties ('createdBy'='alan');
---hive执行,flink sql不支持语法
DESCRIBE DATABASE EXTENDED alan_testdatabase;--更改数据库属性
ALTER DATABASE alan_testdatabase SET DBPROPERTIES ('createdBy'='alanchan','createddate'='2023-08-31');
--更改数据库所有者
ALTER DATABASE alan_testdatabase SET OWNER USER alanchan;
--更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
------------------创建数据库
Flink SQL> use catalog alan_hivecatalog;
Hive Session ID = 094c27ff-fb61-485c-b4ab-3119881224c9
[INFO] Execute statement succeed.Flink SQL> CREATE DATABASE IF NOT EXISTS alan_testdatabase
> comment "This is a database comment"
> with dbproperties ('createdBy'='alan');
Hive Session ID = e406eed8-6575-4c0e-8b1b-b99db288a018
[INFO] Execute statement succeed.Flink SQL> show databases;
Hive Session ID = f37fa06e-3a98-4c63-a304-d431d03c6bfa
+-------------------------+
| database name |
+-------------------------+
| alan_hivecatalog_hivedb |
| alan_testdatabase |
| default |
| test |
| testhive |
+-------------------------+
5 rows in setFlink SQL> DESCRIBE DATABASE EXTENDED alan_testdatabase;
Hive Session ID = 94218191-bcce-4722-8a05-2f11e6d6807b
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.client.gateway.SqlExecutionException: Failed to parse statement: DESCRIBE DATABASE EXTENDED alan_testdatabase
----------------修改数据库属性
Flink SQL> ALTER DATABASE alan_testdatabase SET DBPROPERTIES ('createdBy'='alanchan','createddate'='2023-08-31');
Hive Session ID = 6a598d85-8468-4f66-969f-8e4e1fa1981d
[INFO] Execute statement succeed.Flink SQL> ALTER DATABASE alan_testdatabase SET OWNER USER 'alanchan';
Hive Session ID = e9ce6a7a-6d89-48f8-81c9-5a303706c0f9
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.planner.delegation.hive.copy.HiveASTParseException: line 1:48 cannot recognize input near ''alanchan'' '<EOF>' '<EOF>' in identifier for principal specFlink SQL> ALTER DATABASE alan_testdatabase SET OWNER USER alanchan;
Hive Session ID = 7975a16d-cd2b-4be5-9a1e-90b1454860ed
[INFO] Execute statement succeed.------------------------hive中查询数据库属性
0: jdbc:hive2://server4:10000> DESCRIBE DATABASE EXTENDED alan_testdatabase;
+--------------------+-----------------------------+-------------------+-------------+-------------+-------------------+
| db_name | comment | location | owner_name | owner_type | parameters |
+--------------------+-----------------------------+-------------------+-------------+-------------+-------------------+
| alan_testdatabase | This is a database comment | location/in/test | | USER | {createdBy=alan} |
+--------------------+-----------------------------+-------------------+-------------+-------------+-------------------+
1 row selected (0.048 seconds)
0: jdbc:hive2://server4:10000> DESCRIBE DATABASE EXTENDED alan_testdatabase;
+--------------------+-----------------------------+-------------------+-------------+-------------+-----------------------------------------------+
| db_name | comment | location | owner_name | owner_type | parameters |
+--------------------+-----------------------------+-------------------+-------------+-------------+-----------------------------------------------+
| alan_testdatabase | This is a database comment | location/in/test | | USER | {createdBy=alanchan, createddate=2023-08-31} |
+--------------------+-----------------------------+-------------------+-------------+-------------+-----------------------------------------------+
1 row selected (0.049 seconds)
0: jdbc:hive2://server4:10000> DESCRIBE DATABASE EXTENDED alan_testdatabase;
+--------------------+-----------------------------+-------------------+-------------+-------------+-----------------------------------------------+
| db_name | comment | location | owner_name | owner_type | parameters |
+--------------------+-----------------------------+-------------------+-------------+-------------+-----------------------------------------------+
| alan_testdatabase | This is a database comment | location/in/test | alanchan | USER | {createdBy=alanchan, createddate=2023-08-31} |
+--------------------+-----------------------------+-------------------+-------------+-------------+-----------------------------------------------+
1 row selected (0.047 seconds)
---------flink drop 数据库
Flink SQL> drop database alan_testdatabase;
Hive Session ID = 30c71d25-a8fa-4b84-99b9-b6441937b6cf
[INFO] Execute statement succeed.3)、table
------创建
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [column_constraint] [COMMENT col_comment], ... [table_constraint])][COMMENT table_comment][PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)][[ROW FORMAT row_format][STORED AS file_format]][LOCATION fs_path][TBLPROPERTIES (property_name=property_value, ...)]row_format:: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char][NULL DEFINED AS char]| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, ...)]file_format:: SEQUENCEFILE| TEXTFILE| RCFILE| ORC| PARQUET| AVRO| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classnamecolumn_constraint:: NOT NULL [[ENABLE|DISABLE] [VALIDATE|NOVALIDATE] [RELY|NORELY]]table_constraint:: [CONSTRAINT constraint_name] PRIMARY KEY (col_name, ...) [[ENABLE|DISABLE] [VALIDATE|NOVALIDATE] [RELY|NORELY]]--------修改
ALTER TABLE table_name RENAME TO new_table_name;
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, property_name = property_value, ... );
ALTER TABLE table_name [PARTITION partition_spec] SET LOCATION fs_path;
--如果指定了 partition_spec,那么必须完整,即具有所有分区列的值。如果指定了,该操作将作用在对应分区上而不是表上。
ALTER TABLE table_name [PARTITION partition_spec] SET FILEFORMAT file_format;
--如果指定了 partition_spec,那么必须完整,即具有所有分区列的值。如果指定了,该操作将作用在对应分区上而不是表上。Update SerDe Properties #
ALTER TABLE table_name [PARTITION partition_spec] SET SERDE serde_class_name [WITH SERDEPROPERTIES serde_properties];ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;serde_properties:: (property_name = property_value, property_name = property_value, ... )
--如果指定了 partition_spec,那么必须完整,即具有所有分区列的值。如果指定了,该操作将作用在对应分区上而不是表上。Add Partitions #
ALTER TABLE table_name ADD [IF NOT EXISTS] (PARTITION partition_spec [LOCATION fs_path])+;
Drop Partitions #
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, ...];
Add/Replace Columns #
ALTER TABLE table_nameADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)[CASCADE|RESTRICT]
Change Column #
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
Drop #
DROP TABLE [IF EXISTS] table_name;--------删除drop table tableName;- 基本表操作示例
Flink SQL> create table student(
> num int,
> name string,
> sex string,
> age int,
> dept string)
> row format delimited
> fields terminated by ',';
Hive Session ID = d3a87e7c-4175-4c07-957a-4e855a537654
[INFO] Execute statement succeed.Flink SQL> show tables;
Hive Session ID = 820371a4-d23f-4660-a558-905bd6c578e1
+------------+
| table name |
+------------+
| student |
+------------+
1 row in setFlink SQL> create external table student_ext(
> num int,
> name string,
> sex string,
> age int,
> dept string)
> row format delimited
> fields terminated by ',';
Hive Session ID = 57656797-60f0-420e-8a0e-873ef5356303
[INFO] Execute statement succeed.Flink SQL> show tables;
Hive Session ID = 060b1ab4-58a5-4377-b86c-4941e2dd672e
+-------------+
| table name |
+-------------+
| student |
| student_ext |
+-------------+
2 rows in setFlink SQL> desc student;
Hive Session ID = 25346927-8a02-4178-ae17-0444d7c2ded4
+------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+--------+------+-----+--------+-----------+
| num | INT | true | | | |
| name | STRING | true | | | |
| sex | STRING | true | | | |
| age | INT | true | | | |
| dept | STRING | true | | | |
+------+--------+------+-----+--------+-----------+
5 rows in setFlink SQL> desc student_ext;
Hive Session ID = 4858109e-8e2c-49e0-9319-37dc347de73a
+------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+--------+------+-----+--------+-----------+
| num | INT | true | | | |
| name | STRING | true | | | |
| sex | STRING | true | | | |
| age | INT | true | | | |
| dept | STRING | true | | | |
+------+--------+------+-----+--------+-----------+
5 rows in set
Flink SQL> show tables;
Hive Session ID = a6bc1062-de92-4aa3-abda-587124663002
+-------------+
| table name |
+-------------+
| student |
| student1 |
| student_ext |
+-------------+
3 rows in set-----------删除表
Flink SQL> drop table student;
Hive Session ID = e270ce9f-3bd1-4241-9ad4-a8e42405645b
[INFO] Execute statement succeed.-----------修改表
--1、更改表名
ALTER TABLE student RENAME TO alan_student;
Flink SQL> ALTER TABLE student RENAME TO alan_student;
Hive Session ID = f0659cc5-e578-403e-8a9e-0989a64652dc
[INFO] Execute statement succeed.Flink SQL> show tables;
Hive Session ID = 6a1fdf70-43d5-40bd-86f7-4430b2d30e83
+--------------+
| table name |
+--------------+
| alan_student |
| student_ext |
+--------------+
2 rows in set--2、更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );
--更改表注释
ALTER TABLE alan_student SET TBLPROPERTIES ('comment' = "new comment for alan_student table");
Flink SQL> ALTER TABLE alan_student SET TBLPROPERTIES ('comment' = "new comment for alan_student table");
Hive Session ID = c3a1f8ee-11fd-4e33-94bd-e941e2928c9d
[INFO] Execute statement succeed.
0: jdbc:hive2://server4:10000> DESC FORMATTED alan_student;
+-------------------------------+----------------------------------------------------+-------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-------------------------------------+
| # col_name | data_type | comment |
| num | int | |
| name | string | |
| sex | string | |
| age | int | |
| dept | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | alan_testdatabase | NULL |
| OwnerType: | USER | NULL |
| Owner: | null | NULL |
| CreateTime: | Thu Aug 31 14:02:55 CST 2023 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopHAcluster/user/hive/warehouse/alan_testdatabase.db/alan_student | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | bucketing_version | 2 |
| | comment | new comment for alan_student table |
| | numFiles | 0 |
| | totalSize | 0 |
| | transient_lastDdlTime | 1693461775 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | , |
| | serialization.format | , |
+-------------------------------+----------------------------------------------------+-------------------------------------+
34 rows selected (0.069 seconds)--3、更改列名称/类型/位置/注释
CREATE TABLE test_change (a int, b int, c int);
Flink SQL> CREATE TABLE test_change (a int, b int, c int);// 更改列名称
ALTER TABLE test_change CHANGE a a1 INT;
Flink SQL> ALTER TABLE test_change CHANGE a a1 INT;
Flink SQL> desc test_change;
+------+------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+------+------+-----+--------+-----------+
| a1 | INT | true | | | |
| b | INT | true | | | |
| c | INT | true | | | |
+------+------+------+-----+--------+-----------+// 更改列名称和类型
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
Flink SQL> ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
Flink SQL> desc test_change;
+------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+--------+------+-----+--------+-----------+
| b | INT | true | | | |
| a2 | STRING | true | | | |
| c | INT | true | | | |
+------+--------+------+-----+--------+-----------+
--4、添加/替换列
--使用ADD COLUMNS,可以将新列添加到现有列的末尾但在分区列之前。
--REPLACE COLUMNS 将删除所有现有列,并添加新的列集。
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type,...);
Flink SQL> desc alan_student;
+------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+--------+------+-----+--------+-----------+
| num | INT | true | | | |
| name | STRING | true | | | |
| sex | STRING | true | | | |
| age | INT | true | | | |
| dept | STRING | true | | | |
+------+--------+------+-----+--------+-----------+
Flink SQL> ALTER TABLE alan_student ADD COLUMNS (balance int);
Flink SQL> desc alan_student;
+---------+--------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+---------+--------+------+-----+--------+-----------+
| num | INT | true | | | |
| name | STRING | true | | | |
| sex | STRING | true | | | |
| age | INT | true | | | |
| dept | STRING | true | | | |
| balance | INT | true | | | |
+---------+--------+------+-----+--------+-----------+Flink SQL> ALTER TABLE alan_student REPLACE COLUMNS (age int);
Flink SQL> desc alan_student;
+------+------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+------+------+-----+--------+-----------+
| age | INT | true | | | |
+------+------+------+-----+--------+-----------+- 分区表操作示例
--1、增加分区
创建一个单分区表
create table user_dept (num int,name string,sex string,age int)
partitioned by (dept string)
row format delimited fields terminated by ',';
--加载数据
load data inpath '/hivetest/partition/students_MA.txt' into table user_dept partition(dept ="MA");-- 一次添加一个分区
ALTER TABLE user_dept ADD PARTITION (dept='IS') '/user/hive/warehouse/testhive.db/user_dept/dept=IS';
--加载数据
load data inpath '/hivetest/partition/students_IS.txt' into table user_dept partition(dept ="IS");-- 添加多级分区
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...];
partition_spec:: (partition_column = partition_col_value, partition_column = partition_col_value, ...)--创建一个二级分区表
create table user_dept_sex (id int, name string,age int)
partitioned by (dept string, sex string)
row format delimited fields terminated by ",";
--增加多分区
ALTER TABLE user_dept_sex ADD PARTITION (dept='MA', sex='M')
PARTITION (dept='MA', sex='F')
PARTITION (dept='IS', sex='M')
PARTITION (dept='IS', sex='F') ;
--加载数据
load data inpath '/hivetest/partition/user_dept/ma/m' into table user_dept_sex partition(dept='MA', sex='M');
load data inpath '/hivetest/partition/user_dept/ma/f' into table user_dept_sex partition(dept='MA', sex='F');
load data inpath '/hivetest/partition/user_dept/is/m' into table user_dept_sex partition(dept='IS', sex='M');
load data inpath '/hivetest/partition/user_dept/is/f' into table user_dept_sex partition(dept='IS', sex='F');--2、rename partition
--2、重命名分区
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;ALTER TABLE user_dept_sex PARTITION (dept='MA', sex='M') RENAME TO PARTITION (dept='MA', sex='Male');
ALTER TABLE user_dept_sex PARTITION (dept='MA', sex='F') RENAME TO PARTITION (dept='MA', sex='Female');
ALTER TABLE user_dept_sex PARTITION (dept='IS', sex='M') RENAME TO PARTITION (dept='IS', sex='Male');
ALTER TABLE user_dept_sex PARTITION (dept='IS', sex='F') RENAME TO PARTITION (dept='IS', sex='Female');--3、删除分区
delete partition
--删除表的分区。这将删除该分区的数据和元数据。
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2008-08-08', country='us');
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2008-08-08', country='us') PURGE; --直接删除数据 不进垃圾桶--5、修改分区
alter partition
--更改分区文件存储格式
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET FILEFORMAT file_format;
--更改分区位置
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET LOCATION "new location";
4)、VIEW
--创建
CREATE VIEW [IF NOT EXISTS] view_name [(column_name, ...) ][COMMENT view_comment][TBLPROPERTIES (property_name = property_value, ...)]AS SELECT ...;
--注意: 变更视图只在 Table API 中有效,SQL 客户端不支持。
--修改
ALTER VIEW view_name RENAME TO new_view_name;
ALTER VIEW view_name SET TBLPROPERTIES (property_name = property_value, ... );
ALTER VIEW view_name AS select_statement;
--删除
DROP VIEW [IF EXISTS] view_name;
- 示例
--hive中有一张真实的基础表dim_user
select * from test.dim_user;--1、创建视图
create view dim_user_v as select * from dim_user limit 4;--从已有的视图中创建视图
create view dim_user_from_v as select * from dim_user_v limit 2;--2、显示当前已有的视图
show tables;
show views;--hive v2.2.0之后支持--3、视图的查询使用
select * from dim_user_v ;
select * from dim_user_from_v ;--4、查看视图定义
show create table dim_user_v ;--5、删除视图
drop view dim_user_from_v;--6、更改视图属性
alter view dim_user_v set TBLPROPERTIES ('comment' = 'This is a view');--7、更改视图定义
alter view dim_user_v as select name from dim_user limit 2;
-----------------------flink sql cli 操作记录
Flink SQL> select * from dim_user;+----+--------------------------------+--------------------------------+
| op | id | name |
+----+--------------------------------+--------------------------------+
| +I | 4 | 赵六 |
| +I | 5 | alan |
| +I | 1 | 张三 |
| +I | 2 | 李四 |
| +I | 3 | 王五 |
+----+--------------------------------+--------------------------------+
Received a total of 5 rowsFlink SQL> create view dim_user_v as select * from dim_user limit 4;Flink SQL> create view dim_user_from_v as select * from dim_user_v limit 2;Flink SQL> show views;
Hive Session ID = ebae650c-ae23-4262-b9da-8ccef16d1b91
+-----------------+
| view name |
+-----------------+
| dim_user_from_v |
| dim_user_v |
+-----------------+
2 rows in setFlink SQL> select * from dim_user_v ;+----+--------------------------------+--------------------------------+
| op | id | name |
+----+--------------------------------+--------------------------------+
| +I | 1 | 张三 |
| +I | 2 | 李四 |
| +I | 3 | 王五 |
| +I | 4 | 赵六 |
+----+--------------------------------+--------------------------------+
Received a total of 4 rowsFlink SQL> show create table dim_user_v ;
Hive Session ID = 62802230-2420-484c-9a41-a66d45be3b3c
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.client.gateway.SqlExecutionException: Failed to parse statement: show create table dim_user_vFlink SQL> select * from dim_user_from_v ;
+----+--------------------------------+--------------------------------+
| op | id | name |
+----+--------------------------------+--------------------------------+
| +I | 1 | 张三 |
| +I | 2 | 李四 |
+----+--------------------------------+--------------------------------+
Received a total of 2 rowsFlink SQL> drop view dim_user_from_v;Flink SQL> alter view dim_user_v set TBLPROPERTIES ('comment' = 'This is a view');Flink SQL> alter view dim_user_v as select name from dim_user limit 2;Flink SQL> show views;
+------------+
| view name |
+------------+
| dim_user_v |
+------------+
1 row in setFlink SQL> select * from dim_user_v;
+----+--------------------------------+
| op | name |
+----+--------------------------------+
| +I | 张三 |
| +I | 李四 |
+----+--------------------------------+
Received a total of 2 rows5)、FUNCTION
--创建
CREATE FUNCTION function_name AS class_name;
--删除
DROP FUNCTION [IF EXISTS] function_name;
- 示例
更多的示例参考hive专栏的部分:7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
Flink SQL> select current_date();
+----+------------+
| op | _o__c0 |
+----+------------+
| +I | 2023-08-31 |
+----+------------+
Received a total of 1 rowFlink SQL> select floor(3.1415926);
+----+------------+
| op | _o__c0 |
+----+------------+
| +I | 3 |
+----+------------+
Received a total of 1 row3、DML & DQL
Hive 方言支持常用的 Hive DML 和 DQL 。 下表列出了一些 Hive 方言支持的语法。
SORT/CLUSTER/DISTRIBUTE BY
Group By
Join
Union
LATERAL VIEW
Window Functions
SubQueries
CTE
INSERT INTO dest schema
Implicit type conversions
为了实现更好的语法和语义的兼容,强烈建议使用 HiveModule 并将其放在 Module 列表的首位,以便在函数解析时优先使用 Hive 内置函数。
Hive 方言不再支持 Flink SQL 语法 。 若需使用 Flink 语法,请切换到 default 方言。
以下是一个使用 Hive 方言的示例。
注意:hive以流模式运行时不能insert overwrite插入数据
CREATE CATALOG alan_hivecatalog WITH ('type' = 'hive','default-database' = 'testhive','hive-conf-dir' = '/usr/local/bigdata/apache-hive-3.1.2-bin/conf'
);
use catalog alan_hivecatalog;
set table.sql-dialect=hive;
load module hive;
use modules hive,core;
select explode(array(1,2,3));
create table tbl (key int,value string);
set execution.runtime-mode=streaming;
insert into table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');
select * from tbl;--------------------flink sql 操作
Flink SQL> select explode(array(1,2,3));
Hive Session ID = 7d3ae2d5-24f3-4d97-9897-83c8a9abda9b
[ERROR] Could not execute SQL statement. Reason:
org.apache.hadoop.hive.ql.parse.SemanticException: Invalid function explodeFlink SQL> set table.sql-dialect=hive;Flink SQL> select explode(array(1,2,3));
Hive Session ID = c0b87333-4957-4c18-b197-27649a3f2ae2
[ERROR] Could not execute SQL statement. Reason:
org.apache.hadoop.hive.ql.parse.SemanticException: Invalid function explodeFlink SQL> load module hive;Flink SQL> use modules hive,core;Flink SQL> select explode(array(1,2,3));+----+-------------+
| op | col |
+----+-------------+
| +I | 1 |
| +I | 2 |
| +I | 3 |
+----+-------------+
Received a total of 3 rowsFlink SQL> create table tbl (key int,value string);Flink SQL> insert overwrite table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');
Hive Session ID = 12fe08fa-5e63-44b2-8fc3-a90064959451
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Streaming mode not support overwrite.Flink SQL> set execution.runtime-mode=batch;
Hive Session ID = 4f17cc70-165c-4540-a299-874b66458521
[INFO] Session property has been set.Flink SQL> insert overwrite table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');
Hive Session ID = 1923623f-03d3-44b4-93ab-ee8498c5da06
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException: Checkpoint is not supported for batch jobs.Flink SQL> set execution.runtime-mode=streaming; Flink SQL> insert into table tbl values (5,'e'),(1,'a'),(1,'a'),(3,'c'),(2,'b'),(3,'c'),(3,'c'),(4,'d');Flink SQL> select * from tbl;
+----+-------------+--------------------------------+
| op | key | value |
+----+-------------+--------------------------------+
| +I | 5 | e |
| +I | 1 | a |
| +I | 1 | a |
| +I | 3 | c |
| +I | 2 | b |
| +I | 3 | c |
| +I | 3 | c |
| +I | 4 | d |
+----+-------------+--------------------------------+
Received a total of 8 rows4、注意
以下是使用 Hive 方言的一些注意事项。
- Hive 方言只能用于操作 Hive 对象,并要求当前 Catalog 是一个 HiveCatalog 。
- Hive 方言只支持 db.table 这种两级的标识符,不支持带有 Catalog 名字的标识符。
- 虽然所有 Hive 版本支持相同的语法,但是一些特定的功能是否可用仍取决于你使用的Hive 版本。例如,更新数据库位置 只在 Hive-2.4.0 或更高版本支持。
- 执行 DML 和 DQL 时应该使用 HiveModule 。
以上,介绍了flink sql中使用hive方言的具体。
相关文章:

41、Flink之Hive 方言介绍及详细示例
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

docker环境安装软件、更换镜像源以及E: Unable to locate package xxx解决
docker环境安装vim、ifconfig、ping、更换镜像源以及E: Unable to locate package vim 一. E: Unable to locate package vim 问题解决一、问题分析二、解决方案三、再次安装四. 此镜像源已失效 二. 解决 “E: 仓库xx没有 Release 文件。N: 无法安全地用该源进行更新࿰…...
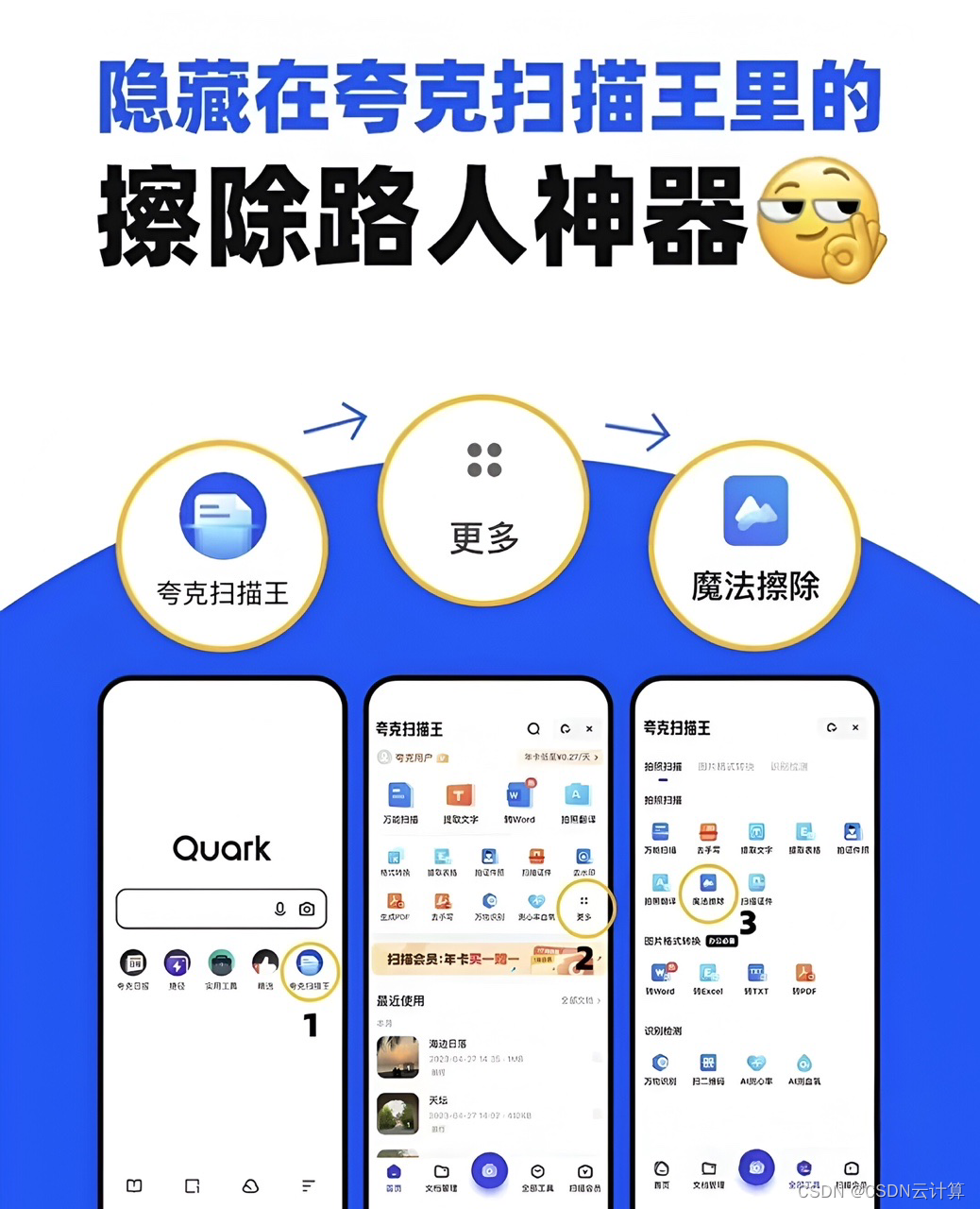
夸克扫描王App用上了AI大模型 让扫描更清楚、提取文字更方便
对上班族来说,找到一个好用的工具类APP,绝对可以提升工作效率。比如最常见的扫描文件,公司的扫描仪虽然好用但是很难进行深度编辑且不能外出使用;很多手机App也有扫描功能,但技术能力总是差一点,当面对复杂…...

代价高昂的 IT 错误:识别并避免供应商锁定
陷入不提供所需服务的云服务器合同中可能会非常痛苦、令人沮丧且成本高昂。 供应商锁定是提供商难以切换的地方,这意味着企业迁移到新供应商的成本太高、破坏性太大或耗时。 这使得公司受到供应商的摆布,尽管该服务可能无法提供他们所需的可靠性或可扩…...
HBase集群环境搭建与测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...

【iOS】Masonry的基本使用
文章目录 前言一、使用Masonry的原因二、约束的常识三、Masonry的简单使用四、Masonry的用例总结 前言 暑假安装了cocoapods,简单使用其调用了SVGKit,但是没有学习Masonry,特此总结博客记录Masonry的学习 一、使用Masonry的原因 Masonry是一…...
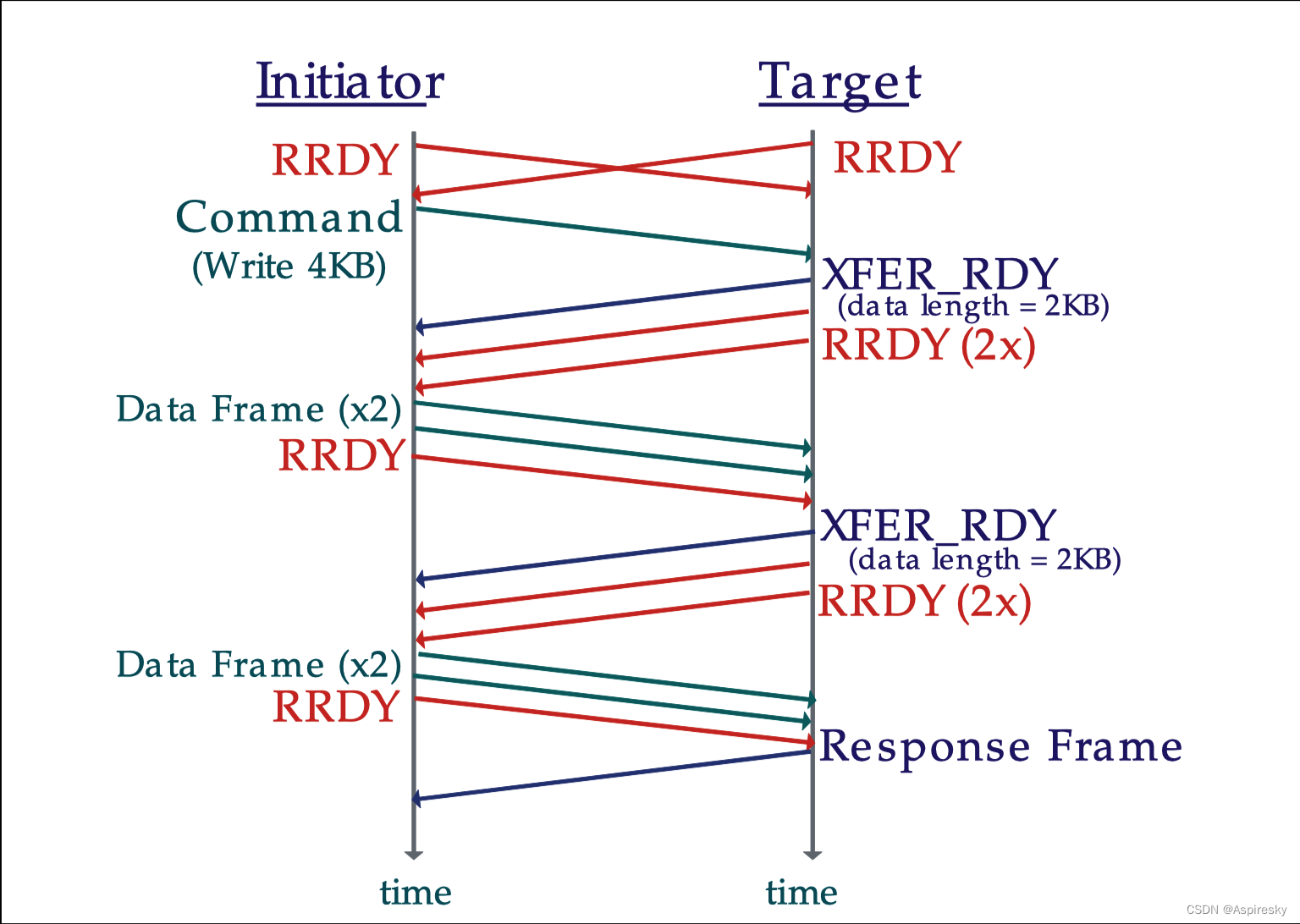
浅析SAS协议:链路层
文章目录 概述原语通用原语连接管理原语连接通信原语 地址帧IDENTIFY地址帧OPEN地址帧 链路复位Link ResetHard ResetSATA的Link Reset 连接管理建立连接连接仲裁 流量控制SSP流控Credit Advance SMP流控 相关参考 概述 SAS链路层用于定义原语、地址帧以及连接相关的内容&…...

ES6之浅尝辄止1:class的用法
class是es6新增的一种语法糖,用于简化js中构造类的过程 1.es5中如何构造类? function Person(name,age){this.name name;this.age age; } Person.prototype.sayName function(){return this.name; } let p1 new Person(小明,22);2.es6中的class方式…...

django-发送邮件
一、业务场景 业务警告 邮箱验证 密码找回 二、邮件相关协议 1.SMYTP(简答邮件传输协议 25端口) 属于“推送”协议 负责发送 2.IMAP(交互式邮件访问协议,应用层协议,143端口) 用于从本地邮件客户端…...

IP私域系统搭建课,视频号打通你的个人ip私域
标题:搭建IP私域系统课程:打通视频号,打造个人IP私域的关键策略 导语: 在当今信息爆炸的时代,个人IP(知识产权)的价值越来越受到重视。搭建IP私域系统通过打通视频号,成为了打造个人…...
咸虾米之一些快捷方式的操作,一行方块的左右滑动,方块在一区域内的任意移动
由于本着只学习微信小程序的目的,上面的几篇博文都是跟着黑马程序的课程走的!后面的就讲解uni-app的实验呢!一个人的精力是有限的,于是换了们课程继续深造微信小程序!!! 以下是在 .wxml中的一些…...

Linux 高级指令
十个常用高级Linux指令、其具体用法和示例: 1.grep:用于搜索指定文本内容,可以通过正则表达式匹配搜索。 用法示例:在当前目录下搜索包含关键词“hello”的文件并列出文件名: grep -r "hello" 2.find&a…...

江苏移动基于OceanBase稳步创新推进核心数据库分布式升级
*本文首发自《中国电信业》 数字经济时代,数据库作为企业核心数据存储、处理、挖潜等方面的关键载体,重要性日益凸显。对于运营商而言,数据库具有行业用户数量多、访问数量多、业务复杂度高、数据安全性高、响应要求性高以及需要 7*24 小时服…...

6. 删除顺序表中的重复元素
p17 6. 删除顺序表中的重复元素 #include<stdio.h> #include<stdlib.h> #define MaxSize 100 typedef struct {int* data;int capacity;int length; }SeqList;int InitList(SeqList &L) {L.data (int*)malloc(MaxSize * sizeof(int));L.capacity MaxSize;L.l…...

Vue——axios的二次封装
文章目录 一、请求和传递参数1、get 请求2、post 请求3、axios 请求配置 二、axios 的二次封装1、配置拦截器2、发送请求 三、API 的解耦1、配置文件对应的请求2、获取请求的数据 四、总结 一、请求和传递参数 在 Vue 中,发送请求一般在 created 钩子中,…...

JavaScript Web APIs -03 事件流、事件委托、其他事件(加载、滚动、尺寸)
Web APIs - 03 文章目录 Web APIs - 03事件流捕获和冒泡阻止冒泡 事件委托其他事件页面加载事件元素滚动事件页面尺寸事件 元素尺寸与位置 进一步学习 事件进阶,实现更多交互的网页特效,结合事件流的特征优化事件执行的效率 掌握阻止事件冒泡的方法理解事…...
QT DAY 2
window.cpp #include "window.h" #include<QDebug> #include<QIcon> Window::Window(QWidget *parent) //构造函数的定义: QWidget(parent) //显性调用父类的构造函数 {//this->resize(430,330);this->resize(QSize(800,600));// this…...

ELK安装、部署、调试(三)zookeeper安装,配置
1.准备 java安装,系统自带即可 2.下载zookeeper zookeeper.apache.org上可以下载 tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local mv apache-zookeeper-3.7.1-bin zookeeper 3.配置zookeeper mv zoo_sample.cfg zoo.cfg /usr/local/zookeeper/con…...

企业级智能PDF及文档处理SDK GdPicture.NET 14.2 Crack
企业级智能PDF及文档处理SDK GdPicture.NET 提供了一组非常先进的 API,这些 API 利用了人工智能、机器学习和模糊逻辑算法等尖端技术。经过超过 15 年的持续研究和对创新的专注,我们的 SDK 已成为市场上针对PDF、OCR、条形码、文档成像和各种格式最全面的…...

应用程序管理工具
应用程序管理是 DevOps 的重要组成部分。它可以定义为在所有阶段监控和管理软件应用程序的可用性、运行状况、性能和功能的过程,包括规划、设计、构建、测试、部署、维护和更新。这意味着应用程序从概念到停止都受到监控。 应用程序管理的重要性 管理应用程序可确…...

C166编译器内联展开机制与嵌入式性能优化
1. C166编译器运行时库函数的内联展开机制解析在嵌入式开发领域,C166架构因其高效的实时性能被广泛应用于工业控制领域。作为长期使用Keil C166工具链的开发者,我发现编译器对标准库函数的内联优化处理直接影响着代码的执行效率和内存占用。本文将深入剖…...
)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南)
STM32F030 HAL库驱动W25Q16实战:从数据手册到SPI读写代码(附避坑指南) 1. 理解W25Q16存储芯片的核心特性 W25Q16作为一款16Mbit容量的SPI Flash存储器,在嵌入式系统中扮演着重要角色。这款芯片采用标准的SPI接口,支持单…...

LeetCode 重新安排行程题解
LeetCode 重新安排行程题解 题目描述 给定一个机票列表,从起点出发,重新安排行程。 示例: 输入:tickets [["MUC","LHR"],["JFK","MUC"],["SFO","SJC"],["LHR&…...

Purple Pi OH开发板适配OpenHarmony 5.0全流程解析与实战
1. 项目概述:从一块开发板到OpenHarmony 5.0的完整旅程最近,我手头的这块触觉智能Purple Pi OH开发板,终于成功跑通了OpenHarmony 5.0 Release版本。这不仅仅是一次简单的系统升级适配,更像是一场从硬件引脚定义、内核驱动、系统服…...

为什么你的Perplexity搜不出科学健身计划?NIST认证信息检索模型原理首度公开
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity搜不出科学健身计划? Perplexity 作为一款以“实时网络检索大模型推理”为特色的AI搜索工具,其底层机制决定了它并非专为结构化健康决策而优化。当你输入“…...

get_kline_serial 用法:K 线序列长度、末尾行与新 bar 判定
前言 分钟线、小时线策略里,指标几乎都挂在 get_kline_serial 返回的序列上。我常见三类报错:长度不够就访问 iloc[-20]、把未收盘的 close 当成定稿信号、以及同一根 K 线里重复下单。下面按天勤量化里的订阅方式、长度防护和与 is_changing 的配合写一…...

保姆级教程:用QGIS的SRTM-Downloader插件,5分钟搞定中国区域地形图下载与渲染
5分钟极速出图:QGIS地形图制作全流程实战指南 当你在凌晨三点赶制项目报告,或是课程作业截止前两小时突然需要一张专业地形图时,传统GIS软件的复杂操作流程往往让人抓狂。本文将带你用QGIS的SRTM-Downloader插件,像点外卖一样简单…...
)
告别手动评分!用ImageJ的IHC Profiler插件,5分钟搞定免疫组化定量分析(附避坑指南)
告别手动评分!用ImageJ的IHC Profiler插件,5分钟搞定免疫组化定量分析(附避坑指南) 免疫组化(IHC)作为病理诊断和生物医学研究中的金标准技术,其结果的量化分析一直是困扰研究人员的难题。传统人…...

3种创新方案解决抖音视频保存难题
3种创新方案解决抖音视频保存难题 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 你是否曾遇到过这样的困扰:在抖…...

Lenovo Legion Toolkit 终极指南:如何让你的拯救者笔记本性能提升30%
Lenovo Legion Toolkit 终极指南:如何让你的拯救者笔记本性能提升30% 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...