第 16 章_多版本并发控制
第 16 章_多版本并发控制
1. 什么是MVCC
MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC 是通过数据行的多个版本管理来实现数据库的并发控制。这项技术使得在InnoDB的事务隔离级别下执行一致性读操作有了保证。换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。
MVCC没有正式的标准,在不同的DBMS中MVCC的实现方式可能是不同的,也不是普遍使用的(大家可以参考相关的DBMS文档)。这里讲解InnoDB 中MVCC的实现机制(MySQL其它的存储引擎并不支持它)。
2. 快照读与当前读
MVCC在MySQL InnoDB中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读,而这个读指的就是快照读, 而非当前读。当前读实际上是一种加锁的操作,是悲观锁的实现。而MVCC本质是采用乐观锁思想的一种方式。
2. 1 快照读
快照读又叫一致性读,读取的是快照数据。 不加锁的简单的 SELECT 都属于快照读 ,即不加锁的非阻塞读;比如这样:
SELECT * FROM player WHERE ...
之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于MVCC,它在很多情况下,避免了加锁操作,降低了开销。
既然是基于多版本,那么快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。
快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读。
2. 2 当前读
当前读读取的是记录的最新版本(最新数据,而不是历史版本的数据),读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。加锁的 SELECT,或者对数据进行增删改都会进行当前读。比如:
SELECT * FROM student LOCK IN SHARE MODE; # 共享锁
SELECT * FROM student FOR UPDATE; # 排他锁
INSERT INTO student values ... # 排他锁
DELETE FROM student WHERE ... # 排他锁
UPDATE student SET ... # 排他锁
3. 复习
3. 1 再谈隔离级别
我们知道事务有 4 个隔离级别,可能存在三种并发问题:

在MySQL中,默认的隔离级别是可重复读,可以解决脏读和不可重复读的问题,如果仅从定义的角度来看,它并不能解决幻读问题。如果我们想要解决幻读问题,就需要采用串行化的方式,也就是将隔离级别提升到最高,但这样一来就会大幅降低数据库的事务并发能力。
MVCC 可以不采用锁机制,而是通过乐观锁的方式来解决不可重复读和幻读问题!它可以在大多数情况下替代行级锁,降低系统的开销。
另图:

3. 2 隐藏字段、Undo Log版本链
回顾一下undo日志的版本链,对于使用InnoDB存储引擎的表来说,它的聚簇索引记录中都包含两个必
要的隐藏列(字段)。
- trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
- roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到
undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
举例:student 表数据如下
mysql> select *from student;
+----+--------+--------+
| id | name | class |
+----+--------+--------+
| 1 | 张三 | 一班 |
+----+--------+--------+
1 row in set (0.01 sec)假设插入该记录的事务id为8,那么此刻该条记录的示意图如下所示:
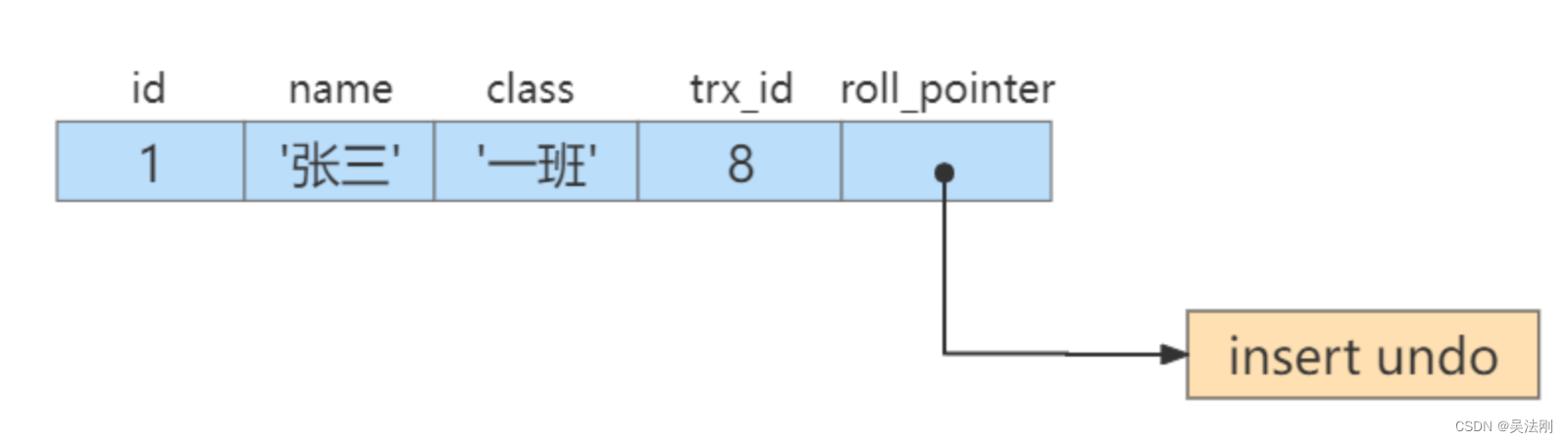
insert undo只在事务回滚时起作用,当事务提交后,该类型的undo日志就没用了,它占用的UndoLog Segment也会被系统回收(也就是该undo日志占用的Undo页面链表要么被重用,要么被释放)。
假设之后两个事务id分别为 10 、 20 的事务对这条记录进行UPDATE操作,操作流程如下:
| 发生时间 顺序 | 事务10 | 事务20 |
|---|---|---|
| 1 | BEGIN; | |
| 2 | BEGIN; | |
| 3 | UPDATE student SET name=“李四” WHERE id=1; | |
| 4 | UPDATE student SET name=“王五” WHERE id=1; | |
| 5 | COMMIT; | |
| 6 | UPDATE student SET name=“钱七” WHERE id=1; | |
| 7 | UPDATE student SET name=“宋八” WHERE id=1; | |
| 8 | COMMIT; |
能不能在两个事务中交叉更新同一条记录呢?不能!这不就是一个事务修改了另一个未提交事务修改过的数据,脏写。
InnoDB使用锁来保证不会有脏写情况的发生,也就是在第一个事务更新了某条记录后,就会给这条记录加锁,另一个事务再次更新时就需要等待第一个事务提交了,把锁释放之后才可以继续更新。
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表:
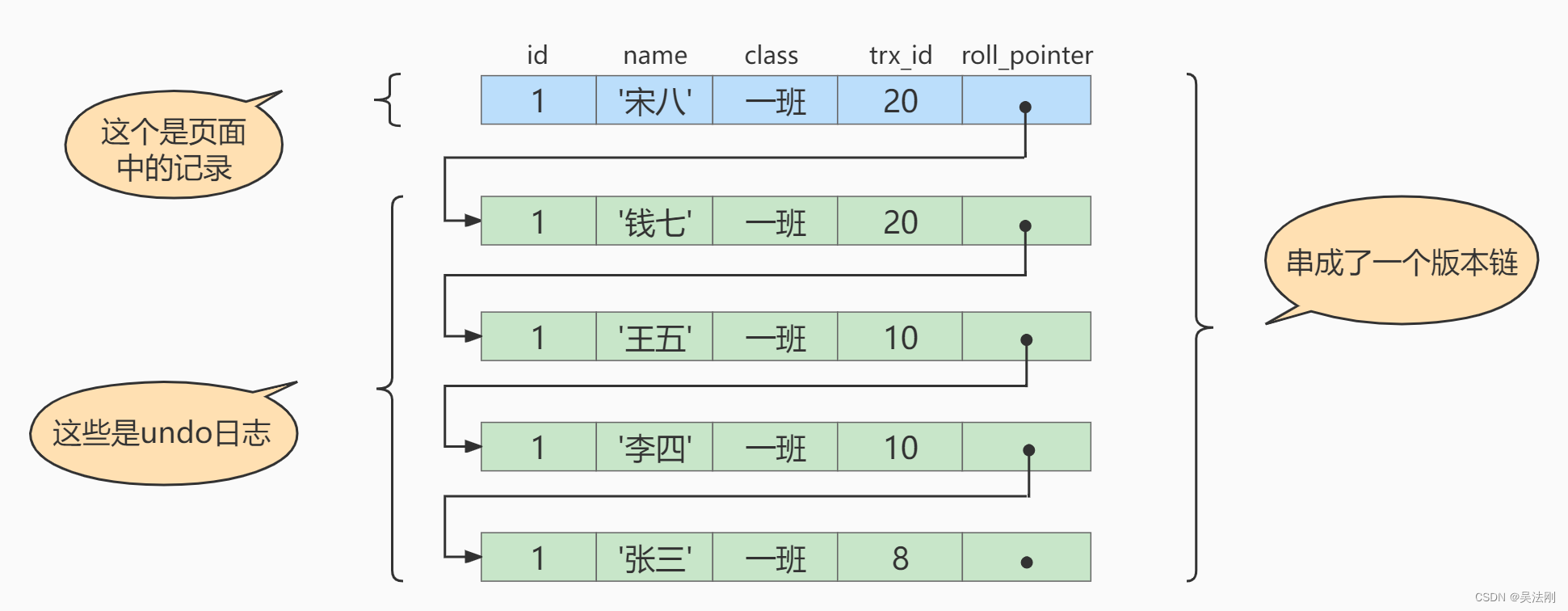
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。
每个版本中还包含生成该版本时对应的事务id。
4. MVCC实现原理之ReadView
MVCC 的实现依赖于: 隐藏字段、Undo Log、Read View 。
4.1 什么是ReadView
在MVCC机制中,多个事务对同一个行记录进行更新会产生多个历史快照,这些历史快照保存在Undo Log里。如果一个事务想要查询这个行记录,需要读取哪个版本的行记录呢?这时就需要用到ReadView了,它帮我们解决了行的可见性问题。
ReadView就是事务在使用MVCC机制进行快照读操作时产生的读视图。当事务启动时,会生成数据库系统当前的一个快照,InnoDB为每个事务构造了一个数组,用来记录并维护系统当前活跃事务的ID(“活跃"指的就是,启动了但还没提交)。
4.2 设计思路
使用READ UNCOMMITTED隔离级别的事务,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。
使用SERIALIZABLE隔离级别的事务,InnoDB规定使用加锁的方式来访问记录。
使用READ COMMITTED和REPEATABLE READ隔离级别的事务,都必须保证读到已经提交了的事务修改过的记录。假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是需要判断一下版本链中的哪个版本是当前事务可见的,这是ReadView要解决的主要问题。
这个ReadView中主要包含 4 个比较重要的内容,分别如下:
-
creator_trx_id,创建这个 Read View 的事务 ID。说明:只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为 0 。
-
trx_ids,表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。 -
up_limit_id,活跃的事务中最小的事务 ID。 -
low_limit_id,表示生成ReadView时系统中应该分配给下一个事务的id值。low_limit_id是系统最大的事务id值,这里要注意是系统中的事务id,需要区别于正在活跃的事务ID。
注意:low_limit_id并不是trx_ids中的最大值,事务id是递增分配的。比如,现在有id为 1 ,2 , 3 这三个事务,之后id为 3 的事务提交了。那么一个新的读事务在生成ReadView时,trx_ids就包括 1 和 2 ,up_limit_id的值就是 1 ,low_limit_id的值就是 4 。
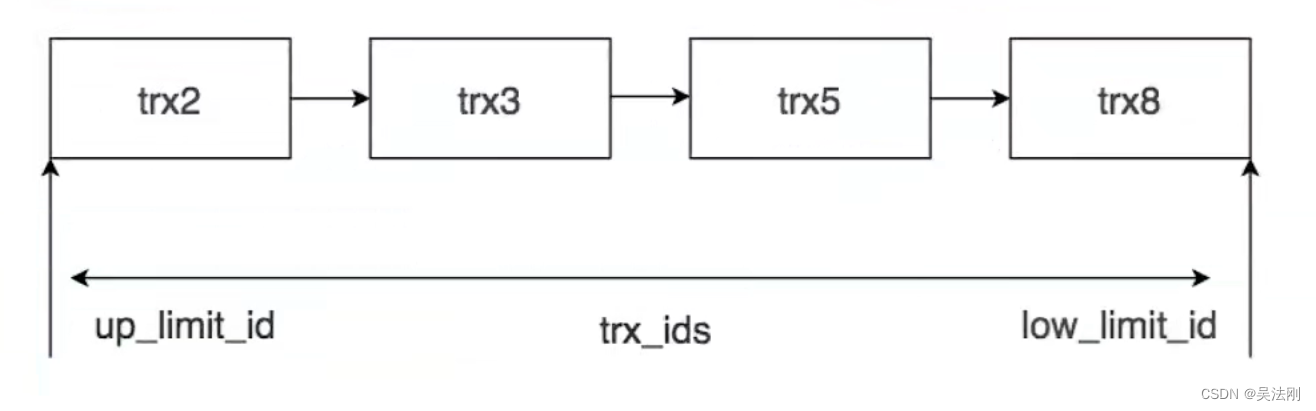
举例:
trx_ids为tr2、tr3、tr:5和trx8的集合,系统的最大事务ID (low_limit_id)为trx8+1(如果之前没有其他的新增事务),活跃的最小事务ID (up_limit_id)为trx2。
4.3 ReadView的规则
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见。
- 如果被访问版本的trx_id属性值与ReadView中的
creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 - 如果被访问版本的trx_id属性值小于ReadView中的
up_limit_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的trx_id属性值大于或等于ReadView中的
low_limit_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。 - 如果被访问版本的trx_id属性值在ReadView的up_limit_id和
low_limit_id之间,那就需要判断一下trx_id属性值是不是在trx_ids列表中。 - 如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问。
- 如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
4. 4 MVCC整体操作流程
了解了这些概念之后,我们来看下当查询一条记录的时候,系统如何通过MVCC找到它:
-
首先获取事务自己的版本号,也就是事务 ID;
-
生成 ReadView;
-
查询得到的数据,然后与 ReadView 中的事务版本号进行比较;
-
如果不符合 ReadView 规则,就需要从 Undo Log 中获取历史快照;
-
最后返回符合规则的数据。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
lnnoDB中,MVCC是通过Undo Log + Read View进行数据读取,Undo Log保存了历史快照,而Read View规则帮我们判断当前版本的数据是否可见。
在隔离级别为读已提交(Read Committed)时,一个事务中的每一次 SELECT 查询都会重新获取一次Read View。
如表所示:
| 事务 | 说明 |
|---|---|
| begin; | |
| select * from student where id >2; | 获取一次Read View |
| … | |
| select * from student where id >2; | 获取一次Read View |
| commit; |
注意,此时同样的查询语句都会重新获取一次 Read View,这时如果 Read View 不同,就可能产生不可重复读或者幻读的情况。
当隔离级别为可重复读的时候,就避免了不可重复读,这是因为一个事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View,如下表所示:

5. 举例说明
假设现在student表中只有一条由事务id为8的事务插入的一条记录:
mysql> select *from student;
+----+--------+--------+
| id | name | class |
+----+--------+--------+
| 1 | 张三 | 一班 |
+----+--------+--------+
1 row in set (0.01 sec)
MVCC只能在READ COMMITTED和REPEATABLE READ两个隔离级别下工作。接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。
5. 1 READ COMMITTED隔离级别下
READ COMMITTED :每次读取数据前都生成一个ReadView 。
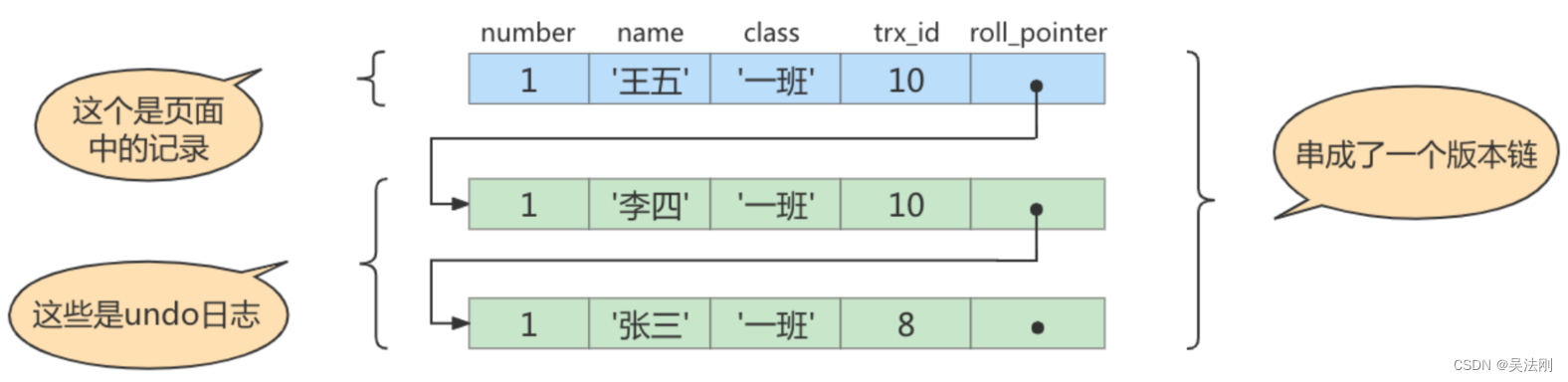
现在有两个事务id分别为 10 、 20 的事务在执行:
# Transaction 10
BEGIN;
UPDATE student SET name="李四" WHERE id= 1 ;
UPDATE student SET name="王五" WHERE id= 1 ;# Transaction 20
BEGIN;
# 更新了一些别的表的记录
...
说明:事务执行过程中,只有在第一次真正修改记录时(比如使用INSERT、DELETE、UPDATE语句),才会被 分配一个单独的事务id,这个事务id是递增的。所以我们才在事务2中更新些别的表的记录,目的是让它分配事务id。
此刻,表student 中id为 1 的记录得到的版本链表如下所示:
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行:
# 使用READ COMMITTED隔离级别的事务
BEGIN;# SELECT1:Transaction 10、 20 未提交
SELECT * FROM student WHERE id = 1 ; # 得到的列name的值为'张三'
这个SELECT1的执行过程如下:
步骤1: 在执行SELECT语句时会先生成一个ReadView , ReadView的 trx_ids列表的内容就是[10,20],up_limit_id为10, low_limit_id为21, creator_trx_id为0。
步骤2:从版本链中挑选可见的记录,从图中看出,最新版本的列name的内容是’王五’,该版本的trx_id值为10,在trx_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
步骤3:下一个版本的列name的内容是’李四’,该版本的trx_id值也为10,也在trx_ids列表内,所以也不符合要求,继续跳到下一个版本。
步骤4:下一个版本的列name的内容是’张三’,该版本的trx_id值为8,小于ReadView中的up_limit_id值10,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为‘张三’的记录。
之后,我们把事务id为 10 的事务提交一下:
# Transaction 10
BEGIN;UPDATE student SET name="李四" WHERE id= 1 ;
UPDATE student SET name="王五" WHERE id= 1 ;COMMIT;
然后再到事务id为 20 的事务中更新一下表student中id为 1 的记录:
# Transaction 20
BEGIN;# 更新了一些别的表的记录
...
UPDATE student SET name="钱七" WHERE id= 1 ;
UPDATE student SET name="宋八" WHERE id= 1 ;
此刻,表student中id为 1 的记录的版本链就长这样:
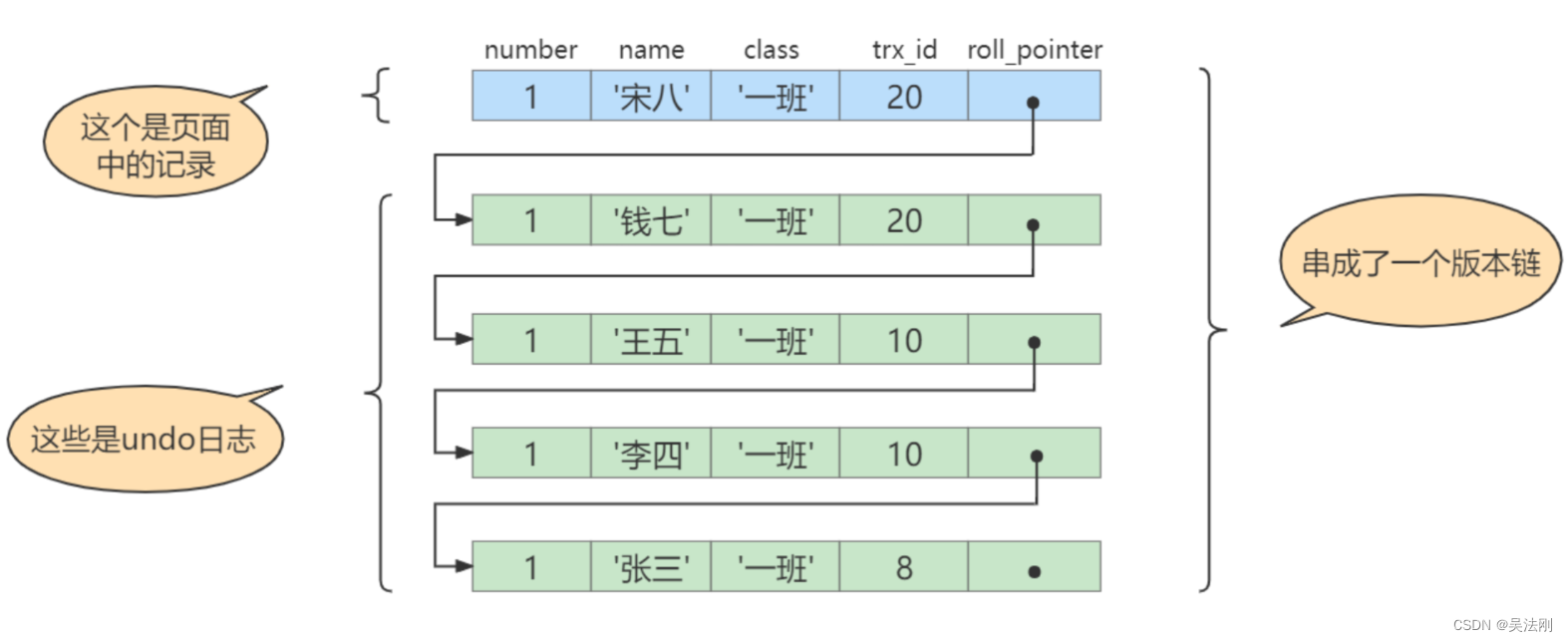
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个id为 1 的记录,如下:
# 使用READ COMMITTED隔离级别的事务
BEGIN;# SELECT1:Transaction 10、 20 均未提交
SELECT * FROM student WHERE id = 1 ; # 得到的列name的值为'张三'# SELECT2:Transaction 10提交,Transaction 20未提交
SELECT * FROM student WHERE id = 1 ; # 得到的列name的值为'王五'
这个SELECT2的执行过程如下:
步骤1:在执行SELECT语句时会又会单独生成一个ReadView,该ReadView的trx_ids列表的内容就是[20],up_limitid为.20,low_limit_id为21, creator_trx_id为0。
步骤2:从版本链中挑选可见的记录,从图中看出,最新版本的列name的内容是‘宋八‘,该版本的trx_id值为20,在trx_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
步骤3:下一个版本的列name的内容是‘钱七’,该版本的trx_id值为28,也在trx_ids列表内,所以也不符合要求,继续跳到下一个版本。
步骤4:下一个版本的列name的内容是’王五’,该版本的trx_id值为10,小于ReadView中的up_limit_id值20,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为‘王五‘的记录。
以此类推,如果之后事务id为20的记录也提交了,再次在使用READ COMMITTED隔离级别的事务中查询表student中id值为1的记录时,得到的结果就是‘宋八’了,具体流程我们就不分析了。
强调: 使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。
5. 2 REPEATABLE READ隔离级别下
使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。
比如,系统里有两个事务id分别为 10 、 20 的事务在执行:
# 开始记录
mysql> select *from student;
+----+--------+--------+
| id | name | class |
+----+--------+--------+
| 1 | 张三 | 一班 |
+----+--------+--------+
1 row in set (0.01 sec)
# Transaction 10
BEGIN;
UPDATE student SET name="李四" WHERE id= 1 ;
UPDATE student SET name="王五" WHERE id= 1 ;# Transaction 20
BEGIN;
# 更新了一些别的表的记录
...
此刻,表student 中id为 1 的记录得到的版本链表如下所示:
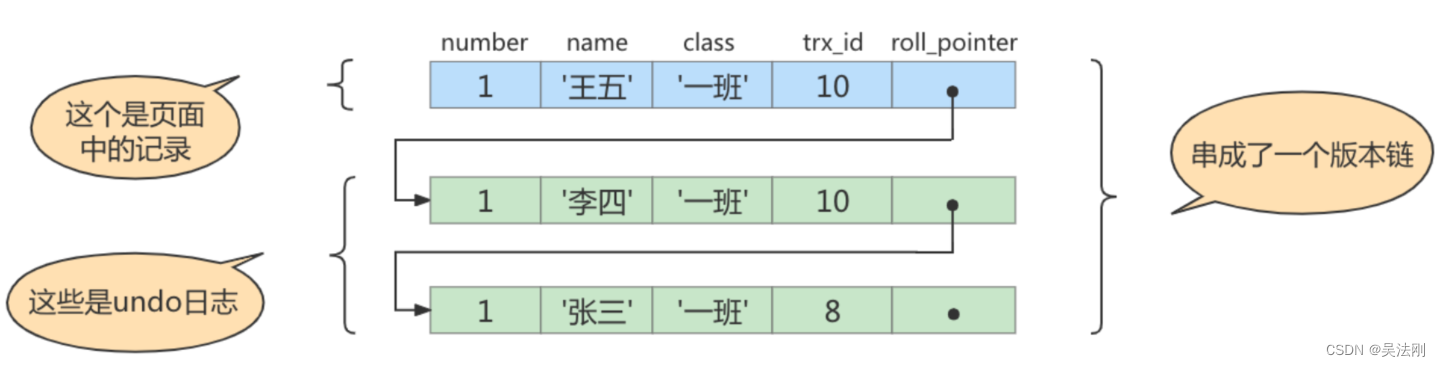
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行:
# 使用REPEATABLE READ隔离级别的事务
BEGIN;# SELECT1:Transaction 10、 20 未提交
SELECT * FROM student WHERE id = 1 ; # 得到的列name的值为'张三'
这个SELECT1的执行过程如下(第一个ReadView和读已提交是一样的):
步骤1: 在执行SELECT语句时会先生成一个ReadView , ReadView的 trx_ids列表的内容就是[10,20],up_limit_id为10, low_limit_id为21, creator_trx_id为0。
步骤2:从版本链中挑选可见的记录,从图中看出,最新版本的列name的内容是’王五’,该版本的trx_id值为10,在trx_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
步骤3:下一个版本的列name的内容是’李四’,该版本的trx_id值也为10,也在trx_ids列表内,所以也不符合要求,继续跳到下一个版本。
步骤4:下一个版本的列name的内容是’张三’,该版本的trx_id值为8,小于ReadView中的up_limit_id值10,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为‘张三’的记录。
之后,我们把事务id为 10 的事务提交一下:
# Transaction 10
BEGIN;UPDATE student SET name="李四" WHERE id= 1 ;
UPDATE student SET name="王五" WHERE id= 1 ;COMMIT;
然后再到事务id为 20 的事务中更新一下表student中id为 1 的记录:
# Transaction 20
BEGIN;# 更新了一些别的表的记录
...
UPDATE student SET name="钱七" WHERE id= 1 ;
UPDATE student SET name="宋八" WHERE id= 1 ;
此刻,表student 中id为 1 的记录的版本链长这样:
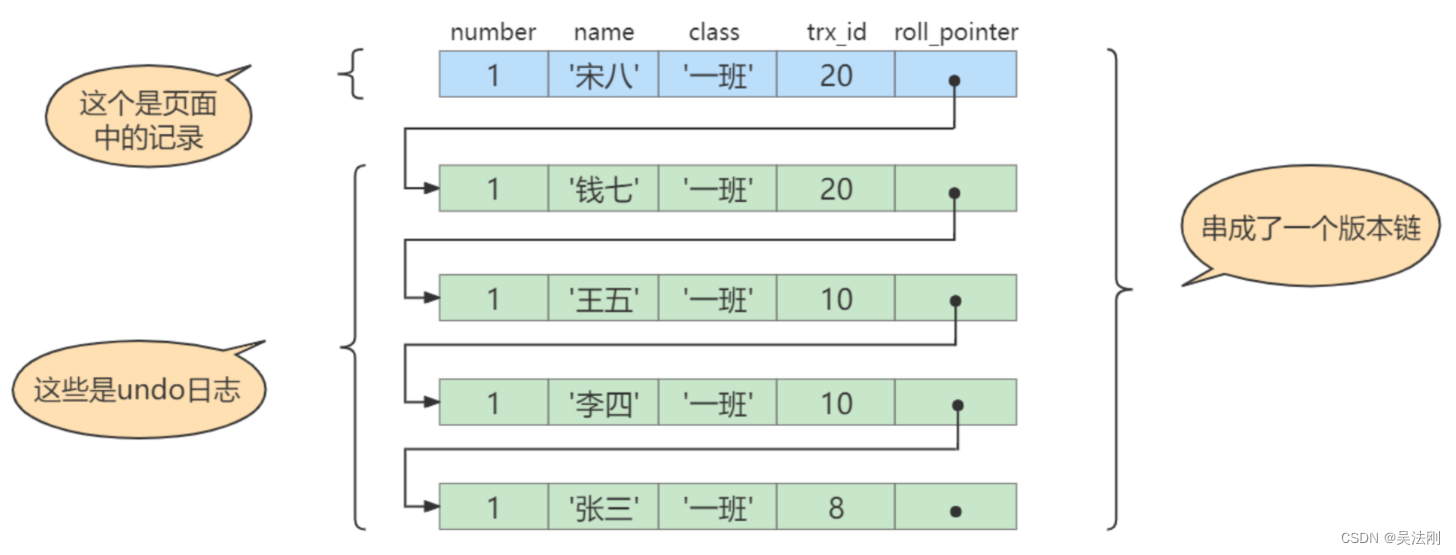
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个id为 1 的记录,如下:
# 使用REPEATABLE READ隔离级别的事务
BEGIN;# SELECT1:Transaction 10、 20 均未提交
SELECT * FROM student WHERE id = 1 ; # 得到的列name的值为'张三'# SELECT2:Transaction 10提交,Transaction 20未提交
SELECT * FROM student WHERE id = 1 ; # 得到的列name的值仍为'张三'
这个SELECT2的执行过程如下:
步骤1:在执行SELECT语句时会继续使用之前的ReadView,该ReadView的trx_ids列表的内容就是[10,20],up_limit_id为10, low_limit_id为21, ``creator_trx_id为0。
步骤2:然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是’宋八’,该版本的trx_id值为20,在trx_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
步骤3:下一个版本的列name的内容是’钱七’,该版本的trx_id值为20,也在trx_ids列表内,所以也不符合要求,继续跳到下一个版本。
步骤4∶下一个版本的列name的内容是’王五’,该版本的trx_id值为10,而trx_ids列表中是包含值为10的事务id的,所以该版本也不符合要求,同理下一个列name的内容是’李四’的版本也不符合要求。继续跳到下一个版本。
步骤5∶下一个版本的列name的内容是‘张三’,该版本的trx_id值为8,小于ReadView中的up_limit_id值10,所以这个版本是符合要求的,最后返回给用户的版本就是这条列c为‘张三’的记录。
两次SELECT查询得到的结果是重复的,记录的列c值都是‘张三’,这就是可重复读的含义。如果我们之后再把事务id为20的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个id为1的记录,得到的结果还是‘张三’,具体执行过程大家可以自己分析一下。
5. 3 如何解决幻读
接下来说明InnoDB 是如何解决幻读的。
假设现在表 student 中只有一条数据,数据内容中,主键 id=1,隐藏的 trx_id=10,它的 undo log 如下图所示。

假设现在有事务 A 和事务 B 并发执行,事务 A 的事务 id 为 20 ,事务 B 的事务 id 为 30 。
步骤 1 :事务 A 开始第一次查询数据,查询的 SQL 语句如下。
select * from student where id >= 1 ;
在开始查询之前,MySQL 会为事务 A 产生一个 ReadView,此时 ReadView 的内容如下:trx_ids=[20,30],up_limit_id=20,low_limit_id=31,creator_trx_id=20。
由于此时表 student 中只有一条数据,且符合 where id>=1 条件,因此会查询出来。然后根据 ReadView机制,发现该行数据的trx_id=10,小于事务 A 的 ReadView 里 up_limit_id,这表示这条数据是事务 A 开启之前,其他事务就已经提交了的数据,因此事务 A 可以读取到。
结论:事务 A 的第一次查询,能读取到一条数据,id=1。
步骤 2 :接着事务 B(trx_id=30),往表 student 中新插入两条数据,并提交事务。
insert into student(id,name) values( 2 ,'李四');
insert into student(id,name) values( 3 ,'王五');
此时表student 中就有三条数据了,对应的 undo 如下图所示:
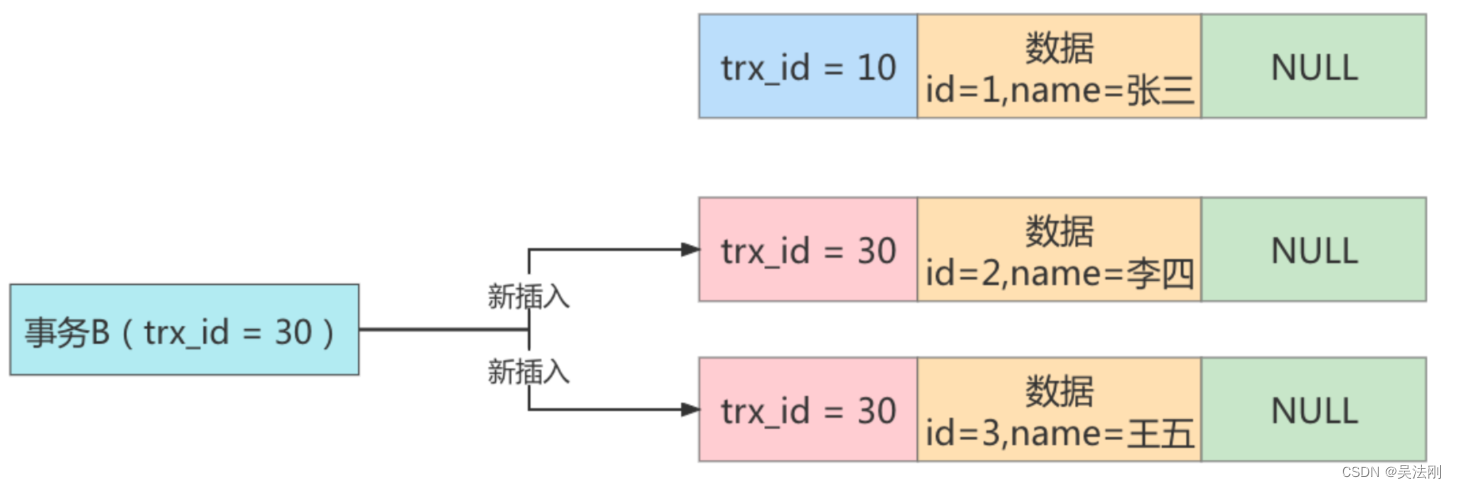
步骤 3 :接着事务 A 开启第二次查询,根据可重复读隔离级别的规则,此时事务 A 并不会再重新生成ReadView。此时表 student 中的 3 条数据都满足 where id>=1 的条件,因此会先查出来。然后根据ReadView 机制,判断每条数据是不是都可以被事务 A 看到。
1 )首先 id=1 的这条数据,前面已经说过了,可以被事务 A 看到。
2 )然后是 id=2 的数据,它的 trx_id=30,此时事务 A 发现,这个值处于 up_limit_id 和 low_limit_id 之间,因此还需要再判断 30 是否处于 trx_ids 数组内。由于事务 A 的 trx_ids=[20,30],因此在数组内,这表示 id=2 的这条数据是与事务 A 在同一时刻启动的其他事务提交的,所以这条数据不能让事务 A 看到。
3 )同理,id=3 的这条数据,trx_id 也为 30 ,因此也不能被事务 A 看见。
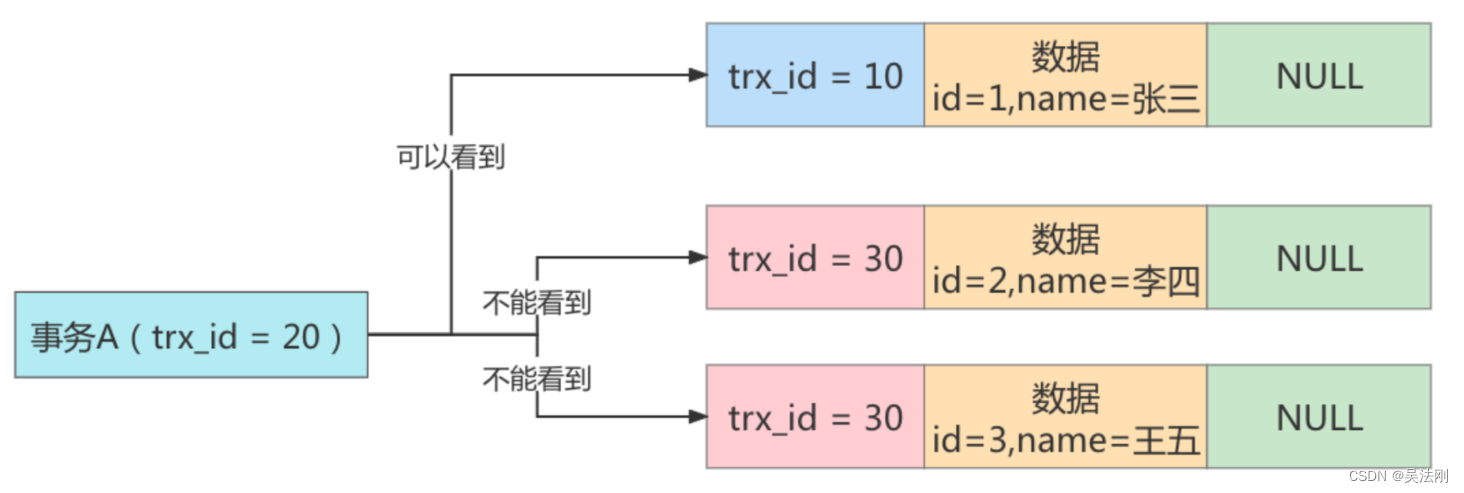
结论:最终事务 A 的第二次查询,只能查询出 id=1 的这条数据。这和事务 A 的第一次查询的结果是一样的,因此没有出现幻读现象,所以说在 MySQL 的可重复读隔离级别下,不存在幻读问题。
6. 总结
这里介绍了MVCC在READ COMMITTD、REPEATABLE READ这两种隔离级别的事务在执行快照读操作时访问记录的版本链的过程。这样使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
核心点在于 ReadView 的原理,READ COMMITTD、REPEATABLE READ这两个隔离级别的一个很大不同就是生成ReadView的时机不同:
READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadViewREPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了。
说明: 我们之前说执行DELETE语句或者更新主键的UPDATE语句并不会立即把对应的记录完全从页面中删除,而是执行一个所谓的delete mark操作,相当于只是对记录打上了一个删除标志位,这主要就是为MVCc服务的。
通过MVCC我们可以解决:
-
读写之间阻塞的问题。通过MVCC可以让读写互相不阻塞,即读不阻塞写,写不阻塞读,这样就可以提升事 务并发处理能力。 -
降低了死锁的概率。这是因为MVCC采用了乐观锁的方式,读取数据时并不需要加锁,对于写操作,也只锁 定必要的行。 -
解决快照读的问题。当我们查询数据库在某个时间点的快照时,只能看到这个时间点之前事务提交更新的结 果,而不能看到这个时间点之后事务提交的更新结果。
相关文章:
第 16 章_多版本并发控制
第 16 章_多版本并发控制 1. 什么是MVCC MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC 是通过数据行的多个版本管理来实现数据库的并发控制。这项技术使得在InnoDB的事务隔离级别下执行一致性读操作…...

五种 IO 模型
文章目录操作系统和内存内核空间和用户空间应用程序的内核态和用户态网络 IO 和磁盘 IO简易的网络通信流程阻塞和非阻塞阻塞 IO 模型非阻塞 IO 模型IO 复用模型SelectPollEpoll小结信号驱动 IO 模型异步 IO 模型五种 IO 模型的对比IO 模型里的同步和异步5种 IO 模型分别是&…...

34-Golang中的结构体!!!
Golang中的结构体结构体和结构体变量(实例)的区别和联系结构体变量(实例)在内存中的布局如何声明结构体字段/属性注意事项和细节说明创建结构体实例的四种方式结构体使用细节结构体和结构体变量(实例)的区别和联系 1.结构体是自定义的数据类型,代表一类事物2.结构体…...

这6个视频剪辑素材库,你一定要知道~
推荐5个免费商用视频素材网站,建议收藏哦! 1、菜鸟图库 视频素材下载_mp4视频大全 - 菜鸟图库 网站素材量很大,有设计、图片、音频、视频等超多素材,大部分都能免费下载。视频素材都很高清,有自然、人物、科技、农业…...

RocketMQ WIN11 搭建
去官方下载 https://rocketmq.apache.org/zh/download/ 下载,博主下载的是 4.6.0 的版本,选择Binary版本 拓展 Source 下载:需要编译 Binary 下载:不需要编译 解压缩,运行 先解压缩环境变量中添加rocketMQ文件夹路…...
iPhone更换电池和屏幕后提醒非原厂配件的操作办法
---开局一张图,内容全靠编系列! 【图】 自从在iPhone系统iOS13开始支持原厂配件检测后,可以说苹果也动起了维修站商家利益的这块蛋糕。道理自然简单,卷嘛!全球汽车行业也不是靠卖新车才赚钱的,各种交通事故…...

chatGPT发布记录
发行说明(2 月 13 日)我们对 ChatGPT 进行了多项更新!这是新功能:我们更新了免费计划中 ChatGPT 模型的性能,以便为更多用户提供服务。根据用户反馈,我们现在默认让 Plus 用户使用更快的 ChatGPT 版本&…...
DataX及DataX-Web
大数据Hadoop之——数据同步工具DataX数据采集工具-DataX datax详细介绍及使用 一、概述 DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、…...

数据结构与算法系列之kmp算法
什么是kmp算法 1.kmp算法是一种改进的字符串算法,其核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数已达到快速匹配的目的。 它主要实现作用的是 在 (主串)中找到 (匹配)字符串。 例 BF算法与k…...

算法分析详解
自古老的公元前1世纪开始,《周髀算经》就作为中国最古老的天文学和数学著作。 《周髀算经》采用最简便可行的方法确定天文历法,揭示日月星辰的运行规律,包括四季更替,气候变化,南北有极,昼夜相推的道理。为…...

东南大学自然辩证法概论期末总结
写在前面 作者:夏日 博客地址:https://blog.csdn.net/zss192 本文为2022年东南大学自然辩证法概论期末总结,内容为根据老师所发题纲综合多个资料总结得来 考试形式:从老师所发题纲,10个题目中选出4个,题…...

《爆肝整理》保姆级系列教程python接口自动化(二十)--token登录(详解)
简介 为了验证用户登录情况以及减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。有些登录不是用 cookie 来验证的,是用 token 参数来判断是否登录。token 传参有两种一种是放在请求头里,本质上是跟 cookie 是一样的&…...
k8s种的kubectl命令
一.kubectl基本命令1.1 称述式资源管理的方法kubernetes集群管理集群资源的唯一入口是通过相应的方法调用apiserver的接口kubectl是官方的CLI命令行工具,用于与apiserver进行通信,将用户在命令行输入的命令,组织并转化为apiserver能识别的信息…...

数组(一)-- LeetCode[26][80] 删除有序数组中的重复元素
1 删除有序数组中的重复项 1.1 题目描述 给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。 由于在某些语言中不能改变数组的长度,…...
GEE学习笔记 六十三:新的地图图层ui.Map.CloudStorageLayer
在GEE中导出数据有一种方式是直接导出地图到Google Cloud Storage中,也就是Export.map.toCloudStorage(xxx),这种方式是将我们计算生成影像导出成为静态瓦片的格式存放在Google Cloud Storage中。我们可以在其他的前端程序比如OpenLayer、Mapbox GL JS等…...

ClickHouse 语法详解
ClickHouse有2类解析器:完整SQL解析器(递归式解析器),以及数据格式解析器(快速流式解析器) 除了 INSERT 查询,其它情况下仅使用完整SQL解析器。 INSERT查询会同时使用2种解析器:INSE…...
手把手教你将微信小程序放到git上
背景 首先,要创建一个自己的git仓库,这里默认大家都能够自己创建了git仓库了。如果不会创建仓库的话,百度一下,很容易就能够创建了!(后续,如有不知道在哪里,怎么创建仓库的话&#…...

功能测试3年,回顾一路走来的艰辛
不论你是什么时候开始接触测试这个行业的,你首先听说的应该是功能测试。通过一些测试手段来验证开发做出的代码是否符合产品的需求?当然你也有自己对功能测试的理解,但是最近两年感觉功能测试好像不太受欢迎,同时不少同学真的是功…...

作为Linux C/C++程序员必备的工具
Linux系统 可以选择centOS或者ubautu server(不建议选择桌面版本的)。不建议裸机安装,玩坏了就特别麻烦。不建议使用有桌面版本的ubautu,在一定程度有桌面的版本的会消耗性能。 如果经济实力允许,可以购买云服务器。 参考文章: Ubuntu server…...

docker Alpine一个只有5M小而美的Docker镜像
docker Alpine一个只有5M小而美的Docker镜像 参考链接: Alpine 一个只有5M的Docker镜像 http://www.infoq.com/cn/news/2016/01/Alpine-Linux-5M-Docker?utm_sourcetuicool&utm_mediumreferral 使用alpinelinux 构建 golang http 启动了才15mb http://blog.csdn.net/fre…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...