k8s之存储篇---存储类StorageClass
介绍
StorageClass 为管理员提供了描述存储"类"的方法。 不同的类型可能会映射到不同的服务质量等级或备份策略,或是由集群管理员制定的任意策略。 Kubernetes 本身并不清楚各种类代表的什么。这个类的概念在其他存储系统中有时被称为"配置文件"。
StorageClass 资源
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在 StorageClass 需要动态制备 PersistentVolume 时会使用到。
StorageClass 对象的命名很重要,用户使用这个命名来请求生成一个特定的类。 当创建 StorageClass 对象时,管理员设置 StorageClass 对象的命名和其他参数, 一旦创建了对象就不能再对其更新。
管理员可以为没有申请绑定到特定 StorageClass 的 PVC 指定一个默认的存储类: 更多详情请参阅 PersistentVolumeClaim 章节。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: standard
provisioner: kubernetes.io/aws-ebs
parameters:type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:- debug
volumeBindingMode: Immediate
默认 StorageClass
当一个 PVC 没有指定 storageClassName 时,会使用默认的 StorageClass。 集群中只能有一个默认的 StorageClass。如果不小心设置了多个默认的 StorageClass, 当 PVC 动态配置时,将使用最新设置的默认 StorageClass。
关于如何设置默认的 StorageClass, 请参见更改默认 StorageClass。 请注意,某些云服务提供商可能已经定义了一个默认的 StorageClass。
存储制备器
每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件制备 PV。 该字段必须指定。
| 卷插件 | 内置制备器 | 配置示例 |
|---|---|---|
| AzureFile | ✓ | Azure File |
| CephFS | - | - |
| FC | - | - |
| FlexVolume | - | - |
| GCEPersistentDisk | ✓ | GCE PD |
| iSCSI | - | - |
| NFS | - | NFS |
| RBD | ✓ | Ceph RBD |
| VsphereVolume | ✓ | vSphere |
| PortworxVolume | ✓ | Portworx Volume |
| Local | - | Local |
你不限于指定此处列出的 “内置” 制备器(其名称前缀为 “kubernetes.io” 并打包在 Kubernetes 中)。 你还可以运行和指定外部制备器,这些独立的程序遵循由 Kubernetes 定义的规范。 外部供应商的作者完全可以自由决定他们的代码保存于何处、打包方式、运行方式、使用的插件(包括 Flex)等。 代码仓库 kubernetes-sigs/sig-storage-lib-external-provisioner 包含一个用于为外部制备器编写功能实现的类库。你可以访问代码仓库 kubernetes-sigs/sig-storage-lib-external-provisioner 了解外部驱动列表。
例如,NFS 没有内部制备器,但可以使用外部制备器。 也有第三方存储供应商提供自己的外部制备器。
回收策略
由 StorageClass 动态创建的 PersistentVolume 会在类的 reclaimPolicy 字段中指定回收策略,可以是 Delete 或者 Retain。 如果 StorageClass 对象被创建时没有指定 reclaimPolicy,它将默认为 Delete。
通过 StorageClass 手动创建并管理的 PersistentVolume 会使用它们被创建时指定的回收策略。
允许卷扩展
特性状态: Kubernetes v1.11 [beta]
PersistentVolume 可以配置为可扩展。将此功能设置为 true 时,允许用户通过编辑相应的 PVC 对象来调整卷大小。
当下层 StorageClass 的 allowVolumeExpansion 字段设置为 true 时,以下类型的卷支持卷扩展。
| 卷类型 | Kubernetes 版本要求 |
|---|---|
| gcePersistentDisk | 1.11 |
| rbd | 1.11 |
| Azure File | 1.11 |
| Portworx | 1.11 |
| FlexVolume | 1.13 |
| CSI | 1.14 (alpha), 1.16 (beta) |
说明:
此功能仅可用于扩容卷,不能用于缩小卷。
挂载选项
由 StorageClass 动态创建的 PersistentVolume 将使用类中 mountOptions 字段指定的挂载选项。
如果卷插件不支持挂载选项,却指定了挂载选项,则制备操作会失败。 挂载选项在 StorageClass 和 PV 上都不会做验证。如果其中一个挂载选项无效,那么这个 PV 挂载操作就会失败。
卷绑定模式
volumeBindingMode 字段控制了卷绑定和动态制备应该发生在什么时候。 当未设置时,默认使用 Immediate 模式。
Immediate 模式表示一旦创建了 PersistentVolumeClaim 也就完成了卷绑定和动态制备。 对于由于拓扑限制而非集群所有节点可达的存储后端,PersistentVolume 会在不知道 Pod 调度要求的情况下绑定或者制备。
集群管理员可以通过指定 WaitForFirstConsumer 模式来解决此问题。 该模式将延迟 PersistentVolume 的绑定和制备,直到使用该 PersistentVolumeClaim 的 Pod 被创建。 PersistentVolume 会根据 Pod 调度约束指定的拓扑来选择或制备。 这些包括但不限于资源需求、 节点筛选器、 Pod 亲和性和互斥性、 以及污点和容忍度。
以下插件支持动态制备的 WaitForFirstConsumer 模式:
- GCEPersistentDisk
以下插件支持预创建绑定 PersistentVolume 的 WaitForFirstConsumer 模式:
- 上述全部
- Local
特性状态: Kubernetes v1.17 [stable]
动态制备和预先创建的 PV 也支持 CSI 卷, 但是你需要查看特定 CSI 驱动的文档以查看其支持的拓扑键名和例子。
说明:
如果你选择使用 WaitForFirstConsumer,请不要在 Pod 规约中使用 nodeName 来指定节点亲和性。 如果在这种情况下使用 nodeName,Pod 将会绕过调度程序,PVC 将停留在 pending 状态。
相反,在这种情况下,你可以使用节点选择器作为主机名,如下所示。
apiVersion: v1
kind: Pod
metadata:name: task-pv-pod
spec:nodeSelector:kubernetes.io/hostname: kube-01volumes:- name: task-pv-storagepersistentVolumeClaim:claimName: task-pv-claimcontainers:- name: task-pv-containerimage: nginxports:- containerPort: 80name: "http-server"volumeMounts:- mountPath: "/usr/share/nginx/html"name: task-pv-storage
允许的拓扑结构
当集群操作人员使用了 WaitForFirstConsumer 的卷绑定模式, 在大部分情况下就没有必要将制备限制为特定的拓扑结构。 然而,如果还有需要的话,可以使用 allowedTopologies。
这个例子描述了如何将制备卷的拓扑限制在特定的区域, 在使用时应该根据插件支持情况替换 zone 和 zones 参数。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: standard
provisioner: kubernetes.io/gce-pd
parameters:type: pd-standard
volumeBindingMode: WaitForFirstConsumer
allowedTopologies:
- matchLabelExpressions:- key: failure-domain.beta.kubernetes.io/zonevalues:- us-central-1a- us-central-1b
参数
Storage Classes 的参数描述了存储类的卷。取决于制备器,可以接受不同的参数。 例如,参数 type 的值 io1 和参数 iopsPerGB 特定于 EBS PV。 当参数被省略时,会使用默认值。
一个 StorageClass 最多可以定义 512 个参数。这些参数对象的总长度不能超过 256 KiB,包括参数的键和值。
AWS EBS
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: slow
provisioner: kubernetes.io/aws-ebs
parameters:type: io1iopsPerGB: "10"fsType: ext4
type:io1、gp2、sc1、st1。详细信息参见 AWS 文档。默认值:gp2。zone(已弃用):AWS 区域。如果没有指定zone和zones, 通常卷会在 Kubernetes 集群节点所在的活动区域中轮询调度分配。zone和zones参数不能同时使用。zones(已弃用):以逗号分隔的 AWS 区域列表。 如果没有指定zone和zones,通常卷会在 Kubernetes 集群节点所在的活动区域中轮询调度分配。zone和zones参数不能同时使用。iopsPerGB:只适用于io1卷。每 GiB 每秒 I/O 操作。 AWS 卷插件将其与请求卷的大小相乘以计算 IOPS 的容量, 并将其限制在 20000 IOPS(AWS 支持的最高值,请参阅 AWS 文档)。 这里需要输入一个字符串,即"10",而不是10。fsType:受 Kubernetes 支持的文件类型。默认值:"ext4"。encrypted:指定 EBS 卷是否应该被加密。合法值为"true"或者"false"。 这里需要输入字符串,即"true",而非true。kmsKeyId:可选。加密卷时使用密钥的完整 Amazon 资源名称。 如果没有提供,但encrypted值为 true,AWS 生成一个密钥。关于有效的 ARN 值,请参阅 AWS 文档。
说明:
zone 和 zones 已被弃用并被允许的拓扑结构取代。
GCE PD
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: slow
provisioner: kubernetes.io/gce-pd
parameters:type: pd-standardfstype: ext4replication-type: none
type:pd-standard或者pd-ssd。默认:pd-standardzone(已弃用):GCE 区域。如果没有指定zone和zones, 通常卷会在 Kubernetes 集群节点所在的活动区域中轮询调度分配。zone和zones参数不能同时使用。zones(已弃用):逗号分隔的 GCE 区域列表。如果没有指定zone和zones, 通常卷会在 Kubernetes 集群节点所在的活动区域中轮询调度(round-robin)分配。zone和zones参数不能同时使用。fstype:ext4或xfs。默认:ext4。宿主机操作系统必须支持所定义的文件系统类型。replication-type:none或者regional-pd。默认值:none。
如果 replication-type 设置为 none,会制备一个常规(当前区域内的)持久化磁盘。
如果 replication-type 设置为 regional-pd, 会制备一个区域性持久化磁盘(Regional Persistent Disk)。
强烈建议设置 volumeBindingMode: WaitForFirstConsumer,这样设置后, 当你创建一个 Pod,它使用的 PersistentVolumeClaim 使用了这个 StorageClass, 区域性持久化磁盘会在两个区域里制备。其中一个区域是 Pod 所在区域, 另一个区域是会在集群管理的区域中任意选择,磁盘区域可以通过 allowedTopologies 加以限制。
说明:
zone 和 zones 已被弃用并被 allowedTopologies 取代。 当启用 GCE CSI 迁移时, GCE PD 卷可能被制备在某个与所有节点都不匹配的拓扑域中,但任何尝试使用该卷的 Pod 都无法被调度。 对于传统的迁移前 GCE PD,这种情况下将在制备卷的时候产生错误。 从 Kubernetes 1.23 版本开始,GCE CSI 迁移默认启用。
NFS
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: example-nfs
provisioner: example.com/external-nfs
parameters:server: nfs-server.example.compath: /sharereadOnly: "false"
server:NFS 服务器的主机名或 IP 地址。path:NFS 服务器导出的路径。readOnly:是否将存储挂载为只读的标志(默认为 false)。
Kubernetes 不包含内部 NFS 驱动。你需要使用外部驱动为 NFS 创建 StorageClass。 这里有些例子:
- NFS Ganesha 服务器和外部驱动
- NFS subdir 外部驱动
vSphere
vSphere 存储类有两种制备器:
- CSI 制备器:
csi.vsphere.vmware.com - vCP 制备器:
kubernetes.io/vsphere-volume
树内制备器已经被 弃用。 更多关于 CSI 制备器的详情,请参阅 Kubernetes vSphere CSI 驱动 和 vSphereVolume CSI 迁移。
CSI 制备器
vSphere CSI StorageClass 制备器在 Tanzu Kubernetes 集群下运行。示例请参阅 vSphere CSI 仓库。
vCP 制备器
以下示例使用 VMware Cloud Provider(vCP)StorageClass 制备器。
-
使用用户指定的磁盘格式创建一个 StorageClass。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata:name: fast provisioner: kubernetes.io/vsphere-volume parameters:diskformat: zeroedthickdiskformat:thin、zeroedthick和eagerzeroedthick。默认值:"thin"。 -
在用户指定的数据存储上创建磁盘格式的 StorageClass。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata:name: fast provisioner: kubernetes.io/vsphere-volume parameters:diskformat: zeroedthickdatastore: VSANDatastoredatastore:用户也可以在 StorageClass 中指定数据存储。 卷将在 StorageClass 中指定的数据存储上创建,在这种情况下是VSANDatastore。 该字段是可选的。 如果未指定数据存储,则将在用于初始化 vSphere Cloud Provider 的 vSphere 配置文件中指定的数据存储上创建该卷。 -
Kubernetes 中的存储策略管理
-
使用现有的 vCenter SPBM 策略
vSphere 用于存储管理的最重要特性之一是基于策略的管理。 基于存储策略的管理(SPBM)是一个存储策略框架,提供单一的统一控制平面的跨越广泛的数据服务和存储解决方案。 SPBM 使得 vSphere 管理员能够克服先期的存储配置挑战,如容量规划、差异化服务等级和管理容量空间。
SPBM 策略可以在 StorageClass 中使用
storagePolicyName参数声明。 -
Kubernetes 内的 Virtual SAN 策略支持
Vsphere Infrastructure(VI)管理员将能够在动态卷配置期间指定自定义 Virtual SAN 存储功能。你现在可以在动态制备卷期间以存储能力的形式定义存储需求,例如性能和可用性。 存储能力需求会转换为 Virtual SAN 策略,之后当持久卷(虚拟磁盘)被创建时, 会将其推送到 Virtual SAN 层。虚拟磁盘分布在 Virtual SAN 数据存储中以满足要求。
你可以参考基于存储策略的动态制备卷管理, 进一步了解有关持久卷管理的存储策略的详细信息。
-
有几个 vSphere 例子供你在 Kubernetes for vSphere 中尝试进行持久卷管理。
Ceph RBD
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: fast
provisioner: kubernetes.io/rbd
parameters:monitors: 10.16.153.105:6789adminId: kubeadminSecretName: ceph-secretadminSecretNamespace: kube-systempool: kubeuserId: kubeuserSecretName: ceph-secret-useruserSecretNamespace: defaultfsType: ext4imageFormat: "2"imageFeatures: "layering"
-
monitors:Ceph monitor,逗号分隔。该参数是必需的。 -
adminId:Ceph 客户端 ID,用于在池 ceph 池中创建映像。默认是 “admin”。 -
adminSecret:adminId的 Secret 名称。该参数是必需的。 提供的 secret 必须有值为 “kubernetes.io/rbd” 的 type 参数。 -
adminSecretNamespace:adminSecret的命名空间。默认是 “default”。 -
pool:Ceph RBD 池。默认是 “rbd”。 -
userId:Ceph 客户端 ID,用于映射 RBD 镜像。默认与adminId相同。 -
userSecretName:用于映射 RBD 镜像的userId的 Ceph Secret 的名字。 它必须与 PVC 存在于相同的 namespace 中。该参数是必需的。 提供的 secret 必须具有值为 “kubernetes.io/rbd” 的 type 参数,例如以这样的方式创建:kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" \--from-literal=key='QVFEQ1pMdFhPUnQrSmhBQUFYaERWNHJsZ3BsMmNjcDR6RFZST0E9PQ==' \--namespace=kube-system -
userSecretNamespace:userSecretName的命名空间。 -
fsType:Kubernetes 支持的 fsType。默认:"ext4"。 -
imageFormat:Ceph RBD 镜像格式,“1” 或者 “2”。默认值是 “1”。 -
imageFeatures:这个参数是可选的,只能在你将imageFormat设置为 “2” 才使用。 目前支持的功能只是layering。默认是 “”,没有功能打开。
Azure 磁盘
Azure Unmanaged Disk Storage Class(非托管磁盘存储类)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: slow
provisioner: kubernetes.io/azure-disk
parameters:skuName: Standard_LRSlocation: eastusstorageAccount: azure_storage_account_name
skuName:Azure 存储帐户 Sku 层。默认为空。location:Azure 存储帐户位置。默认为空。storageAccount:Azure 存储帐户名称。 如果提供存储帐户,它必须位于与集群相同的资源组中,并且location是被忽略的。如果未提供存储帐户,则会在与集群相同的资源组中创建新的存储帐户。
Azure 磁盘 Storage Class(从 v1.7.2 开始)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: slow
provisioner: kubernetes.io/azure-disk
parameters:storageaccounttype: Standard_LRSkind: managed
-
storageaccounttype:Azure 存储帐户 Sku 层。默认为空。 -
kind:可能的值是shared、dedicated和managed(默认)。 当kind的值是shared时,所有非托管磁盘都在集群的同一个资源组中的几个共享存储帐户中创建。 当kind的值是dedicated时,将为在集群的同一个资源组中新的非托管磁盘创建新的专用存储帐户。 -
resourceGroup:指定要创建 Azure 磁盘所属的资源组。必须是已存在的资源组名称。 若未指定资源组,磁盘会默认放入与当前 Kubernetes 集群相同的资源组中。 -
Premium VM 可以同时添加 Standard_LRS 和 Premium_LRS 磁盘,而 Standard 虚拟机只能添加 Standard_LRS 磁盘。
-
托管虚拟机只能连接托管磁盘,非托管虚拟机只能连接非托管磁盘。
Azure 文件
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: azurefile
provisioner: kubernetes.io/azure-file
parameters:skuName: Standard_LRSlocation: eastusstorageAccount: azure_storage_account_name
skuName:Azure 存储帐户 Sku 层。默认为空。location:Azure 存储帐户位置。默认为空。storageAccount:Azure 存储帐户名称。默认为空。 如果不提供存储帐户,会搜索所有与资源相关的存储帐户,以找到一个匹配skuName和location的账号。 如果提供存储帐户,它必须存在于与集群相同的资源组中,skuName和location会被忽略。secretNamespace:包含 Azure 存储帐户名称和密钥的密钥的名字空间。 默认值与 Pod 相同。secretName:包含 Azure 存储帐户名称和密钥的密钥的名称。 默认值为azure-storage-account-<accountName>-secretreadOnly:指示是否将存储安装为只读的标志。默认为 false,表示"读/写"挂载。 该设置也会影响 VolumeMounts 中的ReadOnly设置。
在存储制备期间,为挂载凭证创建一个名为 secretName 的 Secret。如果集群同时启用了 RBAC 和控制器角色, 为 system:controller:persistent-volume-binder 的 clusterrole 添加 Secret 资源的 create 权限。
在多租户上下文中,强烈建议显式设置 secretNamespace 的值,否则其他用户可能会读取存储帐户凭据。
Portworx 卷
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: portworx-io-priority-high
provisioner: kubernetes.io/portworx-volume
parameters:repl: "1"snap_interval: "70"priority_io: "high"
fs:选择的文件系统:none/xfs/ext4(默认:ext4)。block_size:以 Kbytes 为单位的块大小(默认值:32)。repl:同步副本数量,以复制因子1..3(默认值:1)的形式提供。 这里需要填写字符串,即,"1"而不是1。io_priority:决定是否从更高性能或者较低优先级存储创建卷high/medium/low(默认值:low)。snap_interval:触发快照的时钟/时间间隔(分钟)。 快照是基于与先前快照的增量变化,0 是禁用快照(默认:0)。 这里需要填写字符串,即,是"70"而不是70。aggregation_level:指定卷分配到的块数量,0 表示一个非聚合卷(默认:0)。 这里需要填写字符串,即,是"0"而不是0。ephemeral:指定卷在卸载后进行清理还是持久化。emptyDir的使用场景可以将这个值设置为 true,persistent volumes的使用场景可以将这个值设置为 false (例如 Cassandra 这样的数据库)true/false(默认为false)。这里需要填写字符串,即, 是"true"而不是true。
本地
特性状态: Kubernetes v1.14 [stable]
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
本地卷还不支持动态制备,然而还是需要创建 StorageClass 以延迟卷绑定, 直到完成 Pod 的调度。这是由 WaitForFirstConsumer 卷绑定模式指定的。
延迟卷绑定使得调度器在为 PersistentVolumeClaim 选择一个合适的 PersistentVolume 时能考虑到所有 Pod 的调度限制。
相关文章:

k8s之存储篇---存储类StorageClass
介绍 StorageClass 为管理员提供了描述存储"类"的方法。 不同的类型可能会映射到不同的服务质量等级或备份策略,或是由集群管理员制定的任意策略。 Kubernetes 本身并不清楚各种类代表的什么。这个类的概念在其他存储系统中有时被称为"配置文件&quo…...
WordPress(4)关于网站的背景图片更换
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、更改的位置1. 红色区域是要更换的随机的图片二、替换图片位置三.开启随机数量四.结束前言 提示:这里可以添加本文要记录的大概内容: 例如:随着人工智能的不断发展,机器学习这门技术也…...
2 | Window 搭建单机 Hadoop 和Spark
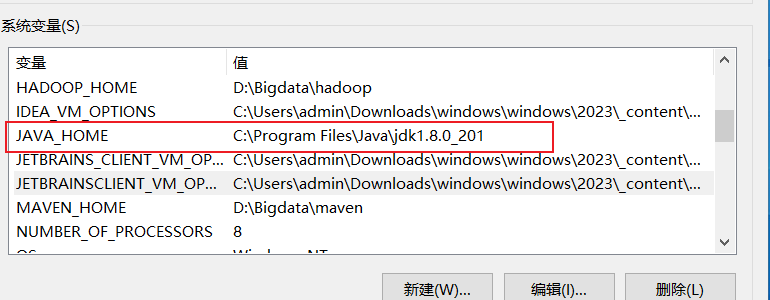
搭建单机 Hadoop 和 Spark 环境可以学习和测试大数据处理的基础知识。在 Windows 操作系统上搭建这两个工具需要一些配置和设置,下面是一个详细的教程: 注意: 在开始之前,请确保你已经安装了 Java 开发工具包(JDK),并且已经下载了 Hadoop 和 Spark 的最新版本。你可以从…...

接口测试与功能测试的区别~
今天为大家分享的是我们在日常测试工作中, 一定会接触并且目前在企业中是主要测试内容的 功能测试与接口测试 一.功能测试与接口测试的基本概念。 1.1 什么是功能测试呢? 功能测试: 是黑盒测试的一方面, 检查实际软件的功能是否符合用户的需求 功能测试测试的内容包括以下…...
LeetCode 23 合并 K 个升序链表
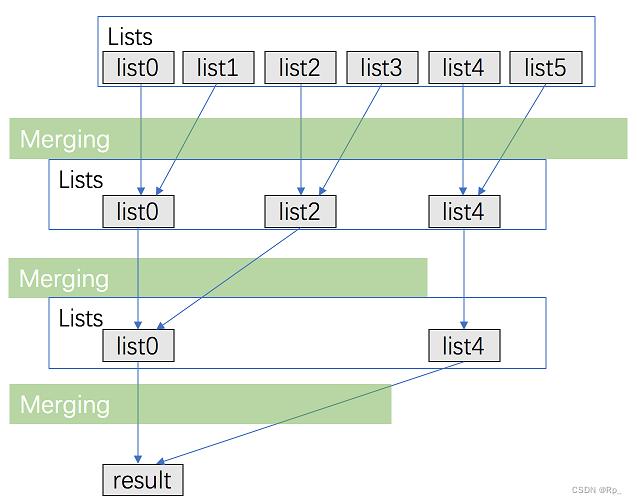
LeetCode 23 合并 K 个升序链表 来源:力扣(LeetCode) 链接:https://leetcode.cn/problems/merge-k-sorted-lists/description/ 博主Github:https://github.com/GDUT-Rp/LeetCode 题目: 给你一个链表数组…...

[国产MCU]-W801开发实例-TCP客户端
TCP客户端 文章目录 TCP客户端1、TCP协议简单介绍2、W801创建TCP客户流程本文将详细介绍如何在W801中使用TCP客户端。 1、TCP协议简单介绍 传输控制协议 (TCP) 是一种标准,它定义了如何建立和维护应用程序可以用来交换数据的网络对话。 TCP 与 Internet 协议 (IP) 一起工作,…...
《爵士乐史》乔德.泰亚 笔记
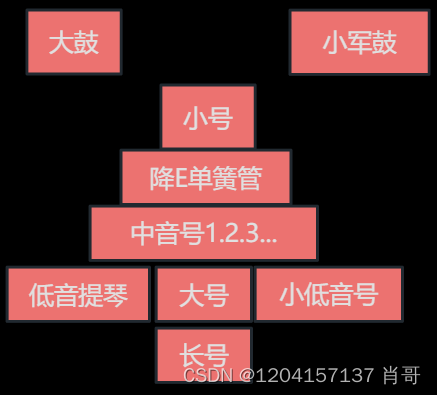
第一章 【美国音乐的非洲化】 【乡村布鲁斯和经典布鲁斯】 布鲁斯:不止包括忧愁、哀痛 十二小节布鲁斯特征: 1.乐型(A:主、B:属、C/D:下属):A→A→B→A→C→D→A→A 2.旋律:大三、小三、降七、降五 盲人…...

工程制造领域:企业IT架构
一、IT组织规划架构图 1.1 IT服务保证梯队与指导思想 二、整体业务规划架构图 三、数据化项目规划架构图 四、应用系统集成架构图...

PY32F003F18点灯
延时函数学习完之后,可以学习PY32F003F18的GPIO输出功能。 1、Debug引脚默认被置于复用功能上拉或下拉模式:PA14默认为SWCLK: 置于下拉模式PA13默认为SWDIO: 置于上拉模式PF4默认为Boot:Boot引脚默认置于输入下拉模式 2、GPIO输出状态&#…...
Mac不想用iTerm2了怎么办
这东西真是让人又爱又恨,爱的是它的UI还真不错,恨的是它把我的环境给破坏啦!让我每次启动终端之后都要重新source激活我的python环境,而且虚拟环境前面没有括号啦!这怎么能忍!在UI和实用性面前我断然选择实…...

x86_64 ansible 源码编译安装
源码 GitHub - ansible/ansible: Ansible is a radically simple IT automation platform that makes your applications and systems easier to deploy and maintain. Automate everything from code deployment to network configuration to cloud management, in a languag…...

数据结构学习系列之顺序表的两种插入方式
方式1:在顺序表末端插入数据元素,代码如下:示例代码: int insert_seq_list_1(list_t *seq_list,int data){if(NULL seq_list){printf("入参为NULL\n");return -1;}if(N seq_list->count){printf("顺序表已满…...
)
Matlab/Python教程系列 | 根据目录下的已有图片制作视频(动画)
MATLAB和Python的编程教程: 根据目录下的已有图片制作视频(动画) 注1:本文系“MATLAB/Python编程教程”系列之一,致力于使用Python和Matlab实现特定的功能。本次要实现的功能是:根据目录下的已有图片制作视频(动画)。 在这个教程中,我们将一起学习如何使用MATLAB和Python编…...
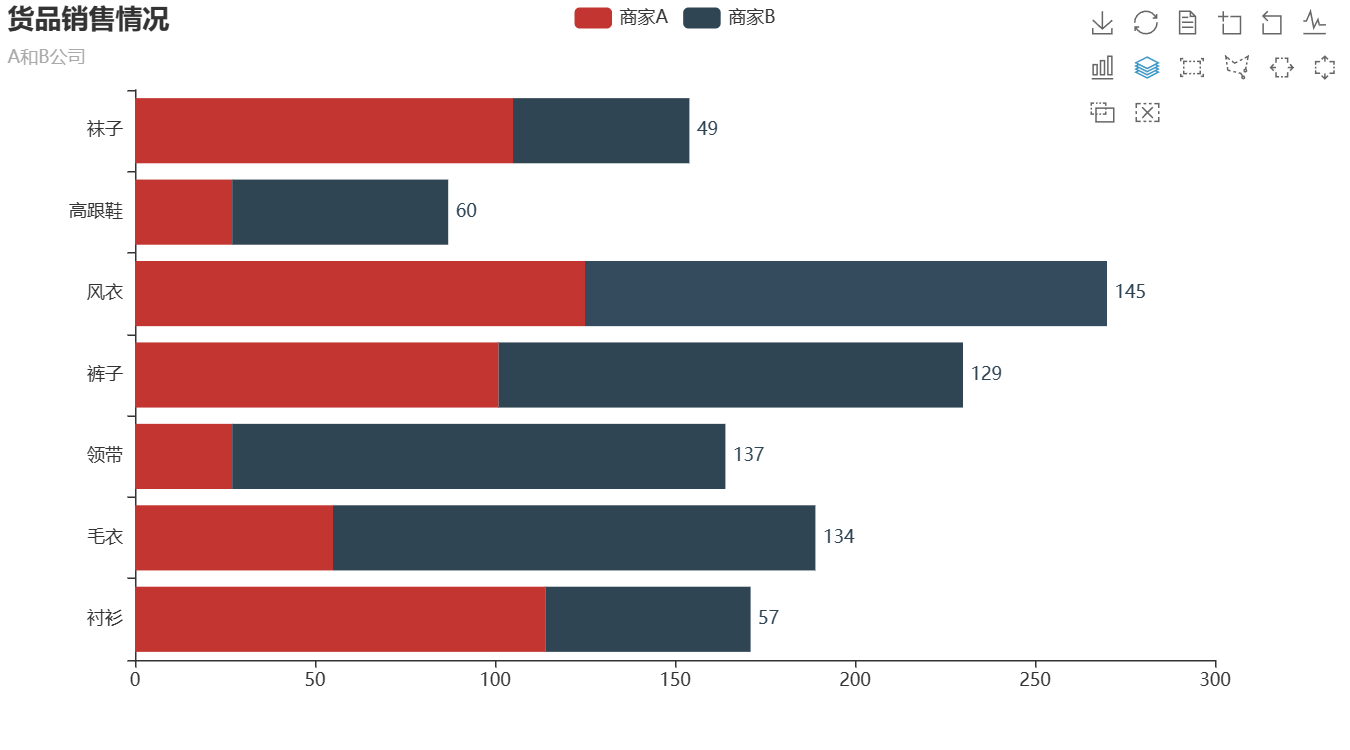
Pyecharts数据可视化(一)
目录 1.Pyecharts简介 2.Pyecharts的常用方法 3.Pyecharts绘制柱状图 3.1 绘制并列柱状图 3.2 绘制水平直方图 1.Pyecharts简介 Pyecharts是一个用于创建交互式图表的Python库。它基于Echarts,一个强大的JavaScript图表库,Pyecharts允许Python开发者…...

stable diffusion实践操作-提示词-图片结构
系列文章目录 stable diffusion实践操作-提示词 文章目录 系列文章目录前言一、提示词汇总1.1 图片结构11.2 图片结构21.3 图片结构3 二、总结 前言 本文主要收纳总结了提示词-图片结构。 一、提示词汇总 1.1 图片结构1 StylesArtistshudson river school哈得逊河学派alpho…...

程序员自由创业周记#2:前期准备
感恩 上次公开了创业的决定后,得到了很多亲朋好友和陌生朋友的鼓励或支持,以不同的形式,感动之情溢于言表。这些都会记在心里,大恩不言谢~ 创业方向 笔者是一名资质平平的iOS开发程序猿,创业项目也就是开发App卖&am…...
:Springboot实现Elasticsearch指标聚合与下钻分析open-API)
Elasticsearch实战(四):Springboot实现Elasticsearch指标聚合与下钻分析open-API
文章目录 系列文章索引一、指标聚合与分类1、什么是指标聚合(Metric)2、Metric聚合分析分为单值分析和多值分析两类3、概述 二、单值分析API设计1、Avg(平均值)(1)对所有文档进行avg聚合(DSL)(2…...
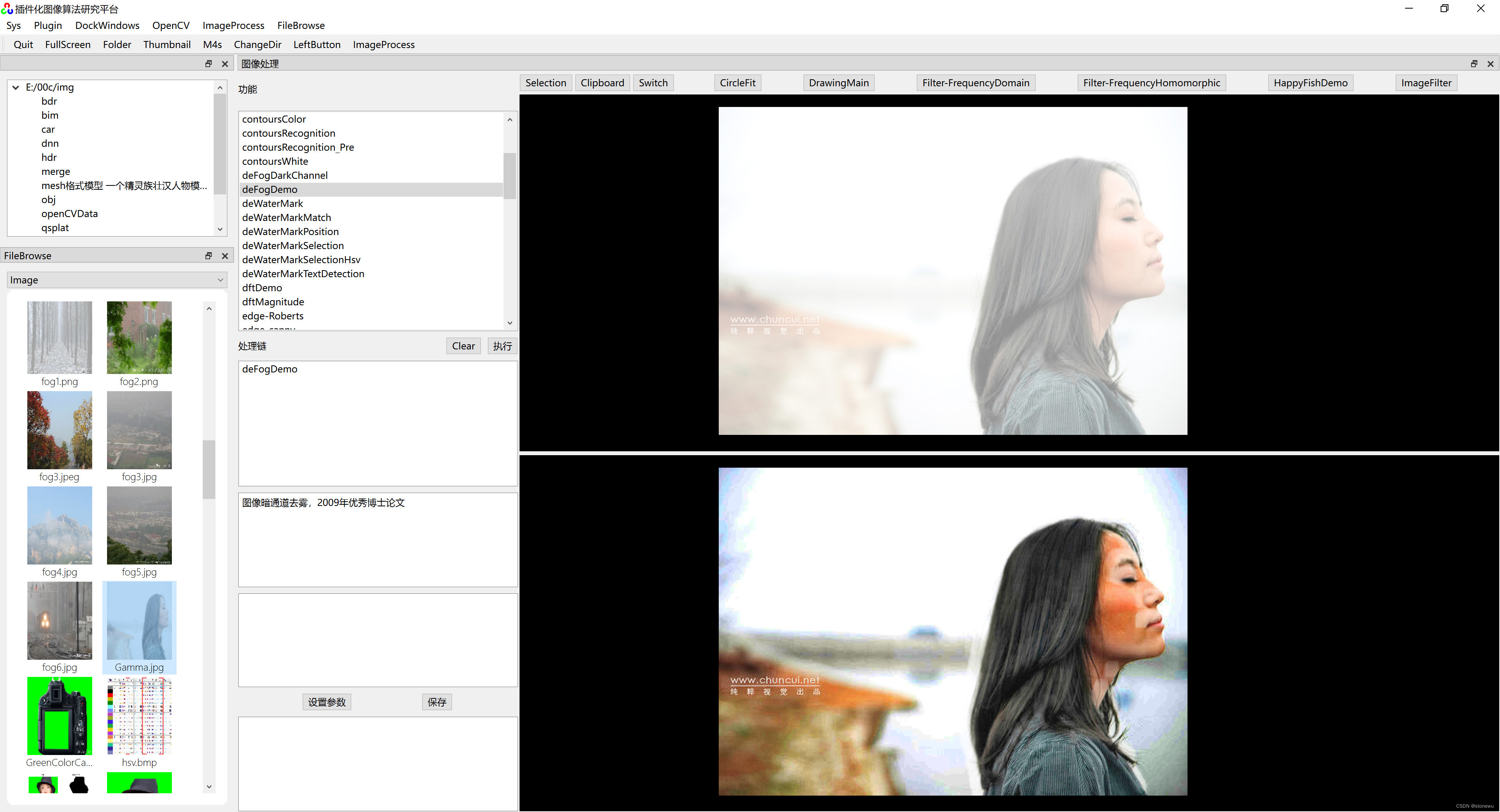
Opencv图像暗通道调优
基于雾天退化模型的去雾算法,Opencv图像暗通道调优,(清华版代码)对普通相片也有较好的调优效果,相片更通透。 结合代码实际运行效果、算法理论模型、实际代码。我个人理解,实际效果是对图像的三个颜色通道…...

怎样来实现流量削峰方案
削峰从本质上来说就是更多地延缓用户请求,以及层层过滤用户的访问需求,遵从“最后落地到数据库的请求数要尽量少”的原则。 1.消息队列解决削峰 要对流量进行削峰,最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直…...

git status搜索.c和.h后缀及git新建分支
git status搜索.c和.h后缀及git新建分支 1.脚本代码2.git新建分支(1)创建新分支(2)删除本地分支(3)删除远端分支(4)合并分支3.指定历史版本创建分支1.脚本代码 $ git status | grep "\.[hc]$"$ 是行尾的意思 \b 就是用在你匹配整个单词的时候。 如果不是整个…...

用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南
用PyTorch复现BCNet息肉分割模型:从论文到代码的保姆级实践指南 医学影像分析领域,息肉分割一直是内窥镜诊断的关键技术。传统方法依赖医生手动标注,效率低下且易受主观因素影响。近年来,深度学习在医学图像分割领域展现出强大潜…...
)
手把手教你搞定Windows下的NAMD和VMD安装(附最新版下载与注册避坑指南)
Windows平台NAMD与VMD安装全攻略:从零开始玩转分子动力学模拟 当第一次接触分子动力学模拟时,软件安装往往是新手面临的第一个挑战。NAMD和VMD作为该领域最常用的工具组合,它们的安装过程看似简单,实则暗藏诸多细节。本文将带你从…...

视觉伺服visual servoing
模拟视觉反馈(图像 X/Y 偏差)自动控制机械臂末端向目标移动闭环控制,偏差越小速度越低无硬件相机也能运行(内置虚拟视觉信号)视觉伺服 Visual Servoing 示例代码cpp运行/********************************************…...

从SPEF到STA:一份寄生参数文件如何影响你的芯片时序签核?
SPEF文件在芯片时序签核中的关键作用与实战解析 芯片设计工程师们常说:"SPEF文件是物理世界与逻辑世界的翻译官。"这句话精准概括了SPEF在芯片设计流程中的核心价值。当设计从逻辑综合进入物理实现阶段,金属连线的电阻电容效应开始显著影响信号…...

双足机器人EDF推进系统与高精度扭矩控制技术
1. 双足机器人EDF推进系统深度解析在双足机器人研发领域,姿态控制一直是核心挑战。传统方案依赖腿部关节的精细调节,但在高速运动或突发扰动情况下往往响应不足。我们团队创新性地引入了EDF(电动涵道风扇)推进系统,通过…...

从理论到实践:用Magma解锁代数计算新维度
1. 为什么你需要Magma这个代数计算神器 第一次接触Magma是在研究生时期,当时我需要计算一个椭圆曲线上的有理点。用Matlab折腾了整整一周毫无进展,导师随手扔给我一个Magma代码示例,三行命令就解决了问题。那一刻我才明白,专业的事…...
)
无碳小车S型走不直?可能是你的转向机构参数没调对(附ProE运动仿真分析)
无碳小车S型轨迹优化:基于ProE运动仿真的转向机构参数调试指南 在大学生工程训练竞赛中,无碳小车的S型轨迹表现往往是决定胜负的关键。许多团队在实物调试阶段都会遇到一个共同难题:明明按照理论计算完成了设计,小车却总是走不出理…...

39. UE5 GAS RPG:利用Motion Warping实现技能释放时的智能角色转向
1. Motion Warping插件基础与启用 Motion Warping是UE5官方提供的一个实验性插件,专门用于解决角色动画过程中的动态转向问题。这个插件的工作原理是在动画播放过程中插入一个"变形窗口",允许开发者指定某个时间段内角色的朝向或位置变化。我刚…...

Win11安全中心总弹警告?手把手教你揪出并删除那个‘捣乱’的内存完整性不兼容驱动
Win11安全中心频繁弹窗?三步精准定位并清除内存完整性冲突驱动 每次开机右下角那个黄色三角警告图标是不是让你血压飙升?Windows安全中心反复提醒"内存完整性已关闭",点开一看又提示"驱动程序不兼容"。这种系统级的警告就…...

MacOS MySQL安装
1、安装包下载地址 MySQL Community Server:开源版本,适用于个人和小型企业。MySQL Enterprise Edition:商业版本,提供额外的功能和技术支持。MySQL Cluster:分布式数据库系统,适用于高可用性和高并发场景…...