9、GPT-1-2-3
GPT
GPT系列即基于Transformer Decoder实现的预训练语言模型,在各类复杂的NLP任务中都取得了不错的效果,如文章生成、代码生成、机器翻译,Q&A等。
对于一个新的任务,GPT仅仅需要非常少的数据便可以理解该任务,并达到或超过其他工作的效果。
GTP系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模的质量,提升网络的参数数量,因此GPT模型的训练需要超大的训练预料,超多的参数和计算资源。

GPT-1:无监督学习
Improving Language Understanding by Generative Pre-Training
github:https://gluebenchmark.com/leaderboard
在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点
- 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP;
根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP
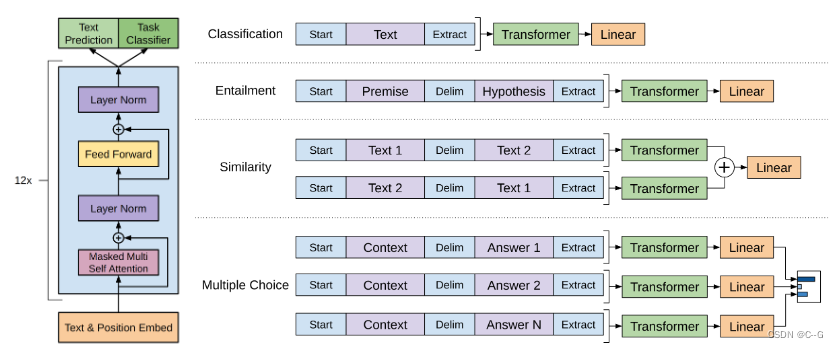
GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定热任务进行微调,处理的有监督任务包括:
- 分类(Classification):判断输入文本类别
- 推理 (Entailment):判断两个句子之间的关系(包含、矛盾、中立)
- 相似度(Semantic Similarity):判断句子语义是否相关
- 问答和常理推理(Question answering and commonsense reasoning):类似多选题,一个文章,多个答案,预测每个答案的正确概率
无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列 ,语言模型的优化目标是最大化下面的似然值
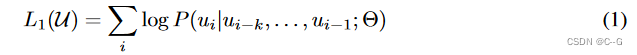
其中 K 是滑动窗口的大小,P 是条件概率, θ\thetaθ 是模型的参数。这些参数使用SGD进行优化。(Transformer Decoder训练方式,当前词只能依据前面的词推断,对后面的词是不知道的)
如上图所示,GPT-1使用了12个Transformer块作为Decoder,每个Transformer块是一个多头自注意力机制,通过全连接得到输出的概率分布。
Decoder流程公式如下:
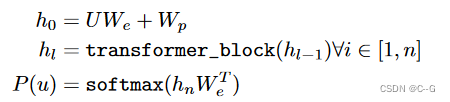
U=(Uk,...,U1)U=(U_k,...,U_1)U=(Uk,...,U1)是当前时间片的上下文token,n是层数,WeW_eWe是词嵌入矩阵,WpW_pWp是位置嵌入矩阵
有监督微调
经过无监督的预训练模型后,将模型直接应用到有监督的任务中。
有标签数据集C,每个实例有m个输入token:{X1,...,XmX^1,...,X^mX1,...,Xm},标签y。将token输入进模型,得到最终的特征向量 hlmh_l^mhlm,最后通过一个全连接层得到预测结果。
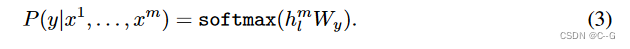
WyW_yWy为全连接层的参数。损失函数为:
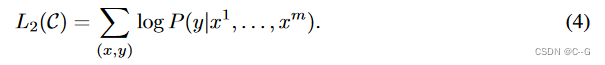
作者将无监督训练和有监督微调的损失结合在一起,通过 λ\lambdaλ 对损失分配权重,λ\lambdaλ 一般为0.5
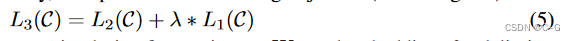
当进行有监督微调的时候,只训练输出层的WyW_yWy和分隔符(delimiter)的嵌入值
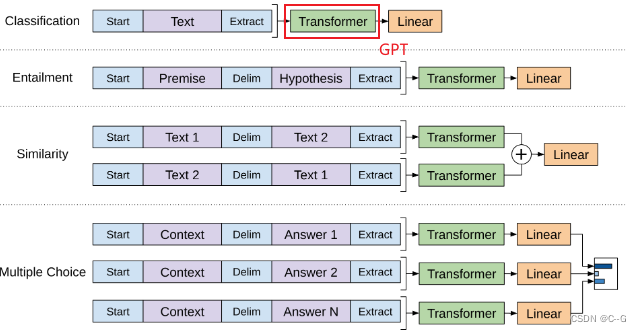
对不同任务的输入进行变换
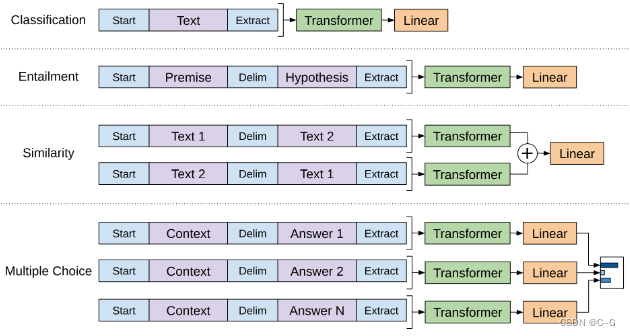
- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果
- 问答和常识推理:将 n 个选项的问题抽象化为 n 个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
实验
GPT-1 使用了BooksGorpus数据集,包含了 7,000本没有发布的书籍,该数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系,并且这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力
无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有40,000个字节对
- 词编码的长度为768
- 位置编码也需要学习
- 12层的transformer,每个transformer块有12个头
- 位置编码的长度是 3,072
- Attention,残差,Dropout等机制用来进行正则化,drop的比例为:0.1
- 激活函数为GLEU
- 训练的batchsize为64,学习率为2.5e-4,序列长度为512,序列epoch为100
- 模型参数数量为1.17亿
有监督微调
- 无监督部分的模型也会用来微调
- 训练的epoch为3,学习率为6.25e-5,这表明模型在无监督部分学到了大量有用的特征
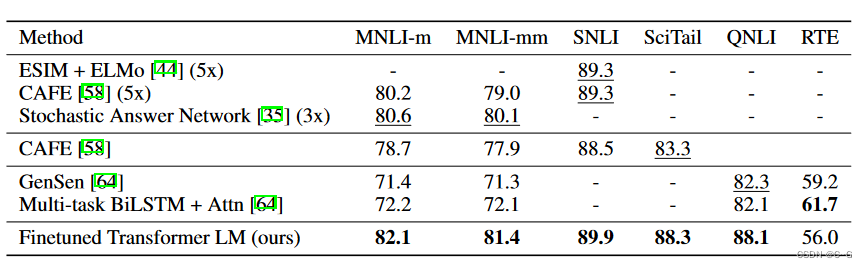
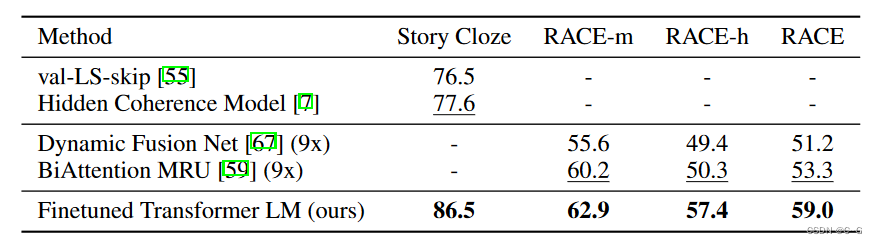
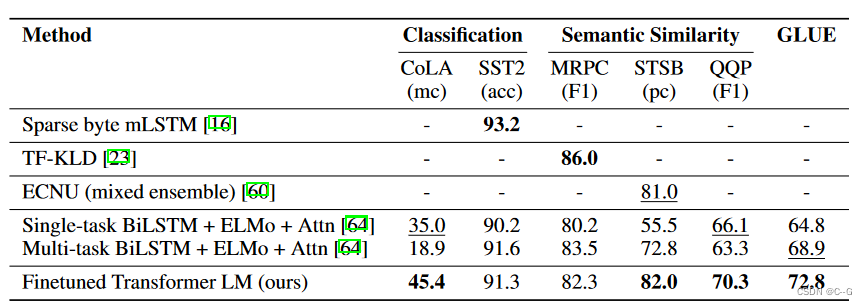
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
GPT-2:多任务学习
Language Models are Unsupervised Multitask Learners
随着模型层数的叠加,参数量随之增加,这时候对模型进行微调也需要消耗大量资源。GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集
核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积
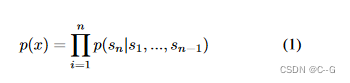
上式也可以表示为p(sn−k,...sn∣s1,s2,...,sn−k−1)p(s_{n-k},...s_n|s_1,s_2,...,s_{n-k-1})p(sn−k,...sn∣s1,s2,...,sn−k−1),实际意义是根据已知的上下文 input={s1,s2,...,sn−k−1}input = \{ s_1,s_2,...,s_{n-k-1} \}input={s1,s2,...,sn−k−1}预测未知的下文 output={sn−k,...,sk}output = \{ s_{n-k},...,s_k\}output={sn−k,...,sk},因此语言模型可以表示为 p(output∣input,task)p(output|input,task)p(output∣input,task)的形式,在decaNLP中,他们提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。
基于上面的思想,作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
综上,GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
实验
- 同样使用了使用字节对编码构建字典,字典的大小为 50,257
- 滑动窗口的大小为 1,024
- batchsize的大小为 512
- Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization;
- 将残差层的初始化值用 1/N1/\sqrt{N}1/N进行缩放,其中 N 是残差层的个数
GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。
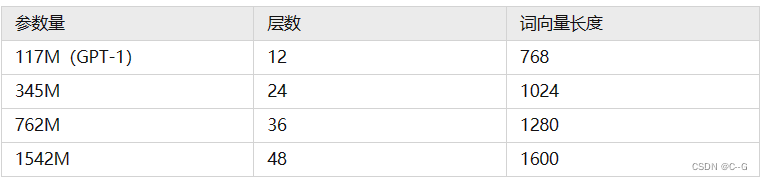
性能
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children’s Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
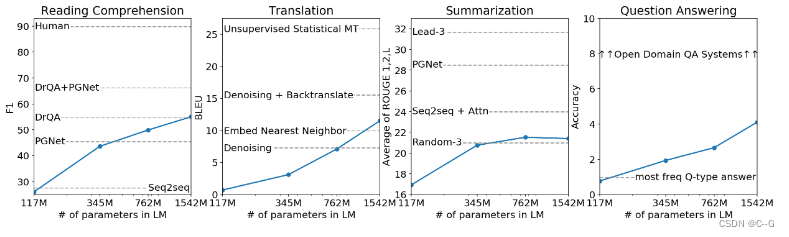
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了下面要介绍的GPT-3。
GPT-3:海量参数
Language Models are Few-Shot Learners
GPT-3仅仅需要zero-shot、one-shot或者few-shot,GPT-3就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的 1,750亿的参数量, 45TB的训练数据以及高达 1,200万美元的训练费用
In-context learning
In-context learning是这篇论文中介绍的一个重要概念,要理解in-context learning,需要先理解meta-learning(元学习)。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
输入需求+(案例)+问题,模型的Attention机制在Prompt中找上下文信息,给出答案
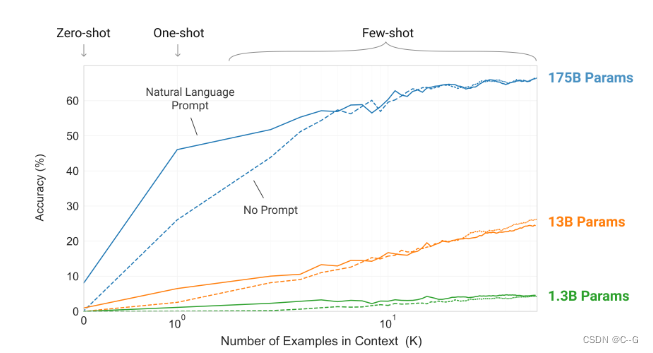
在few-shot learning中,提供若干个(10 - 100个)示例和任务描述供模型学习。one-shot laerning是提供1个示例和任务描述。zero-shot则是不提供示例,只是在测试时提供任务相关的具体描述。作者对这3种学习方式分别进行了实验,实验结果表明,三个学习方式的效果都会随着模型容量的上升而上升,且few shot > one shot > zero show。

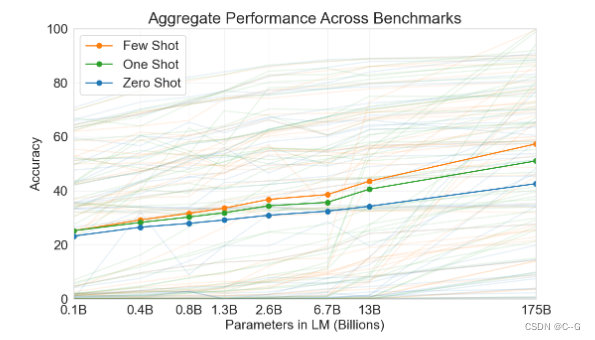
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
实验
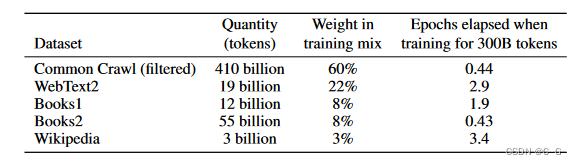
GPT-3共训练了5个不同的语料,分别是低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到。
模型结构
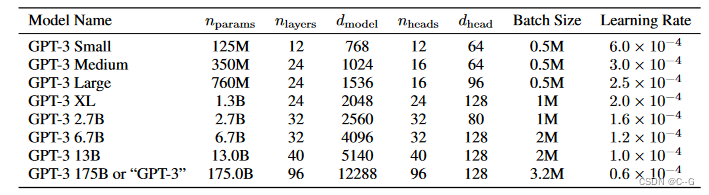
使用了alternating dense和locally banded sparse attention。
仅仅用惊艳很难描述GPT-3的优秀表现。首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
总结
GPT系列从1到3,通通采用的是transformer架构,可以说模型结构并没有创新性的设计。在微软的资金支持下,这更像是一场赤裸裸的炫富:1750亿的参数,31个分工明确的作者,超强算力的计算机(285,000 个CPU, 10,000个GPU),1200万的训练费用,45TB的训练数据(维基百科的全部数据只相当于其中的 0.6%)。这种规模的模型是一般中小企业无法承受的,而个人花费巨金配置的单卡机器也就只能做做微调或者打打游戏了。甚至在训练GPT-3时出现了一个bug,OpenAI自己也没有资金重新训练了。
读懂了GPT-3的原理,相信我们就能客观的看待媒体上对GPT-3的过分神话了。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛。基于这个原因,GPT-3学到的模型分布也很难摆脱这个数据集的分布情况。得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。例如通过目前的测试来看,GPT-3还有很多缺点的:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
参考于:https://zhuanlan.zhihu.com/p/350017443
相关文章:
9、GPT-1-2-3
GPT GPT系列即基于Transformer Decoder实现的预训练语言模型,在各类复杂的NLP任务中都取得了不错的效果,如文章生成、代码生成、机器翻译,Q&A等。 对于一个新的任务,GPT仅仅需要非常少的数据便可以理解该任务,并…...

Python-四分位数计算
怎么计算四分位数先理解四分位数怎么计算:可参考https://zhuanlan.zhihu.com/p/235345817,假设数列一共有n个数1)当 (n1)/4可以整除时,Q1第在(n1)/4位Q2第 (n1)/2位Q3第(n1)/4*3位举…...
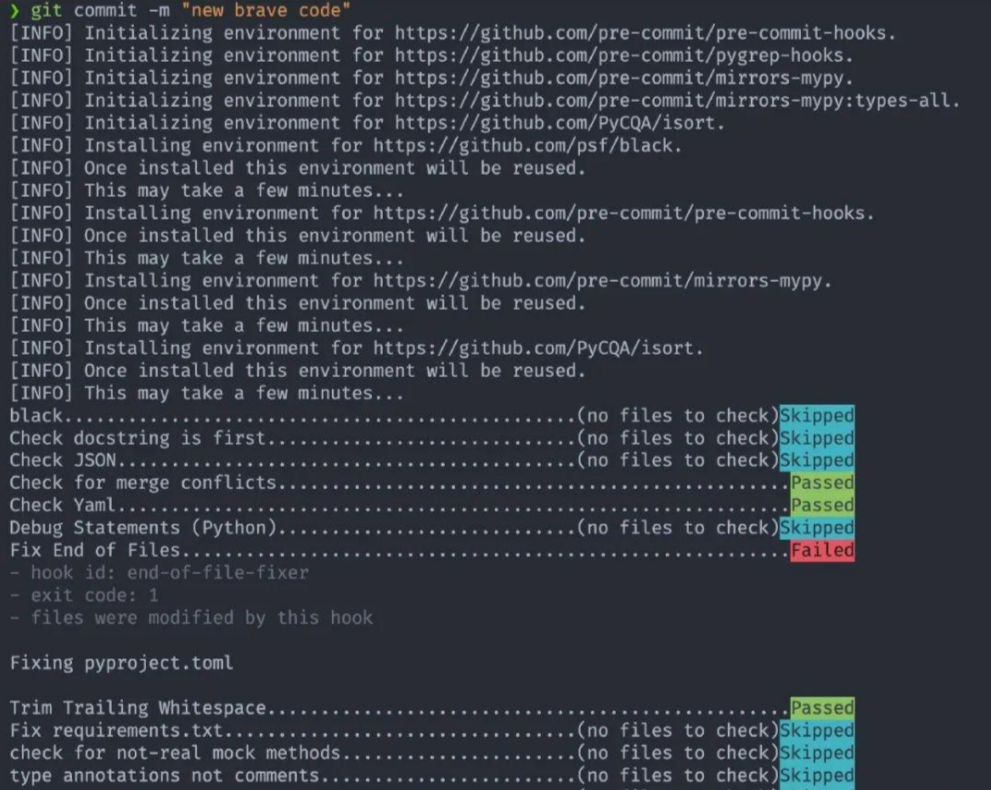
一个简单的步骤让你的 Python 代码更干净
说起来容易做起来难,我们都知道代码可读性非常重要,但是写的时候总是随心所欲,不考虑类型提示、import 排序、PEP8 规范。今天分享一个小技巧,通过一个简单的步骤就可以让你的 Python 代码更干净。这就是 pre-commit:可…...
linux集群技术(二)--keepalived(高可用集群)(一)
高可用集群简介keepalived简介 1.高可用集群简介 1.1什么是高可用集群 高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务&am…...
C++中的类型转换
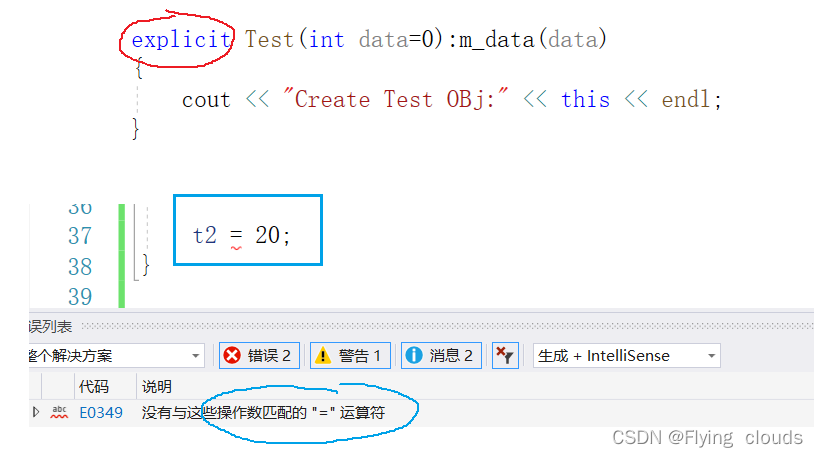
目录 一、C语言中的类型转换 二、C中的类型转化 2.1 static_cast 2.2 const_cast2.2 const_cast 2.3reinterpret_cast 重解释转换 2.4 dynamic_cast 动态转换(!!!) 3. explicit 防止隐式类型转化 一、C语言…...

如何使用raw socket发送UDP报文
前面写的一篇《Linux下如何在数据链路层接收原始数据包》举了一个实例,使用raw socket接收UDP数据报,但是发送一个数据包比接收要复杂一些,本文以一个实例说明如何使用raw socket发送一个UDP报文。 1. 前言 阅读本文前可以考虑先阅读一下我的另外一篇文章《Linux下如何在数据…...
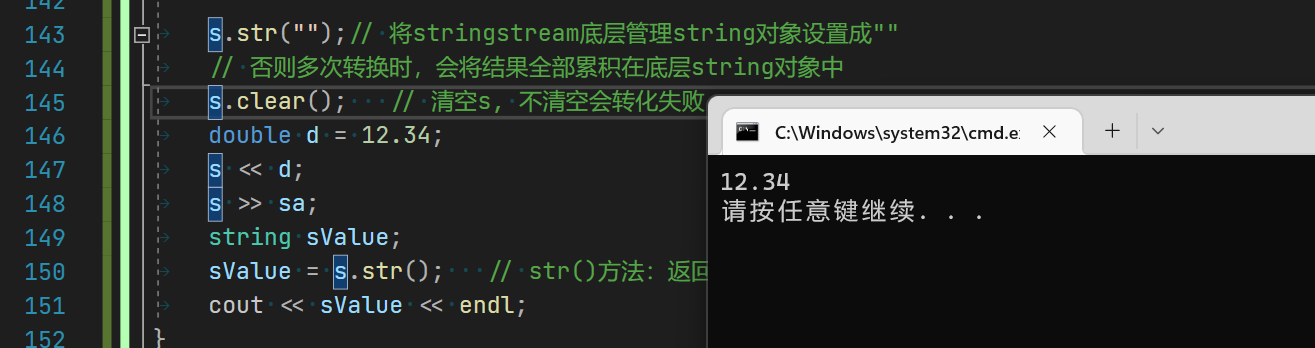
【C++】文件IO流
一起来康康C中的文件IO操作吧 文章目录1.operator bool2.C文件IO流3.文件操作3.0 关于按位与的说明3.1 ifstream3.2 ofstream流插入文本3.3 ostringstream/istringstream3.4 stringstream3.5使用stringstream的注意事项结语1.operator bool 之前写OJ的时候,就已经用…...
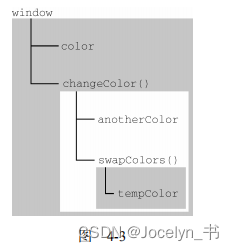
JavaScript高级程序设计读书分享之4章——4.2执行上下文与作用域
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 执行上下文 变量或函数的上下文决定 了它们可以访问哪些数据,以及它们的行为。在浏览器中,全局上下文就是我们常说的 window 对象(第 12 章会详细介绍)&am…...

函数的定义与声明
目录 1.函数的定义 2.函数声明 2.1 函数本地声明 2.2 函数外部声明 2.2.1函数的外部声明的好处和坏处 3.变量定义与声明 3.1变量定义 3.2变量声明 4.结构体的定义与声明 4.1结构体的定义 4.2结构体的声明 1.函数的定义 函数的定义即函数的具体实现。 2.函数声明 函数…...
mysql)
C#部署非安装版(绿色版)mysql
C#部署非安装版(绿色版)mysql场景实现步骤场景 项目由bs和cs端组成,bs端的数据存储在了mysql中,cs依赖bs运行,bs会显示一些实时的信息。 需求是给客户一个安装包,简易操作就可安装完成。 使用版本…...
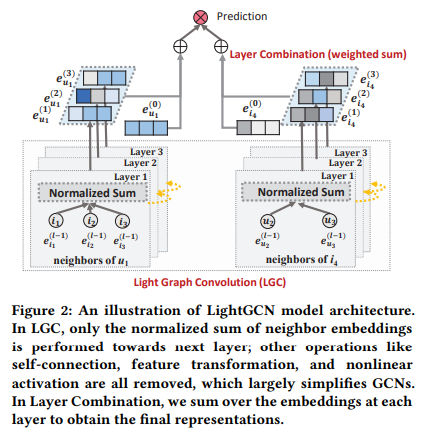
【RecBole-GNN/源码】RecBole-GNN中lightGCN源码解析
如果觉得我的分享有一定帮助,欢迎关注我的微信公众号 “码农的科研笔记”,了解更多我的算法和代码学习总结记录。或者点击链接扫码关注【RecBole-GNN/源码】RecBole-GNN中lightGCN源码解析 【RecBole-GNN/源码】RecBole-GNN中lightGCN源码解析 原文&…...
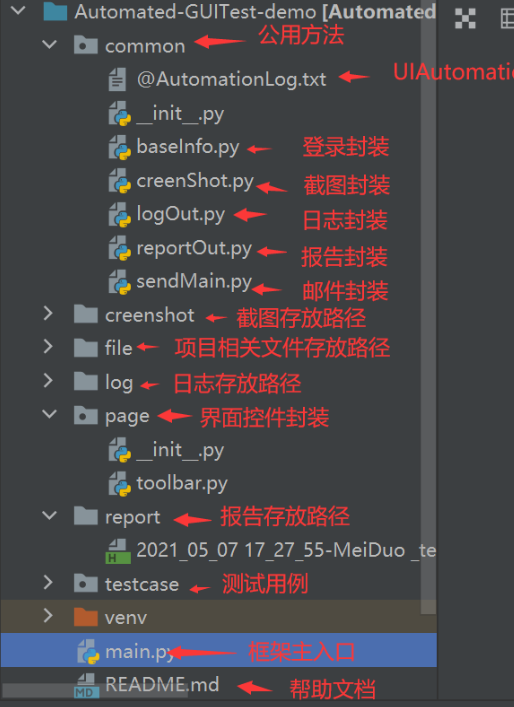
基于UIAutomation+Python+Unittest+Beautifulreport的WindowsGUI自动化测试框架common目录解析
文章目录1 框架工具说明2 技术栈说明3 框架截图4 源码解析/common目录4.1 common/baseinfo.py4.2 common/creenShot.py4.3 common/logOut.py4.4 common/reportOut.py4.5 common/sendMail.py注: 1、本文为本站首发,他用请联系作者并注明出处,谢…...

c++提高篇——queque容器
一、queque容器基本概念 Queue是一种先进先出(FIFO)的教据结构,它有两个出口 队列容器允许从一端新增元素,从另一端移除元素。队列中只有队头和队尾才可以被外界使用,因此队列不允许有遍历行为队列中进数据。 queque容器可以形象化为生活中…...
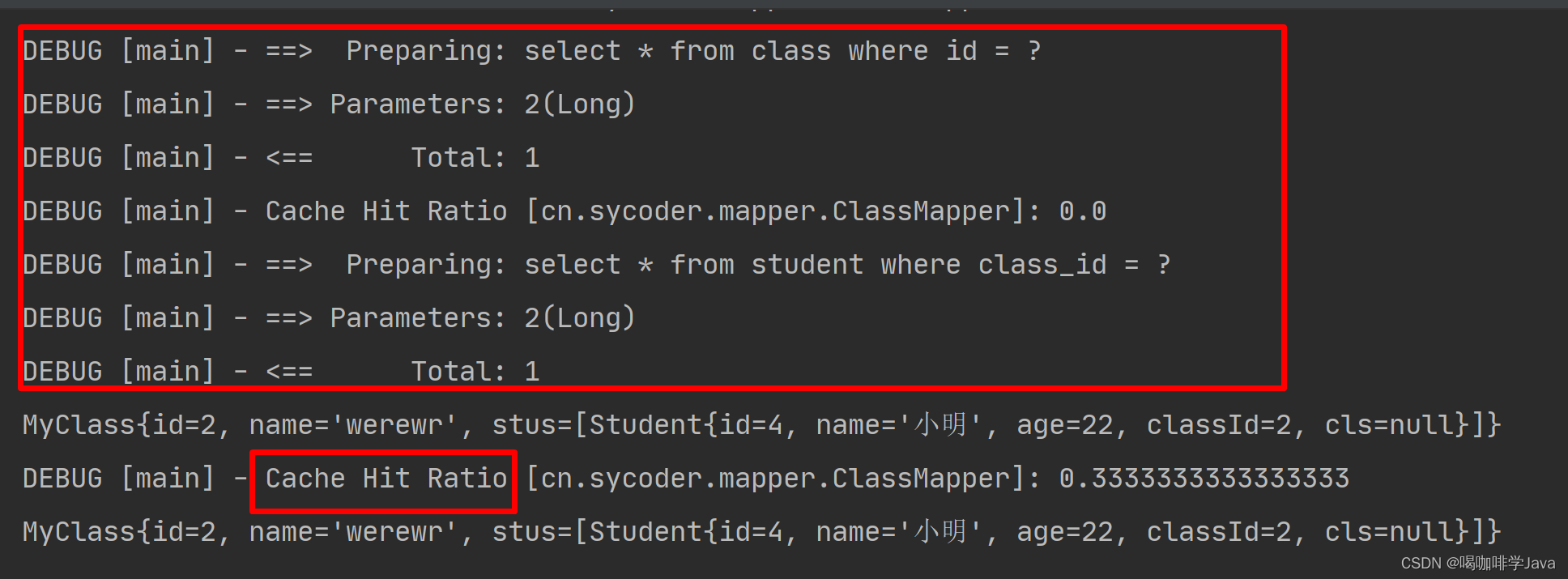
MyBatis-XML映射文件详解
一、XML 映射器 1.概述 使用 xml 文件去配置 SQL 代码,比传统的 jdbc 简单方便,能够少写代码,减少使用成本,提高工作效率。 1.1SQL 映射文件中的顶级元素 cache – 该命名空间的缓存配置。 cache-ref – 引用其它命名空间的缓…...

基于Java+SpringBoot+Vue+Uniapp前后端分离健身预约系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《Spring家族及…...
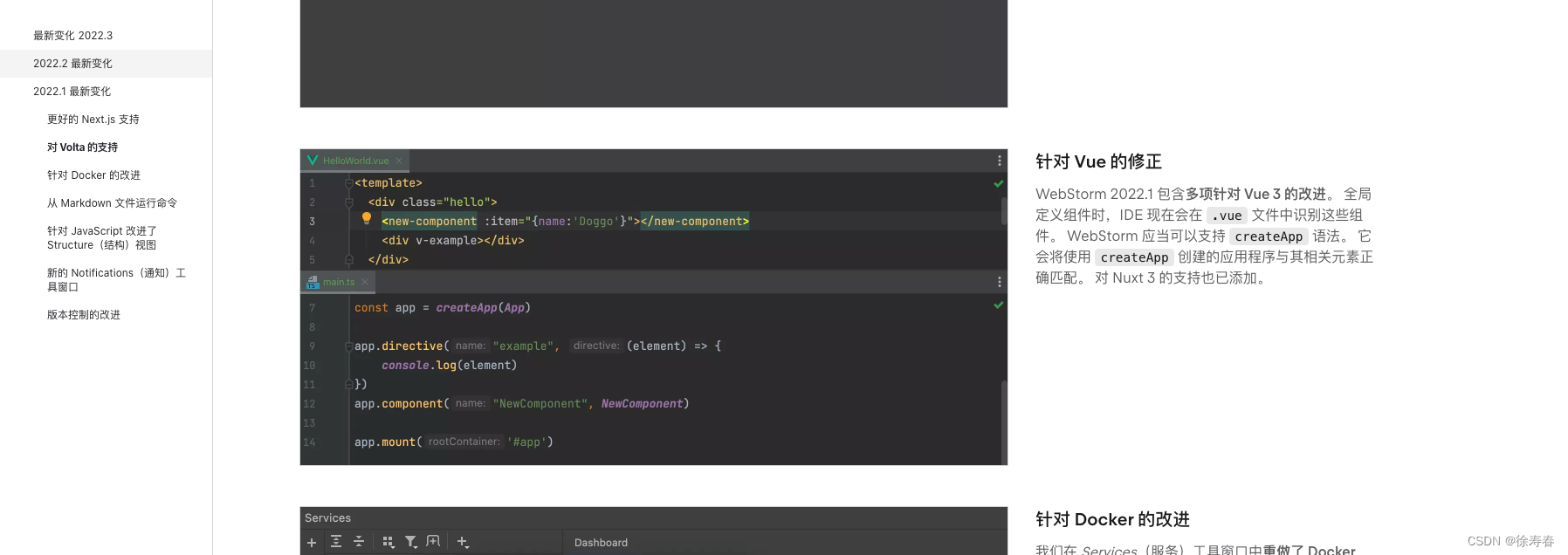
webstom找不到vue全局组件
我真多服气,引入了自动组件注册 // 自动引入组建import { ElementPlusResolver } from unplugin-vue-components/resolversComponents({directoryAsNamespace: true,resolvers: [ElementPlusResolver()]}),生成了 components.d.ts 但是我在webstom中定义了标签 除非…...

ESP32设备驱动-内置霍尔磁力传感器数据读取
内置霍尔磁力传感器数据读取 文章目录 内置霍尔磁力传感器数据读取1、ESP32霍尔磁力传感器介绍2、软件准备3、硬件准备4、读取霍尔磁力传感值5、运行结果ESP32开发板具有内置霍尔效应传感器,可检测周围磁场的变化。本文将介绍如何在Arduino IDE中读取ESP32霍尔效应传感器的数据…...

2023面试准备之--mysql
文章目录mysql存储引擎索引聚簇索引和非聚簇索引事务锁MVCC机制(类似于copy on write)主从复制为什么要主从同步?怎么处理mysql的慢查询?mysql clint ---->server ----> 存储引擎 存储引擎 Innodb 是MySQL5.5版本及之后默…...
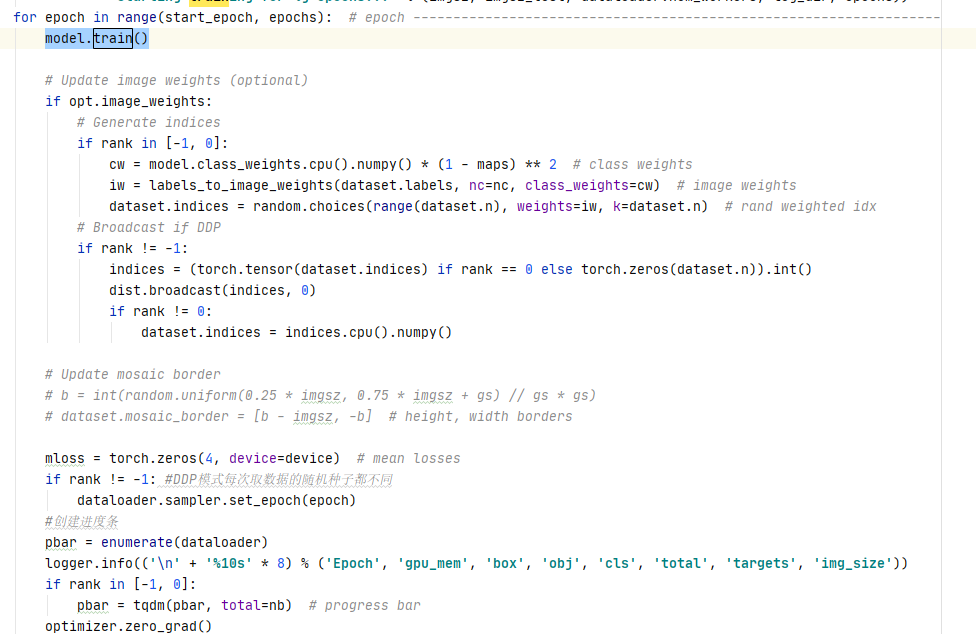
yolov5源码解读--训练策略
yolov5源码解读--训练策略超参数解读命令行参数train模型迭代超参数解读 hyp.scratch.yaml lr0: 0.0032 初始学习率 lrf: 0.12 使用余弦函数动态降低学习率(lr0*lrf) momentum: 0.843 动量 weight_decay: 0.00036 权重衰减项 warmup_epochs: 2.0 预热(…...
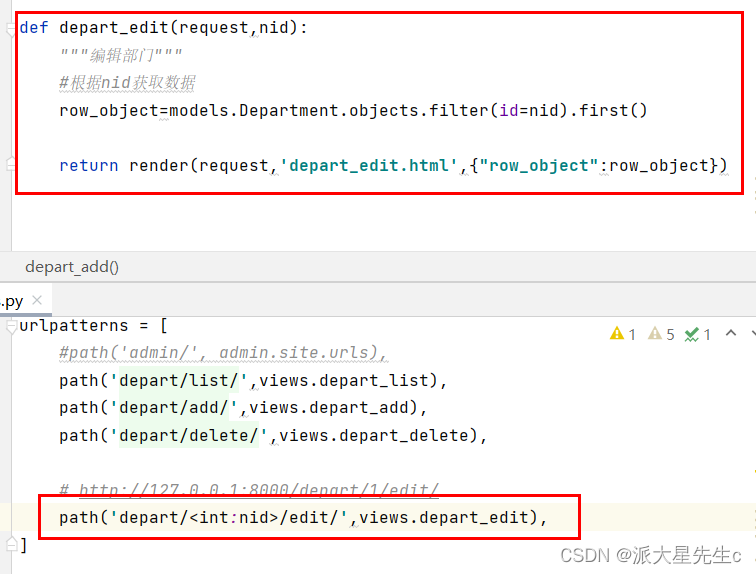
基于Django的员工管理系统
目录 一、新建项目 二、创建app 三、设计表结构 四、在MySQL中生成表 五、静态文件管理 六、添加页面 七、模板的继承 一、新建项目 django-admin startproject 员工管理系统 二、创建app startapp app01 三、设计表结构 app01/migrations/models.py from django.db impo…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...