TDengine函数大全-聚合函数
以下内容来自 TDengine 官方文档 及
GitHub 内容 。以下所有示例基于 TDengine 3.1.0.3
TDengine函数大全
1.数学函数
2.字符串函数
3.转换函数
4.时间和日期函数
5.聚合函数
6.选择函数
7.时序数据库特有函数
8.系统函数
聚合函数
- TDengine函数大全
- APERCENTILE
- AVG
- COUNT
- ELAPSED
- LEASTSQUARES
- SPREAD
- STDDEV
- SUM
- HYPERLOGLOG
- HISTOGRAM
- PERCENTILE
APERCENTILE
APERCENTILE(expr, p [, algo_type])algo_type: {"default"| "t-digest"
}
功能说明:统计表/超级表中指定列的值的近似百分比分位数,与 PERCENTILE 函数相似,但是返回近似结果。
返回数据类型: DOUBLE。
适用数据类型:数值类型。
适用于:表和超级表。
说明:
- p值范围是[0,100],当为0时等同于MIN,为100时等同于MAX。
- algo_type 取值为 “default” 或 “t-digest”。 输入为 “default” 时函数使用基于直方图算法进行计算。输入为 “t-digest” 时使用t-digest算法计算分位数的近似结果。如果不指定 algo_type 则使用 “default” 算法。
- "t-digest"算法的近似结果对于输入数据顺序敏感,对超级表查询时不同的输入排序结果可能会有微小的误差。
示例:
> select * from t6;ts | v1 |
========================================2023-08-31 09:46:31.582 | 1 |2023-08-31 09:46:33.366 | 2 |2023-08-31 09:46:35.271 | 3 |2023-08-31 09:46:37.699 | 4 |2023-08-31 09:46:39.562 | 5 |2023-08-31 09:46:41.868 | 6 |2023-08-31 09:46:44.229 | 7 |2023-08-31 09:46:46.365 | 8 |2023-08-31 09:46:48.345 | 9 |2023-08-31 09:46:50.451 | 10 |> select apercentile(v1,10) from t6;apercentile(v1,10) |
============================1.000000000000000 |> select apercentile(v1,20) from t6;apercentile(v1,20) |
============================2.000000000000000 |> select apercentile(v1,90) from t6;apercentile(v1,90) |
============================9.000000000000000 |> select apercentile(v1,90,"t-digest") from t6;apercentile(v1,90,"t-digest") |
================================9.500000000000000e+00 |AVG
AVG(expr)
功能说明:统计指定字段的平均值。
返回数据类型:DOUBLE。
适用数据类型:数值类型。
适用于:表和超级表。
示例:
> select * from t6;ts | v1 |
========================================2023-08-31 09:46:31.582 | 1 |2023-08-31 09:46:33.366 | 2 |2023-08-31 09:46:35.271 | 3 |2023-08-31 09:46:37.699 | 4 |2023-08-31 09:46:39.562 | 5 |2023-08-31 09:46:41.868 | 6 |2023-08-31 09:46:44.229 | 7 |2023-08-31 09:46:46.365 | 8 |2023-08-31 09:46:48.345 | 9 |2023-08-31 09:46:50.451 | 10 |> select avg(v1) from t6;avg(v1) |
============================5.500000000000000 |
COUNT
COUNT({* | expr})
功能说明:统计指定字段的记录行数。
返回数据类型:BIGINT。
适用数据类型:全部类型字段。
适用于:表和超级表。
使用说明:
- 可以使用星号(*)来替代具体的字段,使用星号(*)返回全部记录数量。
- 如果统计字段是具体的列,则返回该列中非 NULL 值的记录数量。
示例:
> select * from t6;ts | v1 |
========================================2023-08-31 09:46:31.582 | 1 |2023-08-31 09:46:33.366 | 2 |2023-08-31 09:46:35.271 | 3 |2023-08-31 09:46:37.699 | 4 |2023-08-31 09:46:39.562 | 5 |2023-08-31 09:46:41.868 | 6 |2023-08-31 09:46:44.229 | 7 |2023-08-31 09:46:46.365 | 8 |2023-08-31 09:46:48.345 | 9 |2023-08-31 09:46:50.451 | 10 |> select count(*) from t6;count(*) |
========================10 |> select count(v1) from t6;count(v1) |
========================10 |> select count(*) from (select count(v1) from t6);count(*) |
========================1 |
ELAPSED
ELAPSED(ts_primary_key [, time_unit])
功能说明:elapsed函数表达了统计周期内连续的时间长度,和twa函数配合使用可以计算统计曲线下的面积。在通过INTERVAL子句指定窗口的情况下,统计在给定时间范围内的每个窗口内有数据覆盖的时间范围;如果没有INTERVAL子句,则返回整个给定时间范围内的有数据覆盖的时间范围。注意,ELAPSED返回的并不是时间范围的绝对值,而是绝对值除以time_unit所得到的单位个数。
返回结果类型:DOUBLE。
适用数据类型:TIMESTAMP。
适用于: 表,超级表,嵌套查询的外层查询
说明:
- ts_primary_key参数只能是表的第一列,即 TIMESTAMP 类型的主键列。
- 按time_unit参数指定的时间单位返回,最小是数据库的时间分辨率。time_unit 参数未指定时,以数据库的时间分辨率为时间单位。支持的时间单位 time_unit 如下:
1b(纳秒), 1u(微秒),1a(毫秒),1s(秒),1m(分),1h(小时),1d(天), 1w(周)。 - 可以和interval组合使用,返回每个时间窗口的时间戳差值。需要特别注意的是,除第一个时间窗口和最后一个时间窗口外,中间窗口的时间戳差值均为窗口长度。
- order by asc/desc不影响差值的计算结果。
- 对于超级表,需要和group by tbname子句组合使用,不可以直接使用。
- 对于普通表,不支持和group by子句组合使用。
- 对于嵌套查询,仅当内层查询会输出隐式时间戳列时有效。例如select elapsed(ts) from (select diff(value) from sub1)语句,diff函数会让内层查询输出隐式时间戳列,此为主键列,可以用于elapsed函数的第一个参数。相反,例如select elapsed(ts) from (select * from sub1) 语句,ts列输出到外层时已经没有了主键列的含义,无法使用elapsed函数。此外,elapsed函数作为一个与时间线强依赖的函数,形如select elapsed(ts) from (select diff(value) from st group by tbname)尽管会返回一条计算结果,但并无实际意义,这种用法后续也将被限制。
- 不支持与leastsquares、diff、derivative、top、bottom、last_row、interp等函数混合使用。
示例:
> select * from t6;ts | v1 |
========================================2023-08-31 09:46:31.582 | 1 |2023-08-31 09:46:33.366 | 2 |2023-08-31 09:46:35.271 | 3 |2023-08-31 09:46:37.699 | 4 |2023-08-31 09:46:39.562 | 5 |2023-08-31 09:46:41.868 | 6 |2023-08-31 09:46:44.229 | 7 |2023-08-31 09:46:46.365 | 8 |2023-08-31 09:46:48.345 | 9 |2023-08-31 09:46:50.451 | 10 |> select elapsed(ts) from t6;elapsed(ts) |
============================18869.000000000000000 |> select elapsed(ts,1s) from t6;elapsed(ts,1s) |
============================18.869000000000000 |> select elapsed(ts,1m) from t6;elapsed(ts,1m) |
============================0.314483333333333 |> select elapsed(ts,1h) from t6;elapsed(ts,1h) |
============================0.005241388888889 |> select elapsed(ts,1u) from t6;DB error: ELAPSED function time unit parameter should be greater than db precision (0.000691s)> select _wstart,_wend,elapsed(ts,1a) from t6 interval(1s);_wstart | _wend | elapsed(ts,1a) |
================================================================================2023-08-31 09:46:31.000 | 2023-08-31 09:46:32.000 | 418.000000000000000 |2023-08-31 09:46:33.000 | 2023-08-31 09:46:34.000 | 1000.000000000000000 |2023-08-31 09:46:35.000 | 2023-08-31 09:46:36.000 | 1000.000000000000000 |2023-08-31 09:46:37.000 | 2023-08-31 09:46:38.000 | 1000.000000000000000 |2023-08-31 09:46:39.000 | 2023-08-31 09:46:40.000 | 1000.000000000000000 |2023-08-31 09:46:41.000 | 2023-08-31 09:46:42.000 | 1000.000000000000000 |2023-08-31 09:46:44.000 | 2023-08-31 09:46:45.000 | 1000.000000000000000 |2023-08-31 09:46:46.000 | 2023-08-31 09:46:47.000 | 1000.000000000000000 |2023-08-31 09:46:48.000 | 2023-08-31 09:46:49.000 | 1000.000000000000000 |2023-08-31 09:46:50.000 | 2023-08-31 09:46:51.000 | 451.000000000000000 |LEASTSQUARES
LEASTSQUARES(expr, start_val, step_val)
功能说明:统计表中某列的值是主键(时间戳)的拟合直线方程。start_val 是自变量初始值,step_val 是自变量的步长值。
返回数据类型:字符串表达式(斜率, 截距)。
适用数据类型:expr 必须是数值类型。
适用于:表。
示例:
> select * from t7;ts | v1 |
========================================2023-08-01 01:01:01.000 | 1 |2023-08-01 01:01:02.000 | 2 |2023-08-01 01:01:03.000 | 3 |2023-08-01 01:01:04.000 | 4 |2023-08-01 01:01:05.000 | 5 |2023-08-01 01:01:06.000 | 6 |2023-08-01 01:01:07.000 | 7 |2023-08-01 01:01:08.000 | 8 |2023-08-01 01:01:09.000 | 9 |> select leastsquares(v1,0,1) from t7;leastsquares(v1,0,1) |
==========================================={slop:1.000000, intercept:1.000000} |> select leastsquares(v1,0,2) from t7;leastsquares(v1,0,2) |
==========================================={slop:0.500000, intercept:1.000000} |> select leastsquares(v1,0,5) from t7;leastsquares(v1,0,5) |
==========================================={slop:0.200000, intercept:1.000000} |
SPREAD
SPREAD(expr)
功能说明:统计表中某列的最大值和最小值之差。
返回数据类型:DOUBLE。
适用数据类型:INTEGER, TIMESTAMP。
适用于:表和超级表。
示例:
select * from t7;ts | v1 |
========================================2023-08-01 01:01:01.000 | 1 |2023-08-01 01:01:02.000 | 2 |2023-08-01 01:01:03.000 | 3 |2023-08-01 01:01:04.000 | 4 |2023-08-01 01:01:05.000 | 5 |2023-08-01 01:01:06.000 | 6 |2023-08-01 01:01:07.000 | 7 |2023-08-01 01:01:08.000 | 8 |2023-08-01 01:01:09.000 | 9 |> select spread(ts),spread(v1) from t7;spread(ts) | spread(v1) |
========================================================8000.000000000000000 | 8.000000000000000 |
STDDEV
STDDEV(expr)
功能说明:统计表中某列的均方差。
返回数据类型:DOUBLE。
适用数据类型:数值类型。
适用于:表和超级表。
示例:
> select * from t7;ts | v1 |
========================================2023-08-01 01:01:01.000 | 1 |2023-08-01 01:01:02.000 | 2 |2023-08-01 01:01:03.000 | 3 |2023-08-01 01:01:04.000 | 4 |2023-08-01 01:01:05.000 | 5 |2023-08-01 01:01:06.000 | 6 |2023-08-01 01:01:07.000 | 7 |2023-08-01 01:01:08.000 | 8 |2023-08-01 01:01:09.000 | 9 |> select stddev(v1) from t7;stddev(v1) |
============================2.581988897471612 |
SUM
SUM(expr)
功能说明:统计表/超级表中某列的和。
返回数据类型:DOUBLE, BIGINT。
适用数据类型:数值类型。
适用于:表和超级表。
示例:
> select * from t7;ts | v1 |
========================================2023-08-01 01:01:01.000 | 1 |2023-08-01 01:01:02.000 | 2 |2023-08-01 01:01:03.000 | 3 |2023-08-01 01:01:04.000 | 4 |2023-08-01 01:01:05.000 | 5 |2023-08-01 01:01:06.000 | 6 |2023-08-01 01:01:07.000 | 7 |2023-08-01 01:01:08.000 | 8 |2023-08-01 01:01:09.000 | 9 |> select sum(v1) from t7;sum(v1) |
========================45 |
HYPERLOGLOG
HYPERLOGLOG(expr)
功能说明:
- 采用 hyperloglog 算法,返回某列的基数。该算法在数据量很大的情况下,可以明显降低内存的占用,求出来的基数是个估算值,标准误差(标准误差是多次实验,每次的平均数的标准差,不是与真实结果的误差)为 0.81%。
- 在数据量较少的时候该算法不是很准确,可以使用 select count(data) from (select unique(col) as data from table) 的方法。
返回结果类型:INTEGER。
适用数据类型:任何类型。
适用于:表和超级表。
示例:
> select count(*) from meters;count(*) |
========================109847142 |> select hyperloglog(current) from meters;hyperloglog(current) |
========================1003 |> select count(*) from (select unique(current) from meters);count(*) |
========================1009 |> select hyperloglog(voltage) from meters;hyperloglog(voltage) |
========================1001 |> select count(*) from (select unique(voltage) from meters);count(*) |
========================1000 |
HISTOGRAM
HISTOGRAM(expr,bin_type, bin_description, normalized)
功能说明:统计数据按照用户指定区间的分布。
返回结果类型:如归一化参数 normalized 设置为 1,返回结果为 DOUBLE 类型,否则为 BIGINT 类型。
适用数据类型:数值型字段。
适用于: 表和超级表。
详细说明:
- bin_type 用户指定的分桶类型, 有效输入类型为"user_input“, ”linear_bin", “log_bin”。
- bin_description 描述如何生成分桶区间,针对三种桶类型,分别为以下描述格式(均为 JSON 格式字符串):
-
“user_input”: “[1, 3, 5, 7]”
用户指定 bin 的具体数值。 -
“linear_bin”: “{“start”: 0.0, “width”: 5.0, “count”: 5, “infinity”: true}”
“start” 表示数据起始点,“width” 表示每次 bin 偏移量, “count” 为 bin 的总数,“infinity” 表示是否添加(-inf, inf)作为区间起点和终点,
生成区间为[-inf, 0.0, 5.0, 10.0, 15.0, 20.0, +inf]。 -
“log_bin”: “{“start”:1.0, “factor”: 2.0, “count”: 5, “infinity”: true}”
“start” 表示数据起始点,“factor” 表示按指数递增的因子,“count” 为 bin 的总数,“infinity” 表示是否添加(-inf, inf)作为区间起点和终点,
生成区间为[-inf, 1.0, 2.0, 4.0, 8.0, 16.0, +inf]。
-
- normalized 是否将返回结果归一化到 0~1 之间 。有效输入为 0 和 1。
示例:
PERCENTILE
PERCENTILE(expr, p [, p1] ... )
功能说明:统计表中某列的值百分比分位数。
返回数据类型: 该函数最小参数个数为 2 个,最大参数个数为 11 个。可以最多同时返回 10 个百分比分位数。当参数个数为 2 时, 返回一个分位数, 类型为DOUBLE,当参数个数大于 2 时,返回类型为VARCHAR, 格式为包含多个返回值的JSON数组。
应用字段:数值类型。
适用于:表。
使用说明:
- P值取值范围 0≤P≤100,为 0 的时候等同于 MIN,为 100 的时候等同于 MAX;
- 同时计算针对同一列的多个分位数时,建议使用一个PERCENTILE函数和多个参数的方式,能很大程度上降低查询的响应时间。
比如,使用查询SELECT percentile(col, 90, 95, 99) FROM table, 性能会优于SELECT percentile(col, 90), percentile(col, 95), percentile(col, 99) from table。
示例:
> select * from t7;ts | v1 |
========================================2023-08-01 01:01:01.000 | 1 |2023-08-01 01:01:02.000 | 2 |2023-08-01 01:01:03.000 | 3 |2023-08-01 01:01:04.000 | 4 |2023-08-01 01:01:05.000 | 5 |2023-08-01 01:01:06.000 | 6 |2023-08-01 01:01:07.000 | 7 |2023-08-01 01:01:08.000 | 8 |2023-08-01 01:01:09.000 | 9 |2023-08-01 01:01:10.000 | 10 |> select percentile(v1,10,20,50,80) from t7;percentile(v1,10,20,50,80) |
===========================================[1.900000, 2.800000, 5.500000, 8.200000] |
相关文章:

TDengine函数大全-聚合函数
以下内容来自 TDengine 官方文档 及 GitHub 内容 。 以下所有示例基于 TDengine 3.1.0.3 TDengine函数大全 1.数学函数 2.字符串函数 3.转换函数 4.时间和日期函数 5.聚合函数 6.选择函数 7.时序数据库特有函数 8.系统函数 聚合函数 TDengine函数大全APERCENTILEAVGCOUNTELAPS…...
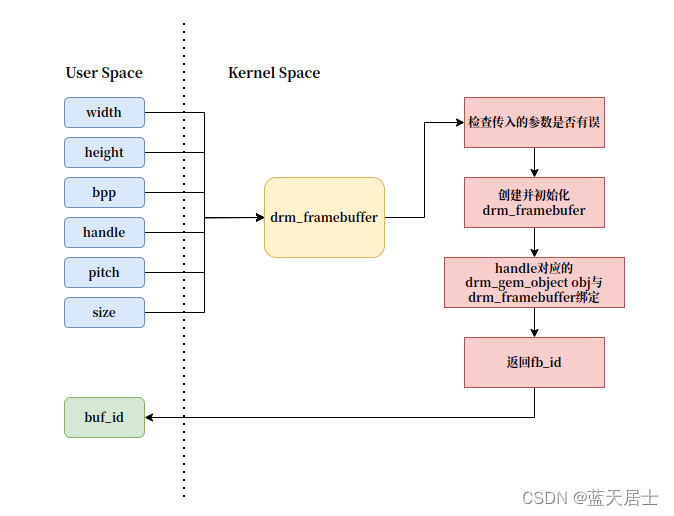
DRM全解析 —— ADD_FB(2)
接前一篇文章:DRM全解析 —— ADD_FB(1) 本文参考以下博文: DRM驱动(四)之ADD_FB 特此致谢! 上一回围绕libdrm与DRM在Linux内核中的接口: DRM_IOCTL_DEF(DRM_IOCTL_MODE_ADDFB, d…...

windows下docker compose方式挂载数据卷volume遇到的问题
例子一,windows 下docker desk top部署TDengine td-compose.yml version: 3 services:tdengine1:image: tdengine/tdengine:latestcontainer_name: tdengine1hostname: tdengine1ports:- 6030:6030- 6041:6041- 6043-6049:6043-6049- 6043-6049:6043-6049/udpresta…...
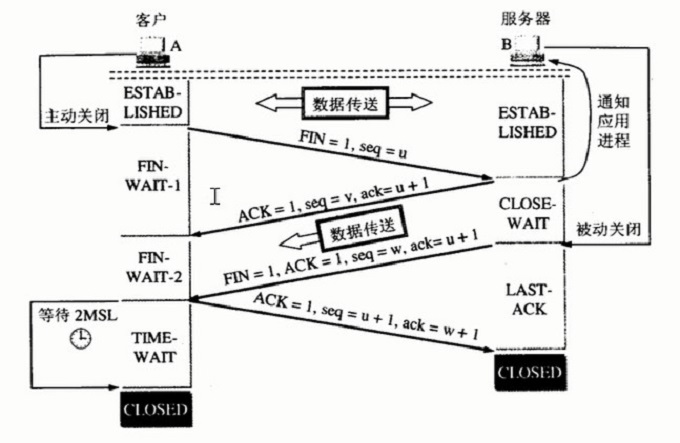
TCP三次握手四次挥手总结
目录 一、两种传输模式: 二、数据方向: 三、端口的作用: 四、端口类型: 五、三次握手: 六、四次断开 常见面试题 TCP(Transfer control protocol)传输控制协议 一、两种传输模式&#x…...

【0901作业】QTday3 对话框、发布软件、事件处理机制,使用文件相关操作完成记事本的保存功能、处理键盘事件完成圆形的移动
目录 一、思维导图 二、作业 2.1 使用文件相关操作完成记事本的保存功能 2.2 处理键盘事件完成圆形的移动 一、思维导图 二、作业 2.1 使用文件相关操作完成记事本的保存功能 void Widget::on_saveBtn_clicked() {QString filename QFileDialog::getSaveFileName(this,&…...
 NULL DEFAULT NULL报错【杭州多测师_王sir】)
mysql数据库运行sql:datetime(0) NULL DEFAULT NULL报错【杭州多测师_王sir】
一、错误信息 CREATE TABLE file (id varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT 文件md5,name varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,create_time datetime(0) NULL DEFAULT NULL,update_time date…...
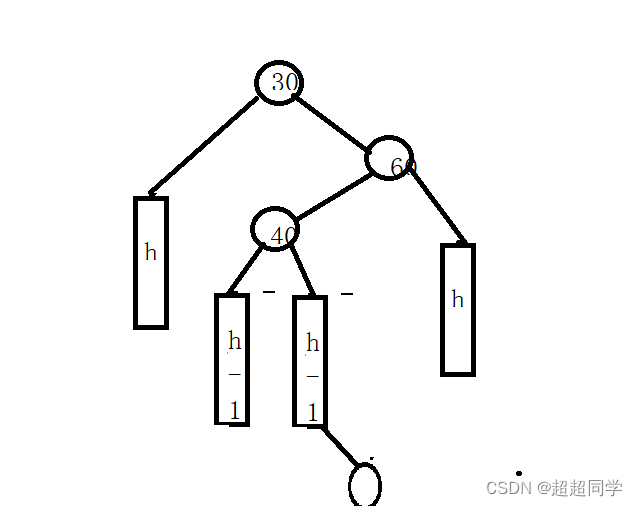
手撕二叉平衡树
今天给大家带来的是平衡树的代码实现,如下: #pragma once #include <iostream> #include <map> #include <set> #include <assert.h> #include <math.h> using namespace std; namespace cc {template<class K, clas…...
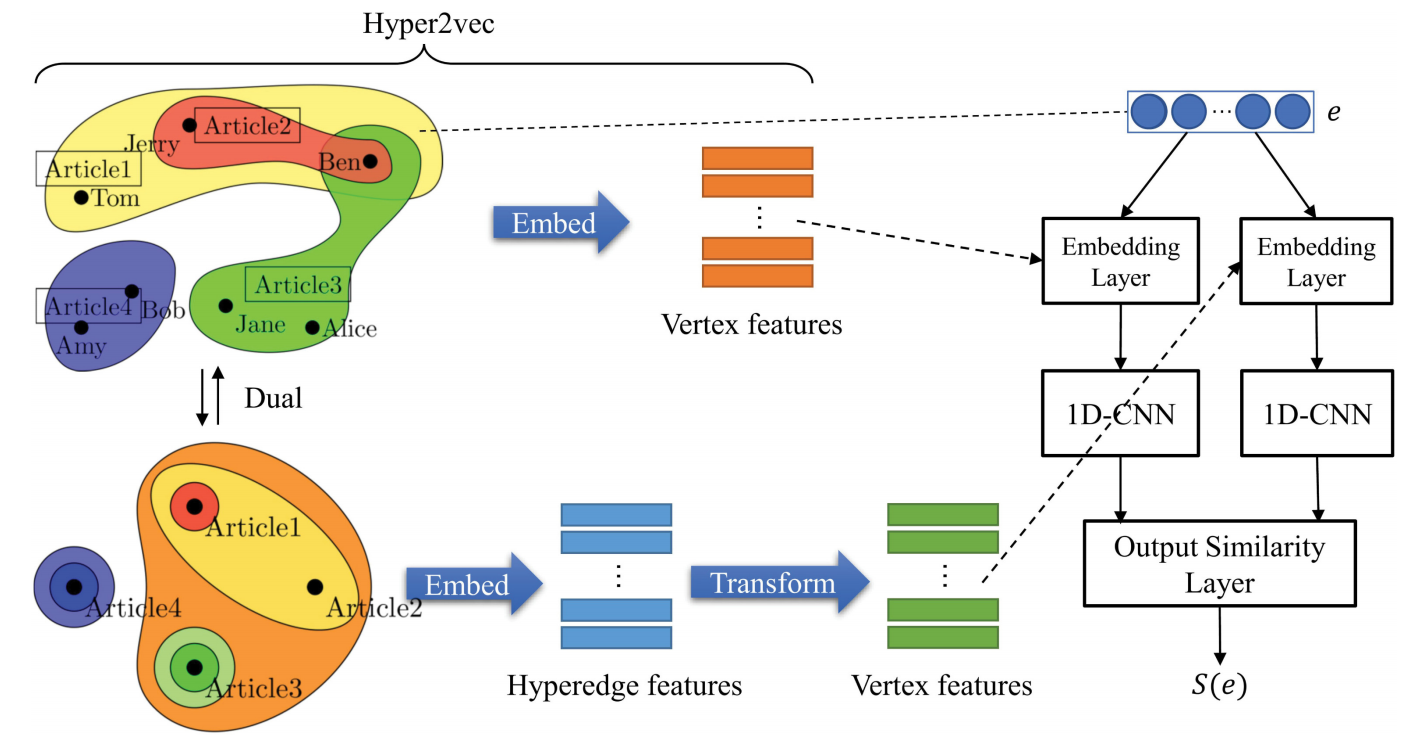
超图嵌入论文阅读1:对偶机制非均匀超网络嵌入
超图嵌入论文阅读1:对偶机制非均匀超网络嵌入 原文:Nonuniform Hyper-Network Embedding with Dual Mechanism ——TOIS(一区 CCF-A) 背景 超边:每条边可以连接不确定数量的顶点 我们关注超网络的两个属性࿱…...
Qt xml解析之QXmlStreamReader
文章目录 背景QXmlStreamReader简单介绍使用QXmlStreamReader添加头文件<QXmlStreamReader>toString()toInt()完整代码 背景 项目中遇到需要解析某个方法返回的xml字符串,奈何C/C中没有原生的方法可供调用,只能使用第三方库,搜了一圈资…...

Selenium基础 — CSS选择器定位大全
1、css属性定位 css选择器策略示例说明#id#telA选择id"telA"的所有元素。.class.telA选择 class"telA”的所有元素。[属性名属性值][nametelA]除了id和class属性,其他属性的定位格式[attribute][target]选择带有target 属性所有元素。**选择所有元素…...
vue3中keep-alive的使用及结合transition使用
正确用法 在组件中使用(这里结合了 transition 内置动画组件 ) <template><div class"layout clearfix"><router-view v-slot"{ Component, route }"><transition name"fade-transform" mode"…...

【提示工程】询问GPT返回Json结构数据
theme: orange 众所周知,我们可以通过构建的Prompt获取期望的内容,但是通常都是以自然语言返回的,假如我们想得到结构化的数据,比如Json,XML那么怎么办,这篇文章给你一个思路。 理所当然的想法 要实现询问大…...

CSS水平垂直居中方案
1 前言 水平居中、垂直居中是前端面试百问不厌的问题。其实现方案也是多种多样,常叫人头昏眼花。 水平方向可以认为是内联方向,垂直方向认为是块级方向。 2 内联元素的水平垂直居中 首先,常见内联元素有:a、span、em、b、stro…...
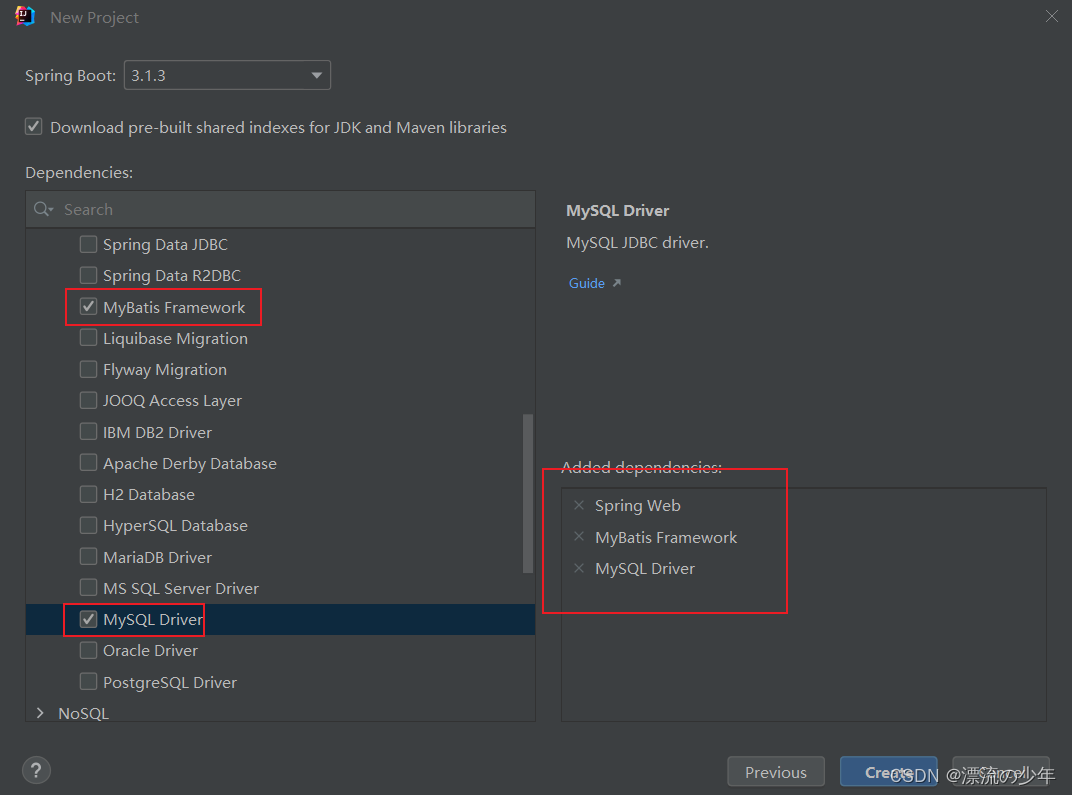
SpringBoot入门篇3 - 整合junit、整合mybatis、基于SpringBoot实现ssm整合
目录 1.整合JUnit Spring整合JUnit SpringBoot整合JUnit 测试类注解:SpringBootTest 作用:设置JUnit加载的SpringBoot启动类 2.整合mybatis ①使用spring initializr初始化项目的时候,添加依赖。 ②设置数据源application.yml spring:d…...
C#,《小白学程序》第七课:列表(List)应用之一“编制高铁车次信息表”
1 文本格式 /// <summary> /// 车站信息类 class /// </summary> public class Station { /// <summary> /// 编号 /// </summary> public int Id { get; set; } 0; /// <summary> /// 车站名 /// </summary>…...

周报/月报 Prompt
前言 用 AI 写好一份周报或月报。 文章目录 前言一、目的二、Prompt 设计原则三、模板 一、目的 简单的日程,扩写成一篇高质量的周报; 二、Prompt 设计原则 角色 目标 背景 要求 三、模板 内容生成模板 你是我的周报助手,根据我的工作…...

c++ 学习 之 构造函数的分类和调用类型 深入学习
正文 构造函数是在C中用于创建和初始化对象的特殊函数。构造函数可以根据不同的特性和参数进行分类,以下是一些常见的构造函数分类和详细讲解它们的调用方式: 默认构造函数: 默认构造函数是一个特殊的构造函数,它没有参数&#x…...

Royal TSX 6 Mac多协议远程软件
Royal TSX是一款功能强大的远程桌面管理软件,适用于Mac操作系统。它允许用户通过一个集成的界面来管理和访问多个远程计算机和服务器。 Royal TSX支持多种远程协议,包括RDP、VNC、SSH、Telnet和FTP等,可以方便地连接到Windows、Linux、Mac和其…...

远程管理通道安全SSH协议主机验证过程
可以使用SSH协议进行远程管理通道安全保护,其中涉及的主要安全功能包括主机验证、数据加密性和数据完整性保护。 这里要注意的是【主机验证】和【身份验证】的区别,主机验证是客户端确认所访问的服务端是目标访问对象,比如从从客户端A(192.16…...

.NET 操作 TDengine .NET ORM
TDengine 是国内比较流的时序库之一,支持群集并且免费,在.NET中资料比较少,这篇文章主要介绍SqlSugar ORM来操作TDengine 优点: 1、SqlSugar支持ADO.NET操作来实现TDengine,并且支持了常用的时间函数、支持联表、分…...

5分钟掌握NoFences:告别杂乱桌面的免费桌面整理终极指南
5分钟掌握NoFences:告别杂乱桌面的免费桌面整理终极指南 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要面对一个布满杂乱图标的Windows桌面&#…...

5分钟永久激活Windows和Office的终极解决方案:KMS智能激活工具完整指南
5分钟永久激活Windows和Office的终极解决方案:KMS智能激活工具完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Offi…...

从账单明细看 Taotoken 按 Token 计费如何实现成本精细化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看 Taotoken 按 Token 计费如何实现成本精细化 1. 引言:从模糊估量到精确计量 在接入和使用大模型 API 时&…...

【收藏干货】2026 版 11 款主流 AI Agent 框架全方位对比!程序员小白入门大模型必备选型指南
本篇整合当下热度顶尖的 11 款 AI Agent 开发框架,囊括 LangChain、AutoGen、CrewAI 等主流工具,新版补充实战落地要点与行业最新应用方向。围绕各框架核心特性、优缺点、适配场景展开深度比对,依托大语言模型搭建智能自主系统,可…...

为Hermes Agent配置自定义大模型供应商Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置自定义大模型供应商Taotoken Hermes Agent 是一个流行的智能体开发框架,它允许开发者灵活地接入不同…...

从需求到上线仅48小时,Lovable无代码交付全流程拆解,含客户验收话术与交付Checklist
更多请点击: https://codechina.net 第一章:从需求到上线仅48小时,Lovable无代码交付全流程拆解,含客户验收话术与交付Checklist 极速交付的核心逻辑 Lovable 平台通过「场景模板 可视化逻辑编排 API 低侵入集成」三重能力压缩…...

Taotoken多模型路由在单一服务故障时的体验保障
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型路由在单一服务故障时的体验保障 1. 引言 在构建依赖大模型能力的应用时,服务的稳定性是开发者必须面对…...

FastGithub终极教程:5分钟解决GitHub访问卡顿问题
FastGithub终极教程:5分钟解决GitHub访问卡顿问题 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub GitHub作为全球最大的代码托管平台,是每个开发…...
TsubakiTranslator:如何用免费工具打破Galgame语言壁垒的终极指南
TsubakiTranslator:如何用免费工具打破Galgame语言壁垒的终极指南 【免费下载链接】TsubakiTranslator 一款Galgame文本翻译工具,支持Textractor/剪切板/OCR翻译 项目地址: https://gitcode.com/gh_mirrors/ts/TsubakiTranslator 还在为看不懂日语…...

利用Taotoken模型广场为不同业务场景快速选型与测试合适大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同业务场景快速选型与测试合适大模型 为客服对话、内容生成、代码辅助等不同业务场景挑选合适的大模型&a…...