数据分析-深度学习 NLP Day2关键词提取案例
训练一个关键词提取算法需要以下几个步骤:
1)加载已有的文档数据集;
2)加载停用词表;
3)对数据集中的文档进行分词;
4)根据停用词表,过滤干扰词;
5)根据数据集训练算法;
根据训练好的关键词提取算法对新文档进行关键词提取要经过以下环节:
1)对新文档进行分词;
2)根据停用词表,过滤干扰词;
3)根据训练好的算法提取关键词;
1 加载模块
import math
import jieba
import jieba.posseg as psg
from gensim import corpora, models
from jieba import analyse
import functools2 定义好停用词表的加载方法
def get_stopword_list():# 停用词表存储路径,每一行为一个词,按行读取进行加载# 进行编码转换确保匹配准确率stop_word_path = './stopword.txt'stopword_list = [sw.replace('/n', '') for sw in open(stop_word_path).readlines()]return stopword_list3 定义一个分词方法
def seg_to_list(sentence, pos=False):''' 分词方法,调用结巴接口。pos为判断是否采用词性标注 '''if not pos:# 不进行词性标注的分词方法seg_list = jieba.cut(sentence)else:# 进行词性标注的分词方法seg_list = psg.cut(sentence)return seg_list4 定义干扰词过滤方法
def word_filter(seg_list, pos=False):''' 1. 根据分词结果对干扰词进行过滤;2. 根据pos判断是否过滤除名词外的其他词性;3. 再判断是否在停用词表中,长度是否大于等于2等;'''stopword_list = get_stopword_list() # 获取停用词表filter_list = [] # 保存过滤后的结果# 下面代码: 根据pos参数选择是否词性过滤## 下面代码: 如果不进行词性过滤,则将词性都标记为n,表示全部保留for seg in seg_list:if not pos:word = segflag = 'n'else:word = seg.word # 单词flag = seg.flag # 词性if not flag.startswith('n'):continue# 过滤停用词表中的词,以及长度为<2的词if not word in stopword_list and len(word)>1:filter_list.append(word)return filter_list5 加载数据集,并对数据集中的数据分词和过滤干扰词
def load_data(pos=False, corpus_path = './corpus.txt'):'''目的:调用上面方法对数据集进行处理,处理后的每条数据仅保留非干扰词参数:1. 数据加载2. pos: 是否词性标注的参数3. corpus_path: 数据集路径'''doc_list = [] # 结果for line in open(corpus_path, 'r'):content = line.strip() # 每行的数据seg_list = seg_to_list(content, pos) # 分词filter_list = word_filter(seg_list, pos) # 过滤停用词doc_list.append(filter_list) # 将处理后的结果保存到doc_listreturn doc_list6 IDF 训练
# TF-IDF的训练主要是根据数据集生成对应的IDF值字典,后续计算每个词的TF-IDF时,直接从字典中读取。def train_idf(doc_list):idf_dic = {} # idf对应的字典tt_count = len(doc_list) # 总文档数# 每个词出现的文档数for doc in doc_list: for word in set(doc):idf_dic[word] = idf_dic.get(word, 0.0) + 1.0# 按公式转换为idf值,分母加1进行平滑处理for k, v in idf_dic.items():idf_dic[k] = math.log(tt_count/(1.0 + v))# 对于没有在字典中的词,默认其尽在一个文档出现,得到默认idf值default_idf = math.log(tt_count/(1.0))return idf_dic, default_idf7 LSI 训练
# LSI的训练时根据现有的数据集生成文档-主题分布矩阵和主题-词分布矩阵,Gensim中有实现好的方法,可以直接调用。def train_lsi(self):lsi = models.LsiModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)return lsi8 LDA训练
# LDA的训练时根据现有的数据集生成文档-主题分布矩阵和主题-词分布矩阵,Gensim中有实现好的方法,可以直接调用。def train_lda(self):lda = models.LdaModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)return lda9 cmp函数
# 为了输出top关键词时,先按照关键词的计算分值排序,在得分相同时,根据关键词进行排序def cmp(e1, e2):''' 排序函数,用于topK关键词的按值排序 '''import numpy as npres = np.sign(e1[1] - e2[1])if res != 0:return reselse:a = e1[0] + e2[0]b = e2[0] + e1[0]if a > b:return 1elif a == b:return 0else:return -110 TF-IDF实现方法
根据具体要处理的文本,计算每个词的TF值,并获取前面训练好的IDF数据,直接获取每个词的IDF值,综合计算每个词的TF-IDF。
class TfIdf(object):# 四个参数分别是:训练好的idf字典,默认idf字典,处理后的待提取文本, 关键词数量def __init__(self, idf_dic, default_idf, word_list, keyword_num):self.idf_dic, self.default_idf = idf_dic, default_idfself.word_list = word_listself.tf_dic = self.get_tf_dic() # 统计tf值self.keyword_num = keyword_numdef get_tf_dic(self):# 统计tf值tf_dic = {}for word in self.word_list:tf_dic[word] = tf_dic.get(word, 0.0) + 1.0tt_count = len(self.word_list)for k, v in tf_dic.items():tf_dic[k] = float(v) / tt_count # 根据tf求值公式return tf_dicdef get_tfidf(self):# 计算tf-idf值tfidf_dic = {}for word in self.word_list:idf = self.idf_dic.get(word, self.default_idf)tf = self.tf_dic.get(word, 0)tfidf = tf * idftfidf_dic[word] = tfidftfidf_dic.items()# 根据tf-idf排序,去排名前keyword_num的词作为关键词for k, v in sorted(tfidf_dic.items(), key=functools.cmp_to_key(cmp), reverse=True)[:self.keyword_num]:print(k + '/', end='')print()11 完整的主题模型实现方法
分别实现了LSI,LDA算法,根据传入参数model进行选择,几个参数如下:
doc_list 是前面数据集加载方法的返回结果
keyword_num同上,为关键词数量
model为本主题模型的具体算法,分别可以传入LSI,LDA,默认为LSI
num_topics为主题模型的主题数量
class TopicModel(object):# 三个传入参数:处理后的数据集,关键词数量,具体模型(LSI,LDA),主题数量def __init__(self, doc_list, keyword_num, model='LSI', num_topics=4):# 使用gensim接口,将文本转为向量化表示# 先构建词空间self.dictionary = corpora.Dictionary(doc_list)# 使用BOW模型向量化corpus = [self.dictionary.doc2bow(doc) for doc in doc_list]# 对每个词,根据tf-idf进行加权,得到加权后的向量表示self.tfidf_model = models.TfidfModel(corpus)self.corpus_tfidf = self.tfidf_model[corpus]self.keyword_num = keyword_numself.num_topics = num_topics# 选择加载的模型if model == "LSI":self.model = self.train_lsi()else:self.model = self.train_lda()# 得到数据集的主题-词分布word_dic = self.word_dictionary(doc_list) self.wordtopic_dic = self.get_wordtopic(word_dic)# LSI的训练时根据现有的数据集生成文档-主题分布矩阵和主题-词分布矩阵,Gensim中有实现好的方法,可以直接调用。def train_lsi(self):lsi = models.LsiModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)return lsi# LDA的训练时根据现有的数据集生成文档-主题分布矩阵和主题-词分布矩阵,Gensim中有实现好的方法,可以直接调用。def train_lda(self):lda = models.LdaModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)return ldadef get_wordtopic(self, word_dic):wordtopic_dic = {}for word in word_dic:single_list = [word]wordcorpus = self.tfidf_model[self.dictionary.doc2bow(single_list)]wordtopic = self.model[wordcorpus]wordtopic_dic[word] = wordtopicreturn wordtopic_dicdef get_simword(self, word_list):# 计算词的分布和文档的分布的相似度,去相似度最高的keyword_num个词作为关键词sentcorpus = self.tfidf_model[self.dictionary.doc2bow(word_list)]senttopic = self.model[sentcorpus]# 余弦相似度计算def calsim(l1, l2):a,b,c = 0.0, 0.0, 0.0for t1, t2 in zip(l1, l2):x1 = t1[1]x2 = t2[1]a += x1 * x1b += x1 * x1c += x2 * x2sim = a / math.sqrt(b * c) if not (b * c) == 0.0 else 0.0return sim# 计算输入文本和每个词的主题分布相似度sim_dic = {}for k, v in self.wordtopic_dic.items():if k not in word_list:continuesim = calsim(v, senttopic)sim_dic[k] = simfor k, v in sorted(sim_dic.items(), key=functools.cmp_to_key(cmp),reverse=True)[:self.keyword_num]:print(k + '/' , end='')print()def word_dictionary(self, doc_list):# 词空间构建方法和向量化方法,在没有gensim接口时的一般处理方法dictionary = []for doc in doc_list:dictionary.extend(doc)dictionary = list(set(dictionary))return dictionarydef doc2bowvec(self, word_list):vec_list = [1 if word in word_list else 0 for word in self.dictionary]return vec_list12 对上面的各个方法进行封装,统一算法调用接口
def tfidf_extract(word_list, pos=False, keyword_num=10):doc_list = load_data(pos)idf_dic, default_idf = train_idf(doc_list)tfidf_model = TfIdf(idf_dic, default_idf, word_list, keyword_num)tfidf_model.get_tfidf()def textrank_extract(text, pos=False, keyword_num=10):textrank = analyse.textrankkeywords = textrank(text, keyword_num)# 输出抽取出的关键词for keyword in keywords:print(keyword + "/", end='')print()def topic_extract(word_list, model, pos=False, keyword_num=10):doc_list = load_data(pos)topic_model = TopicModel(doc_list, keyword_num, model=model)topic_model.get_simword(word_list)13 主函数调用
if __name__ == "__main__":text = '6月19日,《2012年度“中国爱心城市”公益活动新闻发布会》在京举行。' + \'中华社会救助基金会理事长许嘉璐到会讲话。基金会高级顾问朱发忠,全国老龄' + \'办副主任朱勇,民政部社会救助司助理巡视员周萍,中华社会救助基金会副理事长耿志远,' + \'重庆市民政局巡视员谭明政。晋江市人大常委会主任陈健倩,以及10余个省、市、自治区民政局' + \'领导及四十多家媒体参加了发布会。中华社会救助基金会秘书长时正新介绍本年度“中国爱心城' + \'市”公益活动将以“爱心城市宣传、孤老关爱救助项目及第二届中国爱心城市大会”为主要内容,重庆市' + \'、呼和浩特市、长沙市、太原市、蚌埠市、南昌市、汕头市、沧州市、晋江市及遵化市将会积极参加' + \'这一公益活动。中国雅虎副总编张银生和凤凰网城市频道总监赵耀分别以各自媒体优势介绍了活动' + \'的宣传方案。会上,中华社会救助基金会与“第二届中国爱心城市大会”承办方晋江市签约,许嘉璐理' + \'事长接受晋江市参与“百万孤老关爱行动”向国家重点扶贫地区捐赠的价值400万元的款物。晋江市人大' + \'常委会主任陈健倩介绍了大会的筹备情况。'pos = Falseseg_list = seg_to_list(text, pos)filter_list = word_filter(seg_list, pos)print("TF-IDF模型结果:")tfidf_extract(filter_list)print("TextRank模型结果:")textrank_extract(text)print("LSI模型结果:")topic_extract(filter_list, 'LSI', pos)print("LDA模型结果:")topic_extract(filter_list, 'LDA', pos)14 输出结果:

相关文章:
数据分析-深度学习 NLP Day2关键词提取案例
训练一个关键词提取算法需要以下几个步骤:1)加载已有的文档数据集;2)加载停用词表;3)对数据集中的文档进行分词;4)根据停用词表,过滤干扰词;5)根据…...

LeetCode题解:938. 二叉搜索树的范围和,BFS,JavaScript,详细注释
原题链接: https://leetcode.cn/problems/range-sum-of-bst/ 解题思路: 对于二叉搜索树的任意节点,左子树的所有节点值都小于它的值,右子树的所有节点值都小于它的值。使用队列进行BFS搜索,如果当前节点的值小于low&…...

istio初步了解
istio 控制平面: Pilot:管理和配置部署在特定istio服务网格中的所有sidecar代理实例,管理sidecar代理之间的路由流量规则,并配置故障恢复功能,如超时、重试、熔断。 Citadel:istio中负责身份认证和证书管…...

【模板】用HTML编写邮件正文 | 各大邮箱几乎都会过滤css样式、js脚本等效果,如何用基础HTML编写?
用HTML编写邮件正文 文档 编码格式utf-8(使用记事本或其他工具打开,在文件->另存为,编缉选择UTF-8格式) 文档大小在15kb以内 样式 页面宽度:600px~800px 尽量用特殊元素以及元素属性代替样式 样式全部写为内联样式…...
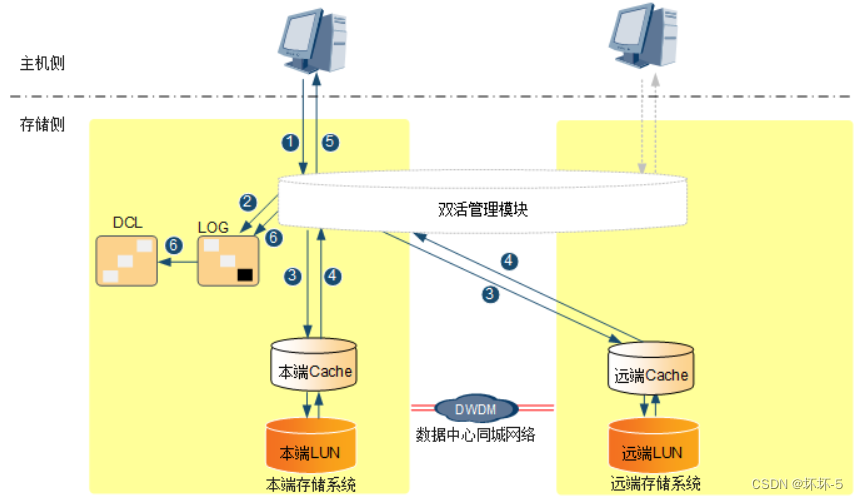
华为云计算之双活容灾
双活(HyperMetro)本地双活:距离≤10km同城双活:距离>10km没有主备之分,只有本端数据中心和远端数据中心。当一个数据中心的设备故障或数据中心故障,业务会自动切换到另一个数据中心继续运行&…...
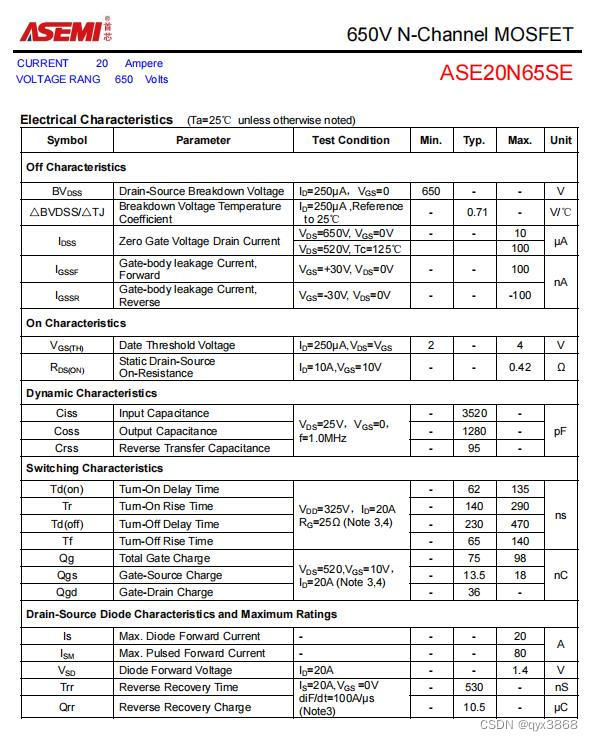
ASEMI高压MOS管ASE20N65SE体积,ASE20N65SE大小
编辑-Z ASEMI高压MOS管ASE20N65SE参数: 型号:ASE20N65SE 漏极-源极电压(VDS):650V 栅源电压(VGS):30V 漏极电流(ID):20A 功耗(P…...
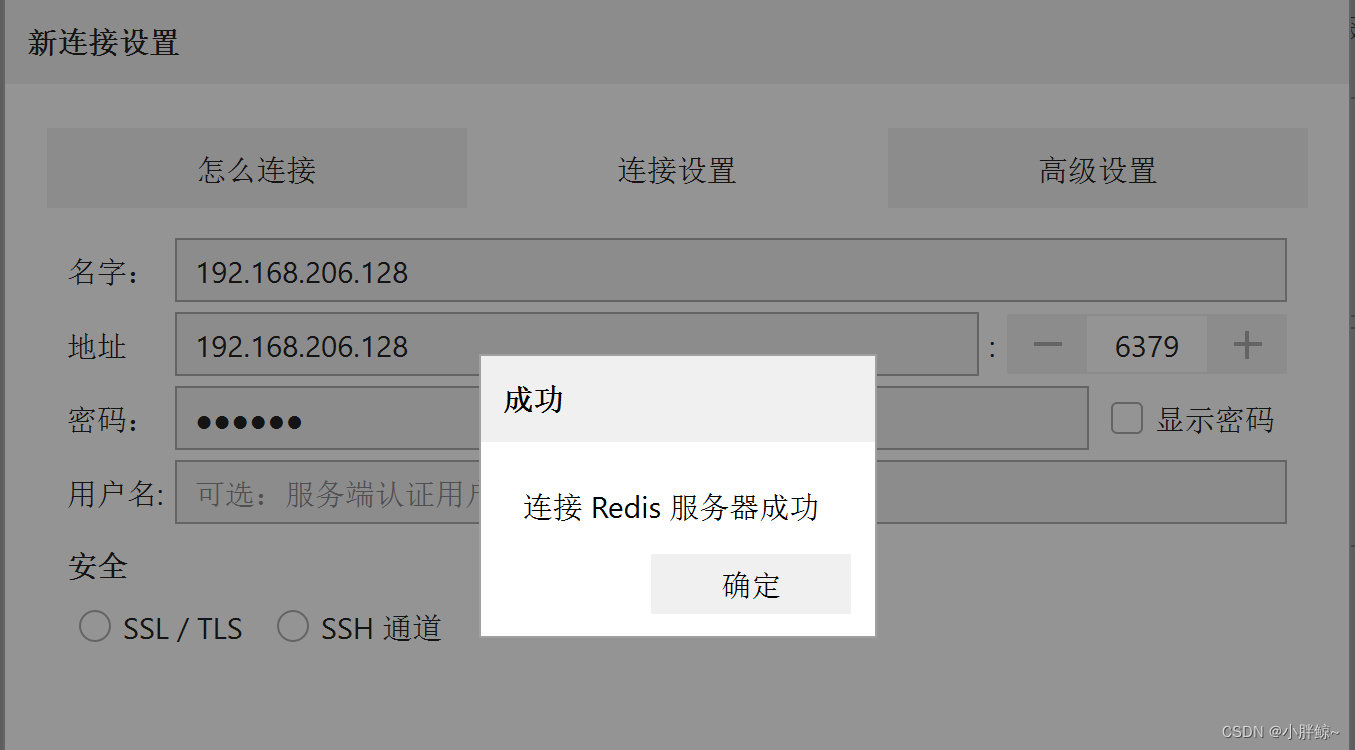
resp连接redis服务器
修改redis的配置文件使得windows的图形界面客户端可以连接redis服务器 resp安装好以后,可以在linux端打开redis.conf中做以下操作,使得windows的图形界面客户端可以连接redis服务器 方法一: 1,在redis.conf文件中添加bind 在文件…...
七天实现一个分布式缓存
目录教程来源目的思路缓存淘汰(失效)算法:FIFO,LFU 和 LRUFIFO(First In First Out)LFU(Least Frequently Used)LRU(Least Recently Used)实现Lru查找功能删除新增/修改测试单机并发缓存主体结构 Group回调 GetterGroup 的定义Group 的 Get 方法HTTP 服务…...

电子招标采购系统源码功能清单
一、立项管理 1、招标立项申请 功能点:招标类项目立项申请入口,用户可以保存为草稿,提交。 2、非招标立项申请 功能点:非招标立项申请入口、用户可以保存为草稿、提交。 3、采购立项列表 功能点:对草稿进行编辑&#x…...

mysql数据库基础知识
一.mysql基本命令 1.基础常用命令 mysql -uroot -p密码;(也可以不带密码,之后输入) 本地登录 mysql -h 登录ip -p 端口(通常3306) -uroot -p密码; 远程登录 desc 表名;查看表的各个字段的属性,以及自增键 mysqldump -u用户 -p 数据库名 >…...
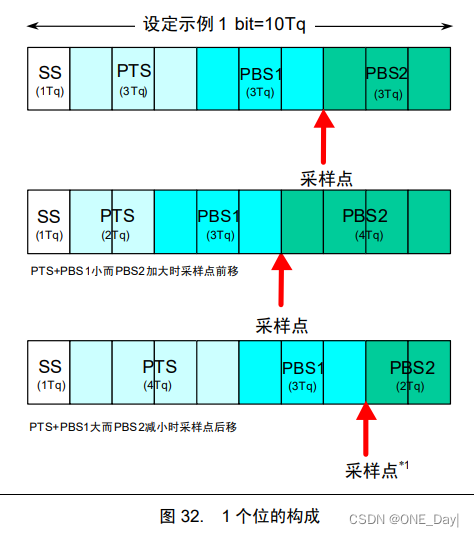
CAN总线通信
CAN总线通信 CAN 是控制器局域网络(Controller Area Network) 的缩写,是 ISO 国际标准化的串行通信协议。 CAN是半双工通信 CAN总线特点 (1) 多主控制 在总线空闲时,所有的单元都可开始发送消息(多主控制…...
MATLAB/Simulink 通信原理及仿真学习(二)
文章目录MATLAB/Simulink 通信原理及仿真学习(二)simulink仿真常用的Simulink库1. 信号源模块库2. 数序运算模块3. 信号输出模块库4.仿真搭建5.搭建自己的库6.S-函数编写MATLAB/Simulink 通信原理及仿真学习(二) simulink仿真 交…...
的操作命令)
CentOS7 防火墙(firewall)的操作命令
CentOS7 防火墙(firewall)的操作命令 安装:yum install firewalld 1、firewalld的基本使用 启动: systemctl start firewalld 查看状态: systemctl status firewalld 禁用,禁止开机启动: s…...

文献工具汇总:论文查找、文献管理、文献翻译
科研人员论文哪里找?文献如何管理?本文给推荐一些提高论文阅读写作效率的一些资料,包括查找论文、文献管理、文献翻译等方面。 一、查找文献 PMC(Pubmed Cenral) Pubmed官方系统中,将免费的全文集中在此,…...
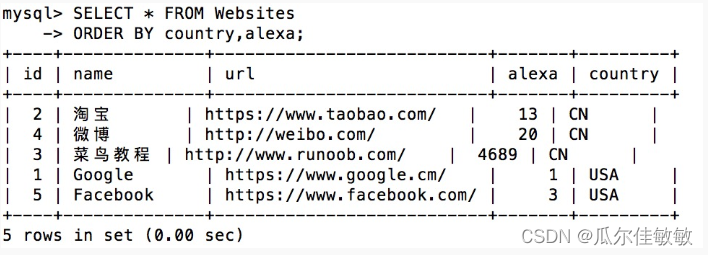
SQL零基础入门学习(三)
SQL零基础入门学习(二) SQL WHERE 子句 WHERE 子句用于提取那些满足指定条件的记录。 SQL WHERE 语法 SELECT column1, column2, ... FROM table_name WHERE condition;参数说明: column1, column2, …:要选择的字段名称&…...

苹果手机如何快速的直接从相册里面的图片提取文字?
//在线工具地址https://ocr.bytedance.zj.cn/image/ImageText在当今信息爆炸的时代,图文并茂已经成为了一个广告宣传的常用方式。然而,图片中的文字信息往往难以获取,尤其对于那些需要快速获取信息的人们来说,阅读图片中的文字会是…...

【go】函数调用
程序中编写的函数在编译阶段会被编译成一段段的指令存放在可执行文件中,在程序运行阶段这些内存会加载到虚拟地址空间的代码段。 当函数A调用了函数B的时候,对应的会生成一条call指令,程序在运行到call指令时就会跳转到对应的B函数的代码段的…...

Linux系统之Uboot、Kernel、Busybox思考之四
目录 三 内核的运行 9 设备树: 1) 设备树产生缘由 2) 设备树方案的流程 3) 有了上述概念,为了支撑整个设备树的工程实现,内核实现以下内容 4) 内核解析设备树 5) 入口分析 6) 解析处理。 10 udev devfs sysfs 11 系统中的USB设备 12 网…...

为什么要经常阅读和分析计算机SCI期刊论文? - 易智编译EaseEditing
训练阅读与分析期刊论文的能力,可以增加中长期的学术竞争力。 只要能够充分掌握阅读与分析期刊论文的技巧,就可以水到渠成地轻松进行「创新」的工作。 所以,只要深入掌握到阅读与分析期刊论文的技巧,就可以掌握到大学生不曾研习过…...

Shiro框架详解
1.Shiro简介 1.1.基本功能点 Shiro 可以非常容易的开发出足够好的应用,其不仅可以用在 JavaSE 环境,也可以用在 JavaEE 环境。Shiro 可以帮助我们完成:认证、授权、加密、会话管理、与 Web 集成、缓存等。 Authentication:身份…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

关于软件版本升级的故事
起因在群里有网友说软件的版本升级比较简单,俺就回了四个字母“PACS”,并补上了一个表情 然后看见开始细说了:一、PACS 属于哪一类?PACS 软件 第二类医疗器械(独立软件)国家药监局分类:Ⅱ 类 2…...
)
别再手动改代码了!用Vivado的VIO IP核实时调试你的FPGA设计(附UART实例)
实时交互式FPGA调试革命:Vivado VIO核的UART实战指南 调试FPGA设计时,你是否经历过这样的痛苦循环:修改一行代码→全编译→下载比特流→测试→发现问题→再修改...这种"石器时代"的工作流正在吞噬工程师的创造力。Xilinx Vivado中的…...

VisualCppRedist AIO:Windows系统依赖问题终极解决方案,一键修复所有VC++运行库
VisualCppRedist AIO:Windows系统依赖问题终极解决方案,一键修复所有VC运行库 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经…...

3分钟掌握中兴光猫配置解密:ZET工具终极快速指南
3分钟掌握中兴光猫配置解密:ZET工具终极快速指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 想要自由掌控家中网络却总被光猫配置限制?中兴光猫…...

Mapbox Studio Classic核心功能解析:CartoCSS与矢量瓦片技术详解
Mapbox Studio Classic核心功能解析:CartoCSS与矢量瓦片技术详解 【免费下载链接】mapbox-studio-classic 项目地址: https://gitcode.com/gh_mirrors/ma/mapbox-studio-classic Mapbox Studio Classic是一款强大的桌面地图设计工具,专为创建专业…...

STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南
STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南 在嵌入式系统开发中,ADC(模数转换器)的稳定性直接关系到整个系统的测量精度。特别是对于STM32F407这类高性能MCU,当应用于电源监控、医疗设备或工业传感…...

【开源】前端拖拽表单设计器 自定义表单
【开源】开源 VUE拖拽表单设计器 自定义表单 开源 tduck-platform: Tduck-填鸭收集器是一款开源的表单在线收集系统,后台基于SpringBootMybatisPlusMySqlRedis,前端基于Vue ElementUI开发,功能强大,界面美观。keywords࿱…...