Linux系统之Uboot、Kernel、Busybox思考之四
目录
三 内核的运行
9 设备树:
1) 设备树产生缘由
2) 设备树方案的流程
3) 有了上述概念,为了支撑整个设备树的工程实现,内核实现以下内容
4) 内核解析设备树
5) 入口分析
6) 解析处理。
10 udev devfs sysfs
11 系统中的USB设备
12 网络子系统
13 文件子系统
四 运行的内核
三 内核的运行
9 设备树:
1) 设备树产生缘由
为解决板级设备杂乱的问题,提供一种简洁方便的管理方案
通过定义一些规则,按规则描述设备信息,然后由内核解析,动态生成设备相关代码,完成设备的挂载
相对硬件编码而言,规则可以看作是在代码上面又封装了一层,更加灵活
而且,规则可以定义的更适合人类阅读,这样对提高效率和复用,也很有帮助
2) 设备树方案的流程
定义设备数规则,根节点,子节点,节点属性,节点属性值,cell单元,引用等等。
需要注意,根
需要注意,可以支持c语言预处理
需要注意,节点可以被覆盖,重写
需要注意,一些节点有限制,比如CPU 节点中的size必须为0, memory的类型必须为memory
需要注意,节点名称带有 根 标记
属性可以有值,也可以无值
属性值可以为字符串,字符串数组,以及字节数组等形式
cell单元,需要注意格式,其地址和size由父节点决定
中断分ppi spi,分上升沿下降沿等,有专有定义
引用可以使用label形式,也可以自定义全局唯一值来实现
兼容属性定义为从一般到特殊,如果一致,需要通过model属性区分
以上为设备树本身的一些构成规则,编写和查看设备树文件时会用到上述内容。
从名称可以看出来,设备树的组织结构形式为树。树是一种层次结构,对应到设备上,也代表着根、枝、叶的构成。
根可以看作是顶层总线,下面挂接了CPU、内存和其他总线,总线下面还可以有总线和设备,这样一级一级展开,构成了系统的硬件体系结构
对应到设备树中,也就存在着父节点和子节点
3) 有了上述概念,为了支撑整个设备树的工程实现,内核实现以下内容
首先是设备树规则,不再多说。
其次是设备树文件,dts格式,source文件,另外还有dtsi格式,属于头文件,设备树支持头文件引用,这有利于代码复用和管理。除此,设备树还支持C语言的宏定义等
编写设备树文件后,该文件内容是human readable的,但不是计算机容易readable的,所以还需要进行转换
内核提供dtc工具,将dts文件内容编译成dtb格式。blob代表着二进制的对象。内核读取dtb格式内容,动态生成内存中的设备对象。
dtc工具在内核源代码的/scripts/dtc/下,编译内核源代码时,会编译出主机端的dtc工具。需要打开内核的CONFIG_DTC选项,配置其为Y
如果配置了CONFIG_ARM_APPENDED_DTB=y,编译内核源代码时,会自动调用dtc工具编译生成dtb文件,并将其附到内核尾部。
当然,我们也可以单独执行该命令编译内核dtb文件,比如
./scripts/dtc/dtc -I dts -O dtb -o /home/nfsshare/hisi.dtb arch/arm/boot/dts/hi3519av100.dts
内核在编译过程中,如何确定编译那些dts文件呢,这些在makefile中会指定,比如对于hisi来讲,arch/arm/boot目录下makefile中有
include $(srctree)/arch/arm/boot/dts/Makefile,在这个makefile中,又会引入dtb-$(CONFIG_ARCH_HISI) += \hi3519-demb.dtb定义了dtb目标,目录下有hi3519-demb.dts源文件,这样dtc工具就会将该文件编译为目标的dtb文件
dtc工具不但可以编译dtb文件,还可以将dtb文件反编译为dts文件。我们看到,为了管理和复用代码,dts文件支持头文件引用,节点覆盖等。
当文件变得庞大时,对于确认和查找节点的最终描述,反而有点不方便,此时可以使用反编译过程,将dtb文件反编译为dts文件。
反编译后的文件是最终整理过的结果,是一颗比较规整和标准的树结构,节点描述是唯一的,这对于确认节点的最终描述,反倒是比较方便的。反编译命令如下
./scripts/dtc/dtc -I dtb -O dts -o /home/nfsshare/hisi.dts arch/arm/boot/dts/hi3519av100-smp-flash.dtb
可以看到,输入-I和输出-O格式发生了调换,输出文件-o也变为了dts格式,默认输入源倒是dtb
4) 内核解析设备树
有了dtb文件,内核就可以解析该文件,动态生成设备对象。
dtb文件的解析在内核启动过程的开始阶段,最终也是解析为一棵树。(待确认)。后续,在内核启动的后期阶段,init线程中,加载设备驱动时,会遍历之前解析的树,
找到每一个节点,生成节点相关的设备对象及属性信息。(待确认)
到此,整个链条就完整了。
5) 入口分析
除了内核,uboot也是可以支持设备树的。相应的,就有以下几种可能:
A uboot支持设备树,uboot解析设备树,将解析后的结果地址告诉内核(这种应该是不行的,从软件开发感觉来讲,也没必要,反而增加了uboot和内核之间的耦合度)
B uboot支持设备树,uboot不解析设备数,只是将dtb文件的地址告诉内核,由内核解析从特定内存或者存储地址获取dtb信息,并进行解析。
实际中是采用这种方式,bootm启动内核时,除了传递内核地址外,还需要在命令行参数中增加dtb的地址。这种方式,二者之间通过dtb达成一致。只要对dtb的解读一致即可。
其实,也完全可以做到不存在任何耦合,比如dtb文件只在内核这一端生成
C uboot不支持设备树,这种情况下,uboot仍然按照bootm启动内核,设备树的相关操作完全由内核完成。
此时,在内核编译中,平台体系结构相关部分,不再是obj-y的目标,而是dtb-y。查看内核源代码可以发现,此时arch/arm/目录下的mach-xxx目录下,体系结构相关代码已经很少
转而,在arch/arm/boot/dts目录下有大量体系结构相关的dts存在。
makefile中也是指定dtc工具编译dtb目标,同时定义了zImage-dtb目标,由原始vmlinux生成压缩的zImage后,通过@cat $(obj)/zImage $(DTB_OBJS_FULL) > $@将dtb目标缀在zImage后面生成zImage-dtb
最终生成uboot引导的uImage镜像也是基于zImage-dtb结果。
$(obj)/uImage: $(obj)/zImage-dtb FORCE
用二进制编辑工具打开此时的uImage,可以在末尾看到可读的dts痕迹,比如P/soc/amba/uart@04540000等,说明内核镜像中包括了dtb内容。
为了让内核启动时,自动查找dtb并进行解析,需要打开配置选项CONFIG_ARM_APPENDED_DTB。
当上述选项配置为Y时,在compressed目录下的head.S汇编代码中,可以看到有对设备树的处理
补充一点,zImage作为压缩镜像,其生成$(obj)/zImage: $(obj)/compressed/vmlinux FORCE依赖于compressed下的目标
head.S汇编代码会嵌入到内核启动代码中,判断启动合法条件,引导跳转到C代码,在head.S中会发现如下一段代码,
#ifdef CONFIG_ARM_APPENDED_DTB/** r0 = delta* r2 = BSS start* r3 = BSS end* r4 = final kernel address (possibly with LSB set)* r5 = appended dtb size (still unknown)* r6 = _edata* r7 = architecture ID* r8 = atags/device tree pointer* r9 = size of decompressed image* r10 = end of this image, including bss/stack/malloc space if non XIP* r11 = GOT start* r12 = GOT end* sp = stack pointer** if there are device trees (dtb) appended to zImage, advance r10 so that the* dtb data will get relocated along with the kernel if necessary.*/ldr lr, [r6, #0]#ifndef __ARMEB__ldr r1, =0xedfe0dd0 @ sig is 0xd00dfeed big endian#elseldr r1, =0xd00dfeed#endifcmp lr, r1bne dtb_check_done @ not found
从上面代码可以看出,r6是内核正常的结尾处,D0 0D FE ED是dtb的魔数,当CONFIG_ARM_APPENDED_DTB选项被选中时
会将内核正常结尾处也就是附加dtb开头的内容加载到lr中,同时根据大小端,将dtb的魔数设置到寄存器r1中
接着判断二者是否相等,如果不等,说明未找到dtb,否则说明内核自带了dtb
如果发现存在dtb append,则在后续解压内核时避免对dtb部分造成影响,最终调整dtb的相关指针,以便内核启动时,能够正确加载和解析dtb
6) 解析处理。
10 udev devfs sysfs
设备的发现与管理
内核启动时,初始化相关资源,包括进程、内存、中断、锁、设备模型、文件系统框架、用户空间交互通道等,并完成设备树的解析
内核创建init进程,在恰当时机执行initcall区域的函数指针,进行driver setup
各个驱动模块的初始化在执行过程中,会进行总线注册和设备匹配,匹配分多种条件,包括id table,设备名称,设备树兼容性属性等等。一般按照严格到宽松的条件进行匹配。
匹配成功后,驱动的probe接口将被调用,进行设备的初始化及设备所需中断和内存等资源的申请
之后,设备一般在中断的驱动下开始正常工作,包括上层触发数据发送,中断触发数据接收,上层触发各种控制操作等。
在Linux中,一切设备均抽象为文件。内核驱动中,可以申请设备号,成功后,在proc/devices中可以看到设备号使用情况
设备号申请分自动和手动两种,自动方式由内核提供空闲设备号,手动由驱动主动注册设备号,手动方式可能存在设备号冲突情况
设备驱动申请设备号并注册后,只是在上述目录下可以看到新增加的设备号,而/dev目录下并没有实际产生设备节点
要在/dev目录下产生设备节点,有多种方式,一种是驱动中调用内核接口device_create,注册时自动生成设备节点;一种是通过sysfs系统,在用户空间通过udev工具生成;还可以调用mknod程序,手动生成。
在内核驱动中自动创建设备节点存在一些缺点,比如节点命名问题,特定功能节点的创建问题。
所以,一些节点可能在需要时由用户空间程序创建,会提供方便。但是,完全交给用户空间,也存在问题。比如,设备发现问题。在错过设备驱动加载时机后,如何发现设备。
这里也牵涉一些关于内核职责的问题,比如机制与策略的分离。
2.6之后的内核提供了sysfs系统,用于管理总线、驱动、设备及它们之间的关系。udev工具就是基于sysfs进行设备管理的用户空间程序。
借助udev工具,可以很好的解决设备命名问题,也可以在设备发现和移除时,很方便的执行定制化动作。
整个流程为:
首先,内核在初始化过程中,会加载内置驱动,完成设备的初始化和部分设备的创建。
init程序加载用户空间第一个程序并执行时,会执行udevd后台例程。
udevd会使用/etc/udev/udev.conf文件配置自己
udevd会监听内核设备事件,包括add remove change等
检测到事件后,会按优先级匹配/etc/udev/rules.d/下面的规则文件(规则文件是udevd启动时预置到其内存数据结构中的?)
udevd是否会监听/etc/udev/rules.d目录下的规则文件的变化,实时更新规则。应该要这样,否则,需要重启udevd获取系统,这不符合用户体验要求。
udevd会遍历所有预置的规则,匹配后,就执行相应的动作,包括赋值、执行动作、获取特定动作的结果进行赋值或执行动作
动作的执行要放到单独的环境中,如果是脚本的话,要明确指定shell类型,udevd会fork子进程处理动作。ps可能会看到多个udevd daemon进程。
规则文件编写原则可参考已有规则文件,其中有关属性和预定义变量,可以通过执行udevadm info -q all -n /dev/xxx -a的输出查看
设备的相关操作信息会被记录到一个数据库中,udevadm就是读取数据库信息来展示设备相关信息的。
-a参数可以输出设备的整个加载链条,比如从最顶层的总线到下一级总线到再下一级总线,直到当前指定设备为止。
设备的组成结构是一个树形结构,比如执行udevadm info -q all -n /dev/sdd -a输出sdd设备信息如下
looking at device '/devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd':KERNEL=="sdd"SUBSYSTEM=="block"DRIVER==""ATTR{ro}=="0"ATTR{size}=="7814037168"ATTR{stat}==" 4597 46 37126 69300 10595 5825 2513672 73590 0 53330 142880"ATTR{range}=="16"ATTR{discard_alignment}=="0"ATTR{events}==""ATTR{ext_range}=="256"ATTR{events_poll_msecs}=="-1"ATTR{alignment_offset}=="0"ATTR{inflight}==" 0 0"ATTR{removable}=="0"ATTR{capability}=="50"ATTR{events_async}==""looking at parent device '/devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0':KERNELS=="3:0:0:0"SUBSYSTEMS=="scsi"DRIVERS=="sd"ATTRS{rev}=="CV11"ATTRS{type}=="0"ATTRS{scsi_level}=="6"ATTRS{model}=="ST4000VX005-2LY1"ATTRS{state}=="running"ATTRS{queue_type}=="simple"ATTRS{modalias}=="scsi:t-0x00"ATTRS{iodone_cnt}=="0x4826"ATTRS{iorequest_cnt}=="0x4844"ATTRS{queue_ramp_up_period}=="120000"ATTRS{timeout}=="30"ATTRS{evt_media_change}=="0"ATTRS{ioerr_cnt}=="0x0"ATTRS{queue_depth}=="31"ATTRS{vendor}=="ATA "ATTRS{device_blocked}=="0"ATTRS{iocounterbits}=="32"looking at parent device '/devices/platform/ahci.0/ata4/host3/target3:0:0':KERNELS=="target3:0:0"SUBSYSTEMS=="scsi"DRIVERS==""looking at parent device '/devices/platform/ahci.0/ata4/host3':KERNELS=="host3"SUBSYSTEMS=="scsi"DRIVERS==""looking at parent device '/devices/platform/ahci.0/ata4':KERNELS=="ata4"SUBSYSTEMS==""DRIVERS==""looking at parent device '/devices/platform/ahci.0':KERNELS=="ahci.0"SUBSYSTEMS=="platform"DRIVERS=="ahci"ATTRS{modalias}=="platform:ahci"looking at parent device '/devices/platform':KERNELS=="platform"SUBSYSTEMS==""DRIVERS==""
可以看到,树根是platform,中间控制器scsi,最后是block
另外,需要注意到,父节点中名称和属性都带S,本节点中不带S,这一点在书写规则文件时也适用。即规则文件中,如果是匹配父节点的属性,则需要使用ATTRS。
规则文件中至少需要一个匹配和一个赋值,匹配使用==,赋值使用=,赋值可以是重命名节点相关属性,或者执行定制动作。
使用udev工具主要就是通过规则匹配来执行相关动作,所以规则文件匹配很重要。但是事件的产生,比如设备插拔等,是需要一定条件的,这对规则文件的验证带来了一些麻烦
能否模拟整个过程,对规则进行快速验证调试呢?如果可以做到这点,那么对提高效率,就非常有帮助了。
udevadm提供了多个选项,可以帮助用户快速调试验证规则。
首先,让目标设备正常加载进系统中
然后,使用前面的udevadm info选项,查看系统中的事件信息,包括一些本地属性和父节点信息
利用上述信息,编写初步的规则文件
使用命令udevadm test /sys/devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd模拟规则的匹配和执行过程
上述命令后面部分是具体设备信息,该命令选项只是模拟过程,不会真正执行
命令也会输出规则文件的解析优先级,使用该命令可进行初步调试
下面进行正式的验证
首先,我们可以启动udevadm monitor,监控实时的事件信息,为调试提供分析依据,如下所示:
udevadm monitor --propertymonitor will print the received events for:UDEV - the event which udev sends out after rule processingKERNEL - the kernel ueventKERNEL[1624468946.462053] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd (block)UDEV_LOG=3ACTION=addDEVPATH=/devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sddSUBSYSTEM=blockDEVNAME=sddDEVTYPE=diskNPARTS=3SEQNUM=1416MAJOR=8MINOR=48UDEV [1624468946.474712] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd (block)UDEV_LOG=3ACTION=addDEVPATH=/devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sddSUBSYSTEM=blockDEVNAME=/dev/sddDEVTYPE=diskNPARTS=3SEQNUM=1416MAJOR=8MINOR=48
monitor会输出内核的uevent事件和udev处理后输出的event
其次,使用udevadm trigger触发事件,比如对于上述硬盘加载,可以用如下触发命令
udevadm trigger --action=add --subsystem-match=block --sysname-match=sdd
udevadm trigger --action=add --subsystem-match=block --sysname-match=sd*
trigger支持shell的通配符匹配,只触发满足规则的节点的事件,这一点需要注意,比如对于上面的第一条规则,monitor输出
KERNEL[1624533496.063615] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd (block)KERNEL[1624533496.063753] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd/sdd1 (block)KERNEL[1624533496.063840] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd/sdd2 (block)KERNEL[1624533496.063919] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd/sdd3 (block)
对于上述第二条,monitor输出
KERNEL[1624533496.063995] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.1/1-1.4.1:1.0/host4/target4:0:0/4:0:0:0/block/sdb (block)KERNEL[1624533496.064080] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.2/1-1.4.2:1.0/host5/target5:0:0/5:0:0:0/block/sda (block)KERNEL[1624533496.064181] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.2/1-1.4.2:1.0/host5/target5:0:0/5:0:0:0/block/sda/sda1 (block)KERNEL[1624533496.064269] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.3/1-1.4.3:1.0/host6/target6:0:0/6:0:0:0/block/sdc (block)UDEV [1624533496.081699] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.1/1-1.4.1:1.0/host4/target4:0:0/4:0:0:0/block/sdb (block)UDEV [1624533496.082981] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.3/1-1.4.3:1.0/host6/target6:0:0/6:0:0:0/block/sdc (block)UDEV [1624533496.083941] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.2/1-1.4.2:1.0/host5/target5:0:0/5:0:0:0/block/sda (block)UDEV [1624533496.085070] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd (block)UDEV [1624533496.103061] add /devices/platform/hiusb-ehci.0/usb1/1-1/1-1.4/1-1.4.2/1-1.4.2:1.0/host5/target5:0:0/5:0:0:0/block/sda/sda1 (block)UDEV [1624533496.107014] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd/sdd3 (block)UDEV [1624533496.107077] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd/sdd2 (block)UDEV [1624533496.112003] add /devices/platform/ahci.0/ata4/host3/target3:0:0/3:0:0:0/block/sdd/sdd1 (block)
可见,monitor输出为满足trigger条件的节点,并未输出父节点或子节点
另外,trigger可以匹配的选项也是比较多的,可以支持attribute匹配,如下
udevadm trigger --action=add --subsystem-match=block --attr-match=size=7814037168
使用上述命令时,需要注意只输出符合条件的节点,另外,发现trigger不触发同时匹配父子节点的条件
udevadm trigger --action=add --attr-match=model=ST4000VX005-2LY1 --attr-match=size=7814037168这一点与上面所述的规则也是一致的
trigger触发事件后,udev就会匹配规则文件,然后执行动作,通过观察monitor的输出,检查动作的执行是否符合预期。
另外,udevadm control可以修改udev后台例程的日志级别
实际设备上发现,修改udev.conf文件,将日志级别从err改为debug或info后,系统启动不了,加载根文件系统后,不再进一步加载其他程序,这一点待研究确认。
通过上述流程,可以发现,新接入的设备,会由内核产生event,udev可以捕获该event
如果错过设备接入时机,没有捕获事件,可以通过trigger主动触发,让内核将之前保存的事件再次通知到应用层,同样可以匹配规则执行动作
所以结合sysfs和udev可以解决设备的重命名和挂载等处理需求
最后补充强调一下,
这里的trigger本质上是让内核重新发出事件,也就是说,实际上事件已经错过了。
根文件系统加载后,对于用户空间加载前,即udev本身启动监控前,内核驱动加载过程中已经识别和加载的设备,如何进行配置,就是依靠该命令
但是udev是在用户空间启动的,所以udev启动后,如果需要处理内核加载过程中的设备事件信息,就需要重新触发。但此时,该如何确定匹配条件呢?
答案是直接执行udevadm trigger,不加参数,此时内核会将所有产生的事件全部上报,由udev按需处理。
11 系统中的USB设备
执行lsusb命令输出如下内容
Bus 002 Device 001: ID 1d6b:0001 主机控制器 根HUBBus 001 Device 001: ID 1d6b:0002 主机控制器 根HUBBus 001 Device 002: ID 05e3:0610 USB HUBBus 001 Device 003: ID 05e3:0610 USB HUBBus 001 Device 004: ID 05e3:0610 USB HUBBus 001 Device 009: ID 1c9e:9b3c 龙尚模块Bus 001 Device 006: ID 0424:2240 USB读卡器Bus 001 Device 007: ID 0424:2240 USB读卡器Bus 001 Device 008: ID 0424:2240 USB读卡器Bus 001 Device 005: ID 0403:6011 USB转串口Bus 001 Device 010: ID 1c9e:9b3c 龙尚模块Bus 003 Device 001: ID 1d6b:0002 主机控制器 根HUBBus 003 Device 002: ID 0eef:0001 触摸屏Bus 004 Device 001: ID 1d6b:0003 主机控制器 根HUB
从上面可以看出,有四个总线,每个总线上各有1个或多个设备
从CPU角度来看,整体的USB树形结构如下图所示:
CPU --ohci 根设备,全速设备--usb2 [1d6b:0001] 主机USB控制器--ehci 根设备,高速设备--usb1 [1d6b:0002] 主机USB控制器--1-1 [05e3:0610] USB HUB--1-1.1 [1c9e:9b3c] 龙尚模块--1-1.4 [05e3:0610] USB HUB--1-1.4.1 [0424:2240] 三个存储卡USB口读卡器--1-1.4.2 [0424:2240]--1-1.4.3 [0424:2240]--1-1.2 nop--1-1.3 nop--1-2 [05e3:0610] USB HUB--1-2.1 [0403:6011] USB转串口--1-2.1:1.0 转换的多个串口--1-2.1:1.1--1-2.1:1.2--1-2.1:1.3--1-2.2 [1c9e:9b3c] 龙尚模块--xhci 根设备,USB3.0--usb3 [1d6b:0002] 主机USB控制器--touch [0eef:0001] 触摸屏--usb4 [1d6b:0003] 主机USB控制器--usb4 [1d6b:0003] 主机USB控制器
CPU本身带了三个控制器,分别支持全速,2.0以及3.0的USB设备。
12 网络子系统
文件抽象特性在网络子系统表达能力不强。
不过,仍然可以通过iNode将网络子系统中的资源和对象跟文件关联起来,这对特定情况下的问题查找很有帮助。
区分路由策略和路由表
待补充。
13 文件子系统
关键几个数据结构
超级块 inode 目录 文件 等。
文件子系统有两个主要问题需要处理,一个是高效的组织结构;一个是一致性。
这里一致性是更加棘手的一个问题。文件系统主要通过两个手段来保证一致性,一个是日志,一个是写时复制。
除此,还有其他一些原则,包括读写、节点、速度、大小、压缩、缓存、备份、索引、均衡、随机等原则。
具体参见博客:
7.5 文件系统_龙赤子的博客-CSDN博客
关于缓存,多说一点。
页缓存与缓冲区缓存。文件子系统构建后,优化的一大目标就是缓冲。我们知道,机械硬盘的吞吐量跟CPU和内存的处理速度差异太大。
特别是近二三十年,摩尔定律使得CPU处理性能不断翻翻,但是机械硬盘的速度,并没有太大的改进。为了匹配速度上的差异,就需要缓存来解决。
在嵌入式领域,很多时候使用flash作为数据断电保存的介质。相对机械动作,电子芯片的处理速度有很大的提升,但是跟CPU和内存相比,仍然有很大差距,所以缓存仍然是需要的。
最开始,块设备缓冲(更多针对直接操作物理设备块)是单独的,跟页缓冲(更多是针对文件映射)没有关系,这样一来,同一份数据,在内核中就可能存在多份。
后来,将二者整合到一起,在底层都是基于页缓冲。按物理页操作,也是内核擅长的。
实际中可能出现文件内容改变、损坏、丢失的情况。解决思路是
A 文件定期备份
B 分类管理,比如对于不变文件,保证只读属性,减少出错可能
C 监测文件IO状态,获取相关信息,辅助问题分析
D 异常断电、关机的特殊处理
E 电磁隔离保护
F 专用模块负责文件读写管理。
四 运行的内核
1 可以把内核想象为一个大进程,把自己想想成CPU,CPU就是一些寄存器的集合加逻辑处理过程。
2 内存视图看内核,Linux 的内存视图
参见博客:
学内核之十六:linux内存管理结构大蓝图_龙赤子的博客-CSDN博客
包括内存实体 :
任务结构 链条 地址空间
3 内核与应用层的交互途径:
proc
sys
dev
ioctl
netlink
unix socket
4 关于堆栈
堆栈分内核堆栈和应用堆栈
对于ARM来讲,在内核配置unwind选项的情况下,堆栈是通过解析unwind段来回溯的。
unwind段中记录了各个函数的入栈指令,然后根据发生异常时的PC地址,定位到具体的函数,之后反推堆栈操作,得到上一级的lr和fp地址
lr为调用函数的返回地址,通过该寄存器内容可以知道调用者是那个函数
fp为堆栈指针,通过该寄存器可以定位堆栈边界,这样一级一级回溯,即可获取调用栈信息。
关于内核调用栈的回溯,在内核unwind.c代码中
对CPU和堆栈的关系理解,可参见博主的文章:
学内核之四:关于内核与硬件的衔接_龙赤子的博客-CSDN博客
5 关于内核调试分析
perf 性能跟踪 大框架
ftrace 函数调用跟踪
ebpf 事件跟踪
相关文章:

Linux系统之Uboot、Kernel、Busybox思考之四
目录 三 内核的运行 9 设备树: 1) 设备树产生缘由 2) 设备树方案的流程 3) 有了上述概念,为了支撑整个设备树的工程实现,内核实现以下内容 4) 内核解析设备树 5) 入口分析 6) 解析处理。 10 udev devfs sysfs 11 系统中的USB设备 12 网…...

为什么要经常阅读和分析计算机SCI期刊论文? - 易智编译EaseEditing
训练阅读与分析期刊论文的能力,可以增加中长期的学术竞争力。 只要能够充分掌握阅读与分析期刊论文的技巧,就可以水到渠成地轻松进行「创新」的工作。 所以,只要深入掌握到阅读与分析期刊论文的技巧,就可以掌握到大学生不曾研习过…...

Shiro框架详解
1.Shiro简介 1.1.基本功能点 Shiro 可以非常容易的开发出足够好的应用,其不仅可以用在 JavaSE 环境,也可以用在 JavaEE 环境。Shiro 可以帮助我们完成:认证、授权、加密、会话管理、与 Web 集成、缓存等。 Authentication:身份…...

redhawk:GSC file与STA file
1.GSC file redhawk做lowpower分析时需要GSC(Global Switching Configuration)file指导block/instance/power domain的开关状态。 Syntax(in GSR file): GSC_FILES <gsc_FilePathName> Syntax(in GSC file&a…...

【Python学习笔记】46.Python3 math 模块和requests 模块
前言 本章介绍Python的math 模块和requests 模块。 Python math 模块 Python math 模块提供了许多对浮点数的数学运算函数。 math 模块下的函数,返回值均为浮点数,除非另有明确说明。 如果你需要计算复数,请使用 cmath 模块中的同名函数…...

页面导航-yang
这就是一个简单的导航 👀 机器视觉? 👨🔧 环境搭建 👨🔧 关与Tensorflow-gpu Anaconda Pycharm配置问题解决方案 👼 口罩识别 💻 实时口罩检测mp4视频识别 Ⅰ 💻…...

Mac配置homebrew
mac配置homebrew Homebrew是一款Mac OS平台下的软件包管理工具,拥有安装、卸载、更新、查看、搜索等很多实用的功能。简单的一条指令,就可以实现包管理,而不用你关心各种依赖和文件路径的情况,十分方便快捷。Homebrew主要有四个部…...

如何无报错运行代码YOLOv6,实现目标识别?
YOLOv6是由美团视觉团队开发的1.环境配置我们先把YOLOv6的代码clone下来git clone https://github.com/meituan/YOLOv6.git安装一些必要的包pip install pycocotools2.0作者要求pytorch的版本是1.8.0,我的环境是1.7.0,也是可以正常运行的pip install -r requirement…...

SQL91 返回购买价格为 10 美元或以上产品的顾客列表
描述OrderItems表示订单商品表,含有字段订单号:order_num、订单价格:item_price;Orders表代表订单信息表,含有顾客id:cust_id和订单号:order_numOrderItems表order_numitem_pricea110a21a21a42a…...
Goreplay使用教程0221
1、简介Goreplay 是用 Golang 写的一个HTTP 实时流量复制工具。功能更强大,支持流量的放大、缩小,频率限制,还支持把请求记录到文件,方便回放和分析,也支持和 ElasticSearch 集成,将流量存入 ES 进行实时分…...
9、GPT-1-2-3
GPT GPT系列即基于Transformer Decoder实现的预训练语言模型,在各类复杂的NLP任务中都取得了不错的效果,如文章生成、代码生成、机器翻译,Q&A等。 对于一个新的任务,GPT仅仅需要非常少的数据便可以理解该任务,并…...

Python-四分位数计算
怎么计算四分位数先理解四分位数怎么计算:可参考https://zhuanlan.zhihu.com/p/235345817,假设数列一共有n个数1)当 (n1)/4可以整除时,Q1第在(n1)/4位Q2第 (n1)/2位Q3第(n1)/4*3位举…...
一个简单的步骤让你的 Python 代码更干净
说起来容易做起来难,我们都知道代码可读性非常重要,但是写的时候总是随心所欲,不考虑类型提示、import 排序、PEP8 规范。今天分享一个小技巧,通过一个简单的步骤就可以让你的 Python 代码更干净。这就是 pre-commit:可…...
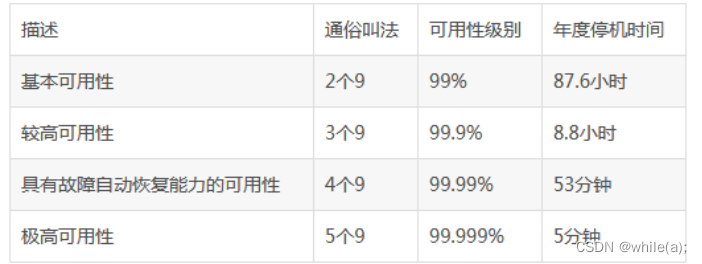
linux集群技术(二)--keepalived(高可用集群)(一)
高可用集群简介keepalived简介 1.高可用集群简介 1.1什么是高可用集群 高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务&am…...
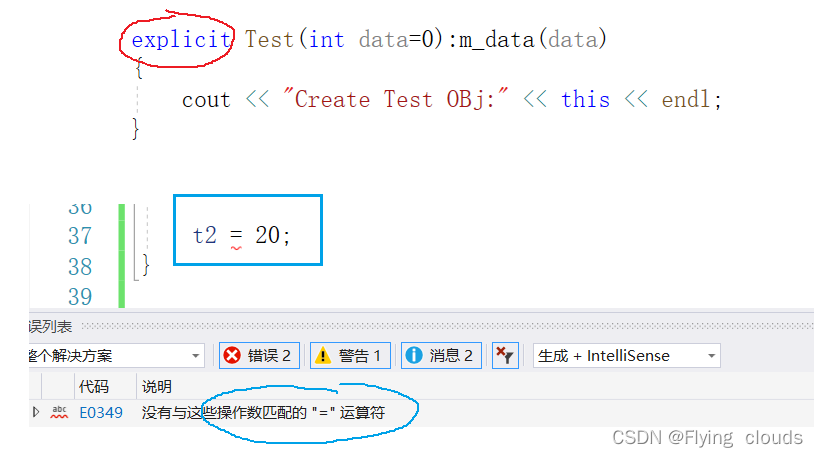
C++中的类型转换
目录 一、C语言中的类型转换 二、C中的类型转化 2.1 static_cast 2.2 const_cast2.2 const_cast 2.3reinterpret_cast 重解释转换 2.4 dynamic_cast 动态转换(!!!) 3. explicit 防止隐式类型转化 一、C语言…...

如何使用raw socket发送UDP报文
前面写的一篇《Linux下如何在数据链路层接收原始数据包》举了一个实例,使用raw socket接收UDP数据报,但是发送一个数据包比接收要复杂一些,本文以一个实例说明如何使用raw socket发送一个UDP报文。 1. 前言 阅读本文前可以考虑先阅读一下我的另外一篇文章《Linux下如何在数据…...
【C++】文件IO流
一起来康康C中的文件IO操作吧 文章目录1.operator bool2.C文件IO流3.文件操作3.0 关于按位与的说明3.1 ifstream3.2 ofstream流插入文本3.3 ostringstream/istringstream3.4 stringstream3.5使用stringstream的注意事项结语1.operator bool 之前写OJ的时候,就已经用…...
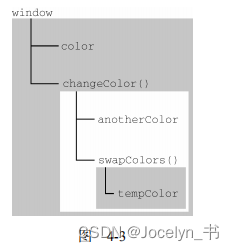
JavaScript高级程序设计读书分享之4章——4.2执行上下文与作用域
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 执行上下文 变量或函数的上下文决定 了它们可以访问哪些数据,以及它们的行为。在浏览器中,全局上下文就是我们常说的 window 对象(第 12 章会详细介绍)&am…...

函数的定义与声明
目录 1.函数的定义 2.函数声明 2.1 函数本地声明 2.2 函数外部声明 2.2.1函数的外部声明的好处和坏处 3.变量定义与声明 3.1变量定义 3.2变量声明 4.结构体的定义与声明 4.1结构体的定义 4.2结构体的声明 1.函数的定义 函数的定义即函数的具体实现。 2.函数声明 函数…...
mysql)
C#部署非安装版(绿色版)mysql
C#部署非安装版(绿色版)mysql场景实现步骤场景 项目由bs和cs端组成,bs端的数据存储在了mysql中,cs依赖bs运行,bs会显示一些实时的信息。 需求是给客户一个安装包,简易操作就可安装完成。 使用版本…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...