实战:基于卷积的MNIST手写体分类
前面实现了基于多层感知机的MNIST手写体识别,本章将实现以卷积神经网络完成的MNIST手写体识别。
1. 数据的准备
在本例中,依旧使用MNIST数据集,对这个数据集的数据和标签介绍,前面的章节已详细说明过了,相对于前面章节直接对数据进行“折叠”处理,这里需要显式地标注出数据的通道,代码如下:
import numpy as npimport einops.layers.torch as elt#载入数据x_train = np.load("../dataset/mnist/x_train.npy")y_train_label = np.load("../dataset/mnist/y_train_label.npy")x_train = np.expand_dims(x_train,axis=1) #在指定维度上进行扩充print(x_train.shape)这里是对数据的修正,np.expand_dims的作用是在指定维度上进行扩充,这里在第二维(也就是PyTorch的通道维度)进行扩充,结果如下:
(60000, 1, 28, 28)
2. 模型的设计
下面使用PyTorch 2.0框架对模型进行设计,在本例中将使用卷积层对数据进行处理,完整的模型如下:
import torch
import torch.nn as nn
import numpy as np
import einops.layers.torch as elt
class MnistNetword(nn.Module):def __init__(self):super(MnistNetword, self).__init__()#前置的特征提取模块self.convs_stack = nn.Sequential(nn.Conv2d(1,12,kernel_size=7), #第一个卷积层nn.ReLU(),nn.Conv2d(12,24,kernel_size=5), #第二个卷积层nn.ReLU(),nn.Conv2d(24,6,kernel_size=3) #第三个卷积层)#最终分类器层self.logits_layer = nn.Linear(in_features=1536,out_features=10)def forward(self,inputs):image = inputsx = self.convs_stack(image) #elt.Rearrange的作用是对输入数据的维度进行调整,读者可以使用torch.nn.Flatten函数完成此工作x = elt.Rearrange("b c h w -> b (c h w)")(x)logits = self.logits_layer(x)return logits
model = MnistNetword()
torch.save(model,"model.pth")
这里首先设定了3个卷积层作为前置的特征提取层,最后一个全连接层作为分类器层,需要注意的是,对于分类器的全连接层,输入维度需要手动计算,当然读者可以一步一步尝试打印特征提取层的结果,依次将结果作为下一层的输入维度。最后对模型进行保存。
3. 基于卷积的MNIST分类模型
下面进入本章的最后示例部分,也就是MNIST手写体的分类。完整的训练代码如下:
import torch
import torch.nn as nn
import numpy as np
import einops.layers.torch as elt
#载入数据
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")
x_train = np.expand_dims(x_train,axis=1)
print(x_train.shape)
class MnistNetword(nn.Module):def __init__(self):super(MnistNetword, self).__init__()self.convs_stack = nn.Sequential(nn.Conv2d(1,12,kernel_size=7),nn.ReLU(),nn.Conv2d(12,24,kernel_size=5),nn.ReLU(),nn.Conv2d(24,6,kernel_size=3))self.logits_layer = nn.Linear(in_features=1536,out_features=10)def forward(self,inputs):image = inputsx = self.convs_stack(image)x = elt.Rearrange("b c h w -> b (c h w)")(x)logits = self.logits_layer(x)return logits
device = "cuda" if torch.cuda.is_available() else "cpu"
#注意记得将model发送到GPU计算
model = MnistNetword().to(device)
model = torch.compile(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
batch_size = 128
for epoch in range(42):train_num = len(x_train)//128train_loss = 0.for i in range(train_num):start = i * batch_sizeend = (i + 1) * batch_sizex_batch = torch.tensor(x_train[start:end]).to(device)y_batch = torch.tensor(y_train_label[start:end]).to(device)pred = model(x_batch)loss = loss_fn(pred, y_batch)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item() # 记录每个批次的损失值# 计算并打印损失值train_loss /= train_numaccuracy = (pred.argmax(1) == y_batch).type(torch.float32).sum().item() / batch_sizeprint("epoch:",epoch,"train_loss:", round(train_loss,2),"accuracy:",round(accuracy,2))
在这里,我们使用了本章新定义的卷积神经网络模块作为局部特征抽取,而对于其他的损失函数以及优化函数,只使用了与前期一样的模式进行模型训练。最终结果如下所示,请读者自行验证。
(60000, 1, 28, 28)
epoch: 0 train_loss: 2.3 accuracy: 0.11
epoch: 1 train_loss: 2.3 accuracy: 0.13
epoch: 2 train_loss: 2.3 accuracy: 0.2
epoch: 3 train_loss: 2.3 accuracy: 0.18
…
epoch: 58 train_loss: 0.5 accuracy: 0.98
epoch: 59 train_loss: 0.49 accuracy: 0.98
epoch: 60 train_loss: 0.49 accuracy: 0.98
epoch: 61 train_loss: 0.48 accuracy: 0.98
epoch: 62 train_loss: 0.48 accuracy: 0.98Process finished with exit code 0
本文节选自《PyTorch 2.0深度学习从零开始学》,本书实战案例丰富,可带领读者快速掌握深度学习算法及其常见案例。

相关文章:
实战:基于卷积的MNIST手写体分类
前面实现了基于多层感知机的MNIST手写体识别,本章将实现以卷积神经网络完成的MNIST手写体识别。 1. 数据的准备 在本例中,依旧使用MNIST数据集,对这个数据集的数据和标签介绍,前面的章节已详细说明过了,相对于前面章…...

Ubuntu开启生成Core Dump的方法
C 文章目录 C1. 首先ulimit通过查看2. 执行下面的命令 Ubuntu下无法生成Core Dump解决方法 1. 首先ulimit通过查看 ulimit -a查看是core file size是否为0,若为0,通过以下方式设置size ulimit -c 1024或者 ulimit -c unlimited //size没有限制2. 执行…...
git视频教程Jenkins持续集成视频教程Git Gitlab Sonar教程
[TOC这里写自定义目录标题) https://edu.51cto.com/lesson/290903.html 欢迎使用Markdown编辑器 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。…...
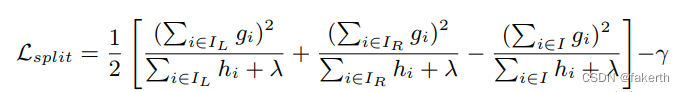
机器学习:Xgboost
Xgboost XGBoost(eXtreme Gradient Boosting)是一种机器学习算法,是梯度提升决策树(Gradient Boosting Decision Trees)的一种优化实现。它是由陈天奇在2014年开发并推出的。XGBoost是一种强大而高效的算法࿰…...

《Kubernetes部署篇:Ubuntu20.04基于二进制安装安装cri-containerd-cni》
一、背景 由于客户网络处于专网环境下, 使用kubeadm工具安装K8S集群,由于无法连通互联网,所有无法使用apt工具安装kubeadm、kubelet、kubectl,当然你也可以使用apt-get工具在一台能够连通互联网环境的服务器上下载cri-tools、cont…...
[CISCN 2019初赛]Love Math
文章目录 前言考点解题过程 前言 感慨自己实力不够,心浮气躁根本做不来难题。难得这题对我还很有吸引力,也涉及很多知识。只能说我是受益匪浅,总的来说加油吧ctfer。 考点 利用php动态函数的特性利用php中的数学函数实现命令执行利用php7的特…...
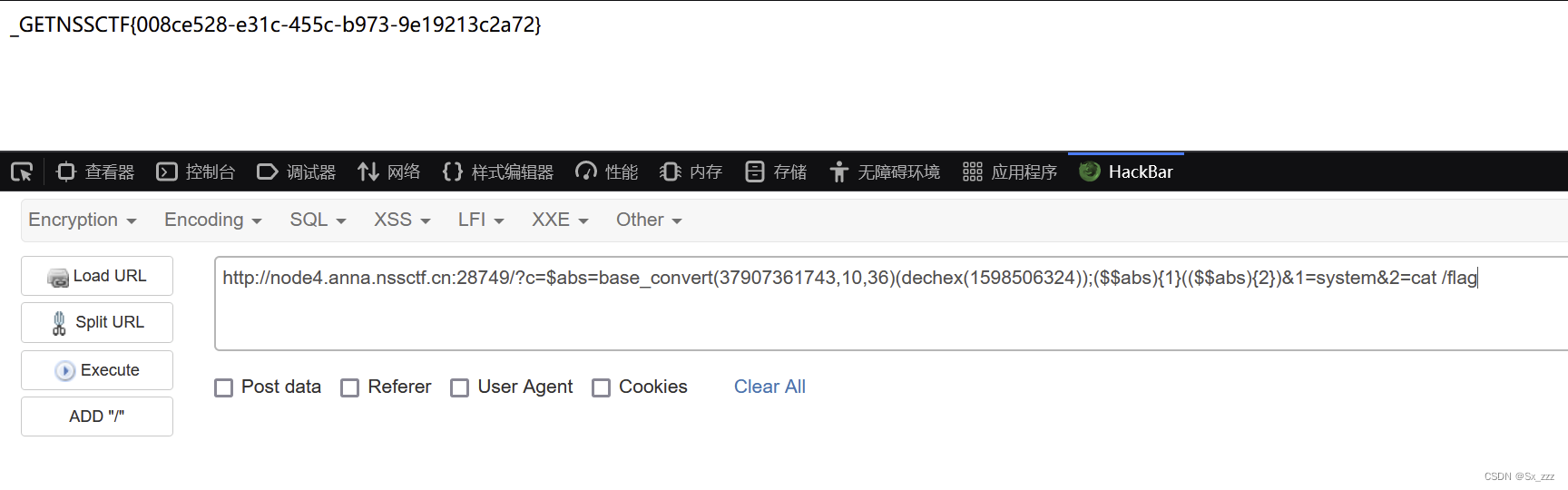
运行命令出现错误 /bin/bash^M: bad interpreter: No such file or directory
在系统上运行一个 Linux 的命令的时候出现下面的错误信息: -bash: ./build.sh: /bin/bash^M: bad interpreter: No such file or directory 这个是在 Windows 作为 WSL 的时候出的错误。 原因和解决 出现问题的原因在于脚本在 Windows 中使用的回车换行和 Linux …...

码农重装系统后需要安装的软件
文章目录 前言1 编程软件1.1 IntelliJ IDEA1.2 Eclipse1.3 VSCode 2 Java 开发环境3 测试运维工具3.1 Docker3.2 VirtualBox3.2.1 windows3.2.2 centos 7 83.2.3 Alma Linux3.2.4 Rocky Linux3.2.5 ubuntu server3.2.6 统信 UOS 服务器操作系统V20(免费使用授权&…...

Kotlin return 和 loop jump
再聊 return 在上一篇文章《Kotlin inline、noinline、crossinline 深入解析》 我们介绍到,在 lambda 中不能使用 return,除非该函数是 inline 的。如果该高阶函数是 inline ,调用该函数时,在传入的 lambda 中使用 return,则 return 的是离它最近的 enclosing function,…...

计算一组数据中的低中位数即如果一组数据中有两个中位数则较小的那个为低中位数statistics.median_low()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 计算一组数据中的低中位数 即如果一组数据中有两个中位数 则较小的那个为低中位数 statistics.median_low() 选择题 以下程序的运行结果是? import statistics data_1[1,2,3,4,5] data_2[1,2,…...

ChatGPT是否能够协助人们提高公共服务和社区建设能力?
ChatGPT可以协助人们提高公共服务和社区建设能力。公共服务是一个广泛的领域,包括教育、医疗、城市规划、紧急救援、环境保护等多个方面。ChatGPT作为一种人工智能工具,具有巨大的潜力,可以在各个领域提供支持和增强决策制定、信息获取、沟通…...

机器人中的数值优化(七)——修正阻尼牛顿法
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,…...

程序员自由创业周记#3:No1.作品
作息 如果不是热爱,很难解释为什么能早上6点自然醒后坐在电脑前除了吃饭一直敲代码到23点这个现象,而且还乐此不疲。 之前上班的时候生活就很规律,没想到失业后的生活比之前还要规律;记得还在上班的时候,每天7点半懒洋…...

固定资产制度怎么完善管理?
固定资产管理制度的完善管理可以从以下几个方面入手: 建立完善的资产管理制度,可以及时掌握企业资产的信息状况,使资产管理更加明确,防止资产流失。 加大固定资产监管力度,从配置资产、使用资产到处置资产进行全…...

神经网络--感知机
感知机 单层感知机原理 单层感知机:解决二分类问题,激活函数一般使用sign函数,基于误分类点到超平面的距离总和来构造损失函数,由损失函数推导出模型中损失函数对参数 w w w和 b b b的梯度,利用梯度下降法从而进行参数更新。让1代表A类,0代…...
Java“牵手”1688图片识别商品接口数据,图片地址识别商品接口,图片识别相似商品接口,1688API申请指南
1688商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要通过图片地址识别获取1688商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问1688商城的网页来获取商品详情信息。以下是两种常…...

科技资讯|微软获得AI双肩包专利,Find My防丢背包大火
根据美国商标和专利局(USPTO)近日公示的清单,微软于今年 5 月提交了一项智能双肩包专利,其亮点在于整合了 AI 技术,可以识别佩戴者周围环境、自动响应用户聊天请求、访问基于云端的信息、以及和其它设备交互。 在此附…...

数学建模:多目标优化算法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:多目标优化算法 多目标优化 分别求权重方法 算法流程: 两个目标权重求和,化为单目标函数,然后求解最优值 min x ∑ i 1 m w i F i ( x ) s.…...

arcmap 在oracle删除表重新创建提示表名存在解决放啊
sde表创建是有注册或者是关联关系存在的 按照以下步骤删除表的数据 select t.* from sde.TABLE_REGISTRY t where table_name like IRR%; DELETE from sde.TABLE_REGISTRY where table_nameIRRIGATION_TYPE; select t.* from sde.LAYERS t where table_name like IRR%; DELET…...
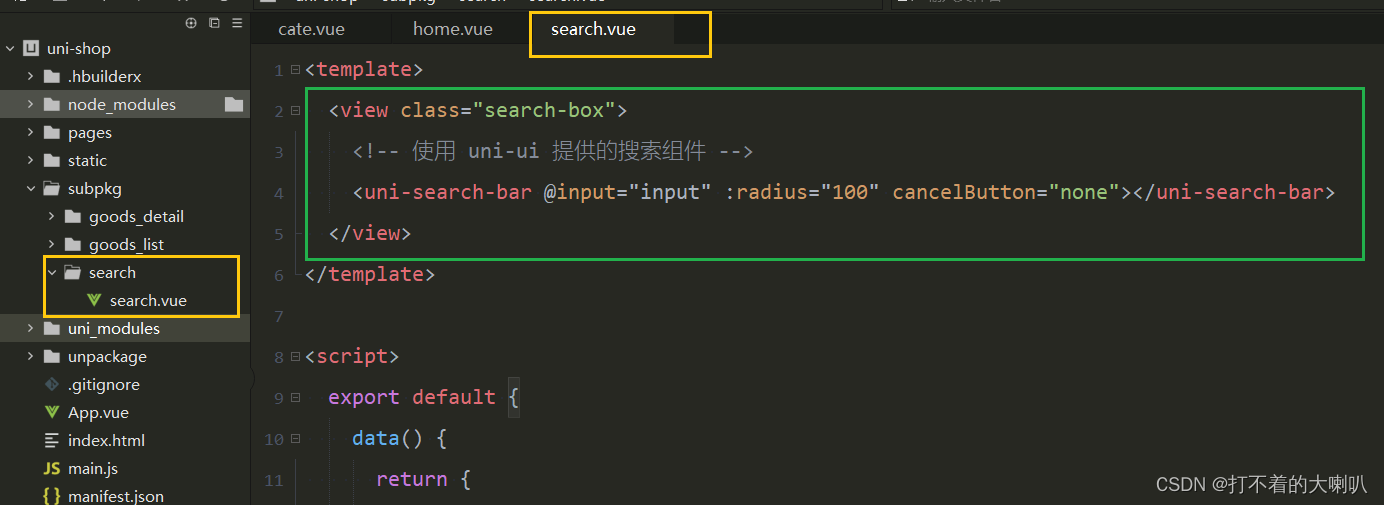
新版HBuilderX在uni_modules创建搜索search组件
1、创建自定义组件 my-search 新版HBuilder没有了 component 文件夹,但是有 uni_modules 文件夹,用来创建组件: 右键 uni_modules 文件夹,点击 新建uni_modules创建在弹出框,填写组件名字,例如:…...

王小川All in医疗大模型:从通用赛道抽身,“造AI医生”能否突围?
All in医疗有它的代价一年前,王小川带着百川智能大幅缩减通用模型团队,关闭多条行业线,All in医疗大模型。当时整个大模型行业热闹非凡,平均3天就有一个新版本的通用大模型面世。而百川在5月22日交出答卷,发布新医疗大…...

linux IO重定向
IO中的文件描述符0 ,stdin, 标准输入, 指向键盘 1 ,stdout, 标准输出, 指向终端屏幕 2 ,stderr, 标准错误输出, 指向终端屏幕 /dev/null 无底洞,有些不想要的输出信息可以送到这里。& , 在重定向中引用文件描述符.例子.2>&1 , 把 stderr(文…...

Taotoken多模型路由在单一服务故障时的体验保障
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型路由在单一服务故障时的体验保障 1. 引言 在构建依赖大模型能力的应用时,服务的稳定性是开发者必须面对…...

FastGithub终极教程:5分钟解决GitHub访问卡顿问题
FastGithub终极教程:5分钟解决GitHub访问卡顿问题 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub GitHub作为全球最大的代码托管平台,是每个开发…...

【电路板】基于matlab模拟电路板激光加工中的热分布【含Matlab源码 15559期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

FTP明文传输风险与Wireshark抓包实证分析
1. 这不是危言耸听:FTP 的“裸奔”现状每天都在发生你有没有在公司内网用过 FTP 上传一份财务报表?有没有在校园网里用 FileZilla 向老师提交课程设计源码?有没有在运维后台用 ftp 命令同步过网站静态资源?如果答案是肯定的&#…...

WidescreenFixesPack:让经典游戏在宽屏显示器上重获新生的终极解决方案
WidescreenFixesPack:让经典游戏在宽屏显示器上重获新生的终极解决方案 【免费下载链接】WidescreenFixesPack Plugins to make or improve widescreen resolutions support in games, add more features and fix bugs. 项目地址: https://gitcode.com/gh_mirrors…...

为什么感觉苹果11的手机放歌音效比华为mate80好,大家觉得呢?什么原因?配置有何差别?——有没有音效好的手机推荐?——有带hifi效果的吗?
公开信息中没有直接对比两款机型音效的权威测试,结合硬件和系统规律来看,这种听感差异主要是调校风格不同导致的,并非绝对的音质好坏。 核心原因分析 系统与音频链路调校差异 苹果iOS是封闭式系统,对音频链路的优化更统一,没有第三方厂商的碎片化干扰,驱动调校成熟…...
)
【独家首发】保险业首个AI Agent成熟度评估模型(5级量化标准+12项KPI基线数据)
更多请点击: https://intelliparadigm.com 第一章:【独家首发】保险业首个AI Agent成熟度评估模型(5级量化标准12项KPI基线数据) 该模型由国内头部保险科技联合实验室历时18个月实证研发,首次将AI Agent在核保、理赔、…...

C++ std::function:类型擦除与万能函数包装器实战指南
1. 项目概述:为什么我们需要 std::function 在C的世界里,函数指针曾经是回调、事件处理和策略模式等场景的绝对主力。但用过的人都知道,那玩意儿用起来有多别扭:类型声明复杂,对非静态成员函数、lambda表达式、函数对…...