Redis面试题
目录
Redis持久化机制:RDB和AOF
Redis线程模型有哪些?单线程为什么快?
Redis的过期键有哪些删除策略?
Redis集群方案有哪些?
redis事务怎么实现?
为什么redis不支持回滚?
redis主从复制的原理是什么
Redis复制功能是如何工作
缓存雪崩、缓存穿透、缓存击穿在实际中如何处理
Redis持久化机制:RDB和AOF
Redis提供了不同级别的持久化方式:
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
你也可以同时开启两种持久化方式,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
最重要的事情是了解RDB和AOF持久化方式的不同,让我们以RDB持久化方式开始
RDB的优点
RDB是一个非常紧凑的文件;它保存了某个时间点得数据集,非常适用于数据集的备份;比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复.
RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他lO操作,所以RDB持久化方式可以最大化redis的性能.
与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
RDB缺点
如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,
那么RDB不适合你.虽然你
可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Red
is要完整的保存整个数据集
是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存;万一在Redis意外宕机,你可能会丢失几分钟的数据.
RDB需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
AOF优点
使用AOF会让你的Redis更加耐久:你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求);一旦出现故障,你最多丢失1秒的数据.
AOF文件是一个只进行追加的日志文件所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
Redis 可以在AOF文件体积变得过大时,自动地在后台对AOF进行重写:重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新AOF文件的过程中,会继续将命令追加到现有的AOF文件里面,即使重写过程中发生停机,现有的AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作。
AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此AOF文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出 (export)AOF文件也非常简单:举个例子,如果你不小心执行了FLUSHALL命令,但只要AOF文件未被重写,那么只要停止服务器,移除AOF文件末尾的FLUSHALL 命令,并重启Redis,就可以将数据集恢复到FLUSHALL执行之前的状态。
AOF缺点
对于相同的数据集来说,AOF文件的体积通常要大于RDB文件的体积。
根据所使用的fsync策略,AOF的速度可能会慢于RDB。在一般情况下,每秒fsync的性能依然非常局,而关闭fsync可以让AOF的速度和RDB一样快,即使在高负荷之下也是如此。不过在处理巨大的写入载入时,RDB可以提供更有保证的最大延迟时间(latency)。
Redis线程模型有哪些?单线程为什么快?
IO模型维度的特征
IO模型使用了多路复用器,在linux系统中使用的是EPOLL
类似netty的BOSS,WORKER使用一个EventLoopGroup(threads=1)
单线程的Reactor模型,每次循环取socket中的命令然后逐一操作,可以保证socket中的指令是按顺序的,不保证不同的socket也就是客户端的命令的顺序性
命令操作在单线程中顺序操作,没有多线程的困扰不需要锁的复杂度,在操作数据上相对来说是原子性质的
架构的设计模型
自身的内存存储数据,读写操作不设计磁盘IO
redis除了提供了Value具备类型还为每种类型实现了一些操作命令
实现了计算向数据移动,而非数据向计算移动,这样在IO的成本上有一定的优势
且在数据结构类型上,丰富了一些统计类属性,读写操作中,写操作会O(1)负载度更新length类属性,使得读操作也是O(1)的
Redis的过期键有哪些删除策略?
过期精度
在Redis 2.4及以前版本,过期期时间可能不是十分准确,有O-1秒的误差。
从Redis 2.6起,过期时间误差缩小到0-1毫秒。
过期和持久
Keys的过期时间使用Unix时间戳存储(从Redis 2.6开始以毫秒为单位)。这意味着即使Redis实例不可用,时间也是一直在流逝的。
要想过期的工作处理好,计算机必须采用稳定的时间。如果你将RDB文件在两台时钟不同步的电脑间同步,有趣的事会发生(所有的keys装载时就会过期)。
即使正在运行的实例也会检查计算机的时钟,例如如果你设置了一个key的有效期是1000秒,然后设置你的计算机时间为未来2000秒,这时key会立即失效,而不是等1000秒之后。
Redis如何淘汰过期的keys
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
1.测试随机的20个keys进行相关过期检测。
2.删除所有已经过期的keys。
3.如果有多于25%的keys过期,重复步骤1.
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys.
在复制AOF文件时如何处理过期
为了获得正确的行为而不牺牲一致性,当一个key过期,DEL将会随着AOF文字一起合成到所有附加的slaves。在master实例中,这种方法是集中的,并且不存在一致性错误的机会。
然而,当slaves连接到master时,不会独立过期keys(会等到master执行DEL命令),他们任然会在数据集里面存在,所以当slave当选为master时淘汰keys会独立执行,然后成为master。
Redis缓存如何回收?
noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
allkeys-1ru:尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
volatile-1ru:尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
allkeys-random:回收随机的键使得新添加的数据有空间存放。
volatile-random:回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
volatile-tt1:回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
volatile-7fu:从所有配置了过期时间的键中驱逐使用频率最少的键
a7lkeys-7fu:从所有键中驱逐使用频率最少的键
如果没有键满足回收的前提条件的话,策略volatile-lru, volatile-random以及volatile-ttl就和noeviction差不多了。
选择正确的回收策略是非常重要的,这取决于你的应用的访问模式,不过你可以在运行时进行相关的策略调整,并且监控缓存命中率和没命中的次数,通过RedisINFO命令输出以便调优。
—般的经验规则:
·使用allkeys-lru策略:当你希望你的请求符合一个幂定律分布,也就是说,你希望部分的子集元素将比其它其它元素被访问的更多。如果你不确定选择什么,这是个很好的选择。.
·使用alkeys-random:如果你是循环访问,所有的键被连续的扫描,或者你希望请求分布正常(所有元素被访问的概率都差不多)。
·使用volatile-ttl:如果你想要通过创建缓存对象时设置TTL值,来决定哪些对象应该被过期。
allkeys-ru和volatile-random策略对于当你想要单一的实例实现缓存及持久化一些键时很有用。不过一般运行两个实例是解决这个问题的更好方法。
为了键设置过期时间也是需要消耗内存的,所以使用allkeys-lru这种策略更加高效,因为没有必要为键取设置过期时间当内存有压力时。
Redis集群方案有哪些?
常见集群分类:主从复制集群、分片集群
Redis集群有哪些?
主从复制集群,手动切换
带有哨兵的HA的主从复制集群
客户端实现路由索引的分片集群
使用中间件代理层的分片集群
redis自身实现的cluster分片集群
redis事务怎么实现?
MULTI、EXEC、DISCARD和WATCH是Redis事务相关的命令。事务可以一次执行多个命令,并且带有以下两个重要的保证:
1、事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
2、事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
EXEC命令负责触发并执行事务中的所有命令:
如果客户端在使用MULTI开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。
另一方面,如果客户端成功在开启事务之后执行EXEC ,那么事务中的所有命令都会被执行。
当使用AOF方式做持久化的时候, Redis 会使用单个write(2)命令将事务写入到磁盘中。
然而,如果Redis服务器因为某些原因被管理员杀死,或者遇上某种硬件故障,那么可能只有部分事务命令会被成功写入到磁盘中。
如果Redis在重新启动时发现AOF文件出了这样的问题,那么它会退出,并汇报一个错误。
使用redis-check-aof程序可以修复这一问题:它会移除AOF文件中不完整事务的信息,确保服务器可以顺利启动。
从2.2版本开始,Redis 还可以通过乐观锁(optimistic lock)实现CAS (check-and-set)操作。
事务中的错误
使用事务时可能会遇上以下两种错误:
事务在执行 EXEC之前,入队的颌令可能会出错。比如说,命令可能会产生语法错误(参数数量错误,参数名错误,等等),或者其他更严重的错误,比如内存不足(如果服务器使用maxmemory 设置了最大内存限制的话)。
命令可能在EXEC 调用之后失败。举个例子,事务中的命令可能处理了错误类型的键,比如将列表命令用在了字符串键上面,诸如此类。
对于发生在EXEC执行之前的错误,客户端以前的做法是检查命令入队所得的返回值:如果命令入队时返回QUEUED,那么入队成功;否则,就是入队失败。如果有命令在入队时失败,那么大部分客户端都会停止并取消这个事务。
不过,从Redis 2.6.5开始,服务器会对命令入队失败的情况进行记录,并在客户端调用EXEC命令时,拒绝执行并自动放弃这个事务。
在Redis 2.6.5以前,Redis只执行事务中那些入队成功的命令,而忽略那些入队失败的命令。而新的处理方式则使得在流水线(pipeline)中包含事务变得简单,因为发送事务和读取事务的回复都只需要和服务器进行一次通讯。
至于那些在EXEC_命令执行之后所产生的错误,并没有对它们进行特别处理:即使事务中有某个/某些命令在执行时产生了错误,事务中的其他命令仍然会继续执行。
为什么redis不支持回滚?
如果你有使用关系式数据库的经验,那么“Redis在事务失败时不进行回滚,而是继续执行余下的命令"这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
因为不需要对回滚进行支持,所以Redis的内部可以保持简单且快速。
有种观点认为Redis处理事务的做法会产生bug,然而需要注意的是,在通常情况下,回滚并不能解决编程错误带来的问题。举个例子,如果你本来想通过INCR命令将键的值加上1,却不小心加上了2,又或者对错误类型的键执行了INCR,回滚是没有办法处理这些情况的。
redis主从复制的原理是什么
主从复制机制
当一个master实例和一个 slave实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给slave , :包括客户端的写入、key 的过期或被逐出等等。
当master和 slave 之间的连接断开之后,因为网络问题、或者是主从意识到连接超时
s7ave重新连接上
master 并会尝试进行部分重同步:这意味着它会尝试只获取在断开连接期间内丢失的命
当无法进行部分重同步时, slave 会请求进行全量重同步。这会涉及到一个更复杂的过程,例如 master需要创建所有数据的快照,将之发送给slave ,之后在数据集更改时持续发送命令流到s1ave
主从复制的关注点
Redis使用异步复制,slave 和 master 之间异步地确认处理的数据量
一个master 可以拥有多个 slave
slave可以接受其他 slave 的连接。除了多个 slave可以连接到同一个 master之外, slave 之间也可以像层叠状的结构(cascading-1ike structure)连接到其他 slave 。自Redis 4.0起,所有的 sub-slave 将会从master收到完全一样的复制流。
Redis复制在 master侧是非阻塞的。这意味着master 在一个或多个slave进行初次同步或者是部分重同步时,可以继续处理查询请求。
复制在 slave侧大部分也是非阻塞的。当 slave进行初次同步时,它可以使用旧数据集处理查询请求,假设你在redis.conf中配置了让 Redis这样做的话。否则,你可以配置如果复制流断开, Redis slave 会返回一个error给客户端。但是,在初次同步之后,旧数据集必须被删除,同时加载新的数据集。
slave 在这个短暂的时间窗口
内(如果数据集很大,会持续较长时间),会阻塞到来的连接请求。自 Redis 4.0开始
可以配置Redis使删除旧数
据集的操作在另一个不同的线程中进行,但是,加载新数据集的操作依然需要在主线程中进行并且会阻塞 slave 。
复制既可以被用在可伸缩性,以便只读查询可以有多个 slave 进行(例如 o(N)复杂度的慢操作可以被下放到 slave),或者仅用于数据安全。
可以使用复制来避免 master 将全部数据集写入磁盘造成的开销:一种典型的技术是配置你的 master Redis.conf以避免对磁盘进行持久化,然后连接一个 slave ,其配置为不定期保存或是启用AOF。但是,这个设置必须小心处理,因为重新启动的 master程序将从一个空数据集开始:如果一个 slave试图与它同步那么这个 slave也会被清空。
任何时候数据安全性都是很重要的,所以如果 master使用复制功能的同时未配置持久化,那么自动重启进程这项应该被禁用。
Redis复制功能是如何工作
每一个Redis master都有一个replication ID:这是一个较大的伪随机字符串,标记了一个给定的数据集。每个master也持有一个偏移量,master将自己产生的复制流发送给slave时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新slave的状态。复制偏移量即使在没有—个slave连接到master时,也会自增,所以基本上每一对给定的。
Replication lD, offset
都会标识一个master数据集的确切版本。
当slave连接到master时,它们使用PSYNC命令来发送它们记录的旧的 master replication lD和它们至今为止处理的偏移量。通过这种方式, master能够仅发送slave所需的增量部分。但是如果master的缓冲区中没有足够的命令积压缓冲记录,或者如果slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量
重同步:在这种情况下, slave 会得到一个完整的数据集副本,从头开始。
下面是一个全量同步的工作细节:
master开启一个后台保存进程,以便于生产一个RDB文件。同时它开始缓冲所有从客户端接收到的新的写入命令。当后台保存完成时,master将数据集文件传输给slave,slave将之保存在磁盘上,然后加载文件到内存。再然后master会发送所有缓冲的命令发给slave。这个过程以指令流的形式完成并且和Redis 协议本身的格式相同。
缓存雪崩、缓存穿透、缓存击穿在实际中如何处理
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存击穿
对于一些设置了过期时间的ey,如果这些key可能会在某些时间点被超高并发地访问,是一种非常"热点"的数据。这个时候,需要考虑一个问题:缓存被"击穿"的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案
1.使用互斥锁(mutex key)
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。SETNX,是「SETif Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。在redis2.6.1之前版本未实现setnx的过期时间
2."提前"使用互斥锁(mutex key):
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
总结
穿透:缓存不存在,数据库不存在,高并发,少量key
击穿:缓存不存在,数据库存在,高并发,少量key
雪崩:缓存不存在,数据库存在,高并发,大量key
语义有些许差异,但是,都可以使用限流的互斥锁,保障数据库的稳定
相关文章:

Redis面试题
目录 Redis持久化机制:RDB和AOF Redis线程模型有哪些?单线程为什么快? Redis的过期键有哪些删除策略? Redis集群方案有哪些? redis事务怎么实现? 为什么redis不支持回滚? redis主从复制的原理是什么 …...

微服务之Eureka
🏠个人主页:阿杰的博客 💪个人简介:大家好,我是阿杰,一个正在努力让自己变得更好的男人👨 目前状况🎉:24届毕业生,奋斗在找实习的路上🌟 …...

日日顺于贞超:供应链数字化要做到有数、有路、有人
在供应链行业里面,关于“数字化”的讨论绝对是一个经久不衰的话题。 但关于这个话题的讨论又时常让人觉得“隔靴搔痒”,因为数字化变革为非一日之功,对于企业来说意味着投入和牺牲。企业既怕不做怕将来被淘汰,又怕投入过高、不达预…...

Js中blob、file、FormData、DataView、TypedArray
引言 最开始我们看网页时,对网页的需求不高,显示点文字,显示点图片就很满足了,所以对于浏览器而言其操作的数据其实并不多(比如读取本地图片显示出来,或上传图片到服务器),那么浏览器…...

CTFer成长之路之任意文件读取漏洞
任意文件读取漏洞CTF 任意文件读取漏洞 afr_1 题目描述: 暂无 docker-compose.yml version: 3.2services:web:image: registry.cn-hangzhou.aliyuncs.com/n1book/web-file-read-1:latestports:- 80:80启动方式 docker-compose up -d 题目Flag n1book{afr_1_solved} W…...

制造企业为何要上数字化工厂系统?
以目前形势来看,数字化转型是制造企业生存的关键,而数字化工厂管理系统是一个综合性、系统性的工程,波及整个企业及其供应链生态系统。数字化工厂系统所要实现的互联互通系统集成、数据信息融合和产品全生命周期集成,将方方面面的…...

Facebook广告投放的正确姿势:玩转目标定位
如果你正在投放 Facebook广告,那么你一定有过这样的经历:明明设置了目标受众,但是广告却没有带来转化。在这方面,你可能忽略了一个很重要的因素——目标定位。想要打造高质量、高曝光率的 Facebook广告,如何才能成功实…...

思科C9115AXI-H型号AP上线C9800失败处理记录
问题描述 原先的AP故障,从DNAC上发现状态down。现场发现AP灯灭,端口不亮。随即定位为AP单点故障。暂时的处理方法为:更换新AP上线。更换完毕后发现绿灯亮后熄灭。进一步说明网线无异常,属于AP故障。 如果顺利,在DNAC上…...

WSO2通过设定Role来订阅对应的Api
WSO2通过设定Role来订阅对应的Api1. Add Role And User1.0 Add Role1.1 Add User 1.2 Add Mapping2. Upload Api2.1 Upload Three Apis2.2 Inspection3. AwakeningWSO2安装使用的全过程详解: https://blog.csdn.net/weixin_43916074/article/details/127987099. 1. Add Role An…...
使用 PyTorch+LSTM 进行单变量时间序列预测(附完整源码)
时间序列是指在一段时间内发生的任何可量化的度量或事件。尽管这听起来微不足道,但几乎任何东西都可以被认为是时间序列。一个月里你每小时的平均心率,一年里一只股票的日收盘价,一年里某个城市每周发生的交通事故数。 在任何一段时间段内记…...
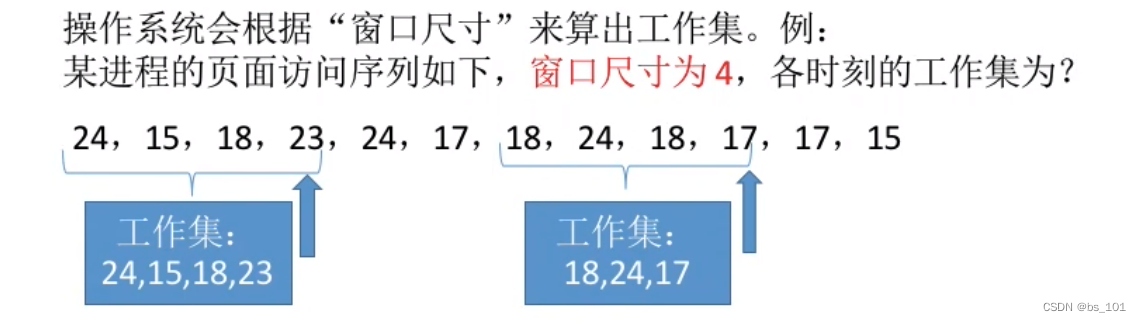
操作系统(day12)-- 虚拟内存;页面分配策略
虚拟内存管理 虚拟内存的基本概念 传统存储管理方式的特征、缺点 一次性: 作业必须一次性全部装入内存后才能开始运行。驻留性:作业一旦被装入内存,就会一直驻留在内存中,直至作业运行结束。事实上,在一个时间段内&…...

Git commit 提交没有被远端分支合并,撤销本次commit
问题:今天修改代码,误把项目配置文件修改为本地数据库连接,需要撤销本次commit 记录。解决办法:第一步:使用git log 查看所有commit 记录。第二步:使用git show commitID 查看指定commit 文件修改记录。第三…...

Netty核心原理(线程模型、核心API)与入门案例详解
Netty核心原理(线程模型、核心API)与入门案例详解 文章目录Netty核心原理(线程模型、核心API)与入门案例详解Netty 介绍原生 NIO 存在的问题概述线程模型线程模型基本介绍传统阻塞 I/O 服务模型Reactor 模型单 Reactor 单线程Nett…...
【 java 8】Lambda 表达式
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

改进YOLO系列 | 谷歌团队 | CondConv:用于高效推理的条件参数化卷积
CondConv:用于高效推理的条件参数化卷积 论文地址:https://arxiv.org/pdf/1904.04971.pdf 代码地址:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/condconv 卷积层是现代深度神经网络的基本构建模块之一。其中一个基本假设是,卷积核应该对数…...

SQL高级 --优化
一、SQL查询的解析 关联查询过多索引失效(单值、符合) 二、mysql explain使用简介 1、关于id的说明: 2 、select_type 常见和常用的值有如下几种: 分别用来表示查询的类型,主要是用于区别普通查询、联合查询、子…...
【C++】空间配置器
空间配置器,听起来高大上,那它到底是什么东西呢? 1.什么是空间配置器? 空间配置器是STL源码中实现的一个小灶,用来应对STL容器频繁申请小块内存空间的问题。他算是一个小型的内存池,以提升STL容器在空间申…...
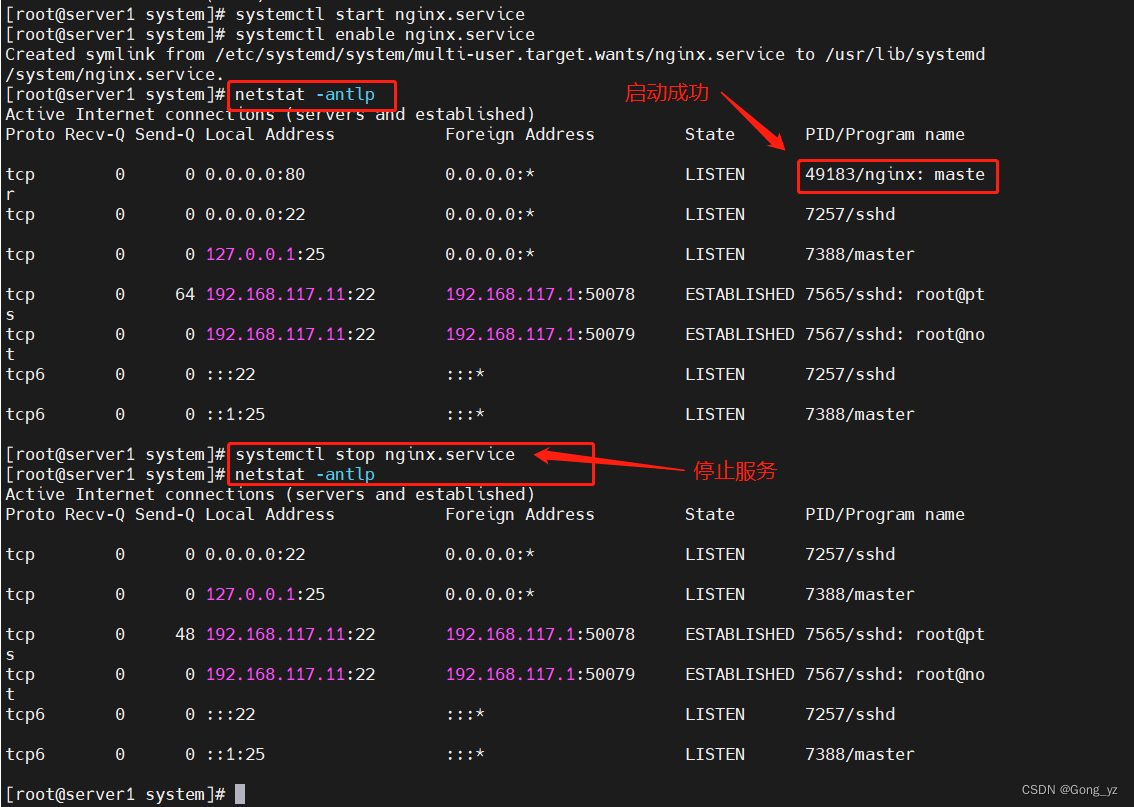
nginx的介绍及源码安装
文章目录前言一、nginx介绍二、nginx应用场合三、nginx的源码安装过程1.下载源码包2.安装依赖性-安装nginx-创建软连接-启动服务-关闭服务3.创建nginx服务启动脚本4.本实验---纯代码过程前言 高可用:高可用(High availability,缩写为 HA),是指系统无中断地执行其功…...
通过openssl生成pfx证书
通过centos7上自带的openssl工具来生成。首先创建一个pfxcert目录。然后进入此目录。 1.生成.key文件(内含被加密后的私钥),要求输入一个自定义的密码 [rootlocalhost cert]# openssl genrsa -des3 -out server.key 2048 Generating RSA priv…...
)
华为OD机试真题Python实现【敏感字段加密】真题+解题思路+代码(20222023)
敏感字段加密 题目 给定一个由多个命令字组成的命令字符串; 字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号命令字之间以一个或多个下划线_进行分割可以通过两个双引号""来标识包含下划线_的命令字或空命令字(仅包含两个双引号的命令字…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...