【数据蒸馏】静态数据蒸馏方法汇总
基于几何的方法
基于几何的方法假设在特征空间中彼此接近的数据点往往具有相似的属性。因此,基于几何的方法试图移除那些提供冗余信息的数据点,剩下的数据点形成一个核心集合S,其中jSj ≤ jTj。
Herding(聚集)
是一种基于几何的方法,它根据特征空间中核心集合的中心点与原始数据集中心点之间的距离选择数据点。该算法每次以贪婪的方式将一个样本逐步添加到核心集合中,以使两个中心点之间的距离最小化。
Herding方法的目标是构建一个代表性的数据子集,以捕捉原始数据集的基本信息。通过选择最小化与核心集合中心的距离的样本,它旨在包含最具信息量和代表性的数据点,以代表整个数据集。
Herding是基于几何的方法中的一种技术,用于数据降维或摘要。它有助于识别一个较小的数据点集合,保留原始数据集的基本特征,从而实现更高效的分析和处理,同时尽量减少信息损失。
k-Center Greedy(k-中心贪婪)
是一种解决最小最大设施选址问题(minimax facility location problem)的方法,即从完整数据集T中选择k个样本作为核心集合S,使得T中的数据点与S中最近的数据点之间的最大距离最小化:
k-Center Greedy已成功应用于广泛的领域,例如主动学和高效的GAN训练。
k-Center Greedy的目标是选择一组k个样本,使得它们能够最好地代表整个数据集,并且能够满足最小最大距离的要求。算法通过贪婪地选择距离当前核心集合最远的样本,逐步构建核心集合。
k-Center Greedy算法的优势在于它的高效性和可扩展性。它可以在大规模数据集上进行快速计算,并且可以通过调整k的值来控制核心集合的大小和代表性。这使得k-Center Greedy成为许多应用中的有用工具,特别是在需要选择一小部分样本来代表整个数据集的问题中。
不确定性方法(Uncertainty Based Methods)
在模型优化中认为,置信度较低的样本可能对模型优化的影响大于置信度较高的样本,因此应该将其包含在核心集合中。下面是给定特定分类器和训练时期的常用样本不确定性度量指标,即最小置信度(Least Confidence)、熵(Entropy)和边界(Margin)[9],其中C是类别的数量。我们按照分数的降序选择样本。
在不确定性方法中,最小置信度(Least Confidence)是指分类器对某个样本所预测的最低置信度。熵(Entropy)是在多分类问题中衡量样本预测概率分布的不确定性的度量,当分类器对某个样本的预测概率分布更平坦时,熵值越大,不确定性越高。**边界(Margin)**是指分类器对两个最高概率的类别之间的差异程度,边界越大表示分类器对某个样本的预测更加确定。
根据以上不确定性度量指标,可以按照分数的降序选择样本。也就是说,将样本按照不确定性度量的分数从高到低进行排序,然后选择分数最高的样本加入核心集合。
不确定性方法在主动学习、样本选择和数据集压缩等领域具有广泛的应用。通过选择具有较高不确定性的样本,可以提高模型的鲁棒性和泛化能力,并减少对大型数据集的依赖,从而加快模型训练和预测的速度。
误差/损失方法(Error/Loss Based Methods)
在训练神经网络时,认为对误差或损失做出更大贡献的训练样本更为重要。样本的重要性可以通过每个样本的损失或梯度,或者它对其他样本预测的影响来衡量,这些样本在模型训练过程中对其他样本预测的影响。选择具有最大重要性的样本作为核心集合。
遗忘事件(Forgetting Events)是指在训练过程中发生遗忘的次数。Toneva等人计算了在当前时期中被正确分类的样本在前一个时期中被错误分类的次数,即accti > acct+1i,其中accti表示时期t中样本i的预测的正确性(True或False)。遗忘次数反映了训练数据的内在特性,可以通过删除那些无法遗忘的样本来实现性能的最小损失。
通过基于误差或损失的方法选择样本,可以强调那些对模型训练产生更大影响的样本,提高模型对重要样本的关注度,从而提高模型的性能。此外,通过观察遗忘次数,可以了解训练数据的特点,并识别出对模型性能影响较小的样本,从而实现数据集的压缩或简化,减少模型训练和推断的计算负担。
重要性采样(Importance Sampling)中,我们定义s(x, y)为数据点(x, y)对总损失函数的上界贡献,也称为敏感性分数。可以通过以下公式表示:
s(x, y) = max [ ∀(x0, y0)∈T ] s(x0, y0) (5)
其中`(x, y)是具有参数Φ的非负代价函数。对于T中的每个数据点,被选择的概率被设置为p(x, y) = s(x, y) / Σs(x, y) (x, y)∈T。
核心集合S是基于这些概率构建的。类似的想法也在黑盒学习器(Black box learners)中提出,其中错误分类的样本将被加权或其采样概率将增加。通过重要性采样方法选择样本,可以更加有效地利用有限的计算资源,并提高对重要样本的关注度,从而加速模型训练和推断的过程。
基于决策边界的方法(Decision Boundary Based Methods)
由于决策边界附近的数据点很难被分离,因此最靠近决策边界的数据点也可以作为核心集合的一部分。
对抗性DeepFool(Adversarial DeepFool)
尽管无法准确获得到达决策边界的距离,但Ducoffe和Precioso在输入空间X中寻求这些距离的近似值。通过对样本进行扰动,直到样本的预测标签发生变化,那些需要最小对抗扰动的数据点最接近决策边界。
对比主动学习(Contrastive Active Learning)
为了找到靠近决策边界的数据点,对比主动学习(Cal)选择预测概率与其邻居之间差异最大的样本来构建核心集合。
基于决策边界的方法通过关注决策边界附近的样本,可以捕捉到类别之间的边界区域,从而更好地表示和优化模型。这些方法可以提高模型对决策边界附近样本的关注度,从而提高模型的性能和鲁棒性。
基于梯度匹配的方法(Gradient Matching Based Methods)
通常使用(随机)梯度下降算法来训练深度模型。因此,我们期望通过完整训练数据集产生的梯度P(x, y)∈T rΦ(x, y, Φ)可以用一个子集P(x, y)∈S wΦ(x, y, Φ)的(加权)梯度来替代,且二者之间的差异最小化。
最小化目标函数:
min w, S D(
1 / |T| ∑_(x, y)∈T rΦ(x, y, Φ), 1 / |w| ∑_(x, y)∈S w rΦ(x, y, Φ))
s.t. S ⊆ T, wx ≥ 0 (6)
其中,w是子集权重向量,|w|是绝对值之和,D(·, ·)是衡量两个梯度之间距离的函数。
Craig方法(Craig)
Mirzasoleiman等人试图找到一个最优的核心集合,以在最大误差"下近似完整数据集的梯度。他们将梯度匹配问题转化为一个单调子模函数F的最大化问题,并使用贪心算法来优化F。
基于梯度匹配的方法通过近似完整数据集的梯度来选择核心集合,从而减少计算和存储的负担。这些方法可以在减少数据集规模的同时,尽可能保留与完整数据集相似的梯度信息,从而提高模型在核心集合上的训练效果。
GradMatch方法
相较于Craig方法能够在保持相同梯度匹配误差"的情况下,使用更小的子集。GradMatch引入了一个带有系数的平方l2正则化项,用于惩罚给个别样本分配较大权重。为了解决优化问题,GradMatch提出了一种贪心算法——正交匹配追踪(Orthogonal Matching Pursuit),该算法可以保证在约束条件jSj ≤ k(k为预设常数)下,达到误差1-exp(−(+kr^2_max))。
GradMatch方法通过引入正则化项和贪心算法,可以在减小子集规模的同时,保持较低的梯度匹配误差。这有助于进一步减少计算和存储需求,并提高在核心集合上的训练效果。
相关文章:

【数据蒸馏】静态数据蒸馏方法汇总
基于几何的方法 基于几何的方法假设在特征空间中彼此接近的数据点往往具有相似的属性。因此,基于几何的方法试图移除那些提供冗余信息的数据点,剩下的数据点形成一个核心集合S,其中jSj ≤ jTj。 Herding(聚集) 是一…...

Cortex-A7 架构
参考《 Cortex-A7 Technical ReferenceManua.pdf 》和《 ARM Cortex-A(armV7) 编程手 册 V4.0.pdf 》 【 正点原子】I.MX6U嵌入式Linux驱动开发指南V1.6学习 1.Cortex-A7 MPCore 简介 I.MX6UL 使用的是 Cortex-A7 架构,Cortex-A7 MPcore 处理器支持 1~4 核&#…...

2023年“羊城杯”网络安全大赛 Web方向题解wp 全
团队名称:ZhangSan 序号:11 不得不说今年本科组打的是真激烈,初出茅庐的小后生没见过这场面QAQ~ D0n’t pl4y g4m3!!! 简单记录一下,实际做题踩坑很多,尝试很多。 先扫了个目录,扫出start.sh 内容如下…...

Matlab——二维绘图(最为详细,附上相关实例)
为了帮助各位同学备战数学建模和学习Matlab的使用,今天我们来聊一聊 Matlab 中的绘图技巧吧!对于 Matlab 这样的科学计算软件来说,绘图是非常重要的一项功能。在数据处理和分析时,良好的绘图技巧能够更直观地呈现数据,…...
JVM学习(四)--内存问题分析思路
linux获取jvm当前dump文件 命令行为:jmap -dump:file[文件名] [pid] 然后等待生成dump文件,生成的dump文件就在当前目录下。如下图: 然后就可以下载到本地,用本地jdk里自带的jvisualvm来解析文件。 在用本地的jvisualvm解析之前…...
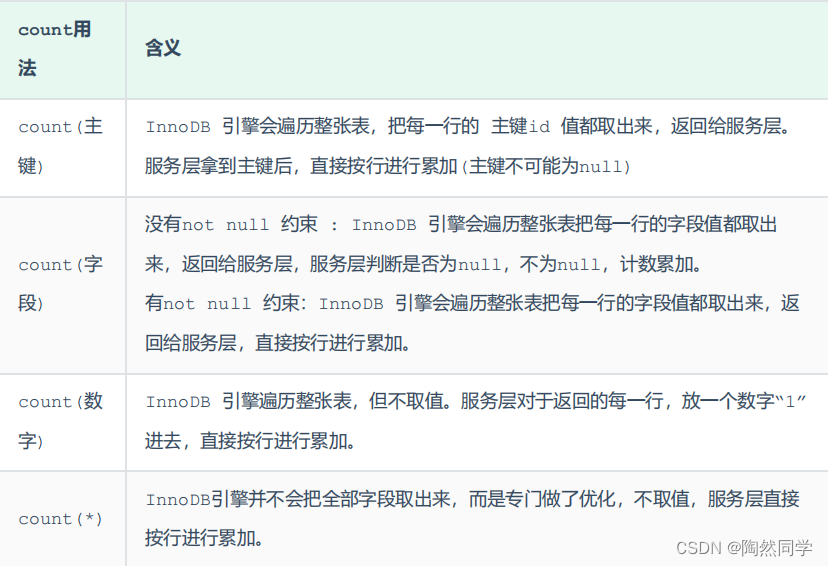
【MySQL】七种SQL优化方式 你知道几条
1.插入数据 1.1insert 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。 insert into tb_test values(1,tom); insert into tb_test values(2,cat); insert into tb_test values(3,jerry); 1). 优化方案一 批量插入数据 Insert into t…...
MySQL8.xx 解决1251 client does not support ..解决方案
MySQL8.0.30一主两从复制与配置(一)_蜗牛杨哥的博客-CSDN博客 MySQL8.xx一主两从复制安装与配置 MySQL8.XX随未生成随机密码解决方案 一、客户端连接mysql,问题:1251 client does not support ... 二、解决 1.查看用户信息 备注:host为 % …...

SpringBoot常用的简化开发注解
一、引言 在Spring Boot框架中,有许多常用的注解可用于开发项目。下面是其中一些常见的注解及其功能和属性的说明: 1、RestController RestController 是 Spring Framework 中的一个注解,用于标识一个类是 RESTful 服务的控制器。它结合了…...

python相关
1、更改用户名之后,C盘下的文件夹下名称没有改?这样设置 https://blog.csdn.net/qq_56088882/article/details/127470766 2、安装python和pycharm 链接 3、vscod中import requests出错:亲测有效: 链接...

C语言的类型转换
C语言的类型转换很重要,经常出现,但是往往不被人注意,而在汇编代码当中就暴露无遗了。 如下列代码: char ch; while ((ch getchar()) ! #) putchar(ch); 反汇编后: .text:00401006 mov…...
从零构建深度学习推理框架-11 Resnet
op和layer结构 在runtime_ir.cpp中,我们上一节只构建了input和output,对于中间layer的具体实现一直没有完成: for (const auto& kOperator : this->operators_) {if (kOperator->type "pnnx.Input") {this->input_o…...

多线程练习-顺序打印
wait和notify的使用推荐看通过wait和notify来协调线程执行顺序 题目 有三个线程,线程名称分别为:a,b,c。 每个线程打印自己的名称。 需要让他们同时启动,并按 c,b,a的顺序打印 代码及其注释…...
)
一文读懂MQTT各参数定义(非ChatGPT生成版)
文章目录 前言主流使用MQTT协议的云平台连接参数连接参数详解1.服务器地址(Server Address)2.端口(Port)3.客户端标识符(Client Identifier)4.用户名和密码(Username and Password)5…...

redis-lua脚本-无参-比较2个数值
以下是演变的过程: eval " return haha " 0 eval " local res haha; return res; " 0 eval " local value1 redis.call(get,value1); local value2 redis.call(get,value2);return value1; " 0 eval " return 1 < 2;…...
Lesson5-1:OpenCV视频操作---视频读写
学习目标 掌握读取视频文件,显示视频,保存视频文件的方法 1 从文件中读取视频并播放 在OpenCV中我们要获取一个视频,需要创建一个VideoCapture对象,指定你要读取的视频文件: 创建读取视频的对象 cap cv.VideoCapt…...

Lesson5-2:OpenCV视频操作---视频追踪
学习目标 理解meanshift的原理知道camshift算法能够使用meanshift和Camshift进行目标追踪 1.meanshift 1.1原理 m e a n s h i f t meanshift meanshift算法的原理很简单。假设你有一堆点集,还有一个小的窗口,这个窗口可能是圆形的,现在你可…...

1778_树莓派系统安装
全部学习汇总: GitHub - GreyZhang/little_bits_of_raspberry_pi: my hacking trip about raspberry pi. 一段视频学习教程的总结,对我来说基本上用处不大。因为我自己的树莓派简简单单安装完就开机成功了,而且实现了很多视频中介绍的功能。 …...
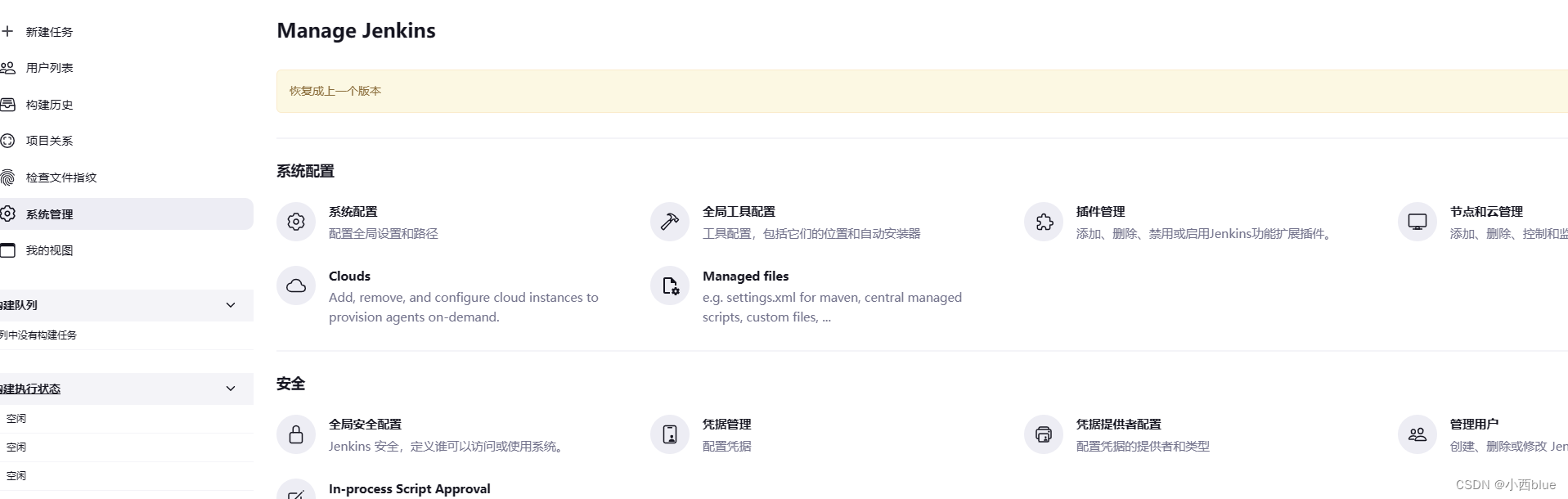
关闭jenkins插件提醒信息
jenkins提醒信息和安全警告可以帮助我们了解插件或者jenkins的更新情况,但是有些插件是已经不维护了,提醒却一直存在,看着糟心,就像下面的提示 1、关闭插件提醒 找到如下位置:系统管理-系统配置-管理监控配置 打开管…...
JixiPix Artista Impresso Pro for mac(油画滤镜效果软件)
JixiPix Artista Impresso pro Mac是一款专业的图像编辑软件,专为Mac用户设计。它提供了各种高质量的图像编辑工具,可以帮助您创建令人惊叹的图像。该软件具有直观的用户界面,使您可以轻松地浏览和使用各种工具。 它还支持多种文件格式&…...
机器学习之 Jupyter Notebook 使用
🎈 作者:Linux猿 🎈 简介:CSDN博客专家🏆,华为云享专家🏆,Linux、C/C、云计算、物联网、面试、刷题、算法尽管咨询我,关注我,有问题私聊! &…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

别只盯着主控芯片!拆解STM32最小系统板:电源、时钟、复位三大支柱电路深度解析
STM32最小系统板设计进阶:电源、时钟与复位电路的工程实践 在嵌入式系统开发中,我们常常将注意力集中在主控芯片的功能实现上,却忽略了支撑系统稳定运行的三大基础电路——电源、时钟和复位。这些看似简单的电路模块,实则是整个系…...
)
Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践)
更多请点击: https://codechina.net 第一章:Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践) Lindy效应在自动化系统设计中揭示了一个关键洞察:越久经考验的实践,其未来预期寿命越长。Lindy多步…...

MT-R1-Zero:基于强化学习的机器翻译范式革新与实战指南
1. 项目概述:当强化学习遇上机器翻译 在机器翻译这个老牌的自然语言处理任务里,我们似乎已经习惯了“数据驱动”的剧本:收集海量的双语平行句对,用它们来监督训练模型,让模型学会从源语言到目标语言的映射。这套方法&a…...