一、了解[mysql]索引底层结构和算法
目录
- 一、索引
- 1.索引的本质
- 2.mysql的索引结构
- 二、存储引擎
- 1.MyISAM
- 2.InnoDB
- 3.为什么建议InnoDB表要建立主键并且推荐int类型自增?
- 4.innodb的主键索引和非主键索引(二级索引)区别
- 5.联合索引
一、索引
1.索引的本质
索引:帮助mysql高效获取数据并排好序的数据结构。
简单举例,我们把一串数据保存到mysql表中的格式如下。
mysql数据保存到磁盘时,每条数据保存的位置并不一定是连续的磁盘地址进行保存的,即mysql表中相邻的两条数据,对应的磁盘地址不一定相邻。
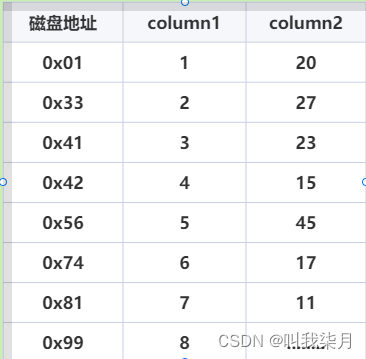
执行一条查询语句
SELECT * FROM TABLE WHERE TABLE.column2 = 15
在没有索引的情况下,他是在全部表数据的范围内开始查找了,从第一条column2为20开始逐条向下找,直到找到15为止。每次查询一条记录时就去和磁盘做一次I/O操作,把存在磁盘中的数据读取出来,那么如果数据量很大时,需要磁盘I/O的次数可能会非常的多,性能不高并且效率非常的低。
基于这种场景,我们就可以设计一个简单的索引,来解决这种问题。把这些数据保存到一个二叉树中(mysql并没有使用二叉树作为索引存储结构这里只是举例)。
二叉树中,每个根节点大于左子节点,小于右子节点。
按照这个规律,查找15时,先比较根节点20,15<20,那么去根节点的左边继续查找,节点15,15等于15。查找两次就找到了。
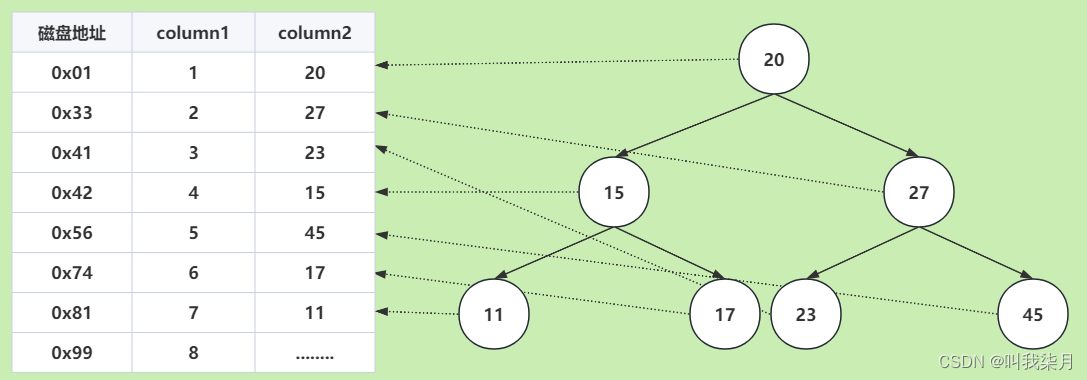
2.mysql的索引结构
那么mysql为什么没有采用二叉树呢?
我们这时来看一下表中第一列的数据,它从1开始值是连续递增的。按照上边的逻辑节点大于左子节点小于右子节点的值。
数据结构演示网站
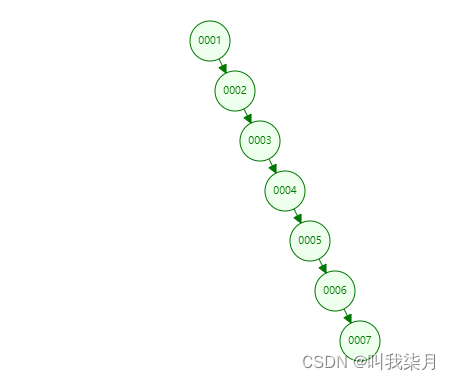
这样就变成了一个链表了,此时查找某个值的时候,又变成全表扫描了。
那能不能改进成红黑树呢?
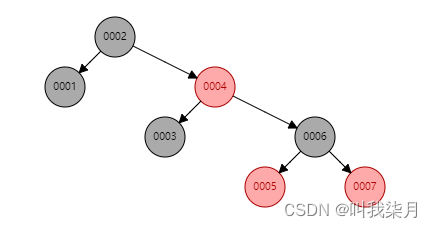
那虽然不会变成链表,但是实际情况下,mysql表中保存的数据不可能就只有几条数据,可能有几万,几十万甚至更多的数据,此时使用红黑树那么树的高度可能会非常的高。如果有100w数据,假设树的高度为50层,如果要查找的数据在这颗树的叶子节点,那么需要查找的次数就为50次。所以说在数据量特别大的情况下红黑树解决的效果就非常的局限了。数越高需要查找的次数就越多,即I/O次数就越多,效率就越低。
那能不能控制一树的高度,不要让他这么高呢?
那就有必要稍微了解一下B树结构了。百度百科
=》了解完B树,这里再来举个例子。《=
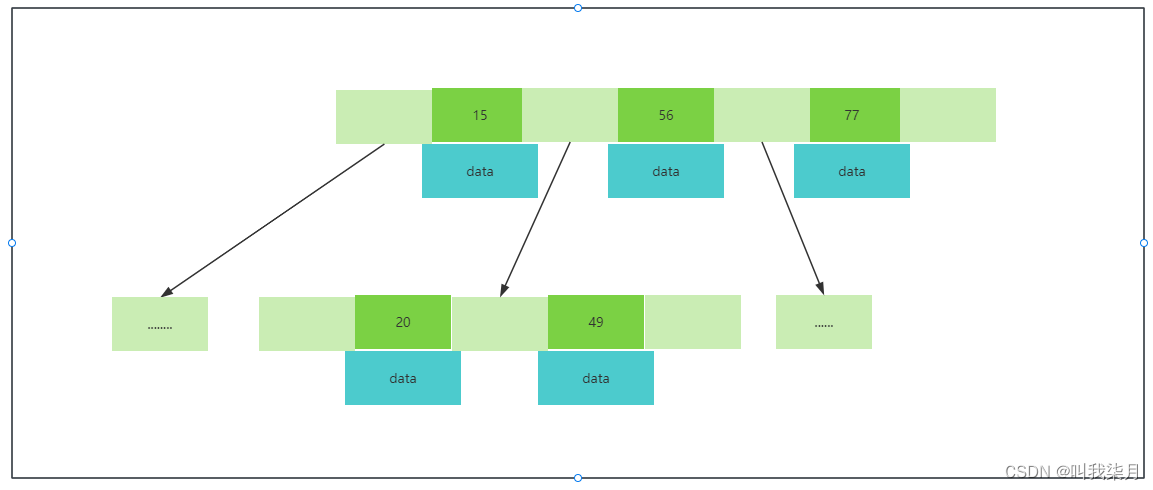
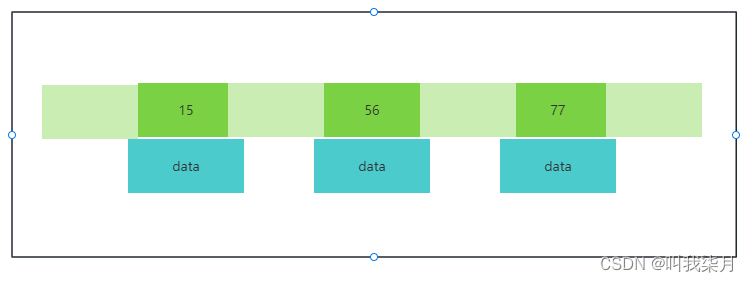
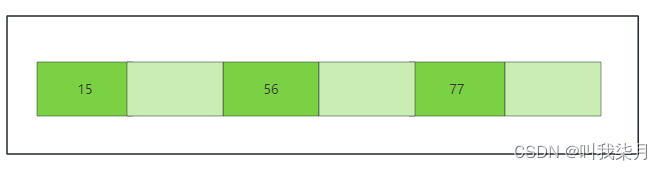
一个节点指定是:
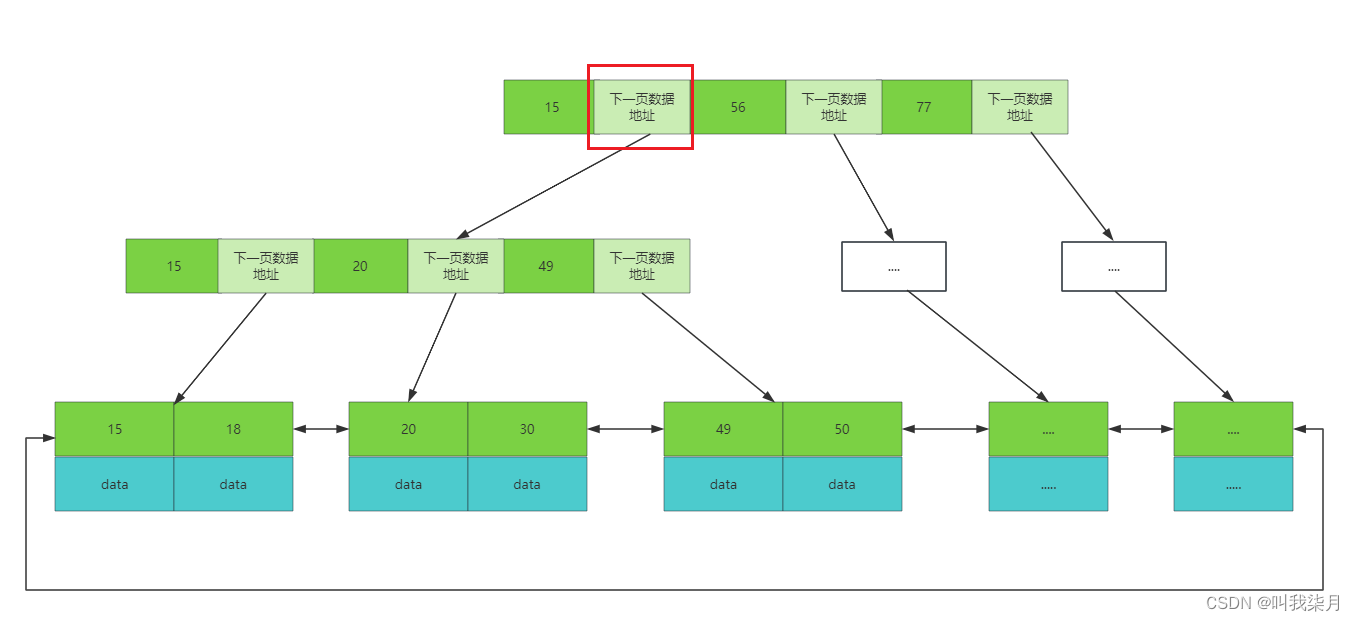
上图中,每个节点都是按照从左到右值依次递增的,所有的元素不会重复,叶节点具有相同深度,叶节点的指针为空。假设深绿色有数值的部分代表mysql表中第一列的值把他理解成id列,下方data保存了它所有对应的数据,即一个id对应的一行数据的所有内容,拿15来举例,15下的data部分a保存的是它15这个值下对应的相关信息。这种数据结构就解决了红黑树的树高度问题,但是实际上mysql也没用采用这种数据结构。而是对它进行了改造,也就是B+树。
=》B+树举例。《=
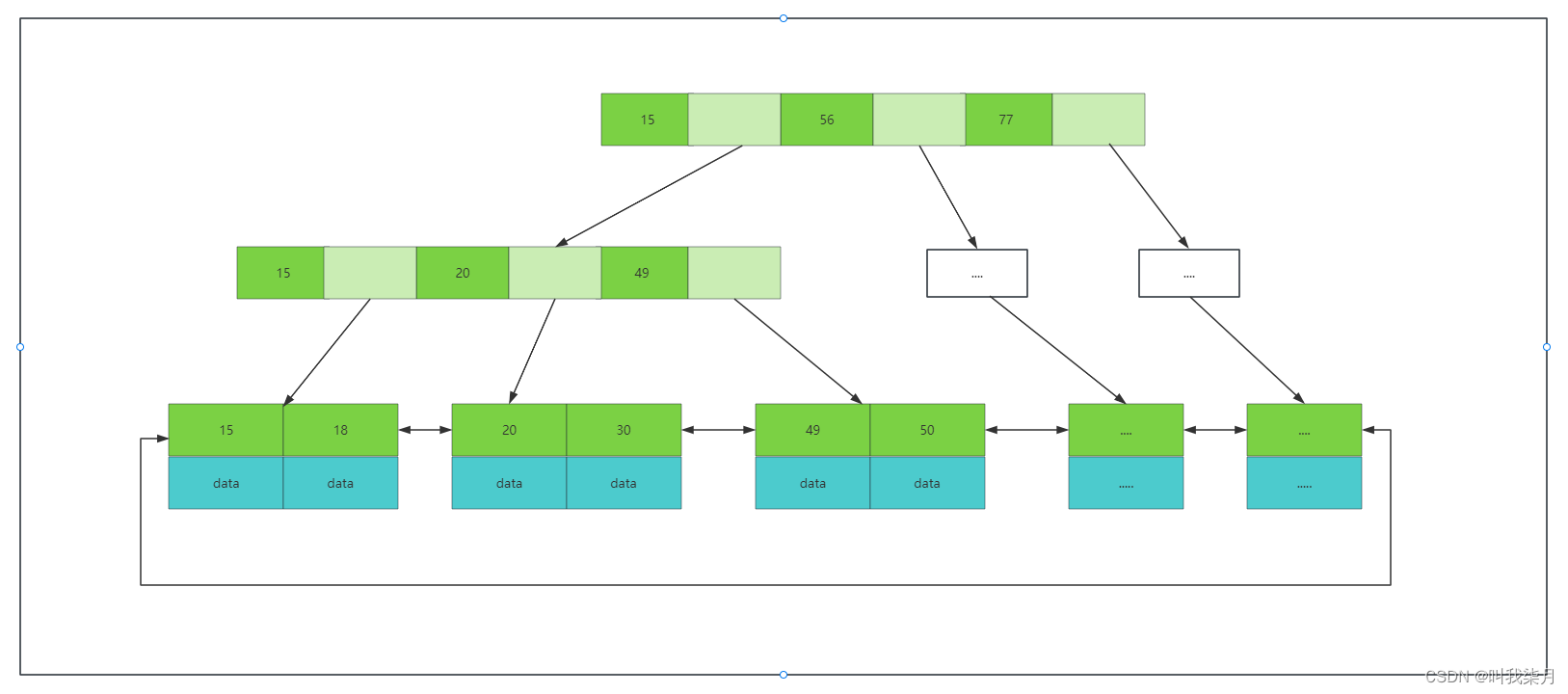
B+树:非叶子节点不存data,只存索引(冗余数据),这样可以放更多的索引。叶子节点包含所有的索引字段。叶子节点用指针连接,提高区间访问的性能。
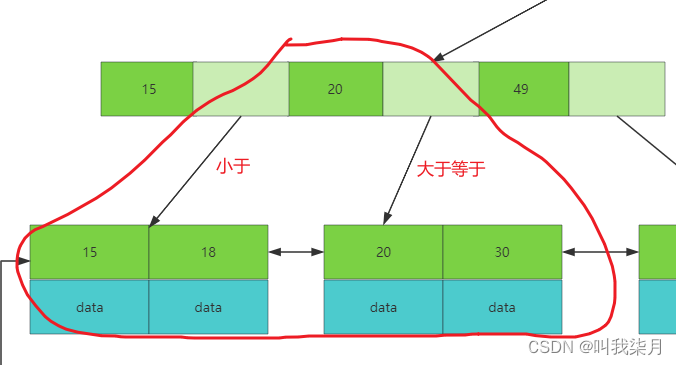
B+树每个节点中的值,拿下图举例,当二叉树来理解,即20这个节点做子树的值都是小于20,右子树的值,都是大于等于20。
B+树的叶子节点相邻节点直接是有指针相连的,并且值从左往右依次递增的,也就是排好序的。
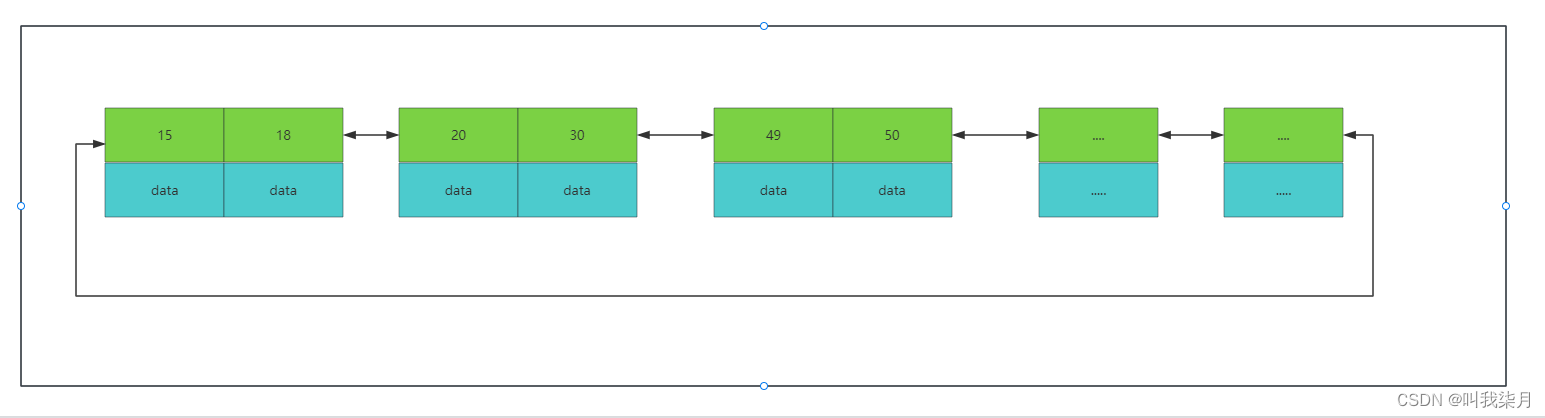
B+树中的一个节点其实就是mysql中一页。mysql中默认一页数据的大小为16KB。(这个大小可以改,但是不建议去改,mysql为啥要定16它肯定是经过理论测试等等过程之后得出来的,是符合大多数场景的。)
这时,淡绿色代表的是下一页数据的地址。
然后我们要查找一个值的时候,比如50,mysql每次会把一页数据加载到内存,因为一页数据即B+树的一个节点,节点里的值都是排好序的,所以可以通过查找算法来进行查找,例如通过二分查找算法去查找,最终找到或者未找到。找到50时,这里的data可能保存的是这个记录对应的所有行数据,也可能是一个地址(这个其实取决于索引的类型和存储引擎这里说的是innodb引擎,下边会讲到)。
这时,我们就能大概算出每个节点能保存多少数据了。一页数据中是由具体的数据和下一页数据地址为单位组成的。

假设15为int类型,mysql中int类型占4个字节的话,下一页地址占大约6个字节。
16KB * 1024 = 16384字节。
16384 / (4+6) ≈ 1638
所以保存int类型的数据,一页大概能保存1638个。如果B+树为三层,那么能保存多少数据呢?
叶子节点一页16Kb一页数据,里边放了不止int这个值,还有data数据。叶子节点每个估计能放16条数据的话。总共能放多少数据呢?
1638 * 1638 * 16 = 42928704 (4千多万)。4千多万树的高度才三层。大大减少 了I/O操作次数。
所以说如果查找数据时走索引查找数据效率是非常高的,而且根节点中的数据是常驻内存中的。
为什么mysql在B和B+树中,最终选择B+树?
如果B树保存int类型的数据。因为B树每个节点下每个int对应的数据是都保存起来的。按照一个节点16Kb大小,一个节点能保存16条数据来算的话,保存4千多万的数据,最终B树能多高呢?
16 * 16 * 16 * …=4千万。
需要乘多少个16,就有少层的高度,结果显而易见。
而B+树的树的高度,取决于非叶子节点每个节点能放多少索引数据(多少个int值),放的越多高度就会越低。所以为什么只有叶子节点存data。其它存的只是索引数据。
当然mysql不止这一种数据结构的索引还有HASH类型的索引。
二、存储引擎
1.MyISAM
MyISAM索引文件和数据文件是分离的(非聚集),请看下面讲解。
我们知道mysql中的数据是存在磁盘中,那么具体在哪个地方呢?
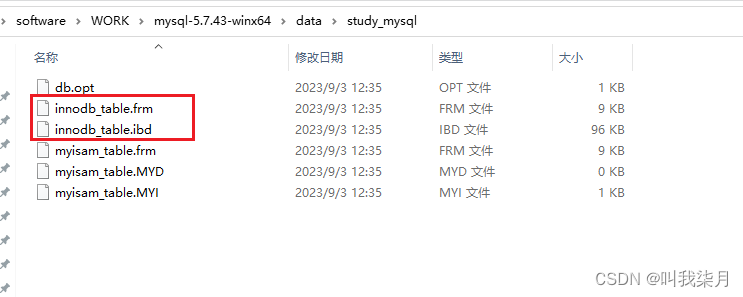
我们有一个数据库:study_mysql
库中有两个表,其中myisam_table存储引擎为MyISAM
CREATE TABLE `myisam_table` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
如果没有修改mysql配置的话,默认是把这些数据库和表保存到data文件夹下的。
下图三个文件对应myisam_table表相关文件。
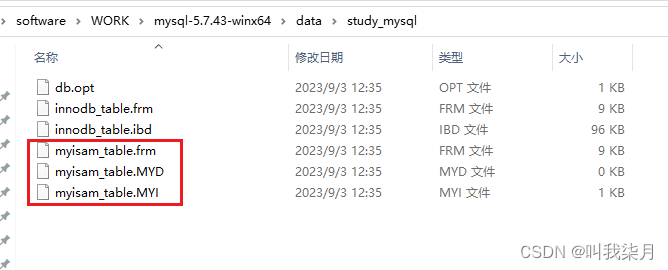
其中
- .frm保存的是表的结构数据。
- .MYD保存的表数据。
- .MYI保存的表索引数据。
=》MyISAM数据保存和查询举例。《=
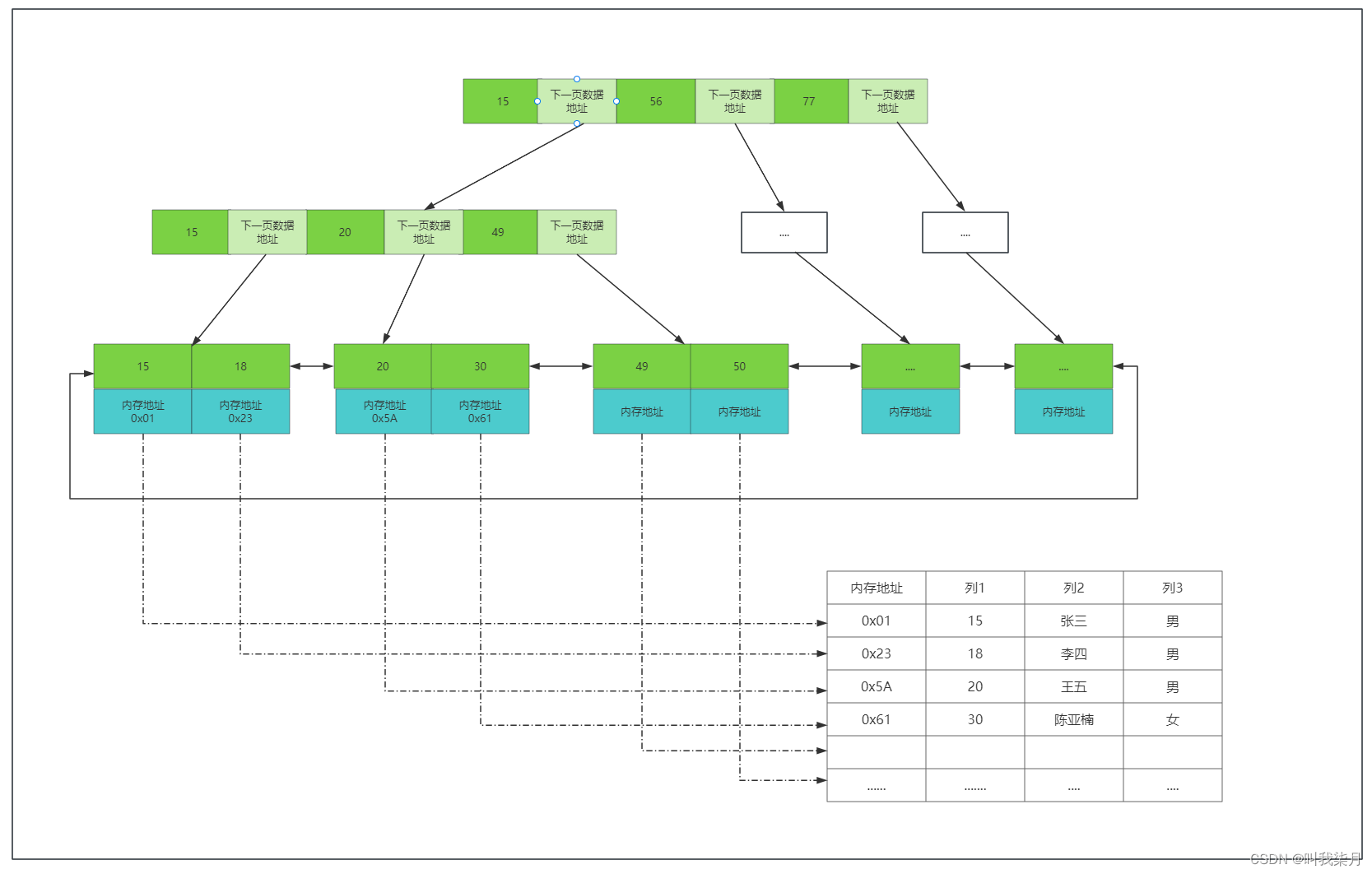
数据也就是下方表格的内容,保存在.MYD文件中。
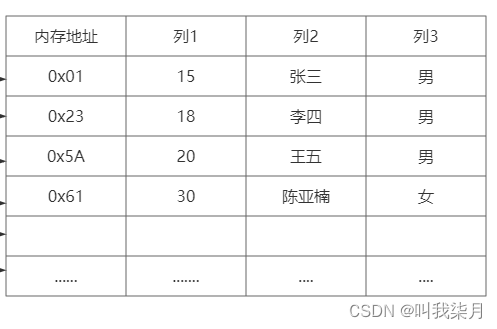
索引也就是B+树的数据保存在.MYI文件中。
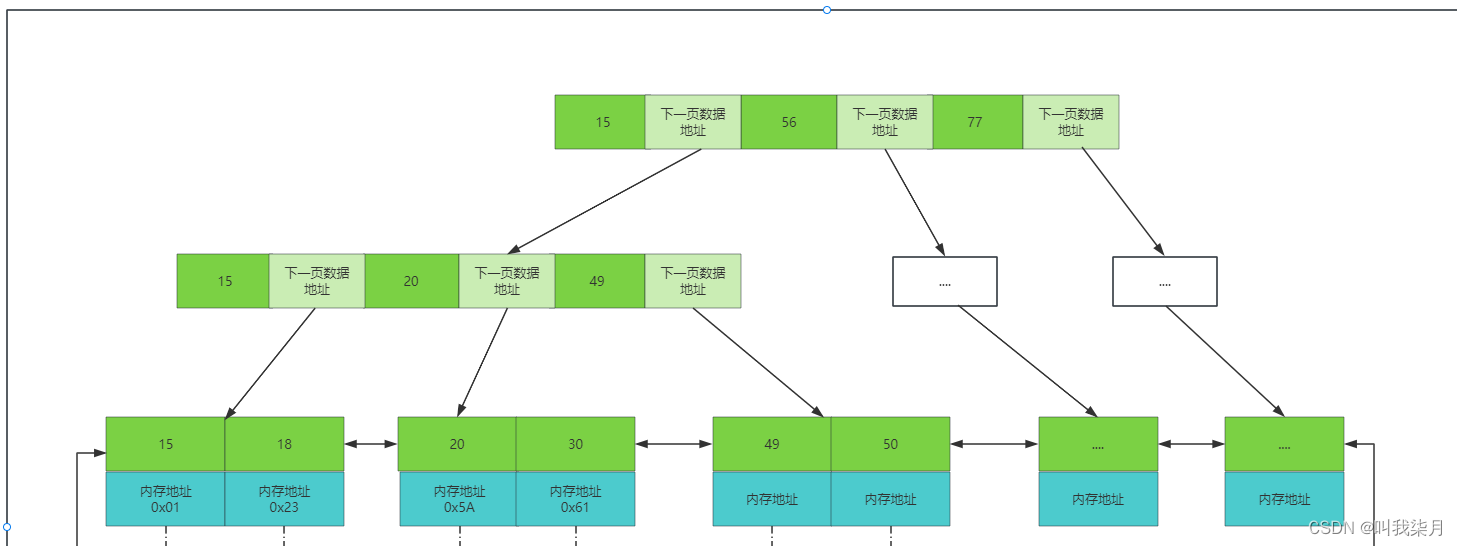
如果要查询列1的值等于30的内容,那么首先去.MYI文件中查找30,然后在根据叶子节点保存的内存地址,再去.MYD文件找到他对应的数据。
非聚集索引:简单理解为叶子节点没有保存索引对应的所有数据内容。请结合下方innodb理解。
2.InnoDB
了解MyISAM的数据保存和读取之后,对于非聚集的概念应该多少有点理解了。
表设置为innodb引擎:
还是study_mysql库
库中有两个表,其中innodb_table存储引擎为InnoDB
CREATE TABLE `innodb_table` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
其中
- .frm保存的是表的结构数据。
- .ibd保存的是索引和数据。
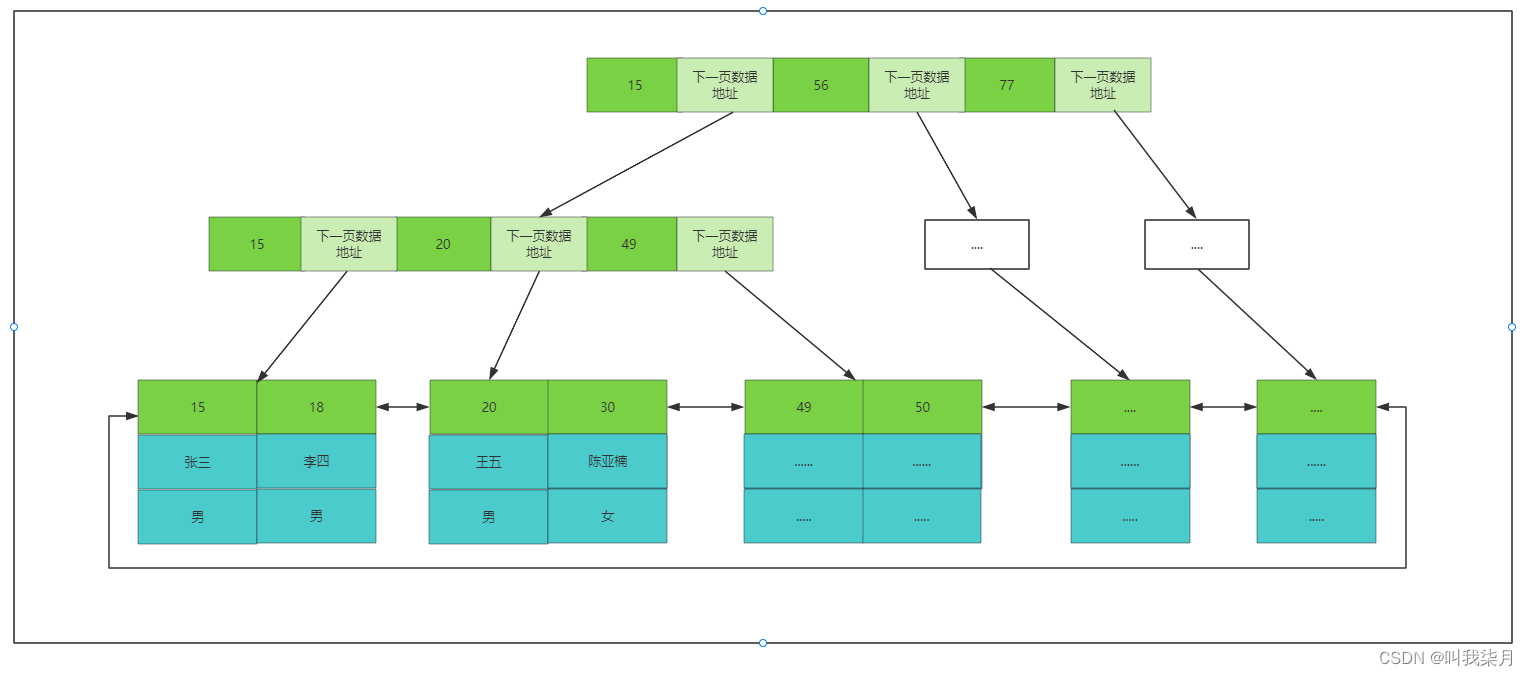
表数据文件本身就是按照B+树组织的一个索引结构文件
聚集索引(聚簇索引,主键索引):叶子节点本身包含了完整的数据记录。
之前有说过叶子节点可能保存的不是所有数据,可能是数据所对应的磁盘地址。其实innodb非主键索引,叶子节点保存得是主键内容,如果叶子节点保存的是全部数据那么就是聚集索引。反之叶子节点只包含主键数据的,称为非聚集索引。MyISAM的主键索引和非主键索引都是一样的。
3.为什么建议InnoDB表要建立主键并且推荐int类型自增?
如果创建表时指定了主键,那么mysql在构造B+树时就可以根据你的主键去维护这个B+树的结构。如果你没指定主键,那么mysql就会从你表中的所有列中找到一列,这列中的值都不重复,如果没有找到则它会自己创建一个隐藏的列,这个隐藏的列会和你表中的数据对应起来,使用隐藏列去构造这个B+树。
那你可能有几个疑问:
1.为啥mysql能做,我还要自己去建主键呢?
其实你这么理解本来干一个事情,你事先准备好沟通好开始去干,可能就只需要等2小时。同一件事你懒得去沟通,导致后续需要额外的1小时来处理你预期想要的东西,总共用了3小时。现在无论是企业还是个人都注重效率,那么为啥不能一个主键能解决的事情还要让程序额外帮你搞呢?当然针对是这个场景。其他情况可能就是得需要程序搞来提高我们的效率,不要过度理解。
2.为啥推荐int类型呢?
你想想你学过的查找算法,大部分场景是不是都是数字之间的比较。如果是字符串之间比较,你还需要把字符串每位的ASCII码值计算出来,最后根据整体的值比大小,这又和上边说的有点像了,本来2小时能完成,你非要干3小时。虽然性能影响不会非常大,不然mysql估计也不会让你设置成字符串类型。当然这里还是推荐int,如果说非要有个场景就需要字符串类型,那就是你把控了,决定权在你。
3.为啥要自增呢?
演示地址
还是那个网站,你们可以自己感受一下,插入连续递增的数据和插入有大有小的数据,不是递增的数据。看下一这个过程。
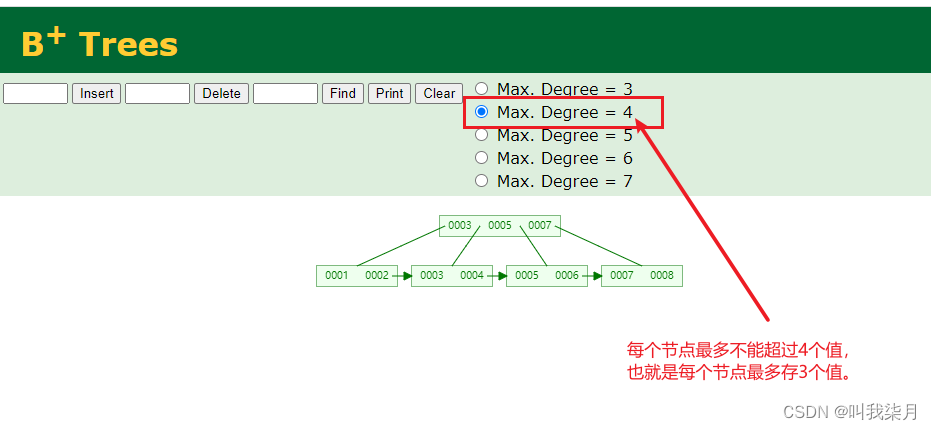
这个过程,你可以看出,如果是自增的话,它只需要在最后一个节点插入,放不下的时候,在后边追加一个节点,并且维护一下上一个节点的值。如果不是自增的话,你往3和4中间插入一个3.5那么就不止是后边追加,可能要分裂还要平衡等。效率是没有自增的高。
4.innodb的主键索引和非主键索引(二级索引)区别
innodb的表,每张表只有一个主键索引,就是叶子节点存放了所有数据内容的索引。
非主键索引,叶子节点只放了对应的主键内容。根据指导的字段建立的索引,比如根据名称列创建的索引。
通过name查询时,走的二级索引,最终找到name对应的主键就,然后再去主键索引里找到他对应的这一行所有数据。也就是我们常说的回表,就是通过二级索引找到id,然后在去根据id查询对应的内容。(这里举例是单值索引,就是一个字段建立一个索引,不推荐建立很多单值索引,这里只是举例。)
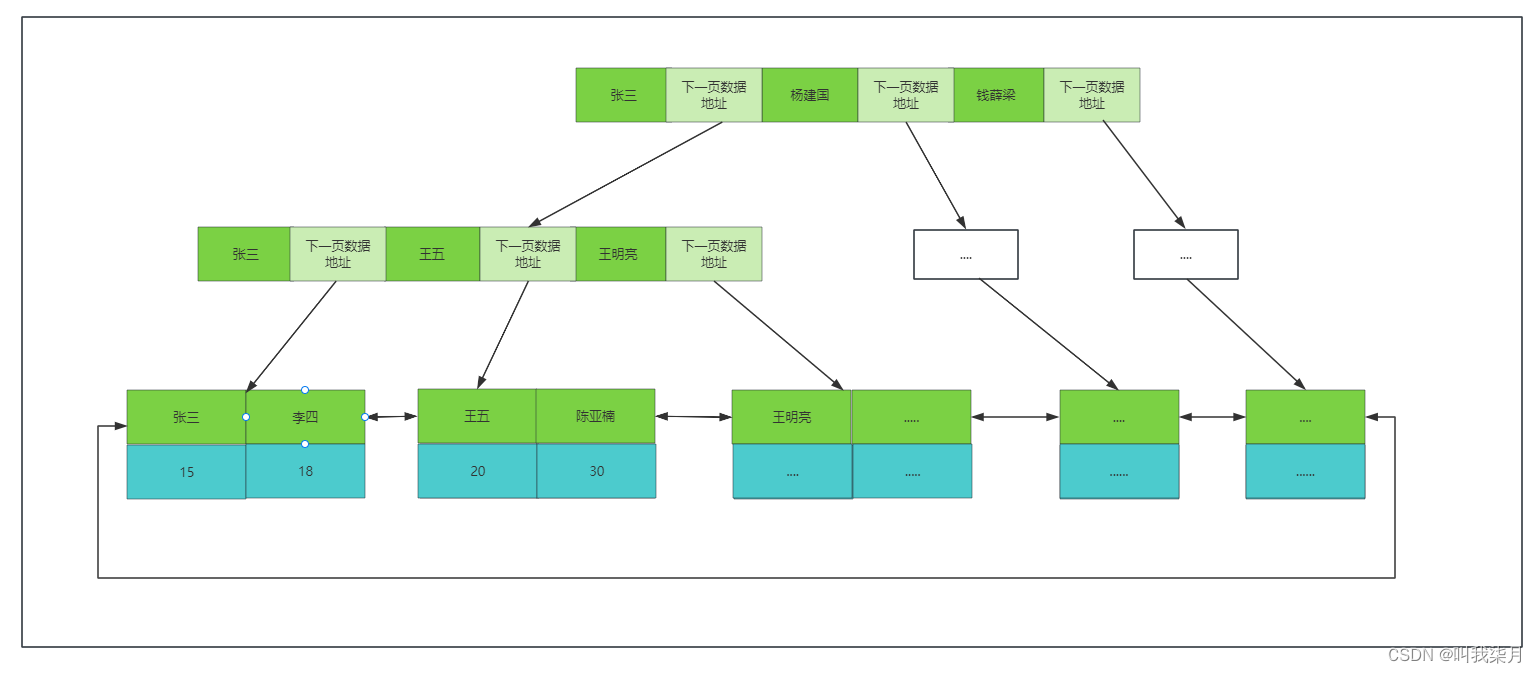
为什么二级索引只存主键信息呢?为啥不把数据全放在叶子节点呢?
- 节省空间,如果你的表数据很多,又多个二级索引那么这么多重复的数据是非常占空间的。
- 保持一致性,你插入一条数据所有的索引都需要维护数据,如果只有主键索引维护,减少了部分维护成本
5.联合索引
1.联合主键结构
可以理解为有一张雇员表,有name,age,job,join_time这几列,其中name,age,job作为联合主键。
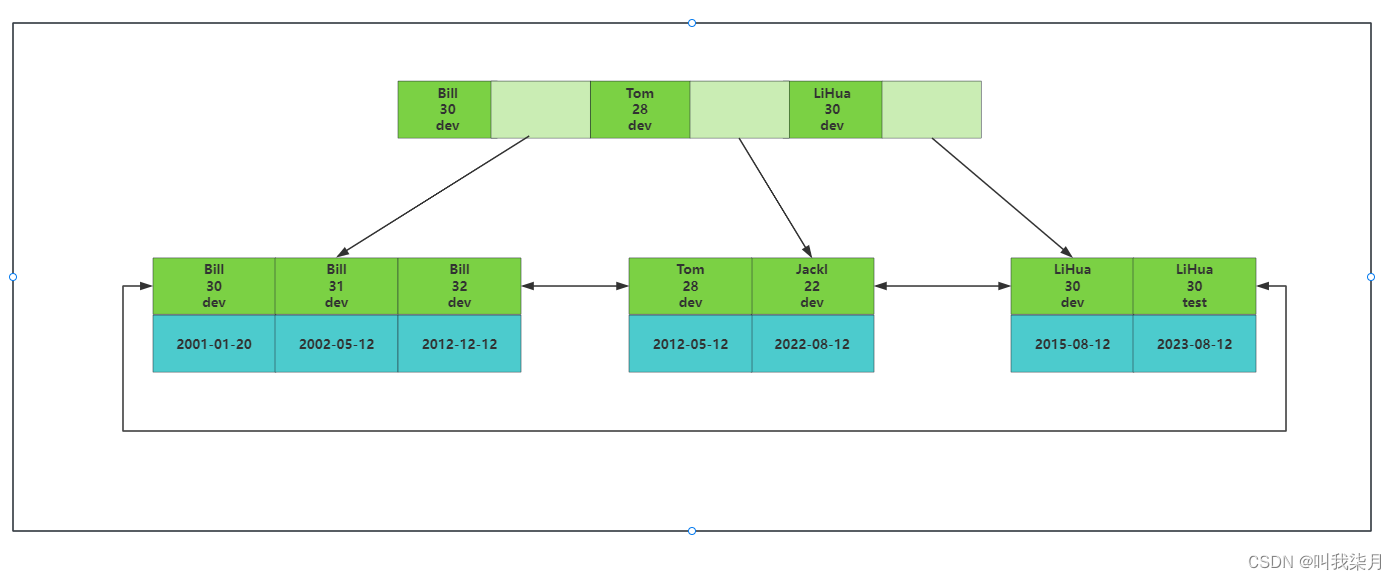
那么叶子节点就是存的join_tiem的数据。
2.联合索引结构(非联合主键)
如果是根据列 name,age,job创建的二级索引,那么结构如下。叶子节点的值为主键信息。
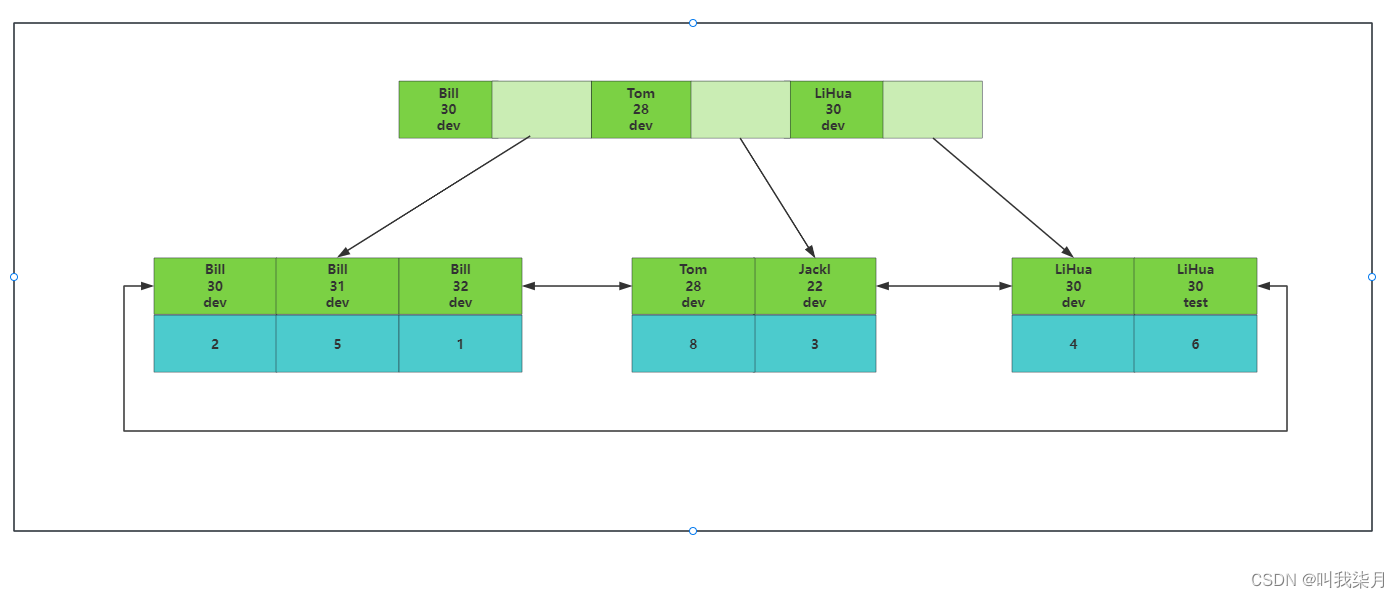
这里有一个最左前缀的内容。
即你创建索引的时候
KEY `idx_name_age_job` (`name`,`age`,`job`)
根据你指定的字段,优先级按照你指定列的左边第一列开始,先按照name排序,如果值相同,按照第二列age排序,以此类推。也就是上图的内。
=》索引最左前缀举例《=
1.
select * from table where name = 'Tom' and age = 19
2.
select * from table where age = 19
3.
select * from table where age = 19 and job = 'dev'
4.
select * from table where job = 'dev'
上述4条语句那些会走索引,那些不会走索引。(这里的索引时上图中的联合索引)
结果:只有第一条会走索引。
为什么只有第一条走索引呢?
因为你的索引创建规则是按照name,age,job的优先级创建的,
首先,我根据name能找到一个范围,这个范围里的数据都是Tom的。
其次,在这个范围中,age也是有序的,所以在这个范围进一步跟进age进行筛查,把范围进一步缩小。
最后,缩小之后的范围就是我们要的全部数据了。
其他情况:
拿2.select * from table where age = 19举例。
你直接查age=19。
此时age在索引中保存的是无序的。为什么这么说呢?你明明说的是根据优先级排序的啊,age的优先级排第二。这个是没错的,那他这age是不是相对于name这个字段是有序的,但是思考一下基于全表他还有序吗?
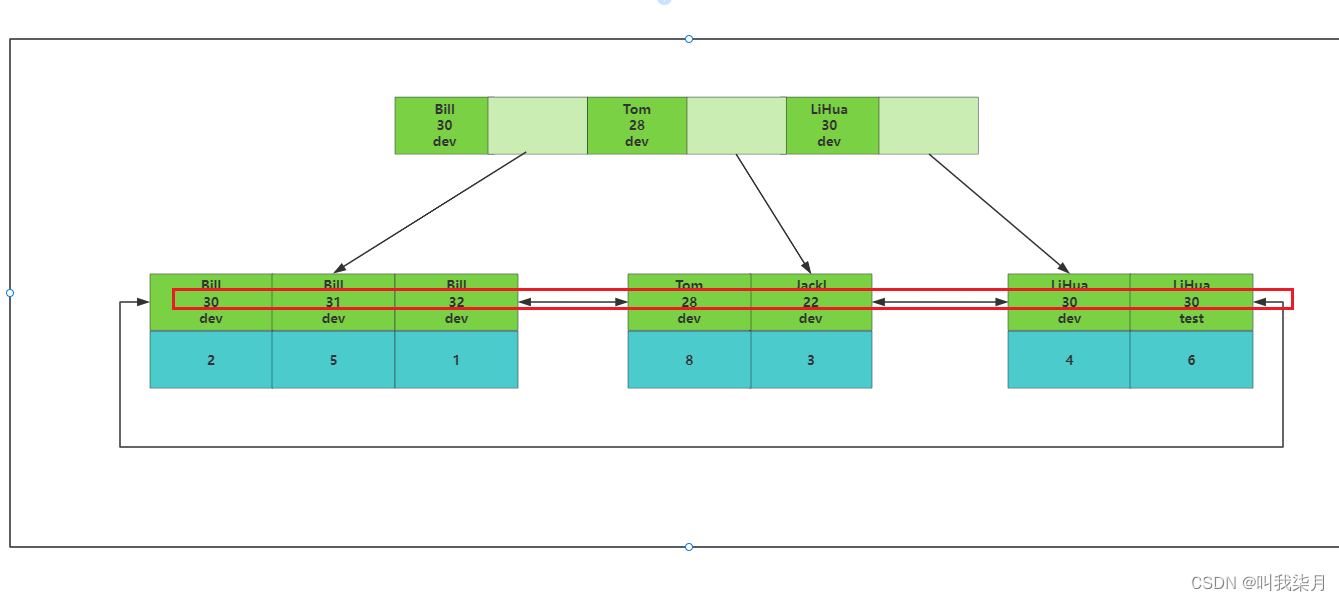
结果显而易见,基于全表是无序的,基于name是有序的。所以只能去表中一个一个找,不会走这个索引的。其他的sql也是这个道理。你没办法一步一步的缩小范围,或者你一开始就没办法限定一个范围。那么你就只能全表扫描,那就不走索引了。
相关文章:
一、了解[mysql]索引底层结构和算法
目录 一、索引1.索引的本质2.mysql的索引结构 二、存储引擎1.MyISAM2.InnoDB3.为什么建议InnoDB表要建立主键并且推荐int类型自增?4.innodb的主键索引和非主键索引(二级索引)区别5.联合索引 一、索引 1.索引的本质 索引:帮助mysql高效获取数…...

DockerFile常用命令
以下是常见的Dockerfile命令: FROM:FROM命令用于指定基础镜像。基础镜像是构建镜像的起点。例如,FROM ubuntu:latest表示使用最新版本的Ubuntu作为基础镜像。 MAINTAINER:MAINTAINER命令用于指定镜像的维护者信息。一般格式为&am…...

Android 动画之插值器PathInterpolator
Android 的View动画、属性动画都可以设置动画插值器,以此来实现不同的动画效果。 这篇文章 Android View动画整理 有介绍各种插值器的效果,这一篇专访 PathInterpolator 。 参考官网 添加曲线动作 , PathInterpolator 基于 贝塞尔曲线 或 …...

递归学习(转载)
转载至 https://www.cnblogs.com/king-lps/p/10748535.html 为避免原文丢失,因此原文转载作者【三年一梦】的帖子 前言 相信不少同学和我一样,在刚学完数据结构后开始刷算法题时,遇到递归的问题总是很头疼,而一看解答,…...

python接口自动化(二)--什么是接口测试、为什么要做接口测试(详解)
简介 上一篇和大家一起科普扫盲接口后,知道什么是接口,接口类型等,对其有了大致了解之后,我们就回到主题-接口测试。 什么是接口测试 接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各…...
)
HashMap源码阅读(一)
HashMap继承抽象类AbstractMap,AbstractMap抽象类实现了Map接口 一、HashMap中的静态常量 //默认初始容量 static final int DEFAULT_INITIAL_CAPACITY 1 << 4; // aka 16 //最大长度 static final int MAXIMUM_CAPACITY 1 << 30; //负载因子&#…...

C语言:动态内存(一篇拿捏动态内存!)
目录 学习目标: 为什么存在动态内存分配 动态内存函数: 1. malloc 和 free 2. calloc 3. realloc 常见的动态内存错误: 1. 对NULL指针的解引用操作 2. 对动态开辟空间的越界访问 3. 对非动态开辟内存使用free释放 4. 使用free释…...

Lua - 替换字符串中的特殊字符
//替换指定串 s string.gsub("Lua is good", "good", "bad") print(s) --> Lua is bad//替换特殊字符 a "我们使用$"; b string.gsub(a, "%$", "RMB"); print(b) --> 我们使用RMB//替换反斜杠 path …...

按钮控件之3---QRadioButton 单选按钮/单选框控件
本文详细的介绍了QRadioButton控件的各种操作,例如:QRadioButton分组、默认选中、禁用启用、重置样式等操作。 一、QRadioButton部件提供了一个带有文本标签的单选框(单选按钮)。QRadioButton是一个可以切换选中(chec…...

基于STM32设计的游戏姿态数据手套
基于STM32设计的游戏姿态数据手套 一、项目背景 随着虚拟现实技术的发展,人机交互越来越朝着多通道、自然化的方向发展,由原来的以机器为中心向以人为中心发展。按照行业通用用途设计的高端数据手套,可以用于测量人手指动作,如搓捻、对掌等动作,广泛应用于人手的运动捕捉…...

react跳转页面redux数据被清除
关键代码如下,页面中有根据redux中state展示的数据,然后在组件卸载的时候会清空redux中存的数据,点击a标签可以打开新的标签页,如下代码会在打开新的标签页,组件卸载,清空redux数据,页面展示的也…...

Spring Cloud 微服务2
Eureka 注册中心,服务的自动注册、发现、状态监控 Ribbon 负载均衡,Eureka中已经集成了负载均衡组件 Hystrix 熔断器,用于隔离访问远程服务、第三方库,防止出现级联失败。 Feign 远程调用,将Rest的请求进行隐藏&a…...
(传统c++语法,类内容))
侯捷课程笔记(一)(传统c++语法,类内容)
侯捷课程笔记(一)(传统c语法,类内容) 2023-09-03更新: 本小节已经完结,只会进行小修改 埋下了一些坑,后面会单独讲或者起新章节讲 最近在学习侯捷的一些课程,虽然其中大部…...

自动化安装Nginx脚本:简化您的服务器配置
在如今的网络世界中,Nginx作为一款高性能的Web服务器和反向代理服务器,扮演着至关重要的角色。然而,手动安装和配置Nginx可能会耗费大量时间和精力,特别是对于那些对Linux系统不太熟悉的人来说。幸运的是,我们为您带来…...

通过es索引生命周期策略删除日志索引
通过es索引生命周期策略删除日志索引 在es 7.x版本之后,多了个索引生命周期的概念,可以一系列的设置,给新生成的索引绑定生命周期策略,到期后,索引自动删除。 也可以通过linux定时任务实现,请查看另一篇文章…...
网络实验 VlAN 中 Trunk Access端口的说明及实验
网络实验 VlAN 中 Trunk Access端口的说明及实验 VlAN 虚拟局域网技术Access端口 工作原理Trunk端口 工作原理简单实验(一)划分不同Vlan,实现vlan内部通信拓朴图主机IP 配置划分Vlanping 测试 (二)跨交换机实现VLAN间通…...
打包个七夕exe玩玩
前段时间七夕 当别的哥们都在酒店不要不要的时候 身为程序员的我 还在单位群收到收到 正好后来看到大佬些的这个 https://www.52pojie.cn/thread-1823963-1-1.html 这个贱 我必须要犯,可是我也不能直接给他装个python吧 多麻烦 就这几个弹窗 好low 加上bgm 再打包成…...

ReactNative 井字游戏 实战
效果展示 需要的插件准备 此实战项目需要用到两个插件。 react-native-snackbar 底部信息提示组件。 react-native-vector-icons 图标组件。 安装组件: npm i react-native-snackbar npm i react-native-vector-icons npm i types/react-native-vector-icons /…...

五-垃圾收集器G1ZGC详解
回顾CMS垃圾收集器 G1垃圾收集器 G1是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量处理的机器。以及高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征 物理上没有明显的物理概念,但是逻辑上还是有分代概念 物理上分…...
opencv入门-Opencv原理以及Opencv-Python安装
图像的表示 1,位数 计算机采用0/1编码的系统,数字图像也是0/1来记录信息,图像都是8位数图像,包含0~255灰度, 其中0代表最黑,1代表最白 3, 4,OpenCV部署方法 安装OpenCV之前…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

面试官问LinkedBlockingQueue和ArrayBlockingQueue区别?别只答有界无界了,这3个实战坑才是重点
面试官追问LinkedBlockingQueue与ArrayBlockingQueue?别只答基础区别,这3个实战陷阱才是关键 当面试官抛出"LinkedBlockingQueue和ArrayBlockingQueue有什么区别"这个问题时,80%的候选人会条件反射般回答"一个有界一个无界&qu…...

【Midjourney霓虹效果终极指南】:20年AI视觉工程师亲授5大参数组合+3类光源建模公式,97%新手一周内复刻赛博朋克海报
更多请点击: https://kaifayun.com 第一章:霓虹美学的视觉原理与Midjourney适配性解析 霓虹美学源于20世纪都市夜景中的荧光灯管、电子广告与赛博朋克文化,其核心视觉特征包括高饱和度冷暖对比、边缘辉光(glow)、深色…...

AVR+ESP8266双核架构打造独立WiFi天气显示器:从硬件设计到软件实现
1. 项目概述:一个独立WiFi天气显示器的诞生几年前,我琢磨着在书桌上放一个能实时显示天气信息的小玩意儿,市面上成品要么功能单一,要么价格不菲,要么数据源依赖复杂的服务器。于是,我决定自己动手ÿ…...