图像分类学习笔记(七)——MobileNet
一、MobileNetV1
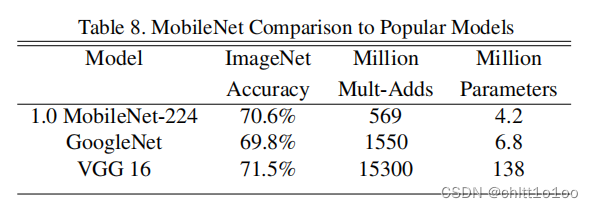
传统的神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。之前的VGG16模型权重大小大概有490M,ResNet模型权重大小大概有644M。MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中轻量级CNN网络。相比于传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
(一)要点
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α,β(α是控制卷积层卷积核个数的倍率,β是控制输入图像的大小),这两个参数是人为设定的,不是学习到的。
- 将卷积核的个数减少后,能保证准确率小幅下降的情况下,减少运算量
- 适当减少输入图像的大小,能保证准确率小幅下降的情况下,减少运算量
- 可以根据项目需求,适当调整α和β

(二) 传统卷积、DW卷积、PW卷积

传统卷积
- 卷积核channel=输入特征矩阵channel
- 输出特征矩阵channel=卷积核个数

DW卷积/深度卷积(Depthwise Convolution)
- 卷积核channel=1
- 输入特征矩阵channel=卷积核个数=输出特征矩阵channel
即DW卷积中的每一个卷积核,只会和输入特征矩阵的一个channel进行卷积计算,所以输出的特征矩阵就等于输入的特征矩阵

PW卷积/逐点卷积(Pointwise Conv)
- 普通卷积,只不过卷积核大小为 1×1,进行升维
(三)Depthwise Separable Conv深度可分卷积
一般来说,DW卷积核PW卷积是放在一起操作的,共同组成深度可分卷积操作。普通卷积和深度可分卷积的参数量和计算量的对比:
参数量和计算量:
- 参数量是指网络中需要多少参数,对于卷积来说,就是卷积核里所有的值的个数,它往往和空间使用情况有关;
- 计算量是指网络中我们进行了多少次乘加运算,对于卷积来说,我们得到的特征图都是进行一系列的乘加运算得到的,计算公式就是卷积核的尺寸DK x DK×M、卷积核个数N、及输出特征图尺寸DF x DF的乘积,计算量往往和时间消耗有关。

普通卷积
- 参数量:DK × DK × M × N
- 计算量:DK × DK × M × N × DF × DF

深度可分卷积
- 参数量:DK × DK × M + M × N
- 计算量:DK × DK × M × DF × DF + M × N × DF × DF
一般的,N较大,
可忽略不计,DK 表示卷积核的大小,若DK =3,
,即我们若使用常见的3×3的卷积核,那么使用深度可分离卷积的参数量和计算量下降到原来的九分之一左右。(理论上普通卷积计算量是深度可分卷积的8倍到9倍)

(四)MobileNetV1网络结构

对于DW卷积,训练完之后会出现部分卷积核会费掉的问题,即卷积核参数大部分为零,也就是表示其实DW卷积没有起到多大的作用。对于这个问题,MobileNetV2有一定的改善。
二、MobileNetV2
MobileNet V2网络是由google团队在2018年提出的,相比于MobileNet V1网络,准确率更高,模型更小。
(一)要点
- Inverted Residuals(倒残差结构)
- Linear Bottlenecks(线性瓶颈结构)
(二)Inverted Residuals(倒残差结构)
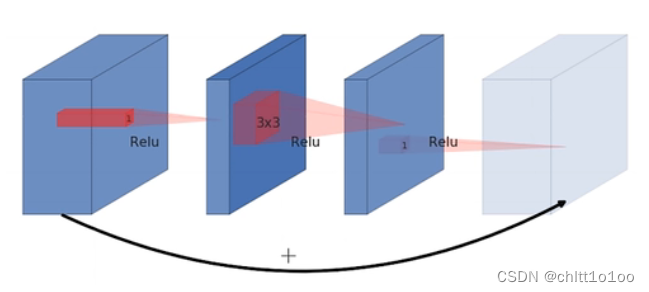
ResNet的传统残差结构(Residual block):
- 1×1卷积降维,3×3卷积处理,1×1卷积升维
- 看图可知两头大,中间小
- 激活函数为ReLU

倒残差结构(Inverted Residuals):
- 1×1卷积升维,3×3卷积DW,1×1卷积降维
- 看图可知两头小,中间大
- 激活函数为ReLU(6)
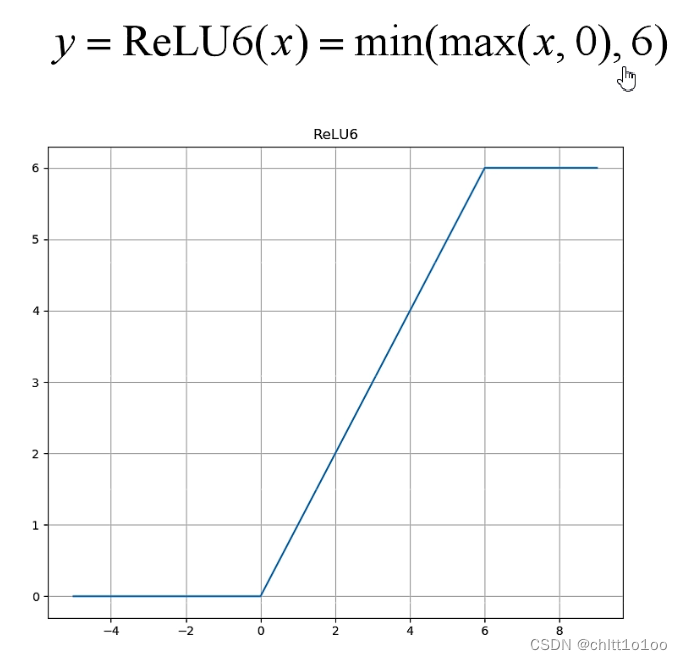
(三)Linear Bottlenecks
Linear Bottlenecks是针对倒残差结构最后一个1×1的卷积层,使用了线性的激活函数,而不是ReLU激活函数。
理由:
作者做了一个实验,输入一个二维的矩阵,channel为1,分别采用不同的矩阵T将其变换到更高的维度上,再使用ReLU激活函数得到输出值,再使用T矩阵的逆将其还原回二维的特征矩阵。在输入维度是2、3时,最后输出和输入相比丢失了较多信息;但是在输入维度是15到30时,最后输出则保留了输入的较多信息。也就是ReLU激活函数对低维特征信息造成大量损失 ,而对高维特征信息造成的损失比较小,又因为倒残差结构是两头小,中间大的结构,所以输出是低维的特征矩阵,所以需要线性的激活函数来替代ReLU激活函数。
因此这里可以有两种思路:
- 一是把Relu激活函数替换成别的
- 二是通过升维将输入的维度变高

倒残差结构图

其中shortcut连接只有当stride=1并且输入特征矩阵与输出特征矩阵shape相同时才有。stride=1保证了输出特征矩阵宽高不变,因此shape相同特指输入输出特征矩阵的深度k = k ′

表中 t 为扩展因子,第一个1 x 1的卷积核个数为tk;第二层dw卷积s(stride为给定的),输出长宽变成1/s倍,深度不变;第三层1 x 1的卷积,降维操作,宽高不变,深度变为k’。
(四)MobileNetV2网络结构

- t是扩展因子(倍率)
- c是输出特征矩阵channel,即k'
- n是bottleneck的重复次数
- s是步距(一个block中只针对第一个bottleneck,后面的bottleneck的步距都为1)
- 表格中的第二行t=1,也就是该bottleneck的第一层卷积层没有对输入特征矩阵的深度进行调整,在pytorch和tensorflow的实现中,没有使用这层的1×1卷积的,而是直接使用了DW卷积。因为第一层卷积层既没有起到升维作用,又没有起到降维作用,所以其实是可以不需要的。
- 其中shortcut连接只有当stride=1并且输入特征矩阵与输出特征矩阵shape相同时才有。在表格的第六行中有三个bottleneck,s=1,但是并没有shortcut,这是因为输入深度64,输出深度为96,无法进行相加。(shortcut连接只有当stride=1并且输入特征矩阵与输出特征矩阵shape相同时才有)
- 最后的一个卷积层相当于一个全连接层,k代表分类的类别个数。
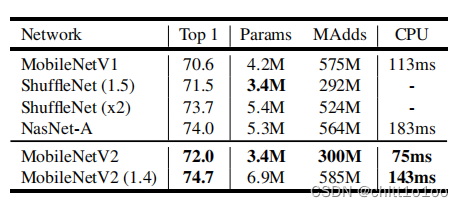
(五)性能对比
分类任务:
目标检测任务:

三、MobileNetV3
(一)要点
- 更新Block(bneck)
- 加入SE(Squeeze-and-Excitation)模块(通道的注意力机制模块)
- 更新了激活函数
- 使用NAS(Neural Architecture Search)搜索参数
- 重新设计耗时层结构
性能比较:

(二)更新Block


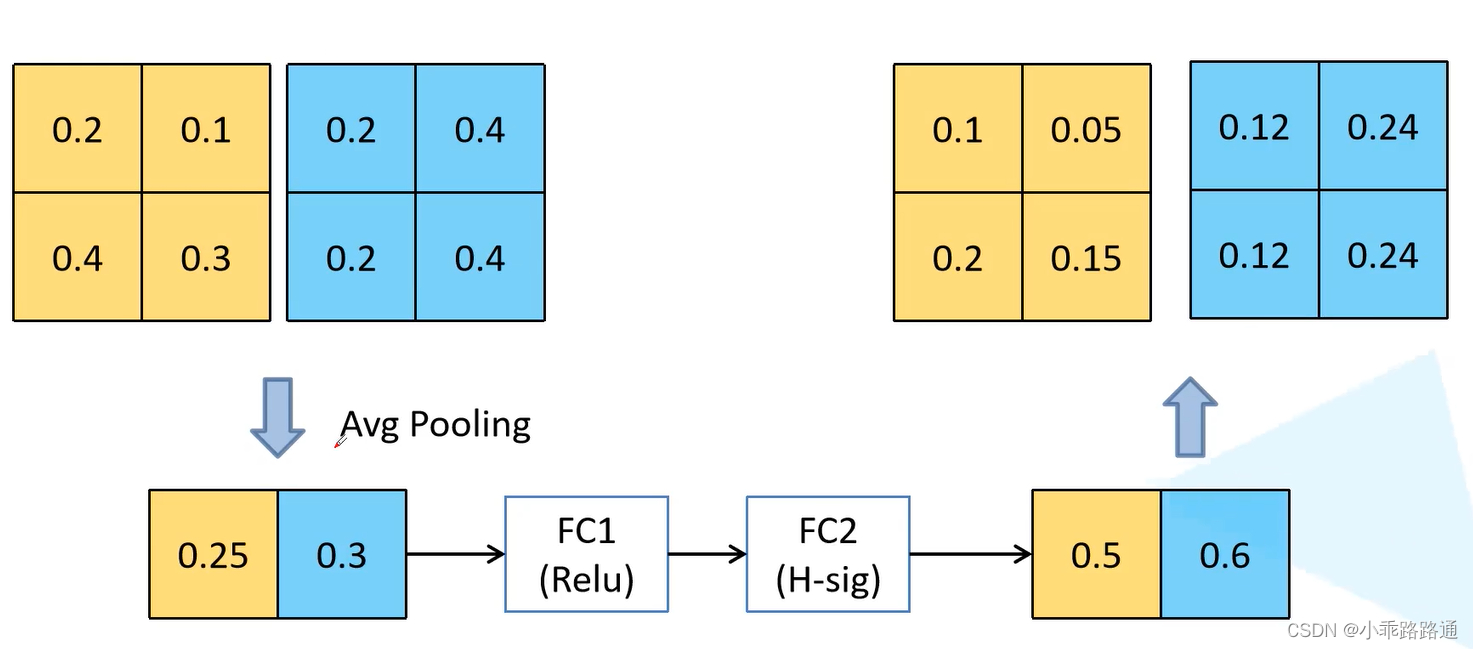
1、加入SE模块

针对得到的特征矩阵,对其每个channel进行池化处理,channel有多少得到的一维向量就有多少元素,再通过两个全连接层得到输出的特征向量。对于第一个全连接层,它的全连接层节点个数是输入特征矩阵channel的四分之一,第二个全连接层节点个数是和最开始输入特征矩阵channel保持一致的。对于最后输出的向量可以理解为对最开始输入特征矩阵的每个channel得出了一个权重关系,对于比较重要的channel就赋予更大的权重。
举例:
2、更新了激活函数
- 图中的NL表示的就是非线性激活函数,因为在每一层所使用的非线性激活函数都不一样,所以没有明确标出具体是哪个激活函数。
- 最后一层1×1卷积核用来降维的后面没有使用激活函数

swish函数确实能够提高网络的准确率,但是计算、求导复杂,对量化过程不友好,针对这两个问题,作者提出了h-swish激活函数。
(三)重新设置耗时层结构
1、减少第一个卷积层的卷积核个数(32->16)

将卷积核的个数从32减少为16后,准确率和原来的一样,那么使用更少的卷积核计算量会更少,大概节省了2ms。
2、精简Last Stage



(四)MobileNetV3网络结构
MobileNetV3-Small

MobileNetV3-Large
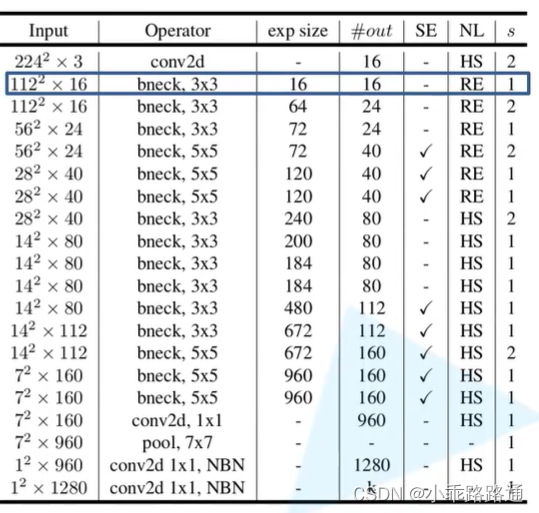
- exp size指用来升维的1×1卷积核的个数
- #out 降维后(输出)的维度
四、使用Pytorch搭建MobileNetV2网络结构
from torch import nn
import torchdef _make_divisible(ch, divisor=8, min_ch=None):"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py"""if min_ch is None:min_ch = divisor# int(ch + divisor / 2) // divisor类似于四舍五入的操作new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.# 确保向下取整时不会减少超过10%if new_ch < 0.9 * ch:new_ch += divisorreturn new_ch# 这个继承nn.Sequential而不是nn.Module这是根据pytorch官方实现样例来的
# 因为后续训练需要使用pytorch官方提供的网络预训练权重,所以按照官网所给的方式搭建
class ConvBNReLU(nn.Sequential):# 注意这里的groups,因为DW卷积还是用的是nn.Conv2d实现,如果groups=1就是普通卷积,如果groups设置为输入特征矩阵的深度就是DW卷积def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):padding = (kernel_size - 1) // 2super(ConvBNReLU, self).__init__(nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),nn.BatchNorm2d(out_channel),nn.ReLU6(inplace=True))class InvertedResidual(nn.Module):def __init__(self, in_channel, out_channel, stride, expand_ratio):super(InvertedResidual, self).__init__()hidden_channel = in_channel * expand_ratio# 当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接self.use_shortcut = stride == 1 and in_channel == out_channel # 是个布尔变量layers = []if expand_ratio != 1:# 1x1 pointwise convlayers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))layers.extend([# extend和append的区别在于extend可以一次性插入很多个# 3x3 depthwise convConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),# 1x1 pointwise conv(linear)nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),nn.BatchNorm2d(out_channel),# 因为线性激活函数的表达式就是y=x,不对输入作任何处理,所以就不需要再额外添加激活函数])self.conv = nn.Sequential(*layers)def forward(self, x):if self.use_shortcut:return x + self.conv(x)else:return self.conv(x)class MobileNetV2(nn.Module):def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):super(MobileNetV2, self).__init__()block = InvertedResidual# 将卷积核个数(即输出通道数)调整为round_nearest的整数倍,更好的调用硬件设备input_channel = _make_divisible(32 * alpha, round_nearest)last_channel = _make_divisible(1280 * alpha, round_nearest)inverted_residual_setting = [# t, c, n, s[1, 16, 1, 1],[6, 24, 2, 2],[6, 32, 3, 2],[6, 64, 4, 2],[6, 96, 3, 1],[6, 160, 3, 2],[6, 320, 1, 1],]features = []# conv1 layerfeatures.append(ConvBNReLU(3, input_channel, stride=2))# building inverted residual residual blockesfor t, c, n, s in inverted_residual_setting:output_channel = _make_divisible(c * alpha, round_nearest)for i in range(n):stride = s if i == 0 else 1features.append(block(input_channel, output_channel, stride, expand_ratio=t))input_channel = output_channel# building last several layersfeatures.append(ConvBNReLU(input_channel, last_channel, 1))# combine feature layersself.features = nn.Sequential(*features)# building classifierself.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应的平均池化下采样,给出输出矩阵的高和宽是1×1的self.classifier = nn.Sequential(nn.Dropout(0.2),nn.Linear(last_channel, num_classes))# weight initializationfor m in self.modules():if isinstance(m, nn.Conv2d): # 如果是卷积层,对它的权重进行初始化nn.init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None: # 如果存在偏置,则偏置置为0nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm2d): # 如果是BN层,方差设置为1.均值设置为0nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear): # 如果是全连接层,对它的权重进行初始化(正态分布,均值为0,方差为0.01),偏置置为0nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x五、使用Pytorch搭建MobileNetV3网络结构
from typing import Callable, List, Optionalimport torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partialdef _make_divisible(ch, divisor=8, min_ch=None):"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py"""if min_ch is None:min_ch = divisornew_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_ch < 0.9 * ch:new_ch += divisorreturn new_chclass ConvBNActivation(nn.Sequential):def __init__(self,in_planes: int,out_planes: int,kernel_size: int = 3,stride: int = 1,groups: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,activation_layer: Optional[Callable[..., nn.Module]] = None):padding = (kernel_size - 1) // 2if norm_layer is None:norm_layer = nn.BatchNorm2dif activation_layer is None:activation_layer = nn.ReLU6super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,out_channels=out_planes,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bias=False),norm_layer(out_planes),activation_layer(inplace=True))class SqueezeExcitation(nn.Module):def __init__(self, input_c: int, squeeze_factor: int = 4):super(SqueezeExcitation, self).__init__()squeeze_c = _make_divisible(input_c // squeeze_factor, 8)self.fc1 = nn.Conv2d(input_c, squeeze_c, 1) # 和全连接层起到相同的作用self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)def forward(self, x: Tensor) -> Tensor:scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))scale = self.fc1(scale)scale = F.relu(scale, inplace=True)scale = self.fc2(scale)scale = F.hardsigmoid(scale, inplace=True)return scale * x# 对应的是MobileNetV3中的每一个bneck结构的参数配置
class InvertedResidualConfig:def __init__(self,input_c: int,kernel: int,expanded_c: int,out_c: int,use_se: bool,activation: str,stride: int,width_multi: float): # width_multi就是相当于alpha参数,倍率因子self.input_c = self.adjust_channels(input_c, width_multi)self.kernel = kernelself.expanded_c = self.adjust_channels(expanded_c, width_multi)self.out_c = self.adjust_channels(out_c, width_multi)self.use_se = use_seself.use_hs = activation == "HS" # whether using h-swish activationself.stride = stride@staticmethoddef adjust_channels(channels: int, width_multi: float):return _make_divisible(channels * width_multi, 8)class InvertedResidual(nn.Module):def __init__(self,cnf: InvertedResidualConfig,norm_layer: Callable[..., nn.Module]):super(InvertedResidual, self).__init__()if cnf.stride not in [1, 2]:raise ValueError("illegal stride value.")self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)layers: List[nn.Module] = []# 要使用Hardswish必须将pytorch更新到1.7或1.7以上activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU# expandif cnf.expanded_c != cnf.input_c:layers.append(ConvBNActivation(cnf.input_c,cnf.expanded_c,kernel_size=1,norm_layer=norm_layer,activation_layer=activation_layer))# depthwiselayers.append(ConvBNActivation(cnf.expanded_c,cnf.expanded_c,kernel_size=cnf.kernel,stride=cnf.stride,groups=cnf.expanded_c,norm_layer=norm_layer,activation_layer=activation_layer))if cnf.use_se:layers.append(SqueezeExcitation(cnf.expanded_c))# projectlayers.append(ConvBNActivation(cnf.expanded_c,cnf.out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity)) # nn.Identity就是线性激活,没有做任何处理self.block = nn.Sequential(*layers)self.out_channels = cnf.out_cself.is_strided = cnf.stride > 1def forward(self, x: Tensor) -> Tensor:result = self.block(x)if self.use_res_connect:result += xreturn resultclass MobileNetV3(nn.Module):def __init__(self,inverted_residual_setting: List[InvertedResidualConfig],last_channel: int,num_classes: int = 1000,block: Optional[Callable[..., nn.Module]] = None,norm_layer: Optional[Callable[..., nn.Module]] = None):super(MobileNetV3, self).__init__()if not inverted_residual_setting:raise ValueError("The inverted_residual_setting should not be empty.")elif not (isinstance(inverted_residual_setting, List) andall([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")if block is None:block = InvertedResidualif norm_layer is None:# partial()是为BatchNorm2d传入了两个默认的参数eps和momentumnorm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)layers: List[nn.Module] = []# building first layerfirstconv_output_c = inverted_residual_setting[0].input_clayers.append(ConvBNActivation(3,firstconv_output_c,kernel_size=3,stride=2,norm_layer=norm_layer,activation_layer=nn.Hardswish))# building inverted residual blocksfor cnf in inverted_residual_setting:layers.append(block(cnf, norm_layer))# building last several layerslastconv_input_c = inverted_residual_setting[-1].out_clastconv_output_c = 6 * lastconv_input_clayers.append(ConvBNActivation(lastconv_input_c,lastconv_output_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Hardswish))self.features = nn.Sequential(*layers)self.avgpool = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),nn.Hardswish(inplace=True),nn.Dropout(p=0.2, inplace=True),nn.Linear(last_channel, num_classes))# initial weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def _forward_impl(self, x: Tensor) -> Tensor:x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef forward(self, x: Tensor) -> Tensor:return self._forward_impl(x)def mobilenet_v3_large(num_classes: int = 1000,reduced_tail: bool = False) -> MobileNetV3:"""Constructs a large MobileNetV3 architecture from"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.weights_link:https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pthArgs:num_classes (int): number of classesreduced_tail (bool): If True, reduces the channel counts of all feature layersbetween C4 and C5 by 2. It is used to reduce the channel redundancy in thebackbone for Detection and Segmentation."""width_multi = 1.0bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)reduce_divider = 2 if reduced_tail else 1inverted_residual_setting = [# input_c, kernel, expanded_c, out_c, use_se, activation, stridebneck_conf(16, 3, 16, 16, False, "RE", 1),bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1bneck_conf(24, 3, 72, 24, False, "RE", 1),bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2bneck_conf(40, 5, 120, 40, True, "RE", 1),bneck_conf(40, 5, 120, 40, True, "RE", 1),bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3bneck_conf(80, 3, 200, 80, False, "HS", 1),bneck_conf(80, 3, 184, 80, False, "HS", 1),bneck_conf(80, 3, 184, 80, False, "HS", 1),bneck_conf(80, 3, 480, 112, True, "HS", 1),bneck_conf(112, 3, 672, 112, True, "HS", 1),bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),]last_channel = adjust_channels(1280 // reduce_divider) # C5return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)def mobilenet_v3_small(num_classes: int = 1000,reduced_tail: bool = False) -> MobileNetV3:"""Constructs a large MobileNetV3 architecture from"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.weights_link:https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pthArgs:num_classes (int): number of classesreduced_tail (bool): If True, reduces the channel counts of all feature layersbetween C4 and C5 by 2. It is used to reduce the channel redundancy in thebackbone for Detection and Segmentation."""width_multi = 1.0bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)reduce_divider = 2 if reduced_tail else 1inverted_residual_setting = [# input_c, kernel, expanded_c, out_c, use_se, activation, stridebneck_conf(16, 3, 16, 16, True, "RE", 2), # C1bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2bneck_conf(24, 3, 88, 24, False, "RE", 1),bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3bneck_conf(40, 5, 240, 40, True, "HS", 1),bneck_conf(40, 5, 240, 40, True, "HS", 1),bneck_conf(40, 5, 120, 48, True, "HS", 1),bneck_conf(48, 5, 144, 48, True, "HS", 1),bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)]last_channel = adjust_channels(1024 // reduce_divider) # C5return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)相关文章:
图像分类学习笔记(七)——MobileNet
一、MobileNetV1 传统的神经网络,内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。之前的VGG16模型权重大小大概有490M,ResNet模型权重大小大概有644M。MobileNet网络是由google团队在2017年提出的,专注于移动端或…...
ssm+vue宠物领养系统源码和论文
ssmvue宠物领养系统源码和论文103 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 本课题是根据用户的需要以及网络的优势建立的一个宠物领养系统,来满足用宠物领养的需求。 本宠物领养系统…...

阜时科技联合客户发布全固态激光雷达面阵SPAD芯片及雷达整机
引言: 首先,我们非常荣幸受邀观摩此次行业盛会。阜时科技在全固态激光雷达面阵SPAD芯片研发上所取得的卓越成果,对于激光雷达大幅降本、扩大市场应用,具有重要意义。先划重点: 1,正式发布之前,阜时科技全固态激光雷达面阵SPAD芯片已被光之矩、武汉万集等多家激光雷达厂…...
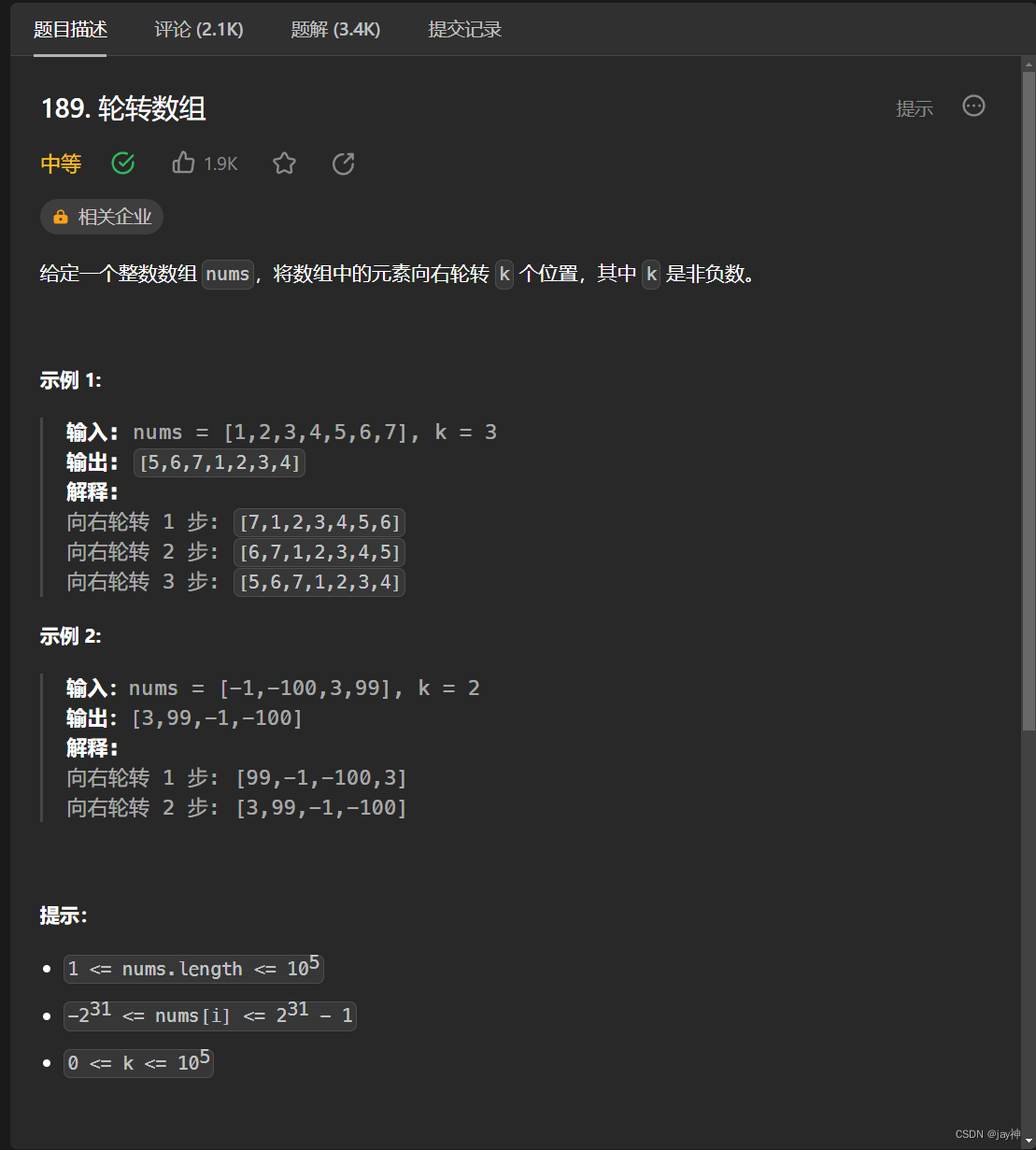
leetcode 189. 轮转数组
2023.9.3 k的取值范围为0~100000,此时需要考虑到两种情况,当k为0时,此时数组不需要轮转,因此直接return返回;当k大于等于数组nums的大小时,数组将会转为原来的数组,然后再接着轮转,此…...

亚马逊广告收入突破百亿美元,有望成为下一个收入支柱来源?
据外媒报道,亚马逊新兴的广告业务已经价值数百亿美元,很可能成为其下一个收入支柱来源。 市场研究公司Insider Intelligence的分析师Andrew Lipsman表示,按照目前的发展轨迹,亚马逊广告业务甚至可以与其云计算业务相互抗衡。“毫…...

MATLAB中isequal函数转化为C语言
背景 有项目算法使用matlab中isequal函数进行运算,这里需要将转化为C语言,从而模拟算法运行,将算法移植到qt。 MATLAB中isequal简单介绍 语法 tf isequal(A,B) tf isequal(A1,A2,...,An) 说明 如果 A 和 B 等效,则 tf is…...
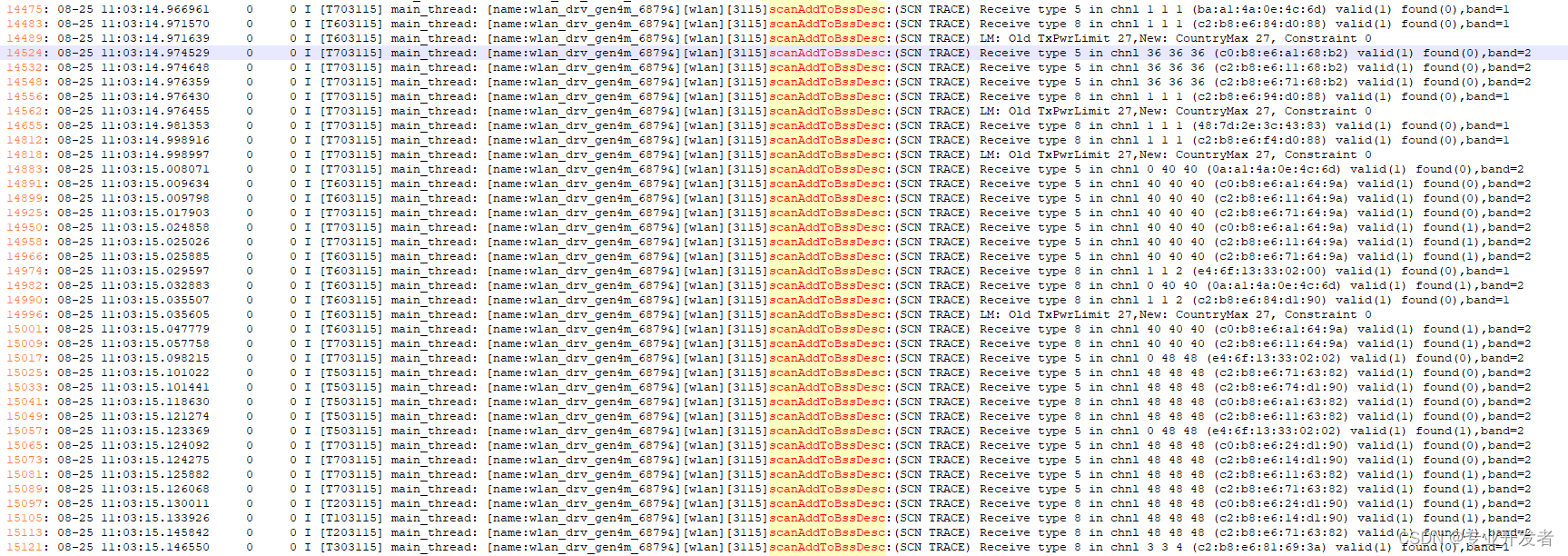
【MTK平台】根据kernel log分析wifi scan的时候流程
一 概要: 本文主要讲解根据kernel log分析下 当前路径下(vendor/mediatek/kernel_modules/connectivity/wlan/core/gen4m/)wifi scan的时候代码流程 二. Log分析: 先看Log: 2.1)在Framework层WifiManager.java 方法中,做了一个标记,可以精准的确认时间 这段log可以…...
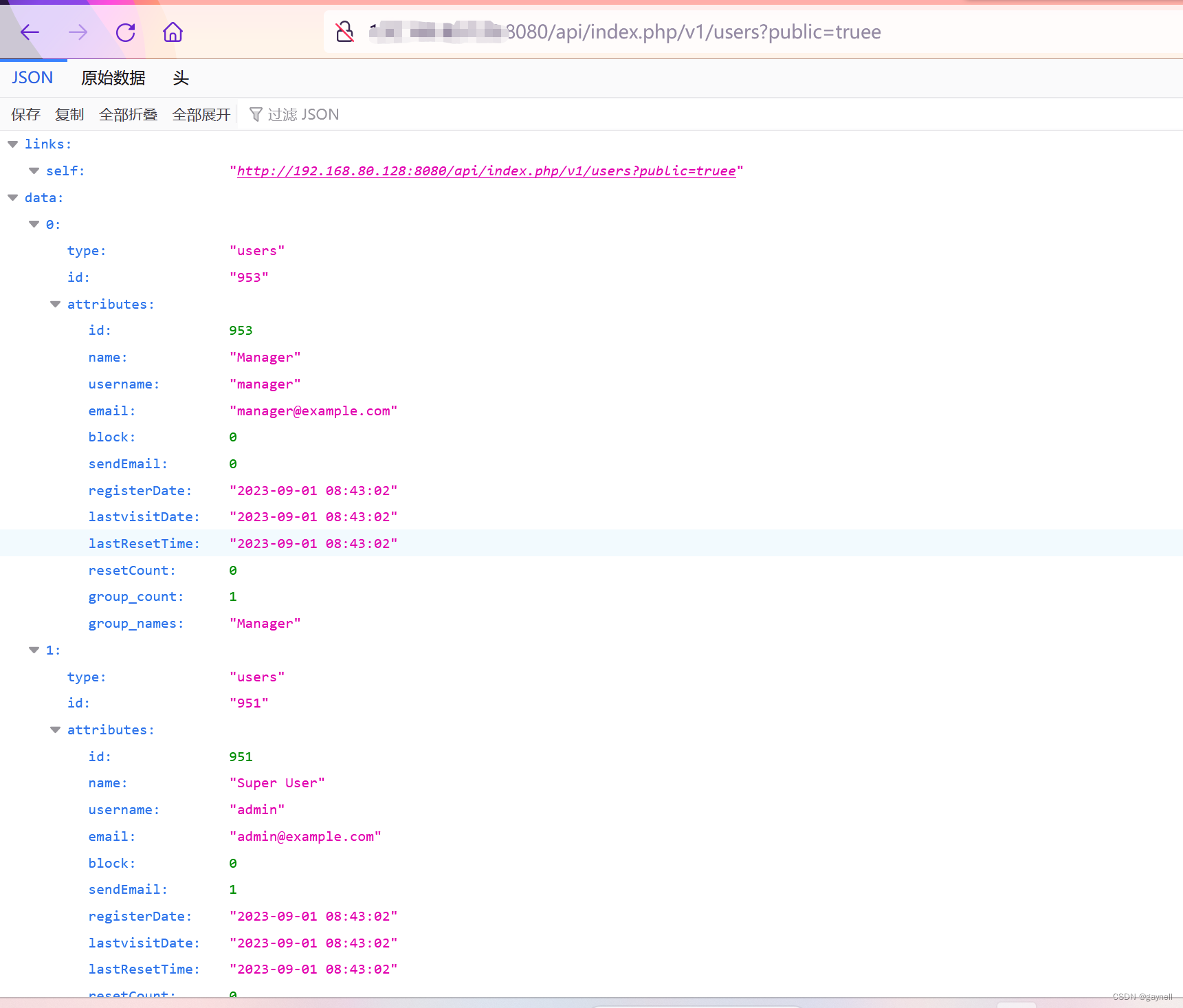
CVE-2023-23752:Joomla未授权访问漏洞复现
CVE-2023-23752:Joomla未授权访问漏洞复现 前言 本次测试仅供学习使用,如若非法他用,与本文作者无关,需自行负责!!! 一.Openfire简介 Joomla是一个免费的开源内容管理系统(CMS&a…...

MATLAB中circshift函数转化为C语言
背景 有项目算法使用matlab中circshift函数进行运算,这里需要将转化为C语言,从而模拟算法运行,将算法移植到qt。 MATLAB中circshift简单介绍 circshift是循环移位函数。可以使用于数组和矩阵元素的循环移位。 当A是数组 Bcircshift(A,p);如果…...

浅谈React生命周期
React组件的生命周期可以分为三个阶段:挂载阶段、更新阶段和卸载阶段。下面对每个生命周期方法进行详细解释。 挂载阶段: constructor(props): 在组件被创建时调用,用于初始化组件的状态(state)和绑定事件处理函数。…...

基于龙格-库塔算法优化的BP神经网络(预测应用) - 附代码
基于龙格-库塔算法优化的BP神经网络(预测应用) - 附代码 文章目录 基于龙格-库塔算法优化的BP神经网络(预测应用) - 附代码1.数据介绍2.龙格-库塔优化BP神经网络2.1 BP神经网络参数设置2.2 龙格-库塔算法应用 4.测试结果ÿ…...

C++ 获取进程信息
1. 概要 通常对于一个正在执行的进程而言,我们会关注进程的内存/CPU占用,网络连接,启动参数,映像路径,线程,堆栈等信息。 而通过类似任务管理器,命令行等方式可以轻松获取到这些信息。但是&…...

【Redis从头学-13】Redis哨兵模式解析以及搭建指南
🧑💻作者名称:DaenCode 🎤作者简介:啥技术都喜欢捣鼓捣鼓,喜欢分享技术、经验、生活。 😎人生感悟:尝尽人生百味,方知世间冷暖。 📖所属专栏:Re…...

【个人笔记js的原型理解】
在 JavaScript 中,最常见的新建一个对象的方式就是使用花括号的方式。然后使用’ . 的方式往里面添加属性和方法。可见以下代码: let animal {}; animal.name Leo; animal.energe 10;animal.eat function (amount) {console.log(${this.name} is ea…...
Liunx系统编程:信号量
一. 信号量概述 1.1 信号量的概念 在多线程场景下,我们经常会提到临界区和临界资源的概念,如果临界区资源同时有多个执行流进入,那么在多线程下就容易引发线程安全问题。 为了保证线程安全,互斥被引入,互斥可以保证…...
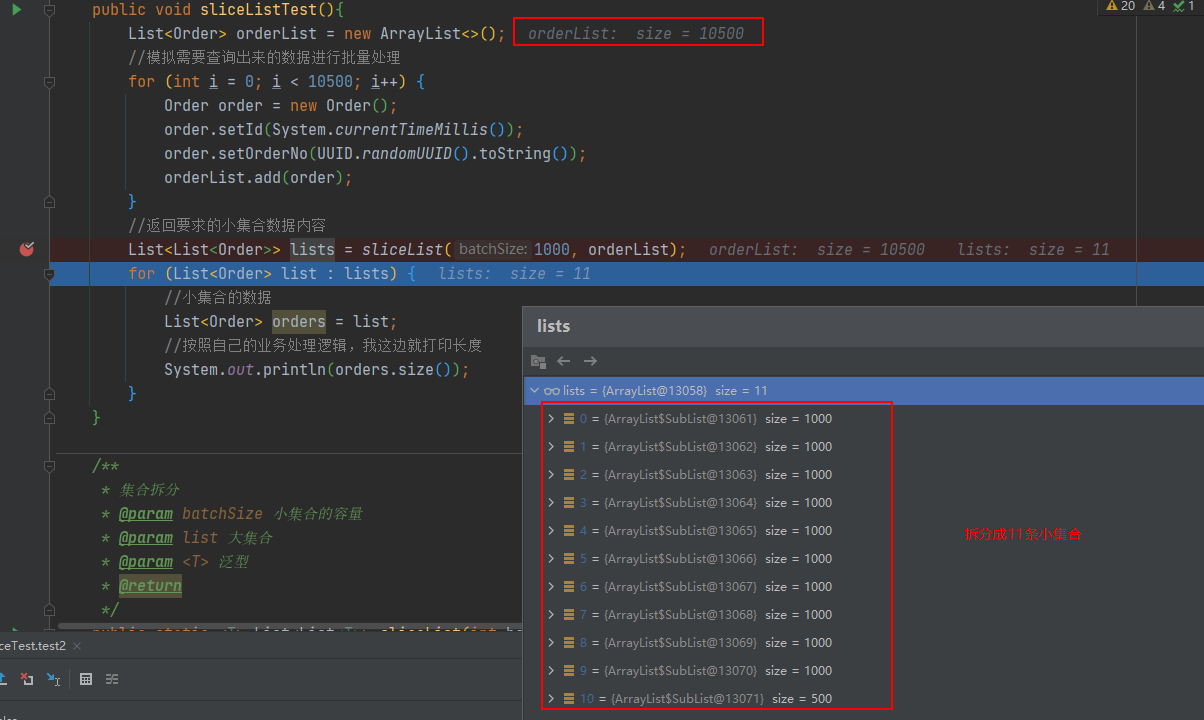
大集合按照指定长度进行分割成多个小集合,用于批量多次处理数据
📚目录 拆分案例拆分的核心代码 通常我们对集合的更新或者保存都需要用集合来承载通过插入的效率,但是这个会遇到一个问题就是你不知道那天那个集合的数量可能就超了,虽然我们连接数据库进行批量提交会在配置上配置allowMultiQueriestrue,但是…...
ELK日志收集系统集群实验(5.5.0版)
目录 前言 一、概述 二、组件介绍 1、elasticsearch 2、logstash 3、kibana 三、架构类型 四、ELK日志收集集群实验 1、实验拓扑 2、在node1和node2节点安装elasticsearch 3、启动elasticsearch服务 4、在node1安装elasticsearch-head插件 5、测试输入 6、node1服…...
基于java swing和mysql实现的电影票购票管理系统(源码+数据库+运行指导视频)
一、项目简介 本项目是一套基于java swing和mysql实现的电影票购票管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。 包含:项目源码、项目文档、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都…...

数据结构--6.0最短路径
目录 一、迪杰斯特拉算法(Dijkstra) 二、弗洛伊德算法(Floyd) 在网图和非网图中,最短路径的含义是不同的。 ——网图是两顶点经过的边上的权值之和最少的路径。 …...

Docker进阶:mysql 主从复制、redis集群3主3从【扩缩容案例】
Docker进阶:mysql 主从复制、redis集群3主3从【扩缩容案例】 一、Docker常规软件安装1.1 docker 安装 tomcat(默认最新版)1.2 docker 指定安装 tomcat8.01.3 docker 安装 mysql 5.7(数据卷配置)1.4 演示--删除mysql容器…...

VideoAgentTrek-ScreenFilter快速开始:10分钟完成Docker部署与API测试
VideoAgentTrek-ScreenFilter快速开始:10分钟完成Docker部署与API测试 你是不是也对那些能自动分析视频、识别屏幕内容的AI工具感到好奇?今天咱们就来聊聊VideoAgentTrek-ScreenFilter,一个专门用来处理视频中屏幕内容的模型。听起来挺酷&am…...

攻克Switch 19.0.1系统Atmosphere启动故障:从诊断到优化的完整方案
攻克Switch 19.0.1系统Atmosphere启动故障:从诊断到优化的完整方案 【免费下载链接】Atmosphere Atmosphre is a work-in-progress customized firmware for the Nintendo Switch. 项目地址: https://gitcode.com/GitHub_Trending/at/Atmosphere 在Switch主机…...

RDMA设计64:数据吞吐量性能测试分析
本博文主要交流设计思路,在本博客已给出相关博文约190篇,希望对初学者有用。 注意这里只是抛砖引玉,切莫认为参考这就可以完成商用IP 设计。 这里将在基于 XCZU47DR FPGA 核心的开发板上对 RoCE v2 高速传输系统进行数据吞吐量、包吞吐量及传…...

新手入门指南:在快马平台用万文通思路打造你的第一个文本转换网页
今天想和大家分享一个特别适合编程新手的实践项目——用万文通思路在InsCode(快马)平台快速搭建文本转换网页。这个项目完全不需要复杂的环境配置,打开浏览器就能完成,特别适合想体验完整开发流程的初学者。 项目核心功能设计 这个网页的核心功能非常简单…...

告别人工筛选!用Word2vec构建主题词库,我们拿“网络暴力”关键词试了试
智能主题词库构建实战:用Word2vec挖掘语义关联词汇 在信息爆炸的时代,内容运营和产品经理们常常面临一个共同挑战:如何从海量文本中快速识别和归类相关主题内容。传统的人工筛选方法不仅效率低下,还容易遗漏那些变体表达和新兴网络…...

Fluent Meshing体网格生成失败?别慌,先检查你的几何模型是不是‘点接触’了
Fluent Meshing体网格生成失败?别慌,先检查你的几何模型是不是‘点接触’了 当你在Fluent Meshing中看到体网格生成失败的红色报错提示时,那种感觉就像考试时突然发现漏做了一整页题目。特别是当截止日期迫在眉睫,这种报错往往让人…...

高效掌握多步提示工程:进阶AI任务处理的系统方法论
高效掌握多步提示工程:进阶AI任务处理的系统方法论 【免费下载链接】LangGPT LangGPT: Empowering everyone to become a prompt expert! 🚀 📌 结构化提示词(Structured Prompt)提出者 📌 元提示词&#x…...

YOLOv12性能优化 | 注意力融合 | 实战解析CBAM模块的集成与调优
1. CBAM注意力机制的核心原理与实战价值 第一次接触CBAM模块时,我被它简洁高效的设计惊艳到了。这个由通道注意力和空间注意力组成的双剑客,能在不显著增加计算量的情况下,让模型学会"该看哪里"。想象一下教小朋友看图说话…...

【ACCELERATED GSTREAMER PERFORMANCE GUIDE】Choosing Between videoconvert and nvvidconv for Optimal Vid
1. 理解videoconvert与nvvidconv的核心差异 第一次接触GStreamer视频处理时,很多人都会困惑到底该用videoconvert还是nvvidconv。这个问题就像选择交通工具:你是要经济实惠的公交车(CPU处理),还是要速度更快的出租车&a…...

基于python的民宿预定管理系统设计与实现j470j
目录同行可拿货,招校园代理 ,本人源头供货商功能需求分析用户端功能房东端功能管理员端功能技术实现要点扩展功能建议项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能需求分析 民宿…...