ELK日志收集系统集群实验(5.5.0版)
目录
前言
一、概述
二、组件介绍
1、elasticsearch
2、logstash
3、kibana
三、架构类型
四、ELK日志收集集群实验
1、实验拓扑
2、在node1和node2节点安装elasticsearch
3、启动elasticsearch服务
4、在node1安装elasticsearch-head插件
5、测试输入
6、node1服务器安装logstash
7、logstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
8、node1节点安装kibana
五、配置http节点
前言
ELK是指Elasticsearch、Logstash和Kibana的组合。它们是一套开源的日志收集、存储、搜索和可视化系统,常用于集中管理和分析日志数据。
1. Elasticsearch:一个分布式的实时搜索和分析引擎。它能够处理大规模的数据,并提供快速的搜索、聚合和数据分析功能。
2. Logstash:一个用于日志收集、处理和传输的工具。它支持从多种来源收集日志数据,可以进行数据清洗、转换和过滤,并将数据发送到Elasticsearch等目标存储。
3. Kibana:一个用于数据可视化和分析的工具。它可以通过图表、仪表盘和报表等方式,直观地展示Elasticsearch中的数据,帮助用户理解和分析日志。
ELK日志收集系统的工作流程如下:
1. Logstash配置:在Logstash中配置输入插件,指定日志数据的来源,如文件、网络或消息队列等。
2. 数据处理:通过Logstash的过滤插件对日志数据进行清洗、转换和过滤,使其符合需要,然后将处理后的数据发送到Elasticsearch。
3. 数据存储:Elasticsearch将接收到的日志数据进行索引并存储,以便快速搜索和分析。
4. 数据可视化:使用Kibana创建图表、仪表盘和报表等可视化组件,通过搜索和聚合数据,展示日志数据的统计信息和趋势。
5. 实时搜索和分析:通过Kibana提供的搜索功能,可以实时搜索和分析日志数据,帮助发现问题、监控系统和进行性能优化。
ELK日志收集系统的优点包括:
- 高效处理大规模日志数据:Elasticsearch作为存储和搜索引擎,能够处理大规模的日志数据。
- 灵活的数据处理和过滤:Logstash提供了丰富的插件和过滤器,可以对日志数据进行灵活的处理和转换。
- 直观的数据可视化:Kibana提供了图形化的界面,以直观的方式展示日志数据的统计信息和趋势。
- 实时搜索和分析:ELK系统支持实时搜索和分析,可以帮助快速定位和解决问题。
总之,ELK日志收集系统是一个功能强大的工具组合,可以帮助企业集中管理、存储、搜索和可视化大量的日志数据,提高系统的监控和故障排查能力。
一、概述
1、ELK由三个组件构成Elasticsearch、Logstash和Kibana的组合
| 日志收集 | Logstash |
| 日志分析 | Elasticsearch |
| 日志可视化 | Kibana |
2、 为什么使用?
日志对于分析系统、应用的状态十分重要,但一般日志的量会比较大,并且比较分散。
如果管理的服务器或者程序比较少的情况我们还可以逐一登录到各个服务器去查看、分析。但如果服务器或者程序的数量比较多了之后这种方法就显得力不从心。基于此,一些集中式的日志系统也就应用而生。目前比较有名成熟的有,Splunk(商业)、FaceBook 的Scribe、Apache的Chukwa Cloudera的Fluentd、还有ELK等等。
二、组件介绍
1、elasticsearch
作用:日志分析、开源的日志收集、分析、存储程序
特点:
分布式
零配置
自动发现
索引自动分片
索引副本机制
Restful风格接口
多数据源
自动搜索负载
2、logstash
作用:日志收集 、搜集、分析、过滤日志的工具
工作的过程:
一般工作方式为c/s架构,Client端安装在需要收集日志的服务器上,Server端负责将收到的各节点日志进行过滤、修改等操作,再一并发往Elasticsearch上去
Inputs → Filters → Outputs
输入-->过滤-->输出
| File:从文件系统的文件中读取,类似于tail -f命令 |
| Syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析 |
| Redis:从redis service中读取 |
| Beats:从filebeat中读取 |
| Grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。 |
| 官方提供的grok表达式:logstash-patterns-core/patterns at main · logstash-plugins/logstash-patterns-core · GitHub |
| Grok在线调试:Grok Debugger |
| Mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。 |
| Drop:丢弃一部分Events不进行处理。 |
| Clone:拷贝Event,这个过程中也可以添加或移除字段。 |
| Geoip:添加地理信息(为前台kibana图形化展示使用) |
| Elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。 |
| File:将Event数据保存到文件中。 |
| Graphite:将Event数据发送到图形化组件中,踏实一个当前较流行的开源存储图形化展示的组件。 |
3、kibana
作用:日志可视化
为Logstash和ElasticSearch在收集、存储的日志基础上进行分析时友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
三、架构类型
1、ELK
es
logstash
kibana
2、ELKK
es
logstash
kafka
kibana
3、ELFK
es
logstash 重量级 、占用系统资源较多
filebeat 轻量级、占用系统资源较少
kibana
4、ELFKK
es
logstash
filebeat
kafka
kibana
四、ELK日志收集集群实验
1、实验拓扑
在进行本实验时至少每台主机给到2核4G。不然嘿嘿~~你懂得。
下载地址 https://elasticsearch.cn/download/

在node1和node2设置主机名
####分别修改主机名#####
###node1
hostnamectl set-hostname node1
echo "192.168.115.131 node1" "192.168.115.136 node2" >> /etc/hosts
scp /etc/hosts 192.168.115.136:/etc/hosts
bash
###node2
hostnamectl set-hostname node2
bash
######测试通联#######
###node1
ping node2
###node2
ping node1

2、在node1和node2节点安装elasticsearch
2.1、首先检查Java环境Java-version,如果没有就装一个yum install -y java-1.8.0-openjdk
2.2、安装elasticsearch
如下所示这是本次实验用到的安装包

##安装elasticsearch
rpm -ivh elasticsearch-5.5.0.rpm
##配置
vim /etc/elasticsearch/elasticsearch.yml
###进去解开注释
cluster.name:my-elk-cluster #集群名称
node.name:node1 #节点名字
path.data: /var/lib/elasticsearch #数据存放路径
path.logs:/var/log/elasticsearch/ #日志存放路径
bootstrap.memory_lock:false #在启动的时候不锁定内存
network.host:192.168.115.131 #提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 #侦听端口为9200
discovery.zen.ping.unicast.hosts:["node1","node2"] #群集发现通过单播实现
###同理安装node2的elasticsearch
###把这份配置文件传输给node2,修改一下节点名字和IP就好了
scp /etc/elasticsearch/elasticsearch.yml 192.168.115.136:/etc/elasticsearch/elasticsearch.yml
3、启动elasticsearch服务
3.1、启动命令systemctl start elasticsearch.service
node1
node2
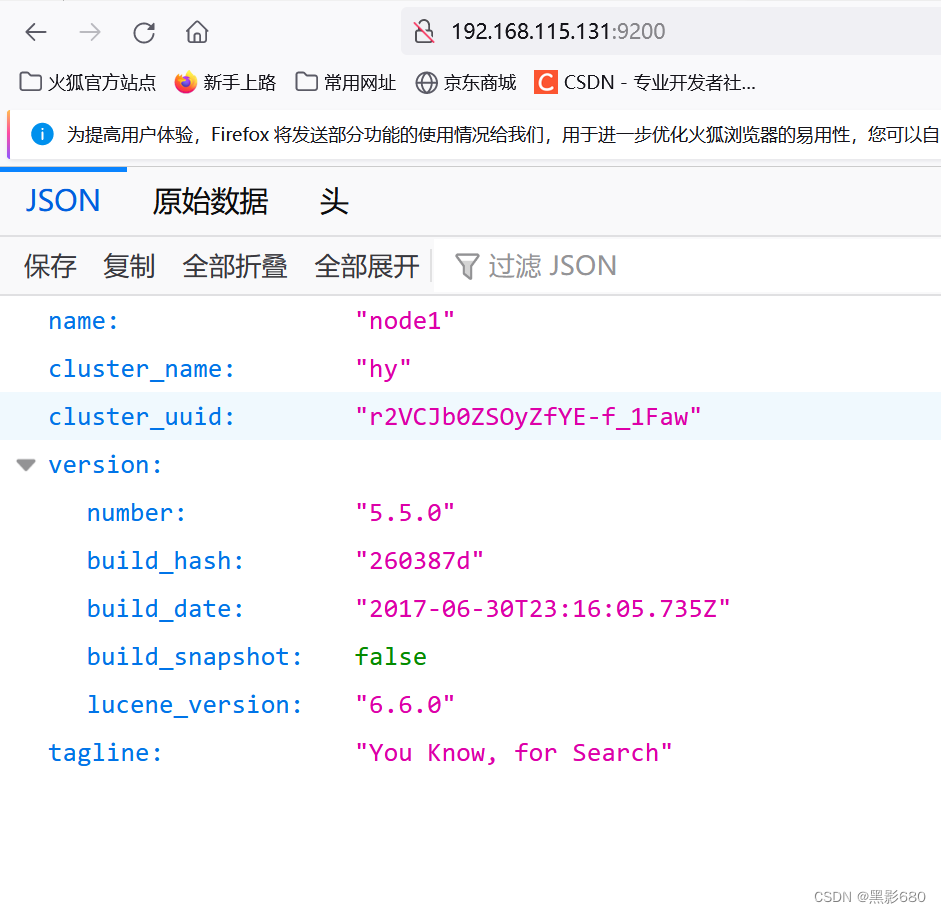
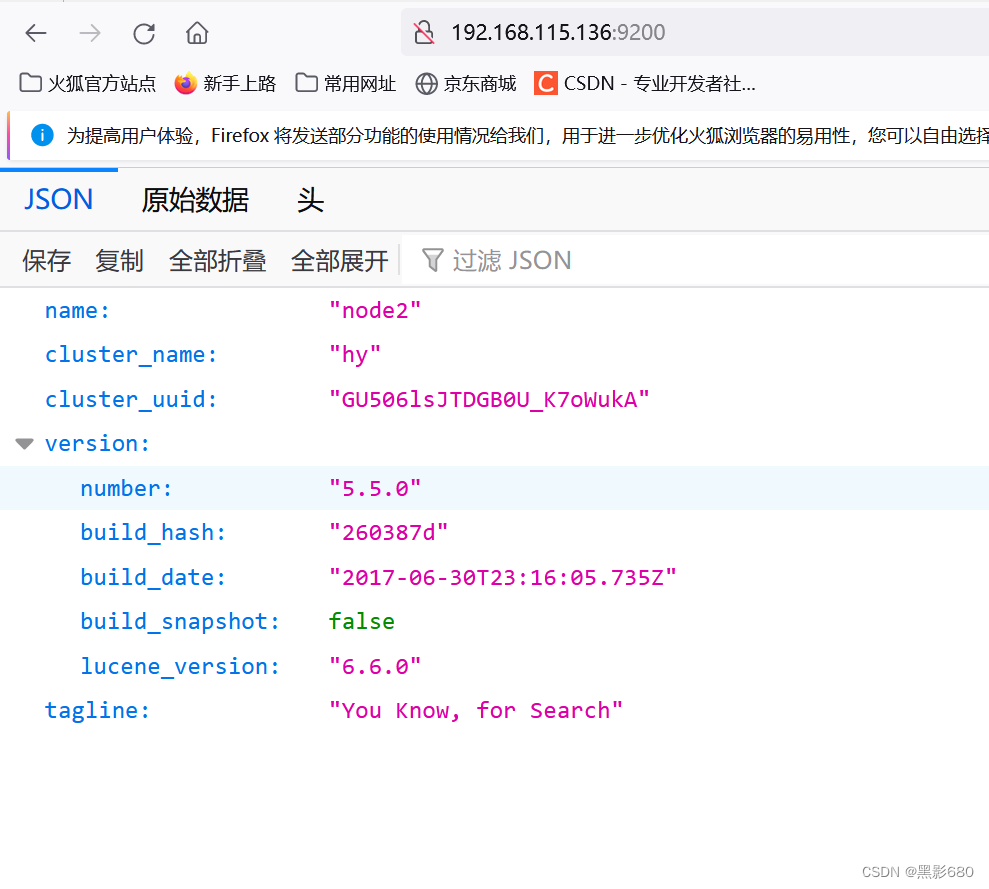
3.2、浏览器访问查看节点信息
192.168.115.131:9200
192.168.115.136
:9200
查看集群健康状态:192.168.115.131:9200/cluster/health
192.168.115.136:9200/cluster/health
Green 健康 yellow 警告 red 集群不可用,严重错误
4、在node1安装elasticsearch-head插件
####编译安装
cd elktar xf node-v8.2.1.tar.gzcd node-v8.2.1./configure && make && make install
###等待安装完毕。安装完毕后会生成命令:npm
###拷贝命令
cd elk
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
##安装elasticsearch-head
cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head
npm install
###修改elasticsearch配置文件node1、2都要改
vim /etc/elasticsearch/elasticsearch.yml# Require explicit names when deleting indices:
#
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin: "*" //跨域访问允许的域名地址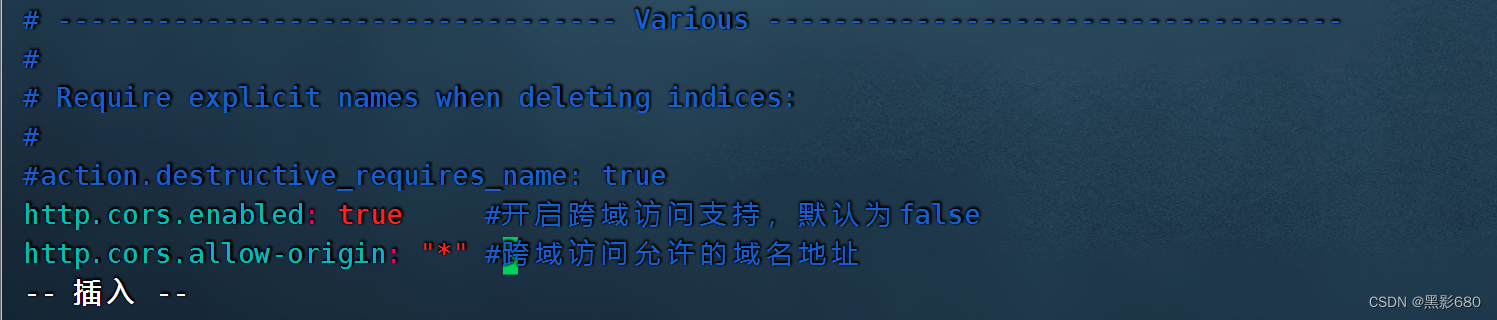 4.1、重启服务: systemctl restart elasticsearch两个节点都检查一下9200端口起来了吗
4.1、重启服务: systemctl restart elasticsearch两个节点都检查一下9200端口起来了吗

###启动elasticsearch-head
cd /root/elk/elasticsearch-head
npm run start &
##查看监听: netstat -anput | grep :9100
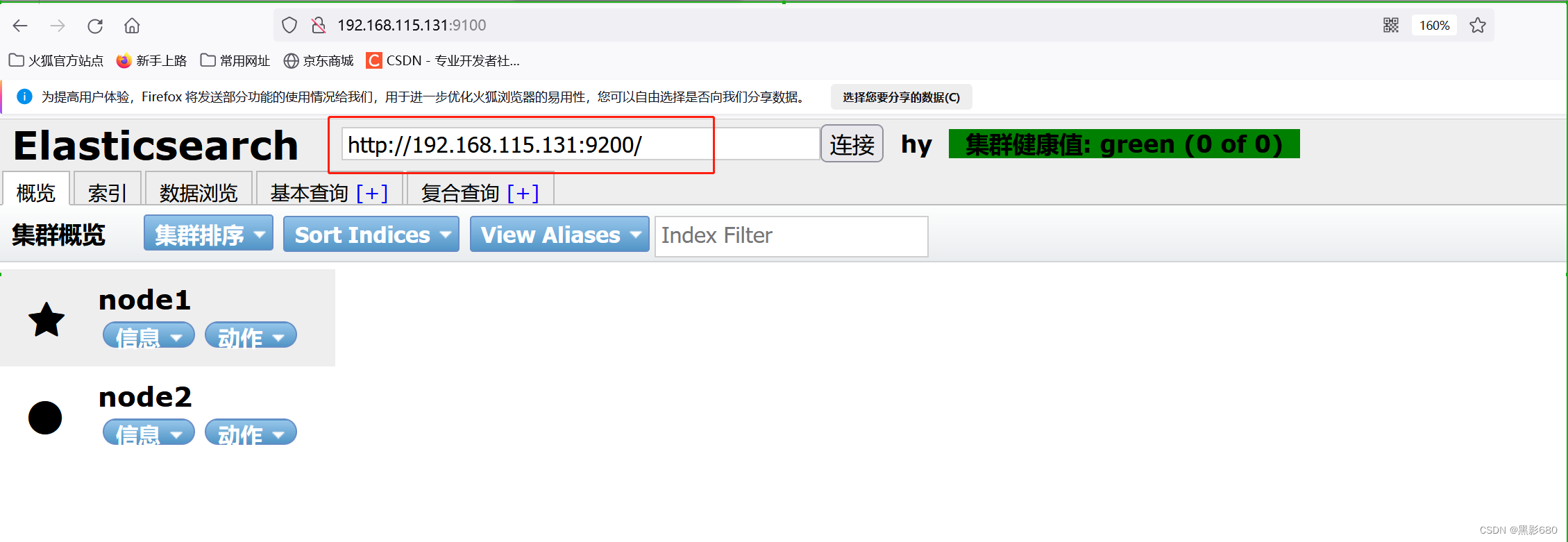
 4.2、访问192.168.115.136:9100
4.2、访问192.168.115.136:9100
5、测试输入
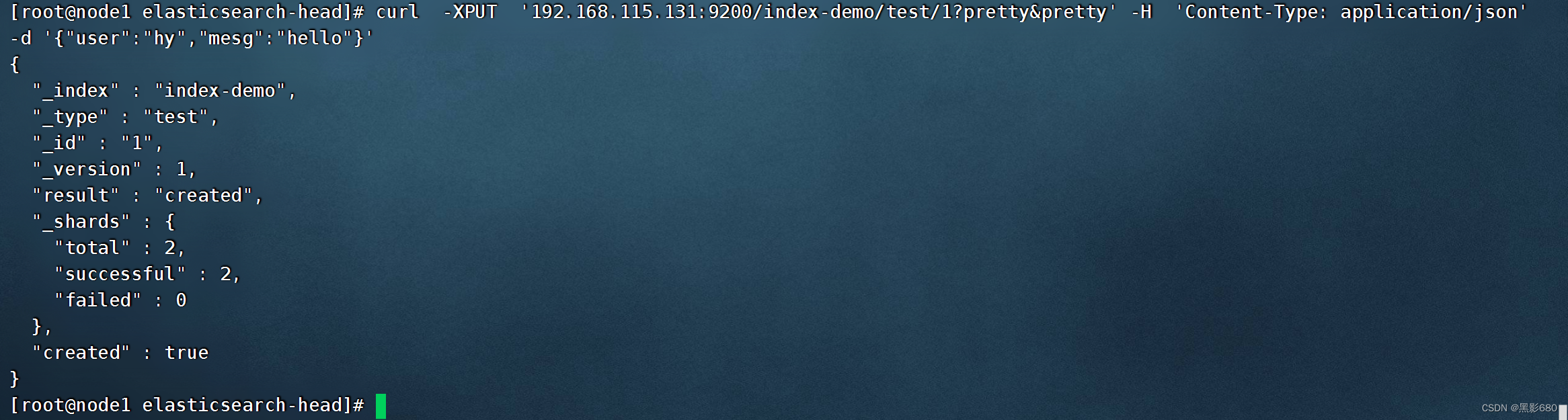
5.1、curl -XPUT '192.168.115.131:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"hy","mesg":"hello"}
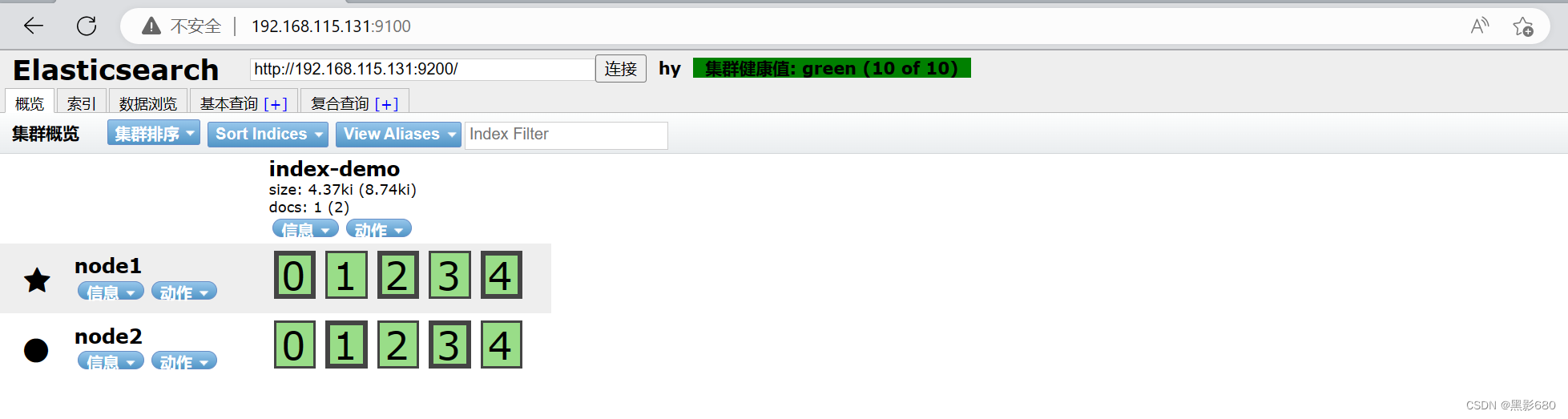
访问192.168.115.131:9100可以看到我们的测试数据 “hy hello”

6、node1服务器安装logstash
cd elk
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
In -s /usr/share/logstash/bin/logstash /usr/local/bin/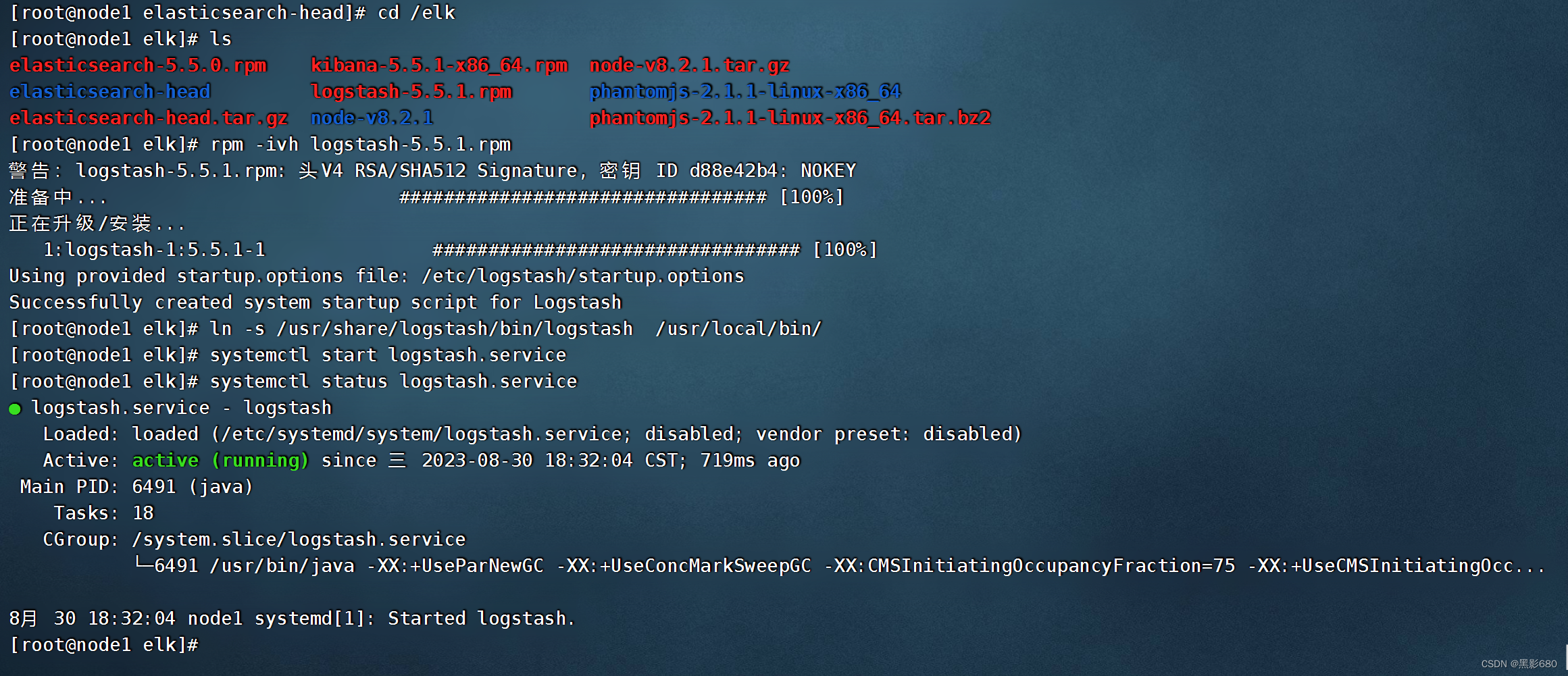
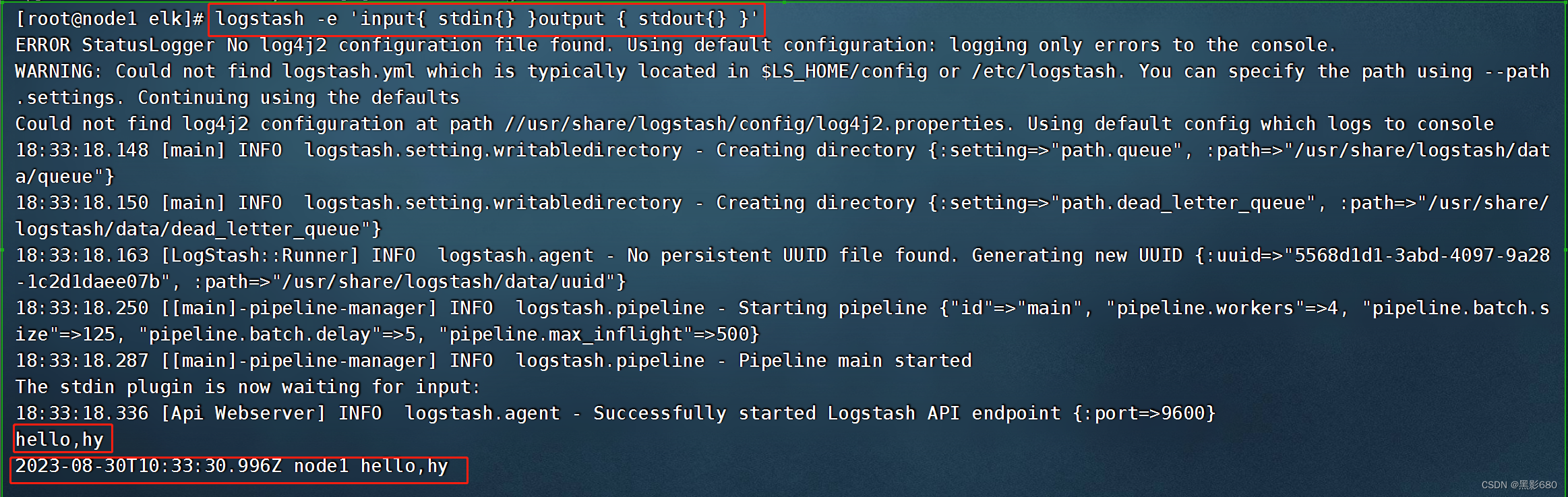
测试1: 标准输入与输出logstash -e 'input{ stdin{} }output { stdout{} }'
测试2: 使用rubydebug解码logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'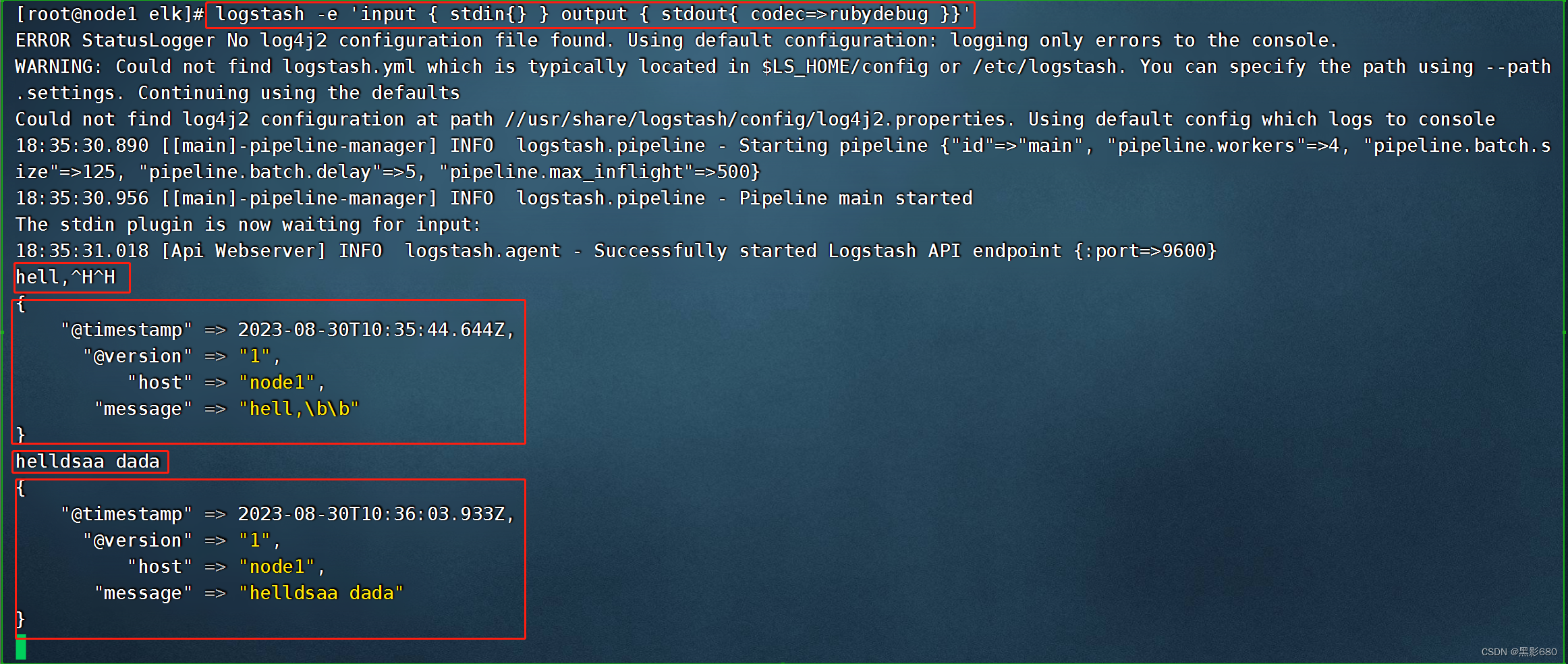
测试3:输出到elasticsearch
logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>["192.168.115.131:9200"]} }'
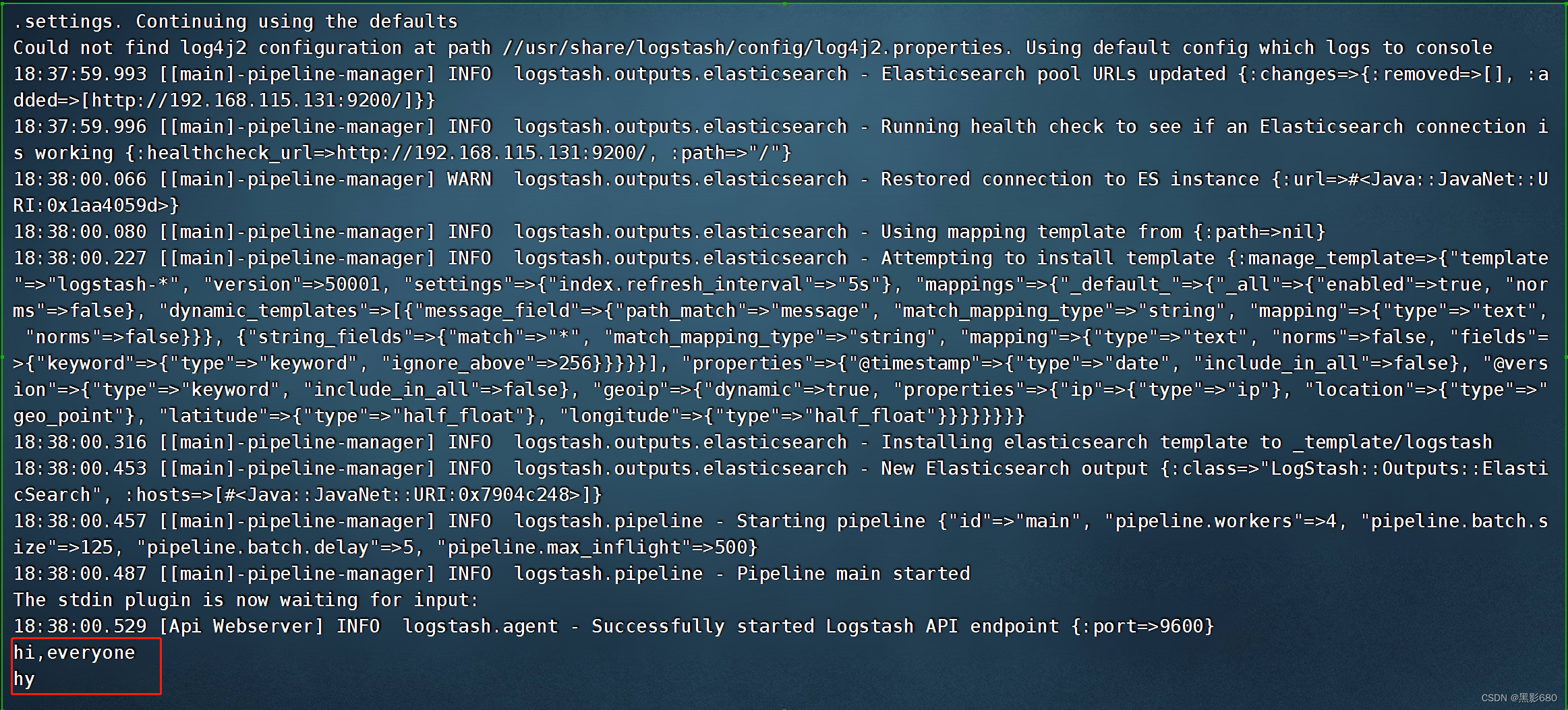
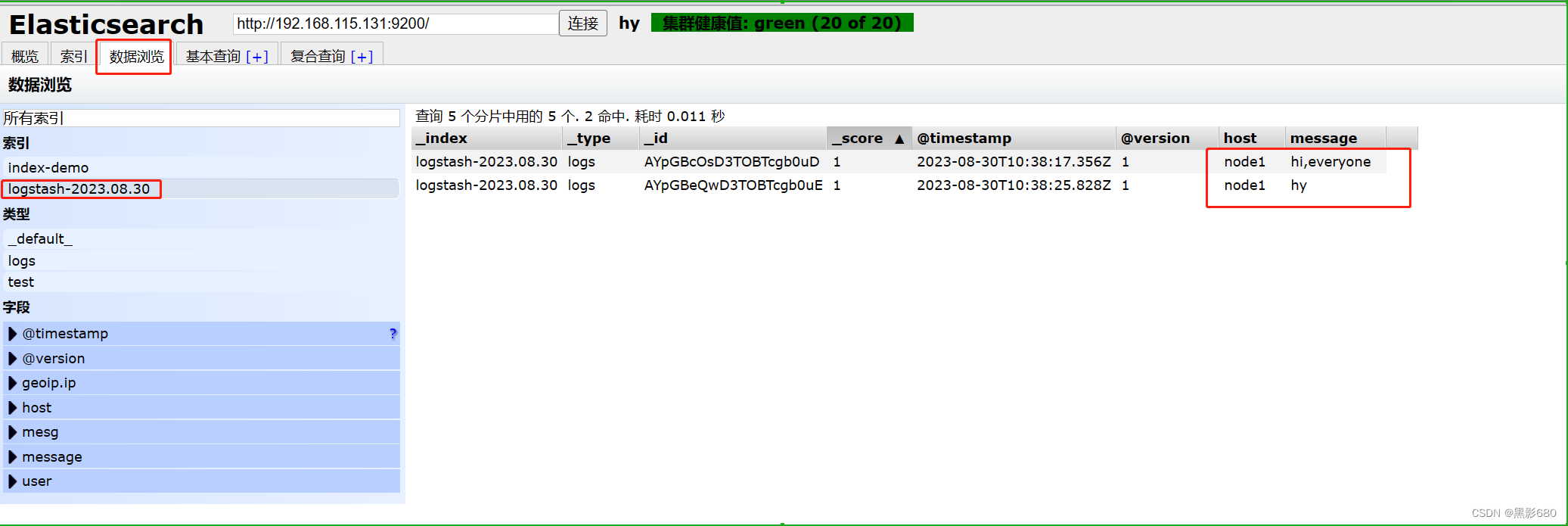
OK,测试完了,我们去192.168.115.131:9100查看一下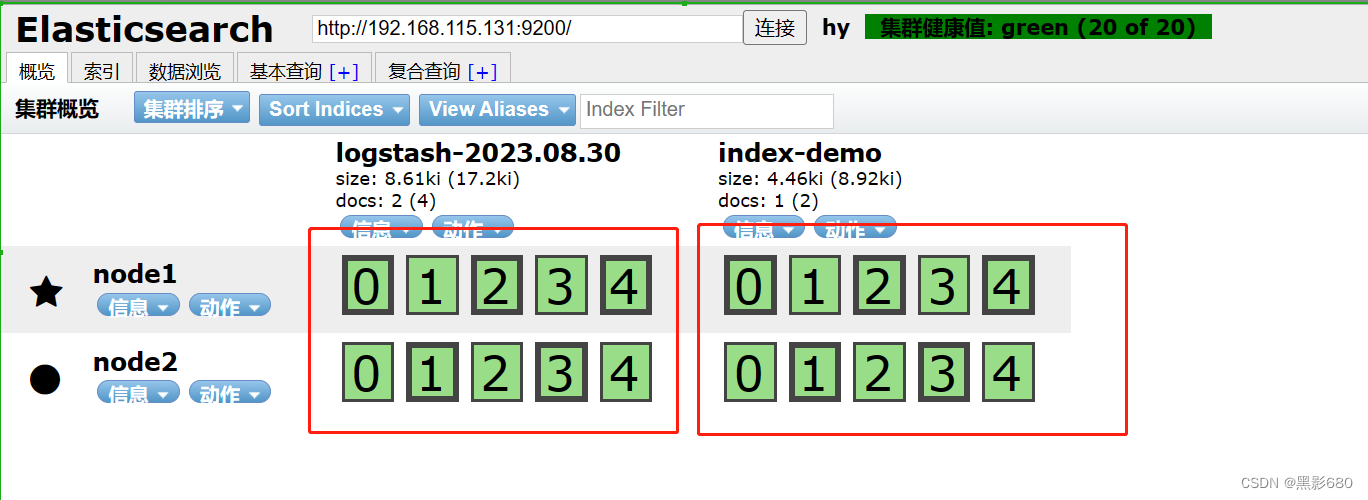
elasticsearch已经在分析了,这就是测得内容而且多了一个索引了
7、logstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
7.1、介绍
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}7.2、配置
通过logstash收集系统信息日志
##因为要收集日志,root用户可以操作,其他用户是没权限的,所以加个读取的权限,否则是收集不到日志的
chmod o+r /var/log/messagesvim /etc/logstash/conf.d/system.conf
##system.conf是自定义的因为我搜集的是系统日志,若其他的应用的话可以取对应的名字来作为区分
##插入
input {
file{ ##类型:文件
path =>"/var/log/messages" ##系统日志文件路径
type => "system" ##类型自定义
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.115.131:9200"] ##给谁处理
index => "system-%{+YYYY.MM.dd}" ##自定义索引
}
}
重启日志服务: systemctl restart logstash
浏览器查看 192.168.115.131:9100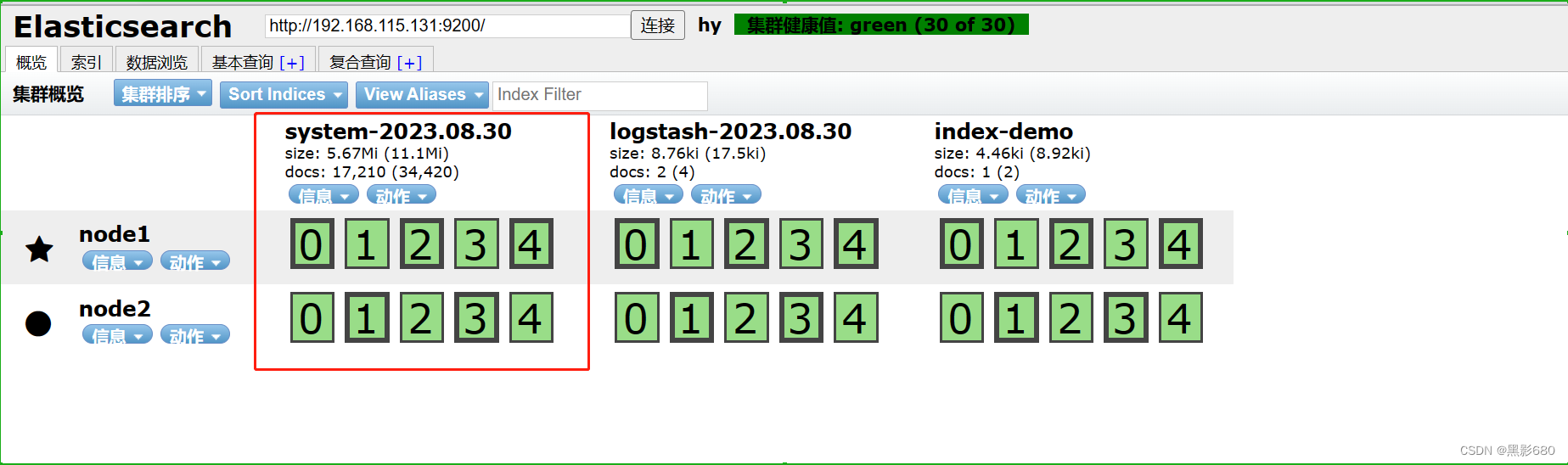
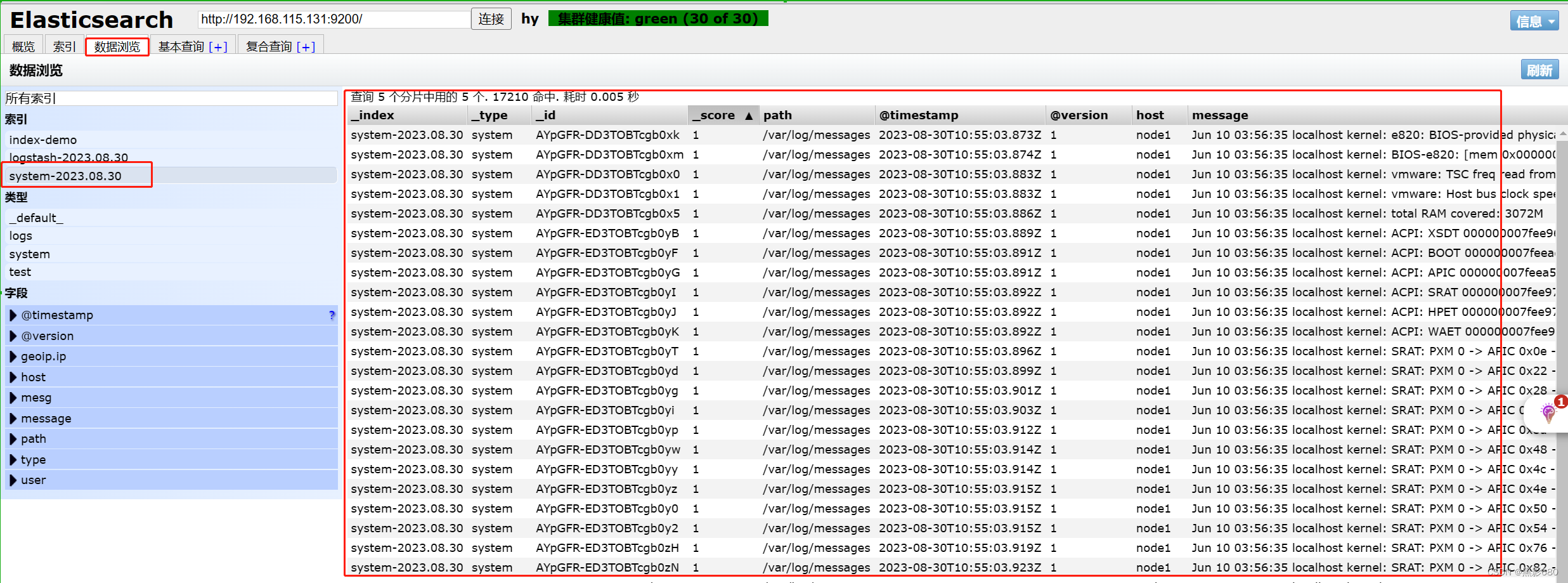
8、node1节点安装kibana
8.1、安装配置
####安装kibana
cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm
##配置kibana
vim /etc/kibana/kibana.yml
server.port:5601 #Kibana打开的端口
server.host:"0.0.0.0" #Kibana侦听的地址
elasticsearch.url: "http://192.168.115.131:9200" #和Elasticsearch 建立连接
kibana.index:".kibana" #在Elasticsearch中添加.kibana索引##启动kibana
systemctl start kibana8.2、访问kibana
访问192.168.115.131:9100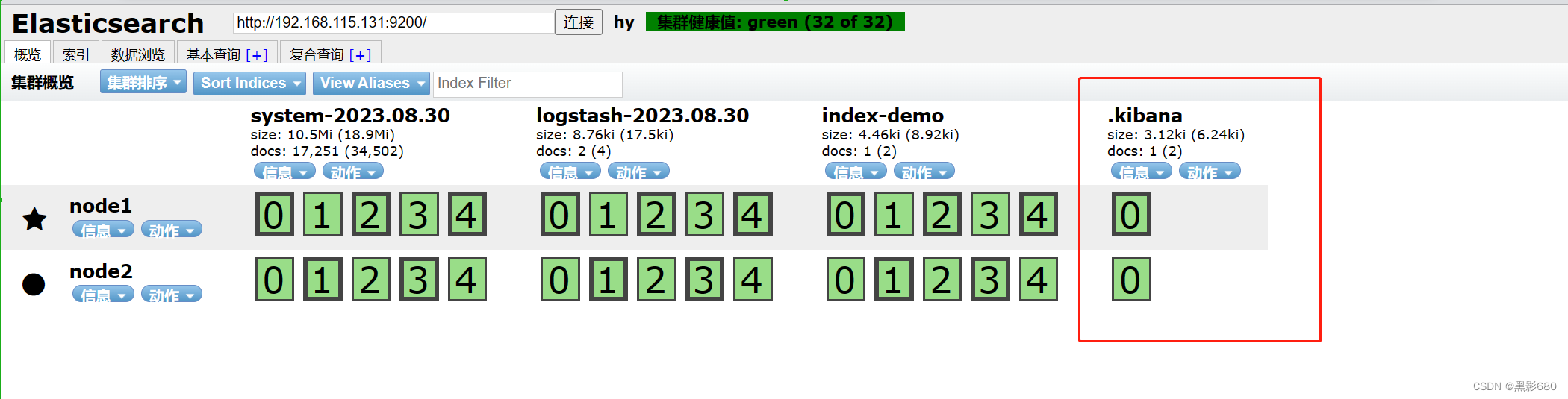
访问192.168.115.131:5601 可以添加索引,可以添加上图中有的索引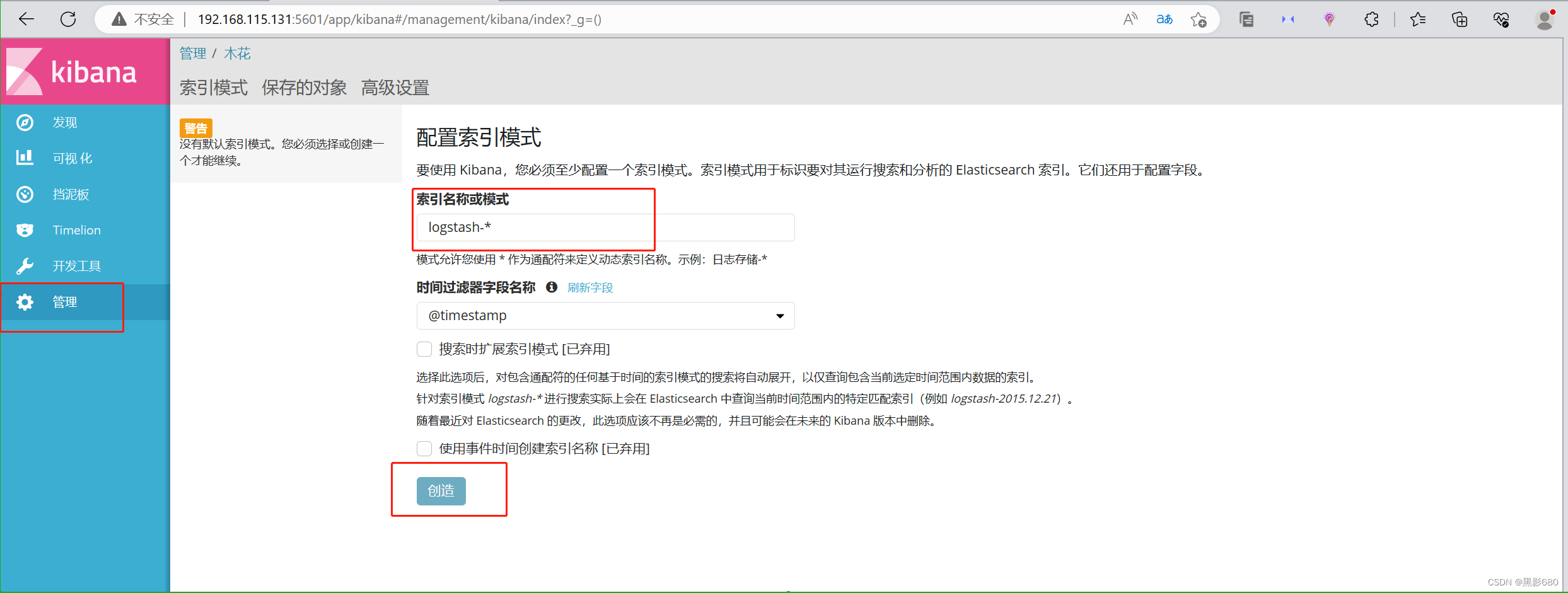
这里我添加一个系统的索引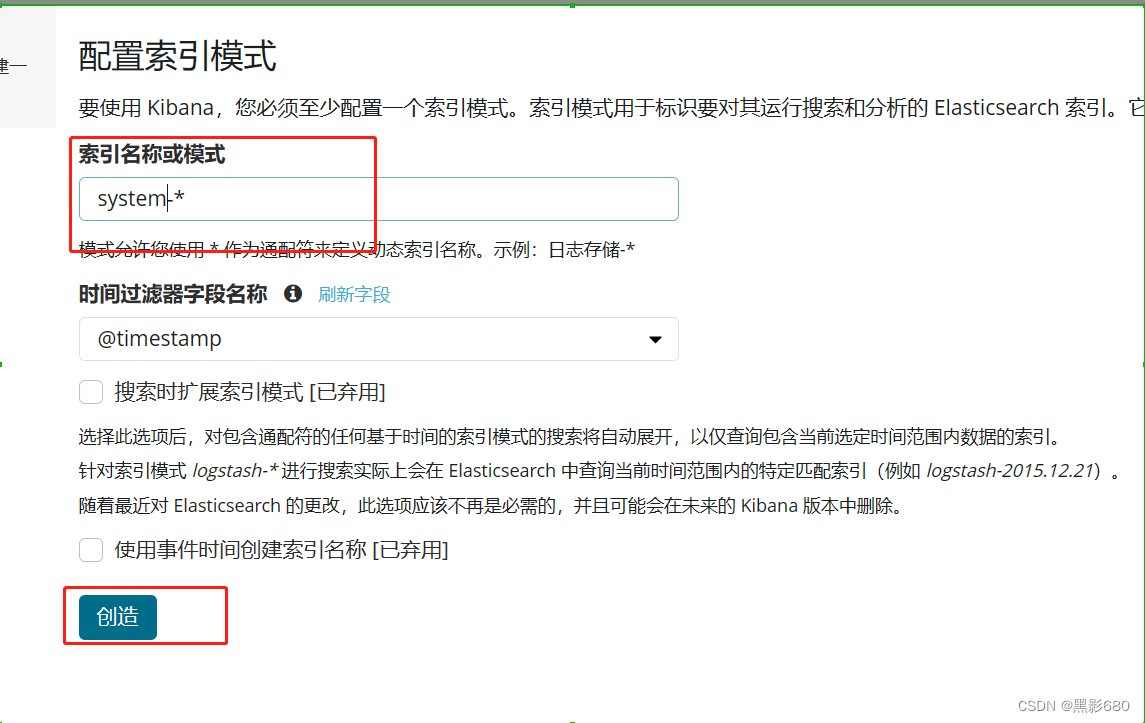
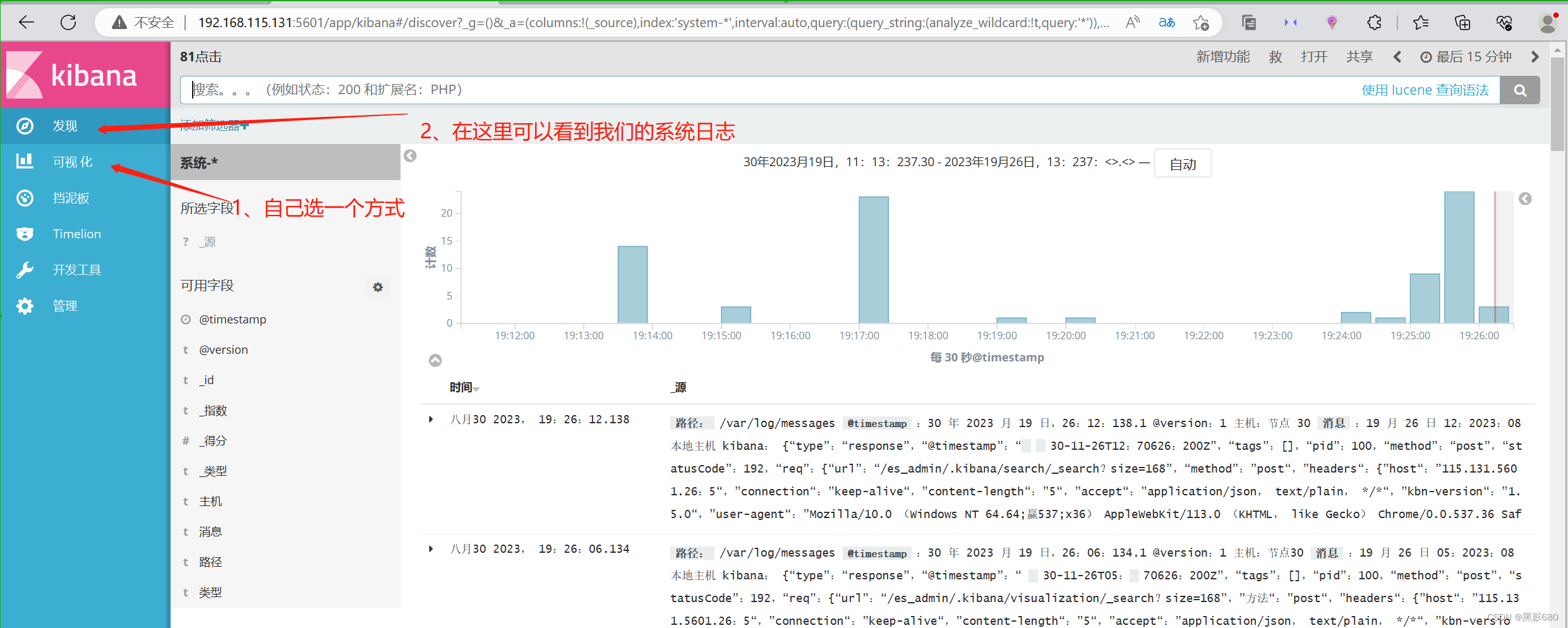
五、配置http节点
1、配置192.168.115.140的http服务
yum -y install httpd
systemctl start httpd
netstat -anput | grep 80访问httpd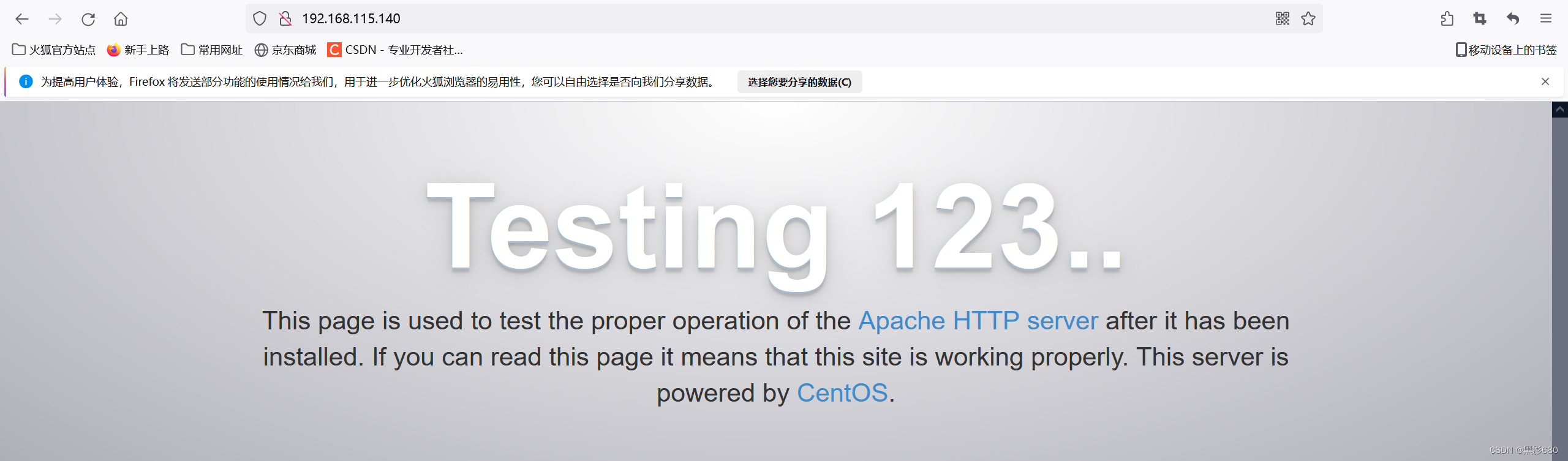
2.在此节点上配置我们的logstash来收集我们的http服务器的访问日志
http访问日志的路径/var/log/httpd/access_log
##安装logstash
rpm -ivh logstash-5.5.1.rpm3、修改配置文件
vim /etc/logstash/conf.d/httpd.conf
###插入
input {
file{ ##类型:文件
path =>"/var/log/httpd/access_log" ##系统日志文件路径
type => "access" ##类型自定义
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.115.131:9200"] ##给谁处理
index => "httpd-%{+YYYY.MM.dd}" ##自定义索引
}
}
启动日志收集systemctl start logstash.service
使用logstash命令导入配置:
创建软连接In -s /usr/share/logstash/bin/logstash /usr/local/bin/
导入logstash -f /etc/logstash/conf.d/httpd.conf
4、访问192.168.115.131:9200

kibana 192.168.115.131:5601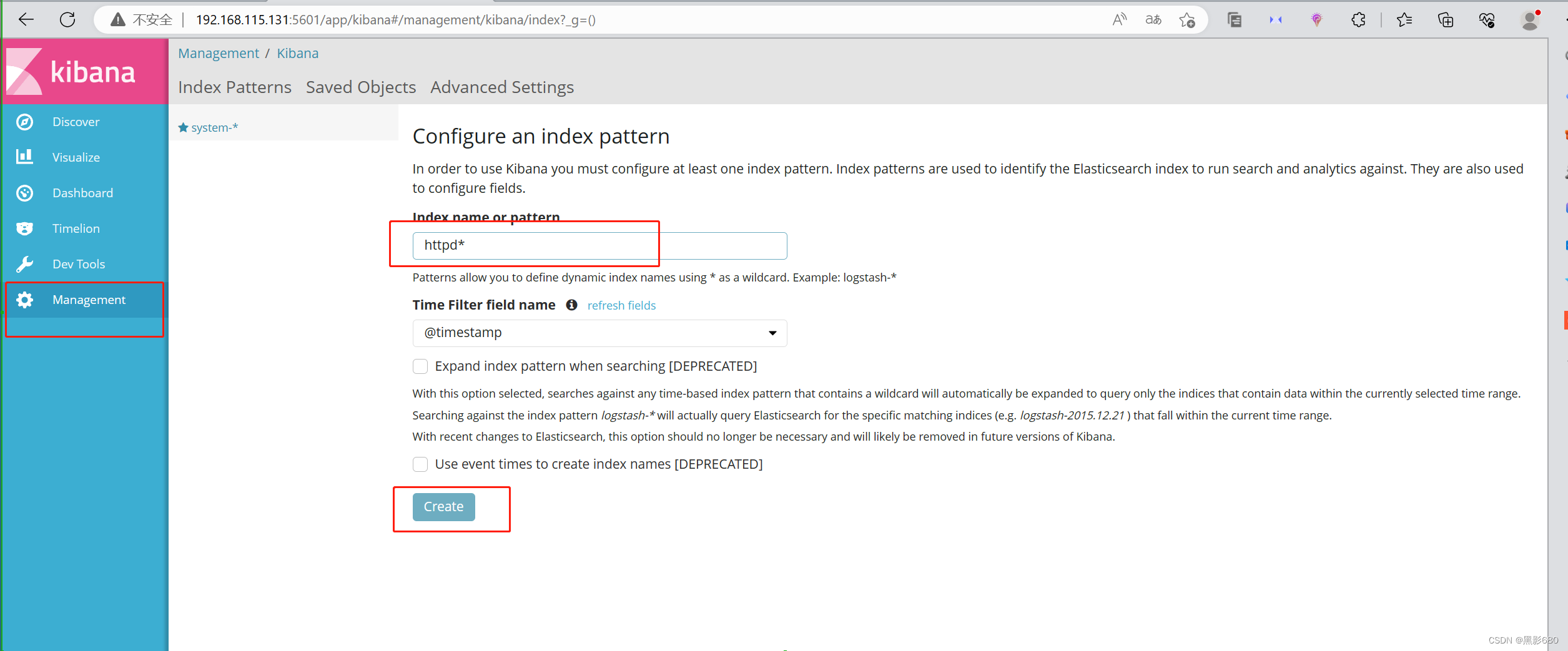
查看httpd的访问日志情况
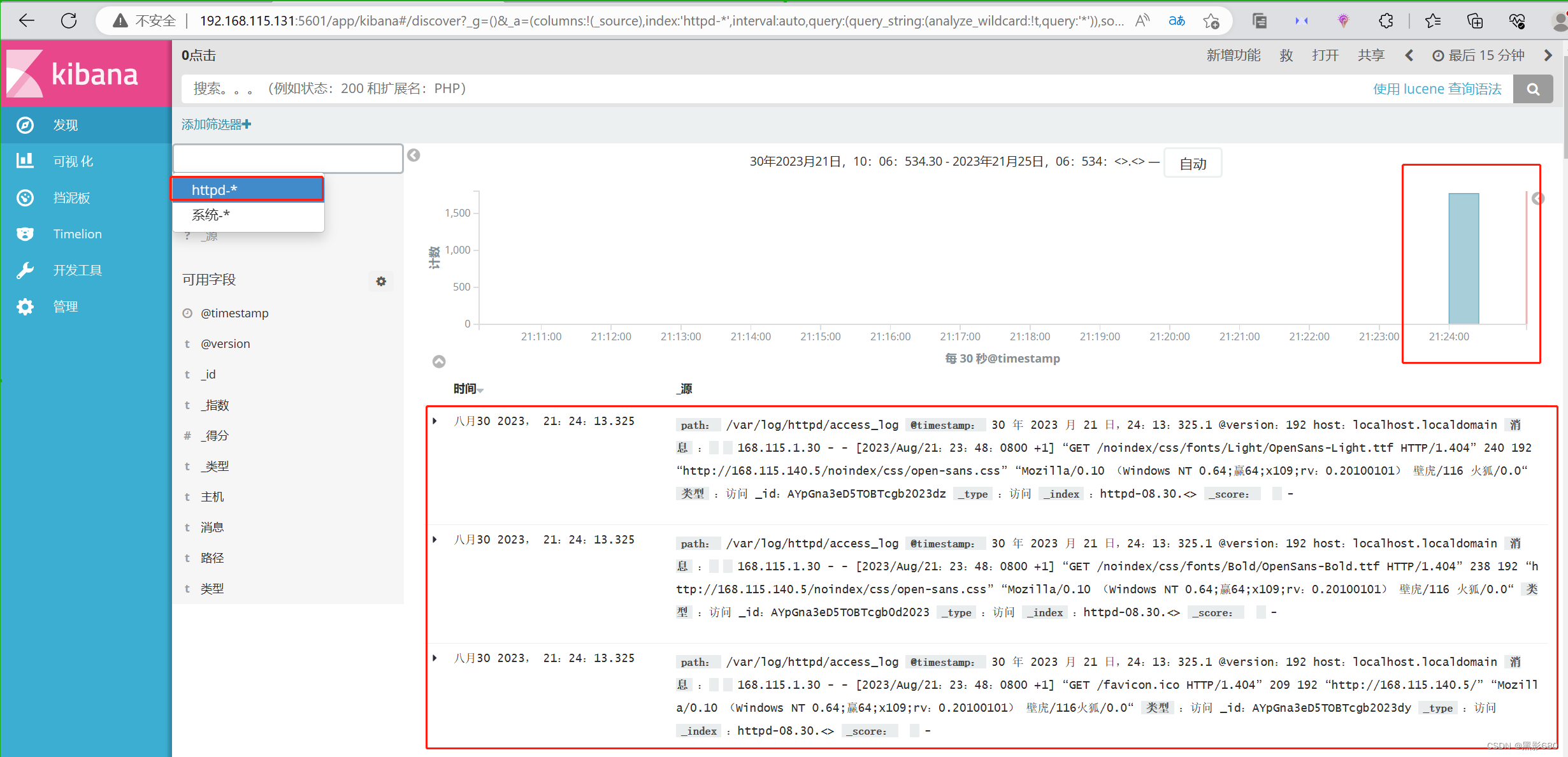
OK,至此实验结束
相关文章:
ELK日志收集系统集群实验(5.5.0版)
目录 前言 一、概述 二、组件介绍 1、elasticsearch 2、logstash 3、kibana 三、架构类型 四、ELK日志收集集群实验 1、实验拓扑 2、在node1和node2节点安装elasticsearch 3、启动elasticsearch服务 4、在node1安装elasticsearch-head插件 5、测试输入 6、node1服…...
基于java swing和mysql实现的电影票购票管理系统(源码+数据库+运行指导视频)
一、项目简介 本项目是一套基于java swing和mysql实现的电影票购票管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。 包含:项目源码、项目文档、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都…...

数据结构--6.0最短路径
目录 一、迪杰斯特拉算法(Dijkstra) 二、弗洛伊德算法(Floyd) 在网图和非网图中,最短路径的含义是不同的。 ——网图是两顶点经过的边上的权值之和最少的路径。 …...

Docker进阶:mysql 主从复制、redis集群3主3从【扩缩容案例】
Docker进阶:mysql 主从复制、redis集群3主3从【扩缩容案例】 一、Docker常规软件安装1.1 docker 安装 tomcat(默认最新版)1.2 docker 指定安装 tomcat8.01.3 docker 安装 mysql 5.7(数据卷配置)1.4 演示--删除mysql容器…...

遗传算法决策变量降维的matlab实现
1.案例背景 1.1遗传算法概述 遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。它最初由美国Michigan大学的J. Holland教授提出,1967年, Holland 教授的学生 Bagley在其博士论文中首次提出了“遗传…...

基于Open3D和PyTorch3D读取三维数据格式OBJ
本节将讨论另一种广泛使用的3D数据文件格式,即OBJ文件格式。OBJ文件格式最初由Wavefront Technologies Inc.开发。与PLY文件格式类似,OBJ格式也有ASCII版本和二进制版本。二进制版本是专有的且未记录文档。本章主要讨论ASCII版本。 与之前类似,将通过示例来学习文件格式。第…...

带纽扣电池产品出口澳洲安全标准,纽扣电池IEC 60086认证
澳大利亚政府公布了《消费品(纽扣/硬币电池)安全标准》和《消费品(纽扣/硬币电池)信息标准》。届时出口纽扣/硬币电池以及含有纽扣/硬币电池产品到澳大利亚的供应商,必须遵守这些标准中的要求。 一、 安全标准及信息标…...
spring高级源码50讲-37-42(springBoot)
Boot 37) Boot 骨架项目 如果是 linux 环境,用以下命令即可获取 spring boot 的骨架 pom.xml curl -G https://start.spring.io/pom.xml -d dependenciesweb,mysql,mybatis -o pom.xml也可以使用 Postman 等工具实现 若想获取更多用法,请参考 curl …...
腾讯云、阿里云、华为云便宜云服务器活动整理汇总
云服务器的选择是一个很重要的事情,避免产生不必要的麻烦,建议选择互联网大厂提供的云计算服务,腾讯云、阿里云、华为云就是一个很不错的选择,云服务器稳定性、安全性以及售后各方面都更受用户认可,下面小编给大家整理…...
 测试点全过)
L1-055 谁是赢家(Python实现) 测试点全过
前言: {\color{Blue}前言:} 前言: 本系列题使用的是,“PTA中的团体程序设计天梯赛——练习集”的题库,难度有L1、L2、L3三个等级,分别对应团体程序设计天梯赛的三个难度。更新取决于题目的难度,…...
开发一个npm包
1 注册一个npm账号 npm https://www.npmjs.com/ 2 初始化一个npm 项目 npm init -y3编写一段代码 function fn(){return 12 }exports.hellofn;4发布到全局node_module npm install . -g5测试代码 创建一个text文件 npm link heath_apisnode index.js6登录(我默认的 https…...
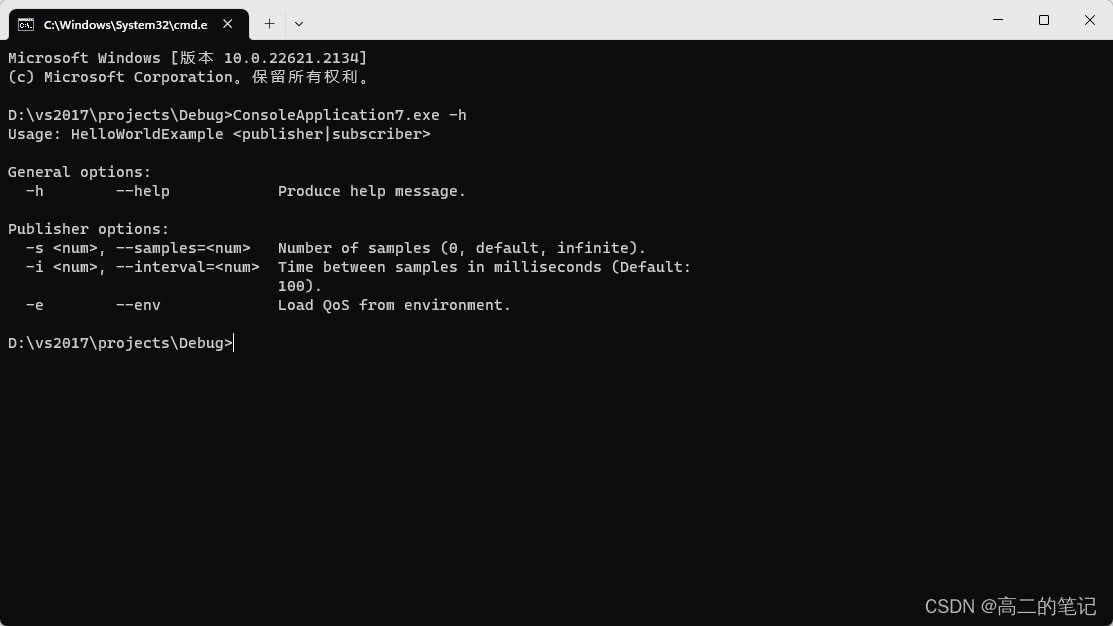
介绍几种使用工具
FileWatch,观测文件变化,源码地址:https://github.com/ThomasMonkman/filewatch nlohmann::json,json封装解析,源码地址:https://github.com/nlohmann/json optionparser,解析选项,源…...

Vue:关于声明式导航中的 跳转、高亮、以及两个类名的定制
声明式导航-导航链接 文章目录 声明式导航-导航链接router-link的两大特点(能跳转、能高亮)声明式导航-两个类名定制两个高亮类名 实现导航高亮,实现方式其实,css,JavaScript , Vue ,都可以实现。其实关于路由导航&…...

Sharding-JDBC分库分表-自动配置与分片规则加载原理-3
Sharding JDBC自动配置的原理 与所有starter一样,shardingsphere-jdbc-core-spring-boot-starter也是通过SPI自动配置的原理实现分库分表配置加载,spring.factories文件中的自动配置类shardingsphere-jdbc-core-spring-boot-starter功不可没,…...

E8267D 是德科技矢量信号发生器
描述 最先进的微波信号发生器 安捷伦E8267D PSG矢量信号发生器是业界首款集成式微波矢量信号发生器,I/Q调制最高可达44 GHz,典型输出功率为23 dBm,最高可达20 GHz,对于10 GHz信号,10 kHz偏移时的相位噪声为-120 dBc/…...

Git git fetch 和 git pull 区别
git pull和git fetch的作用都是用于从远程仓库获取最新代码,但它们之间有一些区别。 git pull会自动执行两个操作:git fetch和git merge。它从远程仓库获取最新代码,并将其合并到当前分支中。 示例:运行git pull origin master会从…...

软件UI工程师工作的岗位职责(合集)
软件UI工程师工作的岗位职责1 职责: 1.负责产品的UI视觉设计(手机软件界面 网站界面 图标设计产品广告及 企业文化的创意设计等); 2.负责公司各种客户端软件客户端的UE/UI界面及相关图标制作; 3.设定产品界面的整体视觉风格; 4.参与产品规划构思和创意过程&…...
Mac系统Anaconda环境配置Python的json库
本文介绍在Mac电脑的Anaconda环境中,配置Python语言中,用以编码、解码、处理JSON数据的json库的方法;在Windows电脑中配置json库的方法也是类似的,大家可以一并参考。 JSON(JavaScript Object Notation)是一…...

Python数据分析与数据挖掘:解析数据的力量
引言: 随着大数据时代的到来,数据分析和数据挖掘已经成为许多行业中不可或缺的一部分。在这个信息爆炸的时代,如何从大量的数据中提取有价值的信息,成为了企业和个人追求的目标。而Python作为一种强大的编程语言,提供…...
)
我的私人笔记(安装hive)
1.hive下载:Index of /dist/hive/hive-1.2.1 或者上传安装包至/opt/software:rz或winscp上传 2.解压 cd /opt/software tar -xzvf apache-hive-1.2.1-bin.tar.gz -C /opt/servers/ 3.重命名 mv apache-hive-1.2.1-bin hive 4.配置环境变量 vi /etc/…...

Bambu Studio 3D打印切片实战指南:从技术原理到场景应用
Bambu Studio 3D打印切片实战指南:从技术原理到场景应用 【免费下载链接】BambuStudio PC Software for BambuLab and other 3D printers 项目地址: https://gitcode.com/GitHub_Trending/ba/BambuStudio Bambu Studio作为一款专为3D打印优化的开源切片软件&…...

霜儿-汉服-造相Z-Turbo作品集:看看AI能生成多美的汉服少女图
霜儿-汉服-造相Z-Turbo作品集:看看AI能生成多美的汉服少女图 1. 惊艳开篇:AI汉服艺术的魅力 当传统汉服遇上现代AI技术,会碰撞出怎样的火花?霜儿-汉服-造相Z-Turbo给出了令人惊叹的答案。这个基于Xinference部署的文生图模型服务…...

Cursor AI Pro终极解锁指南:告别试用限制的专业解决方案
Cursor AI Pro终极解锁指南:告别试用限制的专业解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

SenseVoice-small实战教程:导出SRT/VTT字幕文件用于Premiere剪辑
SenseVoice-small实战教程:导出SRT/VTT字幕文件用于Premiere剪辑 你是不是经常遇到这样的烦恼?录了一段视频,或者拿到一段会议录音,想要给它配上精准的字幕,却发现自己要花几个小时去听写、校对、打时间轴?…...

SuperSplat部署完全指南:从开发到生产环境的终极教程
SuperSplat部署完全指南:从开发到生产环境的终极教程 【免费下载链接】super-splat 3D Gaussian Splat Editor 项目地址: https://gitcode.com/gh_mirrors/su/super-splat SuperSplat是一款基于Web的免费开源3D高斯泼溅编辑器,专为检查、编辑、优…...

别再死记公式了!用TL072运放设计带通滤波器,调出干净正弦波的实战心得与误区盘点
TL072运放带通滤波器实战:从波形失真到纯净正弦波的调试艺术 当你第一次用TL072搭建带通滤波器时,是否也遇到过这样的场景:按照教科书上的公式计算参数,焊接好电路,示波器上却显示着畸形的波形——要么顶部扁平像被削峰…...

3种方法永久解决IDM激活弹窗问题 开源工具全解析
3种方法永久解决IDM激活弹窗问题 开源工具全解析 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script Internet Download Manager(IDM)作为一款…...

威联通NAS安全防护全攻略:10个必做设置让你的数据固若金汤
威联通NAS安全防护全攻略:10个必做设置让你的数据固若金汤 在数字化时代,数据安全已成为个人和企业最关注的议题之一。威联通NAS作为专业级网络存储设备,凭借其强大的硬件性能和丰富的软件生态,成为许多用户存储重要数据的首选。然…...

使用AIVideo实现LaTeX学术报告自动转视频教程
使用AIVideo实现LaTeX学术报告自动转视频教程 1. 引言 作为一名科研工作者,你是否曾经为了准备学术会议的视频报告而头疼?传统的视频制作需要录制、剪辑、配音等多个繁琐步骤,耗时耗力。现在,通过AIVideo这个强大的AI视频创作平…...

ncmdump:一键解锁网易云音乐NCM加密文件,实现无损格式转换
ncmdump:一键解锁网易云音乐NCM加密文件,实现无损格式转换 【免费下载链接】ncmdump ncmdump - 网易云音乐NCM转换 项目地址: https://gitcode.com/gh_mirrors/ncmdu/ncmdump 你是否曾从网易云音乐下载了喜爱的歌曲,却发现只能在特定应…...