SpringCloud(十)——ElasticSearch简单了解(一)初识ElasticSearch和RestClient
文章目录
- 1. 初始ElasticSearch
- 1.1 ElasticSearch介绍
- 1.2 安装并运行ElasticSearch
- 1.3 运行kibana
- 1.4 安装IK分词器
- 2. 操作索引库和文档
- 2.1 mapping属性
- 2.2 创建索引库
- 2.3 对索引库的查、删、改
- 2.4 操作文档
- 3. RestClient
- 3.1 初始化RestClient
- 3.2 操作索引库
- 3.3 操作文档
1. 初始ElasticSearch
1.1 ElasticSearch介绍
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
ElasticSearch中有一些新的概念,这里我们对应于MySQL数据库中的一些概念来对其进行讲解,可能会有更好的效果。
| MySQL | ElasticSearch | 说明 |
|---|---|---|
| Table | Index | 索引,就是文档的集合,类似于数据库中的表 |
| Row | Document | 文档,就是一条条的数据,类似数据库中的一行,文档都是JSON形式 |
| Column | Field | 字段,就是JSON中的字段名,类似数据库中的列 |
| Schema | Mapping | Mapping是索引中文档的约束,例如字段类型约束,类似数据库的表结构 |
| SQL | DSL | DSL是ElasticSearch提供的JSON风格的请求语句,用于操作ElasticSearch |
1.2 安装并运行ElasticSearch
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
然后使用elasticsearch的7.12.1版本的镜像,直接pull。
pull elasticsearch:7.12.1
如果需要运行es并进行单点部署,那么命令如下:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":前一个是设置初始堆的大小,后一个设置最大堆的大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置,暴露的HTTP请求的端口-p 9300:9300:端口映射配置,暴露ElasticSearch互联的端口
访问虚拟机地址的9200端口,如果出现以下页面,说明配置成功,

1.3 运行kibana
kibana可以给我们提供一个ElasticSearch的可视化界面,方便我们学习,运行如下代码表示运行一个kibana,
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-p 5601:5601:端口映射配置
之后等待其部署完毕后,访问虚拟机的5601端口,发现乳腺的界面表示启动成功,

1.4 安装IK分词器
在ElasticSearch中,我们常常需要用到分词的操作,英文还好,其自带的就可以进行分词,但是中文,其只会按照逐字的方式对词进行划分,这显然是并不友好的,因此,我们需要安装一个专门的分词器来对中文进行分词。
安装IK分词器的步骤如下:
# 进入容器内部
docker exec -it es /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit#重启容器
docker restart es
打开kibana中的目录,找到Dev tools,

在其中输入DSL查询语句进行分词。
# 测试分词器
POST /_analyze
{"text": "我们ikun不惹事,但也不怕事","analyzer": "ik_smart"#分词的模式
}
分词结果如下:

还有一种分词模式是 ik_max_word ,能够按照最细粒度去进行分词,更加占用内存空间。
2. 操作索引库和文档
2.1 mapping属性
mapping属性相当于就是数据库的字段约束,主要常用的mapping属性约束如下:
- type:字段数据类型,常见的简单类型如下:
- 字符串:text(客分词的文本),keyword(精确值,如国家、品牌,ip)
- 数值: long, integer, short, byte, double, float
- 布尔值:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
2.2 创建索引库
了解了mapping约束后,我们就可以开始创建索引了,创建索引库的语法如下:
PUT /索引库名
创建索引也就是创建每一个字段的约束条件,与数据库类似,我们创建一个名为 ikun 的索引,索引如下:
PUT /ikun
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstName": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}
执行后显示的结果如下,表明创建成功:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "ikun"
}
2.3 对索引库的查、删、改
查询索引库的语法如下:
GET /索引库名
删除索引库的语法如下:
DELETE /索引库名
需要注意的是,索引库一经创建就不允许进行修改,但是,我们可以对原来的索引库进行新增,语法如下:
PUT /索引库名/_mapping
{ "properties": { "新字段名":{ "type": "integer" } }
}
2.4 操作文档
在索引库中插入文档相当于在数据库的表结构中增加一行数据。
新增文档的DSL语法如下:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4",}
}
文档id如果没有指定的话,会随机生成。
比如我们对上面创建的索引库进行新增如下:
POST /ikun/_doc/1
{"info": "我们ikun不惹事,但也不怕事","email": "snow@gmail.com","name": {"firstName": "i","lastName": "kun"}
}
查看文档的语法为:
GET /ikun/_doc/1
删除文档的语法为:
DELETE /ikun/_doc/1
修改文档有两种方法。
一种是全量修改,其会首先找到旧的文档,将旧的文档进行删除,然后将修改的再添加进去。如果旧的文档不存在,这种方法还是会进行新增。语法如下:
PUT /索引库名/_doc/1
{"字段1": "值1","字段2": "值2",
}
还有一种是增量修改,只会修改指定的字段,语法如下:
POST /索引库名/_update/文档id
{"doc": {"字段名": "新的值"}
}
比如我们修改上面的文档1的邮箱可以为:
POST /ikun/_update/1
{"doc": {"email": "snowsnow@gmail.com"}
}
3. RestClient
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES,这里我们要学习的就是java中调用RestClient。
我们的数据库数据结构如下所示,

故我们构建索引库的代码如下:
PUT /hotel
{"mappings": {"properties": {"id": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address": {"type": "keyword","index": false},"price": {"type": "integer"},"score": {"type": "integer"},"brand": {"type": "keyword","copy_to": "all"},"city": {"type": "keyword"},"starName": {"type": "keyword"},"bussiness": {"type": "keyword","copy_to": "all"},"location": {"type": "geo_point"},"pic": {"type": "keyword","index": false},"all": {"type": "text","analyzer": "ik_max_word"}}}
}
在ElasticSearch中,对经纬度专门指定了一个结构 geo_point ,这里面能够存储经度和纬度的结构,除此之外,上面的 copy_to 字段是对字段进行联合索引的时候使用的。比如在上面我们需要对 name 属性和 brand 属性就行搜索,一般是先搜索符合的 name ,再到结果集里面搜索符合条件的 brand ,这样显然非常麻烦,而加入了一个 copy_to 字段后,便可以将该属性复制一份到 all 属性中,当然, all 属性并不存在与索引的 suorce 里面,此后,如果我们需要查询符合条件的 name 和 brand 时,只需要查询 all 属性即可。
那怎么在java中操作RestClient客户端呢?
3.1 初始化RestClient
首先是引入依赖,需要引入如下的依赖:
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
<dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependencies>
由于SpringBoot在父maven中已经定义了ElasticSearch的版本号,所以改版本的时候需要在 properties 标签中覆盖父pom定义的版本号。
之后就是初始化RestClient了。
如果我们对每一个类都要创建和销毁RestClient客户端的话,那就显得太过麻烦了,我们可以将创建和销毁写作一个Ioc切面,在每一个Bean创建之前切入并创建客户端,在每一个Bean执行后切入并销毁客户端,具体代码如下:
public class HotelIndexTest {private RestHighLevelClient restHighLevelClient;@BeforeEachvoid setup(){this.restHighLevelClient = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.59.233:9200")));}@AfterEachvoid teardown() throws IOException {this.restHighLevelClient.close();}
}
3.2 操作索引库
- 创建索引库
@Testvoid createHotelIndex() throws IOException {//1.创建Request对象,索引坤名称为ikunCreateIndexRequest request = new CreateIndexRequest("ikun");//2.准备请求参数,即DSL语句,第一个参数为DSL语句,第二个参数指定为JSON形式request.source("{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"kunName\": {\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_smart\"\n" +" }\n" +" }\n" +" }\n" +"}", XContentType.JSON);//3.发送请求restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);} - 删除索引库
@Testvoid DeleteHotelIndex() throws IOException {//1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("ikun");restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);} - 判断索引库是否存在
@Testvoid ExistHotelIndex() throws IOException {//1.创建Request对象GetIndexRequest request = new GetIndexRequest("ikun");boolean exist = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);System.out.println(exist);}
3.3 操作文档
-
增加文档
如果我们需要用RestClient进行文档的增加,那么首先我们需要的就是类型转换,我们的文档内容肯定是从数据库中进行获取,但是,数据库中的数据与索引库的数据还是有一点不一样的,那就是经纬度。在数据库中,我们定义的是经度以及纬度,但是,在索引库中,我们定义的是一个数据结构
geo_point,里面包含了经度以及纬度,所以,我们首先定义一个与索引库结构一致的类,如下:@Data @NoArgsConstructor public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();} }之后,便可以读取数据库中的信息对索引库进行文档的增加了,增加的代码如下,
@SpringBootTest public class HotelIndexTest {@Autowiredprivate IHotelService hotelService;private RestHighLevelClient restHighLevelClient;@Testvoid AddHotelDocument() throws IOException {//1.根据ID查询酒店数据Hotel hotel = hotelService.getById(61083L);//2.转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);//3.准备Request对象,其参数只接受StringIndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());//4.准备JSON文档request.source(JSON.toJSONString(hotelDoc),XContentType.JSON);//5.发送请求restHighLevelClient.index(request, RequestOptions.DEFAULT);}@BeforeEachvoid setup(){this.restHighLevelClient = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.59.233:9200")));}@AfterEachvoid teardown() throws IOException {this.restHighLevelClient.close();} } -
查询文档
@Testvoid FindHotelDocument() throws IOException {//1.准备Request对象,其参数只接受StringGetRequest request = new GetRequest("hotel", "61083");//2.发送请求得到响应GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);//3.解析相应结果,即将source字段解析为json格式的字符串String json = response.getSourceAsString();//4.将JSON格式的字符串解析为相应的对象HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);} -
更新文档
@Testvoid UpdateHotelDocument() throws IOException {//1.准备Request对象,其参数只接受StringUpdateRequest request = new UpdateRequest("hotel", "61083");//2.准备参数,特别注意,这里是逗号,没有冒号!!request.doc("price", "1001","startName", "四钻");//3.发送请求restHighLevelClient.update(request, RequestOptions.DEFAULT);} -
删除文档
@Testvoid UpdateHotelDocument() throws IOException {//1.准备Request对象,其参数只接受StringDeleteRequest request = new DeleteRequest("hotel", "61083");//2.发送请求restHighLevelClient.delete(request, RequestOptions.DEFAULT);} -
批量新增数据
@Testvoid AddMoreDocument() throws IOException {//1.批量查询数据库中的信息List<Hotel> hotels = hotelService.list();//2.创建RequestBulkRequest request = new BulkRequest();//3.准备参数,添加多个新增的Requestfor(Hotel hotel: hotels){HotelDoc hotelDoc = new HotelDoc(hotel);request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.toJSONString(hotelDoc),XContentType.JSON));}//4.发送请求restHighLevelClient.bulk(request, RequestOptions.DEFAULT);}
相关文章:
SpringCloud(十)——ElasticSearch简单了解(一)初识ElasticSearch和RestClient
文章目录 1. 初始ElasticSearch1.1 ElasticSearch介绍1.2 安装并运行ElasticSearch1.3 运行kibana1.4 安装IK分词器 2. 操作索引库和文档2.1 mapping属性2.2 创建索引库2.3 对索引库的查、删、改2.4 操作文档 3. RestClient3.1 初始化RestClient3.2 操作索引库3.3 操作文档 1. …...

CAD文字显示?问号解决
背景 从别人哪儿发过来的CAD文件,打开后发现有些文字显示为? 问题排查 通过点击文字特性得知 该文字的样式是 SF和仿宋通过命令行执行st 得知,两种样式关联的字体都是仿宋GB_2312,但当前操作系统无此字体,故显示为&…...

Calico切换网络模式无效
Calico切换网络模式无效 Calico由原先的BGP模式切换为IP IP模式发现未生效,使用的模式还是BGP模式,Calico卸载后查询Etcd发现存在很多Calico数据 [rootk8s-master-1 ~]# etcdctl get / --prefix --keys-only | grep calico /calico/ipam/v2/assignment…...
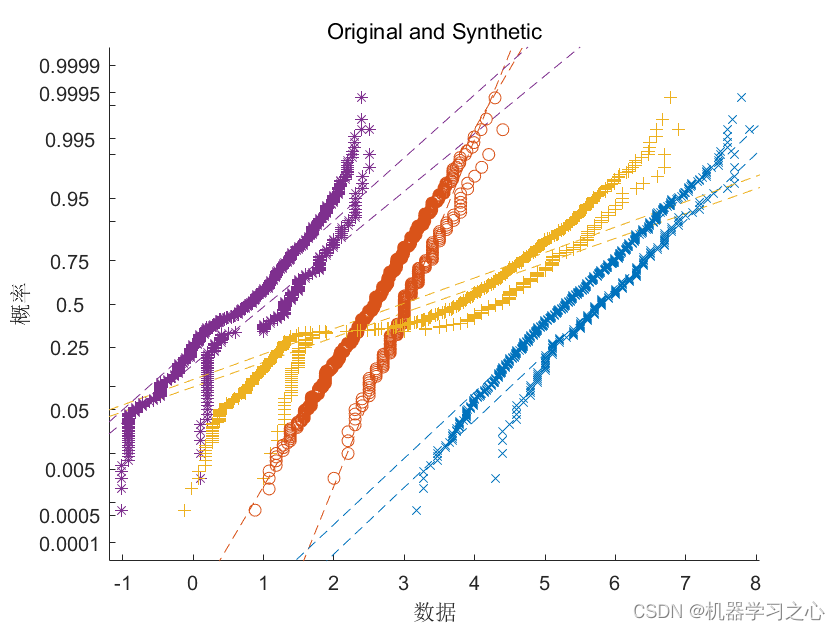
数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成
数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成 目录 数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成生成效果基本描述程序设计参考资料 生成效果 基本描述 数据生成 | MATLAB实现GAN生成对抗网络结合SVM支持向量机的数据生成。 生成对抗…...
iOS - 资源按需加载 - ODR
一、瘦身技术大图 二、On-Demand Resources 简介 将其保存管理在苹果的服务器,按需使用资源、优化包体积,实现更小的应用程序。ODR 的好处: 应用体积更小,下载更快,提升初次启动速度资源会在后台下载操作系统将会在磁…...

arduino仿真 SimulIDE1.0仿真器
SimulIDE 是一个开源的电子电路模拟器,支持模拟各种电子元器件的行为,可以帮助电子工程师和爱好者进行电路设计和测试。以下是 SimulIDE 的安装和使用说明: 安装 SimulIDE SimulIDE 可以在 Windows、Linux 和 Mac OS X 等操作系统上安装。您…...

vue实现导出excel的多种方式
在Vue中实现导出Excel有多种方式,可以通过前端实现,也可以通过前后端配合实现。下面将详细介绍几种常用的实现方式。 1. 前端实现方式: 使用xlsx库:使用xlsx库可以在前端将数据导出为Excel文件。首先需要安装xlsx库,…...

redis实战-实现优惠券秒杀解决超卖问题
全局唯一ID 唯一ID的必要性 每个店铺都可以发布优惠券: 当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题: id的规律性太明显,容易被用户根据id的间隔来猜测…...
C语言:截断+整型提升+算数转换练习
详情关于整型提升、算数转换与截断见文章: 《C语言:整型提升》 《C语言:算数转换》 一、代码一 int main() { char a -1; signed char b -1; unsigned char c -1; printf("%d %d %d", a, b, c); return 0; } 求…...
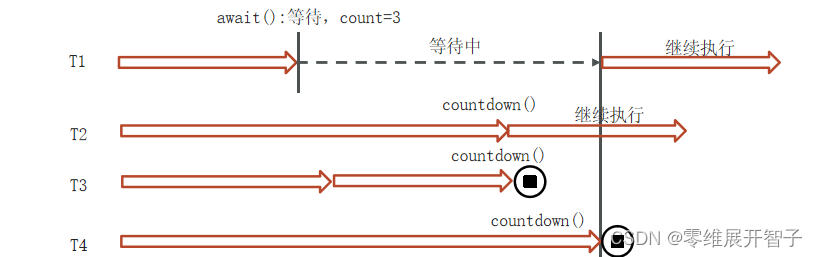
Java后端开发面试题——多线程
创建线程的方式有哪些? 继承Thread类 public class MyThread extends Thread {Overridepublic void run() {System.out.println("MyThread...run...");}public static void main(String[] args) {// 创建MyThread对象MyThread t1 new MyThread() ;MyTh…...

Redis 学习笔记
文章目录 一、简介二、下载三、安装四、启动和关闭五、配置文件六、常用指令七、安全加固 版权声明:本文为CSDN博主「杨群」的原创文章,遵循 CC 4.0 BY-SA版权协议,于2023年9月3日首发于CSDN,转载请附上原文出处链接及本声明。 原…...

华为云新生代开发者招募
开发者您好,我们是华为2012UCD的研究团队 为了解年轻开发者的开发现状和趋势 正在邀请各位先锋开发者,与我们进行2小时的线上交流(江浙沪附近可线下交流) 聊聊您日常开发工作中的产品使用需求 成功参与访谈者将获得至少300元京…...

DockerFile简明教程
需求 由于在测试环境中使用了docker官网的centos 镜像,但是该镜像里面默认没有安装ssh服务,在做测试时又需要开启ssh。所以上网也查了查资料。下面详细的纪录下。在centos 容器内安装ssh后,转成新的镜像用于后期测试使用。 镜像定制 第一种…...

Cygwin是什么?是Windows还是Linux?
原文作者:gentle_zhou 原文链接:https://bbs.huaweicloud.com/blogs/408674 最近在和客户交流的时候,一直以为客户的研发环境就是windows 7,直到和对面的研发团队交流的时候,得到的反馈是在windows 7系统上安装了Cygw…...
成集云 | 多维表格自动化管理jira Server项目 | 解决方案
源系统成集云目标系统 方案介绍 基于成集云集成平台,在多维表格中的需求任务信息自动创建、更新同步至 Jira Server 的指定项目中,实现多维表格中一表管理 Jira Server 中的项目进度。 维格表是一种新一代的团队数据协作和项目管理工具&…...

数据结构(Java实现)-排序
排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序ÿ…...

C++------vector【STL】
文章目录 vector的介绍及使用vector的介绍vector的使用 vector的模拟实现 vector的介绍及使用 vector的介绍 1、vector是表示可变大小数组的序列容器。 2、就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问和数…...
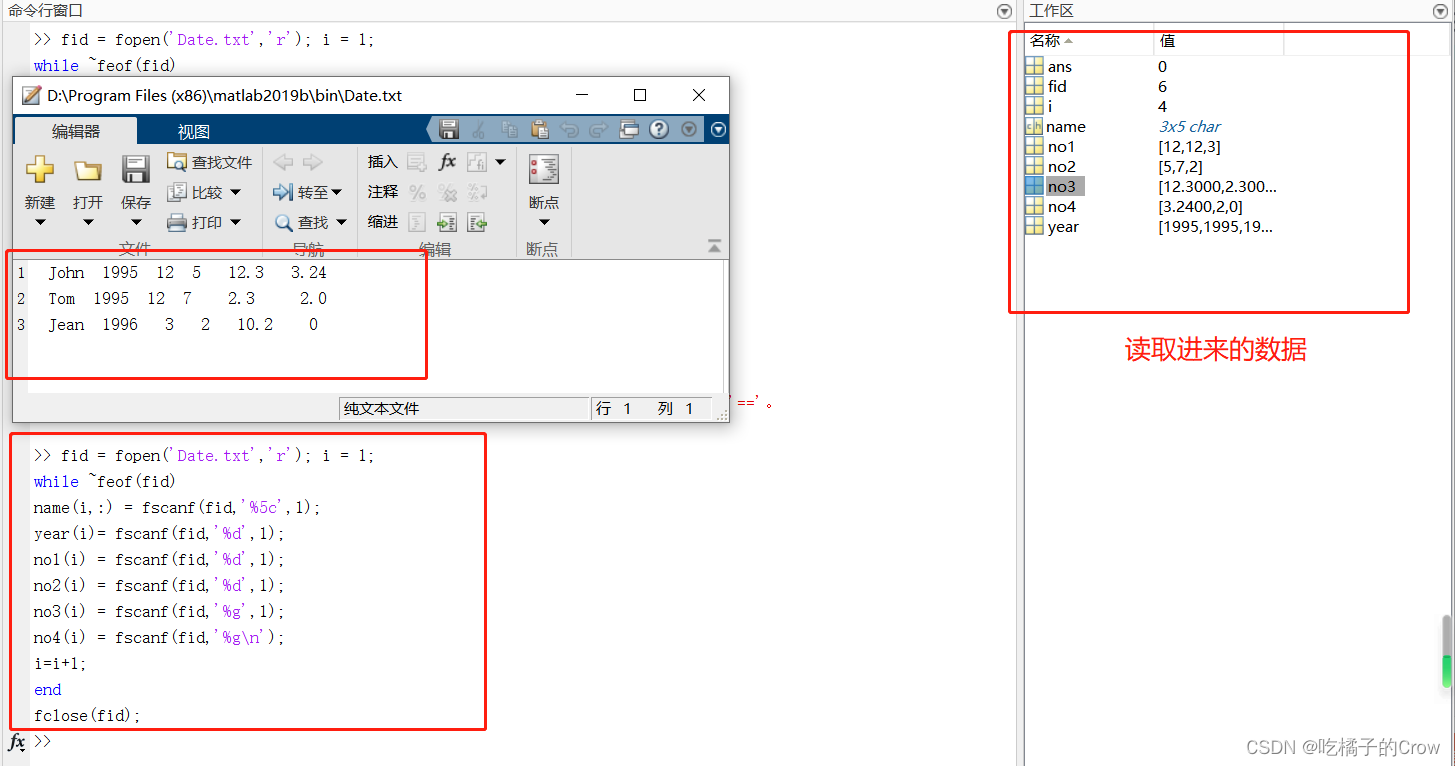
Matlab(变量与文本读取)
目录 1.变量(数据)类型转换 1.1 字符 1.2 字符串 1.3 逻辑操作与赋值 2.Struct结构体数组 2.1函数的详细介绍: 2.1.1 cell2struct 2.1.1.1 垂直维度转换 2.1.1.2 水平维度转换 2.1.1.3 部分进行转换 2.1.2 rmfield 2.1.3 fieldnames(查…...
---使用RenderBundle)
WebGPU学习(8)---使用RenderBundle
RenderBundle是什么 通常情况下,WebGPU每次绘制时都需要向RenderPassEncoder注册渲染命令。处理此绘图命令比 WebGL 内部执行的类似处理更快。但是,如果可以省略此命令注册过程,则可以能够更快地绘制。RenderBundle 就是实现这一点的。 Ren…...
【前端】常用功能合集
目录 js跳转到新标签打开PDF文件js每十个字符换行 es6用表达式或变量名作为对象的属性名 vuev-for插值、:style、:class父组件加载完后再加载子组件keep-alive缓存跨域请求第三方接口跨域请求之callback(不建议)读取本地文件浏览器播放提示音audio jquer…...

保姆级教程:用ColabFold在线版AlphaFold2,5分钟搞定你的第一个蛋白质结构预测
零门槛玩转蛋白质结构预测:ColabFold极简指南 蛋白质结构预测曾是生物信息学领域的"圣杯",直到AlphaFold2的出现彻底改变了游戏规则。但传统方法需要复杂的本地环境配置和命令行操作,让许多感兴趣的非专业人士望而却步。现在&…...

Unpaywall扩展:一键解锁学术论文的终极免费方案
Unpaywall扩展:一键解锁学术论文的终极免费方案 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unpaywall-extension …...

GME多模态向量模型实战部署:华为云ModelArts一键启动图文检索
GME多模态向量模型实战部署:华为云ModelArts一键启动图文检索 1. 引言:多模态检索的实用价值 想象一下,你正在管理一个大型数字资产库,里面有成千上万的图片和文档。当你想找"去年会议上讨论过的那张数据流程图"时&am…...

Python 3.14 JIT编译器性能调优,深度解析_pyltopt.c中6处可调优位点与GCC/Clang后端适配策略
第一章:Python 3.14 JIT编译器性能调优概览Python 3.14 引入了实验性内置 JIT(Just-In-Time)编译器,基于 LLVM 后端实现,旨在对热点函数进行动态编译优化,显著提升数值计算、循环密集型及递归场景的执行效率…...

别再画线框图了!用Axure/墨刀搞定HIS门诊医生站高保真原型的5个实战技巧
医疗HIS系统高保真原型设计:Axure/墨刀5大进阶技巧 在医疗信息化领域,门诊医生站作为HIS系统的核心模块,其原型设计的质量直接影响开发效率和最终用户体验。传统线框图已无法满足现代医疗系统复杂交互的需求,掌握Axure或墨刀的高阶…...
如何快速配置TranslucentTB:Windows任务栏美化终极教程
如何快速配置TranslucentTB:Windows任务栏美化终极教程 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要让Windows任务栏变…...

深入解析DDR3与AXI接口:基于7035开发板的实战笔记
1. DDR3基础概念与7035开发板适配 第一次接触DDR3时,我也被那些专业术语搞得晕头转向。直到在7035开发板上实际调试后,才发现理解DDR3的关键在于抓住几个核心特性。DDR3全称Double Data Rate 3,顾名思义,它在时钟上升沿和下降沿都…...

如何彻底解决ComfyUI-Manager安装难题:终极完整指南
如何彻底解决ComfyUI-Manager安装难题:终极完整指南 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custom …...

Qwen3.5-4B-Claude模型Java微服务集成指南:SpringBoot实战案例
Qwen3.5-4B-Claude模型Java微服务集成指南:SpringBoot实战案例 1. 引言:当大模型遇上微服务 最近在开发企业知识管理系统时,我们遇到了一个典型需求:如何让传统Java微服务架构与前沿的大语言模型无缝集成。经过多次尝试…...

Graphormer部署案例:中小企业AI药物研发团队低成本GPU算力部署方案
Graphormer部署案例:中小企业AI药物研发团队低成本GPU算力部署方案 1. 项目背景与价值 在药物研发领域,分子属性预测是核心环节之一。传统实验方法成本高昂且周期漫长,而Graphormer作为基于纯Transformer架构的图神经网络,为这一…...