手写RPC框架--2.介绍Zookeeper
RPC框架-Gitee代码(麻烦点个Starred, 支持一下吧)
RPC框架-GitHub代码(麻烦点个Starred, 支持一下吧)
该项目的RPC通信将采用Netty+Zookeeper,所以会在前两章介绍使用方法
介绍Zookeeper
- Zookeeper
- a.概述
- 1) 数据模型
- 2) Watcher机制
- b.安装和基本操作
- 1) Java操作zookeeper
- 2) watcher机制
- c.集群安装
- 1) 准备环境
- 2) Zookeeper安装
- 3) Java操作集群
- d.CAP理论
- 1) 一致性,即 CAP 中的 C-Consistency
- 2) 可用性,即 CAP 中的 A-Availability
- 3) 分区容错性,即 CAP 中的 P-Partition
- 4) CAP 不可兼得
- 5) CAP 总结
- 5.a)CP模型:
- 5.b) AP模型
- 6) BASE 理论
- 6.a) 基本可用
- 6.b) 最终一致性
- 6.c) 总结
- e.选举和同步算法
- 1) 写操作的具体流程
- 2) 选举流程
- f.脑裂问题
- 1) 什么是脑裂
- 2) 防止措施:Zookeeper的过半原则
- 3) 新旧Leader争夺
- 4) ZooKeeper集群节点为什么要部署成奇数
Zookeeper
a.概述
- 概念:ZooKeeper是一个开源的分布式协调服务组件,用于构建可靠的分布式系统。它提供了一个高性能的、有序的、可靠的分布式数据存储和协调服务,简单的理解为一个内存数据库,因为有特殊的数据结构和一些特性,它可以实现一些特殊的功能。
- 应用场景:在分布式系统中我们经常使用ZooKeeper实现服务注册发现、分布式锁、配置管理、命名服务和分布式协调等功能。
- 数据模型:ZooKeeper的数据模型是一个类似于文件系统的层次结构。每个节点称为ZNode,它可以存储数据和子节点。zookeeper中的ZNode可以分为持久节点和临时节点。
- Watcher观察者机制:ZooKeeper允许开发人员在节点上设置监视点,以便在节点发生更改时接收通知。
1) 数据模型
ZooKeeper的数据模型是一个类似于**文件系统的层次结构,**被组织成一个树形结构,每个节点称为ZNode
ZNode是ZooKeeper中的基本数据单元,它可以存储数据和子节点。
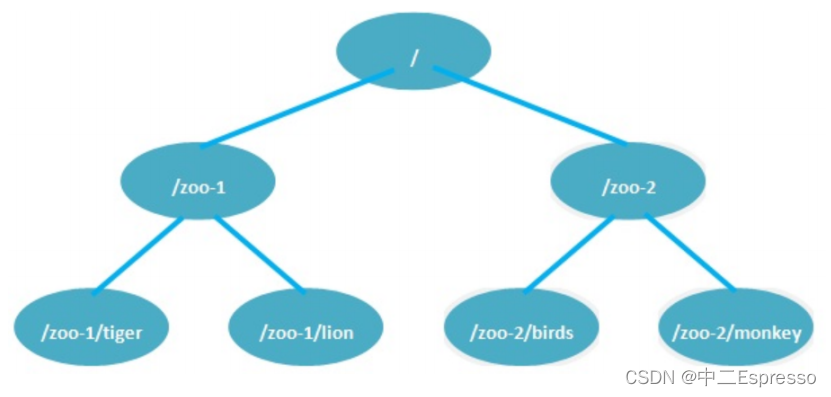
每个ZNode可以存储一个字节数组作为其数据,可以是任意类型的数据,例如配置信息、状态信息等。
持久节点(Persistent Node):
- 持久节点在创建后一直存在,直到主动删除
- 持久节点的数据和子节点都是持久的,即它们在节点创建后仍然存在,直到被显式删除
临时节点(Ephemeral Node):
- 临时节点的生命周期与客户端会话绑定,当会话结束时,临时节点将自动被删除
- 临时节点的数据和子节点也将随之被删除
顺序节点(Sequential Node):
- 顺序节点在创建时会自动分配一个全局唯一且递增的编号
- 顺序节点的编号由ZooKeeper集合维护,可以用于实现有序性或生成全局唯一的标识符
2) Watcher机制
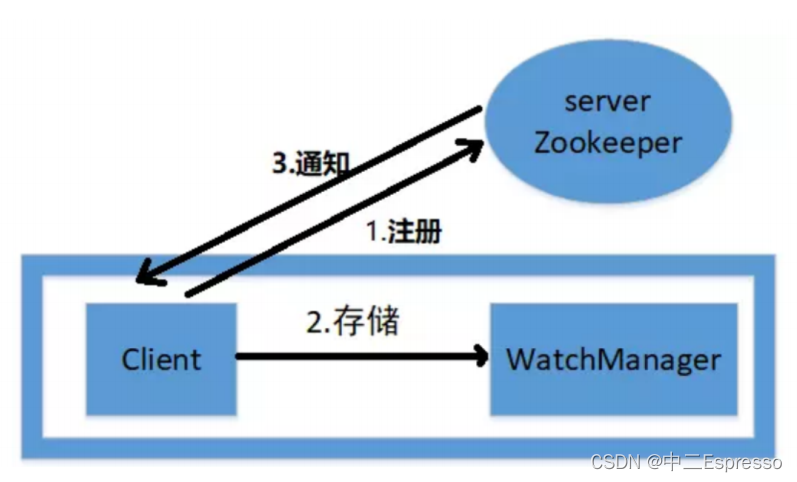
Watcher机制是ZooKeeper中非常重要的概念,它允许客户端在ZooKeeper上设置监视点,以便在节点发生变化时接收通知。Watcher机制使得开发人员可以及时获取关于数据变化的通知,以便采取相应的操作
以下是Watcher机制:
-
1.注册Watcher:
-
客户端可以通过在对节点进行操作时注册Watcher来设置监视点
-
客户端在注册Watcher时需要指定监视的路径和Watcher对象,当指定路径的节点发生变化时,ZooKeeper会将通知发送给客户端
-
-
2.Watcher通知:
- 当一个节点发生变化时,ZooKeeper会将通知发送给注册了Watcher的客户端。
- Watcher通知是一次性的,当客户端接收到Watcher通知后,该Watcher将被移除,需要客户端重新注册Watcher才能再次接收通知
-
3.触发Watcher的类型
- 数据变更触发的Watcher (Data Watcher): 当节点的数据发生变化时触发,例如节点的值被修改。
- 子节点变更触发的Watcher (Child Watcher): 当节点的子节点发生变化时触发,例如新增或删除子节点。
- 连接状态变更触发的Watcher(Existence Watcher):当客户端与ZooKeeper集合的连接状态发生变化时触发,例如连接断开或重新连接。
-
4.Watcher的触发流程
- 当一个节点发生变化时,ZooKeeper首先会将通知发送给与该节点相关的Watcher
- 客户端接收到Watcher通知后,需要处理通知并根据需要采取相应的操作,例如重新读取数据或重新注册Watcher
-
5.Watcher的注意事项
- Watcher通知是异步的,客户端需要保证处理Watcher通知的代码是线程安全的
- Watcher通知是最终一致性的,无法保证实时性
- Watcher通知是有序的,当多个Watcher同时触发时,ZooKeeper会按照注册顺序依次发送通知
b.安装和基本操作
ZooKeeper提供了一组命令行工具(CLI)来与ZooKeeper集群进行交互。
以下是一些常见的ZooKeeper命令:
1.connect
-
连接到ZooKeeper集群。
-
语法:
connect <host:port>
2.ls
-
列出指定路径下的子节点。
-
语法:
ls <path>
3.create
- 创建一个节点
- 语法:
create <path> <data>
4.get
- 获取指定节点的数据
- 语法:
get <path>
5.set
- 设置指定节点的数据
- 语法:
set <path> <data>
6.delete
- 删除指定节点
- 语法:
delete <path>
7.stat
- 获取指定节点的详细信息,包括数据版本、ACL权限等
- 语法:
stat <path>
8.getAcl
- 获取指定节点的ACL(访问控制列表)权限信息。
- 语法:
getAcl <path>
9.setAcl
- 设置指定节点的ACL权限信息
- 语法:
setAcl <path> <acl>
10.quit/exit
- 退出ZooKeeper命令行工具
- 语法:
quit或exit
1) Java操作zookeeper
1.添加Maven依赖,引入ZooKeeper客户端库
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.2</version>
</dependency>
2.测试用例
连接Zookeeper
private ZooKeeper zooKeeper;@Before
public void createZooKeeper() throws IOException {// 定义连接参数String connectString = "127.0.0.1:2181";// 定义超时时间 10秒int sessionTimeout = 10000;zooKeeper = new ZooKeeper(connectString, sessionTimeout, null);
}
创建永久节点
/*** 创建永久节点*/
@Test
public void testCreatePersistentNode(){try {String result = zooKeeper.create("/dcyrpc", "hello world".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);System.out.println("result = " + result);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {try {if (zooKeeper != null){zooKeeper.close();}} catch (InterruptedException ex) {ex.printStackTrace();}}
}
删除一个永久节点
/*** 删除一个永久节点*/
@Test
public void testDeletePersistentNode(){// version: cas mysql 乐观锁,也可以无视版本号 -1try {zooKeeper.delete("/dcyrpc", -1);} catch (InterruptedException | KeeperException e) {e.printStackTrace();} finally {try {if (zooKeeper != null){zooKeeper.close();}} catch (InterruptedException e) {e.printStackTrace();}}
}
设置指定节点的数据
/*** 设置指定节点的数据*/
@Test
public void testSetNodeData(){try {zooKeeper.setData("/dcyrpc", "hi rpc".getBytes(), -1);} catch (KeeperException | InterruptedException e) {e.printStackTrace();} finally {try {if (zooKeeper != null){zooKeeper.close();}} catch (InterruptedException e) {e.printStackTrace();}}
}
检测节点的版本号
/*** 检测节点的版本号*/
@Test
public void testCheckNodeVersion(){try {// version: cas mysql 乐观锁,也可以无视版本号 -1Stat stat = zooKeeper.exists("/dcyrpc", null);// 当前节点的数据版本int version = stat.getVersion();System.out.println("version = " + version);// 当前节点的acl数据版本int aversion = stat.getAversion();System.out.println("aversion = " + aversion);// 当前子节点的数据版本int cversion = stat.getCversion();System.out.println("cversion = " + cversion);} catch (InterruptedException | KeeperException e) {e.printStackTrace();} finally {try {if (zooKeeper != null){zooKeeper.close();}} catch (InterruptedException e) {e.printStackTrace();}}
}
2) watcher机制
watcher机制的本质是向zookeeper注册关心的事件,然后在本地存储钩子函数,当事件发生后调用钩子函数
概念
Zookeeper提供了数据的发布/订阅功能。多个订阅者可监听某一特定主题对象(节点)。当主题对象发生改变(数据内容改变,被删除等),会实时通知所有订阅者。该机制在被订阅对象发生变化时,会异步通知客户端,因此客户端不必在注册监听后轮询阻塞。
Watcher机制实际上与观察者模式类似,也可看作观察者模式在分布式场景中给的一种应用。
特性
| 特性 | 说明 |
|---|---|
| 一次性 | Watcher是一次性的,一旦触发,就会被移除,再次使用需要重新注册 |
| 轻量级 | WatcherEvent是最小的通信单元,结构上只包含连接状态、事件类型和节点路径,并不会告诉数据 |
| 时效性 | watcher只有在当前session彻底时效时才会无效,若在session有效期内重新连接成功,则watcher |
ZooKeeper中的读取操作getData、exist、getChildren 等都可以使用指定参数为节点设置监听
Zookeeper监听有三个关键点:
- 1.客户端对该节点注册监听,也就是客户端对该节点进行订阅
- 2.该节点发生改变,触发某一事件后,客户端会收到一个通知。可以执行相应回调执行相应动作
- 3.注册的监听只会生效一次,要想继续生效,就要在回调的方法中继续注册监听
java api中 有三个方法可以注册监听,getData、exist、getChildren
监听器:
- 监听器接口Watcher,我们可以实现该接口实现自定义的监听器注册到节点上
- 事件类型可以分为连接事件状态类型和节点事件类型
- 事件类型:由Watcher.Event.EventType枚举维护
节点的事件主要有5种类型:
- 1.NodeCreated:节点被创建时触发。
- 2.NodeDeleted:节点被删除时触发。
- 3.NodeDataChanged:节点数据被修改时触发
- 4.NodeChildrenChanged:子节点被创建或者删除时触发。
- 5.NONE: 该状态就是连接状态事件类型
连接事件类型 Watcher.Event.KeeperState枚举维护
- 1.SyncConnected :客户端与服务器正常连接时触发的事件
- 2.Disconnected :客户端与服务器断开连接时触发的事件。
- 3.AuthFailed:身份认证失败时触发的事件
- 4.Expired :客户端会话Session超时时触发的事件。
注册事件的方式与节点事件的关系:
| 方式 | NodeCreate | NodeDeleted | NodeDataChanged | NodeChildrenChanged |
|---|---|---|---|---|
| exist | 可监控 | 可监控 | 可监控 | 不可监控 |
| getData | 不可监控 | 可监控 | 可监控 | 不可监控 |
| getChildren | 不可监控 | 可监控 | 不可监控 | 可监控 |
测试用例
创建方法实现Watcher接口,在process方法里实现业务逻辑
/*** zookeeper 的 watcher 机制* watcher只编写自己关心的事件*/
public class WatcherTest implements Watcher {@Overridepublic void process(WatchedEvent event) {// 判断事件类型:连接事件类型/节点事件类型if (event.getType() == Event.EventType.None) {// 判断具体的连接事件类型if (event.getState() == Event.KeeperState.SyncConnected) {System.out.println("zookeeper连接成功");} else if (event.getState() == Event.KeeperState.AuthFailed) {System.out.println("zookeeper身份认证失败");} else if (event.getState() == Event.KeeperState.Disconnected) {System.out.println("zookeeper断开连接");}} else if (event.getType() == Event.EventType.NodeCreated) {System.out.println(event.getPath() + " 节点被创建");} else if (event.getType() == Event.EventType.NodeDeleted) {System.out.println(event.getPath() + " 节点被删除");}}
}
/*** 检测watcher*/
@Test
public void testWatcher(){try {// 以下三个方法可以注册watcher,可以直接new一个新的watcher// 也可以使用true,选定默认的watcherzooKeeper.exists("/dcyrpc", true);
// zooKeeper.getChildren();
// zooKeeper.getData();while (true) {Thread.sleep(1000);}} catch (InterruptedException | KeeperException e) {e.printStackTrace();} finally {try {if (zooKeeper != null){zooKeeper.close();}} catch (InterruptedException e) {e.printStackTrace();}}
}
c.集群安装
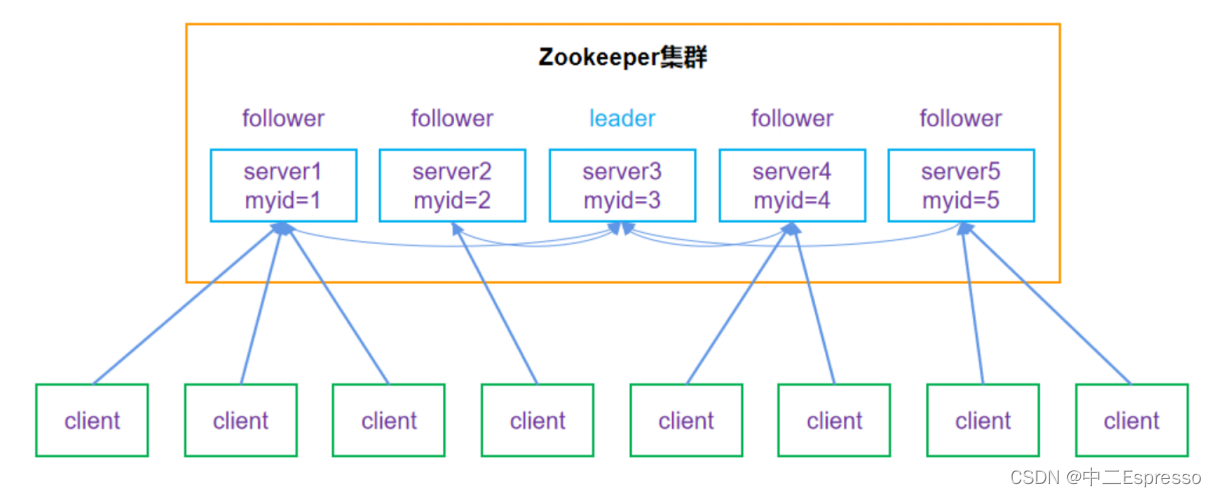
zookeeper的运行模式有单机模式,伪集群模式,集群模式三种。单个Zookeeper节点是会存在单点故障的,Zookeeper节点部署越多,服务的可靠性越高。通常建议部署奇数个节点,因为zookeeper集群是以宕机个数过半才会让整个集群宕机的。
zookeeper的集群模式下,节点分为leader和follower两种状态,leader负责所有的写操作,follower负责相关的读操作。
1) 准备环境
| 主机名 | IP地址 |
|---|---|
| linux-node1 | 192.168.200.128 |
| linux-node2 | 192.168.200.129 |
| linux-node3 | 192.168.200.130 |
2) Zookeeper安装
Zookeeper运行需要java环境,需要安装jdk
注:每台服务器上面都需要安装zookeeper、jdk
修改zookeeper的配置文件,构建集群的基础配置:
dataLogDir=/usr/local/apache-zookeeper-3.8.2-bin/zookeeper/logs
dataDir=/usr/local/apache-zookeeper-3.8.2-bin/zookeeper/data
server.1= 192.168.200.128:2888:3888
server.2= 192.168.200.129:2888:3888
server.3= 192.168.200.130:2888:3888
server.1中的1指代第几个节点,2888端口用来辅助这个服务器与集群中的leader服务器做交换信息的端口,3888端口是在leader挂掉时专门用来进行选举leader所用的端口。
创建日志和持久化目录:
mkdir -p /zookeeper/{logs,data}
创建ServerID标识
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下
在server.1服务器上面创建myid文件,就将他的值设置为1,以此类推
touch myid
each 1 > myid
在每台服务器上都要进行创建目录与ServerID
3) Java操作集群
连接集群
@Before
public void createZooKeeper() throws IOException {// 定义连接集群,用逗号隔开String connectString = "192.168.200.129:2181,192.168.200.130:2181,192.168.200.130:2181";// 定义超时时间 10秒int sessionTimeout = 10000;// 构建zookeeper是否需要等待连接zooKeeper = new ZooKeeper(connectString, sessionTimeout, new WatcherTest());
}
d.CAP理论
对于任何一个分布式系统而言,数据同步永远都是重中之重。因为一个集群当中会有很多节点,那么客户端每次写数据的时候,是只向一个节点写入,还是向所有节点写入就成了一个问题。
如果向所有节点写入,假设节点个数为 N,那么客户端的一次写请求就会被放大 N 倍,因为每个节点都要写一遍,显然这么做是非常不明智的。因此我们应该让客户端只向一个节点写入,然后该节点再将数据同步给集群内的其它节点。
但这就产生了一个问题,如果某个节点的数据同步还没有完成,就收到了客户端的读请求,那么显然会返回旧数据。如果想让客户端看到的一定是新数据,那么就必须等到数据在所有节点之间都同步完成之后,才能让客户端访问,而这又会造成集群服务出现短暂的不可用。
1) 一致性,即 CAP 中的 C-Consistency
客户端的每次读操作,不管访问哪个节点,读到的都是同一份最新的数据。不会出现读不同节点,得到的数据不同这种情况。
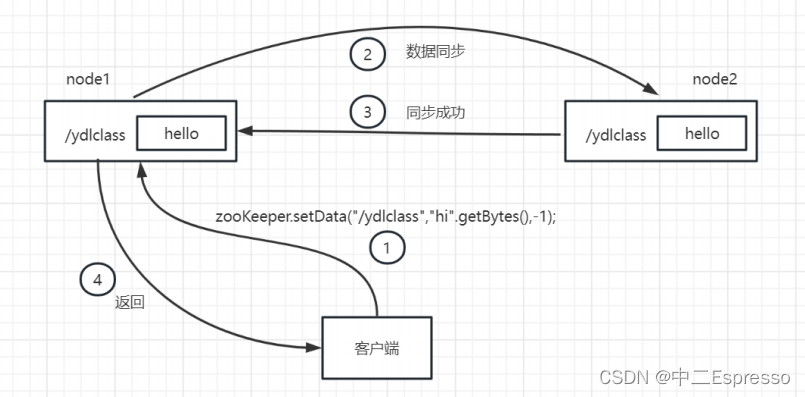
但集群毕竟不是单机,总会有网络故障的时候,这时候如果要保证一致性,也就是让客户端访问任何一个节点都能看到相同的数据,那么就应该拒绝服务(客户端读取失败),等到数据同步完成之后再提供服务。
一致性强调的不是数据完整,而是各节点之间的数据绝对一致。
2) 可用性,即 CAP 中的 A-Availability
任何来自客户端的请求,不管访问哪个节点,都能得到响应数据,但不保证是同一份最新数据。
可用性这个指标强调的是服务可用,但不保证数据的绝对一致。
3) 分区容错性,即 CAP 中的 P-Partition
当节点间出现任意数量的消息丢失或高延迟的时候,系统仍然可以继续提供服务。
分布式系统会告诉客户端:不管我的内部出现什么样的数据同步问题,我会一直运行,提供服务。
这个指标,强调的是集群对分区故障的容错能力。
4) CAP 不可兼得
对于一个分布式系统而言,一致性、可用性、分区容错性 3 个指标不可兼得,只能在 3 个指标中选择两个。
只要有网络交互就一定会有延迟和数据丢失,而这种状况我们必须接受,还必须保证系统不能挂掉。
分区容错性(P)是前提,是必须要保证的
现在就只剩下一致性(C)和可用性(A)可以选择了:**要么选择一致性,保证数据绝对一致;要么选择可用性,保证服务可用。**如果选择 C,那么就是 CP 模型;如果选择 A,那么就是 AP 模型。
- 当选择一致性(C)的时候,如果因为消息丢失、延迟过高发生了网络故障,为无法保证所有节点都是最新信息,所以系统将返回错误,也就是说拒绝请求。
- 当选择可用性(A)的时候,如果发生了网络故障,一些节点将无法返回最新的特定信息,那么将返回自己当前相对新的信息。
5) CAP 总结
5.a)CP模型:
选择 CP 一般都是对数据一致性特别敏感,尤其是在支付交易领域,Hbase 等分布式数据库领域,都要优先保证数据的一致性,在出现网络异常时,系统就会暂停服务处理。还有用来分发及订阅元数据的 Zookeeper、Etcd 等等,也是优先保证 CP 的。
5.b) AP模型
比如微博多地部署,如果不同区域出现网络中断,区域内的用户仍然能发微博、相互评论和点赞,但暂时无法看到其它区域用户发布的新微博和互动状态。
还有类似 12306 这种火车购票系统,在节假日高峰期抢票时也会遇到这种情况,明明某车次有余票,但真正点击购买时,却提示说没有余票。就是因为票已经被抢光了,票的可选数量应该更新为 0,但因并发过高导致当前访问的节点还没有来得及更新就提供服务了。因此它返回的是更新之前的旧数据,但其实已经没有票了。
6) BASE 理论
BASE 理论是 CAP 理论中的 AP 的延伸,所以它强调的是可用性,这个理论广泛应用在大型互联网的后台当中。它的核心思想就是基本可用(Basically Available)和最终一致性(Eventually consistent)。
6.a) 基本可用
当分布式系统在出现不可预知的故障时,允许损失部分功能的可用性,来保障核心功能的可用性。说白了就是服务降级,在服务器资源不够、或者说压力过大时,将一些非核心服务暂停,优先保证核心服务的运行。比如:
- 非核心数据时,拒绝服务,或者直接返回预定义信息、空值或错误信息
- 对用户体验进行降级,比如用小图片来替代原始图片,通过降低图片的清晰度和大小
6.b) 最终一致性
系统中所有的数据副本在经过一段时间的同步后,最终能够达到一致的状态
在数据一致性上,存在一个短暂的延迟,几乎所有的互联网系统采用的都是最终一致性。比如 12306 买票,票明明卖光了,但还是显示有余票,说明此时数据不一致。但当你在真正购买的时候,又会提示你票卖光了,说明数据最终是一致的。
6.c) 总结
如果业务的某功能无法容忍一致性的延迟(比如分布式锁对应的数据),就需要强一致性;如果能容忍短暂的一致性的延迟(比如APP用户的状态数据),就可以考虑最终一致性。
e.选举和同步算法
1) 写操作的具体流程
假设现在有一个写操作,需要在ZooKeeper集群服务中执行写操作,创建一个/dcyrpc节点,其大致流程如
下:
- 1.客户端连接:首先,要创建节点的客户端需要与ZooKeeper集群中的任何一个服务器建立连接
- 2.发起写请求:客户端向Leader发送写请求,请求创建一个新的节点。
- 3.Leader处理写请求:Leader接收到写请求后,将生成一个全局唯一的ZooKeeper事务ID(ZXID),用来标识这个写操作。
- 4.创建节点过程:Leader将写请求转发给其他Follower节点,并协调它们来完成创建节点的过程。具体步骤如下:
- a.Leader将写请求转发给Follower节点。
- b.Follower节点接收到写请求后,会记录下这个写操作的ZXID,并执行节点的创建操作。
- c.Follower节点将创建节点的操作结果返回给Leader。
- d.Leader收集Follower节点的操作结果,并基于大多数原则(过半原则)决定最终的写操作结果。
- 5.数据同步过程:一旦写操作成功并被大多数节点接受,数据同步将在ZooKeeper集群中进行。具体步骤如下:
- a.Leader将写请求成功的结果通知给所有的Follower节点
- b.Follower节点在收到通知后,会将Leader上的数据进行复制,确保自己的数据与Leader上的数据保持一致
- c.Follower节点完成数据复制后,会向Leader发送确认通知
- d.Leader在收到所有Follower节点的确认通知后,确定数据同步成功
- 6.客户端响应:一旦数据同步成功,Leader将向客户端发送操作成功的响应,表示节点创建完成
已经执行了写操作还要数据同步吗?
Follower节点执行写操作并返回成功结果给Leader是为了保证写操作的一致性和持久性。数据同步是确保在整个集群中所有节点的数据是最终一致的关键步骤。
但在写操作的结果被确认之前,数据同步的过程是必要的。这是因为ZooKeeper使用了多数原则来决定写操作的最终结果,只有在大多数节点都完成写操作并确认成功后,Leader才会确认写操作成功。此时,数据同步的过程才会开始。
数据同步是在写操作完成后才开始的,这意味着在数据同步期间的某个时间点,集群中的不同节点的数据可能是不一致的。但是一旦数据同步完成,所有节点都将具有相同的数据,并保持一致性。这样做是为了在写操作期间保持高可用性,并在数据同步完成后确保数据的一致性。
数据同步是增量同步还是全量同步?
全量数据同步需要将所有相关节点上的数据进行复制,网络传输和处理的开销都可能会比较大。
为了减小全量数据同步的性能开销,ZooKeeper在设计上采取了一些优化措施:
- 1.增量更新:ZooKeeper中的数据是以事务日志的形式进行持久化的。当数据有更新时,只会记录变更的内容,而不会每次都全量复制所有的数据。这样可以减小数据同步的开销。
- 2.快速同步:当一个Follower节点加入集群时,它可以通过快速同步(Snapshot)的方式来获取最新的数据。只需要将Leader节点上的整个数据文件传输给新加入的Follower节点,而不是逐个复制增量更新。这样可以加快新节点的数据同步过程。
2) 选举流程
假设现在有myid为1、2、3的三台ZooKeeper服务器,分别启动1、2、3三台服务,下面是集群启动时的选举过程的详细描述:
-
1.初始状态:集群中的所有服务器处于LOOKING状态,即正在寻找leader节点
-
2.服务器1启动:服务器1作为第一台启动的服务器,它将成为Leader选举的候选者,并向其他服务器发送选举请求
-
3.服务器1的选举投票:服务器1将自己的投票信息(包括标识符myid=1、ZXID和状态LOOKING)发送给服务器2和服务器3。(默认给自己也投一票)
-
4.服务器2和服务器3收到选举请求:服务器2和服务器3收到来自服务器1的选举请求,并检查自己的状态
-
5.服务器2和服务器3的选举投票:服务器2和服务器3会分别初始化自己的投票,并将自己的投票信息发送回给服务器1。(默认给自己也投一票)
-
6.服务器1收集和处理投票:服务器1收到来自服务器2和服务器3的投票,它将根据规则进行投票的计算和比较。如果服务器1得到了大多数的投票(超过半数,即两票),它将更改自己的状态为LEADING,并成为leader。
-
7.选举结果通知:服务器1成为leader后,它将选举结果通知给服务器2和服务器3。服务器2和服务器3会更新自己的状态,并认可服务器1作为leader
-
8.集群状态稳定:现在,服务器1成为了leader,而服务器2和服务器3成为了follower。整个集群的状态稳定下来,Leader将开始处理客户端的请求
f.脑裂问题
1) 什么是脑裂
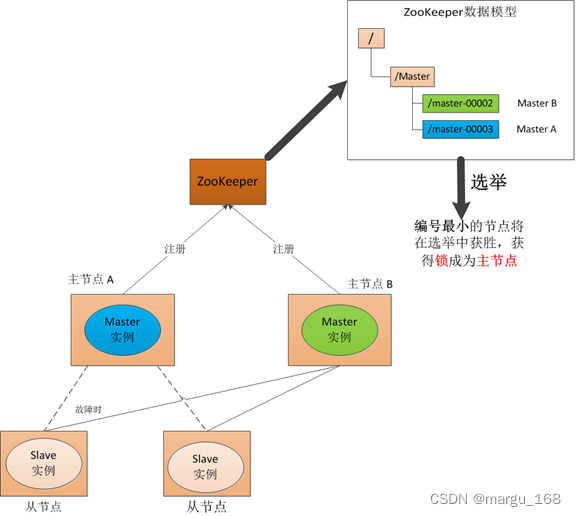
在Elasticsearch、ZooKeeper这些集群环境中,有一个共同的特点,就是它们有一个“大脑”。比如Elasticsearch集群中有Master节点,ZooKeeper集群中有Leader节点。
集群中的Master或Leader节点往往是通过选举产生的。在网络正常的情况下,可以顺利的选举出Leader。但当两个机房之间的网络通信出现故障时,选举机制就有可能在不同的网络分区中选出两个Leader当网络恢复时,这两个Leader该如何处理数据同步?又该听谁的?这也就出现了“脑裂”现象。
zookeeper集群中的脑裂
在使用zookeeper时,很少遇到脑裂现象,是因为zookeeper已经采取了相应的措施来减少或避免脑裂的发生。现在先假设zookeeper没有采取这些防止脑裂的措施。在这种情况下,看看脑裂问题是如何发生的。
现有6台zkServer服务组成了一个集群,部署在2个机房:
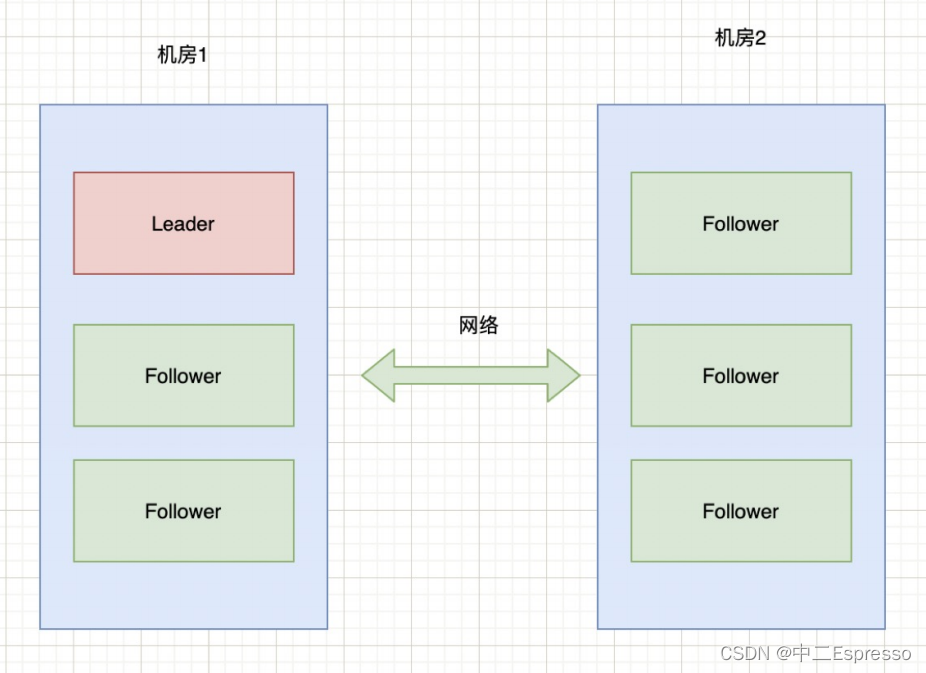
正常情况下,该集群只有会有个Leader,当Leader宕掉时,其他5个服务会重新选举出一个新的Leader。
如果机房1和机房2之间的网络出现故障,暂时不考虑Zookeeper的防止措施,那么就会出现下图的情况:
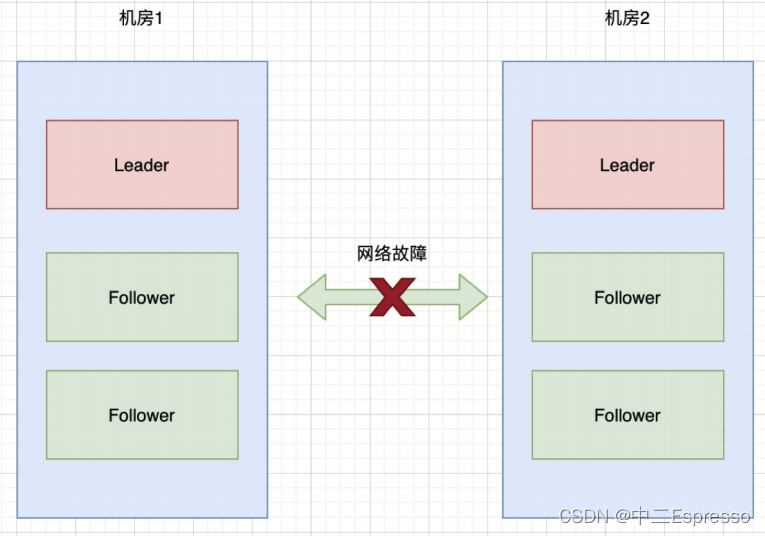
也就是说机房2的三台服务检测到没有Leader了,于是开始重新选举,选举出一个新Leader来。原本一个集群,被分成了两个集群,同时出现了两个“大脑”,这就是所谓的“脑裂”现象。
由于原本的一个集群变成了两个,都对外提供服务。一段时间之后,两个集群之间的数据可能会变得不一致了。当网络恢复时,就面临着谁当Leader,数据怎么合并,数据冲突怎么解决等问题。
2) 防止措施:Zookeeper的过半原则
Zookeeper默认采用的是“过半原则”。所谓的过半原则就是:在Leader选举的过程中,如果某台zkServer获得了超过半数的选票,则此zkServer就可以成为Leader了。
以上图6台服务器为例来进行说明:half = 6 / 2 = 3,也就是说选举的时候,要成为Leader至少要有4台机器投票才能够选举成功。那么,针对上面2个机房断网的情况,由于机房1和机房2都只有3台服务器,根本无法选举出Leader。这种情况下整个集群将没有Leader。
在没有Leader的情况下,会导致Zookeeper无法对外提供服务,所以在设计的时候,我们在集群搭建的时候,要避免这种情况的出现。
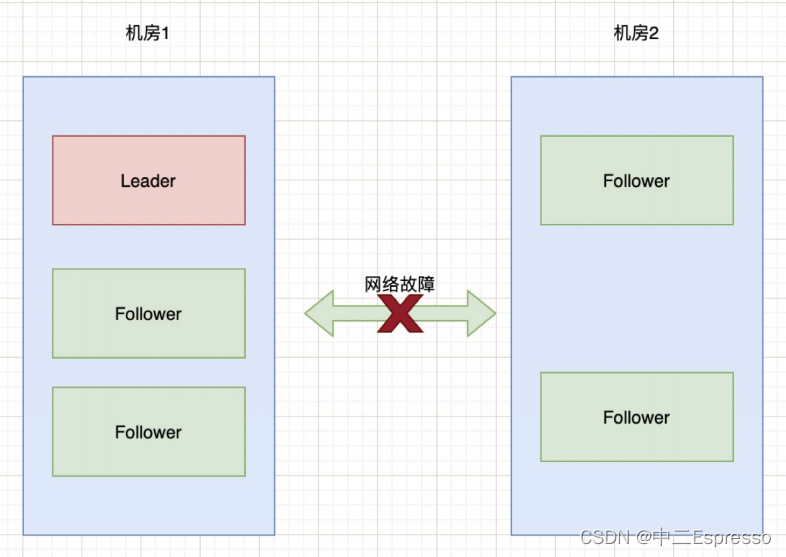
如果两个机房的部署请求部署3:3这种状况,而是3:2,也就是机房1中三台服务器,机房2中两台服务器:
在上述情况下,先计算half = 5 / 2 = 2,也就是需要大于2台机器才能选举出Leader。那么此时,对于机房1可以正常选举出Leader。对于机房2来说,由于只有2台服务器,则无法选出Leader。此时整个集群只有一个Leader。
3) 新旧Leader争夺
通过过半原则可以防止机房分区时导致脑裂现象,但还有一种情况就是Leader假死。
假设某个Leader假死,其余的followers选举出了一个新的Leader。这时,旧的Leader复活并且仍然认为自己是Leader,向其他followers发出写请求也是会被拒绝的。
因为ZooKeeper维护了一个叫epoch的变量,每当新Leader产生时,会生成一个epoch标号(标识当前属于那个Leader的统治时期),epoch是递增的,followers如果确认了新的Leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。
4) ZooKeeper集群节点为什么要部署成奇数
只要集群中有过半的机器是正常工作的,那么整个集群就可对外服务。
列举一些情况,来看看在这些情况下集群的容错性:
- 如果有2个节点,那么只要挂掉1个节点,集群就不可用了。此时,集群的容忍度为0
- 如果有3个节点,那么挂掉1个节点,还有剩下2个正常节点,超过半数,可以重新选举,正常服务。此时,集群的容忍度为1;
- 如果有4个节点,那么挂掉1个节点,剩下3个,超过半数,可以重新选举。但如果再挂掉1个,只剩下2个,就无法正常选举和服务了。此时,集群的容忍度为1;
相关文章:
手写RPC框架--2.介绍Zookeeper
RPC框架-Gitee代码(麻烦点个Starred, 支持一下吧) RPC框架-GitHub代码(麻烦点个Starred, 支持一下吧) 该项目的RPC通信将采用NettyZookeeper,所以会在前两章介绍使用方法 介绍Zookeeper Zookeepera.概述1) 数据模型2) Watcher机制 b.安装和基本操作1) Java操作zooke…...
Docker harbor 私有仓库的部署和管理
目录 一、什么是Harbor 二、Harbor的特性 三、Harbor的构成 四、部署配置Docker Harbor 1. 首先需要安装 Docker-Compose 服务 2.部署 Harbor 服务 3.使用harbor仓库 (1)项目管理 (2)用户管理 一、什么是Harbor Harbor …...

从零开始搭建AI网站(6):如何使用响应式编程
响应式编程(Reactive Programming)是一种编程范式,旨在处理异步数据流和事件流。它通过使用观察者模式和函数式编程的概念,将数据流和事件流抽象为可观察的序列,然后通过操作这些序列来实现各种功能。 在响应式编程中…...
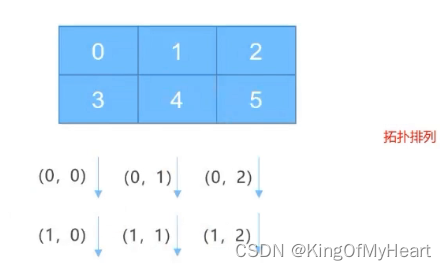
MPI之虚拟进程拓扑
什么是虚拟进程拓扑 在很多并行应用进程中,进程的线性排列不能充分的反映进程间在逻辑上的通信模型,通常由问题几何和所用的算法决定,进程经常被排列成二维或者三维网络形式的拓扑模型而通常用一个图来描述逻辑进程排列,此种逻辑…...

Three.js相机参数及Z-Fighting问题的解决方案
本主题讨论透视相机以及如何为远距离环境设置合适的视锥体。 推荐:用 NSDT编辑器 快速搭建可编程3D场景 透视相机是一种投影模式,旨在模仿人类在现实世界中看待事物的方式。 这是渲染 3D 场景最常用的投影模式。 - three.js 如果你看一下 Three.js 文档…...

微信小程序食疗微信小程序的设计与实现
摘要 现在人们的生活水平高了,大家都想在多活个几十年,要想实现这个想法,有很多事情都必须考虑到,第一个就是适当运动,第二个就是心情好,第三个就是要注意饮食。民以食为天,科学合理的饮食结构是…...

mac环境使用pkgbuild命令打pkg包的几个小细节
mac环境使用pkgbuild命令打pkg包的几个小细节 最近,研发提出要使用jenkins来自动生成mac环境下的pkg包,研究了一下,可以使用pkgbuild来打包。但是有几个小细节需要注意一下: 1 如果有pre-install和post-install脚本,…...
在 Spring Boot 中集成 MinIO 对象存储
MinIO 是一个开源的对象存储服务器,专注于高性能、分布式和兼容S3 API的存储解决方案。本文将介绍如何在 Spring Boot 应用程序中集成 MinIO,以便您可以轻松地将对象存储集成到您的应用中。 安装minio 拉取 minio Docker镜像 docker pull minio/minio创…...
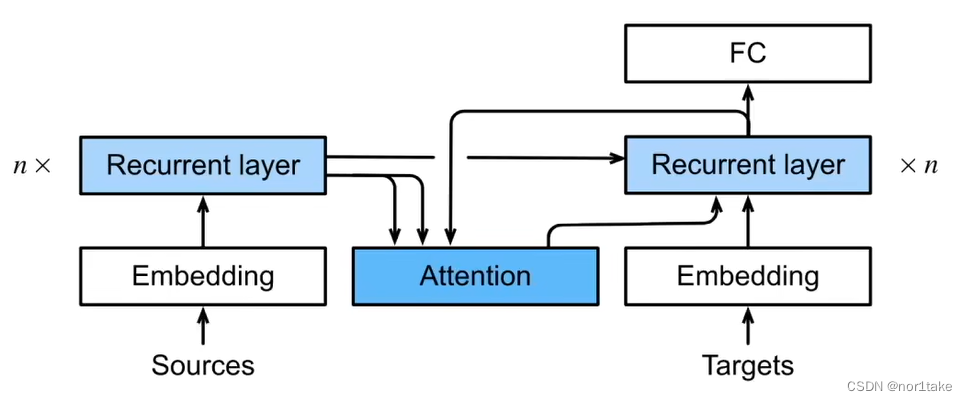
seq2seq与引入注意力机制的seq2seq
1、什么是 seq2seq? 就是字面意思,“句子 到 句子”。比如翻译。 2、seq2seq 有一些特点 seq2seq 的整体架构是 “编码器-解码器”。 其中,编码器是 RNN,并将 最后一个hidden state(隐藏状态)【即&…...
【zookeeper】zookeeper介绍
分布式协调技术 在学习ZooKeeper之前需要先了解一种技术——分布式协调技术。那么什么是分布式协调技术?其实分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的…...

2023高教社杯数学建模思路 - 案例:ID3-决策树分类算法
文章目录 0 赛题思路1 算法介绍2 FP树表示法3 构建FP树4 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模…...

springboot docker
在Spring Boot中使用Docker可以帮助你将应用程序与其依赖的容器化,并简化部署和管理过程。 当你在Spring Boot中使用Docker时,你的代码不需要特殊的更改。你可以按照通常的方式编写Spring Boot应用程序。 java示例代码,展示了如何编写一个基…...
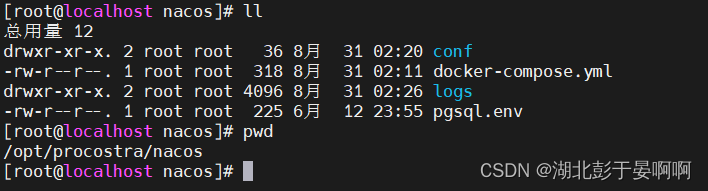
docker-compose 部署nacos 整合 postgresql 为DB
标题docker-compose 部署nacos 整合 postgresql 为DB 前提: 已经安装好postgresql数据库 先创建好一个数据库 nacos,执行以下sql: /** Copyright 1999-2018 Alibaba Group Holding Ltd.** Licensed under the Apache License, Version 2.0 (the "…...
详解 ElasticSearch Kibana 配置部署
默认安装部署所在机器允许外网 SSH工具 Putty 链接:https://pan.baidu.com/s/1b6gumtsjL_L64rEsOdhd4A 提取码:lxs9 Winscp 链接:https://pan.baidu.com/s/1tD8_2knvv0EJ5OYvXP6VTg 提取码:lxs9 WinSCP安装直接下一步到完成…...
SourceTree 使用技巧
参考资料 SourceTree使用教程(一)—克隆、提交、推送SourceTree的软合并、混合合并、强合并区别SourceTree 合并分支上的多个提交,一次性合并分支的多次提交至另一分支,主分支前进时的合并冲突解决 目录 一. 基础设置1.1 用户信息…...

VIRTIO-BLK代码分析(0)概述
也无风雨也无晴。- 苏轼(宋) 接下来介绍VIRTIO相关内容。首先从VIRTIO-BLK开始分析,VIRTIO-BLK各部分交互图如下所示: 这里包含以下几个部分: Guest UserSpace:虚拟机用户空间,如虚拟机中运行f…...
)
【2023年11月第四版教材】第10章《进度管理》(第一部分)
第10章《进度管理》(第一部分) 1 章节说明2 管理基础3 管理过程3.1 管理的过程★★★3.2 管理ITTO汇总★★★ 1 章节说明 【本章分值预测】大部分内容不变,细节有一些变化,预计选择题考3-4分,案例和论文 都有可能考&a…...

【多线程案例】生产者消费者模型(堵塞队列)
文章目录 1. 什么是堵塞队列?2. 堵塞队列的方法3. 生产者消费者模型4. 自己实现堵塞队列 1. 什么是堵塞队列? 堵塞队列也是队列,故遵循先进先出的原则。但堵塞队列是一种线程安全的数据结构,可以避免线程安全问题,当队…...
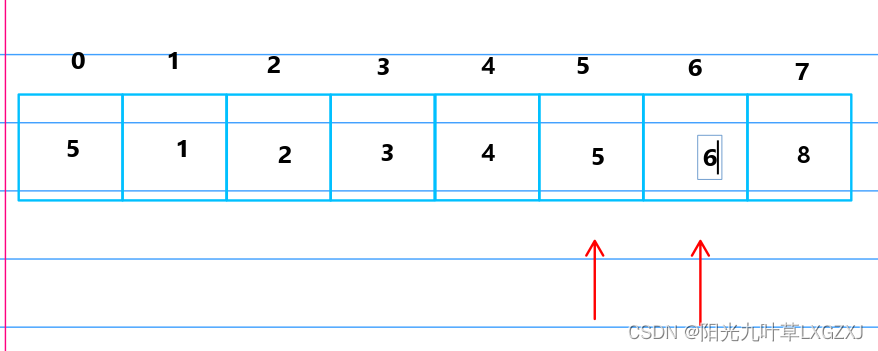
数据结构与算法基础-学习-30-插入排序之直接插入排序、二分插入排序、希尔排序
一、排序概念 将一组杂乱无章的数据按一定规律顺次排列起来。 将无序序列排成一个有序序列(由小到大或由大到小)的运算。 二、排序方法分类 1、按数据存储介质 名称描述内部排序数据量不大、数据在内存,无需内外交换存交换存储。外部排序…...

Qt+C++桌面计算器源码
程序示例精选 QtC桌面计算器源码 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对<<QtC桌面计算器源码>>编写代码,代码整洁,规则,易读。 学习与…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...