随机森林算法
介绍
随机森林是一种基于集成学习的有监督机器学习算法。随机森林是包含多个决策树的分类器,一般输出的类别是由决策树的众数决定。随机森林也可以用于常见的回归拟合。随机森林主要是运用了两种思想。具体如下所示。
- Breimans的Bootstrap aggregating
- Ho的random subspace method
储备知识
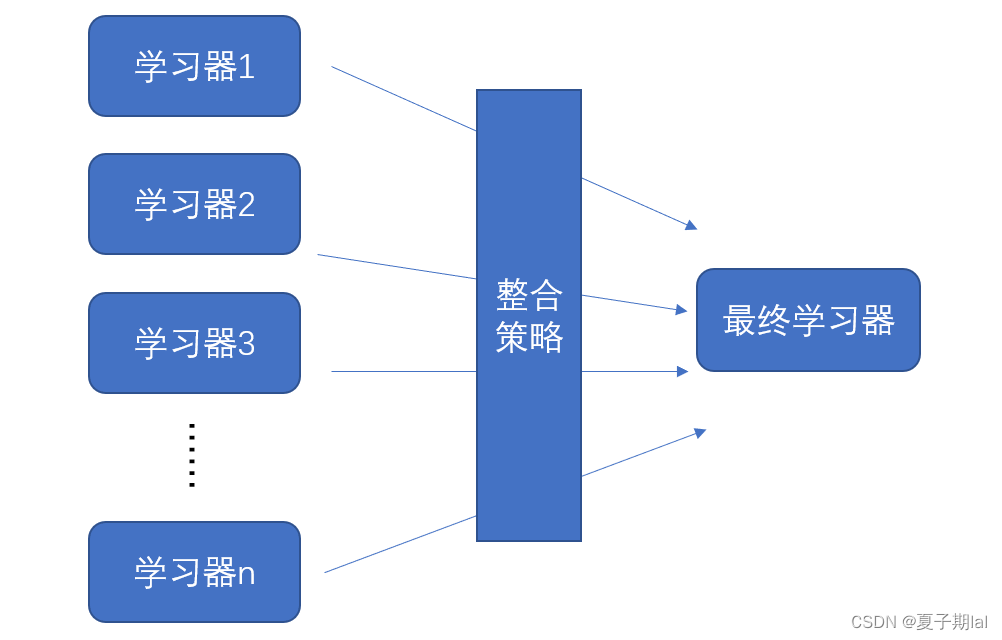
集成学习
集成学习主要是通过个体学习器(如决策树)通过一定组合策略将其组合起来,形成一个准确率较高,较为优秀的学习器。
学习器有同质和异质之分,如随机森林里面的学习器都是决策树,即为是同质,反之即为异质。
集成学习的学习器一般为弱学习器,但弱学习器也需要下列特质。
- 需要一定的准确性
- 需要多样性,弱学习器之间需要存在一定差异性
决策树学习
决策树是机器学习常见的方法,而且决策树本质为树学习,树学习能够有以下优点。
- 在特征值缩放和其他转换下,决策树的结果保持不变
- 无关特征对于结果影响较少,因此决策树对于无关结果是稳健的
树学习的缺点如下。
- 生长很深的树容易学习到高度不规则的模式,即为过学习,在训练集上具有一定的低偏差和高变异数的特点。
因此,随机森林是平均多个深决策树的结果,目的是为了降低变异数。此外,随机森林的决策树是在一个数据集的不同部分进行训练,各部分具有一定的独立性。
随机森林的缺点为偏差的小幅增加和可解释性的丧失。优点为用于大数据集上能够提高准确率和性能。
Bagging 算法
Bagging算法又称为引导聚集算法(装袋算法),属于集成学习算法。主要的目的为能够提高回归,风雷的准确性以及稳定性,同时能够降低结果的变异数,降低过拟合发生的概率。
随机森林训练算法将bagging算法应用于树学习中,给定训练集合 X = x 1 , ⋯ x n X=x_1, \cdots x_n X=x1,⋯xn和label集合 Y = y 1 ⋯ y n Y=y_1 \cdots y_n Y=y1⋯yn,Bagging 算法会从训练集合中有放回采样B次,在这些样本上不断训练树模型。
具体流程如下所示。
For b = 1, …, B:(循环B次,即为重复B次操作)
Sample, with replacement, n training examples from X, Y; call these Xb, Yb.(有放回采样,样本数量为B)
Train a classification or regression tree fb on Xb, Yb(训练树回归/分类模型)
迭代B次之后即为训练结束,对未知样本x的预测可以通过对x上所有单个回归书的预测求取平均来实现。
公式如下所示。 f ^ \hat f f^为预测结果,可以为分类或者拟合结果。 f b ( x ′ ) f_b(x^{\prime}) fb(x′)为经过单个决策树之后的结果。
f ^ = 1 B ∑ b = 1 B f b ( x ′ ) \hat{f}=\frac1B\sum_{b=1}^Bf_b(x^{\prime}) f^=B1b=1∑Bfb(x′)
此外, x ′ x^{\prime} x′上所以单个回归树的预测的标准差可以作为预测的不确定性的估计数值。具体公式如下所示。
σ = ∑ b = 1 B ( f b ( x ′ ) − f ^ ) 2 B − 1 . \sigma=\sqrt{\frac{\sum_{b=1}^B(f_b(x^{\prime})-\hat{f})^2}{B-1}}. σ=B−1∑b=1B(fb(x′)−f^)2.
bagging方法在不增加偏置的情况下能够降低方差。
单个树模型的预测会对数据集的噪声十分敏感,因此对于多个树模型,只要树模型没有明显的相关性,在同一个数据集上简单的训练多个树模型会导致树模型具有强相关性。因此bagging方法的Bootstrap抽样方法能够通过同样的数据集产生不同的训练集以供其他树模型训练。从而降低模型的关联性。
代码
样本数据主要根据下列连接获取。
需要自主上传下载google云盘去获取
import sklearn.datasets as datasets
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.decomposition import PCA
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
import os# 导入数据,路径中要么用\\或/或者在路径前加r,目前是读取当前路径,所以数据文件要放置在同一文件夹/目录中
dataset = pd.read_csv(r'./petrol_consumption.csv')# 准备训练数据
# 自变量, 因变量,本代码主要做的是拟合,而且这里主要获取数据的dataframe转化为ndarry
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values# 将数据分为训练集和测试集,切分数据集合,而且比例为8:2,随机种子为0,保证结果可复现性
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=0)
regr = RandomForestRegressor() # 设置随机森林拟合,下列为参数
# regr = RandomForestRegressor(random_state=100,
# bootstrap=True,
# max_depth=2,
# max_features=2,
# min_samples_leaf=3,
# min_samples_split=5,
# n_estimators=3)
# 这里为封装管道,最终直接可以调用,所以这里运用的是最大最小归一化,而且运用的是PCA降低维度,最终回归用的是regr,所以走完了所有的操作
pipe = Pipeline([('scaler', StandardScaler()), ('reduce_dim', PCA()),('regressor', regr)])
pipe.fit(X_train, y_train)
ypipe = pipe.predict(X_test)# 执行一次,需要自己去配置graphviz,这个网上有很多教程,主要是用于绘制图像
# os.environ['PATH'] = os.environ['PATH']+';'+r"D:\CLibrary\Graphviz2.44.1\bin\graphviz"
dot_data = StringIO()
# export_graphviz()数是一个用于将决策树可视化的函数,通常与机器学习库scikit-learn一起使用
export_graphviz(pipe.named_steps['regressor'].estimators_[0],# pipe.named_steps['regressor'].estimators_[0]返回的是回归器的第一个实例,即为随机初始化一个决策树绘制out_file=dot_data)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('tree.png')Image(graph.create_png())# Get numerical feature importances,获取特征(输入变量的重要程度,即为判断哪个因素最为重要)
importances = list(regr.feature_importances_)
# List of tuples with variable and importance
print(importances)# 保存模型的特征名称
feature_list = list(dataset.columns)[0:4]
# round()函数将特征重要程度四舍五入
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# 将特征重要程度进行排序
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)import matplotlib.pyplot as plt
# Set the style
# plt.style.use('fivethirtyeight')
# list of x locations for plotting
x_values = list(range(len(importances)))
print(x_values)
# Make a bar chart
plt.bar(x_values, importances, orientation = 'vertical')
# Tick labels for x axis
plt.xticks(x_values, feature_list,rotation=6)
# Axis labels and title
plt.ylabel('Importance'); plt.xlabel('Variable'); plt.title('Variable Importances');
plt.show()
print('successful')
回归器的参数如下所示。sklearn的RandomForestRegressor参数如下所示。
'''
sklearn.ensemble.RandomForestRegressor(
n_estimators=100, *, # 树的棵树,默认是100
criterion='mse', # 默认“ mse”,衡量质量的功能,可选择“mae”。
max_depth=None, # 树的最大深度。
min_samples_split=2, # 拆分内部节点所需的最少样本数:
min_samples_leaf=1, # 在叶节点处需要的最小样本数。
min_weight_fraction_leaf=0.0, # 在所有叶节点处的权重总和中的最小加权分数。
max_features='auto', # 寻找最佳分割时要考虑的特征数量。
max_leaf_nodes=None, # 以最佳优先方式生长具有max_leaf_nodes的树。
min_impurity_decrease=0.0, # 如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split=None, # 提前停止树木生长的阈值。
bootstrap=True, # 建立树木时是否使用bootstrap抽样。 如果为False,则将整个数据集用于构建每棵决策树。
oob_score=False, # 是否使用out-of-bag样本估算未过滤的数据的R2。
n_jobs=None, # 并行运行的Job数目。
random_state=None, # 控制构建树时样本的随机抽样
verbose=0, # 在拟合和预测时控制详细程度。
warm_start=False, # 设置为True时,重复使用上一个解决方案,否则,只需拟合一个全新的森林。
ccp_alpha=0.0,
max_samples=None) # 如果bootstrap为True,则从X抽取以训练每个决策树。
'''
参考
维基百科随机森林介绍
随机森林算法梳理(Random Forest)
一文看懂随机森林
用Python实现随机森林回归
相关文章:
随机森林算法
介绍 随机森林是一种基于集成学习的有监督机器学习算法。随机森林是包含多个决策树的分类器,一般输出的类别是由决策树的众数决定。随机森林也可以用于常见的回归拟合。随机森林主要是运用了两种思想。具体如下所示。 Breimans的Bootstrap aggregatingHo的random …...
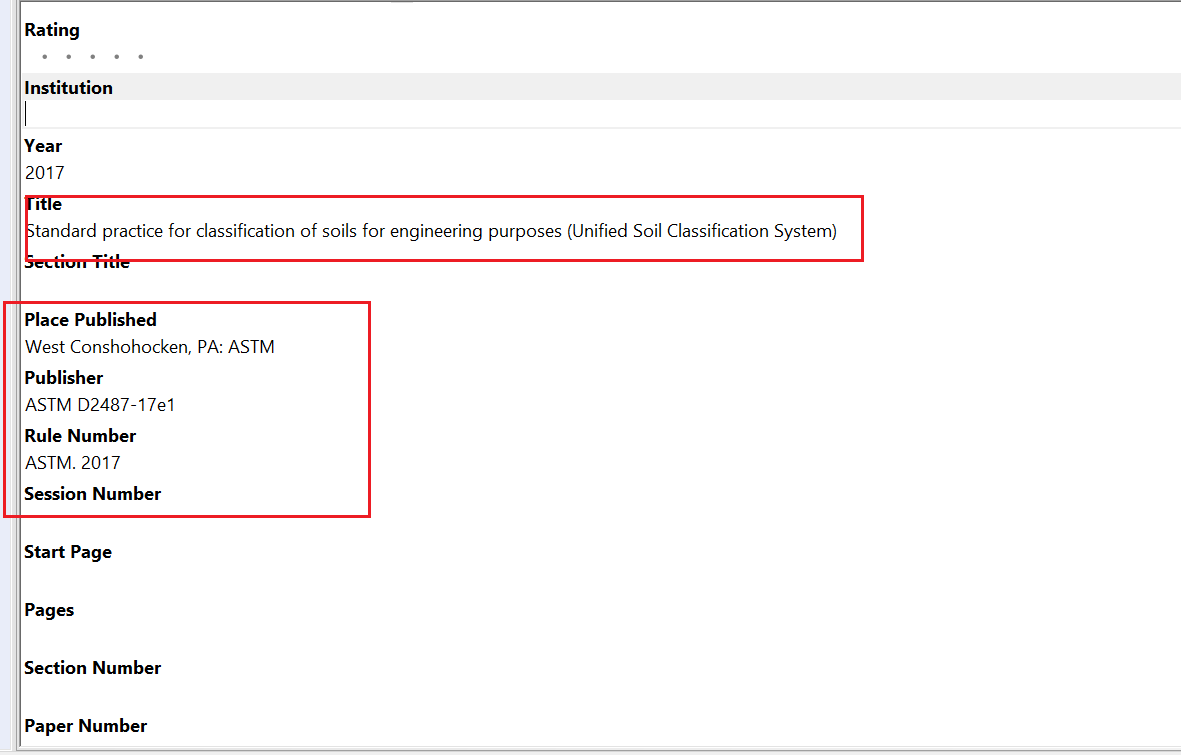
如何将国标规范用EndNote插入到英文期刊中,自定义文献插入指南
EndNote自定义文献 1.插入国标JTG 2034-2020这种新建一个Standard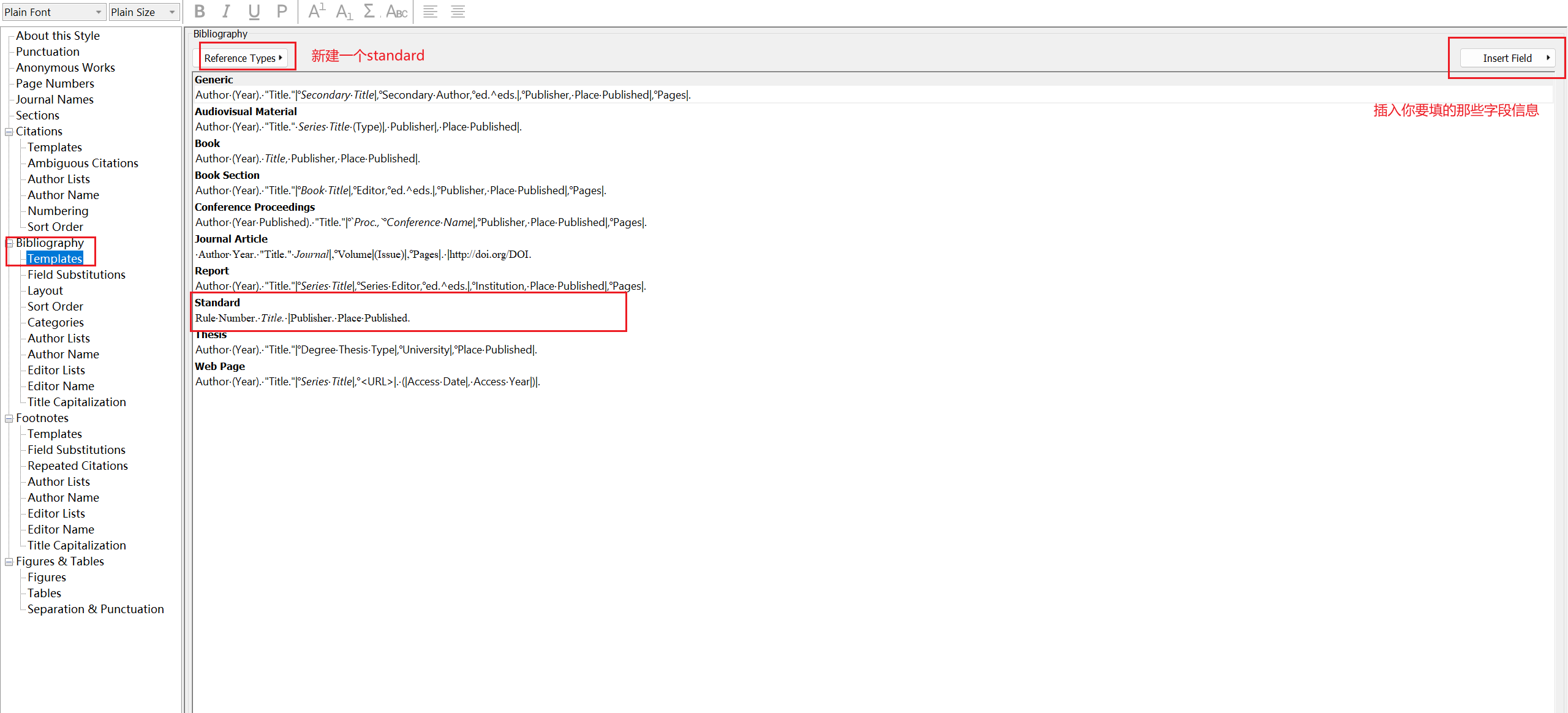Reference填入信息参考 插入英文期刊规范ASTM 1.插入国标JTG 2034-2020这种 首先找到大家要投稿的英文期刊,然后去找那些中…...
重写 UGUI
重写Button using UnityEngine; using UnityEngine.UI; public class MyButton : Button {[SerializeField] private int _newNumber; }using UnityEditor;//编辑器类在UnityEditor命名空间下。所以当使用C#脚本时,你需要在脚本前面加上 "using UnityEditor&q…...

合宙Air724UG LuatOS-Air LVGL API控件--容器 (Container)
容器 (Container) 容器是 lvgl 相当重要的一个控件了,可以设置布局,容器的大小也会自动进行调整,利用容器可以创建出自适应成都很高的界面布局。 代码示例 – 创建容器 cont lvgl.cont_create(lvgl.scr_act(), nil) lvgl.obj_set_auto_re…...

代码随想录训练营第41天|343.整数拆分,96.不同的二叉搜索树
代码随想录训练营第41天|343.整数拆分,96.不同的二叉搜索树 343.整数拆分文章思路代码 96.不同的二叉搜索树文章思路代码 总结 343.整数拆分 文章 代码随想录|0343.整数拆分 思路 二刷不难 d p [ i ] M a x j ( m a x ( j 1 , d p [ j ] ) ∗ ( i − j ) ) \…...

高防服务器与云防产品都适用哪些情况
高防服务器与云防护产品(如高防IP,高防CDN)都可以对DDOS、CC等攻击进行防护,在现如今的互联网市场上,不法分子经常会通过DDOS、CC等攻击服务器,干扰业务正常运行,以此来获得利益。 高防服务器是…...

【广州华锐互动】AR远程连接专家进行协同管理,解放双手让协同更便捷
AR远程协同系统是一种基于AR技术,实现远程设备维修和技术支持的系统。该系统通过将虚拟信息叠加在现实世界中,实现对设备的全方位监控和管理,并可以通过AR眼镜等终端设备,实时查看设备的各项数据和信息,为设备维修提供…...

PNG图片压缩原理
png??png的图片我们每天都在用,可是png到底是什么,它的压缩原理是什么? 很好,接下来我将会给大家一一阐述。 什么是PNG PNG的全称叫便携式网络图型(Portable Network Graphics)是…...

[ Linux Audio 篇 ] Linux Audio 子系统资料集锦
Linux Audio 子系统资料 背景OSS VS ALSAALSA 驱动ALSA libALSA Plugin音频延迟音频调试音频书籍 背景 最近需要准备Linux Audio 相关的PPT,于是将以往的知识点和遇到的问题进行整理和梳理,以便向大家讲解。同时,还整理了在这个过程中发现的…...

VR全景对行业发展有什么帮助?VR全景制作需要注意什么?
引言: 虚拟现实(Virtual Reality,简称VR)早已不再是科幻电影的概念,而是在以惊人的速度改变着我们的世界。VR全景,作为其中的重要组成部分,正为多个行业带来了全新的机遇。 一、VR全景的应用领…...

Unity网络请求队列
引子 最近的一个项目中由于某个需求,需要多次请求后台接口数据,就自己封装了一下网络请求的队列;刚刚好给大家分享一下,互相交流学习 简述 Unity 的网络请求队列是由 UnityWebRequestQueue 类实现的。这个类继承自 MonoBehaviou…...

【Spring Boot】使用XML配置文件实现数据库操作(一)
使用XML配置文件实现数据库操作(一) 1.SQL映射文件 SQL映射文件就是我们通常说的mapper.xml配置文件,主要实现SQL语句的配置和映射,同时实现Java的POJO对象与数据库中的表和字段进行映射关联的功能。 1.1 mapper.xml的结构 下…...

PMP中常用英文术语
常用术语(五) Project 项目 为完成一个唯一的产品或服务的一种一次性努力。 Project Charter 项目许可证 由高级管理部门提供的一个文档,它给项目经理特权把组织的资源应用到项目工作中。 Project Communication Management 项目沟通管理 项目…...

【Apollo学习笔记】——规划模块TASK之SPEED_BOUNDS_PRIORI_DECIDERSPEED_BOUNDS_FINAL_DECIDER
文章目录 前言SPEED_BOUNDS_PRIORI_DECIDER功能简介SPEED_BOUNDS_FINAL_DECIDER功能简介SPEED_BOUNDS_PRIORI_DECIDER相关配置SPEED_BOUNDS_FINAL_DECIDER相关配置SPEED_BOUNDS_DECIDER流程将障碍物映射到ST图中ComputeSTBoundary(PathDecision* path_decision)ComputeSTBounda…...

score_inverse_problems运行环境,pycharm重新安装,jax,jaxlib的GPU版本安装-230831
尝试运行https://github.com/yang-song/score_inverse_problems pycharm2019不支持python3.10,其实后来我用来3.8…… pycharm2022.3.3的安装,涉及激活(淘宝5元),搜狗拼音输入(shift不能切换输入法&#x…...

VSC++: 奇怪的风吹
void 奇怪的风吹() {//缘由https://ask.csdn.net/questions/1062454int aa[]{15, 30, 12, 36, 11, 20, 19, 17, 16, 18, 38, 15, 30, 12, 36, 11, 20, 19, 17, 16, 18, 38, -1},j 0, a 0, y 0, z 0;while (aa[j] > 0){if (j && aa[j] > 35 || aa[j] < 15)…...

被动操作系统指纹识别的强大功能可实现准确的物联网设备识别
到 2030 年,企业网络和互联网上的物联网设备数量预计将达到290 亿。这种指数级增长无意中增加了攻击面。 每个互连设备都可能为网络攻击和安全漏洞创造新的途径。Mirai 僵尸网络通过使用数千个易受攻击的 IoT 设备对关键互联网基础设施和热门网站发起大规模 DDoS 攻…...
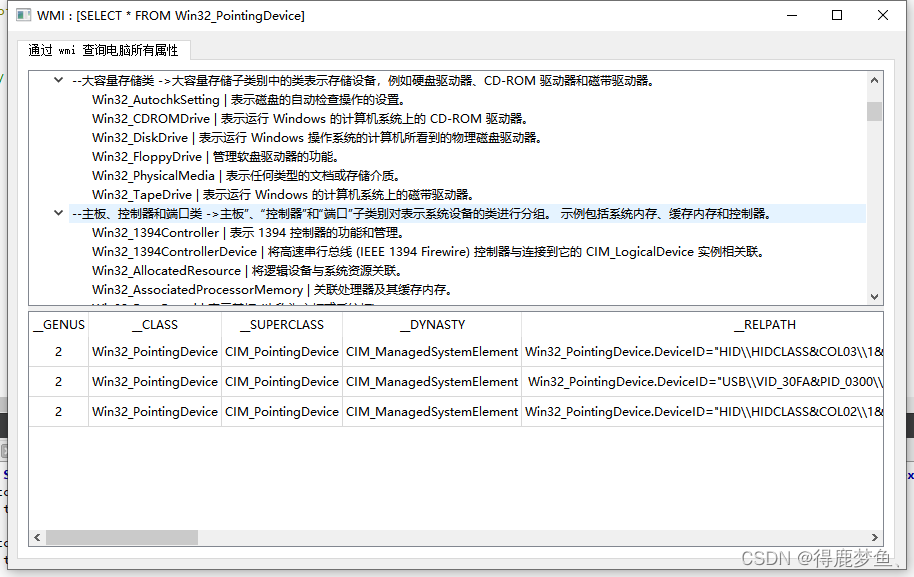
QT/C++获取电脑系统,主板型号,CPU型号,硬盘型号,内存大小等相关信息(二)通过Windows Server (WMI)查询
Qt/C调用windows Api库通过wmi的方式查询电脑能获取更多详细信息,也更加合理有技术性。 建议使用MSCV编译器,如MSCV 2017 ,Qt版本 : 5.13.1 目录导读 关于 WMI示例:创建 WMI 应用程序示例:打印Wmi执行的查询项的所有属性头文件引用…...
自建音乐服务器Navidrome之一
这里写自定义目录标题 1.1 官方网站 2. Navidrome 简介2.1 简介2.2 特性 3. 准备工作4. 视频教程5. 界面演示5.1 初始化页5.2 专辑页 前言 之前给大家介绍过 Koel 音频流服务,就是为了解决大家的这个问题:下载下来的音乐,只能在本机欣赏&…...

ACL 访问控制 过滤数据 维护网络安全(第七课)
一 ACL 简介 ACL是Access Control List(访问控制列表)的缩写,是一种用于控制文件、目录、网络设备等资源访问权限的方法。ACL可以对每个用户或用户组设置不同的访问权,即在访问控制清单中为每个用户或用户组指定允许或禁止访问该资源的权限。它通常由一系列规则组成,规则…...

UltraScale架构FPGA功耗优化技术与工程实践
1. UltraScale架构的功耗优化技术全景解析在当今高性能计算和通信领域,功耗已成为FPGA选型的决定性因素之一。Xilinx UltraScale架构通过多层次的创新,在20nm工艺节点上实现了显著的功耗降低。作为深耕FPGA设计十余年的工程师,我将从实际应用…...

Dot自定义配置指南:调整模型参数满足个性化需求
Dot自定义配置指南:调整模型参数满足个性化需求 【免费下载链接】Dot Text-To-Speech, RAG, and LLMs. All local! 项目地址: https://gitcode.com/gh_mirrors/dot1/Dot Dot是一款功能强大的本地AI应用,支持文本转语音、RAG(检索增强生…...

Arduino智能小车避障与拟人化设计:从传感器到行为逻辑
1. 项目概述与核心思路最近在整理工作室的物料,翻出了几个闲置的360度舵机和超声波模块,手痒之下决定做个智能小车玩玩。这个项目本身不新鲜,网上教程一抓一大把,但我想做点不一样的:不仅要能实现基础的自动避障&#…...

《魔兽世界》怀旧服:纳克萨玛斯教官拉苏维奥斯战术详解与实战心得
1. 教官拉苏维奥斯战斗机制解析 教官拉苏维奥斯作为纳克萨玛斯军事区的守门BOSS,其战斗核心在于学员控制循环与仇恨管理的双重考验。这个BOSS战最特别的地方在于,你需要同时应对教官本体的高伤害和四名学员的协同作战。很多团队第一次开荒时容易忽略学员…...

未来是神经-符号的:AI 推理是如何演变的
原文:towardsdatascience.com/the-future-is-neuro-symbolic-how-ai-reasoning-is-evolving-143ce6485b4f 人工智能软件被用于增强本文文本的语法、流畅性和可读性。 一个名为AlphaGeometry的显著新 AI 系统最近解决了大多数人类都难以解决的困难高中水平数学问题。…...

对话式AI智能中继与编排框架:构建高可用AI应用的核心架构
1. 项目概述:一个面向对话式AI的智能中继与编排框架最近在折腾一个挺有意思的开源项目,叫ChatAgentRelay。乍一看这个名字,可能觉得它又是一个聊天机器人框架,但深入把玩之后,我发现它的定位其实更精准,也更…...

Cursor编辑器深度美化:CSS注入与动态特效实现全解析
1. 项目概述:当代码编辑器拥有了“皮肤”与“特效”如果你和我一样,每天有超过8小时的时间是在代码编辑器里度过的,那么你一定理解一个顺眼、顺手、甚至有点“酷”的编辑环境意味着什么。它不仅仅是生产力的工具,更是我们开发者思…...

别再格式化U盘了!Ubuntu 22.04 LTS下永久解决exFAT支持问题的完整配置指南
永久解决Ubuntu 22.04 LTS的exFAT兼容性问题:从原理到实践 当你在Ubuntu系统中插入一个exFAT格式的U盘或移动硬盘时,那个令人沮丧的错误提示可能已经出现过多次:"unknown filesystem type exfat"。这不是偶然现象,而是源…...

当AI的键值记忆遇上大脑:原来我们和AI共享同一套记忆逻辑
导语在日常经验中,我们常把“遗忘”理解为信息的流失:时间久了,记忆就会慢慢消失;学习新知识,也可能覆盖旧内容。然而,从短视频推荐到大语言模型,再到人类被线索唤醒的记忆体验,这些…...

Synabun:Node.js 高可靠 HTTP 请求策略引擎详解
1. 项目概述:一个被低估的HTTP请求库如果你经常在Node.js环境下处理HTTP请求,大概率用过axios、node-fetch或者原生的http模块。这些工具各有优劣,但当你需要处理复杂的重试逻辑、精细的速率限制、或者想在一个统一的接口下管理多种请求策略时…...