Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。
更多相关内容可见Fastchat实战部署vicuna-7b-v1.3(小羊驼)_Spielberg_1的博客-CSDN博客
一、配置环境
conda create -n fastchat python=3.9 # fastchat官方建议Python版本要>= 3.8
切换到fastchat
conda activate fastchat安装torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1
pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1
二、安装fastchat和transformers
安装fschat==0.1.10,官方建议vicuna-7b-delta-v0对应的fastchat版本低于0.1.10
pip install fschat==0.1.10安装transformers
pip install transformers三、合并权重,生成vicuna-7b-v0模型
python -m fastchat.model.apply_delta \--base /root/LLaMA-7B-hf/llama-7b-hf \--target /root/vicuna-7b-v0 \--delta /root/vicuna-7b-delta-v0| base | hf格式的llama-7b模型的路径 |
| target | 合并权重后生成的vicuna-7b-v0模型路径,稍后启动FastChat要用 |
| delta | 从huggingface下载的vicuna-7b-delta-v0路径 |
vicuna-7b模型合并需要30G的RAM,请合理评估
生成目标模型保存在/root/vicuna-7b-v0

命令行输出
(fastchat) root@dl-230904040428gxb-pod-jupyter-7599dcdb54-qjppf:~# python -m fastchat.model.apply_delta --base /root/LLaMA-7B-hf/llama-7b-hf --target /root/vicuna-7b-v0 --delta /root/vicuna-7b-delta-v0
Loading the base model from /root/LLaMA-7B-hf/llama-7b-hf
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [02:12<00:00, 4.03s/it]
Loading the delta from /root/vicuna-7b-delta-v0
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [02:56<00:00, 88.21s/it]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. If you see this, DO NOT PANIC! This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=True`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
Applying the delta
Applying delta: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 291/291 [00:24<00:00, 11.96it/s]
Saving the target model to /root/vicuna-7b-v0
四、推理
python3 -m fastchat.serve.cli --model-path /root/vicuna-7b-v0| model-path | 上一步合并生成的target路径 |

控制台输出,Human是输入,Assistant是模型的回复
(fastchat) root@dl-230904040428gxb-pod-jupyter-7599dcdb54-qjppf:~# python3 -m fastchat.serve.cli --model-path /root/vicuna-7b-v0
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. If you see this, DO NOT PANIC! This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=True`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [02:00<00:00, 60.38s/it]
Human: hello
Assistant: Hello! How can I help you today?
Human: can you tell me a jok
Assistant: Sure, here's a joke for you:
Why was the math book sad?
Because it had too many problems!
I hope you found that joke amusing. Do you have any other questions or topics you'd like to discuss?
Human: a guide to touring in China
Assistant: China is a vast and diverse country with a rich history and culture, and there is no shortage of things to see and do. Here are some tips for touring in China:
1. Plan ahead: Research the destinations you want to visit, the best time to go, and the logistics of getting there. Consider factors such as cost, time, transportation, and accommodation.
2. Get a visa: Depending on your nationality, you may need to obtain a visa before you travel to China. Make sure you have enough time to apply for a visa and that you have all the necessary documents.
3. Pack appropriately: Pack clothes for the season, and bring a mix of casual and formal wear. Also, don't forget to pack any necessary medication and travel accessories like a first aid kit, phone charger, and a portable battery pack.
4. Learn some basic Mandarin: While many people in China speak English, having some basic Mandarin will help you communicate with locals and navigate the country more easily.
5. Be respectful: China is a highly cultured country, and it's important to be respectful of local customs and traditions. Dress modestly, avoid pointing with your chin, and avoid discussing sensitive political or religious topics.
6. Try the local food: Chinese cuisine is diverse and delicious, and there are many local specialties to try. Don't be afraid to try new things, but be aware of food safety concerns and only eat at reputable restaurants.
7. Stay safe: Be aware of your surroundings and take proper safety precautions, such as avoiding unfamiliar or poorly lit areas at night, and keeping valuable items safe.
8. Enjoy the experience: China is a beautiful and fascinating country, and there is no shortage of things to see and do. Enjoy the experience, take it all in, and have a great time!
Human: how to study vicuna
Assistant: Studying vicuñas can be a challenging and rewarding experience, but it requires careful planning and preparation. Here are some tips for studying vicuñas:
1. Research the species: Learn about the biology, behavior, and ecology of vicuñas, including their habitat, diet, and social structure.
2. Identify the best sites: Identify the best sites to study vicuñas, such as national parks, wildlife reserves, or other protected areas. Make sure you have permission to study the vicuñas and that you are familiar with the local regulations and laws.
3. Develop your skills: Develop the necessary skills to study vicuñas, such as knowledge of the local language, tracking and observation skills, and experience in capturing and handling animals.
4. Set up your equipment: Set up your equipment, such as cameras, GPS devices, and other necessary tools, to monitor and study the vicuñas.
5. Observe and collect data: Observe the vicuñas in their natural habitat and collect data on their behavior, such as their movement patterns, feeding habits, and social interactions.
6. Analyze your data: Analyze the data you have collected and draw conclusions about the behavior and ecology of the vicuñas.
7. Communicate your findings: Communicate your findings to other researchers and conservationists, and use your research to inform conservation efforts and protect the vicuñas.
8. Consider the ethics: Remember to consider the ethical implications of your study and to minimize any negative impacts on the vicuñas and their habitat.
总结:vicuna-7b支持英文,回答能力有限。
遇到的问题
ImportError: cannot import name 'is_tokenizers_available' from 'transformers.utils'
原因:transformers版本不匹配
解决方法:安装transformers,
pip install transformers查看版本为4.32.1

ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported.

翻译;ValueError:Tokenizer类LLaMATokenizer不存在或当前未导入。
原因:transformers版本更新,AutoTokenizer 更新为LlamaTokenizer,AutoModelForCausalLM 更新为LlamaForCausalLM
解决办法:
1、打开fastchat.model.apply_delta.py
将所有的AutoTokenizer 替换为 LlamaTokenizer
AutoModelForCausalLM 替换为 LlamaForCausalLM
2、找到llama-7b的模型,改动tokenizer_config.json文件,
把"tokenizer_class": "LLaMATokenizer" 改为 "tokenizer_class": "LlamaTokenizer".
ImportError: cannot import name ‘LlamaTokenizerFast’ from ‘transformers’
翻译:ImportError:无法从“transformers”导入名称“LlamaTokenizerFast”
原因:transformers中无法导入LlamaTokenizerFast
解决:
确认您已经安装了最新的 Transformers 库:请检查您是否已经安装了最新版本的 Transformers 库,您可以使用pip命令来更新Transformers库:
pip install --upgrade transformers检查LlamaTokenizerFast是否存在于Transformers库中:请确保您在Transformers库中找到了LlamaTokenizerFast类。您可以查看Transformers文档或使用以下命令来检查:
python -c "from transformers import LlamaTokenizerFast"如果该命令未报告任何错误,则表示LlamaTokenizerFast类可用。
UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment
解决办法:
pip install protobufError:AutoTokenizer.from_pretrained,UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment · Issue #25848 · huggingface/transformers · GitHub
RuntimeError: The size of tensor a (32000) must match the size of tensor b (32001) at non-singleton dimension 0
原因:fastchat版本不匹配,降低到0.1.10版本
查看“FastChat版本兼容性”文档:https://github.com/lm-sys/FastChat/blob/main/docs/vicuna_weights_version.md
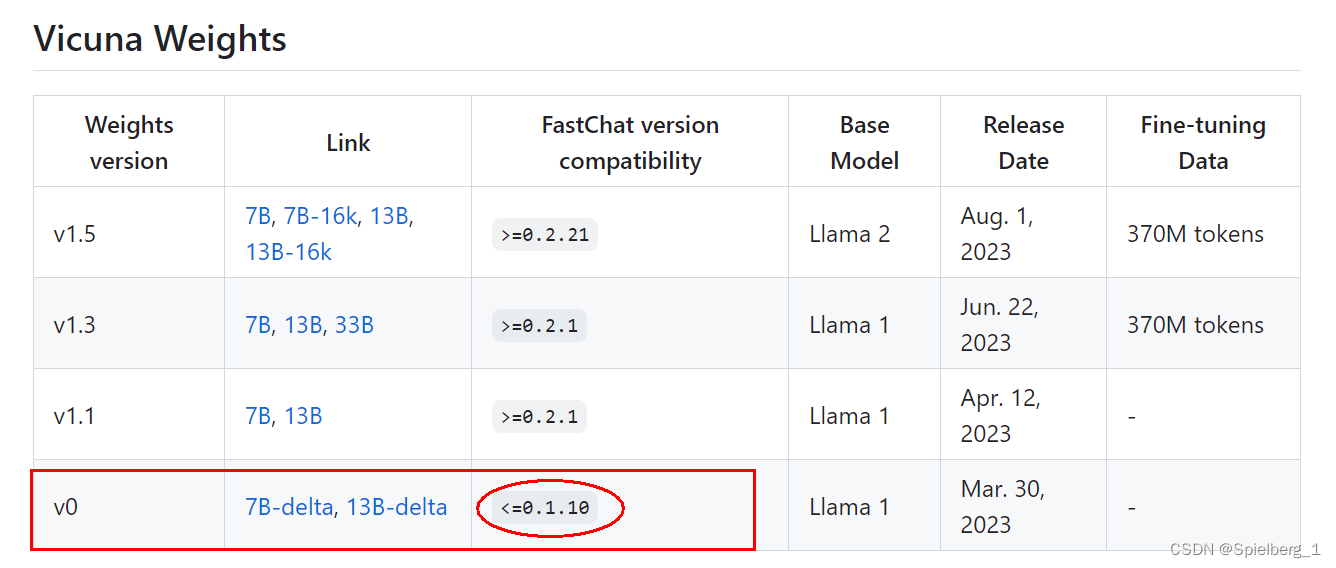
有效的方式:
pip install fschat==0.1.10RuntimeError: The size of tensor a (32000) must match the size of tensor b (32001) at non-singleton dimension 0 · Issue #132 · Vision-CAIR/MiniGPT-4 · GitHub
用到的ubuntu命令:
chmod +rwx file 给file文件添加读、写、执行权限。r表示可读,w表示可写,x表示执行
chmod -rwx file 删除file文件读、写、执行权限
nvidia-smi -l 5 每隔5秒刷新nvidia-smi,实时查看GPU使用、显存占用情况
参考
Fastchat实战部署vicuna-7b-v1.3(小羊驼)_Spielberg_1的博客-CSDN博客
nvidia-smi命令实时查看GPU使用、显存占用情况_我们是宇宙中最孤独的孩子的博客-CSDN博客
MiniGPT-4 本地部署 RTX 3090 - 知乎
解决ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported_wx6176918821622的技术博客_51CTO博客
http://www.kuazhi.com/post/445223.html
ChatGPT DeepSpeed 部署中bug以及解决方法_博客_夸智网
Error:AutoTokenizer.from_pretrained,UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment · Issue #25848 · huggingface/transformers · GitHub
ubuntu如何修改读写权限设置 - 小小蚂蚁
小羊驼模型(FastChat-vicuna)运行踩坑记录 - 知乎
win10,win11 下部署Vicuna-7B,Vicuna-13B模型,gpu cpu运行_babytiger的博客-CSDN博客
相关文章:
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。 更多相关内容可见Fastchat实战…...

Centos、OpenEuler系统安装mysql
要在CentOS上安装MySQL并设置开机自启和root密码,请按照以下步骤进行操作: 确保您的CentOS系统已连接到Internet,并且具有管理员权限(root或sudo访问权限)。打开终端或SSH会话,使用以下命令安装MySQL&…...
如何在Win10系统上安装WSL(适用于 Linux 的 Windows 子系统)
诸神缄默不语-个人CSDN博文目录 本文介绍的方法不是唯一的安装方案,但在我的系统上可用。 文章目录 1. 视频版2. 文字版和代码3. 本文撰写过程中使用到的其他网络参考资料 1. 视频版 B站版:在Windows上安装Linux (WSL, 适用于 Linux 的 Windows 子系统…...
单片机通用学习-什么是寄存器?
什么是寄存器? 寄存器是一种特殊的存储器,主要用于存储和检查微机的状态。CPU寄存器用于存储和检查CPU的状态,具体包括计算中途数据、程序因中断或子程序分支时的返回地址、计算结果为零时的负值、计算结果为零时的信息、进位值等。 由于CP…...

【C语言】文件操作详解
文章目录 前言一、文件是什么二、文件具体介绍1.文件名2.文件类型3.文件缓冲区4.文件指针5.文件的打开和关闭 三、文件的顺序读写1.字符输入函数(fgetc)2.字符输出函数(fputc)3.文本行输入函数(fgets)4.文本…...

栈(Stack)的详解
目录 1.栈的概念 2.栈的模拟实现 1.栈的方法 2.模拟栈用(整型)数组的形式呈现 2.1栈的创建 2.2压栈 2.3栈是否为空 2.4出栈 2.5获取栈中有效元素个数 2.6获取栈顶元素 2.7完整代码实现 1.栈的概念 从上图中可以看到, Stack 继承了…...

深入了解GCC编译过程
关于Linux的编译过程,其实只需要使用gcc这个功能,gcc并非一个编译器,是一个驱动程序。其编译过程也很熟悉:预处理–编译–汇编–链接。在接触底层开发甚至操作系统开发时,我们都需要了解这么一个知识点,如何…...

leetcode 594.最长和谐子序列(滑动窗口)
⭐️ 题目描述 🌟 leetcode链接:最长和谐子序列 思路: 第一步先将数组排序,在使用滑动窗口(同向双指针),定义 left right 下标,比如这一组数 {1,3,2,2,5,2,3,7} 排序后 {1,2,2,2,3,…...

深入剖析云计算与云服务器ECS:从基础到实践
云计算已经在不断改变着我们的计算方式和业务模式,而云服务器ECS(Elastic Compute Service)作为云计算的核心组件之一,为我们提供了灵活、可扩展的计算资源。在本篇长文中,我们将从基础开始,深入探讨云计算…...
苍穹外卖技术栈
重难点详解 1、定义全局异常 2、ThreadLocal ThreadLocal 并不是一个Thread,而是Thread的一个局部变量ThreadLocal 为每一个线程提供独立的存储空间,具有线程隔离的效果,只有在线程内才能取到值,线程外则不能访问 public void …...

重新开始 杂类:C++基础
目录 1.输入输出 2 . i 与 i 3.结构体 4.二进制 1.输入输出 #include<cstdio>//cin>>,cout #include<iostream>//printf,scanf (1) cin , cout输入输出流可直接用于数字,字符 (2)scanf(&quo…...

自用的markdown与latex特殊符号
\triangleq \approx \xlongequal[y\arctan x]{x\tan y} \sum_{\substack{j1 \\ j\neq i}} \iiint\limits_\Omega \overset{\circ}{\vec{r}} \varphi \checkmark \stackrel{\cdot\cdot\cdot}{x}≜ ≈ y arctan x x tan y ∑ j 1 j ≠ i ∭ Ω r ⃗ ∘ φ ✓ x ⋅ ⋅ ⋅…...
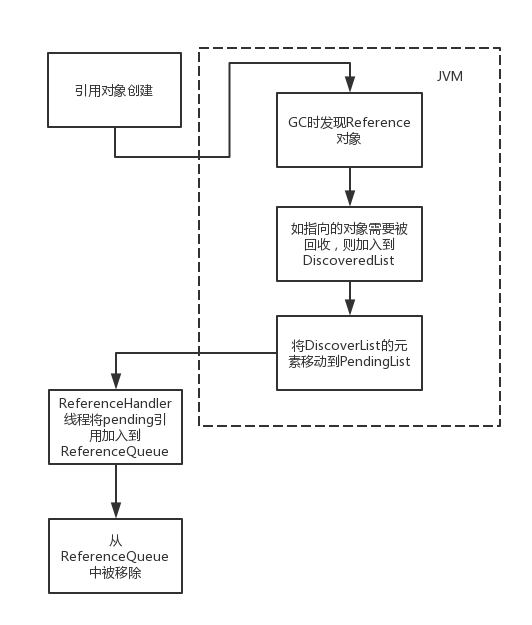
【20期】说一说Java引用类型原理
Java中一共有4种引用类型(其实还有一些其他的引用类型比如FinalReference):强引用、软引用、弱引用、虚引用。 其中强引用就是我们经常使用的Object a new Object(); 这样的形式,在Java中并没有对应的Reference类。 本篇文章主要是分析软引用、弱引用、…...

无锡布里渊——厘米级分布式光纤-锅炉安全监测解决方案
无锡布里渊——厘米级分布式光纤-锅炉安全监测解决方案 厘米级分布式光纤-锅炉安全监测解决方案 1、方案背景与产品简介: 1.1:背景简介: 锅炉作为一种把煤、石油或天燃气等化石燃料所储藏的化学能转换成水或水蒸气的热能的重要设备ÿ…...

GREASELM: GRAPH REASONING ENHANCED LANGUAGE MODELS FOR QUESTION ANSWERING
本文是LLM系列文章,针对《GREASELM: GRAPH REASONING ENHANCED LANGUAGE MODELS FOR QUESTION ANSWERING》的翻译。 GREASELM:图推理增强的问答语言模型 摘要1 引言2 相关工作3 提出的方法:GREASELM4 实验设置5 实验结果6 结论 摘要 回答关…...
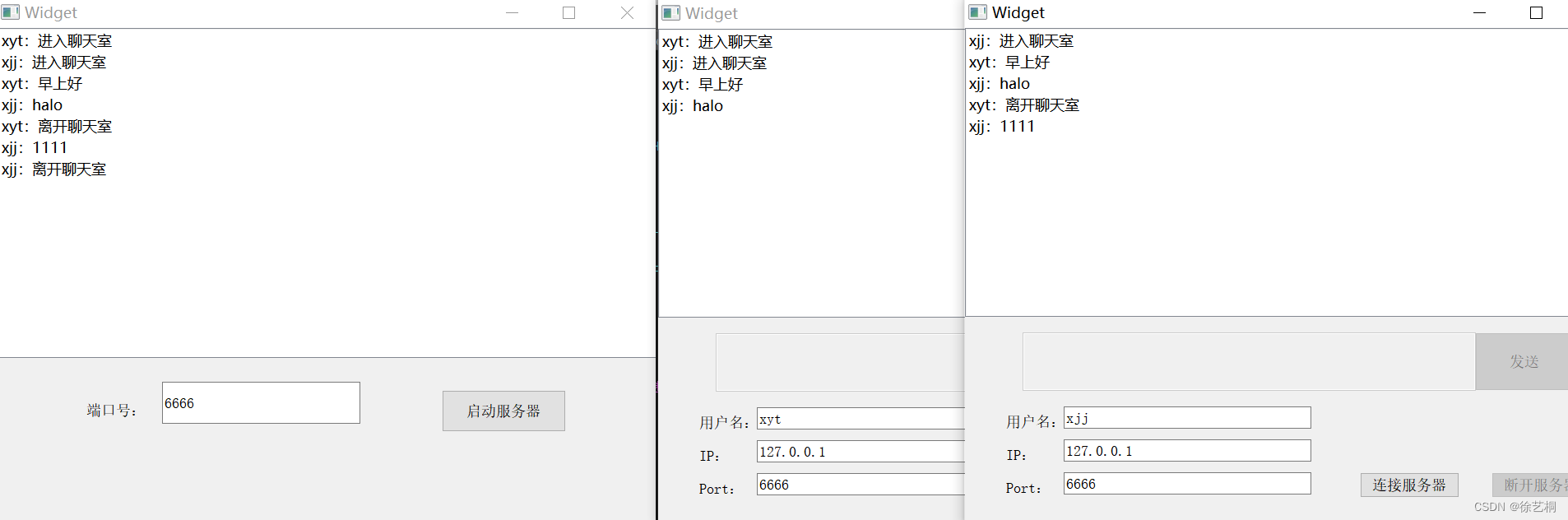
QT C++ 实现网络聊天室
一、基本原理及流程 1)知识回顾(C语言中的TCP流程) 2)QT中的服务器端/客户端的操作流程 二、代码实现 1)服务器 .ui .pro 在pro文件中添加network库 .h #ifndef WIDGET_H #define WIDGET_H#include <QWidget>…...

每日一道面试题之什么是上下文切换?
上下文切换是指在计算机操作系统中,当多个进程或线程同时运行时,系统需要将当前运行进程或线程的状态(包括程序计数器、寄存器值、内存映像等)保存起来,然后切换到另一个进程或线程继续执行的过程。上下文切换通常由操…...
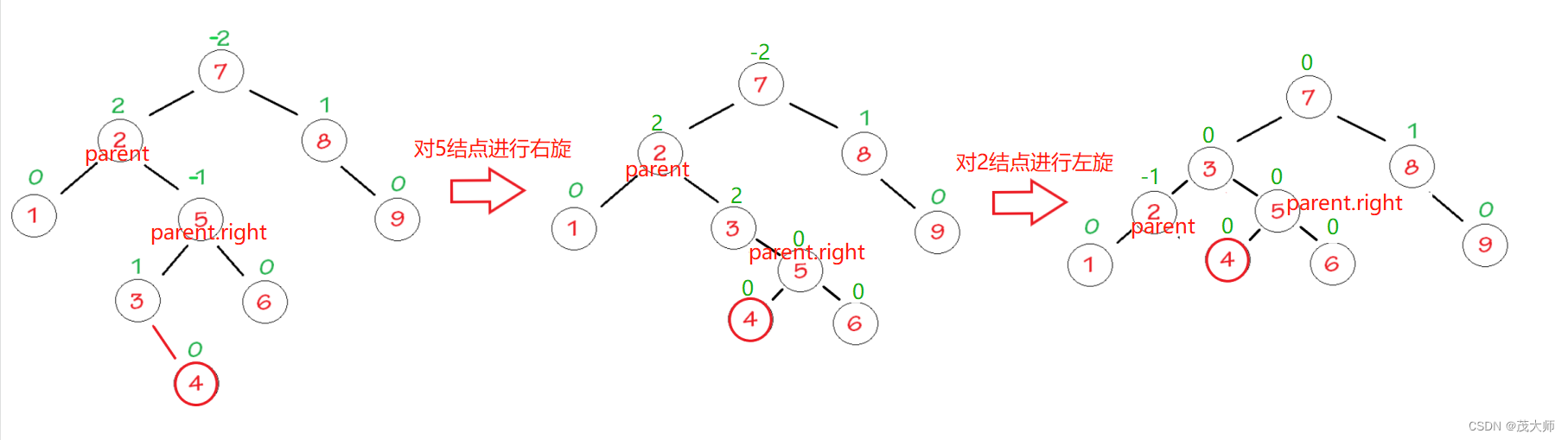
2023.9.3 关于 AVL 树
目录 二叉搜索树 二叉搜索树的简介: 二叉搜索树的查找: 二叉搜索树的效率: AVL树 AVL 树的简介: AVL 树的实现: AVL树的旋转 右单旋 左单旋 左右双旋 右左双旋 完整 AVL树插入代码 验证 AVL 树 AVL 树的性…...

机器学习课后习题 --- 机器学习实践
(一)单选题 1.以下关于训练集、验证集和测试集说法不正确的是( )。 A:测试集是纯粹是用于测试模型泛化能力B:训练集是用来训练以及评估模型性能 C:验证集用于调整模型参数 D:以上说法都不对 2.当数据分布不平衡时,我们可采取的措施不包括…...

git常用操作
删除分支 例:例如想删除的分支是dev_delete,那么可以按照如下的操作进行 #查看当前所在分支 git branch#如果在当前dev_delete分支上,就要切换到其他分支才能删除该分支 git checkout 其他分支#删除本地名为dev_delete的分支 git branch -d dev_delete…...
18 CLIP 论文精读:ViT 如何走向图文多模态?(Learning Transferable Visual Models From Natural Language Supervision)
在前几篇文章中,我们围绕 ViT 的自监督预训练路线进行了连续梳理。MAE 的核心思想是:遮住大部分图像 patch,让模型重建被遮挡区域的像素。BEiT 的核心思想是:先用视觉 tokenizer 把图像转换成离散 visual token,再让模…...

2026年AI论文写作工具实测排行,哪款真正适合写论文?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5ÿ…...

电脑自动化 OpenClaw 安装教程 自然语言操控电脑
告别命令行!Windows OpenClaw 一键安装,5 分钟一键部署 ✨ 前言 OpenClaw(小龙虾)是一款能直接操控电脑的 AI 智能体,无需复杂配置、不用敲命令行,Windows 环境下全程可视化操作,5 分钟即可完…...

揭秘AI专著撰写:工具加持,20万字专著快速成型!
AI专著写作:挑战与工具解决方案 学术专著的撰写,不仅考验着研究者的学术能力,更是对心理耐受力的一种挑战。与团队合作撰写论文不同,专著大多是由个人独立完成的。从选题到框架构建,再到具体内容的撰写、修改…...

在 Clean Core 约束下扩展 SAP S/4HANA 标准 OData API
我们正在做的事情很具体,S/4HANA 后端已经能够发布产品主数据相关的 Enterprise Event,事件经过 Integration Suite、Event Mesh、Advanced Event Mesh,再进入 Kafka Event Broker,消费系统按照 product type 订阅不同的 material event。链路跑通以后,业务方很快发现一个…...

边缘AI语音交互实战:从唤醒词识别到MCP外设控制的嵌入式实现
1. 项目概述:当边缘计算遇见语音交互 最近在折腾一个挺有意思的项目,核心是把语音交互的能力从云端“拽”下来,直接部署到边缘设备上,然后让它去控制各种MCP(Microcontroller Peripheral)外设。听起来像是智…...

5步彻底解决显卡风扇异常:FanControl专业调校完全指南
5步彻底解决显卡风扇异常:FanControl专业调校完全指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...

避坑指南:STM32F407的DAC输出Buffer为啥会导致0V?ADC连续转换模式与DMA配置的细节解析
STM32F407模拟信号处理实战:DAC输出与ADC采样的深度避坑指南 1. 从异常现象到原理剖析:DAC输出Buffer的隐藏陷阱 调试STM32F407的DAC外设时,不少开发者都遇到过这样的困惑:明明配置了正确的数值,输出电压却始终为0V。…...

Android Studio中文界面全面配置指南:专业汉化解决方案
Android Studio中文界面全面配置指南:专业汉化解决方案 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack Android Studi…...

抖音视频批量下载工具:免费保存去水印内容完整指南
抖音视频批量下载工具:免费保存去水印内容完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...