Hadoop的概述与安装
Hadoop的概述与安装
- 一、Hadoop内部的三个核心组件
- 1、HDFS:分布式文件存储系统
- 2、YARN:分布式资源调度系统
- 3、MapReduce:分布式离线计算框架
- 4、Hadoop Common(了解即可)
- 二、Hadoop技术诞生的一个生态圈
- 数据采集存储
- 数据清洗预处理
- 数据统计分析
- 数据迁移
- 数据可视化
- zookeeper
- 三、主要围绕Apache的Hadoop发行版本来学习
- 四、Hadoop的安装的四种模式
- 五、Hadoop的伪分布安装流程
- 六、格式化HDFS集群
- 七、启动HDFS和YARN
- 八、Hadoop的完全分布式安装
- 1、克隆虚拟机
- 2、安装JDK
- 3、安装Hadoop完全分布式
- 4、格式化HDFS
- 5、启动HDFS和YARN
Hadoop技术 —— 脱自于Google的三篇论文(大数据软件一般都要求7*24小时不宕机)
把大数据中遇到的两个核心问题(海量数据的存储问题和海量数据的计算问题)全部解决了
一、Hadoop内部的三个核心组件
1、HDFS:分布式文件存储系统
分布式思想解决了海量数据的分布式存储问题
三个核心组件组成
- NameNode:主节点
- 存储整个HDFS集群的元数据(目录结构)
- 管理整个HDFS集群
- DataNode:数据节点/从节点
- 存储数据的,DataNode以Block块的形式进行文件存储
- SecondaryNameNode:小秘书
- 帮助NameNode合并日志数据的(元数据)
2、YARN:分布式资源调度系统
解决分布式计算程序的资源分配以及任务监控问题
Mesos:分布式资源管理系统(YARN的替代品)
两个核心组件组成
- ResourceManager:主节点
- 管理整个YARN集群的,同时负责整体的资源分配
- NodeManager:从节点
- 真正负责进行资源提供的
3、MapReduce:分布式离线计算框架
分布式思想解决了海量数据的分布式计算问题
4、Hadoop Common(了解即可)
二、Hadoop技术诞生的一个生态圈
数据采集存储
flume、Kafka、hbase、hdfs
数据清洗预处理
MapReduce、Spark
数据统计分析
Hive、Pig
数据迁移
sqoop
数据可视化
ercharts
zookeeper
三、主要围绕Apache的Hadoop发行版本来学习
官网:https://hadoop.apache.org
apache hadoop发行版本
- hadoop1.x
- hadoop2.x
- hadoop3.x
- hadoop3.1.4
四、Hadoop的安装的四种模式
hadoop软件中HDFS和YARN是一个系统,而且是一个分布式的系统,同时他们还是一种主从架构的软件。
第一种:本地安装模式:只能使用MapReduce,HDFS、YARN均无法使用 —— 基本不用
第二种:伪分布安装模式:hdfs和yarn的主从架构软件全部安装到同一个节点上
第三种:完全分布式安装模式:hdfs和yarn的主从架构组件安装到不同的节点上
第四种:HA高可用安装模式:hdfs和yarn的主从架构组件安装到不同节点上,同时还需要把他们的主节点多安装两三个,但是在同一时刻只能有一个主节点对外提供服务 —— 借助Zookeeper软件才能实现
修改配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-env.sh、mapred-site.xml、yarn-site.xml、yarn-env.sh、workers、log4j.properties、capacity-scheduler.xml、dfs.hosts、dfs.hosts.exclude
五、Hadoop的伪分布安装流程
1、需要在Linux上先安装JDK,Hadoop底层是基于Java开发的
- 环境变量的配置主要有两个地方可以配置
/etc/profile:系统环境变量
~/.bash_profile:用户环境变量
环境变量配置完成必须重新加载配置文件
source 环境变量文件路径
2、配置当前主机的主机映射以及ssh免密登录
3、安装本地版本的Hadoop
- 上传 —— 使用xftp将Windows下载好的
hadoop-3.1.4.tar.gz传输到/opt/software目录下 - 解压 ——
tar -zxvf hadoop-3.1.4.tar.gz -C /opt/app - 配置环境变量
vim /etc/profileexport HADOOP_HOME=/opt/app/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
4、安装伪分布式版本的Hadoop
修改各种各样的hadoop配置文件即可
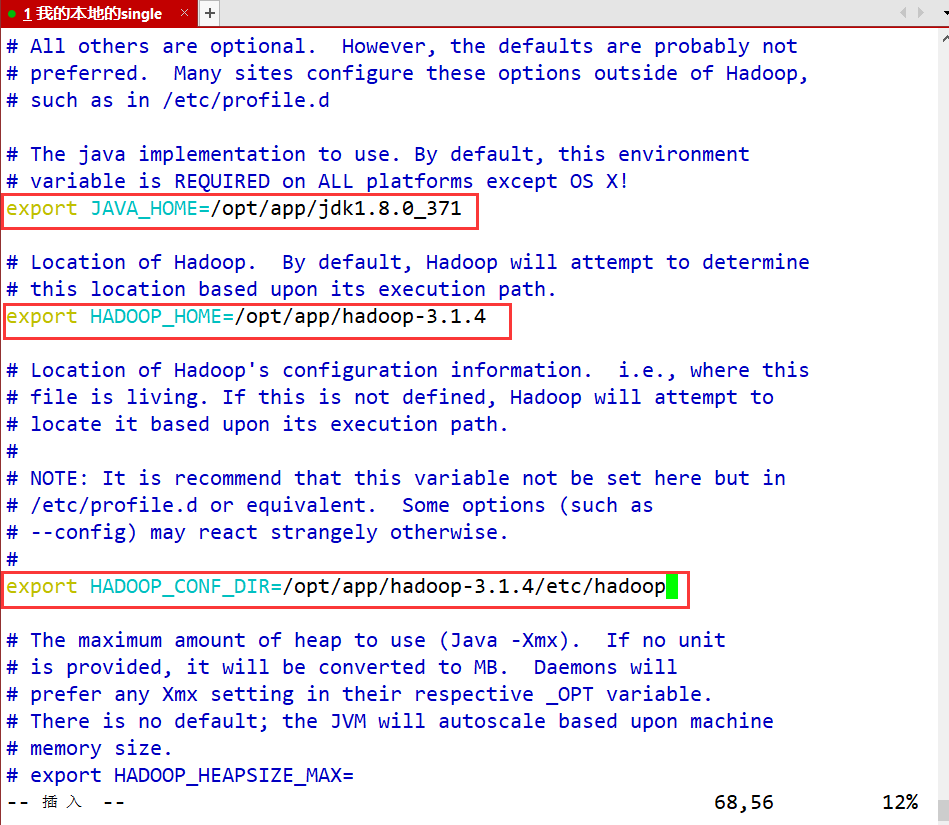
- hadoop-env.sh 配置Java的路径
vim hadoop-env.sh
#第54行
export JAVA_HOME=/opt/app/jdk1.8.0_371
#第58行
export HADOOP_HOME=/opt/app/hadoop-3.1.4
#第68行
export HADOOP_CONF_DIR=/opt/app/hadoop-3.1.4/etc/hadoop
#最后一行
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- core-site.xml 配置HDFS和YARN的一些共同的配置项
- 配置HDFS的NameNode路径
- 配置HDFS集群存储的文件路径
vim core-site.xml
<!--在configuration标签中增加如下配置-->
<configuration><!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://single:9000</value></property><!-- 指定hadoop运行时产生文件的存储目录 HDFS相关文件存放地址--><property><name>hadoop.tmp.dir</name><value>/opt/app/hadoop-3.1.4/metaData</value></property><!-- 整合hive 用户代理设置 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property></configuration>
- hdfs-site.xml 配置HDFS的相关组件
- 配置NameNode的web访问路径、DN的web访问网站,SNN的web访问路径等等
vim hdfs-site.xml
<configuration><!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><!-- hdfs的dn存储的block的备份数--><value>1</value></property><!--hdfs取消用户权限校验--><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>dfs.namenode.http-address</name><value>0.0.0.0:9870</value>
<!-- 50070,9870--> </property><property><name>dfs.datanode.http-address</name><value>0.0.0.0:9864</value>
<!-- 50075,9864--> </property><property><name>dfs.secondary.http-address</name><value>0.0.0.0:9868</value>
<!-- 50090,9868--> </property><!--用于指定NameNode的元数据存储目录--><property><name>dfs.namenode.name.dir</name><value>/opt/app/hadoop-3.1.4/metaData/dfs/name1,/opt/app/hadoop-3.1.4/metaData/dfs/name2</value></property>
</configuration>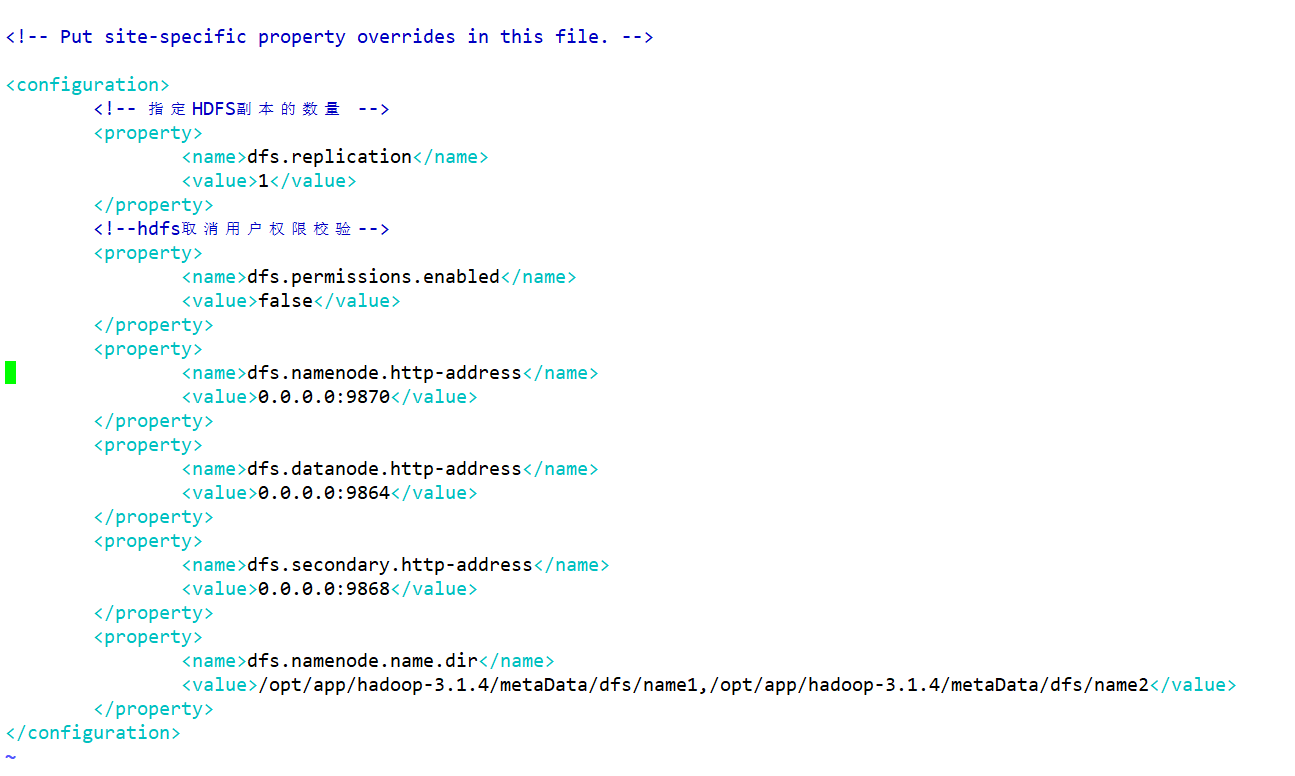
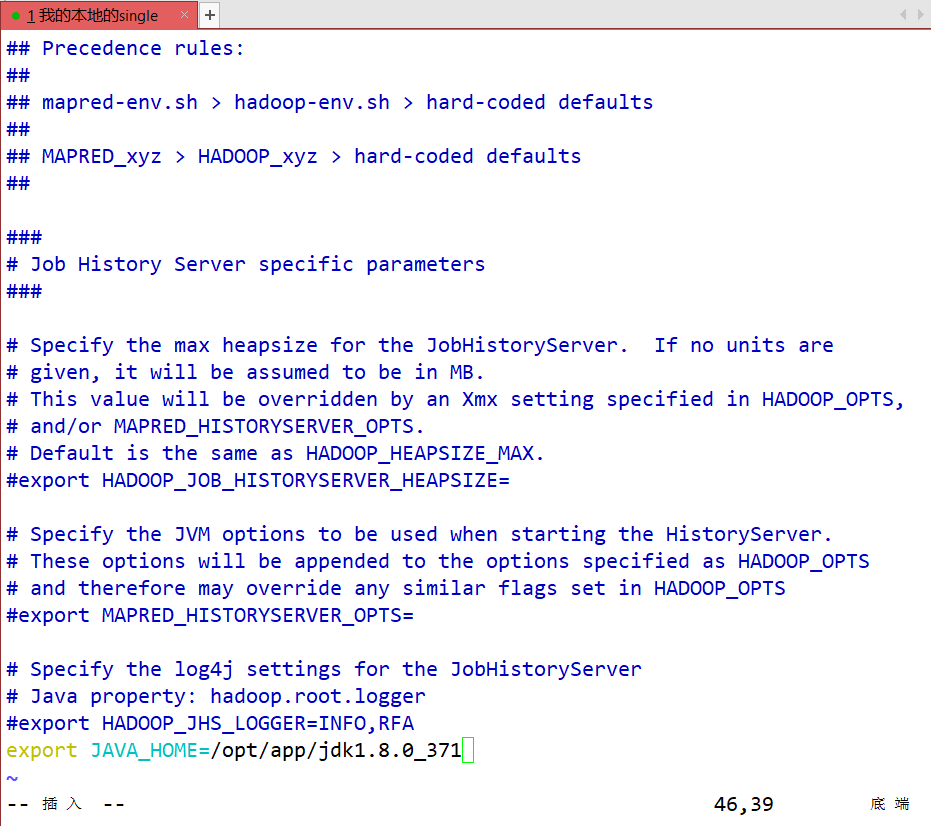
- mapred-env.sh 配置MR程序运行时的关联的软件(Java YARN)路径
vim mapred-env.sh
#最后一行
export JAVA_HOME=/opt/app/jdk1.8.0_371
- mapred-site.xml 配置MR程序运行环境
- 配置将MR程序在YARN上运行
vim mapred-site.xml
<!-- 指定mr运行在yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 指定MR APP Master需要用的环境变量 hadoop3.x版本必须指定--><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- 指定MR 程序 map阶段需要用的环境变量 hadoop3.x版本必须指定--><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- 指定MR程序 reduce阶段需要用的环境变量 hadoop3.x版本必须指定--><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
<property><name>mapreduce.map.memory.mb</name><value>250</value>
</property>
<property><name>mapreduce.map.java.opts</name><value>-Xmx250M</value>
</property>
<property><name>mapreduce.reduce.memory.mb</name><value>300</value>
</property>
<property><name>mapreduce.reduce.java.opts</name><value>-Xmx300M</value>
</property><property><name>mapreduce.jobhistory.address</name><value>single:10020</value>
</property>
<property><name>mapreduce.jobhistory.webapp.address</name><value>single:19888</value>
</property>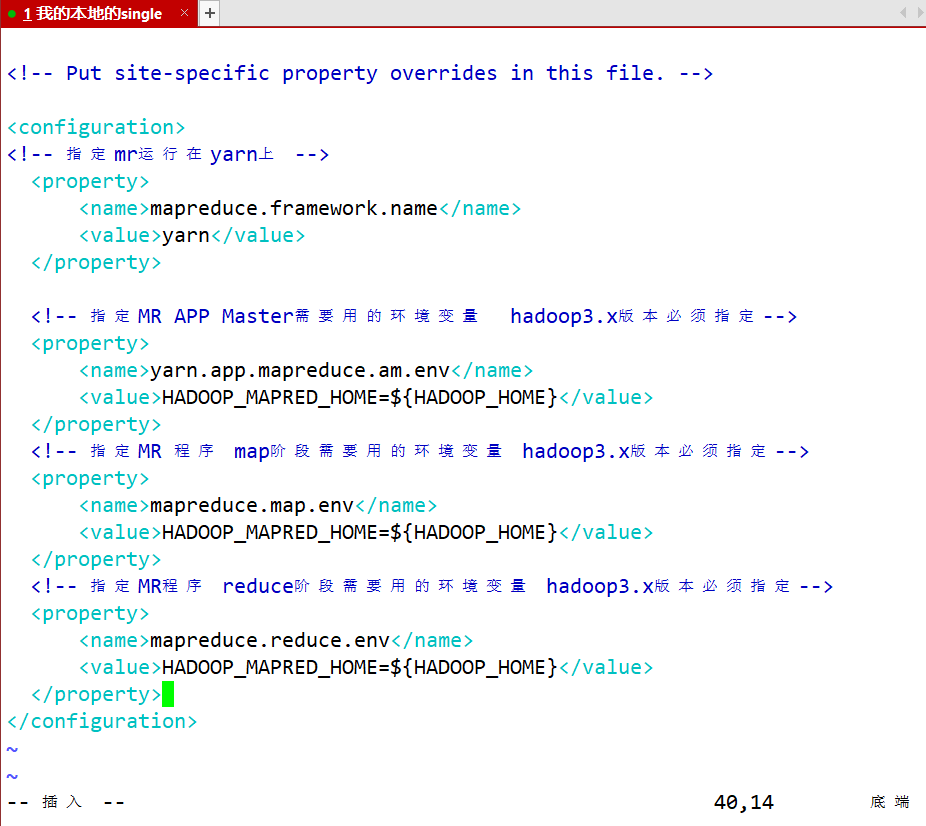

- yarn-env.sh 配置YARN关联的组件路径
vim yarn-env.sh
#最后一行
export JAVA_HOME=/opt/app/jdk1.8.0_371
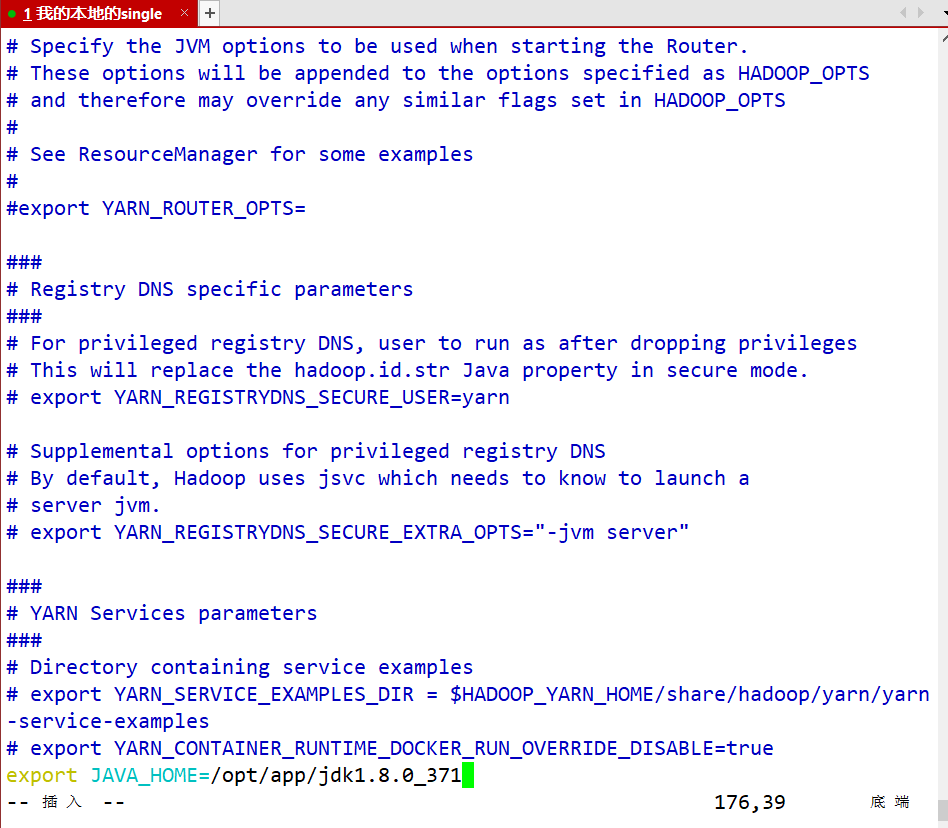
- yarn-site.xml 配置YARN的相关组件
- 配置RM、NM的web访问路径等等
vim yarn-site.xml
<!-- reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><!-- 指定yarn的RM组件安装到哪个主机上--><value>single</value></property><property><name>yarn.application.classpath</name><!-- 指定yarn软件在运行时需要的一些环境路径--><value>/opt/app/hadoop-3.1.4/etc/hadoop,/opt/app/hadoop-3.1.4/share/hadoop/common/*,/opt/app/hadoop-3.1.4/share/hadoop/common/lib/*,/opt/app/hadoop-3.1.4/share/hadoop/hdfs/*,/opt/app/hadoop-3.1.4/share/hadoop/hdfs/lib/*,/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/*,/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/lib/*,/opt/app/hadoop-3.1.4/share/hadoop/yarn/*,/opt/app/hadoop-3.1.4/share/hadoop/yarn/lib/*</value></property>
<!-- yarn.resourcemanager.webapp.address:指的是RM的web访问路径-->
<!-- 日志聚集功能启动 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property><property><name>yarn.log.server.url</name><value>http://single:19888/jobhistory/logs</value>
</property>
<!--关闭yarn对虚拟内存的限制检查 -->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>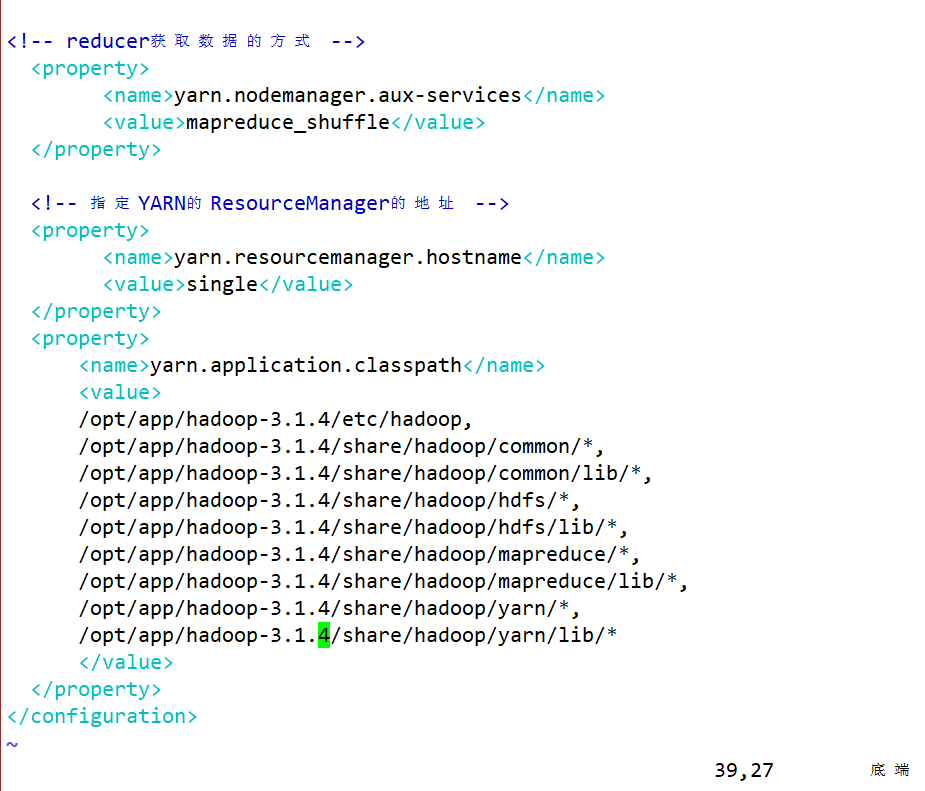
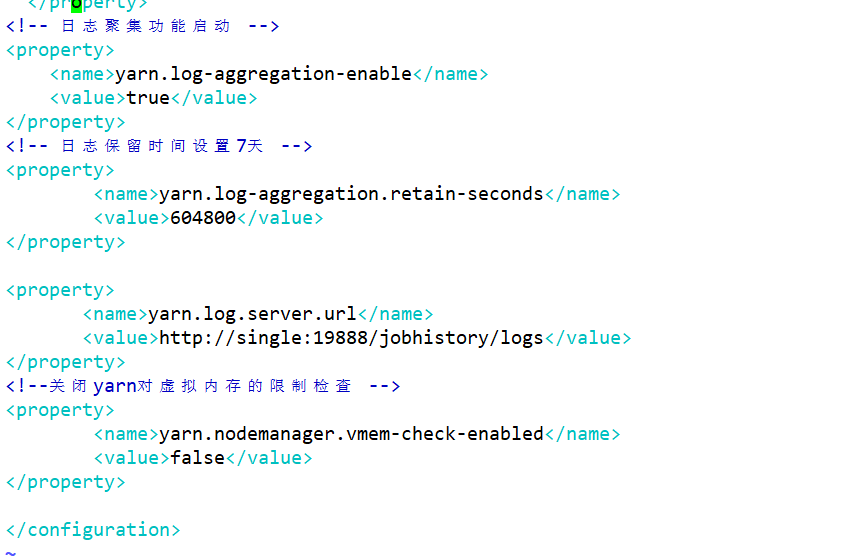
- workers/slaves 配置HDFS和YARN的从节点的主机
- 配置DN和NM在哪些节点上需要安装
vim workers
<!-- 将localhost改为single -->
single
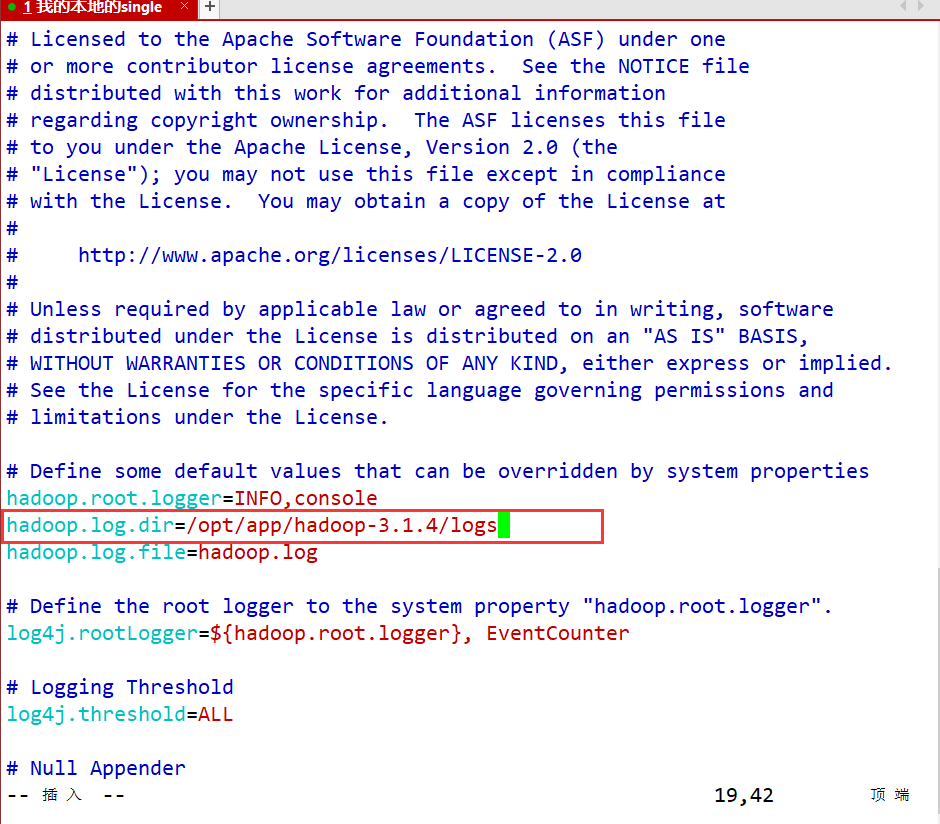
- log4j.properties —— 配置Hadoop运行过程中日志输出目录
vim log4j.properties
#第19行
hadoop.log.dir=/opt/app/hadoop-3.1.4/logs
#指定Hadoop运行过程中日志输出目录
六、格式化HDFS集群
hdfs namenode -format
七、启动HDFS和YARN
-
HDFS
- start-dfs.sh
报错
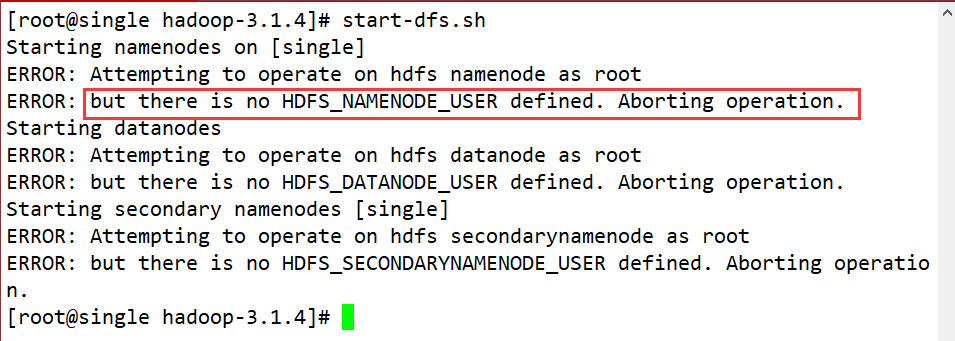
解决方案:
vim /etc/profile #在最后一行加入以下内容 # HADOOP 3.X版本还需要增加如下配置 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root #然后使配置文件生效 source /etc/profile
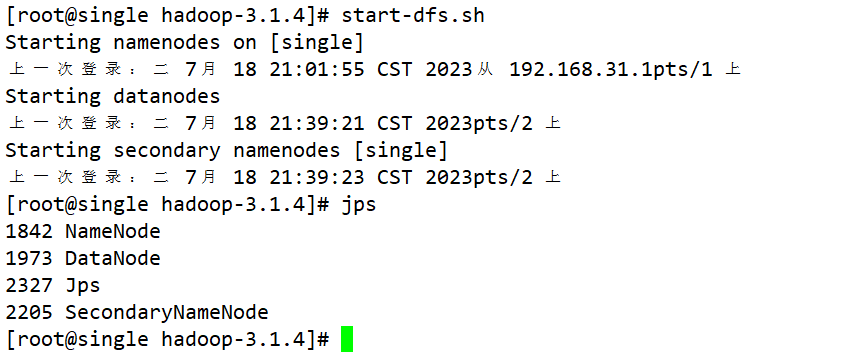
- stop-dfs.sh
- 提供了一个web访问网站,可以监控整个HDFS集群的状态信息
http://ip:9870 hadoop3.x
ip:50070 hadoop2.x
-
yarn
- start-yarn.sh
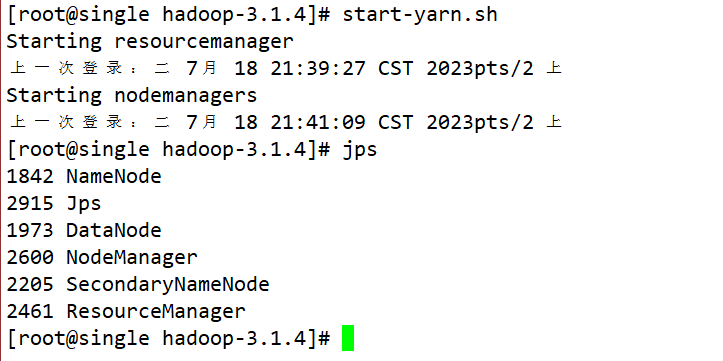
- stop-yarn.sh
- 提供了一个web网站,可以监控整个YARN集群的状态:
http://ip:8088
八、Hadoop的完全分布式安装
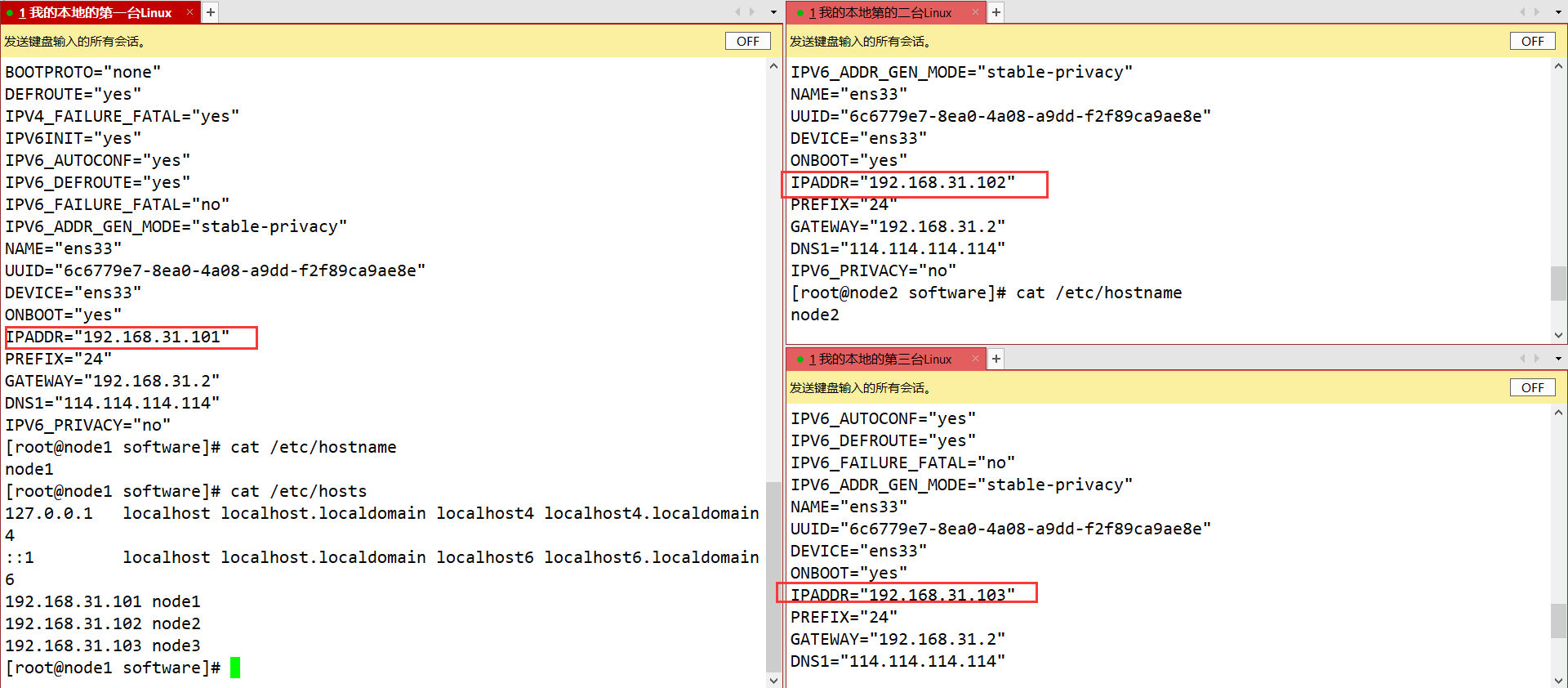
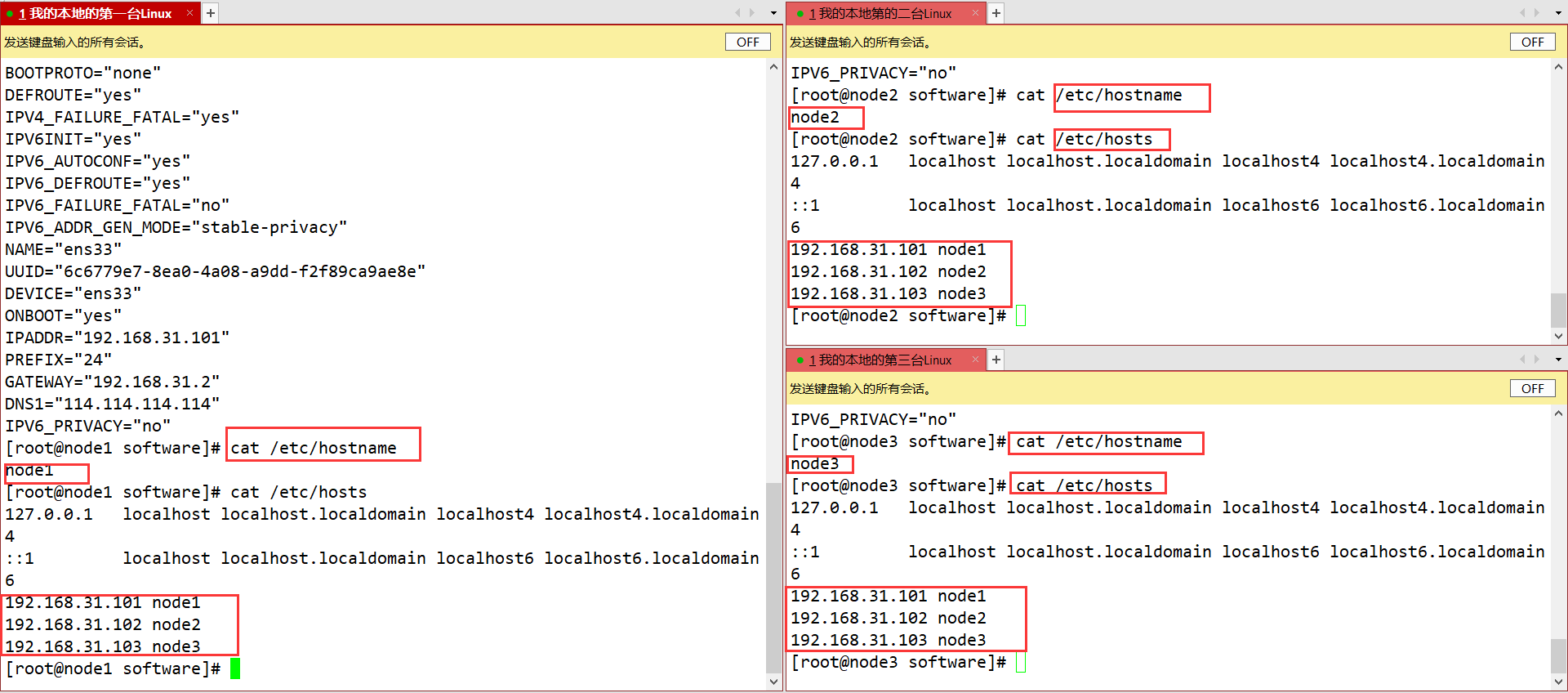
1、克隆虚拟机
三台虚拟机需要配置IP、主机名、主机IP映射、ssh免密登录、时间服务器的安装同步、yum数据仓库更换为国内镜像源
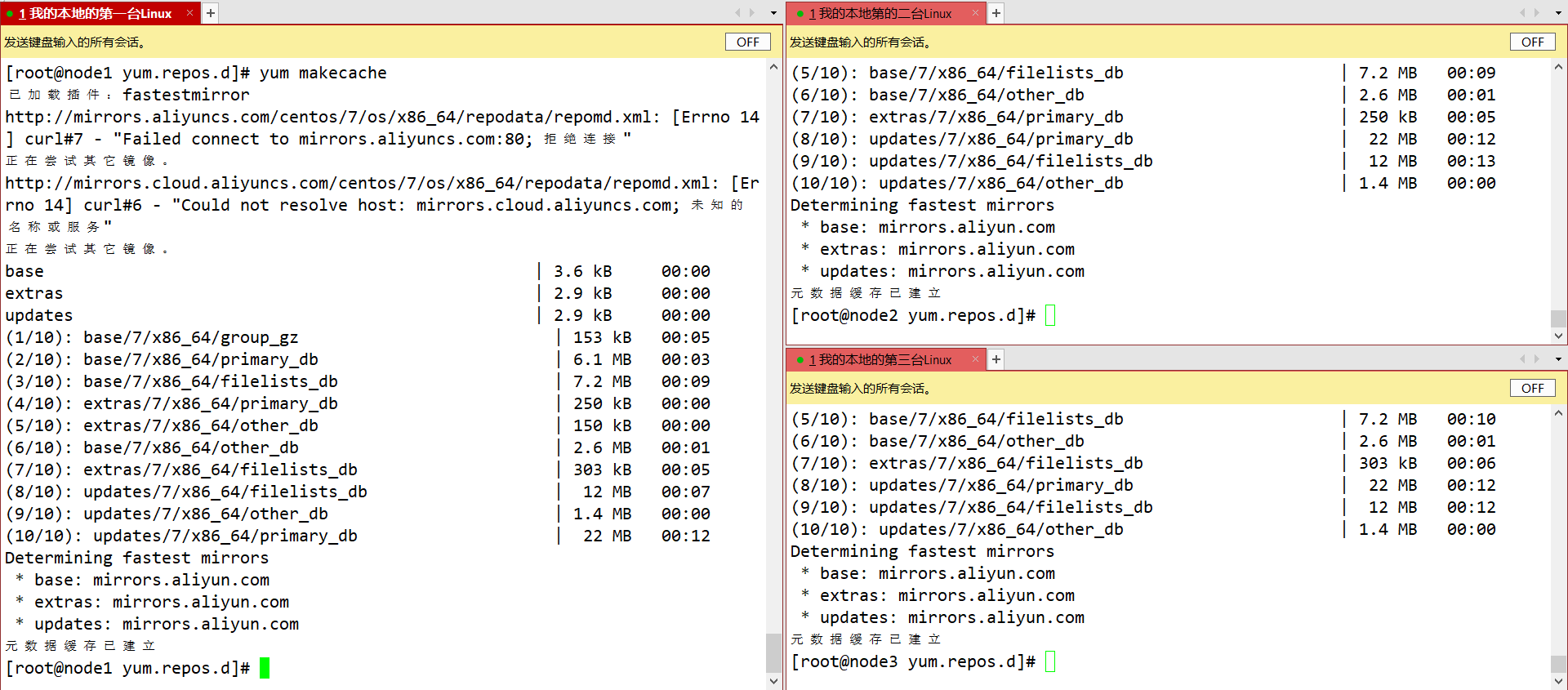
时间服务器chrony的安装同步
yum install -y chrony
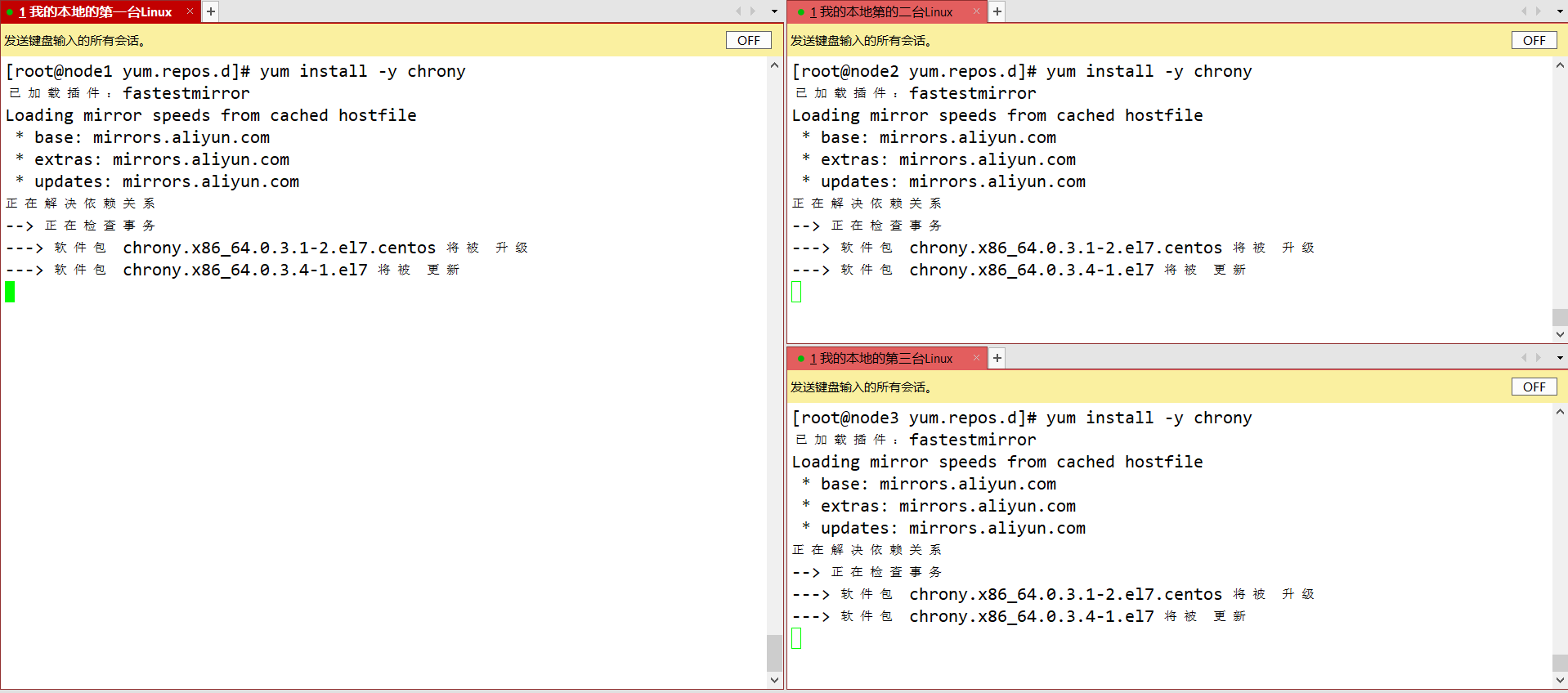
先配置主服务器
vim /etc/chrony.conf
在第7行添加allow 192.168.31.0/24
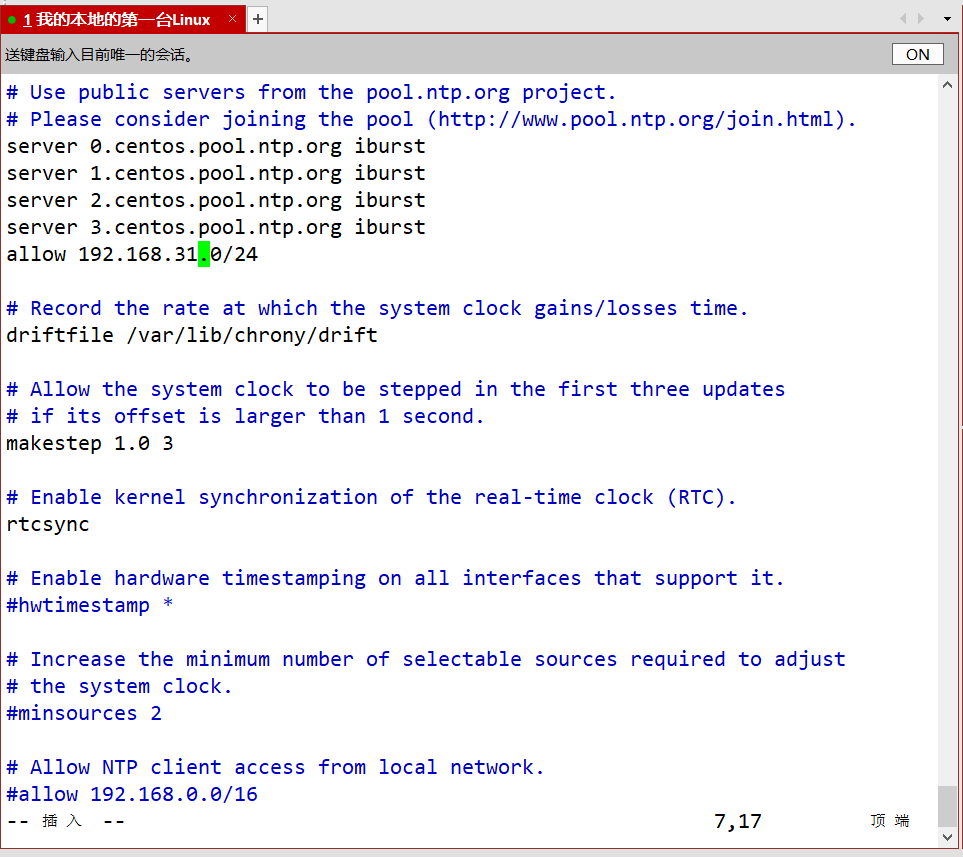
再配置两台从服务器
vim /etc/chrony.conf
就将3 - 6行的server删除后,添加一行server node1 iburst
开启服务
2、安装JDK
此处省略,如需请查看之前博客
3、安装Hadoop完全分布式
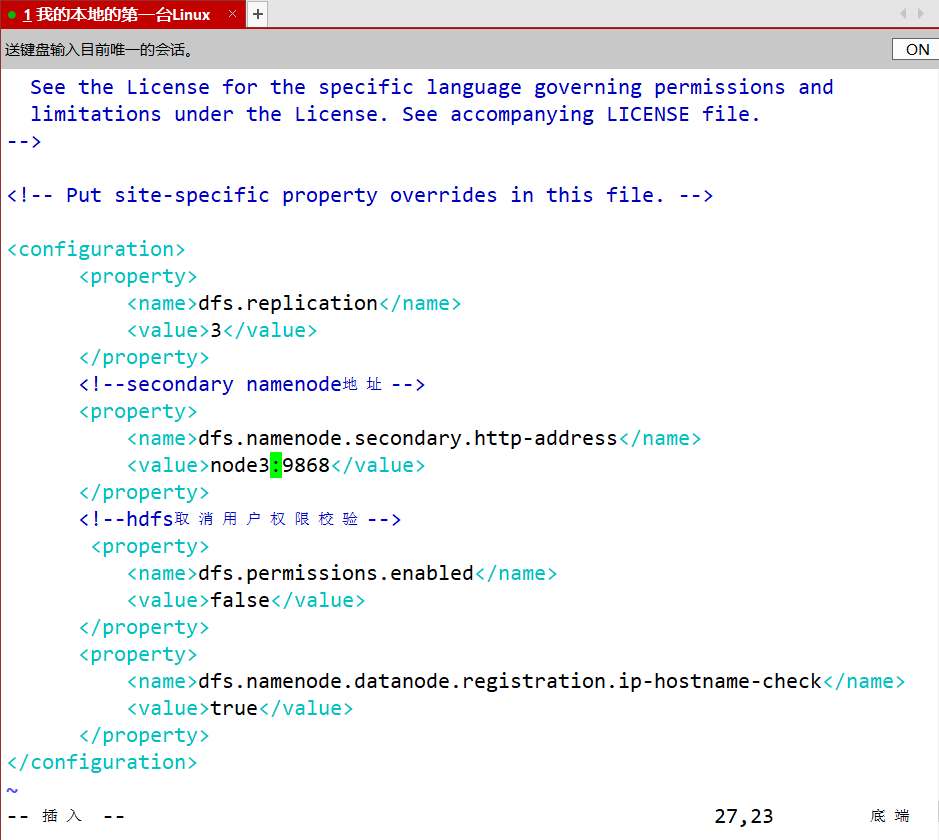
- hdfs.site.xml
<configuration><property><name>dfs.replication</name><value>3</value></property><!--secondary namenode地址--><property><name>dfs.namenode.secondary.http-address</name><value>node3:9868</value></property><!--hdfs取消用户权限校验--><property><name>dfs.permissions.enabled</name><value>false</value> </property><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>true</value></property>
</configuration>
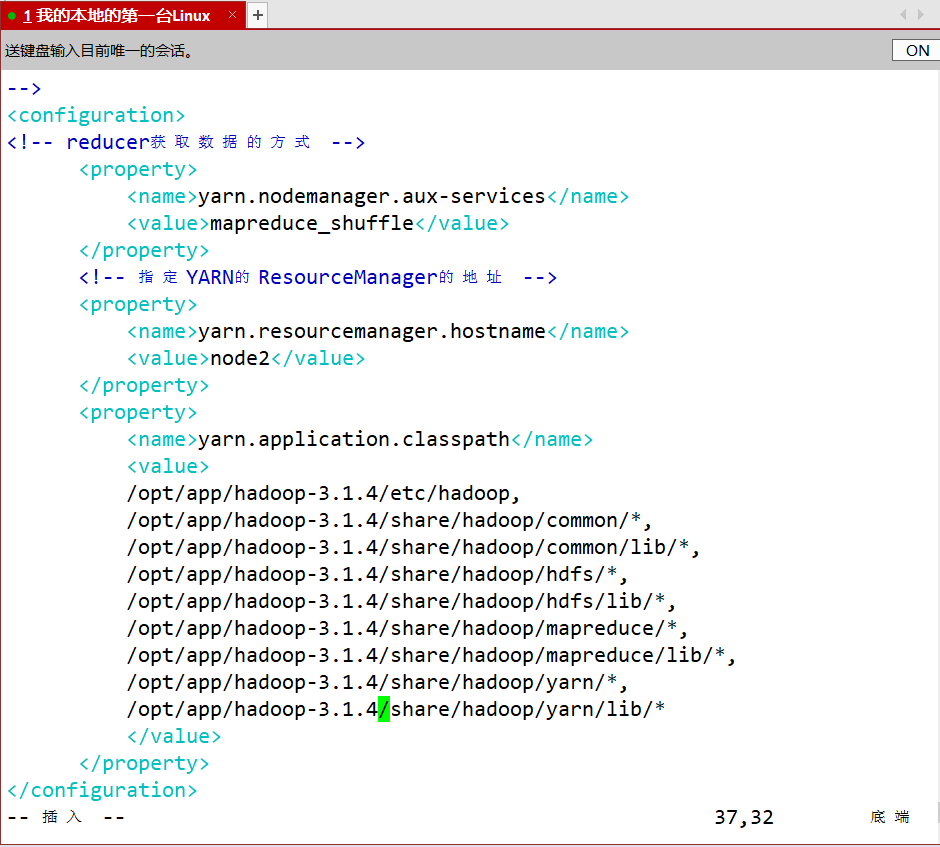
- yarn.site.xml
<configuration>
<!-- reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>node2</value></property><property><name>yarn.application.classpath</name><value>/opt/app/hadoop-3.1.4/etc/hadoop,/opt/app/hadoop-3.1.4/share/hadoop/common/*,/opt/app/hadoop-3.1.4/share/hadoop/common/lib/*,/opt/app/hadoop-3.1.4/share/hadoop/hdfs/*,/opt/app/hadoop-3.1.4/share/hadoop/hdfs/lib/*,/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/*,/opt/app/hadoop-3.1.4/share/hadoop/mapreduce/lib/*,/opt/app/hadoop-3.1.4/share/hadoop/yarn/*,/opt/app/hadoop-3.1.4/share/hadoop/yarn/lib/*</value></property>
</configuration>
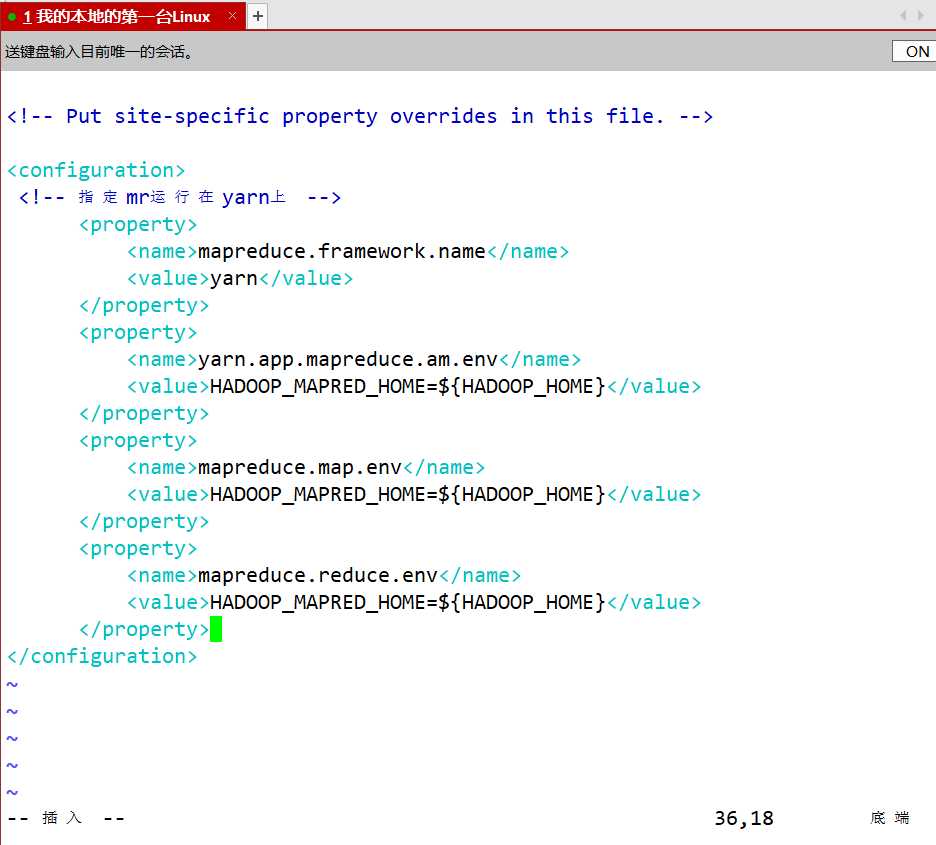
- mapred-site.xml
<!-- 指定mr运行在yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
共需配置九个相关文件
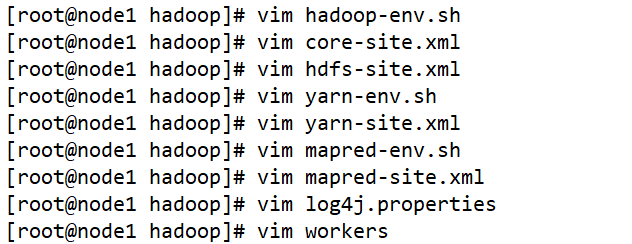
然后将node1上的/opt/app发送到node2和node3节点上的/opt上
scp -r /opt/app root@node2:/opt
4、格式化HDFS
namenode所在节点格式化
hdfs namenode -format
5、启动HDFS和YARN
1、 HDFS是在namenode所在节点启动(node1)
2、YARN是在RM所在节点启动(node2)
相关文章:
Hadoop的概述与安装
Hadoop的概述与安装 一、Hadoop内部的三个核心组件1、HDFS:分布式文件存储系统2、YARN:分布式资源调度系统3、MapReduce:分布式离线计算框架4、Hadoop Common(了解即可) 二、Hadoop技术诞生的一个生态圈数据采集存储数…...
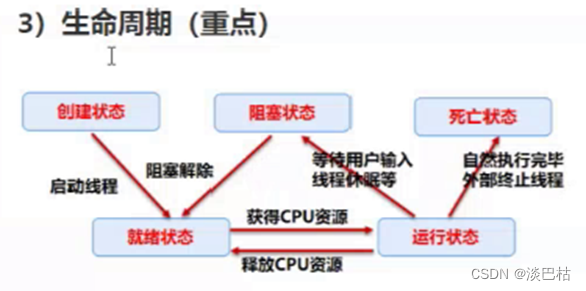
进程、线程与构造方法
进程、线程与构造方法 目录 一. 进程与线程1. 通俗解释2. 代码实现3. 线程生命周期(图解) 二. 构造方法 一. 进程与线程 1. 通俗解释 进程:就像电脑上运行的软件,例如QQ等。 线程:…...
04 Linux补充|C/C++
目录 Linux补充 C语⾔ C语言中puts和printf的区别? Linux补充 (1)ubuntu安装ssh服务端openssh-server命令: ubuntu安装后默认只有ssh客户端,只能去连其它ssh服务器;其它客户端想要连接这个ubuntu系统,需要安装部署…...
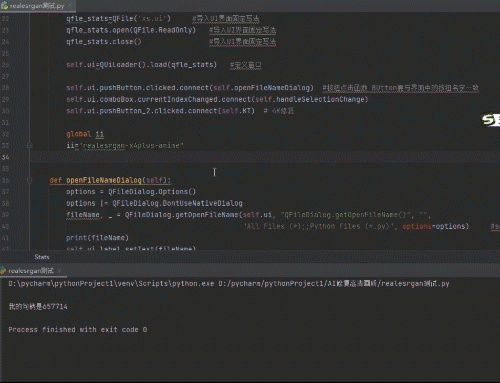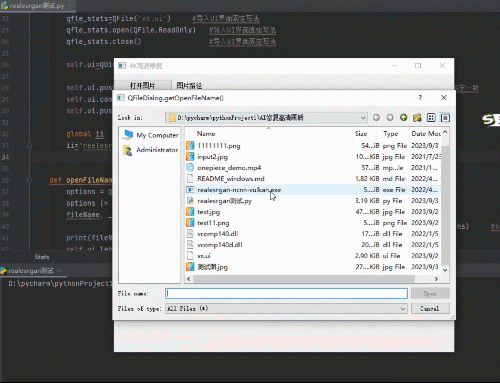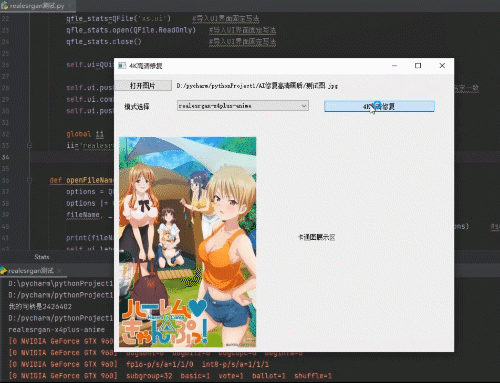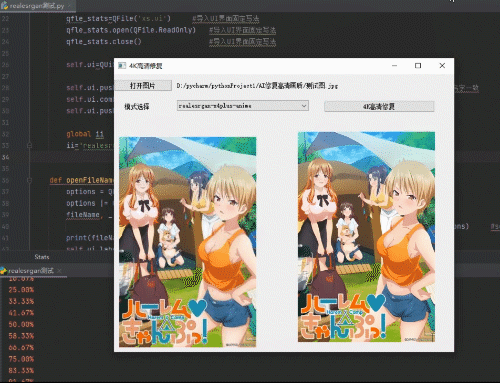
利用python制作AI图片优化工具
将模糊图片4K高清化效果如下: 优化前的图片 优化后如下图: 优化后图片变大变清晰了效果很明显 软件界面如下: 所用工具和代码: 1、所需软件包 网盘链接:https://pan.baidu.com/s/1CMvn4Y7edDTR4COfu4FviA提取码&…...

React v6(仅支持函数组件,不支持类组件)与v5版本路由使用详情和区别(详细版)
1.路由安装(默认安装最新版本6.15.0) npm i react-router-dom 2.路由模式 有常用两种路由模式可选:HashRouter 和 BrowserRouter。 ①HashRouter:URL中采用的是hash(#)部分去创建路由。 ②BrowserRouter:URL采用真实的URL资源,…...
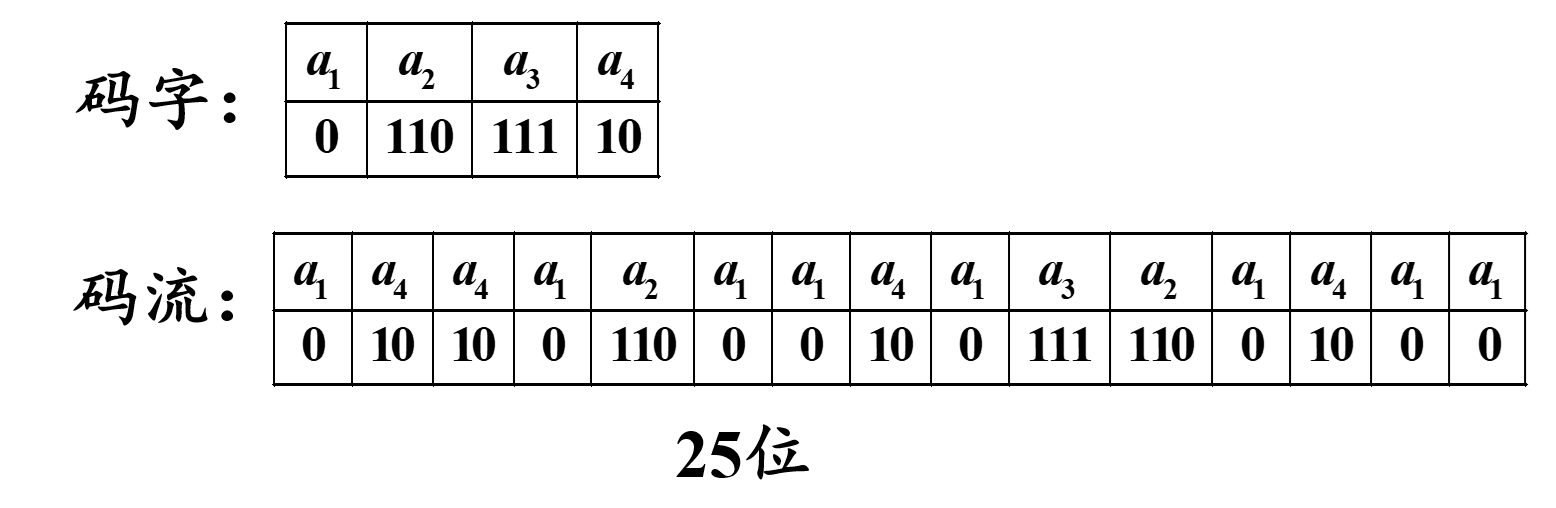
(数字图像处理MATLAB+Python)第十二章图像编码-第一、二节:图像编码基本理论和无损编码
文章目录 一:图像编码基本理论(1)图像压缩的必要性(2)图像压缩的可能性A:编码冗余B:像素间冗余C:心理视觉冗余 (3)图像压缩方法分类A:基于编码前后…...

【Unity编辑器扩展】| 顶部菜单栏扩展 MenuItem
前言【Unity编辑器扩展】 | 顶部菜单栏扩展 MenuItem一、创建多级菜单二、创建可使用快捷键的菜单项三、调节菜单显示顺序和可选择性四、创建可被勾选的菜单项五、右键菜单扩展5.1 Hierarchy 右键菜单5.2 Project 右键菜单5.3 Inspector 组件右键菜单六、AddComponentMenu 特性…...

golang读取键盘功能按键输入
golang读取键盘功能按键输入 需求 最近业务上需要做一个终端工具,能够直接连到docker容器中进行交互。 技术选型 docker官方提供了python sdk、go sdk和remote api。 https://docs.docker.com/engine/api/sdk/ 因为我们需要提供命令行工具,因此采用g…...

用sklearn实现线性回归和岭回归
此文为ai创作,今天写文章的时候发现创作助手限时免费,想测试一下,于是就有了这篇文章,看的出来,效果还可以,一行没改。 线性回归 在sklearn中,可以使用线性回归模型做多变量回归。下面是一个示…...

结构型模式-桥接模式
用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。 这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类…...

缓存的放置时间和删除时间
缓存的放置时间和删除时间是指缓存中存储的数据的生命周期。这两个时间点非常重要,因为它们决定了缓存数据的有效期和何时应该从缓存中删除。 缓存的放置时间(Cache Put Time):这是指数据首次放入缓存的时间点。当数据被放入缓存时…...
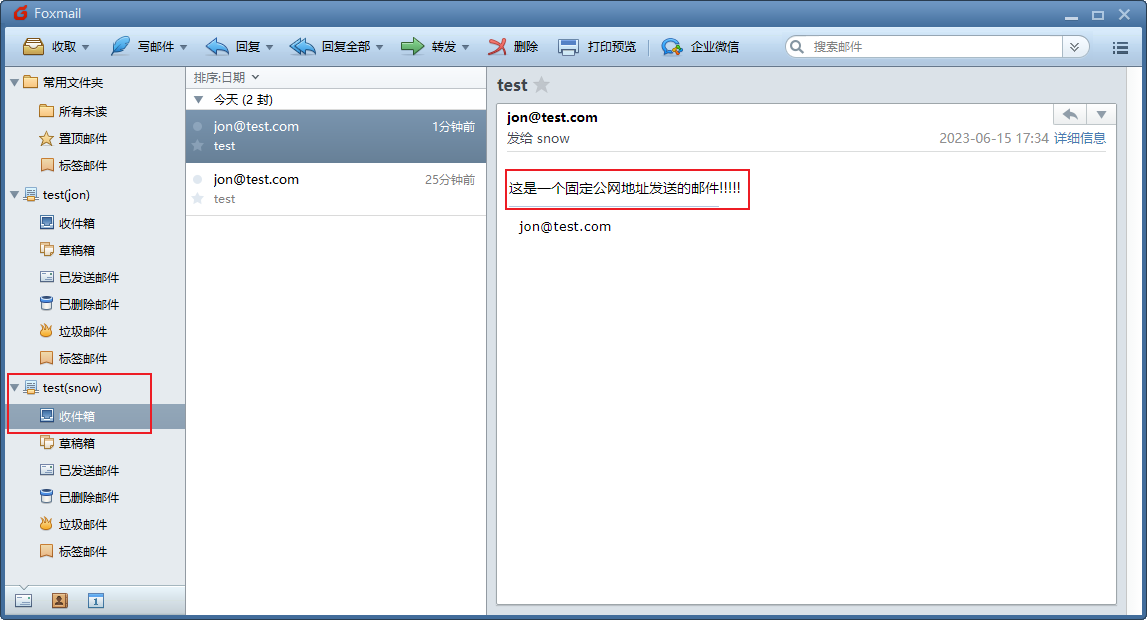
内网穿透实战应用-如何通过内网穿透实现远程发送个人本地搭建的hMailServer的邮件服务
文章目录 1. 安装hMailServer2. 设置hMailServer3. 客户端安装添加账号4. 测试发送邮件5. 安装cpolar6. 创建公网地址7. 测试远程发送邮件8. 固定连接公网地址9. 测试固定远程地址发送邮件 hMailServer 是一个邮件服务器,通过它我们可以搭建自己的邮件服务,通过cpolar内网映射工…...
)
ensp基础命令大全(华为设备命令)
路漫漫其修远兮,吾将上下而求索 今天写一些曾经学习过的网络笔记,希望对您的学习有所帮助。 OSPF,BGP,IS-IS的命令笔记没有写上来,计划单独写,敬请期待,或者您可以在这个网站查查 : 万能查询网站 …...

thinkphp6 入门(4)--数据库操作 增删改查
一、设计数据库表 比如我新建了一个数据库表,名为test 二、配置数据库连接信息 本地测试 直接在.env中修改,不用去config/database.php中修改 正式环境 三、增删改查 引入Db库 use think\facade\Db; 假设新增的控制器路径为 app\test\control…...
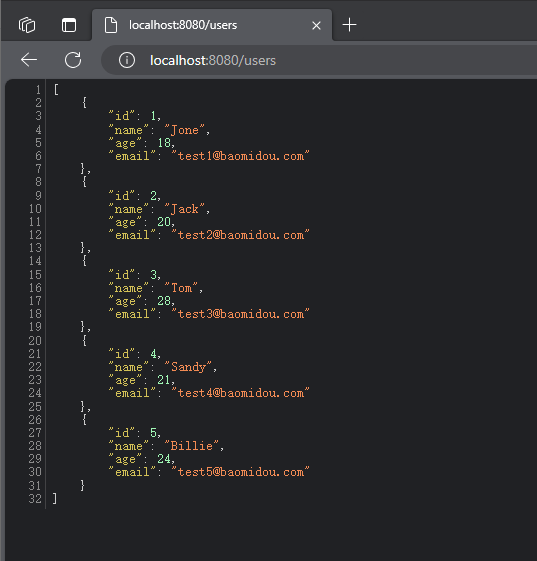
MyBatisPlus 基础实现(一)
说明 创建一个最基本的MyBatisPlus项目,参考官网。 依赖 MyBatisPlus 依赖,最新版是:3.5.3.2 (截止2023-9-4)。 <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-bo…...
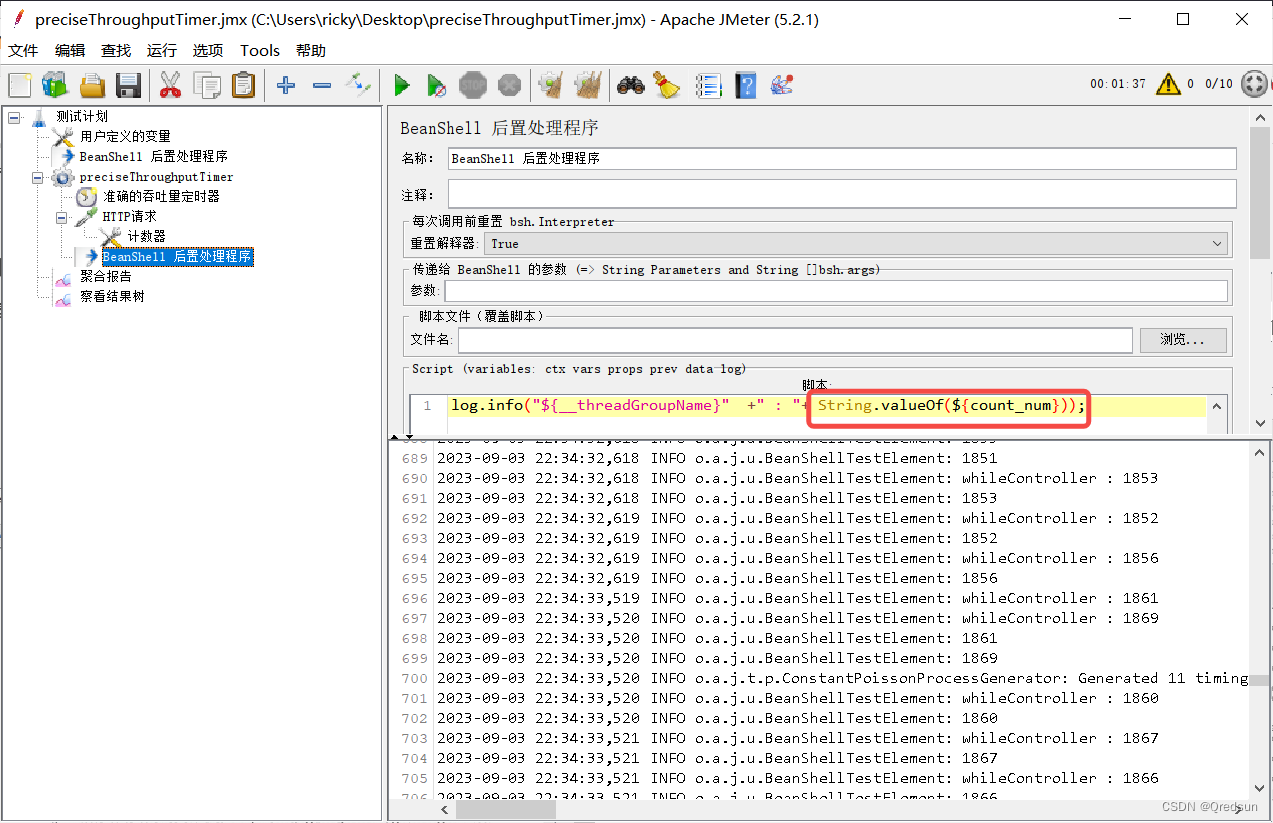
jmeter 计数器Counter
计数器可以用于生成动态的数值或字符串,以模拟不同的用户或数据。 计数器通常与用户线程组结合使用,以生成不同的变量值并在测试中应用。以下是计数器的几个常用属性: 变量前缀(Variable Name Prefix):定义…...
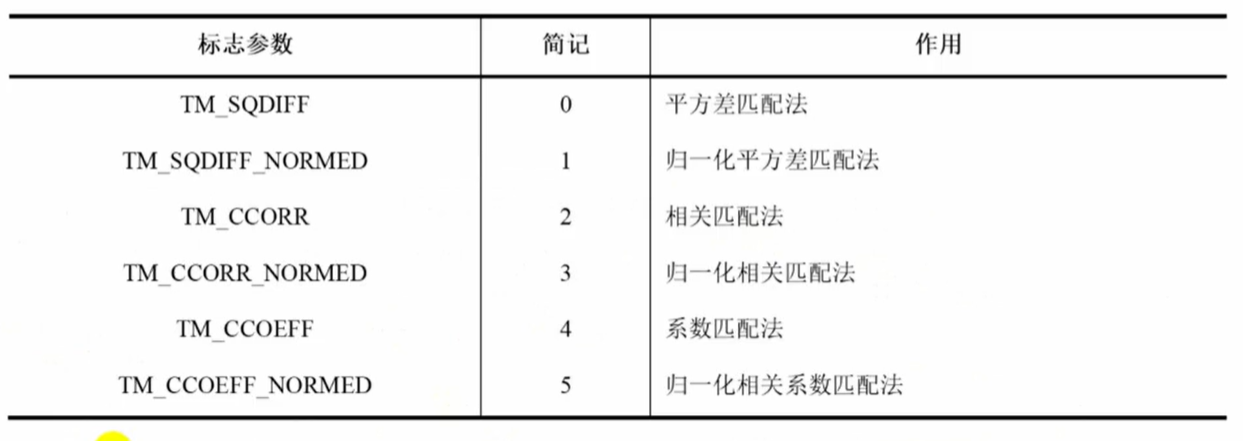
OpenCV(十九):模板匹配
1.模板匹配: OpenCV提供了一个模板匹配函数,用于在图像中寻找给定模板的匹配位置。 2.图像模板匹配函数matchTemplate void matchTemplate( InputArray image, InputArray templ, OutputArray result, int method, InputArray mask noArray() ); image…...
【iOS】Category、Extension和关联对象
Category分类 Category 是 比继承更为简洁 的方法来对Class进行扩展,无需创建子类就可以为现有的类动态添加方法。 可以给项目内任何已经存在的类 添加 Category甚至可以是系统库/闭源库等只暴露了声明文件的类 添加 Category (看不到.m 文件的类)通过 Category 可以添加 实例…...
)
支持向量机(一)
文章目录 前言分析数据集线性可分情况下的支持向量机原始问题凸优化包解法对偶问题凸优化包解法 数据集线性不可分情况下的线性支持向量机与软间隔最大化 前言 在支持向量机中,理论逻辑很简单:最大化最小的几何间隔。但是实际编写代码过程中有一个小点需…...

MyBatis中至关重要的关系映射----全方面介绍
目录 一 对于映射的概念 1.1 三种关系映射 1.2 resultType与resultMap的区别 resultType: resultMap: 二,一对一关联查询 2.1 嵌套结果集编写 2.2 案例演示 三,一对多关联查询 3.1 嵌套结果集编写 3.3 案例演示 四&…...

突破ThinkPad散热限制:TPFanCtrl2智能风扇控制完全指南
突破ThinkPad散热限制:TPFanCtrl2智能风扇控制完全指南 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 ThinkPad笔记本以其稳定性和性能在专业用户中享有盛…...

终极实战指南:Godot PCK解包器深度解析与高效资源提取
终极实战指南:Godot PCK解包器深度解析与高效资源提取 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 在游戏开发与逆向工程领域,Godot引擎的PCK文件格式一直是技术爱好者关注…...

STM32F103ZET6【HAL库实战】STM32CubeMX配置高级定时器实现三相电机驱动PWM
1. 为什么需要带死区的互补PWM 在驱动三相无刷电机时,最头疼的问题就是上下桥臂直通。想象一下,如果同一个桥臂的上下两个MOS管同时导通,电源正负极就直接短路了,轻则烧MOS管,重则整个电路板冒烟。我当年第一次调电机驱…...

如何使用unbuild在5分钟内搭建现代化JavaScript项目:终极快速指南
如何使用unbuild在5分钟内搭建现代化JavaScript项目:终极快速指南 【免费下载链接】unbuild 📦 A unified JavaScript build system 项目地址: https://gitcode.com/gh_mirrors/un/unbuild 在当今快速发展的JavaScript生态系统中,构建…...

《YOLOv11 实战:从入门到深度优化》002、环境搭建:从零配置YOLOv11开发与训练环境
002、环境搭建:从零配置YOLOv11开发与训练环境 昨天深夜调试一个边缘设备上的推理异常,问题最终定位到CUDA版本和torch不匹配——这种环境配置埋下的坑,往往比算法本身更难排查。今天咱们就老老实实把YOLOv11的环境从头搭一遍,这份…...
》——从“像素认知”到“空间计算”,构建现实世界的智能操作体系)
《SpaceOS:空间操作系统白皮书(终极封神版)》——从“像素认知”到“空间计算”,构建现实世界的智能操作体系
🚀《SpaceOS:空间操作系统白皮书(终极封神版)》——从“像素认知”到“空间计算”,构建现实世界的智能操作体系(镜像视界(浙江)科技有限公司原创技术体系)🔴 …...

开源激活利器:KMS_VL_ALL_AIO全场景应用指南
开源激活利器:KMS_VL_ALL_AIO全场景应用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 问题:激活困境与技术痛点 个人用户的激活难题 当Windows系统突然弹出激活提…...

3个步骤实现Windows直接运行安卓应用:开发者与玩家的跨平台解决方案
3个步骤实现Windows直接运行安卓应用:开发者与玩家的跨平台解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为手机应用无法在电脑上运行而困扰…...

如何实现真实感前端游戏碰撞响应:从弹性到摩擦的完整指南
如何实现真实感前端游戏碰撞响应:从弹性到摩擦的完整指南 【免费下载链接】frontend-stuff 📝 A continuously expanded list of frameworks, libraries and tools I used/want to use for building things on the web. Mostly JavaScript. 项目地址: …...

新手入门:在快马上手第一个web项目,用图表解读技术职级薪资数据
新手入门:在快马上手第一个web项目,用图表解读技术职级薪资数据 最近想学习前端开发,但一直找不到合适的入门项目。直到看到阿里P10薪资这个话题,突然觉得可以做个简单的数据可视化页面来练手。作为一个完全的新手,我…...