计算机毕设 大数据商城人流数据分析与可视化 - python 大数据分析
文章目录
- 0 前言
- 课题背景
- 分析方法与过程
- 初步分析:
- 总体流程:
- 1.数据探索分析
- 2.数据预处理
- 3.构建模型
- 总结
- 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的基站数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
课题背景
- 随着当今个人手机终端的普及,出行群体中手机拥有率和使用率已达到相当高的比例,手机移动网络也基本实现了城乡空间区域的全覆盖。根据手机信号在真实地理空间上的覆盖情况,将手机用户时间序列的手机定位数据,映射至现实的地理空间位置,即可完整、客观地还原出手机用户的现实活动轨迹,从而挖掘得到人口空间分布与活动联系特征信息。移动通信网络的信号覆盖从逻辑上被设计成由若干六边形的基站小区相互邻接而构成的蜂窝网络面状服务区,手机终端总是与其中某一个基站小区保持联系,移动通信网络的控制中心会定期或不定期地主动或被动地记录每个手机终端时间序列的基站小区编号信息。
- 商圈是现代市场中企业市场活动的空间,最初是站在商品和服务提供者的产地角度提出,后来逐渐扩展到商圈同时也是商品和服务享用者的区域。商圈划分的目的之一是为了研究潜在的顾客的分布以制定适宜的商业对策。
分析方法与过程
初步分析:
- 手机用户在使用短信业务、通话业务、开关机、正常位置更新、周期位置更新和切入呼叫的时候均产生定位数据,定位数据记录手机用户所处基站的编号、时间和唯一标识用户的EMASI号等。历史定位数据描绘了用户的活动模式,一个基站覆盖的区域可等价于商圈,通过归纳经过基站覆盖范围的人口特征,识别出不同类别的基站范围,即可等同地识别出不同类别的商圈。衡量区域的人口特征可从人流量和人均停留时间的角度进行分析,所以在归纳基站特征时可针对这两个特点进行提取。
总体流程:
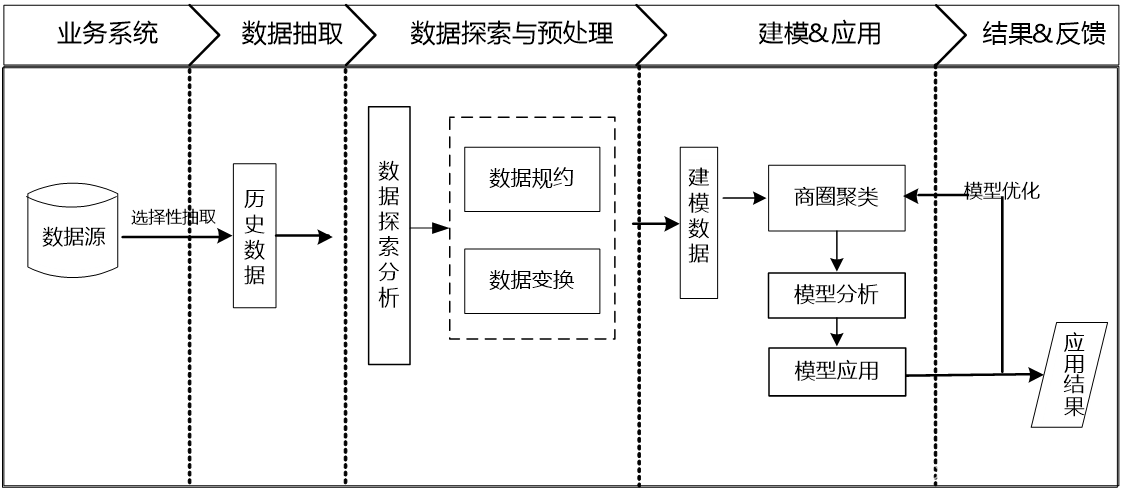
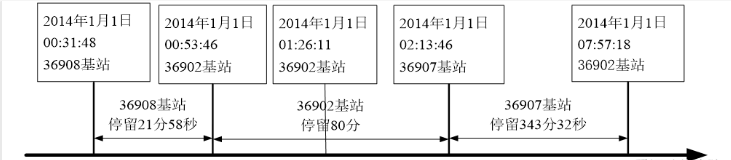
1.数据探索分析
EMASI号为55555的用户在2014年1月1日的定位数据

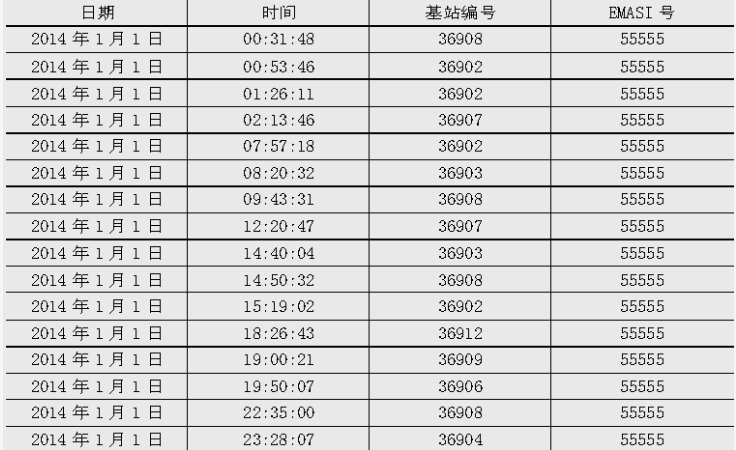
2.数据预处理
数据规约
- 网络类型、LOC编号和信令类型这三个属性对于挖掘目标没有用处,故剔除这三个冗余的属性。而衡量用户的停留时间并不需要精确到毫秒级,故可把毫秒这一属性删除。
- 把年、月和日合并记为日期,时、分和秒合并记为时间。
import numpy as npimport pandas as pddata=pd.read_excel('C://Python//DataAndCode//chapter14//demo//data//business_circle.xls')# print(data.head())#删除三个冗余属性del data[['网络类型','LOC编号','信令类型']]#合并年月日periods=pd.PeriodIndex(year=data['年'],month=data['月'],day=data['日'],freq='D')data['日期']=periodstime=pd.PeriodIndex(hour=data['时'],minutes=data['分'],seconds=data['秒'],freq='D')data['时间']=timedata['日期']=pd.to_datetime(data['日期'],format='%Y/%m/%d')data['时间']=pd.to_datetime(data['时间'],format='%H/%M/%S')
数据变换
假设原始数据所有用户在观测窗口期间L( 天)曾经经过的基站有 N个,用户有 M个,用户 i在 j天在 num1 基站的工作日上班时间停留时间为
weekday_num1,在 num1 基站的凌晨停留时间为night_num1 ,在num1基站的周末停留时间为weekend_num1, 在
num1基站是否停留为 stay_num1 ,设计基站覆盖范围区域的人流特征:
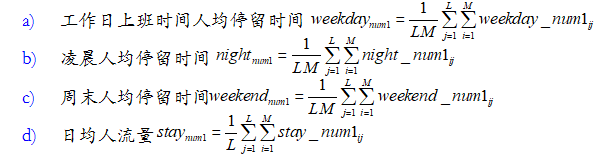

由于各个属性的之间的差异较大,为了消除数量级数据带来的影响,在进行聚类前,需要进行离差标准化处理。
#-*- coding: utf-8 -*-#数据标准化到[0,1]import pandas as pd#参数初始化filename = '../data/business_circle.xls' #原始数据文件standardizedfile = '../tmp/standardized.xls' #标准化后数据保存路径data = pd.read_excel(filename, index_col = u'基站编号') #读取数据data = (data - data.min())/(data.max() - data.min()) #离差标准化data = data.reset_index()data.to_excel(standardizedfile, index = False) #保存结果
3.构建模型
构建商圈聚类模型
采用层次聚类算法对建模数据进行基于基站数据的商圈聚类,画出谱系聚类图。从图可见,可把聚类类别数取3类。
#-*- coding: utf-8 -*-#谱系聚类图import pandas as pd#参数初始化standardizedfile = '../data/standardized.xls' #标准化后的数据文件data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据import matplotlib.pyplot as pltfrom scipy.cluster.hierarchy import linkage,dendrogram#这里使用scipy的层次聚类函数Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图P = dendrogram(Z, 0) #画谱系聚类图plt.show()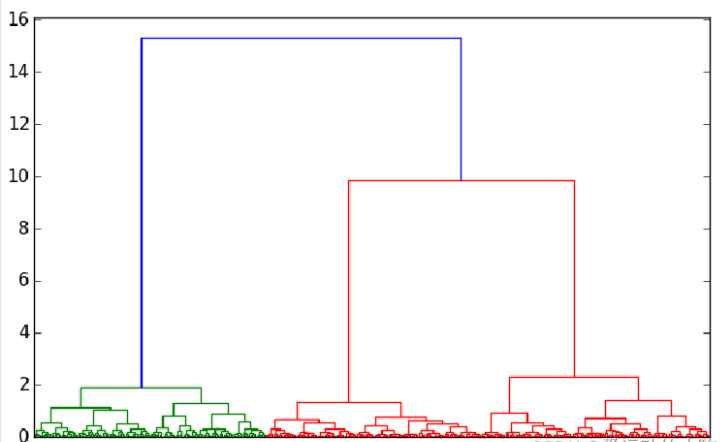
模型分析
针对聚类结果按不同类别画出4个特征的折线图。
#-*- coding: utf-8 -*-#层次聚类算法import pandas as pd#参数初始化standardizedfile = '../data/standardized.xls' #标准化后的数据文件k = 3 #聚类数data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')model.fit(data) #训练模型#详细输出原始数据及其类别r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别r.columns = list(data.columns) + [u'聚类类别'] #重命名表头import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号style = ['ro-', 'go-', 'bo-']xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']pic_output = '../tmp/type_' #聚类图文件名前缀for i in range(k): #逐一作图,作出不同样式plt.figure()tmp = r[r[u'聚类类别'] == i].iloc[:,:4] #提取每一类for j in range(len(tmp)):plt.plot(range(1, 5), tmp.iloc[j], style[i])plt.xticks(range(1, 5), xlabels, rotation = 20) #坐标标签plt.title(u'商圈类别%s' %(i+1)) #我们计数习惯从1开始plt.subplots_adjust(bottom=0.15) #调整底部plt.savefig(u'%s%s.png' %(pic_output, i+1)) #保存图片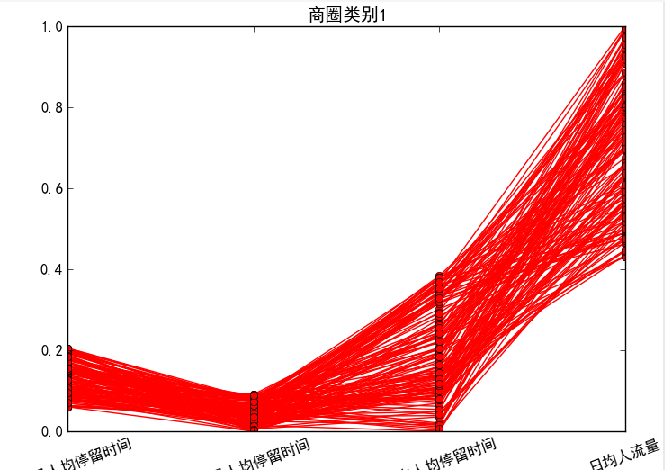
对于商圈类别1,日均人流量较大,同时工作日上班时间人均停留时间、凌晨人均停留时间和周末人均停留时间相对较短,该类别基站覆盖的区域类似于商业区

对于商圈类别2,凌晨人均停留时间和周末人均停留时间相对较长,而工作日上班时间人均停留时间较短,日均人流量较少,该类别基站覆盖的区域类似于住宅区。
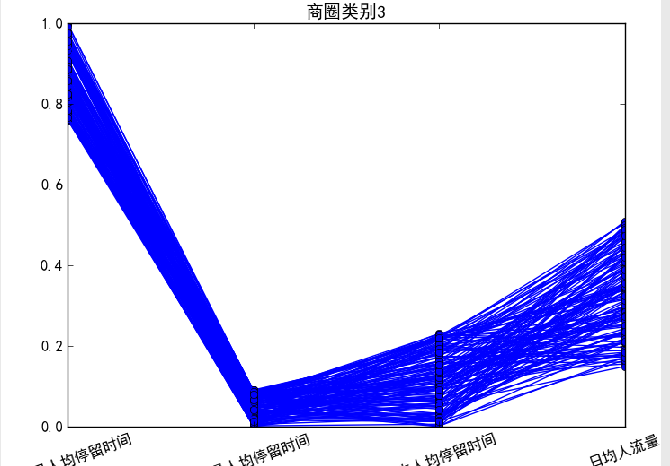
对于商圈类别3,这部分基站覆盖范围的工作日上班时间人均停留时间较长,同时凌晨人均停留时间、周末人均停留时间相对较短,该类别基站覆盖的区域类似于白领上班族的工作区域。
总结
商圈类别2的人流量较少,商圈类别3的人流量一般,而且白领上班族的工作区域一般的人员流动集中在上下班时间和午间吃饭时间,这两类商圈均不利于运营商的促销活动的开展,商圈类别1的人流量大,在这样的商业区有利于进行运营商的促销活动。
最后
相关文章:
计算机毕设 大数据商城人流数据分析与可视化 - python 大数据分析
文章目录 0 前言课题背景分析方法与过程初步分析:总体流程:1.数据探索分析2.数据预处理3.构建模型 总结 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到…...
vscode上搭建go开发环境
前言 Go语言介绍: Go语言适合用于开发各种类型的应用程序,包括网络应用、分布式系统、云计算、大数据处理等。由于Go语言具有高效的并发处理能力和内置的网络库,它特别适合构建高并发、高性能的服务器端应用。以下是一些常见的Go语言应用开发…...
10.(Python数模)(预测模型二)LSTM回归网络(1→1)
LSTM回归网络(1→1) 长短期记忆网络 - 通常只称为“LSTM” - 是一种特殊的RNN,能够学习长期的规律。 它们是由Hochreiter&Schmidhuber(1997)首先提出的,并且在后来的工作中被许多人精炼和推广。…...

mac常见问题(五) Mac 无法开机
在mac的使用过程中难免会碰到这样或者那样的问题,本期为您带来Mac 无法开机怎么进行操作。 1、按下 Mac 上的电源按钮。每台 Mac 电脑都有一个电源按钮,通常标有电源符号 。然后检查有没有通电迹象,例如: 发声,例如由风…...

WebSocket与SSE区别
一,websocket WebSocket是HTML5下一种新的协议(websocket协议本质上是一个基于tcp的协议) 它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的 Websocket是一个持久化的协议 websocket的原理 …...
Qt鼠标点击事件处理:显示鼠标点击位置(完整示例)
Qt 入门实战教程(目录) 前驱文章: Qt Creator 创建 Qt 默认窗口程序(推荐) 什么是事件 事件是对各种应用程序需要知道的由应用程序内部或者外部产生的事情或者动作的通称。 事件(event)驱动…...

OpenCV:实现图像的负片
负片 负片是摄影中会经常接触到的一个词语,在最早的胶卷照片冲印中是指经曝光和显影加工后得到的影像。负片操作在很多图像处理软件中也叫反色,其明暗与原图像相反,其色彩则为原图像的补色。例如,颜色值A与颜色值B互为补色&#…...

HZOJ#237. 递归实现排列型枚举
题目描述 从 1−n这 n个整数排成一排并打乱次序,按字典序输出所有可能的选择方案。 输入 输入一个整数 n。(1≤n≤8) 输出 每行一组方案,每组方案中两个数之间用空格分隔。 注意每行最后一个数后没有空格。 样例…...

C++ PIMPL 编程技巧
C PIMPL 编程技巧 文章目录 C PIMPL 编程技巧什么是pimpl?pimpl优点举例实现 什么是pimpl? Pimpl (Pointer to Implementation) 是一种常见的 C 设计模式,用于隐藏类的实现细节,从而减少编译依赖和提高编译速度。它的基本思想是将…...

一个通用的EXCEL生成下载方法
Excel是一个Java开发中必须会用到的东西,之前博主也发过一篇关于使用Excel的文章,但是最近工作中,发现了一个更好的使用方法,所以,就对之前的博客进行总结,然后就有了这篇新的,万能通用的方法说…...

介绍 TensorFlow 的基本概念和使用场景。
TensorFlow(简称TF)是由Google开发的开源机器学习框架,它具有强大的数值计算和深度学习功能,广泛用于构建、训练和部署机器学习模型。以下是TensorFlow的基本概念和使用场景: 基本概念: 张量(T…...
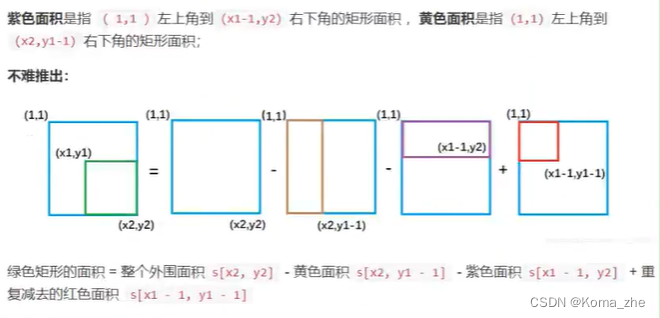
【力扣】304. 二维区域和检索 - 矩阵不可变 <二维前缀和>
目录 【力扣】304. 二维区域和检索 - 矩阵不可变二维前缀和理论初始化计算面积 题解 【力扣】304. 二维区域和检索 - 矩阵不可变 给定一个二维矩阵 matrix,以下类型的多个请求: 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为 (row1, …...
线上问诊:数仓开发(三)
系列文章目录 线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 线上问诊:数仓开发(二) 线上问诊:数仓开发(三) 文章目录 系列文章目录前言一、ADS1.交易主题1.交易综合统计2.各医院交易统计3.各性…...
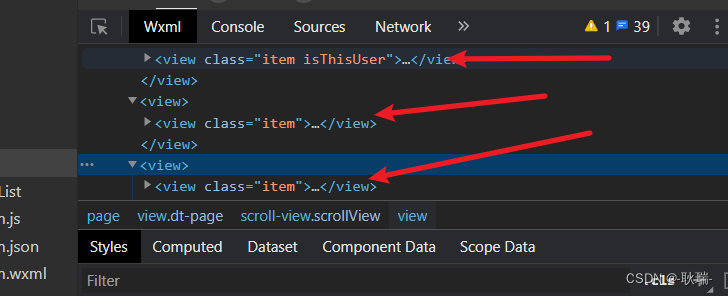
微信小程序 通过响应式数据控制元素class属性
我想大家照这个和我最初的目的一样 希望有和vue中v-bind:class一样方便的指令 但答案不太尽人意 这里 我们只能采用 三元运算符的形式 参考代码如下 <view class"item {{ userId item.userId ? isThisUser : }}"> </view>这里 我们判断 如果当前ite…...

linux并发服务器 —— linux网络编程(七)
网络结构模式 C/S结构 - 客户机/服务器;采用两层结构,服务器负责数据的管理,客户机负责完成与用户的交互;C/S结构中,服务器 - 后台服务,客户机 - 前台功能; 优点 1. 充分发挥客户端PC处理能力…...

Java后端开发面试题——企业场景篇
单点登录这块怎么实现的 单点登录的英文名叫做:Single Sign On(简称SSO),只需要登录一次,就可以访问所有信任的应用系统 JWT解决单点登录 用户访问其他系统,会在网关判断token是否有效 如果token无效则会返回401&am…...
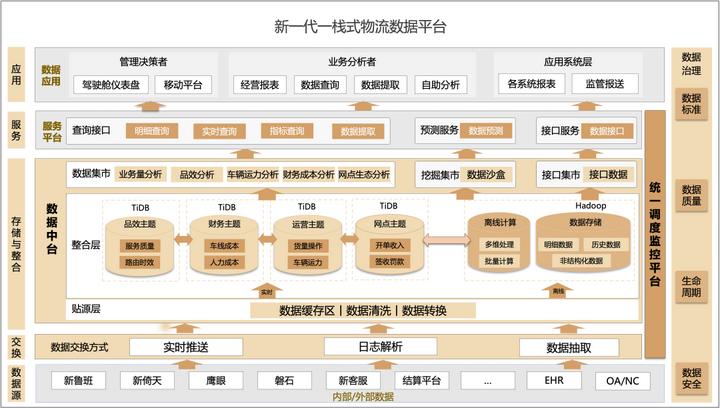
TiDB x 安能物流丨打造一栈式物流数据平台
作者:李家林 安能物流数据库团队负责人 本文以安能物流作为案例,探讨了在数字化转型中,企业如何利用 TiDB 分布式数据库来应对复杂的业务需求和挑战。 安能物流作为中国领先的综合型物流集团,需要应对大规模的业务流程ÿ…...

负载均衡算法实现
负载均衡算法实现 负载均衡介绍 负责均衡主要有以下五种方法实现: 1、轮询法 将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载; 2、随机法 通过系统的随机算法&#…...

Flutter 完美的验证码输入框 转载
刚开始看到这个功能的时候一定觉得so easy,开始的时候我也是这么觉得的,这还不简单,然而真正写的时候才发现并没有想象的那么简单。 先上图,不上图你们都不想看,我难啊,到Github: https://gith…...
)
SpringBoot整合Jpa实现增删改查功能(提供Gitee源码)
前言:在日常开发中,总是撰写一些简单的SQL会非常耗时间,Jpa可以完美的帮我们提高开发的效率,对于常规的SQL不需要我们自己撰写,相对于MyBatis有着更简单易用的功能,但是MyBatis自由度相对于Jpa会更高一些&a…...

Win11Debloat:让你的Windows系统告别臃肿,重获极速体验的完整指南
Win11Debloat:让你的Windows系统告别臃肿,重获极速体验的完整指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other chang…...

保姆级教程:用Python手把手复现FastICA算法,搞定信号盲分离
从零实现FastICA:Python实战信号盲源分离 想象一下,你正站在一个嘈杂的鸡尾酒会现场,四周环绕着此起彼伏的交谈声、玻璃杯碰撞声和背景音乐。神奇的是,人类大脑能够自动聚焦于特定对话——这种能力在信号处理领域被称为"盲源…...

N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频
N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 还…...
)
收藏必备!小白程序员快速入门RAG,解锁大模型知识检索与增强(干货满满)
本文详细介绍了RAG(检索增强生成)的概念、流程及优化策略。RAG通过从数据库检索上下文文档,有效提升LLM答案的准确性与时效性,解决纯生成模型的局限性。文章覆盖了文档加载、切分、向量化存储,以及检索与生成两个核心阶…...

如何用AntiMicroX解决PC游戏手柄兼容性问题:终极手柄映射工具完全指南
如何用AntiMicroX解决PC游戏手柄兼容性问题:终极手柄映射工具完全指南 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gi…...

终极微信聊天记录备份指南:免费开源工具WeChatExporter完整教程
终极微信聊天记录备份指南:免费开源工具WeChatExporter完整教程 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否担心珍贵的微信聊天记录会因手机损坏或…...

波卡XCMP深度解析:跨链通信的核心标准与实战指南
波卡XCMP深度解析:跨链通信的核心标准与实战指南 引言:多链时代的“通信协议” 在区块链从“单链”走向“多链”甚至“链网”的演进中,跨链互操作性已成为决定生态繁荣与否的关键。波卡(Polkadot)提出的XCMP࿰…...

废物利用实战:把吃灰的中兴B860AV1.1-T刷成Armbian服务器,跑Docker、挂小雅
旧机顶盒重生计划:中兴B860AV1.1-T改造家庭服务器全指南 当家里闲置的机顶盒积满灰尘时,大多数人会选择丢弃或闲置。但你可能不知道,这些被淘汰的设备往往隐藏着惊人的潜力——只需简单改造,就能变身为一台7x24小时运行的低功耗家…...

别再混淆了!一张图看懂SAP特殊采购类40、70、80的核心区别与适用场景
深度解析SAP特殊采购类40/70/80:业务逻辑与实战选型指南 引言 在SAP供应链管理的复杂生态中,特殊采购类(Special Procurement Type)是连接多工厂协同的神经中枢。当企业面临跨工厂物料调配、集中采购或分布式生产等场景时…...

如何实现虚拟游戏控制器:ViGEmBus驱动完整技术解析
如何实现虚拟游戏控制器:ViGEmBus驱动完整技术解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款专业的Windows内核模式驱动&am…...