软件工程学术顶会——ESEC/FSE 2022 议题(网络安全方向)清单、摘要与总结

总结
本次会议中网络安全相关议题涵盖区块链、智能合约、符号执行、浏览器API模糊测试等不同研究领域。
热门研究方向:
1. 基于深度学习的漏洞检测与修复
2. 基于AI的自动漏洞修复
3. 模糊测试与漏洞发现
冷门研究方向:
1. 多语言代码的漏洞分析
2. 代码审查中的软件安全
3. 浏览器API模糊测试
未来值得研究的方向建议:
1. 结合程序分析和AI技术的端到端自动漏洞管理
2. 面向0day漏洞的AI驱动检测与修复
3. 安全的机器学习系统构建与对抗样本防御

1、An empirical study of blockchain system vulnerabilities: modules, types, and patterns
区块链作为分布式账本技术,越来越受欢迎,特别是在支持有价值的加密货币和智能合约方面。然而,区块链软件系统不可避免地存在许多错误。尽管智能合约中的错误已经得到广泛研究,但底层区块链系统的安全错误却很少被探索。在本论文中,我们对四个代表性的区块链系统(比特币、以太坊、门罗币和恒星)进行了区块链系统漏洞的经验性研究。具体而言,我们首先设计了一个系统化的过滤流程,从GitHub上的34,245个问题/PR(拉取请求)和85,164个提交中有效地识别出1,037个漏洞及其2,317个修补程序。因此,我们建立了第一个区块链漏洞数据集,可在[https://github.com/VPRLab/BlkVulnDataset ↗](https://github.com/VPRLab/BlkVulnDataset) 上获取。然后,我们对这个数据集进行了三个层面的独特分析,包括(i)通过识别和关联项目之间的模块路径来对文件级别的脆弱模块进行分类,(ii)通过自然语言处理和基于相似度的句子聚类对文本级别的漏洞类型进行聚类,以及(iii)通过生成和聚类代码变更签名对代码级别的漏洞模式进行分析,这些签名捕捉了修补代码片段的语法和语义信息。
我们的分析揭示了三个关键发现:(i)一些区块链模块比其他模块更容易受到攻击;特别是与共识、钱包和网络相关的每个模块都有200多个问题;(ii)约70%的区块链漏洞属于传统类型,但我们还确定了四种针对区块链的新类型;(iii)我们获得了21种独特的区块链特定漏洞模式,捕捉了独特的区块链属性和状态,并证明它们可以用于检测其他流行区块链(如狗狗币、比特币SV和Zcash)中的类似漏洞。
论文链接:https://doi.org/10.1145/3540250.3549105

2、Automated generation of test oracles for RESTful APIs
近年来,用于生成RESTful API的测试用例的工具不断增多。然而,尽管它们取得了令人期待的结果,但它们都面临着同样的限制:它们只能检测崩溃(即服务器错误)和与API规范不符的情况。在本论文中,我们提出了一种通过检测不变量来自动生成RESTful API测试用例的技术。在实践中,我们的方法旨在通过分析先前的API请求及其相应来学习输出的预期属性。为此,我们扩展了广受欢迎的工具Daikon,用于动态检测可能的不变量。在对6个工业API的8个操作进行的初步评估中,总体精确度达到了66.5%(在2个操作中达到了100%)。此外,我们的方法还揭示了在拥有数百万用户的API中的6个可再现的错误:Amadeus、GitHub和OMDb。
论文链接:https://doi.org/10.1145/3540250.3559080

3、Automated unearthing of dangerous issue reports
协调漏洞披露(CVD)流程通常用于开源软件(OSS)漏洞管理,建议私下报告发现的漏洞,并在正式披露之前保密相关信息。然而,在实践中,由于各种原因(例如,缺乏安全领域专业知识或安全管理意识),许多漏洞在正式披露之前首先通过公开的问题报告(IRs)进行报告。这些IRs是危险的IRs,因为攻击者可以利用泄露的漏洞信息发起零日攻击。及早识别此类危险的IRs至关重要,这样OSS用户就可以更早地开始漏洞修复过程,OSS维护者也可以及时管理危险的IRs。在本文中,我们提出并评估了一种基于深度学习的方法,名为MemVul,用于在IR报告时自动识别危险的IRs。MemVul通过增加一个存储来自公共弱点枚举(CWE)的外部漏洞知识的记忆组件来增强神经网络。我们依靠公开可访问的CVE参考IRs(CIRs)来实施危险IR的概念。我们挖掘了分布在GitHub上托管的1,390个OSS项目中的3,937个CIRs。在高数据不平衡的实际场景下进行评估,MemVul在精确度和召回率之间取得了最佳权衡。特别是,MemVul的F1得分(即0.49)比最佳基线改进了44%。对于被预测为CIR但未报告给CVE的IRs,我们进行了用户研究,以调查它们对OSS利益相关者的有用性。我们观察到82%(50个中的41个)这些IR与安全相关,其中28个安全专家建议公开披露,表明MemVul能够识别未披露的危险IRs。
论文链接:https://doi.org/10.1145/3540250.3549156

4、Avgust: automating usage-based test generation from videos of app executions
编写和维护移动应用程序的UI测试是一项耗时且繁琐的任务。尽管经过数十年的研究,已经产生了自动生成UI测试的自动化方法,但这些方法通常侧重于测试崩溃或最大化代码覆盖率。相比之下,最近的研究表明,开发人员更喜欢基于使用方式的测试,这些测试集中在特定的应用功能使用上,以帮助支持回归测试等活动。很少有现有的技术支持生成此类测试,因为这要求自动化理解UI界面和用户输入的语义这一困难任务。在本文中,我们介绍了名为Avgust的工具,它自动化了生成基于使用方式的测试的关键步骤。Avgust使用神经模型进行图像理解,处理应用使用的视频录制,以合成与应用无关的状态机编码。然后,Avgust使用这个编码为新的目标应用程序合成测试用例。我们对18个热门应用程序的374个常见使用情况的视频进行了Avgust的评估,并显示69%的测试用例能够成功执行所需的使用方式,并且Avgust的分类器表现优于现有技术水平。
论文链接:https://doi.org/10.1145/3540250.3549134

5、Blackbox adversarial attacks and explanations for automatic speech recognition
自动语音识别(ASR)模型广泛应用于语音导航和家用电器的语音控制等应用程序中。ASR的计算核心是深度神经网络(DNN),已经证明其容易受到对抗性扰动的影响,并存在不良偏差和伦理问题。为了评估ASR的安全性,我们提出了一些生成黑盒(对DNN不可知)对抗性攻击的技术,这些攻击对各种ASR都具有可移植性。与现有的重点放在耗时且缺乏可移植性的白盒攻击的工作相比,这是一种不同的方法。此外,为了弄清楚为什么ASR(始终为黑盒)容易受到攻击,我们提供了一些关于ASR的解释方法,以帮助增加我们对系统的理解,并最终建立对系统的信任。
论文链接:https://doi.org/10.1145/3540250.3558906

6、CLIFuzzer: mining grammars for command-line invocations
命令行实用程序的行为可以通过传递命令行选项和参数(配置设置)来影响,这些设置可以启用、禁用或以其他方式影响要执行的代码部分。因此,对命令行实用程序的系统测试需要使用各种支持的命令行选项的不同配置进行测试。
我们介绍了CLIFuzzer,这是一个工具,它接收一个可执行程序,并使用动态分析来跟踪输入处理,自动提取其选项、参数和参数类型的完整集合。这个集合形成了一个语法,表示有效选项和参数的有效序列。通过从这个语法生成调用,我们可以使用无限列表的随机配置对程序进行模糊测试,覆盖相关代码。这将导致比纯变异式模糊测试器更高的覆盖率和新的错误发现。
论文链接:https://doi.org/10.1145/3540250.3558918

7、CodeMatcher: a tool for large-scale code search based on query semantics matching
由于大规模代码库(如GitHub和Gitee)的出现,搜索和重用现有代码可以帮助开发人员显著提高软件开发生产力。多年来,已经开发了许多代码搜索工具。早期的工具利用信息检索(IR)技术来对频繁变动的大规模代码库进行高效的代码搜索。然而,由于查询和代码之间的语义不匹配,搜索准确性较低。近年来,许多工具利用深度学习(DL)技术来解决这个问题。但基于DL的工具速度较慢,搜索准确性不稳定。
在本文中,我们介绍了一种基于IR的工具CodeMatcher,它继承了基于DL的工具在查询语义匹配方面的优点。通常,CodeMatcher首先为大规模代码库建立索引,以加快搜索响应时间。对于给定的搜索查询,它会处理查询中的无关和噪声词,然后通过迭代模糊搜索从索引的代码库中检索候选代码,最后根据查询和候选代码之间的两个设计指标重新排列候选代码。我们将CodeMatcher实现为一个搜索引擎网站。为了验证我们工具的有效性,我们在超过41,000个开源Java代码库上对CodeMatcher进行了评估。实验结果表明,CodeMatcher可以在一台普通配备Intel-i7 CPU的服务器上实现工业级响应时间(0.3秒)。在搜索准确性方面,CodeMatcher明显优于三个最先进的工具(DeepCS、UNIF和CodeHow)和两个在线搜索引擎(GitHub搜索和Google搜索)。
论文链接:https://doi.org/10.1145/3540250.3558935

8、DeJITLeak: eliminating JIT-induced timing side-channel leaks
时序侧信道可以在程序的执行时间与机密信息相关时被利用来推断机密信息。最近的研究表明,即时编译(JIT)可以引入新的时序侧信道,即使在源代码层面上是时间平衡的。在本文中,我们提出了一种新颖的方法来消除JIT引起的泄漏。我们首先通过时间平衡的概念,形式化了在JIT编译下的时序侧信道安全性,为推理带有JIT编译的程序奠定了基础。然后,我们提出通过细粒度的JIT编译来消除JIT引起的泄漏。为此,我们提供了一种自动化生成编译策略的方法和一种新颖的类型系统来保证其健全性。我们开发了一个名为DeJITLeak的工具,用于实际的Java代码,并在HotSpot JVM中实现了细粒度的JIT编译。实验结果表明,DeJITLeak可以在侧信道检测设置中,对三个广泛采用的基准测试中有效且高效地消除JIT引起的泄漏。
论文链接:https://doi.org/10.1145/3540250.3549150

9、Demystifying the underground ecosystem of account registration bots
会员服务是大多数在线系统的核心部分。例如,在在线社交网络和视频平台中,会员服务使得能够为用户提供定制内容或跟踪他们的足迹以进行推荐。然而,会员服务背后存在着一个黑暗的一面,包括影响者营销、优惠券收集和传播虚假消息。所有这些活动都严重依赖于拥有大量的虚假账户,而为了高效地创建新账户,恶意注册者使用了能够轻松绕过网站安全策略的自动注册机器人和反人类验证服务。在本文中,我们迈出了了解账户注册机器人及其使用的反人类验证服务的第一步。通过全面的分析,我们确定了三种最流行的反人类验证服务。然后,我们从攻击者的角度对这些服务进行了实验以验证它们的有效性。结果显示,所有这些服务都能够轻松绕过网站提供商为防止虚假注册而采取的安全策略,如短信验证、验证码和IP监控。我们进一步估计了地下注册生态系统的市场规模,约为每年480万至1.281亿美元。我们的研究表明,我们需要紧急思考我们的注册安全策略的有效性,并促使我们制定新的策略以更好地保护系统。
论文链接:https://doi.org/10.1145/3540250.3549090

10、Diet code is healthy: simplifying programs for pre-trained models of code
预训练的代码表示模型(如CodeBERT)在各种软件工程任务中展现出了卓越的性能,然而它们往往在复杂性上很重,与输入序列的长度呈二次关系。我们对CodeBERT的注意力进行了实证分析,发现CodeBERT更关注某些类型的标记和语句,如关键字和与数据相关的语句。基于这些发现,我们提出了DietCode,旨在对源代码进行轻量级的大规模预训练模型利用。DietCode通过三种策略简化了CodeBERT的输入程序,即词语丢弃、频率过滤和基于注意力的策略,在预训练期间选择接收最多关注权重的语句和标记。因此,它在不影响模型性能的情况下大幅减少了计算成本。两个下游任务的实验结果表明,DietCode在微调和测试中的计算成本比CodeBERT低40%,并提供了可比较的结果。
论文链接:https://doi.org/10.1145/3540250.3549094

11、FastKLEE: faster symbolic execution via reducing redundant bound checking of type-safe pointers
符号执行(SE)已被广泛应用于自动程序分析和软件测试。许多SE引擎(如KLEE或Angr)在执行过程中需要解释代码的某些中间表示(IR),这可能会很慢且成本高昂。尽管有很多研究提出了加速SE的方法,但其中很少有考虑优化内部解释操作的。在本文中,我们提出了FastKLEE,这是一个更快的SE引擎,旨在通过减少在IR代码解释过程中对类型安全指针进行冗余边界检查来加速执行。具体而言,在FastKLEE中,首先利用了一个类型推断系统来对最常解释的读/写指令的指针类型进行分类(即安全或不安全)。然后,设计了一个定制的内存操作,仅对不安全指针进行边界检查,并省略对安全指针的冗余检查。我们在著名的SE引擎KLEE之上实现了FastKLEE,并将其与知名的类型推断系统CCured相结合。评估结果表明,相对于同样探索相同数量(即10k)执行路径的最新方法KLEE,FastKLEE能够将时间降低高达9.1%(平均为5.6%)。FastKLEE的开源代码可在[https://github.com/haoxintu/FastKLEE上找到 ↗](https://github.com/haoxintu/FastKLEE上找到)。FastKLEE的视频演示可在[https://youtu.be/fjV_a3kt-mo上观看 ↗](https://youtu.be/fjV_a3kt-mo上观看)。
论文链接:https://doi.org/10.1145/3540250.3558919

12、Fault localization to detect co-change fixing locations
故障定位(FL)是大多数自动化程序修复(APR)方法的先导步骤,它修复了FL工具识别出的有问题的语句。我们提出了FixLocator,一种基于深度学习(DL)的故障定位方法,支持在同一个修复中检测一个或多个方法中的有问题语句,并相应地进行修改。我们称它们为故障的共同修改(CC)位置。我们将这个FL问题看作是双任务学习,使用两个模型。方法级别的FL模型MethFL学习需要一起修复的方法。语句级别的FL模型StmtFL学习需要共同修复的语句。一个模型的正确学习可以使另一个模型受益,反之亦然。因此,我们通过交叉连接单元以软共享模型参数来同时训练它们,以实现MethFL和StmtFL之间的影响传播。此外,我们还探索了一种用于FL的新特征:共同修改的语句。我们还使用基于图的卷积网络来整合不同类型的程序依赖关系。
我们的实证结果显示,FixLocator相对于最先进的语句级FL基准模型,定位了26.5% - 155.6%更多的共同修改语句。为了评估其在APR中的有用性,我们将FixLocator与最先进的APR工具结合使用。结果显示,FixLocator+DEAR(DEAR中原始的FL被FixLocator替换)和FixLocator+CURE相对于原始的DEAR和Ochiai+CURE分别在修复的错误数量方面提高了10.5%和42.9%。
论文链接:https://doi.org/10.1145/3540250.3549137

13、Fuzzing deep-learning libraries via automated relational API inference
近年来,深度学习(DL)引起了广泛关注。与此同时,DL系统中的错误可能导致严重后果,甚至可能威胁到人类生命安全。因此,越来越多的研究致力于DL模型测试。然而,对于DL库(例如PyTorch和TensorFlow)的测试工作仍然有限,而这些库是构建、训练和运行DL模型的基础。以往关于DL库模糊测试的工作只能为已经被文档示例、开发者测试或DL模型调用过的API生成测试,留下了大量未经测试的API。在本文中,我们提出了DeepREL,这是第一个用于自动推断关系型API以实现更有效的DL库模糊测试的方法。我们的基本假设是,在测试的DL库中,可能存在许多共享相似输入参数和输出的API;通过这种方式,我们可以轻松地从调用过的API中“借用”测试输入来测试其他关系型API。此外,我们为关系型API形式化了值等价和状态等价的概念,以作为有效的错误发现的预期结果。我们已经将DeepREL实现为完全自动化的端到端关系型API推断和DL库模糊测试技术,它可以:1)基于API的语法/语义信息自动推断潜在的API关系;2)合成用于调用关系型API的具体测试程序;3)通过代表性的测试输入验证推断的关系型API;最后4)对经过验证的关系型API进行模糊测试以发现潜在的不一致之处。我们对两个最流行的DL库PyTorch和TensorFlow进行了评估,结果显示DeepREL可以涵盖比最先进的FreeFuzz多157%的API。迄今为止,DeepREL已经总共检测出162个错误,其中106个已由开发者确认为以前未知的错误。令人惊讶的是,DeepREL在三个月的时间内检测到了整个PyTorch问题跟踪系统中13.5%的高优先级错误。此外,除了这162个代码错误,我们还发现了14个文档错误(全部得到确认)。
论文链接:https://doi.org/10.1145/3540250.3549085

14、Generating realistic vulnerabilities via neural code editing: an empirical study
大规模、真实的漏洞数据集的可用性对于评估现有技术和开发有效的基于数据驱动的软件安全方法至关重要。然而,这样的数据集严重缺乏。一种有前途的解决方案是通过向现实世界的程序注入漏洞来生成这样的数据集,而现实世界的程序是丰富可用的。因此,在本文中,我们通过神经代码编辑探索了注入漏洞的可行性。通过合成数据集和真实数据集,我们调查了三种最先进的神经代码编辑器在注入漏洞方面的潜力和差距。我们发现,在真实数据集上,这些研究中的编辑器存在关键限制,最好的准确率仅为10.03%,而在合成数据集上为79.40%。虽然基于图的编辑器比基于序列的编辑器更有效(在高达34.93%的真实测试样本中成功注入漏洞),但它们仍然受到复杂的代码结构和长时间编辑的限制,因为它们在预处理和深度学习(DL)模型的设计上不足。我们揭示了神经代码编辑生成真实易受攻击样本的潜力,因为它们可以提高基于DL的漏洞检测器的F1得分高达49.51%。我们还提供了对当前编辑器的差距的深入了解(例如,它们擅长删除但不擅长替换代码)以及解决这些差距的可行建议(例如,设计有效的编辑原语)。
论文链接:https://doi.org/10.1145/3540250.3549128

15、Group-based corpus scheduling for parallel fuzzing
并行模糊测试依赖于硬件资源来保证测试吞吐量和效率。在工业实践中,众所周知,并行模糊测试面临任务划分的挑战,但大多数研究忽视了重要的语料库分配过程。在本文中,我们提出了一种基于群组的语料库调度策略来解决这两个问题,该策略已被LLVM社区接受。我们基于该策略实现了一个名为glibFuzzer的并行模糊测试工具。glibFuzzer首先将全局语料库划分为不同的子集,然后为它们分配不同的能量分数和差异分数。能量分数主要由种子大小和覆盖信息的长度确定,而差异分数可以描述不同子集种子所覆盖的代码差异程度。在每一轮关键的局部语料库构建中,主节点通过结合这两个分数选择高质量的种子,以提高测试效率并避免任务冲突。为了证明该策略的有效性,我们对真实世界的程序和FuzzBench进行了广泛的评估。经过4×24个CPU小时的测试,glibFuzzer在18个真实世界的程序中比libFuzzer覆盖了22.02%更多的分支,执行了19.42倍的测试用例。相较于AFL、PAFL和UniFuzz,glibFuzzer的平均分支覆盖率分别提高了73.02%、55.02%和55.86%。更重要的是,glibFuzzer发现了100多个独特的漏洞。
论文链接:https://doi.org/10.1145/3540250.3560885

16、How to better utilize code graphs in semantic code search?
语义代码搜索极大地促进了软件重用,使用户能够找到与用户指定的自然语言查询高度匹配的代码片段。由于代码图的丰富表达能力(如控制流图和程序依赖图),这两种主流研究工作(即多模态模型和预训练模型)都试图将代码图纳入代码建模中。然而,它们仍然存在一些局限性:首先,在搜索效果方面仍有很大的改进空间。其次,它们尚未充分考虑代码图的独特特征。在本文中,我们提出了一种名为G2SC的图转序列转换器。通过将代码图转换为无损序列,G2SC能够通过序列特征学习解决小图学习问题,并捕捉代码图的边缘和节点属性信息。从而,可以大大提高代码搜索的效果。特别是,G2SC首先通过特定的图遍历策略将代码图转换为唯一的相应节点序列。然后,通过用相应语句替换每个节点,得到语句序列。一组精心设计的图遍历策略确保该过程是一对一且可逆的。G2SC能够捕捉丰富的语义关系(如控制流、数据流、节点/关系属性),并提供适合学习模型的数据转换。它可以灵活地与现有模型集成,以更好地利用代码图。作为概念验证应用,我们提出了两种启用了G2SC的模型:GSMM(启用G2SC的多模态模型)和GSCodeBERT(启用G2SC的CodeBERT模型)。对两个真实的大规模数据集进行的广泛实验结果表明,GSMM和GSCodeBERT在R@1上分别将先前最先进的模型MMAN和GraphCodeBERT的性能提高了92%和22%,在MRR上分别提高了63%和11.5%。
论文链接:https://doi.org/10.1145/3540250.3549087

17、Input splitting for cloud-based static application security testing platforms
随着软件开发团队采用DevSecOps实践,应用程序安全越来越成为开发团队的责任,他们需要建立自己的静态应用程序安全测试(SAST)基础设施。由于开发团队通常没有必要的基础设施和专业知识来设置自定义的SAST解决方案,因此对于以服务方式运行各种静态分析器的基于云的SAST平台的需求越来越大。将新的静态分析器添加到基于云的SAST平台中可能具有挑战性,因为静态分析器在复杂性上存在很大差异,从高效扩展的代码检查工具到使用立方或更复杂算法的过程间数据流引擎。需要仔细的手动评估来决定新分析器是否会降低平台的整体响应时间或是否会经常超时。我们探讨了是否可以通过将分析器的输入分成多个分区并独立分析这些分区来简化这个问题。根据静态分析器的复杂性,可以调整分区大小以缩短整体响应时间。我们报告了一项实验,其中我们使用不同的分析工具运行了有和没有分割输入的情况。实验结果表明,简单的分割策略可以有效地减少每个分区的运行时间和内存使用,而不会对工具产生显著影响的结果。
论文链接:https://doi.org/10.1145/3540250.3558944

18、KVS: a tool for knowledge-driven vulnerability searching
我们将现有的漏洞管理库中分散的漏洞信息进行提取和整理,以便快速定位和搜索特定的漏洞及其解决方案变得更加容易。为了解决这个问题,我们从漏洞报告中提取知识,并将漏洞信息组织成知识图谱的形式。然后,我们实现了一个基于知识驱动的漏洞搜索工具,即KVS。该工具主要使用BERT模型实现漏洞命名实体识别,并构建漏洞知识图谱(VulKG)。最后,我们可以根据VulKG搜索感兴趣的漏洞。该工具的URL是[https://cinnqi.github.io/Neo4j-D3-VKG/ ↗](https://cinnqi.github.io/Neo4j-D3-VKG/)。我们演示的视频可在[https://youtu.be/FT1BaLUGPk0中观看 ↗](https://youtu.be/FT1BaLUGPk0中观看)。
论文链接:https://doi.org/10.1145/3540250.3558920

19、MANDO-GURU: vulnerability detection for smart contract source code by heterogeneous graph embeddings
智能合约在区块链系统中越来越广泛应用于高价值应用。在部署之前,确保智能合约源代码的质量非常重要。本论文提出了一种新的基于深度学习的工具,名为MANDO-GURU,旨在准确检测智能合约在粗粒度合约级别和细粒度行级别上的漏洞。通过使用Solidity代码的控制流图和调用图的组合,我们设计了新的异构图注意力神经网络,以编码图中不同类型的节点和边之间的更多结构和潜在语义关系,并使用图和节点的编码嵌入来检测漏洞。我们通过对真实世界的智能合约数据集进行验证,发现MANDO-GURU在合约级别的F1得分方面可以显着改善其他许多漏洞检测技术,具体取决于漏洞类型,改进幅度高达24%。它是第一个基于学习的以太坊智能合约工具,可以在行级别识别漏洞,并且在传统的基于代码分析的技术上改进了高达63.4%。我们的工具可以在[https://github.com/MANDO-Project/ge-sc-machine公开获取 ↗](https://github.com/MANDO-Project/ge-sc-machine公开获取)。测试版本目前已部署在[http://mandoguru.com ↗](http://mandoguru.com),并且我们的工具演示视频可在[http://mandoguru.com/demo-video上观看 ↗](http://mandoguru.com/demo-video上观看)。
论文链接:https://doi.org/10.1145/3540250.3558927

20、MOSAT: finding safety violations of autonomous driving systems using multi-objective genetic algorithm
自动驾驶系统(ADS)是安全关键系统,实际交通中自动驾驶车辆(AV)的安全违规将会造成巨大损失。因此,在将ADS部署到真实道路之前,必须进行充分的测试。仿真测试对于发现ADS的安全违规非常重要。本论文提出了一种名为MOSAT的多目标基于搜索的测试框架,该框架构建了多样化和对抗性的驾驶环境,以揭示ADS的安全违规。具体而言,基于原子驾驶动作,MOSAT引入了模式图案,描述了一系列能够有效挑战ADS的驾驶动作序列。MOSAT通过原子动作和模式图案构建测试场景,并使用多目标遗传算法搜索对抗性和多样化的测试场景。此外,为了全面测试ADS在长里程驾驶期间的性能,我们设计了一种新颖的连续仿真测试技术,通过同时运行多个并行搜索过程在模拟器中生成的场景,并持续对ADS进行不同的扰动。我们在百度Apollo工业级平台上展示了MOSAT,并实验证明MOSAT能够有效地生成导致ADS崩溃的安全关键场景,并在短时间内暴露出11种不同类型的安全违规。它还通过在同一道路上发现更多的6种不同安全违规而超越了现有技术的表现。
论文链接:https://doi.org/10.1145/3540250.3549100

21、Minerva: browser API fuzzing with dynamic mod-ref analysis
现代网络体验中浏览器API是必不可少的。由于其数量众多且复杂性高,它们极大地扩展了浏览器的攻击面。为了检测这些API中的漏洞,模糊测试器生成大量随机API调用的测试用例。然而,由任意API组合形成的庞大搜索空间阻碍了它们的有效性:由于随机选择的API调用不太可能相互干扰(即,在部分共享数据上计算),很少探索有趣的API交互。因此,在浏览器模糊测试中,通过揭示API之间的关系来减少搜索空间是一个重大挑战。我们提出了Minerva,一种用于浏览器API漏洞检测的高效模糊测试工具。关键思想是利用API干扰关系来减少冗余并改善覆盖率。Minerva包括两个模块:动态修改引用分析和引导代码生成。在模糊测试开始之前,动态修改引用分析模块构建了一个API干扰图。它首先从浏览器的代码库中自动识别单个浏览器API。接下来,它对浏览器进行仪器化以动态收集API之间的修改引用关系。在模糊测试过程中,引导代码生成模块根据修改引用关系合成高度相关的API调用。我们在三个主流浏览器(Safari,FireFox和Chromium)上评估了Minerva。与最先进的模糊测试工具相比,Minerva将边界覆盖率提高了19.63%至229.62%,并发现了2倍至3倍的独特漏洞。此外,Minerva还发现了35个以前未知的漏洞,其中20个已经得到修复,并分配了5个CVE编号,并得到了浏览器供应商的认可。
论文链接:https://doi.org/10.1145/3540250.3549107

22、On the vulnerability proneness of multilingual code
使用多种语言进行软件构建长期以来一直是一种常态,然而多语言代码构建是否具有重要的安全影响和实际的安全后果仍然不清楚。本论文旨在通过对GitHub上流行的多语言项目及其演化历史进行大规模研究来回答这个问题,我们采用了新颖的多语言代码特征化技术实现了这一目标。我们发现多语言代码易受漏洞攻击(包括一般漏洞和特定类别的漏洞)与其语言选择之间存在统计学上显著的关联。我们还发现,这种关联与语言接口机制的关联相关,而不是与个别语言的关联相关。我们通过深入的实际漏洞案例研究验证了我们的统计结果,通过机制和语言选择进行了解释。我们的研究结果呼吁立即采取行动来评估和防御多语言漏洞,并提供了实际的建议。
论文链接:https://doi.org/10.1145/3540250.3549173

23、RoboFuzz: fuzzing robotic systems over robot operating system (ROS) for finding correctness bugs
机器人系统正在成为人类生活中不可或缺的一部分。为了应对对机器人生产的增加需求,机器人操作系统(ROS)作为一种开源的中间件套件,通过提供实用的工具和库来快速开发机器人,正在受到越来越多的关注。在本文中,我们关注于ROS和基于ROS的机器人系统中相对较少经过测试的一类错误,称为语义正确性错误,包括规范违反、物理定律违反和网络物理不一致。这些错误通常源于机器人系统的网络物理特性,其中嘈杂的硬件组件与软件组件交织在一起,因此无法通过现有的主要关注于查找内存安全错误的模糊测试方法来检测。
我们提出了RoboFuzz,这是一个与ROS集成并能够测试正确性错误的反馈驱动模糊测试框架。RoboFuzz具有以下特点:(1) 数据类型感知的变异,有效地对数据驱动的ROS系统进行压力测试;(2) 混合执行,从真实世界和模拟器中获取机器人状态,捕捉到未预料的网络物理不一致;(3) 一个预定义正确性规则的判断器,通过检查执行状态与预定义的正确性规则进行对比,识别正确性错误;(4) 一个语义反馈引擎,为输入变异器提供增强的指导,补充传统的基于代码覆盖率的反馈,对于分布式的数据驱动机器人而言,传统反馈方法不够有效。通过将ROS和四个与ROS兼容的机器人系统的正确性不变式编码到专门的判断器中,RoboFuzz检测到了30个之前未知的错误,其中25个已被确认并修复了六个。
论文链接:https://doi.org/10.1145/3540250.3549164

24、SEDiff: scope-aware differential fuzzing to test internal function models in symbolic execution
符号执行已成为基础的程序分析技术。执行符号执行时,不可避免地会遇到提供基本操作(例如字符串处理)的内部函数(例如库函数)。
许多符号执行引擎构建内部函数模型,以便为可扩展性和兼容性考虑抽象函数行为。由于构建模型的复杂性很高,开发人员有意只摘要部分函数行为,即模型化的功能。
内部函数模型的正确性至关重要,因为它将影响符号执行的所有应用,例如漏洞检测和模型检查。
对内部函数模型进行正确性测试的一种简单解决方案是交叉检查模型的行为是否符合其相应的原始函数实现。然而,这样的解决方案通常会检测到与未建模功能有关的压倒性不一致性,这些功能超出了模型的范围,因此被认为是虚假报告。
我们认为,合理的测试方法应仅针对开发人员打算建模的功能。然而,自动识别被建模功能的范围是一个重大挑战。
在本文中,我们提出了一种面向范围的差异测试框架SEDiff来解决这个问题。我们设计了一种新颖的算法,自动将模型化的功能映射到原始实现中的代码。SEDiff然后将面向范围的灰盒差异模糊化应用于原始实现中的相关代码。它还配备了一种新颖的面向范围的输入生成器和定制的错误检查器,可以高效且正确地检测出错误的不一致性。我们对几个针对二进制、Web和内核的热门实际符号执行引擎进行了广泛评估。我们的手动调查显示,SEDiff准确地识别了模型化的功能,并检测出在符号执行引擎中使用的内部函数模型中的46个新漏洞。
论文链接:https://doi.org/10.1145/3540250.3549080

25、Security code smells in apps: are we getting better?
用户在日常任务中越来越依赖于移动应用程序,包括在线银行、电子健康和电子政务等涉及安全和隐私的任务。此外,大量传感器捕捉用户的运动和习惯,用于健身追踪和便利性。尽管法律法规对处理隐私敏感数据施加了要求和限制,用户仍然必须信任应用程序开发者能够提供足够的保护。在本文中,我们调查了Android应用程序的安全状态以及自Android操作系统引入以来安全相关代码异味的发展。
通过对2010年至2021年期间谷歌Play商店的每年300个应用程序进行分析,我们发现每千行代码的代码扫描器发现数量随时间而减少。然而,这一发展趋势被代码规模的增加所抵消。应用程序的发现越来越多,表明整体安全水平降低。这一趋势源于加密使用的缺陷、不安全的编译器标志、WebView组件的不安全使用以及反射等语言特性的不安全使用。根据我们的数据,我们主张在应用程序进入商店之前对其进行更严格的控制。
论文链接:https://doi.org/10.1145/3540250.3549091

26、Software security during modern code review: the developer’s perspective
为了避免软件漏洞,组织机构正在将安全性转移到软件开发的早期阶段,比如在代码审查时。在本文中,我们旨在了解开发人员在代码审查期间评估软件安全性时的观点,他们遇到的挑战以及公司和项目提供的支持。为此,我们进行了两步调查:我们采访了10名专业开发人员,并对182名从业者进行了关于代码审查期间软件安全性评估的调查。研究结果是开发人员在代码审查期间对软件安全性的感知概述和一系列已经确定的挑战。我们的研究发现,大多数开发人员在代码审查期间并不立即报告关注安全问题。只有在被问及软件安全性后,开发人员才表示在审查过程中始终考虑安全性并认识到其重要性。大多数公司并不提供安全培训,但却期望开发人员在审查中仍然确保安全性。因此,开发人员报告了缺乏培训和安全知识是他们在检查安全问题时面临的主要挑战。此外,他们在处理第三方库和识别可能具有安全影响的代码部分之间的交互时也面临挑战。此外,由于开发人员对他们开发的应用程序的安全动态的假设,安全性在审查过程中可能被忽视。
预印本:https://arxiv.org/abs/2208.04261
数据和材料:https://doi.org/10.5281/zenodo.6969369
论文链接:https://doi.org/10.1145/3540250.3549135

27、SolSEE: a source-level symbolic execution engine for solidity
大多数现有的智能合约符号执行工具在字节码上进行分析,这导致源代码中的高级语义信息丢失。这使得交互式分析任务(如可视化和调试)变得非常具有挑战性,并且显著限制了工具的可用性。在本文中,我们介绍了SolSEE,一种针对Solidity智能合约的源代码级符号执行引擎。我们描述了SolSEE的设计,突出了其关键特性,并通过基于Web的用户界面演示了其用法。SolSEE在所支持的高级Solidity语言特性和分析灵活性方面具有优势,相比其他现有的源代码级分析工具。可以在以下链接中观看演示视频:https://sites.google.com/view/solsee/。
论文链接:https://doi.org/10.1145/3540250.3558923

28、Tracking patches for open source software vulnerabilities
开源软件(OSS)漏洞威胁着使用OSS的软件系统的安全性。漏洞数据库提供有关缓解OSS漏洞的宝贵信息(例如,易受攻击的版本和补丁)。人们越来越关注漏洞数据库的信息质量问题。然而,现有的漏洞数据库中补丁的质量尚不清楚;而现有的基于手动或启发式方法的补丁跟踪方法要么过于昂贵,要么过于特定,无法应用于所有OSS漏洞。
为了解决这些问题,我们首先进行了一项实证研究,以了解两个工业漏洞数据库中的OSS漏洞补丁的质量和特征。受我们研究的启发,我们提出了第一个自动化方法Tracer,用于从多个知识来源跟踪OSS漏洞的补丁。我们的评估结果表明:i)与基于启发式方法相比,Tracer可以跟踪多达273.8%的漏洞补丁,并且在F1分数上实现更高的得分,高达116.8%;ii)Tracer可以补充工业漏洞数据库。我们的评估还表明了Tracer的普适性和实用性。
论文链接:https://doi.org/10.1145/3540250.3549125

29、VulCurator: a vulnerability-fixing commit detector
开源软件(OSS)漏洞管理过程在当今时代非常重要,因为发现的OSS漏洞数量随着时间的推移而增加。监测漏洞修复提交是防止漏洞利用的标准流程的一部分。然而,由于需要审核的提交可能很多,手动检测漏洞修复提交非常耗时。最近,许多技术已经提出使用机器学习自动检测漏洞修复提交。这些解决方案要么没有使用深度学习,要么只使用有限的信息源进行深度学习。本文提出了VulCurator,这是一个利用更丰富的信息源(包括提交消息、代码更改和问题报告)的深度学习工具,用于漏洞修复提交分类。我们的实验结果表明,VulCurator在F1分数方面超过了现有技术基准最多16.1%。
VulCurator工具可以在以下网址公开获取:https://github.com/ntgiang71096/VFDetector 和 https://zenodo.org/record/7034132# .Yw3MN-xBzDI,并附有演示视频:https://youtu.be/uMlFmWSJYOE。
论文链接:https://doi.org/10.1145/3540250.3558936

30、VulRepair: a T5-based automated software vulnerability repair
随着软件漏洞数量和复杂性的增加,研究人员提出了各种基于人工智能(AI)的方法,以帮助资源有限的安全分析人员发现、检测和定位漏洞。然而,安全分析人员仍然需要花费大量的精力手动修复这些易受攻击的功能。最近的研究提出了一种基于NMT的自动漏洞修复方法,但由于各种限制,它仍然远未完善。在本文中,我们提出了VulRepair,一种基于T5的自动软件漏洞修复方法,它利用了预训练和BPE组件来解决之前工作中的各种技术限制。通过对来自1,754个真实软件项目的8,482个漏洞修复进行广泛实验,我们发现我们的VulRepair实现了44%的完美预测,比竞争基准方法更准确13%-21%。这些结果使我们得出结论,我们的VulRepair比两种基准方法更准确,突显了基于NMT的自动漏洞修复的重大进展。我们的额外调查还显示,我们的VulRepair可以准确修复1,706个真实世界中的多达745个众所周知的漏洞(例如Use After Free、不正确的输入验证、操作系统命令注入),展示了我们的VulRepair在生成漏洞修复方面的实用性和重要性,帮助资源有限的安全分析人员修复漏洞。
论文链接:https://doi.org/10.1145/3540250.3549098

31、You see what I want you to see: poisoning vulnerabilities in neural code search
在基于自然语言查询的开源软件代码片段搜索和重用方面,可以极大地提高编程效率。最近,基于深度学习的方法在代码搜索领域越来越受欢迎。尽管在训练准确的代码搜索模型方面取得了实质性进展,但对这些模型的鲁棒性的关注却很少。
本文旨在通过回答以下问题来研究和了解代码搜索模型的安全性和鲁棒性:我们能否向基于深度学习的代码搜索模型注入后门?如果是这样,我们能否检测到被污染的数据并清除这些后门?本研究通过数据污染对基于深度学习模型的代码搜索模型进行了一系列后门攻击的研究和开发。我们首先展示了现有模型对基于数据污染的后门攻击的脆弱性。然后,我们介绍了一种简单而有效的攻击方法,通过污染相应的训练数据集来攻击神经代码搜索模型。
此外,我们还证明攻击可以通过向训练语料库中添加几个特制的源代码文件来影响代码搜索结果的排名。我们展示了这种类型的后门攻击对几个代表性的基于深度学习的代码搜索系统是有效的,并且可以成功操纵搜索结果的排名列表。以双向RNN为基础的代码搜索系统为例,给定一个包含攻击目标词(例如“file”)的查询,目标候选项的归一化排名可以从前50%显著提升到前4.43%。为了防御这种攻击,我们经验性地检查了一种现有的常用防御策略,并评估了其性能。我们的结果表明,在我们提出的代码搜索系统的后门攻击中,探索的防御策略尚不起作用。
论文链接:https://doi.org/10.1145/3540250.3549153

相关文章:
软件工程学术顶会——ESEC/FSE 2022 议题(网络安全方向)清单、摘要与总结
总结 本次会议中网络安全相关议题涵盖区块链、智能合约、符号执行、浏览器API模糊测试等不同研究领域。 热门研究方向: 1. 基于深度学习的漏洞检测与修复 2. 基于AI的自动漏洞修复 3. 模糊测试与漏洞发现 冷门研究方向: 1. 多语言代码的漏洞分析 2. 代码审查中的软件安全 3. 浏…...

从C语言到C++_36(智能指针RAII)auto_ptr+unique_ptr+shared_ptr+weak_ptr
目录 1. 智能指针的引入_内存泄漏 1.1 内存泄漏 1.2 如何避免内存泄漏 2. RAII思想 2.1 RAII解决异常安全问题 2.2 智能指针原理 3. auto_ptr 3.1 auto_ptr模拟代码 4. unique_ptr 4.1 unique_ptr模拟代码 5. shared_ptr 5.1 shared_ptr模拟代码 5.2 循环引用 6.…...
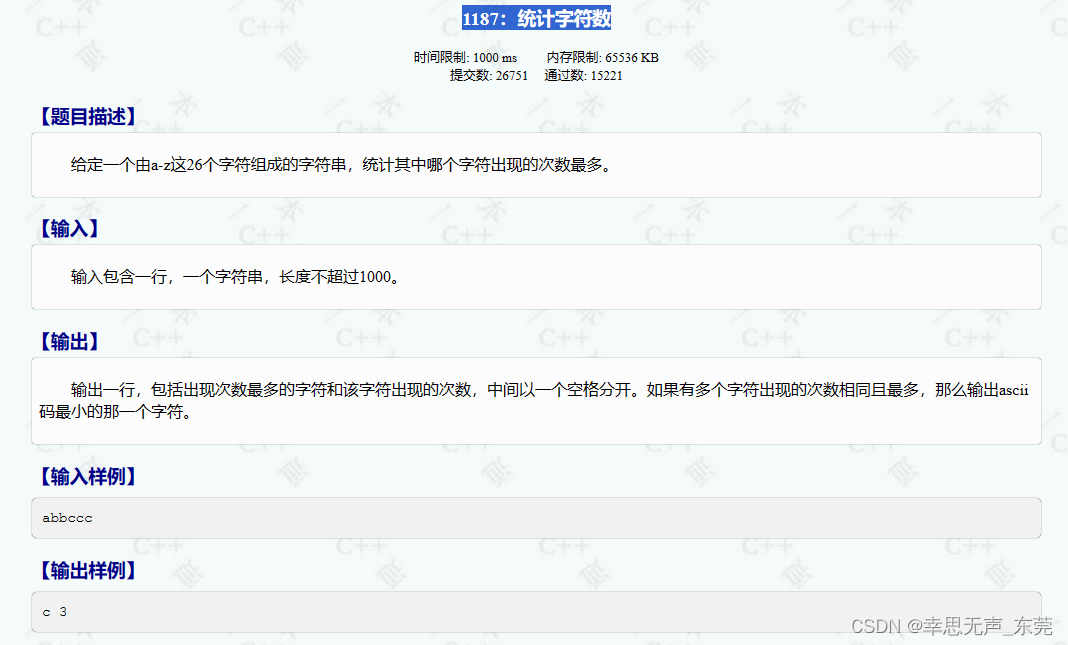
C++信息学奥赛1187:统计字符数
#include <bits/stdc.h> using namespace std; int main() {string arr;cin >> arr; // 输入一个字符串int n, a, max; // 定义变量n, a, maxchar ArrMax; // 定义字符变量ArrMaxn arr.length(); // 获取字符串长度max a 0; // 初始化max和a为0// 外层循环&…...
计算机毕设 大数据商城人流数据分析与可视化 - python 大数据分析
文章目录 0 前言课题背景分析方法与过程初步分析:总体流程:1.数据探索分析2.数据预处理3.构建模型 总结 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到…...
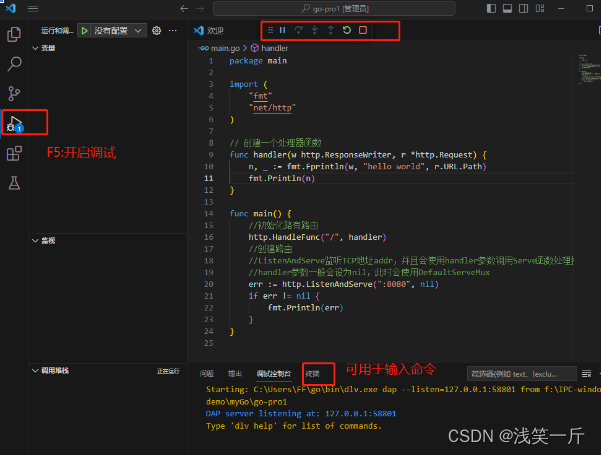
vscode上搭建go开发环境
前言 Go语言介绍: Go语言适合用于开发各种类型的应用程序,包括网络应用、分布式系统、云计算、大数据处理等。由于Go语言具有高效的并发处理能力和内置的网络库,它特别适合构建高并发、高性能的服务器端应用。以下是一些常见的Go语言应用开发…...
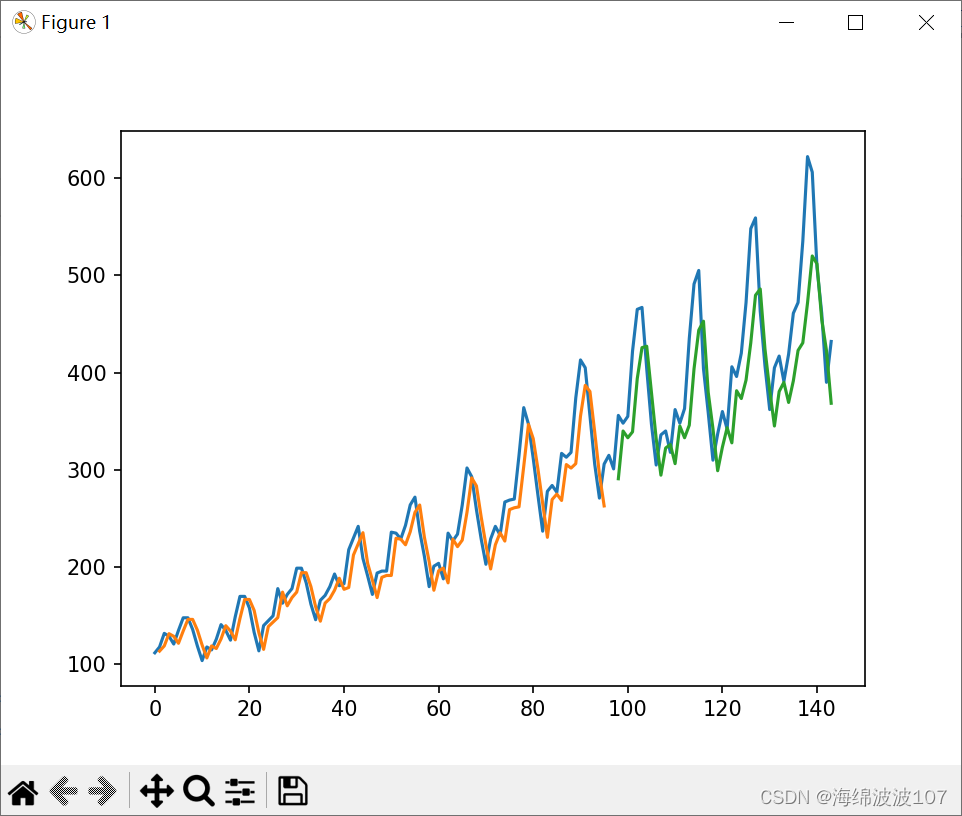
10.(Python数模)(预测模型二)LSTM回归网络(1→1)
LSTM回归网络(1→1) 长短期记忆网络 - 通常只称为“LSTM” - 是一种特殊的RNN,能够学习长期的规律。 它们是由Hochreiter&Schmidhuber(1997)首先提出的,并且在后来的工作中被许多人精炼和推广。…...

mac常见问题(五) Mac 无法开机
在mac的使用过程中难免会碰到这样或者那样的问题,本期为您带来Mac 无法开机怎么进行操作。 1、按下 Mac 上的电源按钮。每台 Mac 电脑都有一个电源按钮,通常标有电源符号 。然后检查有没有通电迹象,例如: 发声,例如由风…...

WebSocket与SSE区别
一,websocket WebSocket是HTML5下一种新的协议(websocket协议本质上是一个基于tcp的协议) 它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的 Websocket是一个持久化的协议 websocket的原理 …...
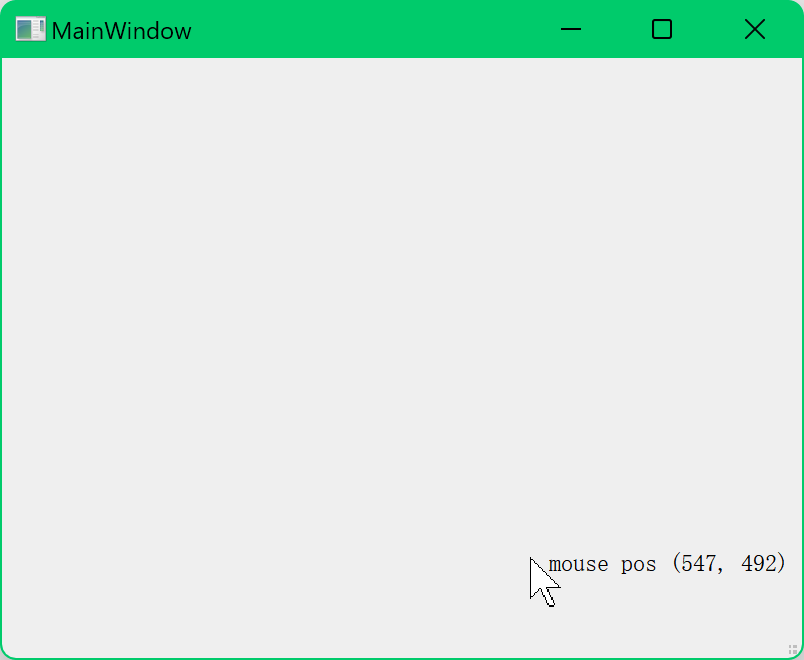
Qt鼠标点击事件处理:显示鼠标点击位置(完整示例)
Qt 入门实战教程(目录) 前驱文章: Qt Creator 创建 Qt 默认窗口程序(推荐) 什么是事件 事件是对各种应用程序需要知道的由应用程序内部或者外部产生的事情或者动作的通称。 事件(event)驱动…...

OpenCV:实现图像的负片
负片 负片是摄影中会经常接触到的一个词语,在最早的胶卷照片冲印中是指经曝光和显影加工后得到的影像。负片操作在很多图像处理软件中也叫反色,其明暗与原图像相反,其色彩则为原图像的补色。例如,颜色值A与颜色值B互为补色&#…...

HZOJ#237. 递归实现排列型枚举
题目描述 从 1−n这 n个整数排成一排并打乱次序,按字典序输出所有可能的选择方案。 输入 输入一个整数 n。(1≤n≤8) 输出 每行一组方案,每组方案中两个数之间用空格分隔。 注意每行最后一个数后没有空格。 样例…...

C++ PIMPL 编程技巧
C PIMPL 编程技巧 文章目录 C PIMPL 编程技巧什么是pimpl?pimpl优点举例实现 什么是pimpl? Pimpl (Pointer to Implementation) 是一种常见的 C 设计模式,用于隐藏类的实现细节,从而减少编译依赖和提高编译速度。它的基本思想是将…...

一个通用的EXCEL生成下载方法
Excel是一个Java开发中必须会用到的东西,之前博主也发过一篇关于使用Excel的文章,但是最近工作中,发现了一个更好的使用方法,所以,就对之前的博客进行总结,然后就有了这篇新的,万能通用的方法说…...

介绍 TensorFlow 的基本概念和使用场景。
TensorFlow(简称TF)是由Google开发的开源机器学习框架,它具有强大的数值计算和深度学习功能,广泛用于构建、训练和部署机器学习模型。以下是TensorFlow的基本概念和使用场景: 基本概念: 张量(T…...
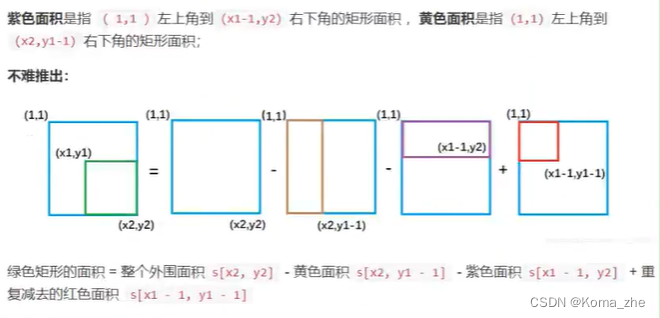
【力扣】304. 二维区域和检索 - 矩阵不可变 <二维前缀和>
目录 【力扣】304. 二维区域和检索 - 矩阵不可变二维前缀和理论初始化计算面积 题解 【力扣】304. 二维区域和检索 - 矩阵不可变 给定一个二维矩阵 matrix,以下类型的多个请求: 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为 (row1, …...
线上问诊:数仓开发(三)
系列文章目录 线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 线上问诊:数仓开发(二) 线上问诊:数仓开发(三) 文章目录 系列文章目录前言一、ADS1.交易主题1.交易综合统计2.各医院交易统计3.各性…...
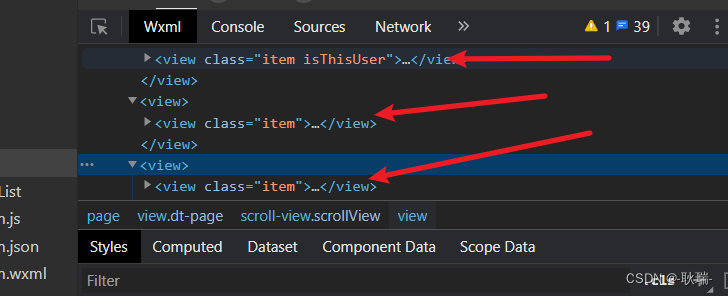
微信小程序 通过响应式数据控制元素class属性
我想大家照这个和我最初的目的一样 希望有和vue中v-bind:class一样方便的指令 但答案不太尽人意 这里 我们只能采用 三元运算符的形式 参考代码如下 <view class"item {{ userId item.userId ? isThisUser : }}"> </view>这里 我们判断 如果当前ite…...

linux并发服务器 —— linux网络编程(七)
网络结构模式 C/S结构 - 客户机/服务器;采用两层结构,服务器负责数据的管理,客户机负责完成与用户的交互;C/S结构中,服务器 - 后台服务,客户机 - 前台功能; 优点 1. 充分发挥客户端PC处理能力…...

Java后端开发面试题——企业场景篇
单点登录这块怎么实现的 单点登录的英文名叫做:Single Sign On(简称SSO),只需要登录一次,就可以访问所有信任的应用系统 JWT解决单点登录 用户访问其他系统,会在网关判断token是否有效 如果token无效则会返回401&am…...
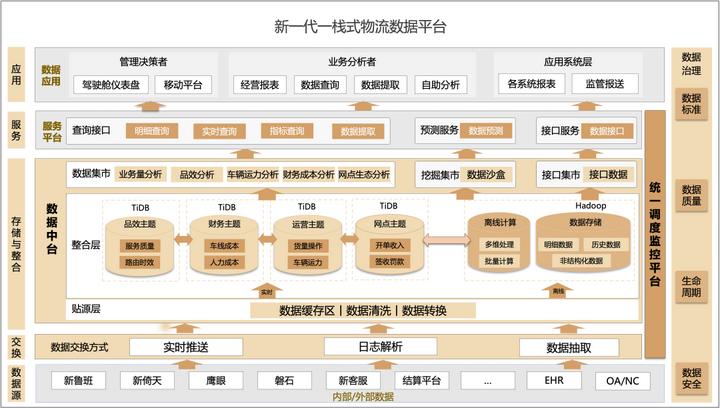
TiDB x 安能物流丨打造一栈式物流数据平台
作者:李家林 安能物流数据库团队负责人 本文以安能物流作为案例,探讨了在数字化转型中,企业如何利用 TiDB 分布式数据库来应对复杂的业务需求和挑战。 安能物流作为中国领先的综合型物流集团,需要应对大规模的业务流程ÿ…...

Java Map集合详解与实战
集合进阶(Map集合)一、Map集合1.1 Map概述体系各位同学,前面我们已经把单列集合学习完了,接下来我们要学习的是双列集合。首先我们还是先认识一下什么是双列集合。所谓双列集合,就是说集合中的元素是一对一对的。格式:…...

计算机专业生打 CTF 全指南:从新手小白到赛事拿分,附实战避坑手册_ctf比赛自己带电脑吗
作为计算机专业毕业的过来人,我始终觉得:CTF 比赛是大学生把课本知识落地成硬技能的最佳载体。 刚上大二时,我还是个只会敲基础代码、对 网络安全停留在课本概念的小白,靠着 3 次参赛经历,不仅吃透了操作系统、计算机…...

Frida+Fart实战:在ART Dex加载临界点精准dump二代壳内存Dex
1. 这不是“又一个脱壳教程”,而是对Android加固演进逻辑的现场解剖你打开一个市面上主流的金融类App,用adb shell pm list packages | grep bank随手一搜,发现它被某知名商业加固厂商打了“二代壳”——启动慢、内存占用高、关键so文件加密、…...

抖音直播数据采集:如何用Golang构建实时弹幕监控系统
抖音直播数据采集:如何用Golang构建实时弹幕监控系统 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作日益火爆的今天,数据驱动的运营决策变得…...

wangEditor公式插件kityformula的‘幽灵注册’与按钮刷新:两个容易被忽略的Vue组件级问题
wangEditor公式插件kityformula的‘幽灵注册’与按钮刷新:两个容易被忽略的Vue组件级问题 在Vue3项目中集成wangEditor富文本编辑器并引入kityformula公式插件时,开发者往往会遇到一些看似诡异的问题。这些问题表面上是功能异常,实则隐藏着对…...

第二章:达梦数据库基础操作入门——从零搭建与核心操作
想要熟练运用达梦数据库,基础操作是关键。本章将聚焦达梦数据库(以主流的DM8版本为例)的基础操作,包括环境准备、数据库安装、核心工具使用、基础SQL操作等,全程贴合实操场景,新手也能快速上手,…...
)
别再傻傻分不清L2和L3了!一张图看懂自动驾驶分级(附SAE/国标对照表)
自动驾驶分级全解析:从L0到L5的技术演进与商业应用 当特斯拉车主开启Autopilot功能在高速公路上行驶,或是蔚来汽车宣传其NOP领航辅助时,这些究竟属于什么级别的自动驾驶?为什么有些厂商称自己的系统为"L2.999"ÿ…...

OpenWrt opkg配置进阶:手把手教你设置代理、跳过证书检查,解决国内下载慢问题
OpenWrt opkg高效配置指南:突破网络限制的实战技巧 每次在OpenWrt上安装软件时,看着缓慢的下载进度条或者突如其来的连接错误,是不是感觉既熟悉又无奈?作为一款强大的路由器操作系统,OpenWrt的opkg包管理器本该是我们的…...

Python-json-logger集成指南:Django、Flask等框架中的终极使用教程
Python-json-logger集成指南:Django、Flask等框架中的终极使用教程 【免费下载链接】python-json-logger Json Formatter for the standard python logger 项目地址: https://gitcode.com/gh_mirrors/py/python-json-logger Python-json-logger是一个强大的J…...

CausalImpact最佳实践:避免因果推断中的7个常见陷阱
CausalImpact最佳实践:避免因果推断中的7个常见陷阱 【免费下载链接】CausalImpact An R package for causal inference in time series 项目地址: https://gitcode.com/gh_mirrors/ca/CausalImpact 在时间序列分析领域,因果推断是揭示变量间真实…...