GreenPlum的gpfdist使用与原理流程分析
一、简介
GreenPlum 的数据导入功能作为对数据源的一种扩充,数据导入的方式有:
- 1、insert 该方式通过 sql 语句,把数据一条一条插入至表中。这种方式,不仅读取数据慢(一条一条读取),且数据需要经过 master 节点后再分发给所有 segment,所以 master 制约着导入性能。
- 2、copy 该方式实现了数据的批量读取,但数据依然需要通过 master 节点,所以 master 制约着导入性能,无法实现并行、高效的数据加载。
- 3、gpfdist 该方式使用 gpfdist 协议,segment 与 数据源直连,数据读取后直接发送给每个 segment。这种方式,数据不再通过 master,真正实现了数据加载的并行、高效。
gpfdist 是 Greenplum 数据库并行文件分发程序。
它可以被外部表和 gpload 用来并行地将外部表文件提供给所有的 Greenplum 数据库 Segment。
它也可以被可写外部表使用,并行接受来自 Greenplum 数据库 Segment 的输出流,并将它们写出到文件中。
总的来说,可以并行读文件数据,通过 segment 将数据读取至 master 中, 可以并行写文件数据,通过 segment 将数据写入文件中。 gpfdist 本身是单进程单线程程序,所以如果需要实现服务端的并行,需要启动多个 gpfdist 服务。
二、架构部署

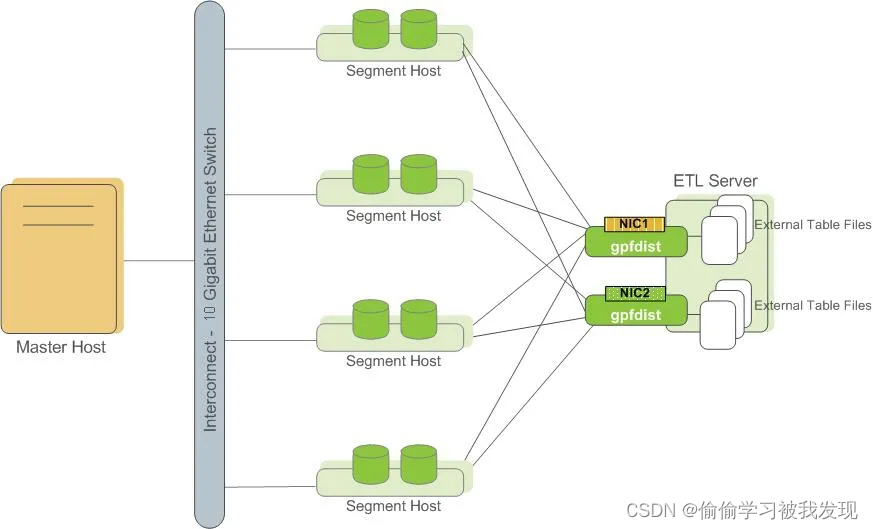
三、配置与使用
命令格式:
gpfdist [-d <directory>] [-p <http_port>] [-l <log_file>] [-t <timeout>]
[-S] [-w <time>] [-v | -V] [-m <max_length>] [--ssl <certificate_path>]gpfdist [-? | help] | --version
例如:gpfdist -p 9000
参数:
-d <directory> 可以指定工作目录,如果没指定,则为当前目录
-l <log_file> 指定 log 文件,如果没指定,则直接输出到屏幕中
-p <http_port> 指定服务端口,默认是 8080
-m <max_length> 指定最大一行数据的大小,单位是 byte,默认是 32768, 即 32K,可配范围是 32K ~ 256M
-S <use O_SYNC> 写入文件的时候,同步等待数据写入至存盘后再返回
-v 显示详细信息
-V 显示更详细信息,当使用这个 V 时,上面的 v 也会被显示出来
-s 不显示头信息 (这个在 --help 中没有显示,但代码里面是支持的,可以用)
-c 指定一个配置文件,用来执行数据转换的 (这个在 --help 中没有显示,但代码是支持的)
--ssl <certificate_path> 指定 ssl 加密
使用示例
示例中主要使用的是 gpfdist 协议,使用的文件格式主要是 csv。
1、创建只读外部表基本语法
只读外部表
CREATE [READABLE] EXTERNAL [TEMPORARY | TEMP] TABLE table_name ( column_name data_type [, ...] | LIKE other_table )LOCATION ('file://seghost[:port]/path/file' [, ...])| ('gpfdist://filehost[:port]/file_pattern[#transform=trans_name]'[, ...]| ('gpfdists://filehost[:port]/file_pattern[#transform=trans_name]'[, ...])| ('pxf://path-to-data?PROFILE=profile_name[&SERVER=server_name][&custom-option=value[...]]'))| ('s3://S3_endpoint[:port]/bucket_name/[S3_prefix] [region=S3-region] [config=config_file]')[ON MASTER]FORMAT 'TEXT' [( [HEADER][DELIMITER [AS] 'delimiter' | 'OFF'][NULL [AS] 'null string'][ESCAPE [AS] 'escape' | 'OFF'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][FILL MISSING FIELDS] )]| 'CSV'[( [HEADER][QUOTE [AS] 'quote'] [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][FORCE NOT NULL column [, ...]][ESCAPE [AS] 'escape'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][FILL MISSING FIELDS] )]| 'CUSTOM' (Formatter=<formatter_specifications>)[ ENCODING 'encoding' ][ [LOG ERRORS [PERSISTENTLY]] SEGMENT REJECT LIMIT count[ROWS | PERCENT] ]
1.1、 使用csv 文件创建只读外部表示例
只读外部表
指定了csv格式的时候,默认的 分隔符(DELIMITER)为 ‘,’ ,默认的引号值(QUOTE)为 ‘"’,默认的换行符(NEWLINE)为\n。
create external table ext (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv') format 'csv';insert into a select * from ext;create external table ext2 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9000/data2.csv') format 'csv';create external table ext6 (id int, name char(20)) location ('gpfdist://gp_init:9000/data*.csv') format 'csv';create external table ext7 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9001/data2.csv') format 'csv';
查看数据文件与外部表
数据文件的内容
[root@gp_init gpfdist]# cat data.csv
0, asdfghjkl;
1, asdfghjkl;
[root@gp_init gpfdist]# cat data2.csv
0, asdfghjkl;
1, asdfghjkl;
查询外部表
postgres=# select * from ext;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl;
(2 rows)postgres=# select * from ext2;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl; 0 | asdfghjkl; 1 | asdfghjkl;
(4 rows)postgres=# select * from ext6;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl; 0 | asdfghjkl; 1 | asdfghjkl;
(4 rows)postgres=# select * from ext7;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl; 0 | asdfghjkl; 1 | asdfghjkl;
(4 rows)
1.2、使用 pipe管道创建只读外部表示例
只读外部表
gpfdist 支持从管道中读取数据流。
创建一个管道
[root@gp_init gpfdist]# mkfifo gpfdist_pipe
往管道里填写数据
cat data.csv > gpfdist_pipe
创建外部表
create external table ext_pipe(id int, name varchar(30))
location ('gpfdist://gp_init:9000/gpfdist_pipe')
format 'csv';
查询外部表
postgres=# select * from ext_pipe ;id | name
----+-------------0 | asdfghjkl;1 | asdfghjkl;
2、创建可写外部表
2.1、使用csv 文件创建可写外部表示例
目前可写的外部表只支持 gpfdist 协议。
CREATE WRITABLE EXTERNAL [TEMPORARY | TEMP] TABLE table_name( column_name data_type [, ...] | LIKE other_table )LOCATION('gpfdist://outputhost[:port]/filename[#transform=trans_name]'[, ...])| ('gpfdists://outputhost[:port]/file_pattern[#transform=trans_name]'[, ...])FORMAT 'TEXT' [( [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][ESCAPE [AS] 'escape' | 'OFF'] )]| 'CSV'[([QUOTE [AS] 'quote'] [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][FORCE QUOTE column [, ...]] | * ][ESCAPE [AS] 'escape'] )]| 'CUSTOM' (Formatter=<formatter specifications>)[ ENCODING 'write_encoding' ][ DISTRIBUTED BY ({column [opclass]}, [ ... ] ) | DISTRIBUTED RANDOMLY ]
创建可写外部表
create writable external table extw (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv')format 'csv';create writable external table extw2 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9000/data2.csv') format 'csv';create writable external table extw3 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9001/data2.csv') format 'csv';
插入数据
postgres=# create table abc(id int, name char(20));
postgres=# insert INTO abc select * from ext;
postgres=# select count(*) from abc;count
--------100000
(1 row)-- 写入文件
-- 基本上是会把数据平局分给各个文件里。
postgres=# insert INTO extw select * from abc ;
INSERT 0 100000
[root@gp_init gpfdist]# wc -l data.csv
100000 data.csvpostgres=# insert INTO extw2 select * from abc ;
INSERT 0 100000
[root@gp_init gpfdist]# wc -l data.csv data2.csv 50171 data.csv49829 data2.csv100000 totalpostgres=# insert INTO extw3 select * from abc ;
INSERT 0 100000
[root@gp_init gpfdist]# wc -l data.csv data2.csv 50135 data.csv49865 data2.csv100000 total
2.2、使用 pipe管道创建可写外部表示例
创建可写外部表
create writable external table extw4 (id int, name char(20)) location ('gpfdist://gp_init:9000/gpfdist_pipe') format 'csv';
-- 执行写入操作
postgres=# insert INTO extw4 select * from abc;
[root@gp_init opt]# bash read.sh gpfdist_pipe
100000
主要函数代码解析
1、main
- gpfdist_init :所有的处理都是在 gpfdist_init 函数中。
- gpfdist_run:只有一个 event_dispatch。
2、gpfdist_init
- 命令行输入参数解析:parse_command_line。
- 注册信号处理signal_register:对信号的处理。捕获 SIGTERM 信号,设置最高优先级,注册 process_term_signal 回调函数,在回调函数中,关闭所有 socket 后,退出。
- http服务配置http_setup:
- 先根据配置的端口,获取地址信息,然后对地址进行端口绑定。这里获取的地址信息包含两个:ipv4 地址 和 ipv6 地址。gpfdist 优先使用ipv6进行绑定,因为IPv6的监听套接字能够同时监听v4客户端和v6客户端。
- 遍历所有可用的套接字,设置监听事件:EV_READ | EV_PERSIST(持久属性),设置优先级,并绑定回调函数:do_accept。可用套接字个数保存在 gcb.listen_sock_count 中,可用的 socket 保存在 gcb.listen_socks 数组中。
- do_accept:对请求进行 accept,记录了自己 accept 产生的 socket(r->sock),client 的 port(r->port),并对socket设置一些属性,例如:keepalive、reuseaeddr 等。
- 并调用 setup_read 设置read事件。
- setup_read设置可读事件的回调函数:do_read_request,并判断该请求中是否带 timeout 参数:
- 如果没带 timeout 参数,则是普通请求,不需要设置 timeout。
- 如果带 timeout 参数,则是超时事件,需要重新设置超时参数。
- setup_read设置可读事件的回调函数:do_read_request,并判断该请求中是否带 timeout 参数:
- 看门狗初始化:watchdog_thread。
3、do_read_request
如果是超时事件,则直接发送http_end,后续会关闭连接。
读取socket,如果是返回0,发送 http_end。
- gnet_parse_request :解析出请求的方法,以及后面跟的参数
- request_validate :检测请求参数是否正确:必须是GET或POST,且使用协议必须是 HTTP/1.xx。
- percent_encoding_to_char :检测path中的字符是否存在 %XX 的格式,如果有,则转化为 char 类型的字符。
如果 path 为 “/gpfdist/status”,则直接返回 send_gpfdist_status。(该请求作为 debug 使用) - request_set_path: 将 path 相对路径转换为绝对路径。
- request_parse_gp_headers:解析 header 中的信息,比如 xid / cid / sn / segcount / csvopt 等。
- request_set_transform : 执行 transform 转换。
- session_attach:根据文件名和 TID (由 xid/cid/sn 生成) 创建一个会话,对文件的处理都在会话中处理。根据 tid 和 path 组成 key,从 hash 表中获取该 session,如果没有则进行创建。如果 session 中没获取到 fstream,则直接返回错误。
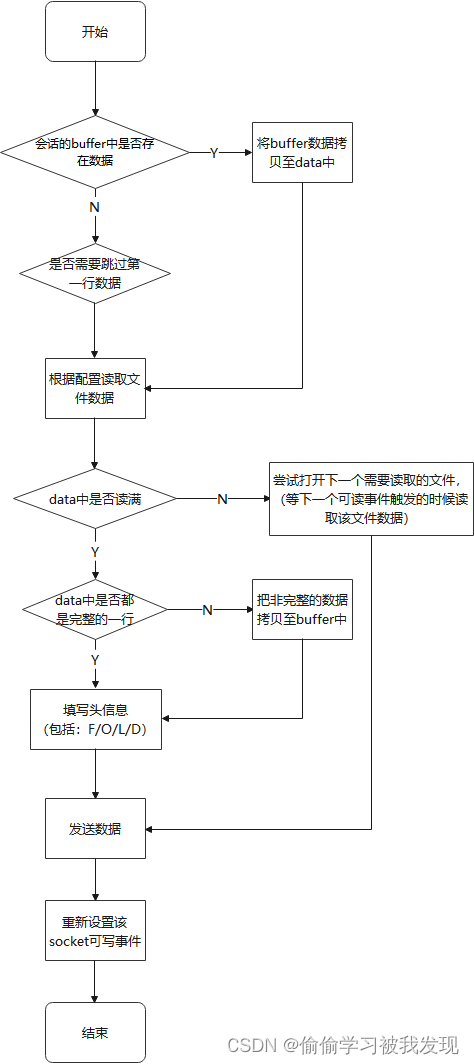
如果是 GET,则通过 handle_get_request 函数增加写事件监听(被监听的 fd 是在 do_accept 函数中 accept的 fd),如果是 POST,则调用 handle_post_request 函数。 - do_write:
- 1、如果上次读取的数据,都已经发送完成了(通过 block_t 里面的 bot == top 来判断),则再通过 session_get_block 读取一个 block。
- 2、如果 gp_proto 的协议号为 1,则调用 local_send:发送头部数据,即 blockhdr_t 中的 hbyte
- 3、调用 local_send:再发送真正的数据,即 block_t 中的 data
- 4、通过 setup_write,再次添加当前 fd 的写事件
数据读取示意图
学习记录,原文
相关文章:
GreenPlum的gpfdist使用与原理流程分析
一、简介 GreenPlum 的数据导入功能作为对数据源的一种扩充,数据导入的方式有: 1、insert 该方式通过 sql 语句,把数据一条一条插入至表中。这种方式,不仅读取数据慢(一条一条读取),且数据需要…...
Spring AOP与静态代理/动态代理
文章目录 一、代理模式静态代理动态代理代理模式与AOP 二、Spring AOPSping AOP用来处理什么场景jdk 动态代理cglib 动态代理面试题:讲讲Spring AOP的原理与执行流程 总结 一、代理模式 代理模式是一种结构型设计模式,它允许对象提供替代品或占位符&…...
【LeetCode算法系列题解】第51~55题
CONTENTS LeetCode 51. N 皇后(困难)LeetCode 52. N 皇后 II(困难)LeetCode 53. 最大子序和(中等)LeetCode 54. 螺旋矩阵(中等)LeetCode 55. 跳跃游戏(中等) …...
驱动开发错误汇编
本博文将会不定期更新。以便记录我的驱动开发生涯中的一些点点滴滴的技术细节和琐事。 1. link阶段找不到导出函数 比如"LNK2019 无法解析的外部符号 _FltCreateCommunicationPort32"。 出现这种情况的原因是,驱动的编译环境忽略了所有的默认库&#x…...
知识图谱项目实践
目录 步骤 SpaCy Textacy——Text Analysis for Cybersecurity Networkx Dateparser 导入库 写出页面的名称 编辑 自然语言处理 词性标注 可能标记的完整列表 依存句法分析(Dependency Parsing,DEP) 可能的标签完整列表 实例理…...

stable diffusion实践操作-提示词-人物属性
系列文章目录 stable diffusion实践操作-提示词 文章目录 系列文章目录前言一、提示词汇总1.1 人物属性11.2 人物属性2 前言 本文主要收纳总结了提示词-人物属性。 一、提示词汇总 1.1 人物属性1 角色类型人物身材胸部头发-发型头发-发色[女仆][霊烏路空][大腿][乳房][呆毛…...

RabbitMQ的安装和配置
将RabbitMQ文件夹传到linux根目录 开启管理界面及配置...

WebRTC 日志
WebRTC 日志 flyfish WebRTC支持的日志等级 // // The meanings of the levels are: // LS_VERBOSE: This level is for data which we do not want to appear in the // normal debug log, but should appear in diagnostic logs. // LS_INFO: Chatty level used in de…...
【python爬虫】16.爬虫知识点总结复习
文章目录 前言爬虫总复习工具解析与提取(一)解析与提取(二)更厉害的请求存储更多的爬虫更强大的爬虫——框架给爬虫加上翅膀 爬虫进阶路线指引解析与提取 存储数据分析与可视化更多的爬虫更强大的爬虫——框架项目训练 反爬虫应对…...
Windows系统中Apache Http服务器简单使用
1 简介 Apache HTTP服务器是一个开源的、跨平台的Web服务器软件。它由Apache软件基金会开发和维护。Apache HTTP服务器可以在多种操作系统上运行,如Windows、Linux、Unix等,并且支持多种编程语言和技术,如PHP、Perl、Python、Java等。…...
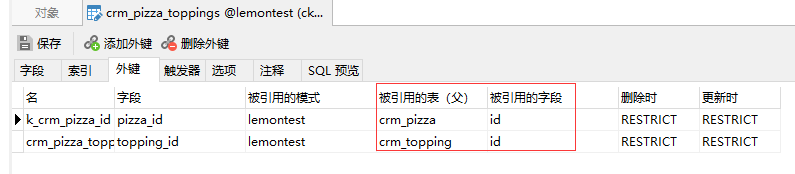
Django ORM 框架中的表关系,你真的弄懂了吗?
Django ORM 框架中的表关系 为了说清楚问题,我们设计一个 crm 系统,包含五张表: 1.tb_student 学生表 2.tb_student_detail 学生详情表 3.tb_salesman 课程顾问表 4.tb_course 课程表 5.tb_entry 报名表 表关系和字段如下图:…...

第五课:C++实现加密PDF文档解密
请注意,未经授权的加密PDF文件解密是非法的,本文仅为学术和研究目的提供参考。 打开加密的PDF文件并获取密钥 在C++中,可以使用pdfium库打开加密的PDF文件。使用pdfium库中的FPDF_LoadCustomDocument函数可以打开具有自定义访问权限的加密文件。该函数接受一个IFX_FileRead*…...

罗马数字转整数
罗马数字转整数 题目: 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M …...
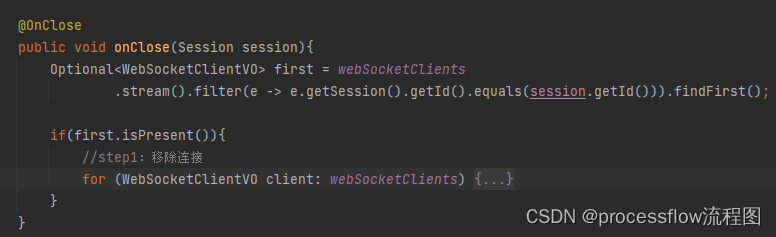
processflow流程图多人协作预热
前言 在线上办公如火如荼的今天,多人协作功能是每个应用绕不开的门槛。processflow在线流程图(前身基于drawio二次开发)沉寂两年之久,经过长时间设计开发,调整,最终完成了多人协作的核心模块设计。废话不多…...
)
PCL点云处理之快速计算多个点到同一直线的距离(二百零五)
PCL点云处理之快速计算多个点到同一直线的距离(二百零五) 一、算法简介二、具体实现1.代码2.结果一、算法简介 点到直线的距离计算,是一种常用的算法,在点云处理中,经常遇到需要计算多个点云到同一条直线的距离计算需求,此时若是逐点计算将耗费大量的时间,熟悉点到直线…...

xxl-job 任务调度搭建及简单使用
xxl-job是开源架构,可以通过它实现调度中心和执行器。 git地址和 官网中进行了详细的技术说明。 xxl-job支持单机部署和集群式部署,在集群式部署中又可以实现调度中心集群式部署和执行器集群式部署。本文主要针对调度中心和执行器分离单机部署方式进…...
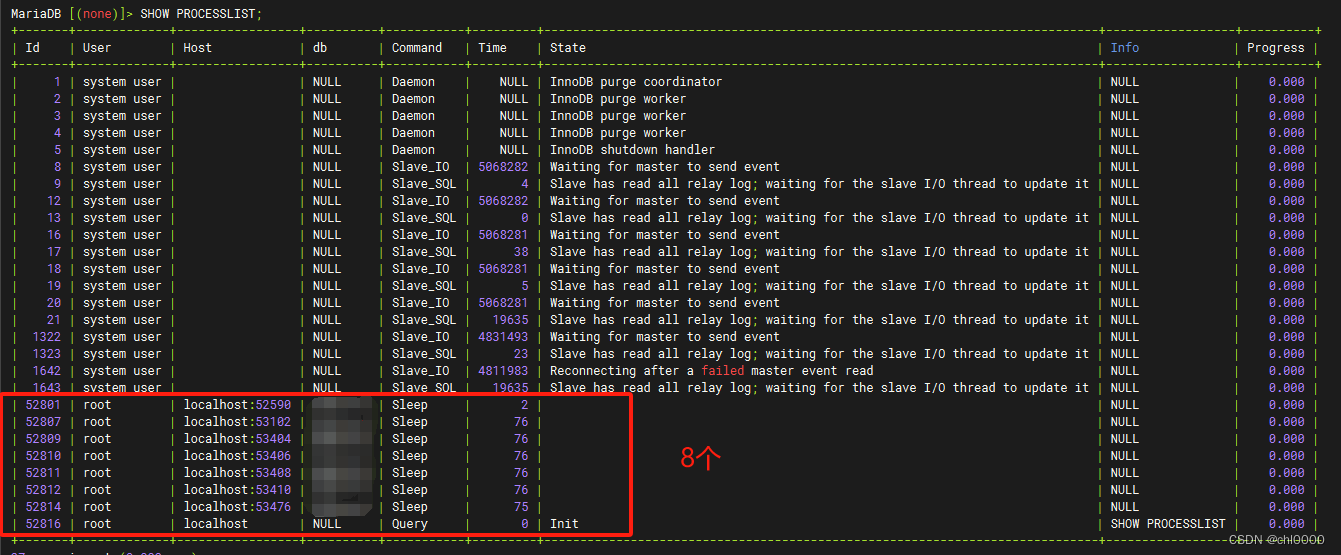
mysql数据库使用技巧整理
查看当前数据库已建立的client连接 > SHOW VARIABLES LIKE max_connections; -- 查看数据库允许的最大连接数,不是实时正在使用的连接数 > SHOW STATUS LIKE Threads_connected; -- 查看当前数据库client的连接数 > SHOW PROCESSLIST; -- 查看具体的连接...

车规微控制器的ECC机制及EMU外设
车规微控制器的ECC机制及EMU外设 文章目录 车规微控制器的ECC机制及EMU外设引言ECC的基本原理ECC RAM的访问方式ECC RAM的初始化SRAM ECC错误注入及EMU外设Flash ECC校验参考文献 引言 ECC是微控制器系统中,用于保障信息安全的常用机制,主要是避免存储设…...

Less的强大变量用法
less中的变量应用十分强大,可以灵活的应用到各种不同需求的场景。 一,属性值变量 声明:sass声明变量是用$符号,而less声明变量是用符号 作用域:也区分为全局变量和局部变量,如果引用的变量有定义局部变量&…...

【相机标定】opencv python 标定相机内参时不计算 k3 畸变参数
文章目录 1. 背景2. 完整的 opencv python 标定相机内参过程3. 选择是否计算畸变参数 k3 1. 背景 畸变参数 k3 通常用于描述径向畸变的更高阶效应,即在需要高精度的应用中可以用到,一般的应用中 k1, k2 足矣。 常见的应用中, orbslam3 中是否…...

构建企业级智能设计转换桥梁:Unity Figma Bridge高性能自动化集成方案深度解析
构建企业级智能设计转换桥梁:Unity Figma Bridge高性能自动化集成方案深度解析 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBrid…...

不用示波器也能调:在Vivado/Quartus里用时序约束搞定RGMII接口的建立保持时间
不依赖示波器的RGMII时序优化:FPGA工具链实战指南 当千兆以太网接口出现数据丢包或误码时,多数工程师的第一反应是抓起示波器测量信号完整性。但在实际项目周期中,硬件调试设备可能无法随时调用,而PCB设计又已成定局。此时&#x…...

BGP状态机详解:从邻居建立到故障排查的完整指南
1. 项目概述:从“拒绝一切”到“稳定对话”的BGP邻居建立之旅如果你在网络运维或者数据中心工作的岗位上待过一阵子,肯定对BGP(边界网关协议)又爱又恨。爱的是它作为互联网“大管家”的稳定和强大,恨的是它一旦出问题&…...

Claude Code cli 以及vscode版本的各种命令参考手册
Claude Code 各种命令参考手册版本说明: 截至 2026 年 4 月,Claude Code 官方文档共收录超过 70 条内置命令与绑定技能。其中约一半为内置命令(行为由 CLI 代码实现),另一半为绑定技能(通过 Prompt 机制实现…...

终极指南:如何在Windows电脑上免模拟器安装安卓APK文件
终极指南:如何在Windows电脑上免模拟器安装安卓APK文件 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是Windows用户的游戏规则改变者࿰…...

cann/cann-bench: Softmax算子API描述
Softmax 算子 API 描述 【免费下载链接】cann-bench 评测AI在处理CANN领域代码任务的能力,涵盖算子生成、算子优化等领域,支撑模型选型、训练效果评估,统一量化评估标准,识别Agent能力短板,构建CANN领域评测平台&#…...

CANN/hccl参数面建链阶段故障诊断
参数面建链阶段 【免费下载链接】hccl 集合通信库(Huawei Collective Communication Library,简称HCCL)是基于昇腾AI处理器的高性能集合通信库,为计算集群提供高性能、高可靠的通信方案 项目地址: https://gitcode.com/cann/hcc…...

解密网易云音乐NCM文件:3分钟掌握ncmdump核心技术与实战应用
解密网易云音乐NCM文件:3分钟掌握ncmdump核心技术与实战应用 【免费下载链接】ncmdump 转换网易云音乐 ncm 到 mp3 / flac. Convert Netease Cloud Music ncm files to mp3/flac files. 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdump ncmdump作为C实…...

燃油车的“催命符”还是环保的“里程碑”?2026年Euro 7标准下的汽车变局
如果你正打算换车,或者对汽车行业的未来走向充满好奇,那么“Euro 7”(欧7排放标准)绝对是你绕不开的一个关键词。这项被业内称为“史上最严”的排放法规,将于2026年11月29日正式对新车型实施强制认证。它不仅给内燃机戴…...

极域电子教室破解指南:3步重获电脑控制权的终极方案
极域电子教室破解指南:3步重获电脑控制权的终极方案 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在机房上课时,被极域电子教室的全屏广播困住无…...