神经网络训练时只对指定的边更新参数
在神经网络中,通常采用反向传播算法来计算网络中各个参数的梯度,从而进行参数更新。在反向传播过程中,所有的参数都会被更新。因此,如果想要只更新指定的边,需要采用特殊的方法。
一种可能的方法是使用掩码(masking)技术,将不需要更新的参数的梯度设置为0。在这种方法中,可以通过创建一个掩码张量来指定哪些参数需要更新,哪些参数不需要更新。将不需要更新的参数对应的掩码设置为0,将需要更新的参数对应的掩码设置为1,然后将掩码张量与梯度张量相乘,就可以得到只包含需要更新的参数的梯度张量。最后,将这个梯度张量用于参数更新即可。
另一种方法是使用稀疏矩阵(sparse matrix)技术。在这种方法中,将网络中的所有参数看作一个大的稀疏矩阵,其中只有需要更新的参数对应的元素有非零值。可以使用专门的稀疏矩阵运算库来进行矩阵乘法和梯度计算,从而只更新需要更新的参数。
这两种方法都需要在网络的实现上进行一定的改动,但可以实现只对指定的边进行参数更新的目的。
以下是一个使用掩码(masking)技术的例子,演示如何只对指定的边进行参数更新:
import torch# 创建一个大小为 (2, 2) 的参数张量
weights = torch.randn(2, 2, requires_grad=True)# 创建一个大小与参数张量相同的掩码张量
mask = torch.tensor([[1, 0], [1, 1]])# 对参数进行一次前向传播和反向传播
input = torch.randn(2)
output = torch.matmul(weights, input)
loss = output.sum()
loss.backward()# 将不需要更新的参数的梯度张量设置为0
weights.grad *= mask# 使用得到的梯度张量更新参数
learning_rate = 0.1
weights.data -= learning_rate * weights.grad# 打印更新后的参数张量
print(weights)在这个例子中,我们创建了一个大小为 (2, 2) 的参数张量 weights,同时创建了一个大小与参数张量相同的掩码张量 mask,其中掩码值为0的位置对应的参数不会被更新。在进行一次前向传播和反向传播后,我们将不需要更新的参数的梯度张量设置为0,然后使用得到的梯度张量更新参数。最后,我们打印更新后的参数张量。
注意,这个例子只演示了如何使用掩码技术对指定的边进行参数更新,实际上掩码技术的应用还需要考虑一些细节,例如如何处理掩码对梯度张量的影响,如何更新多个参数张量等等。实际应用中需要根据具体情况进行调整。
以下是一个使用稀疏矩阵(sparse matrix)技术的例子,演示如何只对指定的边进行参数更新:
import torch# 创建一个大小为 (2, 2) 的稀疏矩阵
indices = torch.tensor([[0, 0], [1, 0], [1, 1]])
values = torch.randn(3)
weights = torch.sparse_coo_tensor(indices.t(), values, (2, 2), requires_grad=True)# 对参数进行一次前向传播和反向传播
input = torch.randn(2)
output = torch.sparse.mm(weights, input)
loss = output.sum()
loss.backward()# 使用得到的梯度张量更新参数
learning_rate = 0.1
weights.data -= learning_rate * weights.grad.to_dense()# 打印更新后的参数张量
print(weights.to_dense())import torch# 定义网络参数和稀疏矩阵
W1 = torch.randn(2, 2, requires_grad=True)
W2 = torch.randn(1, 2, requires_grad=True)
indices = torch.tensor([[0, 0], [1, 1], [1, 0]])
values = torch.randn(3)
mask = torch.sparse_coo_tensor(indices.t(), values, (2, 2), requires_grad=True)# 定义输入和目标输出
X = torch.tensor([[0.5, 0.2]])
target_output = torch.tensor([[0.7]])# 前向传播
z1 = torch.matmul(X, W1.t())
h1 = torch.sigmoid(z1)
z2 = torch.matmul(h1, W2.t())
output = torch.sigmoid(z2)# 计算损失函数并进行反向传播
loss = torch.nn.functional.binary_cross_entropy(output, target_output)
loss.backward()# 对需要更新的参数进行梯度更新
learning_rate = 0.1
with torch.no_grad():W1.grad *= mask.to_dense()W1 -= learning_rate * W1.gradW2 -= learning_rate * W2.grad# 打印更新后的 W1
print(W1)在这个例子中,我们定义了一个两层神经网络,其中第一层权重参数为 W1,第二层权重参数为 W2。我们还创建了一个稀疏矩阵 mask,用于指定第一层权重参数中哪些边需要更新。然后我们进行了一次前向传播和反向传播,并使用 mask 对需要更新的参数进行梯度更新,最后打印更新后的 W1。
需要注意的是,在稀疏矩阵的梯度更新中,需要将稀疏矩阵转换为稠密矩阵进行更新,因为 PyTorch 目前不支持对稀疏矩阵进行原位更新。因此,在更新 W1 时,我们使用了 mask.to_dense() 将稀疏矩阵转换为稠密矩阵,然后再与 W1.grad 相乘。
神经网络对指定的边进行l1正则化
import torch# 定义网络参数和稀疏矩阵
W1 = torch.randn(2, 2, requires_grad=True)
W2 = torch.randn(1, 2, requires_grad=True)
indices = torch.tensor([[0, 0], [1, 1], [1, 0]])
values = torch.randn(3)
mask = torch.sparse_coo_tensor(indices.t(), values, (2, 2), requires_grad=False)# 定义输入和目标输出
X = torch.tensor([[0.5, 0.2]])
target_output = torch.tensor([[0.7]])# 定义 L1 正则化系数和学习率
lambda_l1 = 0.1
learning_rate = 0.1# 计算正则化项并添加到损失函数中
reg_loss = lambda_l1 * torch.sum(torch.abs(W1 * mask.to_dense()))
loss = torch.nn.functional.binary_cross_entropy(torch.sigmoid(torch.matmul(torch.sigmoid(torch.matmul(X, W1.t())), W2.t())), target_output)
loss += reg_loss# 进行反向传播并对需要更新的参数进行梯度更新
loss.backward()
with torch.no_grad():W1.grad *= mask.to_dense()W1 -= learning_rate * (W1.grad + lambda_l1 * torch.sign(W1) * mask.to_dense())W2 -= learning_rate * W2.grad# 打印更新后的 W1
print(W1)对神经网络的边(即权重)进行 L1 正则化的方法通常是在损失函数中添加一个 L1 正则项,其目的是鼓励网络学习稀疏权重,从而减少过拟合。
对于只对指定的边进行 L1 正则化的问题,可以使用稀疏矩阵技术。具体来说,可以使用与前面提到的相同的稀疏矩阵 mask,其中非零元素表示需要正则化的权重。在计算 L1 正则化项时,我们只需将非零元素的绝对值相加即可。最终,将这个正则化项添加到损失函数中,以鼓励模型学习稀疏的权重。
以下是一个使用稀疏矩阵技术对神经网络的指定边进行 L1 正则化的示例:
import torch# 定义网络参数和稀疏矩阵
W1 = torch.randn(2, 2, requires_grad=True)
W2 = torch.randn(1, 2, requires_grad=True)
indices = torch.tensor([[0, 0], [1, 1], [1, 0]])
values = torch.randn(3)
mask = torch.sparse_coo_tensor(indices.t(), values, (2, 2), requires_grad=False)# 定义输入和目标输出
X = torch.tensor([[0.5, 0.2]])
target_output = torch.tensor([[0.7]])# 定义 L1 正则化的权重系数
l1_weight = 0.01# 前向传播
z1 = torch.matmul(X, W1.t())
h1 = torch.sigmoid(z1)
z2 = torch.matmul(h1, W2.t())
output = torch.sigmoid(z2)# 计算损失函数
loss = torch.nn.functional.binary_cross_entropy(output, target_output)
l1_loss = l1_weight * torch.sum(torch.abs(mask * W1))
total_loss = loss + l1_loss# 进行反向传播
total_loss.backward()# 对所有参数进行梯度更新
learning_rate = 0.1
with torch.no_grad():W1 -= learning_rate * W1.gradW2 -= learning_rate * W2.grad# 打印更新后的 W1
print(W1)在这个例子中,我们将稀疏矩阵 mask 中的非零元素与 W1 相乘,得到需要正则化的权重矩阵。然后,我们计算 L1 正则化项,并将其乘以一个权重系数 l1_weight。最后,将 L1 正则化项和交叉熵损失项相加,得到总的损失函数 total_loss。最终,我们对所有参数进行梯度更新,而不仅仅是对需要正则化的权重进行更新。
相关文章:

神经网络训练时只对指定的边更新参数
在神经网络中,通常采用反向传播算法来计算网络中各个参数的梯度,从而进行参数更新。在反向传播过程中,所有的参数都会被更新。因此,如果想要只更新指定的边,需要采用特殊的方法。 一种可能的方法是使用掩码࿰…...

Python列表list操作-遍历、查找、增加、删除、修改、排序
在使用列表的时候需要用到很多方法,例如遍历列表、查找元素、增加元素、删除元素、改变元素、插入元素、列表排序、逆序列表等操作。 1、遍历列表 遍历列表通常采用for循环的方式以及for循环和enumerate()函数搭配的方式去实现。 1ÿ…...

Python开发-学生管理系统
文章目录1、需求分析2、系统设计3、系统开发必备4、主函数设计5、 学生信息维护模块设计6、 查询/统计模块设计7、排序模块设计8、 项目打包1、需求分析 学生管理系统应具备的功能: ●添加学生及成绩信息 ●将学生信息保存到文件中 ●修改和删除学生信息 ●查询学生…...

大数据处理 - Trie树/数据库/倒排索引
Trie树Trie树的介绍和实现请参考 树 - 前缀树(Trie)适用范围: 数据量大,重复多,但是数据种类小可以放入内存基本原理及要点: 实现方式,节点孩子的表示方式扩展: 压缩实现。一些适用场景:寻找热门查询: 查询串的重复度比较高&#…...
jjava企业级开发-01
一、Spring容器演示 采用Spring配置文件管理Bean 1、创建Maven项目 修改项目的Maven配置 2、添加Spring依赖 在Maven仓库里查找Spring框架(https://mvnrepository.com) 同上添加其他依赖 <?xml version"1.0" encoding"UTF-8…...

「事务一致性」事务afterCommit
在事务还没有执行完消息就已经发出去了, 导致后续的一些数据或逻辑上的问题产生。场景如下:异步-记录日志:当事务提交后,再记录日志。发送mq消息:只有业务数据都存入表后,再发mq消息。方案1. 利用TransactionSynchroni…...
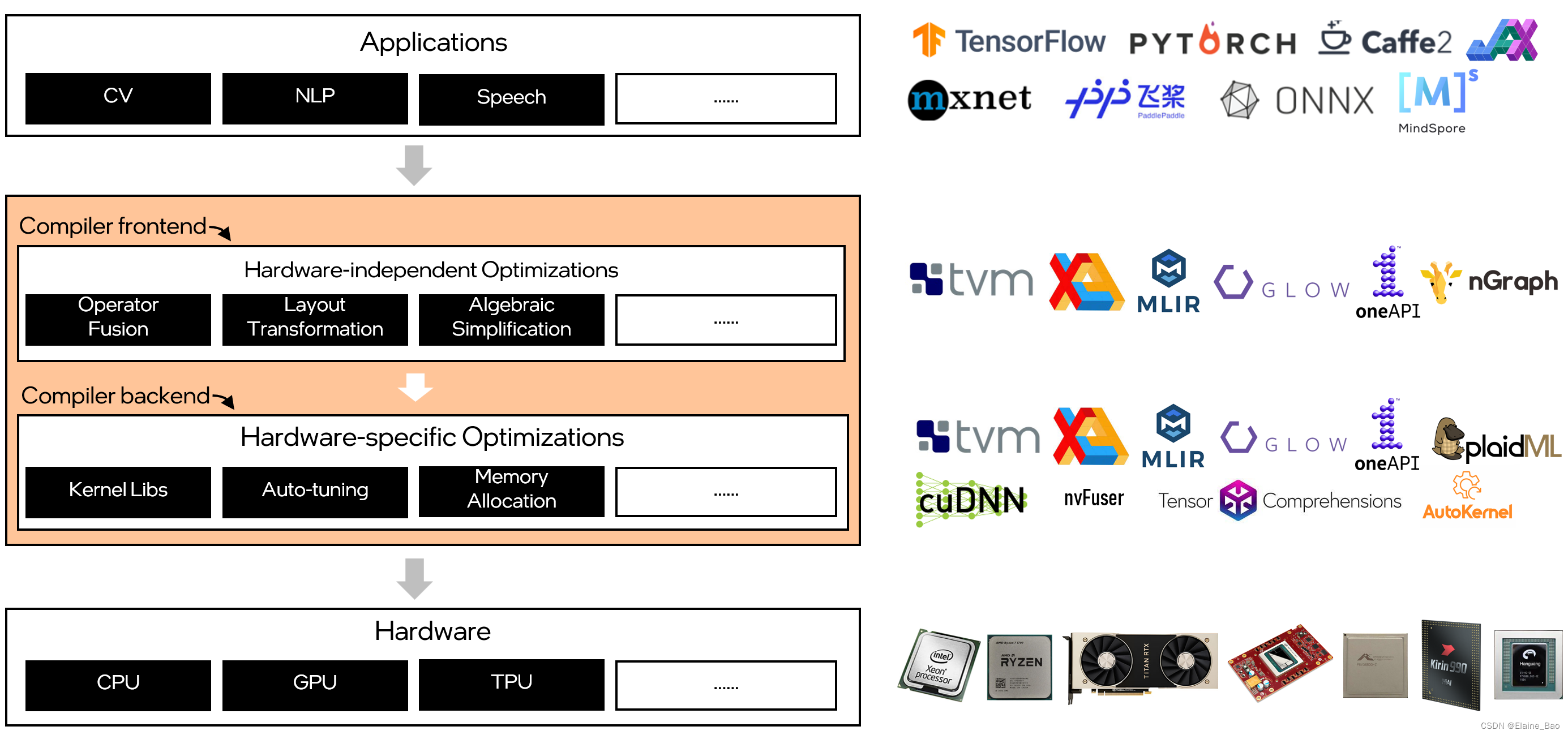
【深度学习编译器系列】2. 深度学习编译器的通用设计架构
在【深度学习编译器系列】1. 为什么需要深度学习编译器?中我们了解到了为什么需要深度学习编译器,和什么是深度学习编译器,接下来我们把深度学习编译器这个小黑盒打开,看看里面有什么东西。 1. 深度学习编译器的通用设计架构 与…...
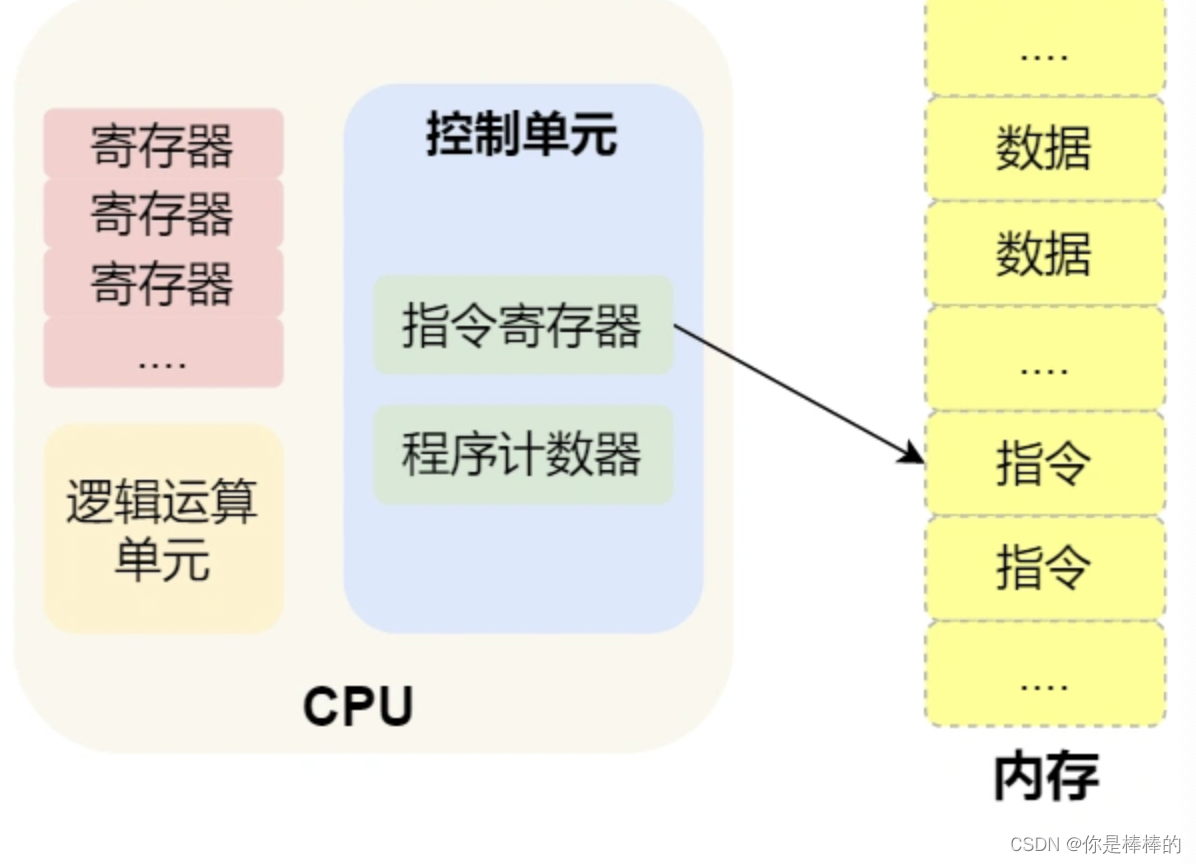
图解操作系统
硬件结构 CPU是如何执行程序的? 图灵机的工作方式 图灵机的基本思想:用机器来模拟人们用纸笔进行数学运算的过程,还定义了由计算机的那些部分组成,程序又是如何执行的。 图灵机的基本组成如下: 有一条「纸带」&am…...

【发版或上线项目保姆级心得】
第一步:先在正式环境创建数据库/新增表格或者字段 在数据库表中增加字段/表格,不会报错。 但是切记不要过早数据库字段/表格或者删除字段/表格 第二步:修改配置文件 先将正式环境需要的配置给写好,包括但不仅限于数据库配置、…...

Python数据分析-pandas库入门
pandas 库概述pandas 提供了快速便捷处理结构化数据的大量数据结构和函数。自从2010年出现以来,它助使 Python 成为强大而高效的数据分析环境。pandas使用最多的数据结构对象是 DataFrame,它是一个面向列(column-oriented)的二维表…...
MacBook Pro 恢复出厂设置
目录1.恢复出厂设置1.1 按Command-R 键1.2 macOS 实用工具1.3 从 macOS 恢复功能的实用工具窗口中选择“磁盘工具”,然后点按“继续”1.4 在“磁盘工具”边栏中选择您的设备或宗卷。1.5 点按“抹掉”按钮或标签页1.6 抹掉OS X HD - 数据 完成1.7 抹掉 OS X HD1.8 查…...

googletest 笔记
什么是一个好的测试 1 测试应该是独立的和可重复的。调试一个由于其他测试而成功或 失败的测试是一件痛苦的事情。googletest 通过在不同的对象上 运行测试来隔离测试。当测试失败时,googletest 允许您单独运 行它以快速调试。 2 测试应该很好地“组织”,…...

MySQL修改密码的几种方式?
第一种方式: 最简单的方法就是借助第三方工具Navicat for MySQL来修改。方法如下: 1、登录mysql到指定库,如:登录到test库。 2、然后点击上方"用户"按钮。 3、选择要更改的用户名,然后点击上方的"编辑用…...

关于画一个句号--基于2022年终总结的反思与分享
没有平台鼓风造势,今年各大平台没有涌现出一批总结,非常清爽 正如同人发明了抽屉,将杂物进行整理、丢弃、收纳,才能对空间进行更合理地使用。我们也需要对知识、过往经历进行整理、丢弃、收纳,才能对大脑进行更合理地…...

学习Flask之三、模板
学习Flask之三、模板 书写易于维护的应用的关键是书写整洁和良构的代码。到目前为止你所见的例子过于简单而不能体现这点。把两个目的完全独立的Flask view 函数当作一个来写,会产生问题。view函数的一个显然的任务是对请求作出响应,如前面的例子所示。对…...

2023-02-20干活小计:
所以我今天的活开始了: In this paper, the authors target the problem of Multimodal Name Entity Recognition(MNER) as an improvement on NER(text only) The paper proposes a multimodal fusion based on a heterogeneous graph of texts and images to mak…...
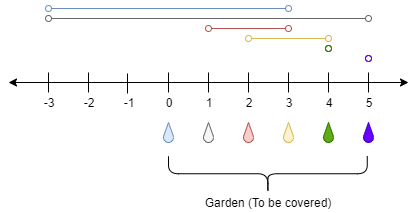
LeetCode_动态规划_困难_1326.灌溉花园的最少水龙头数目
目录1.题目2.思路3.代码实现(Java)1.题目 在 x 轴上有一个一维的花园。花园长度为 n,从点 0 开始,到点 n 结束。 花园里总共有 n 1 个水龙头,分别位于 [0, 1, …, n] 。 给你一个整数 n 和一个长度为 n 1 的整数数…...
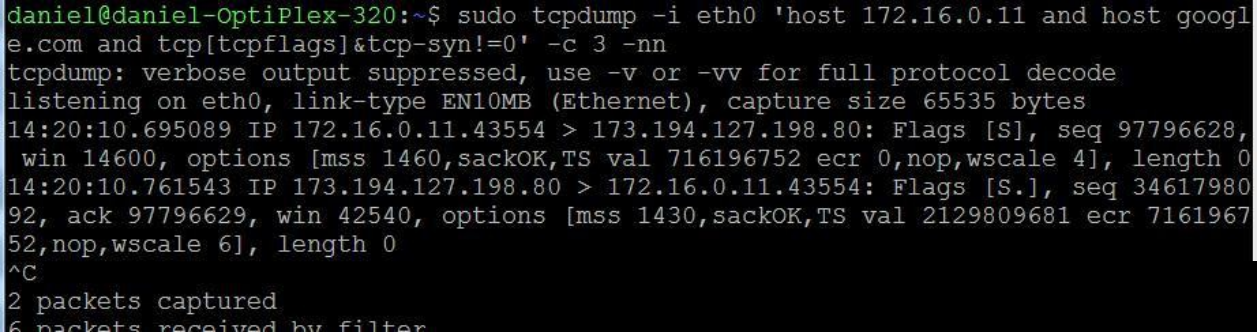
mac tcpdump学习
学习原因 工作上遇到了重启wifi后无法发出mDNS packet的情况,琢磨一下用tcpdump用的命令如下 sudo tcpdump -n -k -s 0 -i en0 -w VENDOR-DUT-INTERFACE.pcapng是在测airplay BCT认证时,官方文档的解决方法。对tcpdump很不了解,现汇总如下的学…...

【跟我一起读《视觉惯性SLAM理论与源码解析》】第二章 编程及编译工具
23.2.21终于拿到六哥的新书 感觉很是不错,打算近期写一写心得之类的 废话不多说,直接开啃 PS:我的建议是阅读完十四讲后再来看这本书,效果应该会很不错。 因为第一章都是介绍之类的我觉得没什么整理的必要,所以直接来…...

广东望京卡牌科技有限公司,2023年团建活动圆满举行
玉兔初临,春天相随,抖擞精神,好运连连。春天是一个万物复苏的季节,来自广东的望京卡牌科技有限公司,也迎来了新年第一次团建活动。在“乘风破浪、追逐梦想”的口号声中,2023望京卡牌目标启动会团结活动正式…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...