16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors 示例: Apache Hive
- 1、支持的Hive版本
- 2、依赖项
- 1)、使用 Flink 提供的 Hive jar
- 2)、用户定义的依赖项
- 3)、移动 planner jar 包
- 3、Maven 依赖
- 4、连接到Hive
- 5、DDL&DML
本文介绍了Apache Hive连接器的使用,以具体的示例演示了通过java和flink sql cli创建catalog。
本文依赖环境是hadoop、zookeeper、hive、flink环境好用,本文内容以flink1.17版本进行介绍的,具体示例是在1.13版本中运行的(因为hadoop集群环境是基于jdk8的,flink1.17版本需要jdk11)。
更多的内容详见后续关于hive的介绍。
一、Table & SQL Connectors 示例: Apache Hive
Apache Hive 已经成为了数据仓库生态系统中的核心。 它不仅仅是一个用于大数据分析和ETL场景的SQL引擎,同样它也是一个数据管理平台,可用于发现,定义,和演化数据。
Flink 与 Hive 的集成包含两个层面。
一是利用了 Hive 的 MetaStore 作为持久化的 Catalog,用户可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。 例如,用户可以使用HiveCatalog将其 Kafka 表或 Elasticsearch 表存储在 Hive Metastore 中,并后续在 SQL 查询中重新使用它们。
二是利用 Flink 来读写 Hive 的表。
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以"开箱即用"的访问其已有的 Hive 数仓。 您不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
1、支持的Hive版本
Flink 支持以下的 Hive 版本。
- 2.3
2.3.0
2.3.1
2.3.2
2.3.3
2.3.4
2.3.5
2.3.6
2.3.7
2.3.8
2.3.9 - 3.1
3.1.0
3.1.1
3.1.2
3.1.3
某些功能是否可用取决于您使用的 Hive 版本,这些限制不是由 Flink 所引起的:
- Hive 内置函数在使用 Hive-2.3.0 及更高版本时支持。
- 列约束,也就是 PRIMARY KEY 和 NOT NULL,在使用 Hive-3.1.0 及更高版本时支持。
- 更改表的统计信息,在使用 Hive-2.3.0 及更高版本时支持。
- DATE列统计信息,在使用 Hive-2.3.0 及更高版时支持。
2、依赖项
要与 Hive 集成,您需要在 Flink 下的/lib/目录中添加一些额外的依赖包, 以便通过 Table API 或 SQL Client 与 Hive 进行交互。 或者,您可以将这些依赖项放在专用文件夹中,并分别使用 Table API 程序或 SQL Client 的-C或-l选项将它们添加到 classpath 中。
Apache Hive 是基于 Hadoop 之上构建的, 首先您需要 Hadoop 的依赖,请参考 Providing Hadoop classes:
export HADOOP_CLASSPATH=`hadoop classpath`
有两种添加 Hive 依赖项的方法。第一种是使用 Flink 提供的 Hive Jar包。您可以根据使用的 Metastore 的版本来选择对应的 Hive jar。第二个方式是分别添加每个所需的 jar 包。如果您使用的 Hive 版本尚未在此处列出,则第二种方法会更适合。
注意:建议您优先使用 Flink 提供的 Hive jar 包。仅在 Flink 提供的 Hive jar 不满足您的需求时,再考虑使用分开添加 jar 包的方式。
1)、使用 Flink 提供的 Hive jar
下表列出了所有可用的 Hive jar。您可以选择一个并放在 Flink 发行版的/lib/ 目录中。

2)、用户定义的依赖项
您可以在下方找到不同Hive主版本所需要的依赖项。
- Hive 2.3.4
/flink-1.17.1/lib// Flink's Hive connector.Contains flink-hadoop-compatibility and flink-orc jarsflink-connector-hive_2.12-1.17.1.jar// Hive dependencieshive-exec-2.3.4.jar// add antlr-runtime if you need to use hive dialectantlr-runtime-3.5.2.jar
- Hive 3.1.0
/flink-1.17.1/lib// Flink's Hive connectorflink-connector-hive_2.12-1.17.1.jar// Hive dependencieshive-exec-3.1.0.jarlibfb303-0.9.3.jar // libfb303 is not packed into hive-exec in some versions, need to add it separately// add antlr-runtime if you need to use hive dialectantlr-runtime-3.5.2.jar
3)、移动 planner jar 包
把 FLINK_HOME/opt 下的 jar 包 flink-table-planner_2.12-1.17.1.jar 移动到 FLINK_HOME/lib 下,并且将 FLINK_HOME/lib 下的 jar 包 flink-table-planner-loader-1.17.1.jar 移出去。 具体原因请参见 FLINK-25128。你可以使用如下命令来完成移动 planner jar 包的工作:
mv $FLINK_HOME/opt/flink-table-planner_2.12-1.17.1.jar $FLINK_HOME/lib/flink-table-planner_2.12-1.17.1.jar
mv $FLINK_HOME/lib/flink-table-planner-loader-1.17.1.jar $FLINK_HOME/opt/flink-table-planner-loader-1.17.1.jar
只有当要使用 Hive 语法 或者 HiveServer2 endpoint, 你才需要做上述的 jar 包移动。 但是在集成 Hive 的时候,推荐进行上述的操作。
3、Maven 依赖
如果您在构建自己的应用程序,则需要在 mvn 文件中添加以下依赖项。 您应该在运行时添加以上的这些依赖项,而不要在已生成的 jar 文件中去包含它们。
<!-- Flink Dependency -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.17.1</version><scope>provided</scope>
</dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.12</artifactId><version>1.17.1</version><scope>provided</scope>
</dependency><!-- Hive Dependency -->
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>${hive.version}</version><scope>provided</scope>
</dependency>
4、连接到Hive
通过 TableEnvironment 或者 YAML 配置,使用 Catalog 接口 和 HiveCatalog连接到现有的 Hive 集群。
以下是如何连接到 Hive 的示例:
- java
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);String name = "myhive";
String defaultDatabase = "mydatabase";
String hiveConfDir = "/opt/hive-conf";HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);// set the HiveCatalog as the current catalog of the session
tableEnv.useCatalog("myhive");----------------------示例----------------------------
import java.util.List;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;/*** @author alanchan**/
public class TestHiveCatalogDemo {/*** @param args* @throws DatabaseNotExistException * @throws CatalogException */public static void main(String[] args) throws CatalogException, DatabaseNotExistException {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);String name = "alan_hive";// testhive 数据库名称String defaultDatabase = "testhive";String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);tenv.registerCatalog("alan_hive", hiveCatalog);// 使用注册的catalogtenv.useCatalog("alan_hive");List<String> tables = hiveCatalog.listTables(defaultDatabase); for (String table : tables) {System.out.println("Database:testhive tables:" + table);}}}
- sql
CREATE CATALOG myhive WITH ('type' = 'hive','default-database' = 'mydatabase','hive-conf-dir' = '/opt/hive-conf'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;------------------具体示例如下----------------------------
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
+-----------------+
1 row in setFlink SQL> CREATE CATALOG alan_hivecatalog WITH (
> 'type' = 'hive',
> 'default-database' = 'testhive',
> 'hive-conf-dir' = '/usr/local/bigdata/apache-hive-3.1.2-bin/conf'
> );
[INFO] Execute statement succeed.Flink SQL> show catalogs;
+------------------+
| catalog name |
+------------------+
| alan_hivecatalog |
| default_catalog |
+------------------+
2 rows in setFlink SQL> use alan_hivecatalog;
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.catalog.exceptions.CatalogException: A database with name [alan_hivecatalog] does not exist in the catalog: [default_catalog].Flink SQL> use catalog alan_hivecatalog;
[INFO] Execute statement succeed.Flink SQL> show tables;
+-----------------------------------+
| table name |
+-----------------------------------+
| alan_hivecatalog_hivedb_testtable |
| apachelog |
| col2row1 |
| col2row2 |
| cookie_info |
| dual |
| dw_zipper |
| emp |
| employee |
| employee_address |
| employee_connection |
| ods_zipper_update |
| row2col1 |
| row2col2 |
| singer |
| singer2 |
| student |
| student_dept |
| student_from_insert |
| student_hdfs |
| student_hdfs_p |
| student_info |
| student_local |
| student_partition |
| t_all_hero_part_msck |
| t_usa_covid19 |
| t_usa_covid19_p |
| tab1 |
| tb_dept01 |
| tb_dept_bucket |
| tb_emp |
| tb_emp01 |
| tb_emp_bucket |
| tb_json_test1 |
| tb_json_test2 |
| tb_login |
| tb_login_tmp |
| tb_money |
| tb_money_mtn |
| tb_url |
| the_nba_championship |
| tmp_1 |
| tmp_zipper |
| user_dept |
| user_dept_sex |
| users |
| users_bucket_sort |
| website_pv_info |
| website_url_info |
+-----------------------------------+
49 rows in set- ymal
execution:...current-catalog: alan_hivecatalog # set the HiveCatalog as the current catalog of the sessioncurrent-database: testhivecatalogs:- name: alan_hivecatalog type: hivehive-conf-dir: /usr/local/bigdata/apache-hive-3.1.2-bin/conf
下表列出了通过 YAML 文件或 DDL 定义 HiveCatalog 时所支持的参数。
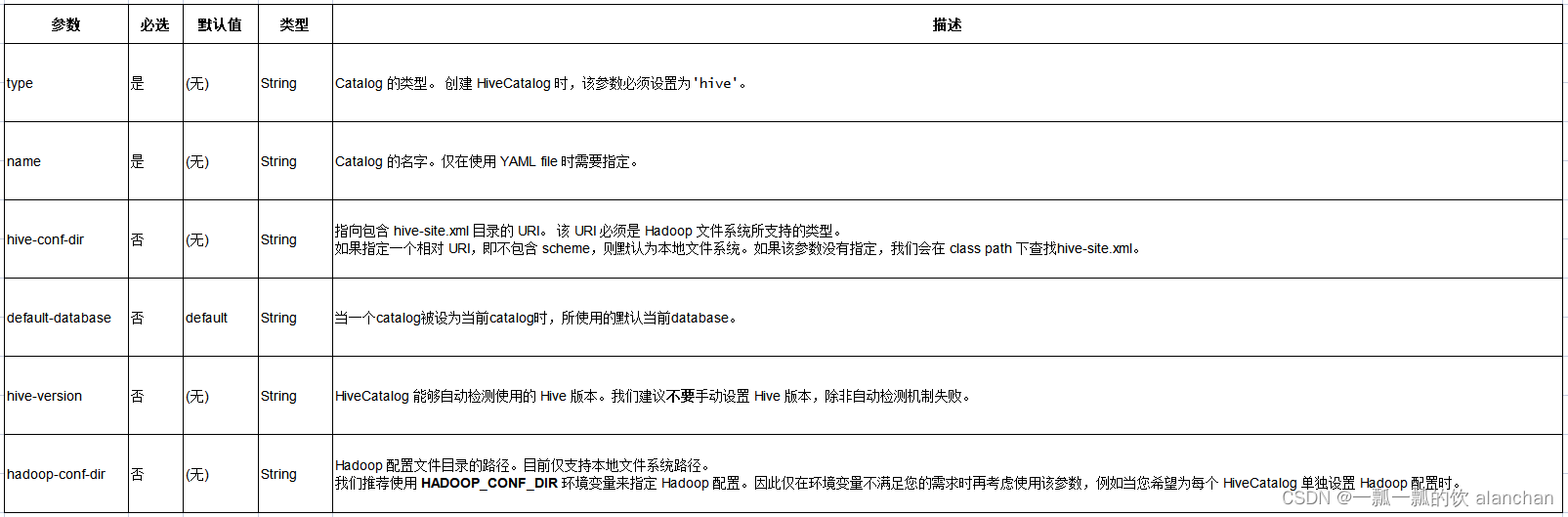
5、DDL&DML
在 Flink 中执行 DDL 操作 Hive 的表、视图、分区、函数等元数据时,参考:33、Flink之hive
Flink 支持 DML 写入 Hive 表,请参考:33、Flink之hive
以上,介绍了Apache Hive连接器的使用,以具体的示例演示了通过java和flink sql cli创建catalog。
相关文章:
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
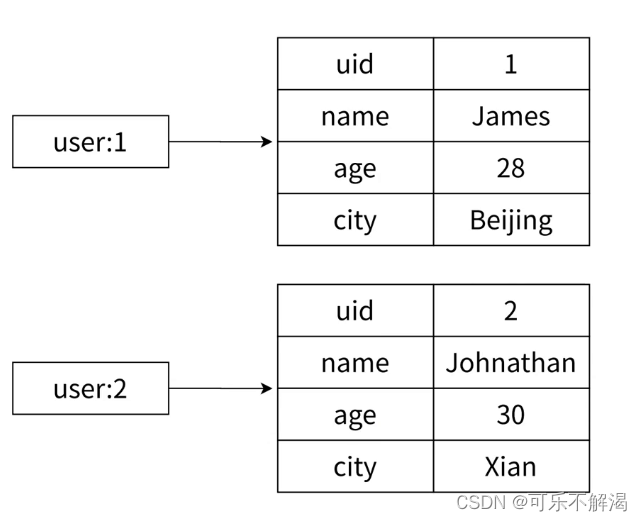
6.Redis-hash
hash 哈希类型中的映射关系通常称为field-value,⽤于区分 Redis 整体的键值对(key-value),注意这⾥的value是指field对应的值,不是键(key)对应的值,请注意 value 在不同上下⽂的作⽤…...
)
点云从入门到精通技术详解100篇-多时相机载激光雷达人工林点云匹配及生长监测(续)
目录 多时相机载激光雷达人工林点云匹配及变化监测 3.1 技术路线 3.2 数据准备 3.3 方法...

【Vue3 知识第七讲】reactive、shallowReactive、toRef、toRefs 等系列方法应用与对比
文章目录 一、reactive()二、readonly()三、shallowReactive()四、shallowReadonly()五、isReactive() 和 isReadonly()六、toRef()七、toRefs()八、toRaw()九、ref、toRef、toRefs 异同点 一、reactive() reactive() 函数用于返回一个对象的响应式代理。与 ref() 函数定义响应…...

Docker 摸门级简易手册
Docker 摸门级简易手册 文章目录 Docker 摸门级简易手册使用 Docker 构建 Java 项目镜像Docker 安装Install on MacInstall on WindowsInstall on Linux Dockerfile 说明FROMLABELENVWORKDIRCOPYADDRUNCMDEXPOSEENTRYPOINTVOLUMEUSER 使用 Docker 构建 Java 项目镜像 假设有个…...
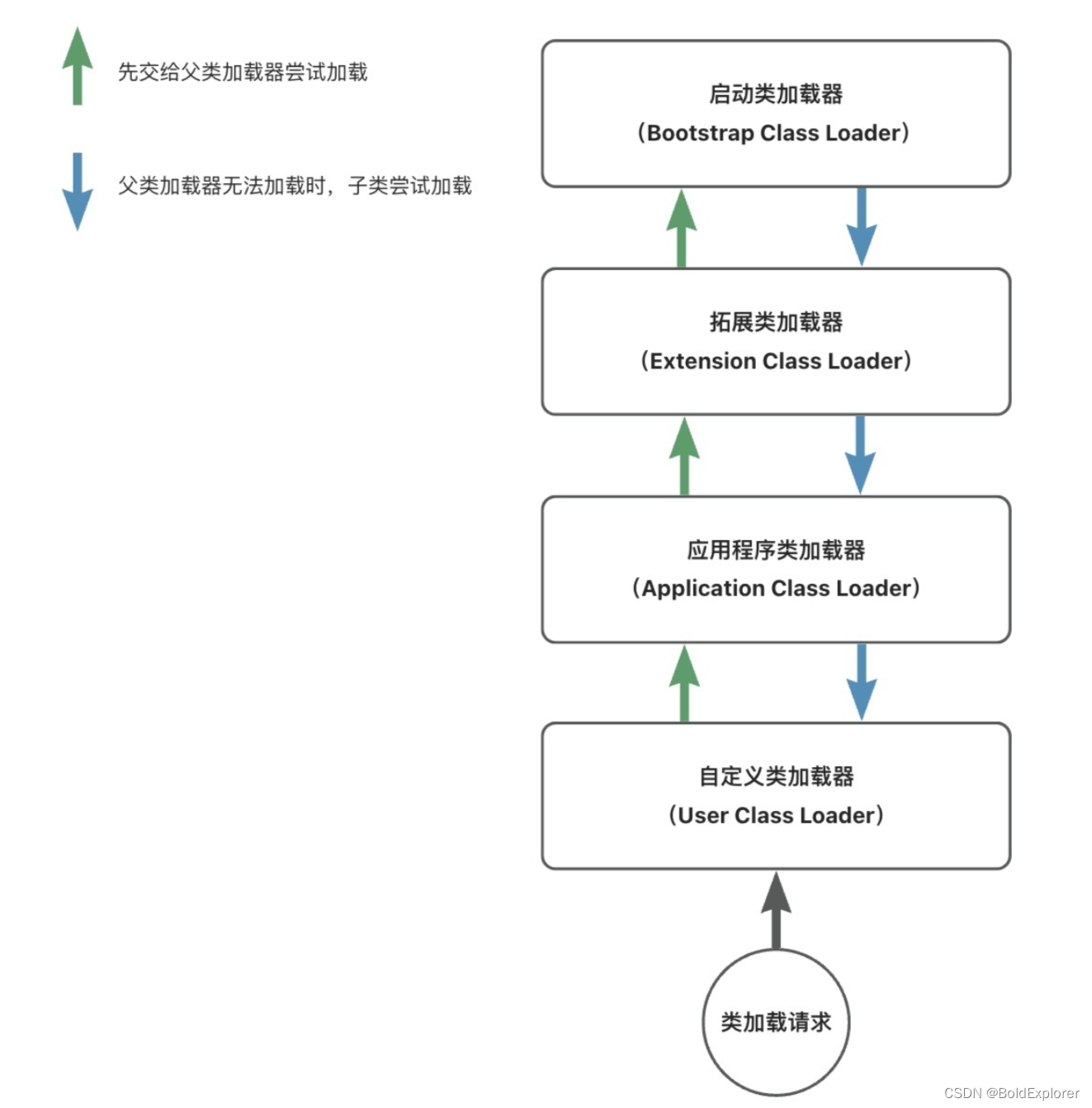
Java类加载机制
简介 在Java的世界里,每一个类或者接口,在经历编译器后,都会生成一个个.class文件。 类加载机制指的是将这些.class文件中的二进制数据读入到内存中,并对数据进行校验,解析和初始化。最终,每一个类都会在…...

vue 自定义指令简单记录
自定义指令例子 // src/main.js import { createApp } from vue; import App from ./App.vue;const app = createApp(App);// 全局自定义指令 app.directive(color-directive, {mounted(el, binding) {// 当指令绑定到元素上时触发// el 是绑定的元素// binding 包含了指令的信…...

算法通关村-----快速排序的原理和实现
快速排序介绍 快速排序是一种经典高效的排序方法,是分治策略在排序上的具体体现。将一个大的待排序列分割成若干个小的有序序列,最终将各个小的有序序列合并成一个大的有序序列。 快速排序的实现原理 选择一个基准值,将小于基准值的元素放…...
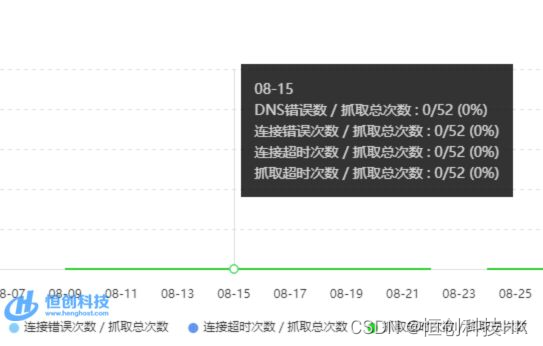
百度抓取香港服务器抓取超时是什么情况?
网络延迟导致抓取超时 网络延迟是指从发送请求到接收响应之间的时间延迟。如果网络延迟过高,服务器可能无法及时响应请求,导致超时。在香港服务器上抓取数据时,如果网络延迟过高,可能会出现抓取超时的情况。 服务器负载过高可能…...
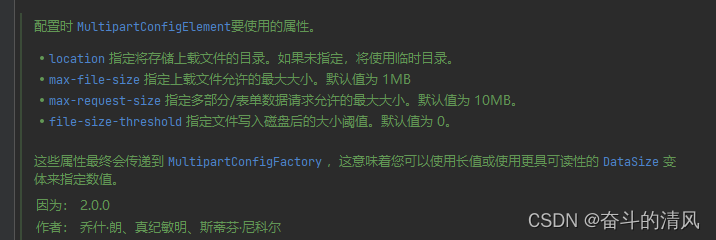
Springboot上传文件
上传文件示例代码: ApiOperation("上传文件") PostMapping(value "/uploadFile", consumes MediaType.MULTIPART_FORM_DATA_VALUE) public ApiResult<String> uploadFile(RequestPart("file") MultipartFile file) { //调用七…...

kafka教程
kafka教程 Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统,其主要特点为: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能高吞吐率。即使在非常…...

JVM的故事—— 内存分配策略
内存分配策略 文章目录 内存分配策略一、对象优先在Eden分配二、大对象直接进入老年代三、长期存活的对象将进入老年代四、动态对象年龄判定五、空间分配担保 一、对象优先在Eden分配 堆内存有新生代和老年代,新生代中有一个Eden区和一个Survivor区(from space或者…...

21.CSS的动态圆形进度条
效果 源码 <!doctype html> <html><head><meta charset="utf-8"><title>Animated Circular Progress | CSS Only</title><link rel="stylesheet" href="style.css"></head><body><di…...
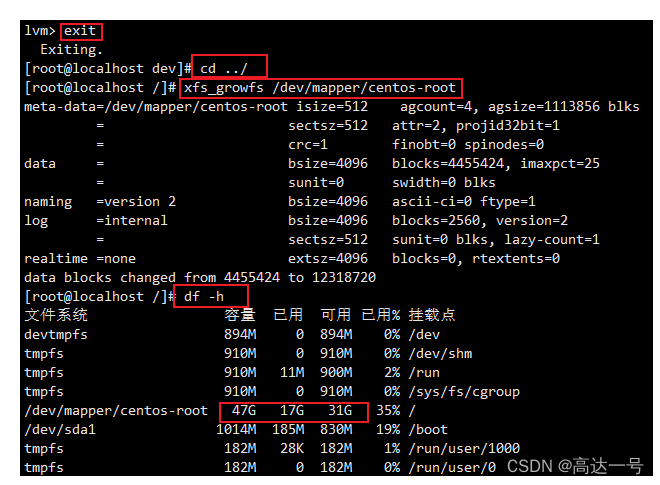
Linux_VMware_虚拟机磁盘扩容
来源文章 :VMware教学-虚拟机扩容篇_vmware虚拟机扩容_系统免驱动的博客-CSDN博客 由于项目逐步的完善,需要搭建的中间件,软件越来越多,导致以前虚拟机配置20G的内存不够用了,又不想重新创建新的虚拟机,退…...

中欧财富:分布式数据库的应用历程和 TiDB 7.1 新特性探索
原文来源: https://tidb.net/blog/ccbaeda2 作者:张政俊, 中欧财富数据库负责人 导读 中欧财富是中欧基金控股的销售子公司,旗下 APP 实现业内基金品种全覆盖,提供基金交易、大数据选基、智慧定投、理财师咨询等…...

树莓 LUMA-OLED.EXAMPLE使用
详细介绍在文件目录下的README.rst中 第一步 $ sudo usermod -a -G i2c,spi,gpio pi //好像没什么用 $ sudo apt install python3-dev python3-pip python3-numpy libfreetype6-dev libjpeg-dev build-essential //安装依赖包,树莓派中好像已经有了 $ sudo a…...
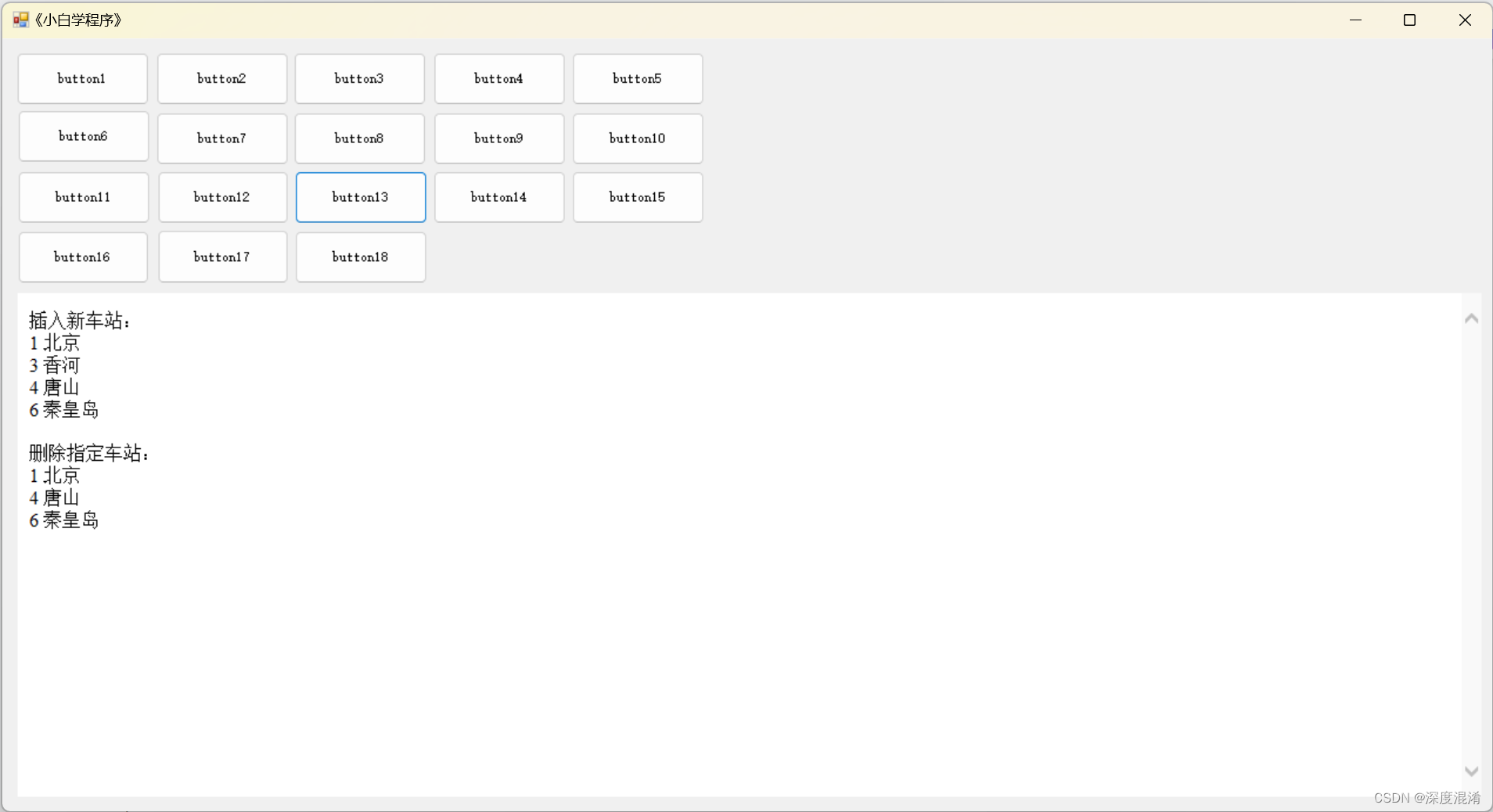
C#,《小白学程序》第十一课:双向链表(Linked-List)其二,链表的插入与删除的方法(函数)与代码
1 文本格式 /// <summary> /// 改进的车站信息类 class /// 增加了 链表 需要的两个属性 Last Next /// </summary> public class StationAdvanced { /// <summary> /// 编号 /// </summary> public int Id { get; set; } 0; ///…...
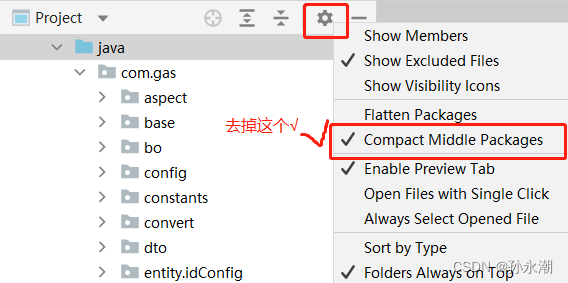
java IDEA文件路径分层级
如下图这样 在设置里找到Compact Middle Packages,去掉勾选就行了...

Spring AOP+Redis实现接口访问限制
目录 一、需求二、实现思路三、代码实现3.1 导入依赖3.2 配置redis3.3 自定义注解3.4 定义切面类3.5 自定义异常类3.6 全局异常处理器 一、需求 在我们程序中,有时候需要对一些接口做访问控制,使程序更稳定,最常用的一种是通过ip限制&#x…...

互联网后端技术大全!
互联网后端技术大全! 一. 系统开发 高内聚/低耦合 高内聚 高内聚指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一责任原则。模块的内聚反映模块内部联系的紧密程度。 低耦合 模块之间联系越紧密,其…...

Perplexity新闻资讯搜索终极对比:VS Google News、Bing News、Feedly——基于3000+查询样本的准确率/时效性/溯源完整性三维压测报告
更多请点击: https://kaifayun.com 第一章:Perplexity新闻资讯搜索终极对比:VS Google News、Bing News、Feedly——基于3000查询样本的准确率/时效性/溯源完整性三维压测报告 在为期12周的基准测试中,我们构建了覆盖科技、金融、…...

接口自动化测试框架搭建:基于Python+Requests+Pytest的实战教程
在软件测试领域,接口自动化测试是保障系统稳定性、提升测试效率的关键手段。随着敏捷开发和DevOps理念的普及,自动化测试的重要性愈发凸显。Python凭借其简洁的语法、丰富的库生态,成为接口自动化测试的首选语言;Requests库让HTTP…...

探索Artisan:用开源软件解码咖啡烘焙的数据科学
探索Artisan:用开源软件解码咖啡烘焙的数据科学 【免费下载链接】artisan artisan: the worlds most trusted roasting software 项目地址: https://gitcode.com/gh_mirrors/ar/artisan 在咖啡烘焙的世界里,每一次烘焙都是一次精确的化学反应。从…...

黑苹果配置复杂化挑战:OCAT跨平台管理工具的智能化解决方案
黑苹果配置复杂化挑战:OCAT跨平台管理工具的智能化解决方案 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 面对日益复杂…...
)
手把手教你用STM32F103驱动TLC7528双路DAC(附完整代码与避坑指南)
手把手教你用STM32F103驱动TLC7528双路DAC(附完整代码与避坑指南) 在嵌入式开发中,数字模拟转换器(DAC)是实现数字信号到模拟信号转换的关键组件。TLC7528作为一款经典的双路8位DAC芯片,以其高性价比和简单…...

2026生鲜零售收银软件推荐:四大主流方案深度对比
开一家生鲜店,最让人头疼的往往不是进货渠道或选址,而是每天高峰期那台“卡住”的收银机。想象一下,周末傍晚顾客排成长龙,称重员手忙脚乱地输入代码,屏幕转圈加载,后面的顾客开始不耐烦地催促,…...
)
为什么你的Perplexity薪资查询总返回403?3类Token权限陷阱+2种合法绕行路径(含Postman配置模板)
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity薪资查询总返回403?3类Token权限陷阱2种合法绕行路径(含Postman配置模板) 当你调用 Perplexity 提供的薪资数据 API(如 /v1/salari…...

GaussDB GDS 搭建完全指南:从安装到启动,一文搞定数据迁移服务
在进行 GaussDB 跨库数据迁移时,GDS(Gauss Data Service) 是实现外表迁移的核心组件。本文将手把手带你完成 GDS 的下载、安装、配置与启动,确保数据迁移通道畅通无阻。 📎 关联阅读:GaussDB GDS 外表迁移实…...

OpenClaw 2.7.5 Windows 一键部署教程|零配置开箱即用
前言 本地 AI 智能体技术持续迭代,私有化部署、数据安全可控、低门槛快速落地,已成为用户选型的核心考量。开源轻量化 AI 智能体 OpenClaw 2.7.5 版本完成全面优化升级,在环境适配性、服务稳定性与模型集成能力上均有显著提升,原…...

盘点6款优质客户销售管理系统:全业务打通到垂直场景适配
前言在数字化转型的深水区,企业对于管理工具的需求已从单一的工具辅助转向全链路的业务协同。面对市场上纷繁复杂的SaaS产品,如何基于“客户信息管理、销售机会管理、表单流程、数据统计、移动端端支持、自动化、权限安全、系统集成”八大核心维度进行精…...