【python爬虫】15.Scrapy框架实战(热门职位爬取)
文章目录
- 前言
- 明确目标
- 分析过程
- 企业排行榜的公司信息
- 公司详情页面的招聘信息
- 代码实现
- 创建项目
- 定义item
- 创建和编写爬虫文件
- 存储文件
- 修改设置
- 代码实操
- 总结
前言
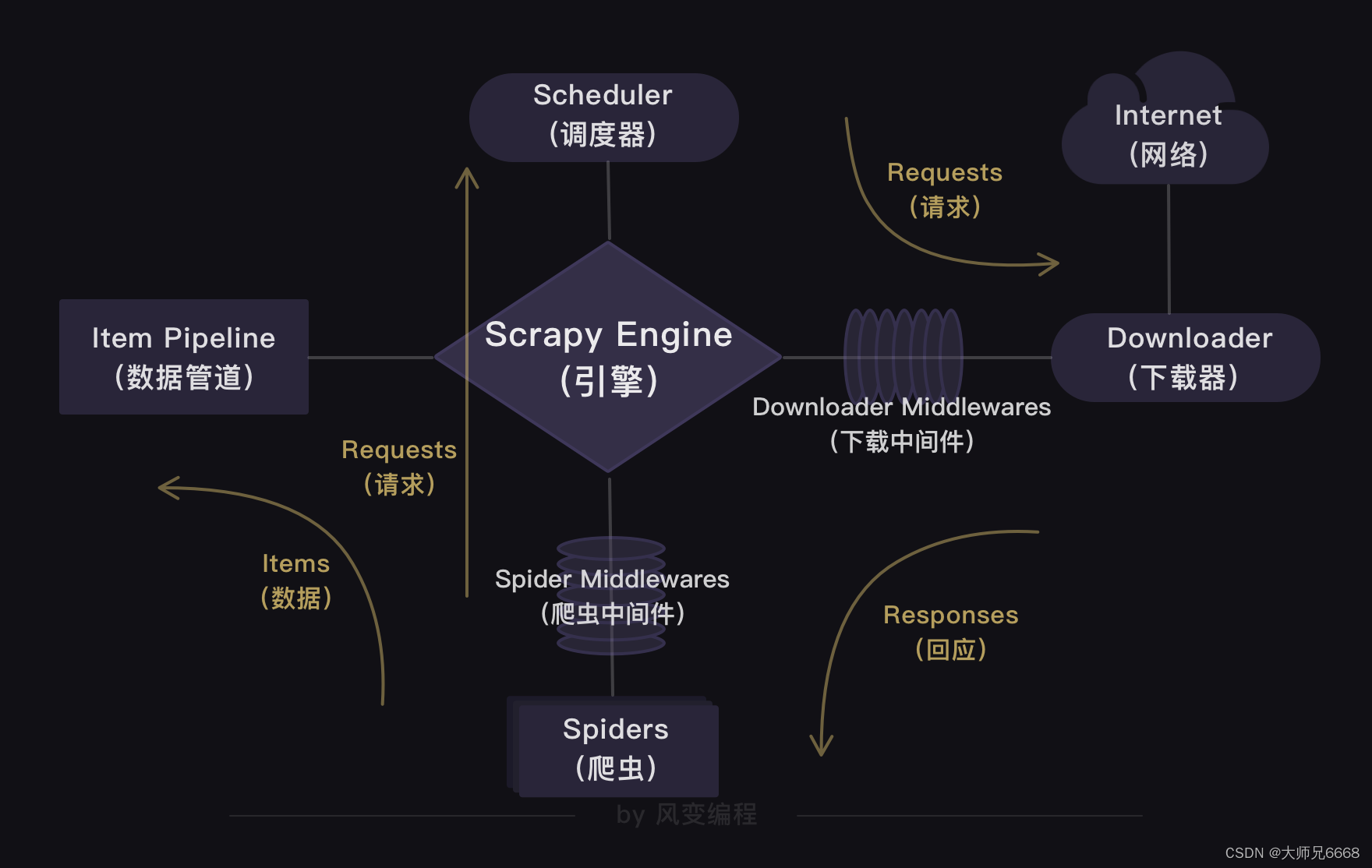
上一关,我们学习了Scrapy框架,知道了Scrapy爬虫公司的结构和工作原理。
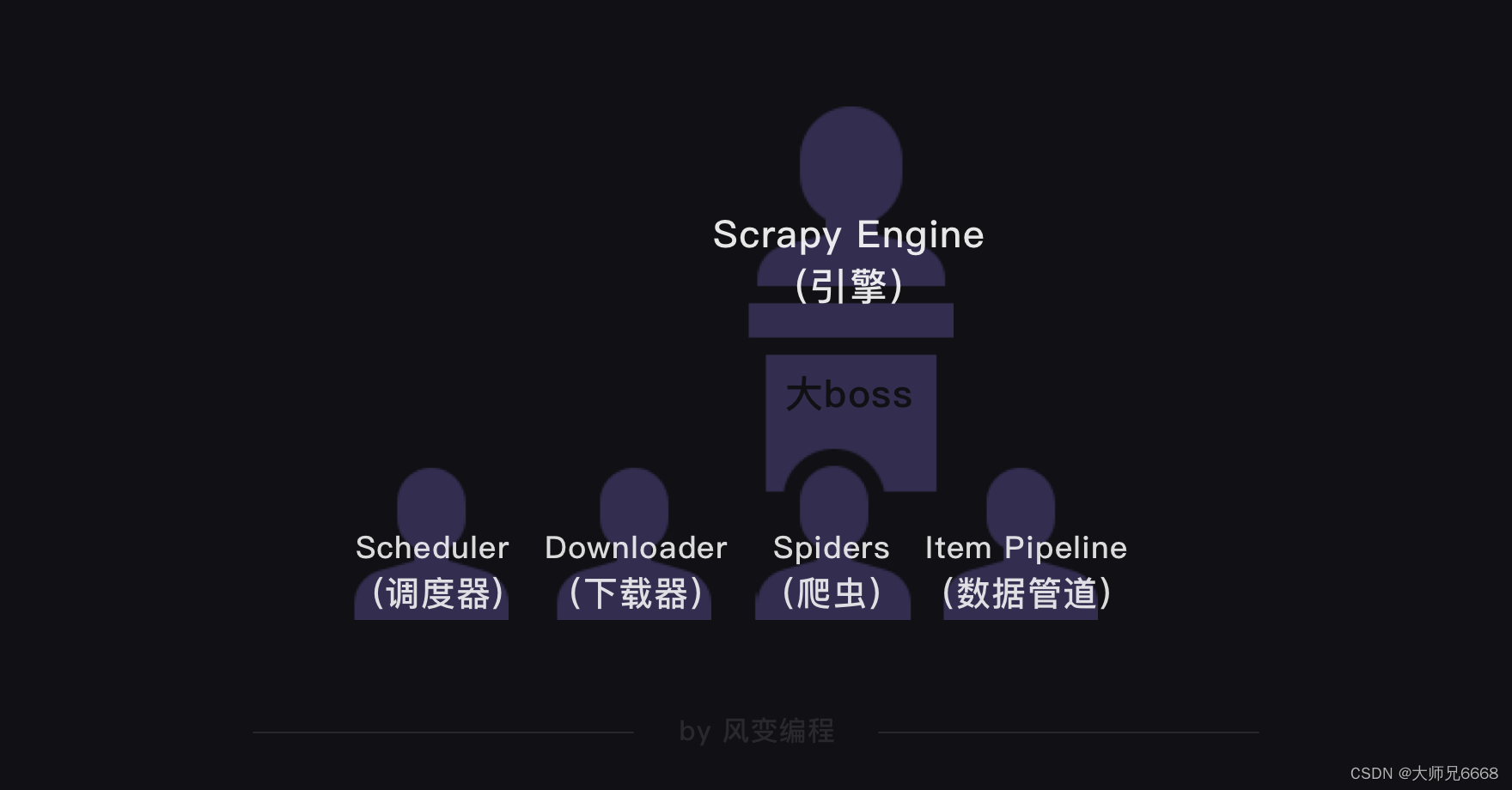
在Scrapy爬虫公司里,引擎是最大的boss,统领着调度器、下载器、爬虫和数据管道四大部门。
这四大部门都听命于引擎,视引擎的需求为最高需求。
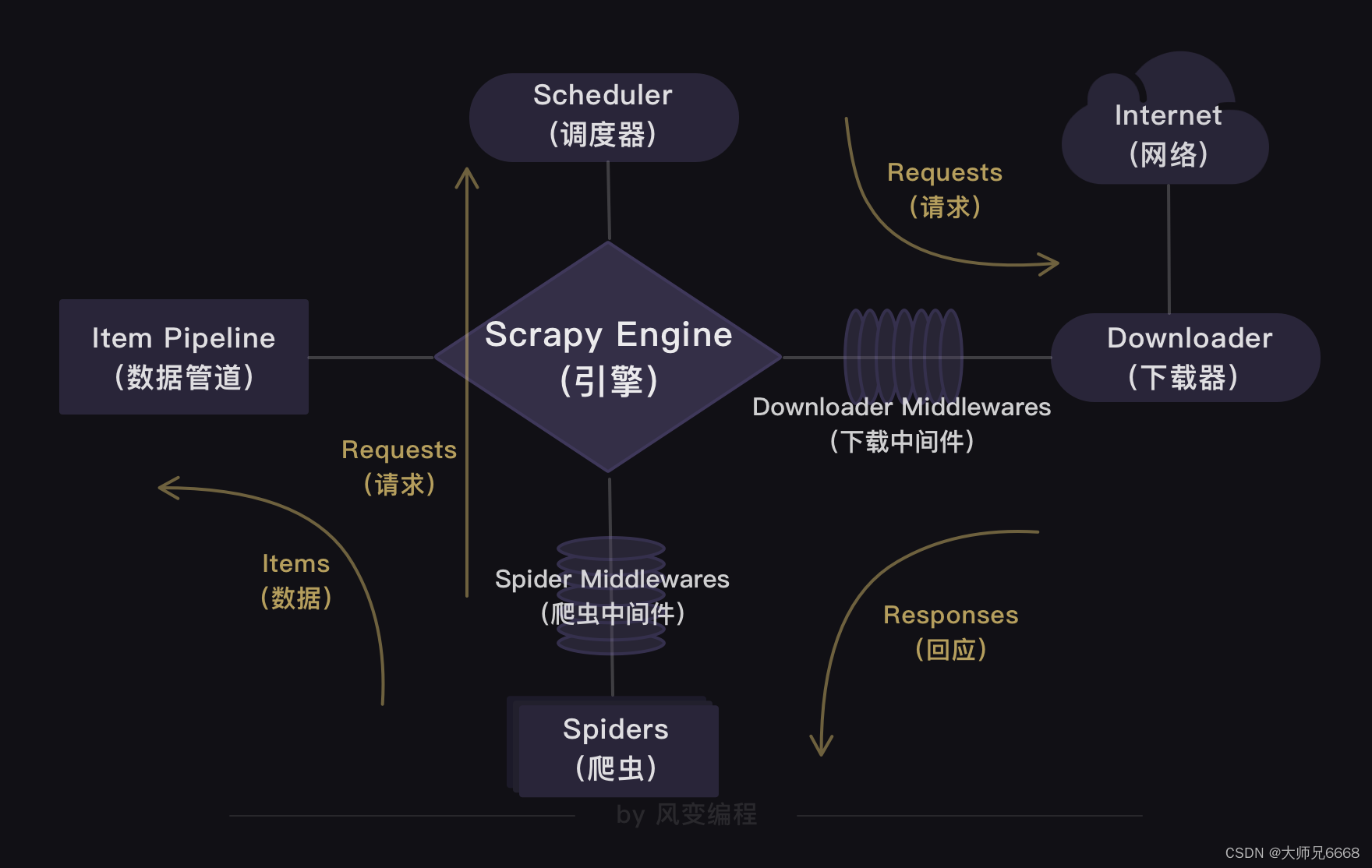
我们还通过实操爬取豆瓣Top250图书的项目,熟悉了Scrapy的用法。

这一关,我会带你实操一个更大的项目——用Scrapy爬取招聘网站的招聘信息。
你可以借此体验一把当Scrapy爬虫公司CEO的感觉,用代码控制并操作整个Scrapy的运行。
那我们爬取什么招聘网站呢?在众多招聘网站中,我挑选了职友集。这个网站可以通过索引的方式,搜索到全国上百家招聘网站的最新职位。
现在,请你用浏览器打开职友集的网址链接(一定要打开哦):
https://www.jobui.com/rank/company/view/beijing/
我用的是北京的页面,大家可以根据自己的需要来进行更换地区。
我们先对这个网站做初步的观察,这样我们才能明确项目的爬取目标。
明确目标
打开网址后,你会发现:这是职友集网站的地区企业排行榜,里面含有本月人气企业榜。
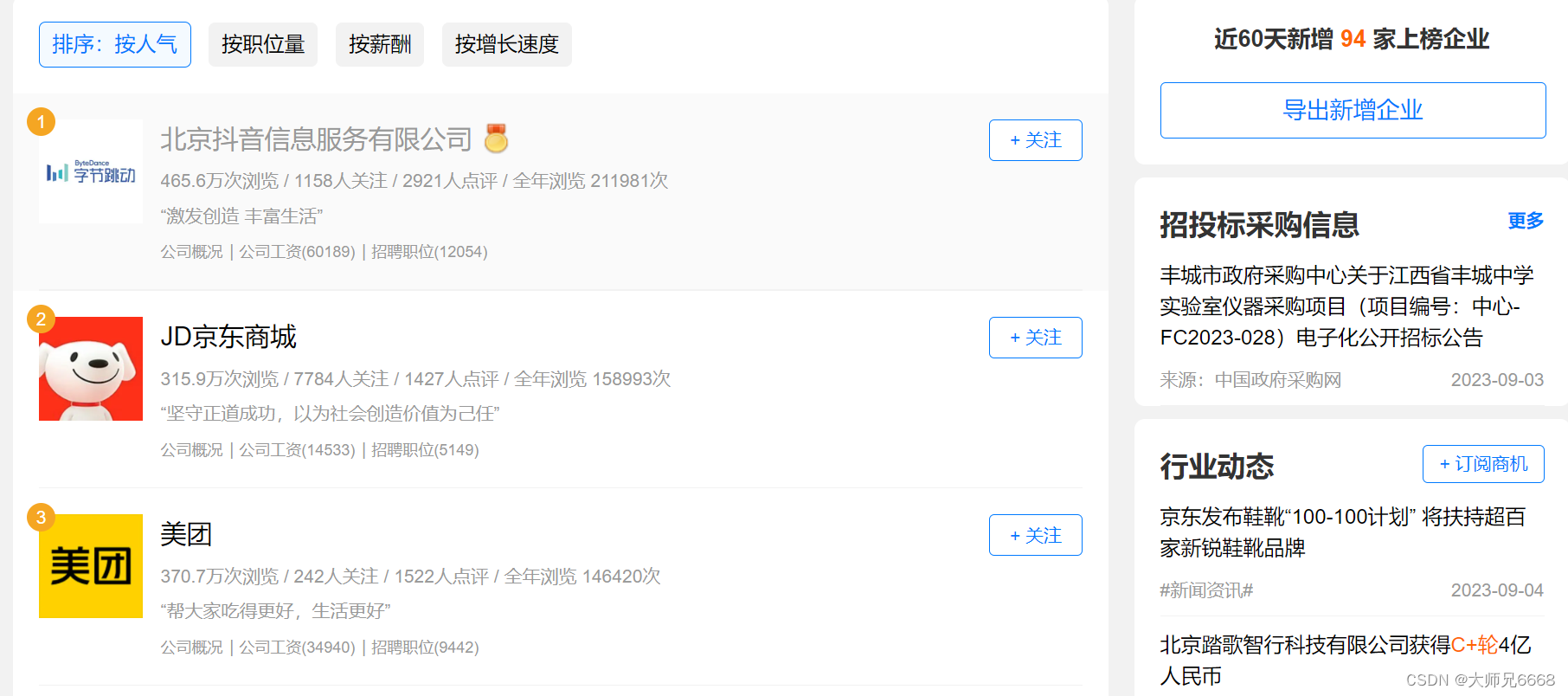
点击【北京痘印信息服务有限公司】,会跳转到这家公司的详情页面,再点击【招聘】,就能看到这家公司正在招聘的所有岗位信息。
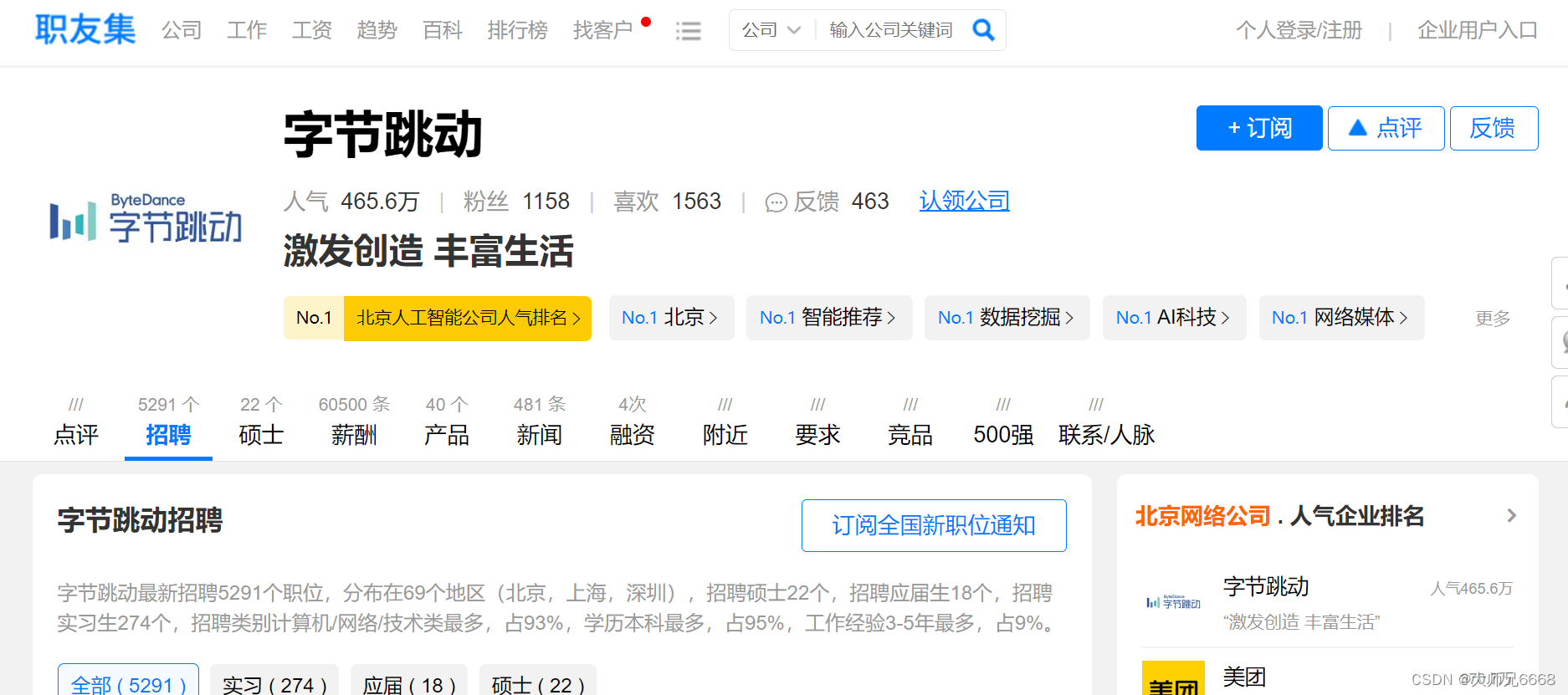
初步观察后,我们可以把爬取目标定为:先爬取企业排行榜四个榜单里的公司,再接着爬取这些公司的招聘信息。
每个榜单有10家公司,四个榜单一共就是40家公司。也就是说,我们要先从企业排行榜爬取到这40家公司,再跳转到这40家公司的招聘信息页面,爬取到公司名称、职位、工作地点和招聘要求。
分析过程
明确完目标,我们开始分析过程。首先,要看企业排行榜里的公司信息藏在了哪里。
企业排行榜的公司信息
请你右击打开“检查”工具,点击Network,刷新页面。点开第0个请求beijing/,看Response,找一下有没有榜单的公司信息在里面。
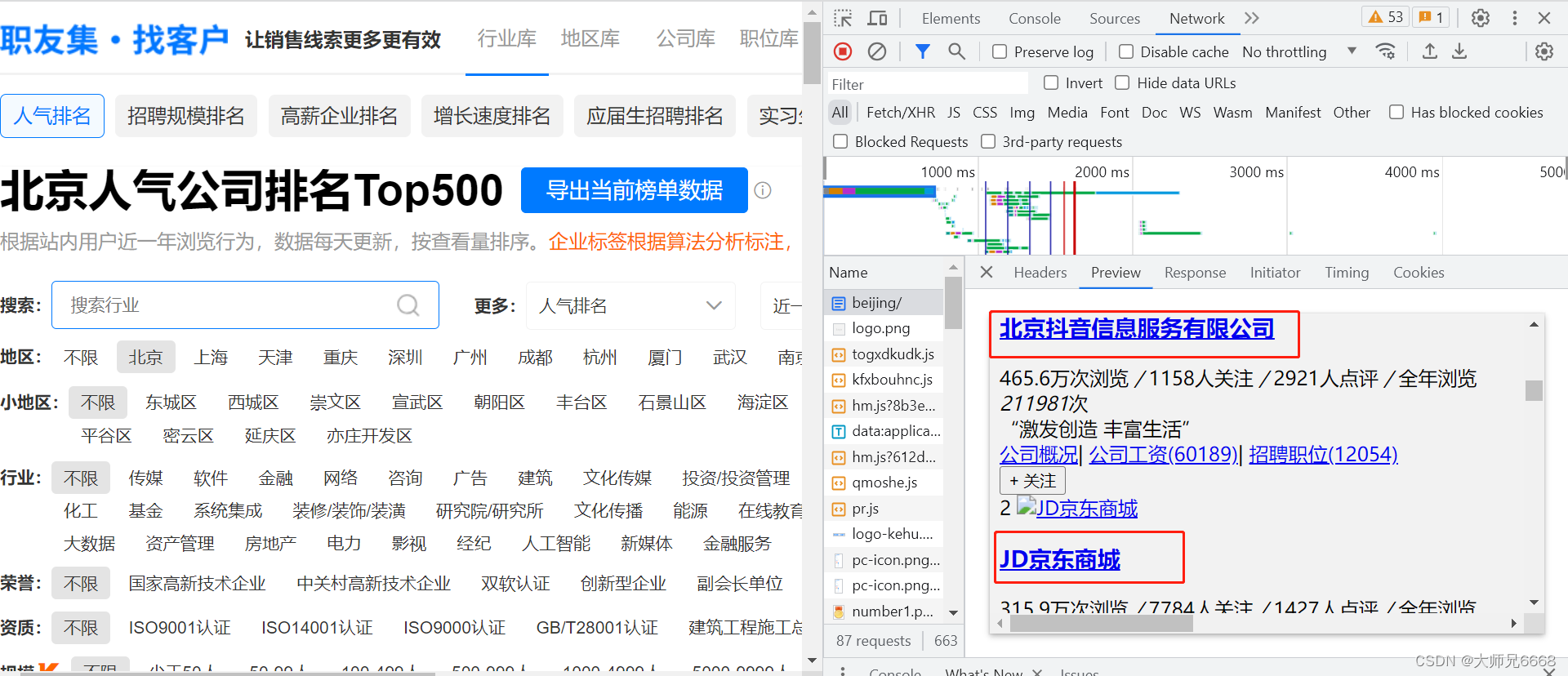
一找,发现四个榜单的所有公司信息都在里面。说明企业排行榜的公司信息就藏在html里。
现在请你点击Elements,点亮光标,再把鼠标移到【北京抖音信息服务有限公司】,这时就会定位到含有这家公司信息的<a>元素上。
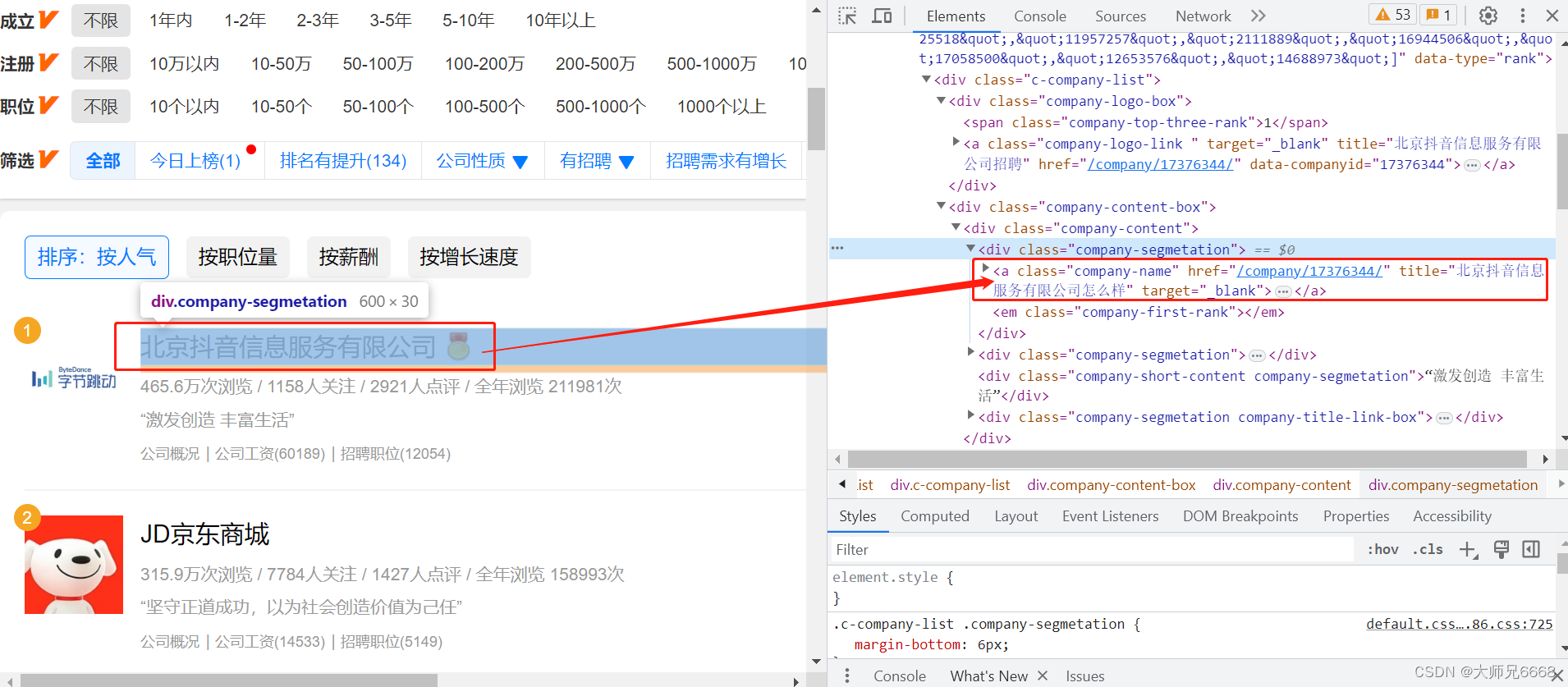
点击href=“/company/10375749/”,会跳转到字节跳动这家公司的详情页面。详情页面的网址是:
https://www.jobui.com/company/17376344/
我们可以猜到:/company/+数字/应该是公司id的标识。这么一观察,榜单上的公司详情页面的网址规律我们就得出来了。
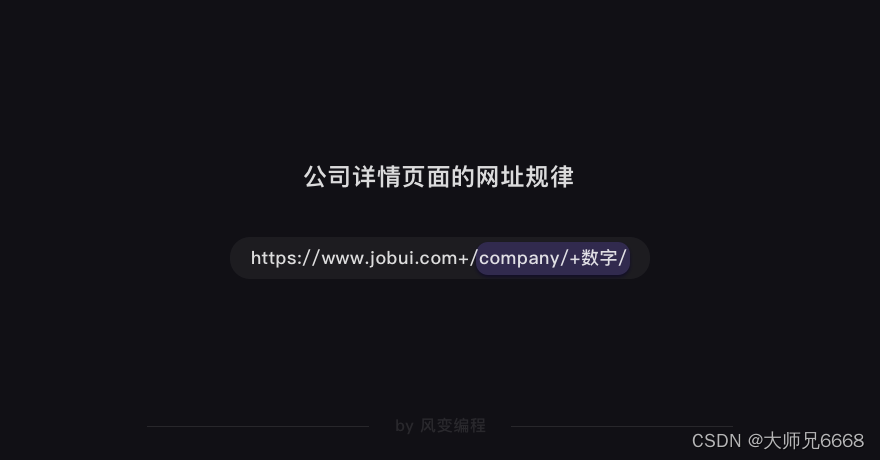
那么,我们只要把<a>元素的href属性的值提取出来,就能构造出每家公司详情页面的网址。
构造公司详情页面的网址是为了后面能获得详情页面里的招聘信息。
现在,我们来分析html的结构,看看怎样才能把<a>元素href属性的值提取出来。
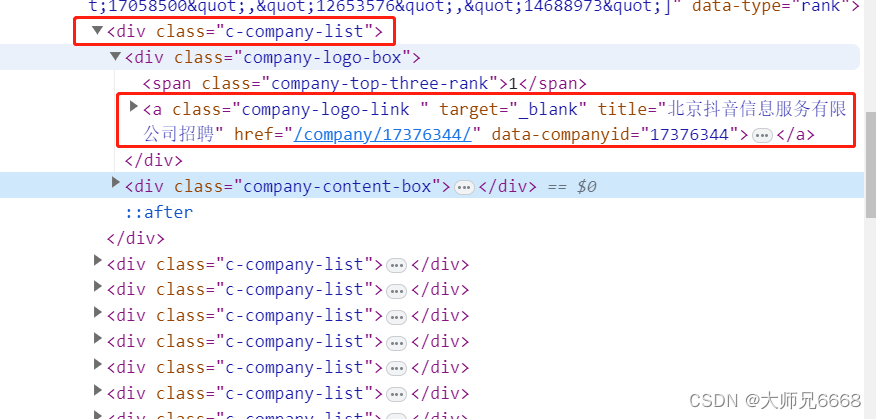
仔细观察html的结构,你会发现,每个公司信息都藏在一个<div class="c-company-list">元素里,这个div标签中包<div class="company-logo-box">和<div class="company-content-box">两个div。
我们想要的<a>标签,就在<div class="company-logo-box">里面。
我们想拿到所有<a>元素href属性的值。我们当然不能直接用find_all()抓取<a>标签,原因也很简单:这个页面有太多的<a>标签,会抓出来很多我们不想要的信息。
一个稳妥的方案是:先抓取最外层的<div>标签,再抓取<div>标签里的<a>元素,最后提取到<a>元素href属性的值。就像剥洋葱,要从最外面的一层开始剥一样。
分析到这里,我们已经知道公司详情页面的网址规律,和如何提取<a>元素href属性的值。
接下来,我们需要分析的就是,每家公司的详情页面。
公司详情页面的招聘信息
我们打开【北京字节跳动科技有限公司】的详情页面,点击【招聘】。这时,网址会发生变化,多了jobs的参数。
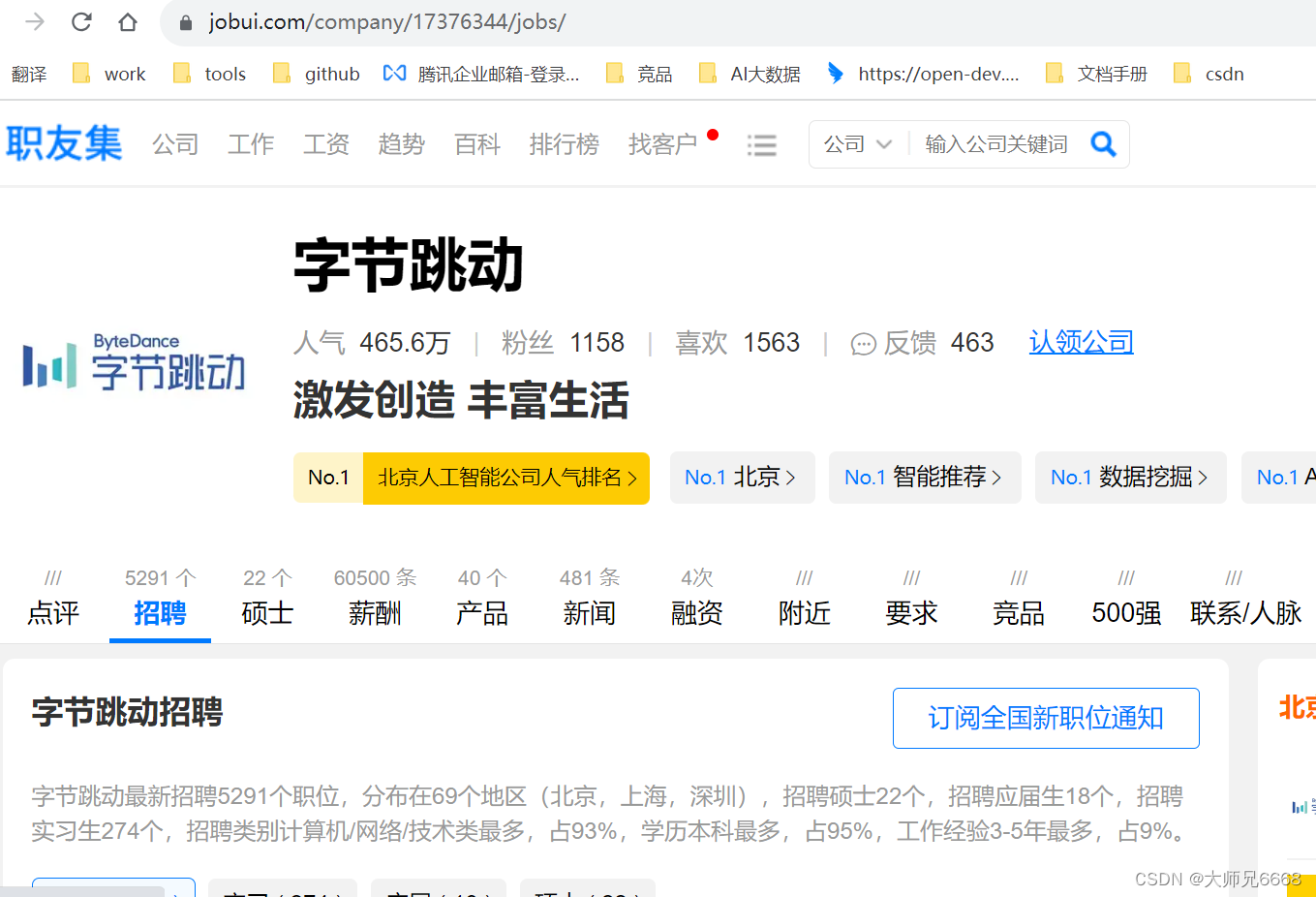
如果你多点击几家公司的详情页面,查看招聘信息,就会知道:公司招聘信息的网址规律也是有规律的。

接着,我们需要找找看公司的招聘信息都存在了哪里。
还是在字节跳动公司的招聘信息页面,右击打开“检查”工具,点击Network,刷新页面。我们点击第0个请求jobs/,查看Response,翻找看看里面有没有这家公司的招聘信息。
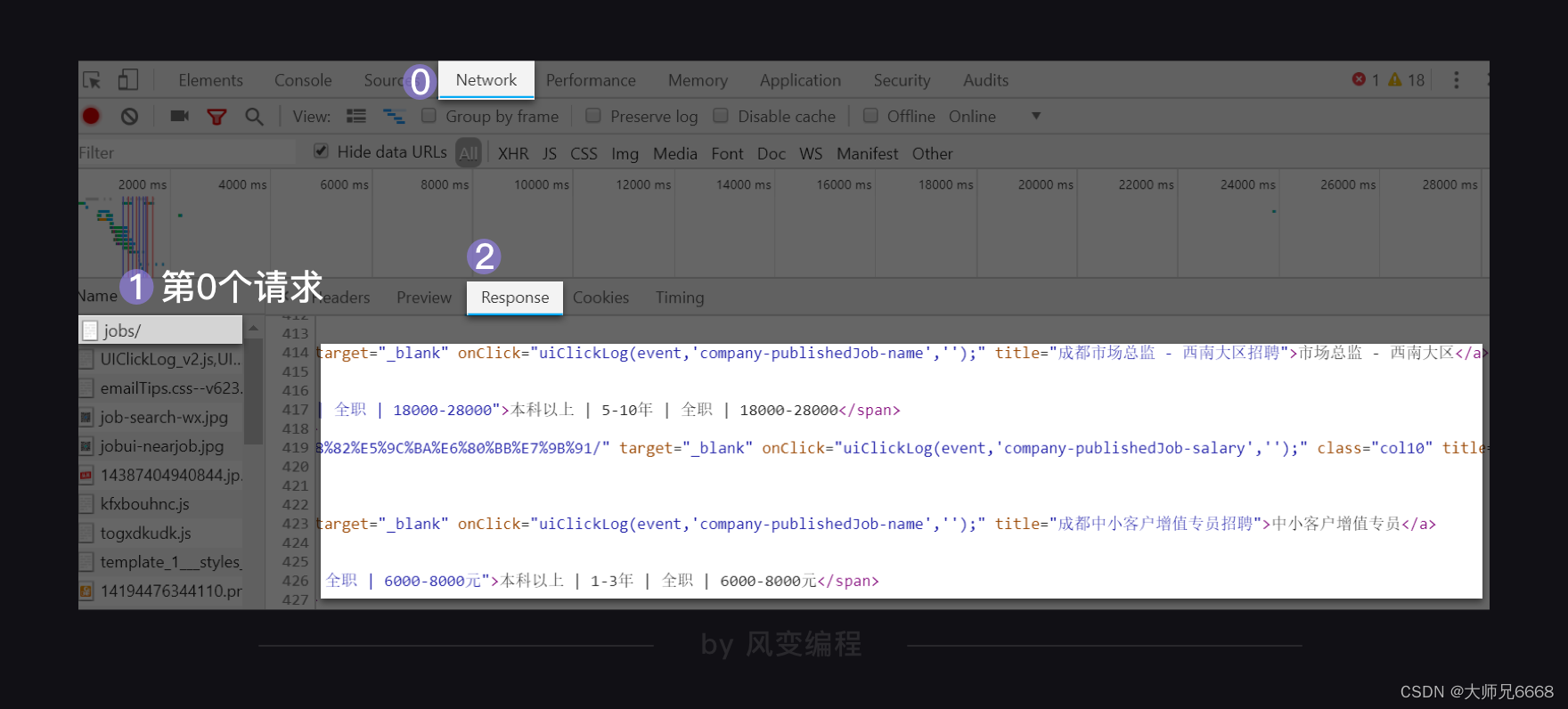
在Response里我们找到了想要的招聘信息。这说明公司的招聘信息依旧是藏在了html里。
接下来,你应该知道要分析什么了吧。
分析的套路都是相同的,知道数据藏在html后,接着是分析html的结构,想办法提取出我们想要的数据。
那就按照惯例点击Elements,然后点亮光标,把鼠标移到公司名称吧。
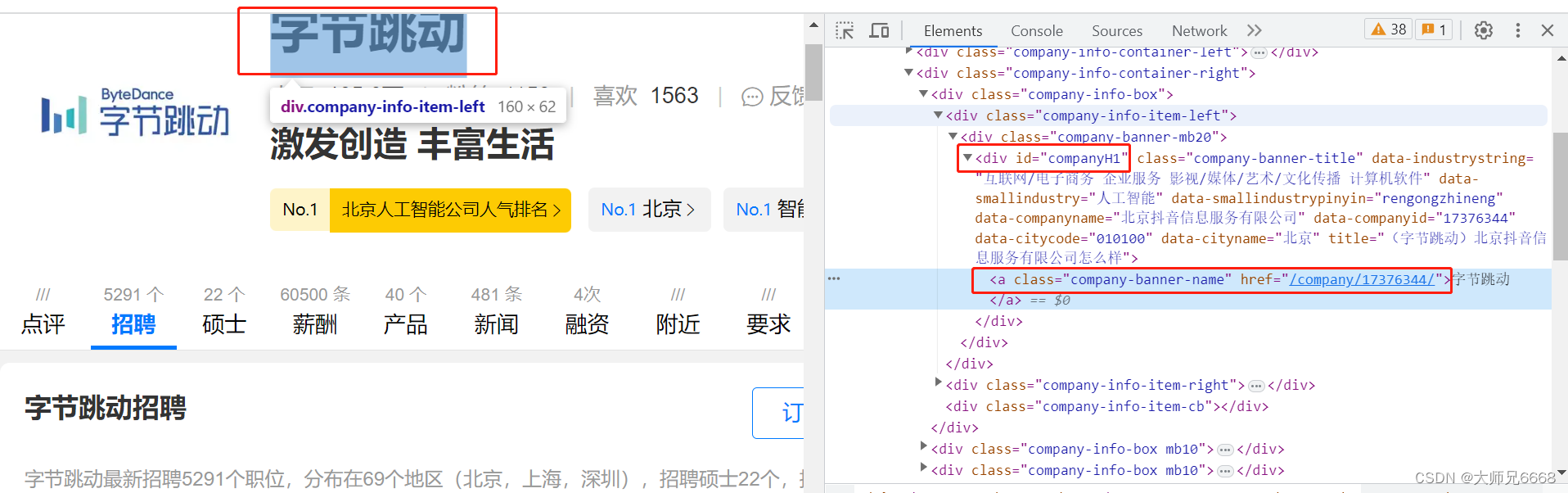
公司名称藏在<div class="company-banner-title">标签下的<a>元素的文本中。按道理来说,我们可以通过class属性,定位到<div>的这个标签,取出<div>标签的文本,就能拿到公司名称。
不过经过我几次的操作试验,发现职友集这个网站间隔一段时间就会更换这个标签的名字(可能你此时看到的标签名不一定是
为了保证一定能取到公司名称,我们改成用id属性(id=“companyH1”)来定位这个标签。这样,不管这个标签名字如何更换,我们依旧能抓到它。
下面,再把鼠标移到岗位名称,看看招聘的岗位信息可以怎么提取。
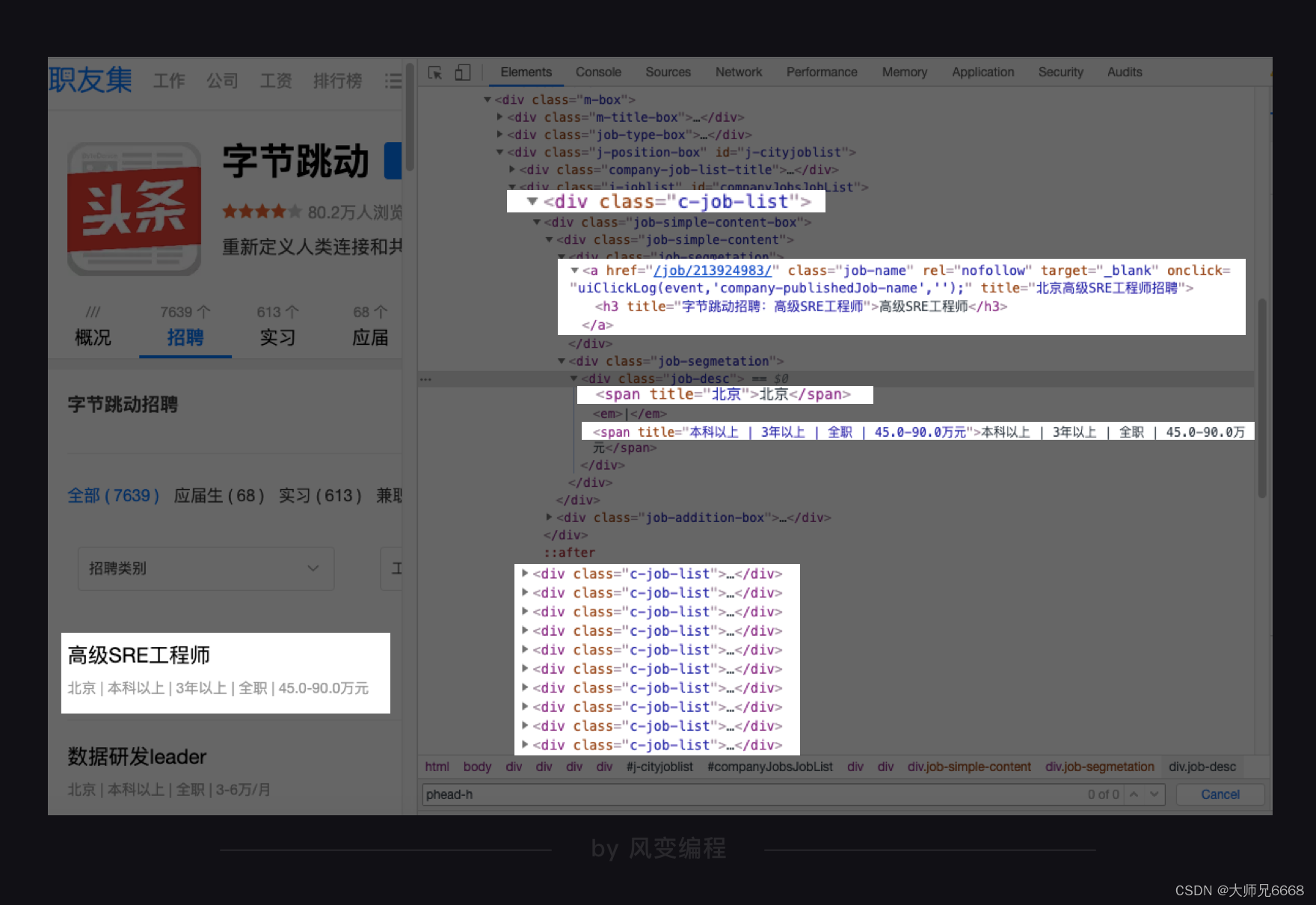
你会发现:每个岗位的信息都藏在一个<div>标签下,职位名称在<a>元素的文本中,工作地点和职位要求在<div class="job-desc">元素中,工作地点在第 1 个<span>标签里,职位要求在第 2 个<span>标签里。
这样分析下来,我们想要的招聘信息,包括公司名称、职位名称、工作地点和职位要求,都定位清楚了。
至此,我们分析完了整个爬取过程,接下来就是代码实现啦。
代码实现

我们按照Scrapy正常的用法一步步来。首先,我们必须创建一个Scrapy项目。
创建项目
还记得怎么创建吗?打开本地电脑的终端(windows:Win+R,输入cmd;mac:command+空格,搜索“终端”),跳转到你想要保存项目的目录下,输入创建Scrapy项目的命令:scrapy startproject jobui(jobui是职友集网站的英文名,在这里我们把它作为Scrapy项目的名字)。
创建好项目后,你在本地电脑的编译器打开这个Scrapy项目,会看到如下的结构:
定义item
我们刚刚分析的时候,已经确定要爬取的数据是公司名称、职位名称、工作地点和招聘要求。
那么,现在请你写出定义item的代码。
下面,是我写的定义item的代码。
import scrapyclass JobuiItem(scrapy.Item):
#定义了一个继承自scrapy.Item的JobuiItem类company = scrapy.Field()#定义公司名称的数据属性position = scrapy.Field()#定义职位名称的数据属性address = scrapy.Field()#定义工作地点的数据属性detail = scrapy.Field()#定义招聘要求的数据属性
创建和编写爬虫文件
定义好item,我们接着要做的是在spiders里创建爬虫文件,命名为jobui_ jobs。
现在,我们可以开始在这个爬虫文件里编写代码。
先导入所需的模块:
import scrapy
import bs4
from ..items import JobuiItem
接下来,是编写爬虫的核心代码。我会先带着你理清代码的逻辑,这样等下你才能比较顺利地理解和写出代码。
在前面分析过程的步骤里,我们知道要先抓取企业排行榜40家公司的id标识,比如字节跳动公司的id标识是/company/17376344/。

再利用抓取到的公司id标识构造出每家公司招聘信息的网址。比如,字节跳动公司的招聘信息网址就是https://www.jobui.com/company/17376344/jobs/
我们需要再把每家公司招聘信息的网址封装成requests对象。这里你可能有点不理解为什么要封装成requests对象,我解释一下。
如果我们不是使用Scrapy,而是使用requests库的话,一般我们得到一个网址,需要用requests.get(),传入网址这个参数,才能获取到网页的源代码。
而在Scrapy里,获取网页源代码这件事儿,会由引擎交分配给下载器去做,不需要我们自己处理。我们之所以要构造新的requests对象,是为了告诉引擎,我们新的请求需要传入什么参数。
这样才能让引擎拿到的是正确requests对象,交给下载器处理。
既然构造了新的requests对象,我们就得定义与之匹配的用来处理response的新方法。这样才能提取出我们想要的招聘信息的数据。
好啦,核心代码的逻辑我们理清楚了。

我们接着往下写核心代码。
#导入模块
import scrapy
import bs4
from ..items import JobuiItemclass JobuiSpider(scrapy.Spider):
#定义一个爬虫类JobuiSpidername = 'jobui' #定义爬虫的名字为jobuiallowed_domains = ['www.jobui.com']#定义允许爬虫爬取网址的域名——职友集网站的域名start_urls = ['https://www.jobui.com/rank/company/view/beijing/']#定义起始网址——职友集企业排行榜的网址(北京)def parse(self, response):#parse是默认处理response的方法bs = bs4.BeautifulSoup(response.text, 'html.parser')#用BeautifulSoup解析response(企业排行榜的网页源代码)company_list = bs.find('div',id="companyList").find_all('div',class_='c-company-list')#用find_all提取所有<div class="c-company-list">标签for company in company_list:#遍历company_listdata = company.find('a')# 找到其中第一个<a>标签,即<div class="company-logo-box">下的<a>标签company_id = data['href']#提取出所有<a>元素的href属性的值,也就是公司id标识url = 'https://www.jobui.com{id}jobs'real_url = url.format(id=company_id)#构造出公司招聘信息的网址链接
第6-13行代码:定义了爬虫类JobuiSpider、爬虫的名字jobui、允许爬虫爬取的域名和起始网址。
剩下的代码,你应该都能看懂。我们用默认的parse方法来处理response(企业排行榜的网页源代码);用BeautifulSoup来解析response;用find_all方法提取数据(公司id标识)。
公司id标识就是<a>元素的href属性的值,我们想要把它提取出来,就得先抓到所有最外层的<div class="c-company-list">标签,再从中抓取<a>元素。
所以这里用了个for循环,把元素的href属性的值提取了出来,并成功构造了公司招聘信息的网址。
代码写到这里,我们已经完成了核心代码逻辑的前两件事:提取企业排行榜的公司id标识和构造公司招聘信息的网址。

接下来,就是构造新的requests对象和定义新的方法处理response。
继续来完善核心代码(请你重点看第30行代码及之后的代码)。
#导入模块
import scrapy
import bs4
from ..items import JobuiItemclass JobuiSpider(scrapy.Spider):
#定义一个爬虫类JobuiSpidername = 'jobui' #定义爬虫的名字为jobuiallowed_domains = ['www.jobui.com']#定义允许爬虫爬取网址的域名——职友集网站的域名start_urls = ['https://www.jobui.com/rank/company/view/beijing/']#定义起始网址——职友集企业排行榜的网址def parse(self, response):#parse是默认处理response的方法bs = bs4.BeautifulSoup(response.text, 'html.parser')#用BeautifulSoup解析response(企业排行榜的网页源代码)company_list = bs.find('div',id="companyList").find_all('div',class_='c-company-list')#用find_all提取所有<div class="c-company-list">标签for company in company_list:#遍历company_listdata = company.find('a')# 找到其中第一个<a>标签,即<div class="company-logo-box">下的<a>标签company_id = data['href']#提取出所有<a>元素的href属性的值,也就是公司id标识url = 'https://www.jobui.com{id}jobs'real_url = url.format(id=company_id)#构造出公司招聘信息的网址链接yield scrapy.Request(real_url, callback=self.parse_job)
#用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parsejob方法。def parse_job(self, response):#定义新的处理response的方法parse_job(方法的名字可以自己起)bs = bs4.BeautifulSoup(response.text, 'html.parser')#用BeautifulSoup解析response(公司招聘信息的网页源代码)company = bs.find(id="companyH1").text#用find方法提取出公司名称datas = bs.find_all('div',class_="c-job-list")#用find_all提取<div class_="c-job-list">标签,里面含有招聘信息的数据for data in datas:#遍历datasitem = JobuiItem()#实例化JobuiItem这个类item['company'] = company#把公司名称放回JobuiItem类的company属性里item['position']=data.find('a').find('h3').text#提取出职位名称,并把这个数据放回JobuiItem类的position属性里item['address'] = data.find_all('span')[0].text#提取出工作地点,并把这个数据放回JobuiItem类的address属性里item['detail'] = data.find_all('span')[1].text#提取出招聘要求,并把这个数据放回JobuiItem类的detail属性里yield item#用yield语句把item传递给引擎
你应该不理解第30行代码:yield scrapy.Request(real_url, callback=self.parse_job)的意思。我跟你解释一下。
scrapy.Request是构造requests对象的类。real_url是我们往requests对象里传入的每家公司招聘信息网址的参数。
callback的中文意思是回调。self.parse_job是我们新定义的parse_job方法。往requests对象里传入callback=self.parse_job这个参数后,引擎就能知道response要前往的下一站,是parse_job()方法。
yield语句就是用来把这个构造好的requests对象传递给引擎。
第34行代码,是我们定义的新的parse_job方法。这个方法是用来解析和提取公司招聘信息的数据。
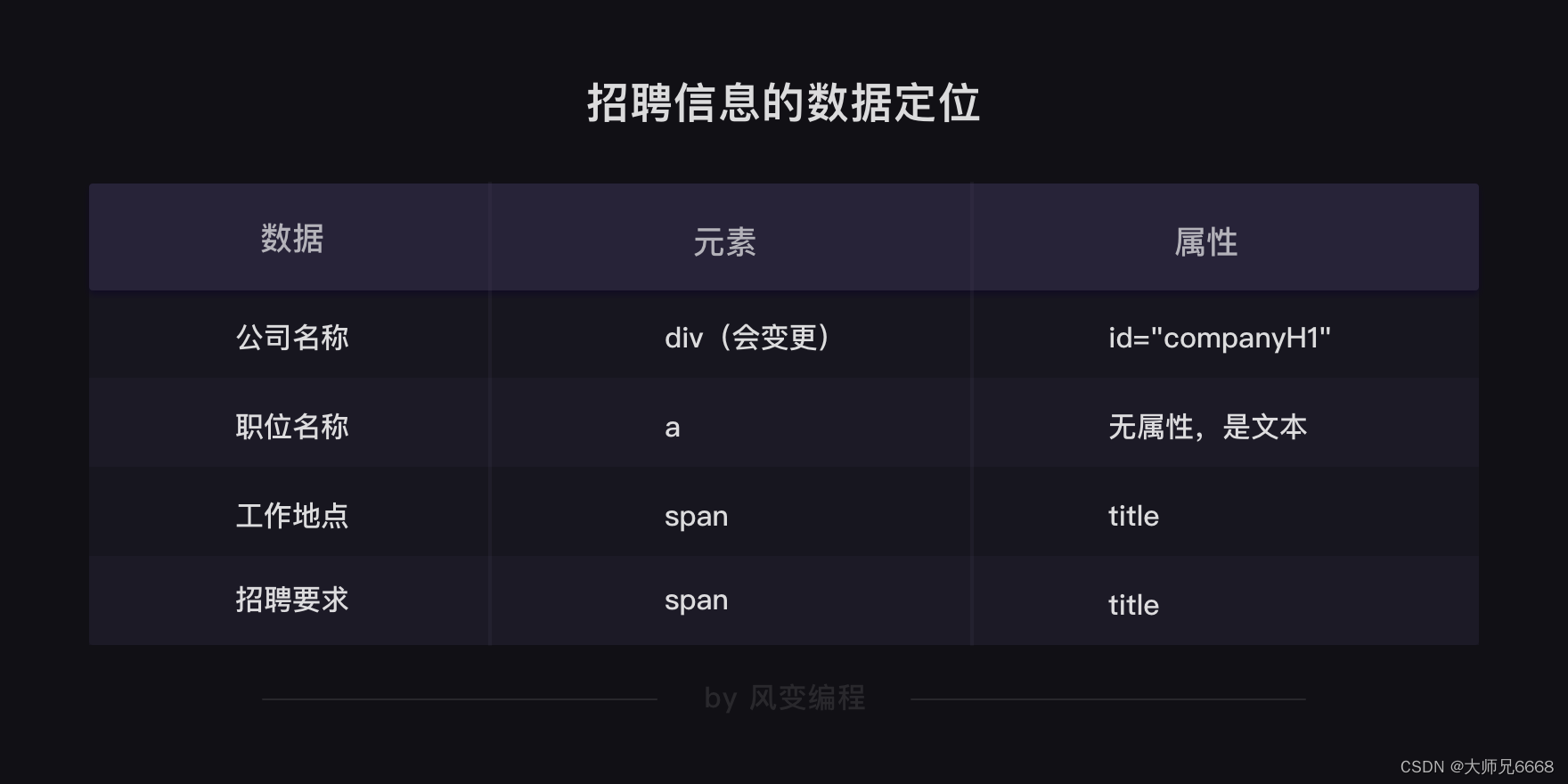
对照下面的招聘信息的数据定位表格,你应该能比较好地理解之后的代码。
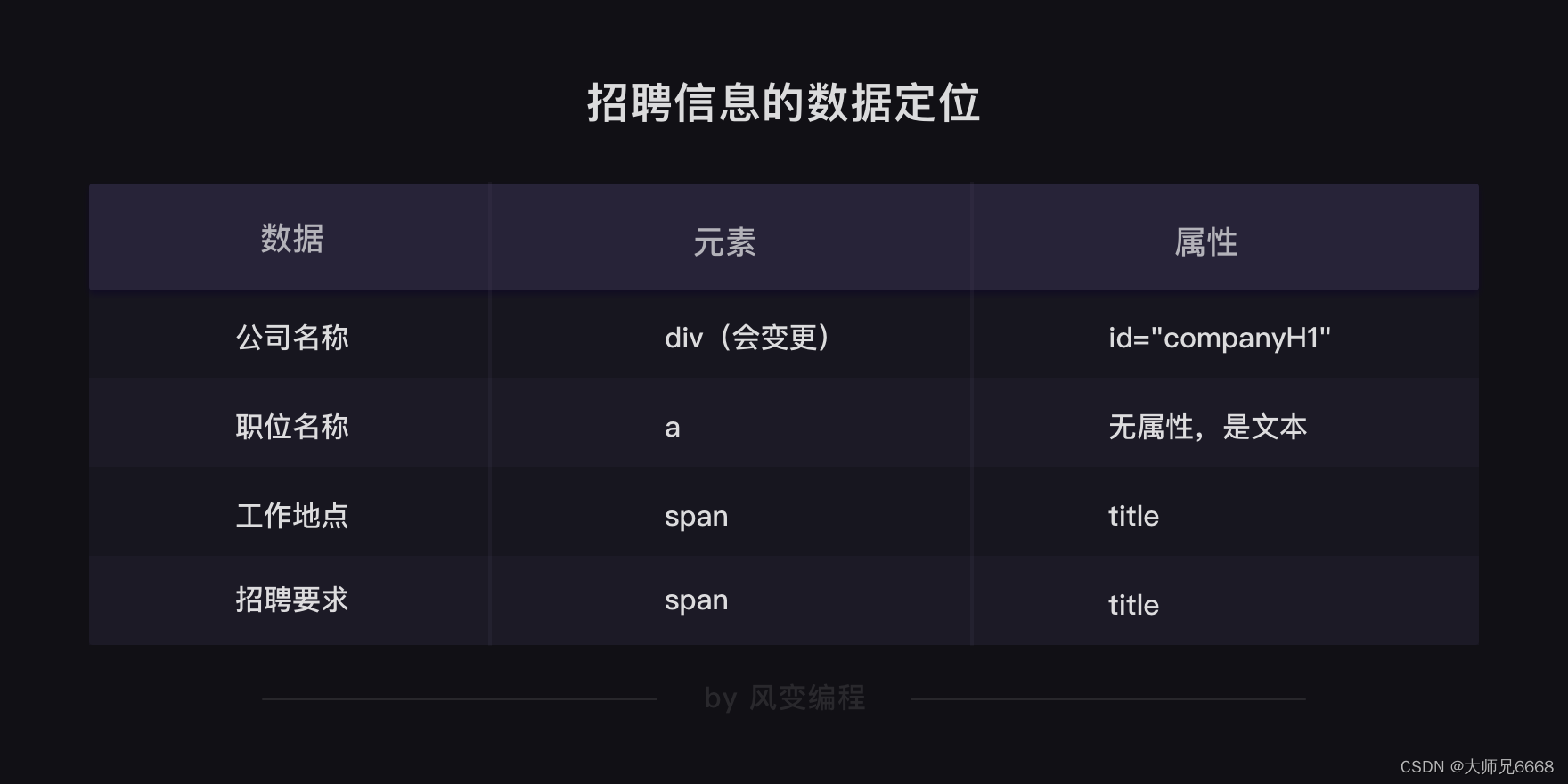
上图中的工作地点和招聘要求 的属性,已经修正为了 text 请大家注意。
提取出公司名称、职位名称、工作地点和招聘要求这些数据,并把这些数据放进我们定义好的JobuiItem类里。
最后,用yield语句把item传递给引擎,整个核心代码就编写完啦!ヽ(゚∀゚)メ(゚∀゚)ノ
存储文件
至此,我们整个项目还差存储数据这一步。在第7关,我们学过用csv模块把数据存储csv文件,用openpyxl模块把数据存储Excel文件。
其实,在Scrapy里,把数据存储成csv文件和Excel文件,也有分别对应的方法。我们先说csv文件。
存储成csv文件的方法比较简单,只需在settings.py文件里,添加如下的代码即可。
FEED_URI='./storage/data/%(name)s.csv'
FEED_FORMAT='csv'
FEED_EXPORT_ENCODING='ansi'
FEED_URI是导出文件的路径。‘./storage/data/%(name)s.csv’,就是把存储的文件放到与main.py文件同级的storage文件夹的data子文件夹里。
FEED_FORMAT 是导出数据格式,写csv就能得到csv格式。
FEED_EXPORT_ENCODING 是导出文件编码,ansi是一种在windows上的编码格式,你也可以把它变成utf-8用在mac电脑上。
存储成Excel文件的方法要稍微复杂一些,我们需要先在settings.py里设置启用ITEM_PIPELINES,设置方法如下:
#需要修改`ITEM_PIPELINES`的设置代码:# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'jobui.pipelines.JobuiPipeline': 300,
# }
只要取消ITEM_PIPELINES的注释(删掉#)即可。
#取消`ITEM_PIPELINES`的注释后:# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'jobui.pipelines.JobuiPipeline': 300,
}
接着,我们就可以去编辑pipelines.py文件。存储为Excel文件,我们依旧是用openpyxl模块来实现,代码如下,注意阅读注释:
import openpyxlclass JobuiPipeline(object):
#定义一个JobuiPipeline类,负责处理itemdef __init__(self):#初始化函数 当类实例化时这个方法会自启动self.wb =openpyxl.Workbook()#创建工作薄self.ws = self.wb.active#定位活动表self.ws.append(['公司', '职位', '地址', '招聘信息'])#用append函数往表格添加表头def process_item(self, item, spider):#process_item是默认的处理item的方法,就像parse是默认处理response的方法line = [item['company'], item['position'], item['address'], item['detail']]#把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给lineself.ws.append(line)#用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格return item#将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度def close_spider(self, spider):#close_spider是当爬虫结束运行时,这个方法就会执行self.wb.save('./jobui.xlsx')#保存文件self.wb.close()#关闭文件
修改设置
在最后,我们还要再修改Scrapy中settings.py文件里的默认设置:添加请求头,以及把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False。
#需要修改的默认设置:# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'jobui (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = True
还有一处默认设置我们需要修改,代码如下:
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 0
我们需要取消DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,我们要把下载延迟的时间改成0.5秒。
改好后的代码如下:
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5
修改完设置,我们已经可以运行代码。

温馨提示:由于网站反爬策略升级,如果发现请求的响应结果不是200,那就参照之前的文章来进行解决即可。
代码实操
我带你完成了核心代码的编写,现在是时候到你自己动手编写一遍这个项目的核心代码。
提示1:除了编写核心代码,还要定义item、修改设置和运行Scrapy。
提示2:运行Scrapy的方法,在main.py文件里导入cmdline模块,用execute方法执行终端的命令行:scrapy crawl+项目名
提示3:如果是使用main.py作为入口来进行运行的话,只有main.py文件是能点击运行的。
提示4:存储为csv还是Excel,你可以自己决定。存储为csv只需要更改settings文件,存储为Excel则还需要修改pipelines.py文件。
开始代码实操吧~
怎么样,完成了吗?
不管代码有没有运行成功,我都为你鼓掌!ヾ(o´∀`o)ノ
总结
至此,我们使用Scrapy完成了一个完整项目。它涉及了一个爬虫的全程:获取数据,解析数据,提取数据和存储数据。
但是必须要指出的是,受篇幅所限,还有许多内容没展开讲:Scrapy的自带解析器怎么用?如何带参数请求数据?如何写入cookies?如何发送邮件?如何与selenium联动?如何完成超厉害的分布式爬虫……如是种种。
如是种种,全都讲出来可能还要新增好几个关卡。但是我认为,这不是必要的。
一来,你已经学习过用BS解析数据、带参数请求数据、加入cookies、发邮件、协程……你明白它们的工作原理。
二来,你已经明白Scrapy框架的组成和工作原理。
只要将两者加以组合,辅以练习,就能轻松掌握。
今日的你,只是不知道语法怎么写罢了。而语法问题,是最容易解决的问题,我们可以去阅读官方文档。因为你已具备上述知识,所以这文档读起来也会非常简单。
在下一关,我为你准备了对过往知识的总复习、反爬虫策略汇总、对未来爬虫学习的指引,以及一封书信。
我们下一关见!
相关文章:
【python爬虫】15.Scrapy框架实战(热门职位爬取)
文章目录 前言明确目标分析过程企业排行榜的公司信息公司详情页面的招聘信息 代码实现创建项目定义item 创建和编写爬虫文件存储文件修改设置 代码实操总结 前言 上一关,我们学习了Scrapy框架,知道了Scrapy爬虫公司的结构和工作原理。 在Scrapy爬虫公司…...
Apinto 网关 V0.14 版本发布,6 大插件更新!
大家好! 距离上次更新已经过去一段时间了,这段日子里我们一直在酝酿新的功能,本次的迭代将给大家带来 6 大插件的更新~一起来看看有哪些变化吧! 新特性 1. 新增 额外参数v2 插件,支持对转发参数进行加密、拼接等操作…...

突破销售瓶颈:亚马逊卖家如何借力TikTok网红营销?
随着社交媒体的崛起,营销方式也在不断变革。TikTok作为一款风靡全球的短视频平台,吸引了数以亿计的用户,成为了品牌宣传和销售的新热点。对于亚马逊卖家而言,通过合理运用TikTok网红营销策略,可以有效提升产品的曝光度…...

JavaWeb之Cookie的简单使用!!!
什么是Cookie Cookie:客户端会话技术,将数据保存到客户端,以后每次请求都携带Cookie数据进行访问 Cookie 数据存放在浏览器端(客户端) 创建Cookie 1.创建Cookie Cookie cookie new Cookie("key","value"); 2.使用response响应…...
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
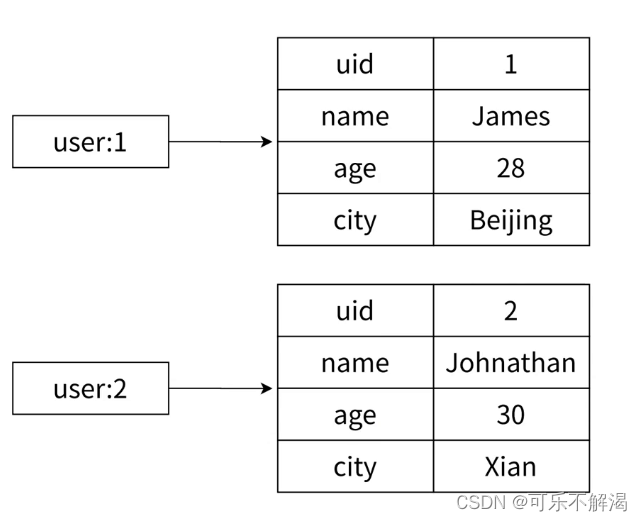
6.Redis-hash
hash 哈希类型中的映射关系通常称为field-value,⽤于区分 Redis 整体的键值对(key-value),注意这⾥的value是指field对应的值,不是键(key)对应的值,请注意 value 在不同上下⽂的作⽤…...
)
点云从入门到精通技术详解100篇-多时相机载激光雷达人工林点云匹配及生长监测(续)
目录 多时相机载激光雷达人工林点云匹配及变化监测 3.1 技术路线 3.2 数据准备 3.3 方法...

【Vue3 知识第七讲】reactive、shallowReactive、toRef、toRefs 等系列方法应用与对比
文章目录 一、reactive()二、readonly()三、shallowReactive()四、shallowReadonly()五、isReactive() 和 isReadonly()六、toRef()七、toRefs()八、toRaw()九、ref、toRef、toRefs 异同点 一、reactive() reactive() 函数用于返回一个对象的响应式代理。与 ref() 函数定义响应…...

Docker 摸门级简易手册
Docker 摸门级简易手册 文章目录 Docker 摸门级简易手册使用 Docker 构建 Java 项目镜像Docker 安装Install on MacInstall on WindowsInstall on Linux Dockerfile 说明FROMLABELENVWORKDIRCOPYADDRUNCMDEXPOSEENTRYPOINTVOLUMEUSER 使用 Docker 构建 Java 项目镜像 假设有个…...
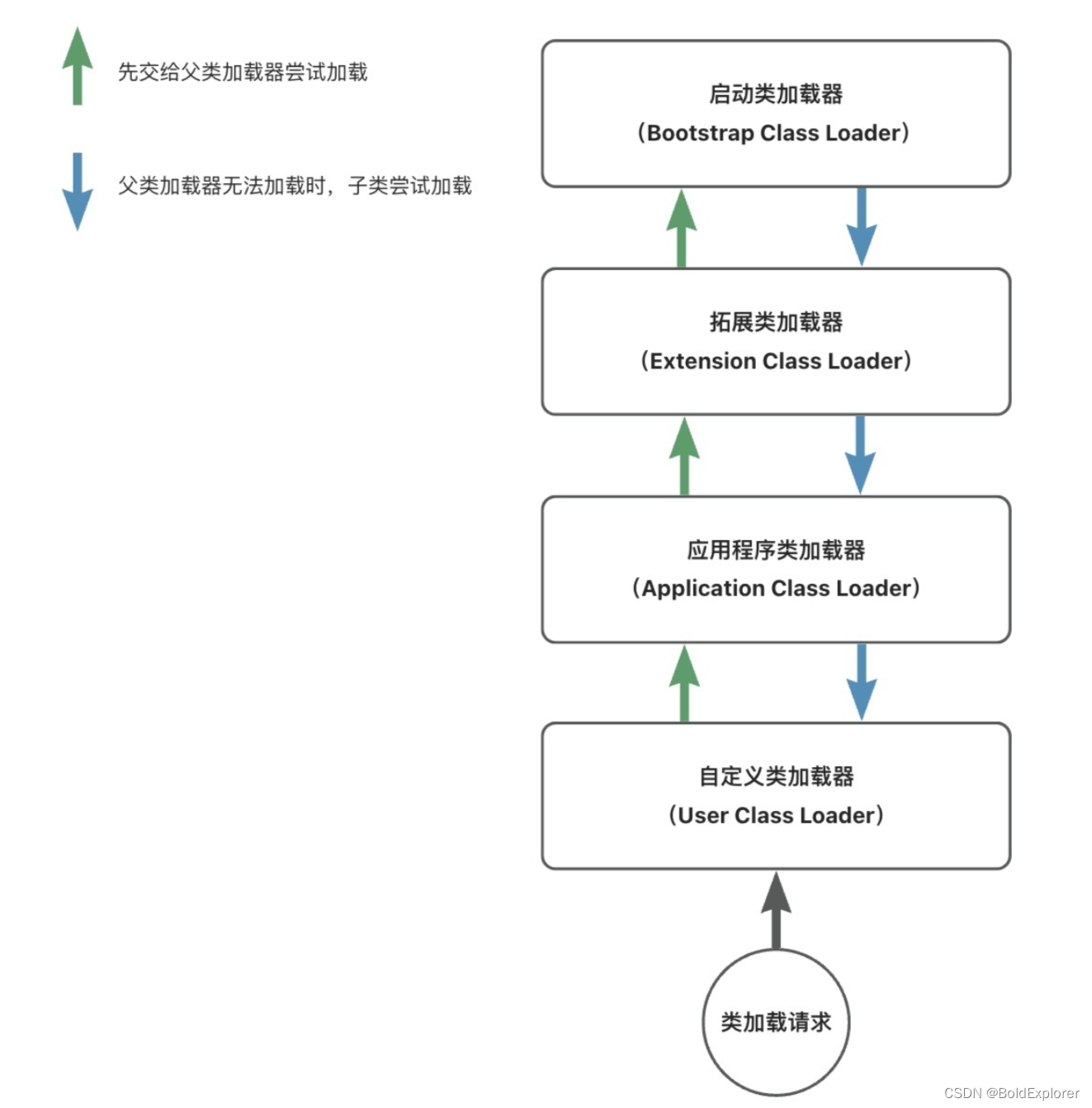
Java类加载机制
简介 在Java的世界里,每一个类或者接口,在经历编译器后,都会生成一个个.class文件。 类加载机制指的是将这些.class文件中的二进制数据读入到内存中,并对数据进行校验,解析和初始化。最终,每一个类都会在…...

vue 自定义指令简单记录
自定义指令例子 // src/main.js import { createApp } from vue; import App from ./App.vue;const app = createApp(App);// 全局自定义指令 app.directive(color-directive, {mounted(el, binding) {// 当指令绑定到元素上时触发// el 是绑定的元素// binding 包含了指令的信…...

算法通关村-----快速排序的原理和实现
快速排序介绍 快速排序是一种经典高效的排序方法,是分治策略在排序上的具体体现。将一个大的待排序列分割成若干个小的有序序列,最终将各个小的有序序列合并成一个大的有序序列。 快速排序的实现原理 选择一个基准值,将小于基准值的元素放…...
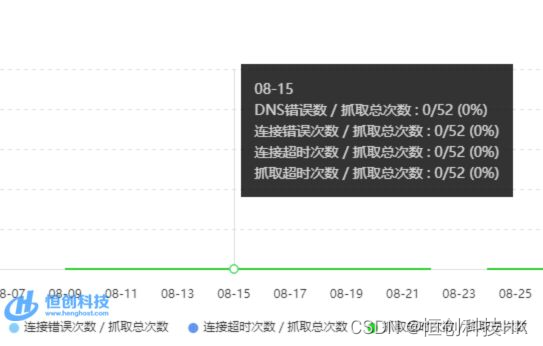
百度抓取香港服务器抓取超时是什么情况?
网络延迟导致抓取超时 网络延迟是指从发送请求到接收响应之间的时间延迟。如果网络延迟过高,服务器可能无法及时响应请求,导致超时。在香港服务器上抓取数据时,如果网络延迟过高,可能会出现抓取超时的情况。 服务器负载过高可能…...
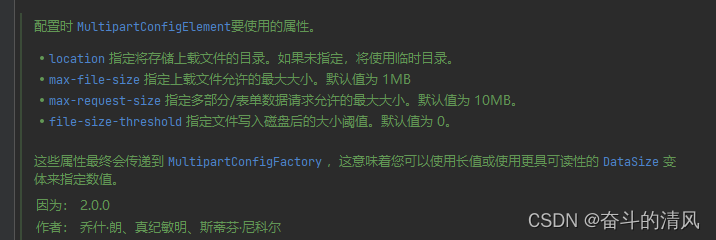
Springboot上传文件
上传文件示例代码: ApiOperation("上传文件") PostMapping(value "/uploadFile", consumes MediaType.MULTIPART_FORM_DATA_VALUE) public ApiResult<String> uploadFile(RequestPart("file") MultipartFile file) { //调用七…...

kafka教程
kafka教程 Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统,其主要特点为: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能高吞吐率。即使在非常…...

JVM的故事—— 内存分配策略
内存分配策略 文章目录 内存分配策略一、对象优先在Eden分配二、大对象直接进入老年代三、长期存活的对象将进入老年代四、动态对象年龄判定五、空间分配担保 一、对象优先在Eden分配 堆内存有新生代和老年代,新生代中有一个Eden区和一个Survivor区(from space或者…...

21.CSS的动态圆形进度条
效果 源码 <!doctype html> <html><head><meta charset="utf-8"><title>Animated Circular Progress | CSS Only</title><link rel="stylesheet" href="style.css"></head><body><di…...
Linux_VMware_虚拟机磁盘扩容
来源文章 :VMware教学-虚拟机扩容篇_vmware虚拟机扩容_系统免驱动的博客-CSDN博客 由于项目逐步的完善,需要搭建的中间件,软件越来越多,导致以前虚拟机配置20G的内存不够用了,又不想重新创建新的虚拟机,退…...

中欧财富:分布式数据库的应用历程和 TiDB 7.1 新特性探索
原文来源: https://tidb.net/blog/ccbaeda2 作者:张政俊, 中欧财富数据库负责人 导读 中欧财富是中欧基金控股的销售子公司,旗下 APP 实现业内基金品种全覆盖,提供基金交易、大数据选基、智慧定投、理财师咨询等…...

树莓 LUMA-OLED.EXAMPLE使用
详细介绍在文件目录下的README.rst中 第一步 $ sudo usermod -a -G i2c,spi,gpio pi //好像没什么用 $ sudo apt install python3-dev python3-pip python3-numpy libfreetype6-dev libjpeg-dev build-essential //安装依赖包,树莓派中好像已经有了 $ sudo a…...

【亲测免费】 高效频谱分析利器:STM32F4 AD采集与FFT计算
高效频谱分析利器:STM32F4 AD采集与FFT计算 【下载地址】STM32F4AD采集DMA方式进行FFT计算 STM32F4 AD采集DMA方式进行FFT计算本资源文件提供了一个基于STM32F4系列微控制器的AD采集与FFT计算的实现方案 项目地址: https://gitcode.com/open-source-toolkit/7ed4e…...

Node.js 服务端应用接入 Taotoken 实现异步对话补全的完整步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务端应用接入 Taotoken 实现异步对话补全的完整步骤 在 Node.js 服务端应用中集成大模型能力,通常需要处理密…...

摄影师的终极批量水印神器:semi-utils让照片保护变得如此简单
摄影师的终极批量水印神器:semi-utils让照片保护变得如此简单 【免费下载链接】semi-utils 一个批量添加相机机型和拍摄参数的工具,后续「可能」添加其他功能。 项目地址: https://gitcode.com/gh_mirrors/se/semi-utils 还在为一张张手动添加水印…...

LLMs 的新前沿:挑战、解决方案与工具
原文:towardsdatascience.com/the-new-frontiers-of-llms-challenges-solutions-and-tools-b1d48c34cf8e?sourcecollection_archive---------2-----------------------#2024-01-25 https://towardsdatascience.medium.com/?sourcepost_page---byline--b1d48c34cf8…...

力扣17,电话号码的字母组合
class Solution { public: //设置一个map,用来数字与字母比对unordered_map<char, string> _mp{{2,"abc"},{3,"def"},{4,"ghi"},{5,"jkl"},{6,"mno"},{7,"pqrs"},{8,"tuv"},{9,"…...

技术博主都在悄悄用的Perplexity高级搜索语法,11个未公开符号组合全曝光
更多请点击: https://kaifayun.com 第一章:Perplexity高级搜索语法的底层逻辑与设计哲学 Perplexity 的高级搜索语法并非简单的关键词匹配扩展,而是基于语义意图建模与查询图谱重构的设计实践。其核心在于将用户自然语言查询实时编译为可执行…...

高效掌握Simscape Electrical:BLDC电机控制器设计的5大关键技术实战
高效掌握Simscape Electrical:BLDC电机控制器设计的5大关键技术实战 【免费下载链接】Design-motor-controllers-with-Simscape-Electrical This repository contains MATLAB and Simulink files used in the "How to design motor controllers using Simscape…...

无王无帝定乾坤,来自田间第一人 凰标传世照千秋
无王无帝定乾坤 ——来自田间第一人华夏文明千年流转,王朝霸业此起彼伏。 无数帝王功业随岁月风化,无数朝堂规制随朝代更迭消散。 真正能够跨越岁月、贯穿古今、安定世道、照亮千秋的, 从不是一时的权位霸业,而是亘古不变的公道正…...

告别复杂设置!Sunshine v0.21.0 + Moonlight安卓版:5分钟搞定家庭局域网游戏串流
5分钟极简指南:用Sunshine和Moonlight打造家庭游戏串流系统 客厅的沙发上,手机屏幕突然变成了你的高性能游戏PC——这不是科幻电影,而是每个家庭都能实现的游戏串流体验。过去需要复杂网络知识才能搭建的串流系统,如今借助Sunshin…...

在Node.js后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken实现稳定高效的多模型调用 对于需要构建AI功能的后端开发者而言,直接对接多个模型厂商…...