强化学习DQN之俄罗斯方块
强化学习DQN之俄罗斯方块
- 强化学习DQN之俄罗斯方块
- 算法流程
- 文件目录结构
- 模型结构
- 游戏环境
- 训练代码
- 测试代码
- 结果展示
强化学习DQN之俄罗斯方块
算法流程
本项目目的是训练一个基于深度强化学习的俄罗斯方块。具体来说,这个代码通过以下步骤实现训练:
- 首先设置一些随机数种子,以便在后面的训练中能够重现结果。
- 创建一个俄罗斯方块环境实例,这个环境是一个俄罗斯方块游戏,用于模拟AI与游戏的交互。
- 创建一个DeepQNetwork模型,这个模型是基于深度学习的强化学习模型,用于预测下一步的最佳行动。
- 创建一个优化器(optimizer)和一个损失函数(criterion),用于训练模型。
- 在每个训练时期(epoch)中,对于当前状态(state),计算所有可能的下一步状态(next_steps),根据一定的策略(exploration or exploitation)选择一个行动(action),并计算该行动带来的奖励(reward)和下一步是否为终止状态(done)。
- 将当前状态、奖励、下一步状态和终止状态添加到回放内存(replay memory)中。
- 如果当前状态为终止状态,则重置环境,并记录得分(final_score)、俄罗斯方块数量(final_tetrominoes)和消除的行数(final_cleared_lines)。
- 从回放内存中随机选择一批样本(batch),并将其用于训练模型。具体来说,将状态批次(state_batch)、奖励批次(reward_batch)、下一步状态批次(next_state_batch)和是否为终止状态批次(done_batch)分别取出,并将其分别转换为张量(tensor)。然后计算每个样本的目标值(target)y_batch,并用它来计算损失值(loss),并将损失值的梯度反向传播(backpropagation)。最后,使用优化器来更新模型参数。
- 输出当前训练时期的信息,并记录得分、俄罗斯方块数量和消除的行数到TensorBoard中。
- 如果当前训练时期为某个特定数的倍数,将模型保存到硬盘中。
- 重复上述步骤,直到达到指定的训练时期数。
文件目录结构
├── output.mp4
├── src
│ ├── deep_q_network.py 模型结构
│ └── tetris.py 游戏环境
├── tensorboard
│ └── events.out.tfevents.1676879249.aifs3-worker-2
├── test.py 测试代码
├── trained_models 训练保存的模型
│ ├── tetris
│ ├── tetris_1000
│ ├── tetris_1500
│ ├── tetris_2000
│ └── tetris_500
└── train.py 训练代码模型结构
import torch.nn as nnclass DeepQNetwork(nn.Module):def __init__(self):super(DeepQNetwork, self).__init__()self.conv1 = nn.Sequential(nn.Linear(4, 64), nn.ReLU(inplace=True))self.conv2 = nn.Sequential(nn.Linear(64, 64), nn.ReLU(inplace=True))self.conv3 = nn.Sequential(nn.Linear(64, 1))self._create_weights()def _create_weights(self):for m in self.modules():if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)nn.init.constant_(m.bias, 0)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)return x
游戏环境
import numpy as np
from PIL import Image
import cv2
from matplotlib import style
import torch
import randomstyle.use("ggplot")class Tetris:piece_colors = [(0, 0, 0),(255, 255, 0),(147, 88, 254),(54, 175, 144),(255, 0, 0),(102, 217, 238),(254, 151, 32),(0, 0, 255)]pieces = [[[1, 1],[1, 1]],[[0, 2, 0],[2, 2, 2]],[[0, 3, 3],[3, 3, 0]],[[4, 4, 0],[0, 4, 4]],[[5, 5, 5, 5]],[[0, 0, 6],[6, 6, 6]],[[7, 0, 0],[7, 7, 7]]]def __init__(self, height=20, width=10, block_size=20):self.height = heightself.width = widthself.block_size = block_sizeself.extra_board = np.ones((self.height * self.block_size, self.width * int(self.block_size / 2), 3),dtype=np.uint8) * np.array([204, 204, 255], dtype=np.uint8)self.text_color = (200, 20, 220)self.reset()#---------------------------------------------------------------------------------------# 重置游戏#---------------------------------------------------------------------------------------def reset(self):self.board = [[0] * self.width for _ in range(self.height)]self.score = 0self.tetrominoes = 0self.cleared_lines = 0self.bag = list(range(len(self.pieces)))random.shuffle(self.bag)self.ind = self.bag.pop()self.piece = [row[:] for row in self.pieces[self.ind]]self.current_pos = {"x": self.width // 2 - len(self.piece[0]) // 2, "y": 0}self.gameover = Falsereturn self.get_state_properties(self.board)#---------------------------------------------------------------------------------------# 旋转方块#---------------------------------------------------------------------------------------def rotate(self, piece):num_rows_orig = num_cols_new = len(piece)num_rows_new = len(piece[0])rotated_array = []for i in range(num_rows_new):new_row = [0] * num_cols_newfor j in range(num_cols_new):new_row[j] = piece[(num_rows_orig - 1) - j][i]rotated_array.append(new_row)return rotated_array#---------------------------------------------------------------------------------------# 获取当前游戏状态的一些属性#---------------------------------------------------------------------------------------def get_state_properties(self, board):lines_cleared, board = self.check_cleared_rows(board)holes = self.get_holes(board)bumpiness, height = self.get_bumpiness_and_height(board)return torch.FloatTensor([lines_cleared, holes, bumpiness, height])#---------------------------------------------------------------------------------------# 面板中空洞数量#---------------------------------------------------------------------------------------def get_holes(self, board):num_holes = 0for col in zip(*board):row = 0while row < self.height and col[row] == 0:row += 1num_holes += len([x for x in col[row + 1:] if x == 0])return num_holes#---------------------------------------------------------------------------------------# 计算游戏面板的凹凸度和亮度#---------------------------------------------------------------------------------------def get_bumpiness_and_height(self, board):board = np.array(board)mask = board != 0invert_heights = np.where(mask.any(axis=0), np.argmax(mask, axis=0), self.height)heights = self.height - invert_heightstotal_height = np.sum(heights)currs = heights[:-1]nexts = heights[1:]diffs = np.abs(currs - nexts)total_bumpiness = np.sum(diffs)return total_bumpiness, total_height#---------------------------------------------------------------------------------------# 获取下一个可能的状态#---------------------------------------------------------------------------------------def get_next_states(self):states = {}piece_id = self.indcurr_piece = [row[:] for row in self.piece]if piece_id == 0: # O piecenum_rotations = 1elif piece_id == 2 or piece_id == 3 or piece_id == 4:num_rotations = 2else:num_rotations = 4for i in range(num_rotations):valid_xs = self.width - len(curr_piece[0])for x in range(valid_xs + 1):piece = [row[:] for row in curr_piece]pos = {"x": x, "y": 0}while not self.check_collision(piece, pos):pos["y"] += 1self.truncate(piece, pos)board = self.store(piece, pos)states[(x, i)] = self.get_state_properties(board)curr_piece = self.rotate(curr_piece)return states#---------------------------------------------------------------------------------------# 获取当前面板状态#---------------------------------------------------------------------------------------def get_current_board_state(self):board = [x[:] for x in self.board]for y in range(len(self.piece)):for x in range(len(self.piece[y])):board[y + self.current_pos["y"]][x + self.current_pos["x"]] = self.piece[y][x]return board#---------------------------------------------------------------------------------------# 添加新的方块#---------------------------------------------------------------------------------------def new_piece(self):if not len(self.bag):self.bag = list(range(len(self.pieces)))random.shuffle(self.bag)self.ind = self.bag.pop()self.piece = [row[:] for row in self.pieces[self.ind]]self.current_pos = {"x": self.width // 2 - len(self.piece[0]) // 2,"y": 0}if self.check_collision(self.piece, self.current_pos):self.gameover = True#---------------------------------------------------------------------------------------# 检查边界 输入:形状、位置#---------------------------------------------------------------------------------------def check_collision(self, piece, pos):future_y = pos["y"] + 1for y in range(len(piece)):for x in range(len(piece[y])):if future_y + y > self.height - 1 or self.board[future_y + y][pos["x"] + x] and piece[y][x]:return Truereturn Falsedef truncate(self, piece, pos):gameover = Falselast_collision_row = -1for y in range(len(piece)):for x in range(len(piece[y])):if self.board[pos["y"] + y][pos["x"] + x] and piece[y][x]:if y > last_collision_row:last_collision_row = yif pos["y"] - (len(piece) - last_collision_row) < 0 and last_collision_row > -1:while last_collision_row >= 0 and len(piece) > 1:gameover = Truelast_collision_row = -1del piece[0]for y in range(len(piece)):for x in range(len(piece[y])):if self.board[pos["y"] + y][pos["x"] + x] and piece[y][x] and y > last_collision_row:last_collision_row = yreturn gameoverdef store(self, piece, pos):board = [x[:] for x in self.board]for y in range(len(piece)):for x in range(len(piece[y])):if piece[y][x] and not board[y + pos["y"]][x + pos["x"]]:board[y + pos["y"]][x + pos["x"]] = piece[y][x]return boarddef check_cleared_rows(self, board):to_delete = []for i, row in enumerate(board[::-1]):if 0 not in row:to_delete.append(len(board) - 1 - i)if len(to_delete) > 0:board = self.remove_row(board, to_delete)return len(to_delete), boarddef remove_row(self, board, indices):for i in indices[::-1]:del board[i]board = [[0 for _ in range(self.width)]] + boardreturn boarddef step(self, action, render=True, video=None):x, num_rotations = actionself.current_pos = {"x": x, "y": 0}for _ in range(num_rotations):self.piece = self.rotate(self.piece)while not self.check_collision(self.piece, self.current_pos):self.current_pos["y"] += 1if render:self.render(video)overflow = self.truncate(self.piece, self.current_pos)if overflow:self.gameover = Trueself.board = self.store(self.piece, self.current_pos)lines_cleared, self.board = self.check_cleared_rows(self.board)score = 1 + (lines_cleared ** 2) * self.widthself.score += scoreself.tetrominoes += 1self.cleared_lines += lines_clearedif not self.gameover:self.new_piece()if self.gameover:self.score -= 2return score, self.gameoverdef render(self, video=None):if not self.gameover:img = [self.piece_colors[p] for row in self.get_current_board_state() for p in row]else:img = [self.piece_colors[p] for row in self.board for p in row]img = np.array(img).reshape((self.height, self.width, 3)).astype(np.uint8)img = img[..., ::-1]img = Image.fromarray(img, "RGB")img = img.resize((self.width * self.block_size, self.height * self.block_size))img = np.array(img)img[[i * self.block_size for i in range(self.height)], :, :] = 0img[:, [i * self.block_size for i in range(self.width)], :] = 0img = np.concatenate((img, self.extra_board), axis=1)cv2.putText(img, "Score:", (self.width * self.block_size + int(self.block_size / 2), self.block_size),fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)cv2.putText(img, str(self.score),(self.width * self.block_size + int(self.block_size / 2), 2 * self.block_size),fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)cv2.putText(img, "Pieces:", (self.width * self.block_size + int(self.block_size / 2), 4 * self.block_size),fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)cv2.putText(img, str(self.tetrominoes),(self.width * self.block_size + int(self.block_size / 2), 5 * self.block_size),fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)cv2.putText(img, "Lines:", (self.width * self.block_size + int(self.block_size / 2), 7 * self.block_size),fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)cv2.putText(img, str(self.cleared_lines),(self.width * self.block_size + int(self.block_size / 2), 8 * self.block_size),fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)if video:video.write(img)cv2.imshow("Deep Q-Learning Tetris", img)cv2.waitKey(1)训练代码
import argparse
import os
import shutil
from random import random, randint, sampleimport numpy as np
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
import time
from src.deep_q_network import DeepQNetwork
from src.tetris import Tetris
from collections import dequedef get_args():parser = argparse.ArgumentParser("""Implementation of Deep Q Network to play Tetris""")parser.add_argument("--width", type=int, default=10, help="The common width for all images")parser.add_argument("--height", type=int, default=20, help="The common height for all images")parser.add_argument("--block_size", type=int, default=30, help="Size of a block")parser.add_argument("--batch_size", type=int, default=512, help="The number of images per batch")parser.add_argument("--lr", type=float, default=1e-3)parser.add_argument("--gamma", type=float, default=0.99)parser.add_argument("--initial_epsilon", type=float, default=1)parser.add_argument("--final_epsilon", type=float, default=1e-3)parser.add_argument("--num_decay_epochs", type=float, default=2000)parser.add_argument("--num_epochs", type=int, default=3000)parser.add_argument("--save_interval", type=int, default=500)parser.add_argument("--replay_memory_size", type=int, default=30000,help="Number of epoches between testing phases")parser.add_argument("--log_path", type=str, default="tensorboard")parser.add_argument("--saved_path", type=str, default="trained_models")args = parser.parse_args()return argsdef train(opt):if torch.cuda.is_available():torch.cuda.manual_seed(123)else:torch.manual_seed(123)if os.path.isdir(opt.log_path):shutil.rmtree(opt.log_path)os.makedirs(opt.log_path)writer = SummaryWriter(opt.log_path)env = Tetris(width=opt.width, height=opt.height, block_size=opt.block_size)model = DeepQNetwork()optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)criterion = nn.MSELoss()state = env.reset()if torch.cuda.is_available():model.cuda()state = state.cuda()replay_memory = deque(maxlen=opt.replay_memory_size)epoch = 0t1 = time.time()total_time = 0best_score = 1000while epoch < opt.num_epochs:start_time = time.time()next_steps = env.get_next_states()# Exploration or exploitationepsilon = opt.final_epsilon + (max(opt.num_decay_epochs - epoch, 0) * (opt.initial_epsilon - opt.final_epsilon) / opt.num_decay_epochs)u = random()random_action = u <= epsilonnext_actions, next_states = zip(*next_steps.items())next_states = torch.stack(next_states)if torch.cuda.is_available():next_states = next_states.cuda()model.eval()with torch.no_grad():predictions = model(next_states)[:, 0]model.train()if random_action:index = randint(0, len(next_steps) - 1)else:index = torch.argmax(predictions).item()next_state = next_states[index, :]action = next_actions[index]reward, done = env.step(action, render=True)if torch.cuda.is_available():next_state = next_state.cuda()replay_memory.append([state, reward, next_state, done])if done:final_score = env.scorefinal_tetrominoes = env.tetrominoesfinal_cleared_lines = env.cleared_linesstate = env.reset()if torch.cuda.is_available():state = state.cuda()else:state = next_statecontinueif len(replay_memory) < opt.replay_memory_size / 10:continueepoch += 1batch = sample(replay_memory, min(len(replay_memory), opt.batch_size))state_batch, reward_batch, next_state_batch, done_batch = zip(*batch)state_batch = torch.stack(tuple(state for state in state_batch))reward_batch = torch.from_numpy(np.array(reward_batch, dtype=np.float32)[:, None])next_state_batch = torch.stack(tuple(state for state in next_state_batch))if torch.cuda.is_available():state_batch = state_batch.cuda()reward_batch = reward_batch.cuda()next_state_batch = next_state_batch.cuda()print("state_batch",state_batch.shape)q_values = model(state_batch)model.eval()with torch.no_grad():next_prediction_batch = model(next_state_batch)model.train()y_batch = torch.cat(tuple(reward if done else reward + opt.gamma * prediction for reward, done, prediction inzip(reward_batch, done_batch, next_prediction_batch)))[:, None]optimizer.zero_grad()loss = criterion(q_values, y_batch)loss.backward()optimizer.step()end_time = time.time()use_time = end_time-t1 -total_timetotal_time = end_time-t1print("Epoch: {}/{}, Action: {}, Score: {}, Tetrominoes {}, Cleared lines: {}, Used time: {}, total used time: {}".format(epoch,opt.num_epochs,action,final_score,final_tetrominoes,final_cleared_lines,use_time,total_time))writer.add_scalar('Train/Score', final_score, epoch - 1)writer.add_scalar('Train/Tetrominoes', final_tetrominoes, epoch - 1)writer.add_scalar('Train/Cleared lines', final_cleared_lines, epoch - 1)if epoch > 0 and epoch % opt.save_interval == 0:print("save interval model: {}".format(epoch))torch.save(model, "{}/tetris_{}".format(opt.saved_path, epoch))elif final_score>best_score:best_score = final_scoreprint("save best model: {}".format(best_score))torch.save(model, "{}/tetris_{}".format(opt.saved_path, best_score))if __name__ == "__main__":opt = get_args()train(opt)测试代码
import argparse
import torch
import cv2
from src.tetris import Tetrisdef get_args():parser = argparse.ArgumentParser("""Implementation of Deep Q Network to play Tetris""")parser.add_argument("--width", type=int, default=10, help="The common width for all images")parser.add_argument("--height", type=int, default=20, help="The common height for all images")parser.add_argument("--block_size", type=int, default=30, help="Size of a block")parser.add_argument("--fps", type=int, default=300, help="frames per second")parser.add_argument("--saved_path", type=str, default="trained_models")parser.add_argument("--output", type=str, default="output.mp4")args = parser.parse_args()return argsdef test(opt):if torch.cuda.is_available():torch.cuda.manual_seed(123)else:torch.manual_seed(123)if torch.cuda.is_available():model = torch.load("{}/tetris_2000".format(opt.saved_path))else:model = torch.load("{}/tetris_2000".format(opt.saved_path), map_location=lambda storage, loc: storage)model.eval()env = Tetris(width=opt.width, height=opt.height, block_size=opt.block_size)env.reset()if torch.cuda.is_available():model.cuda()out = cv2.VideoWriter(opt.output, cv2.VideoWriter_fourcc(*"MJPG"), opt.fps,(int(1.5*opt.width*opt.block_size), opt.height*opt.block_size))while True:next_steps = env.get_next_states()next_actions, next_states = zip(*next_steps.items())next_states = torch.stack(next_states)if torch.cuda.is_available():next_states = next_states.cuda()predictions = model(next_states)[:, 0]index = torch.argmax(predictions).item()action = next_actions[index]_, done = env.step(action, render=True, video=out)if done:out.release()breakif __name__ == "__main__":opt = get_args()test(opt)结果展示

相关文章:
强化学习DQN之俄罗斯方块
强化学习DQN之俄罗斯方块强化学习DQN之俄罗斯方块算法流程文件目录结构模型结构游戏环境训练代码测试代码结果展示强化学习DQN之俄罗斯方块 算法流程 本项目目的是训练一个基于深度强化学习的俄罗斯方块。具体来说,这个代码通过以下步骤实现训练: 首先…...

1.3总线:并行总线、串行总线、单工、半双工、全双工、总线宽度、总线带宽、总线的分类、数据总线、地址总线、控制总线
1.3总线:并行总线、串行总线、单工、半双工、全双工、总线宽度、总线带宽、总线的分类、数据总线、地址总线、控制总线总线并行总线、串行总线单工、半双工、全双工总线宽度总线带宽总线的分类数据总线(Data Bus,DB)地址总线&…...

Linux驱动开发—设备树开发详解
设备树开发详解 设备树概念 Device Tree是一种描述硬件的数据结构,以便于操作系统的内核可以管理和使用这些硬件,包括CPU或CPU,内存,总线和其他一些外设。 Linux内核从3.x版本之后开始支持使用设备树,可以实现驱动代…...

深入浅出C++ ——继承
文章目录一、继承的相关概念1. 继承的概念2. 继承格式3. 继承方式4. 访问限定符5. 继承基类成员访问方式的变化二、基类和派生类对象赋值转换三、继承中的作用域四、派生类的默认成员函数五、继承与友元六、继承与静态成员七、菱形继承及菱形虚拟继承1. 单继承2. 多继承3. 菱形…...
设计模式C++实现20: 桥接模式(Bridge)
部分内容参考大话设计模式第22章;本实验通过C语言实现。 一 基本原理 意图:将抽象部分和实现部分分离,使它们都可以独立变化。 上下文:某些类型由于自身的逻辑,具有两个或多个维度的变化。如何应对“多维度的变化”…...

Android中的Rxjava
要使用Rxjava首先要导入两个包,其中rxandroid是rxjava在android中的扩展 implementation io.reactivex:rxandroid:1.2.1implementation io.reactivex:rxjava:1.2.0observer 是一个观察者接口,泛型T为观察者观察数据的类型,里面只有三个方法&a…...

【RocketMQ】源码详解:消息储存服务加载、文件恢复、异常恢复
消息储存服务加载 入口:org.apache.rocketmq.store.DefaultMessageStore#load 在创建brokerContriller时会调用初始化方法初始化brokerController,在初始化方法中会进行消息储存服务的加载 this.messageStore.load(); 加载方法主要是加载一些必要的参数和数据,如配…...

数字IC设计工程师是做什么的?
随着我国半导体产业的发展,近几年的新入行的从业人员,除了微电子相关专业的,还有就是物理、机械、数学、计算机等专业,很多人对这一高薪行业充满了好奇,那么数字IC设计工程师到底是做什么的? 首先来看看数…...

【040】134. 加油站[简单模拟 + 逻辑转化]
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。 给定两个整数数组 gas 和 cost &am…...
Python用selenium实现自动登录和下单的脚本
前言 学python对selenium应该不陌生吧 Selenium 是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动…...
Cartographer源码无死角解析-(55) 2D后端优化→AppendNode()、class MapById、 PoseGraphData、)
(02)Cartographer源码无死角解析-(55) 2D后端优化→AppendNode()、class MapById、 PoseGraphData、
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解(02)Cartographer源码无死角解析-链接如下: (02)Cartographer源码无死角解析- (00)目录_最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/127350885 文末正下方中心提供了本…...

如何在jmeter中把响应中的数据提取出来并引用
jmeter做接口测试过程中,经常遇到请求需要用到token的时候,我们可以把返回token的接口用后置处理器提取出来,但是在这种情况下,只能适用于当前的线程组,其他线程组无法引用到提取的token变量值,所以必须要生…...

2023环翠区编程挑战赛中学组题解
T1. 出栈序列 题目描述 栈是一种“先进后出”的数据结构,对于一个序列1,2,...,n1,2, ...,n1,2,...,n,其入栈顺序是1,2,...n1,2, ...n1,2,...n,但每个元素出栈的时机可以自由选择。 例如111入栈、111出栈,222入栈、333入栈、333…...

手撸一个Switch开关组件
一、前言 手撸系列又来了,这次咱们来撸一个Switch开关组件,废话不多说,咱们立刻发车。 二、使用效果 三、实现分析 首先我们先不想它的这个交互效果,我们就实现“不合格”时的一个静态页面,静态页面大致如下&#x…...
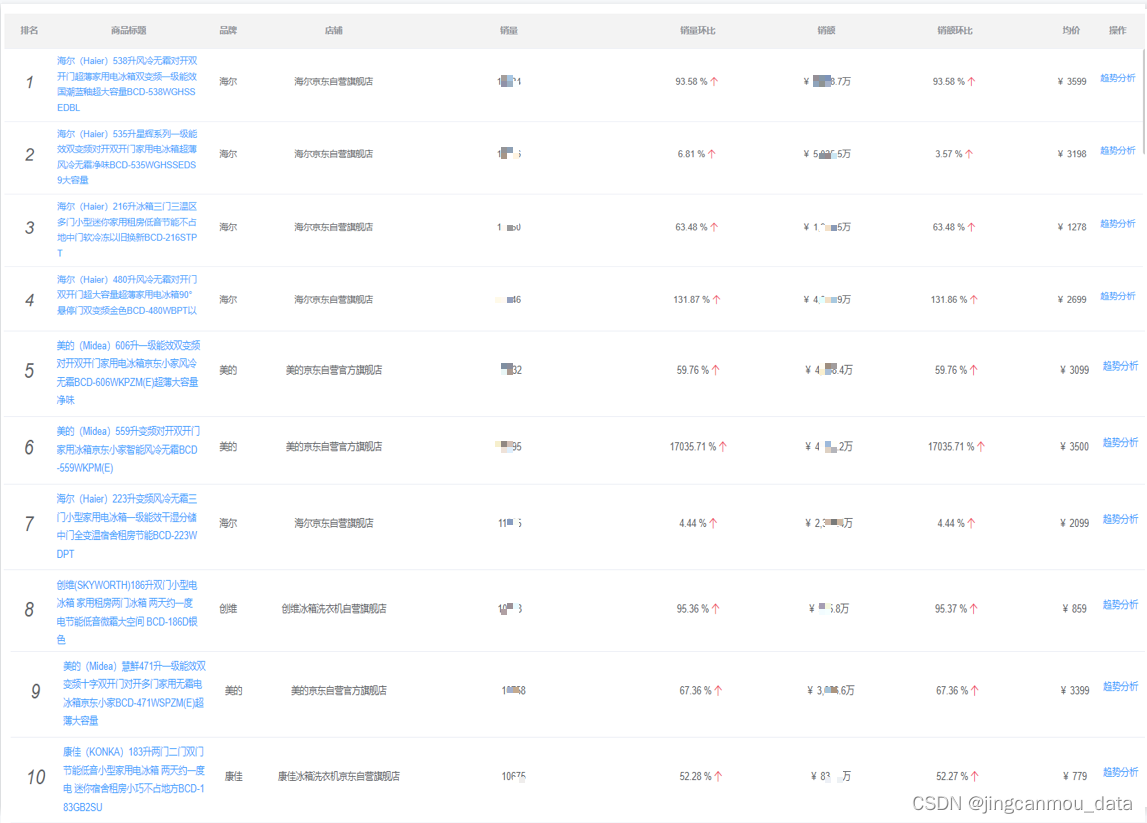
2023年1月冰箱品牌销量排行:销量环比增长26%,销售额36亿+
鲸参谋电商大数据2023年1月京东平台“冰箱”销售数据出炉! 根据鲸参谋平台电商数据显示,2023年1月份,在京东平台上,冰箱的销量将近130万件,环比增长26%,同比下滑8%;销售额达36亿,环比…...
DSP CCS 开发问题总结及解决办法
文章目录 问题汇总 1. CCS编译器的Project菜单栏工程导入选项丢失,怎么解决! 1.1启动CCS后发现导入工程菜单栏丢失,无法导入工程文件。 1.2方法一 工程选项的导入工程文件丢失,如果要重新获得相应的选项,就需要删除当前…...
Vue3.x+Element Plus仿制Acro Design简洁模式分页器组件
Vue3.xElement Plus仿制Acro Design简洁模式分页器组件 开发中难免会遇到宽度很窄的列表需要使用分页器的情况,这时若使用Element Plus组件的分页器会导致分页器内容超出展示的区域,而Element Plus组件中目前没有Acro Design那样小巧的分页器(…...

经典文献阅读之--VoxelMap(体素激光里程计)
0. 简介 作为激光里程计,常用的方法一般是特征点法或者体素法,最近Mars实验室发表了一篇文章《Efficient and Probabilistic Adaptive Voxel Mapping for Accurate Online LiDAR Odometry》,同时还开源了代码在Github上。文中为雷达里程计提…...
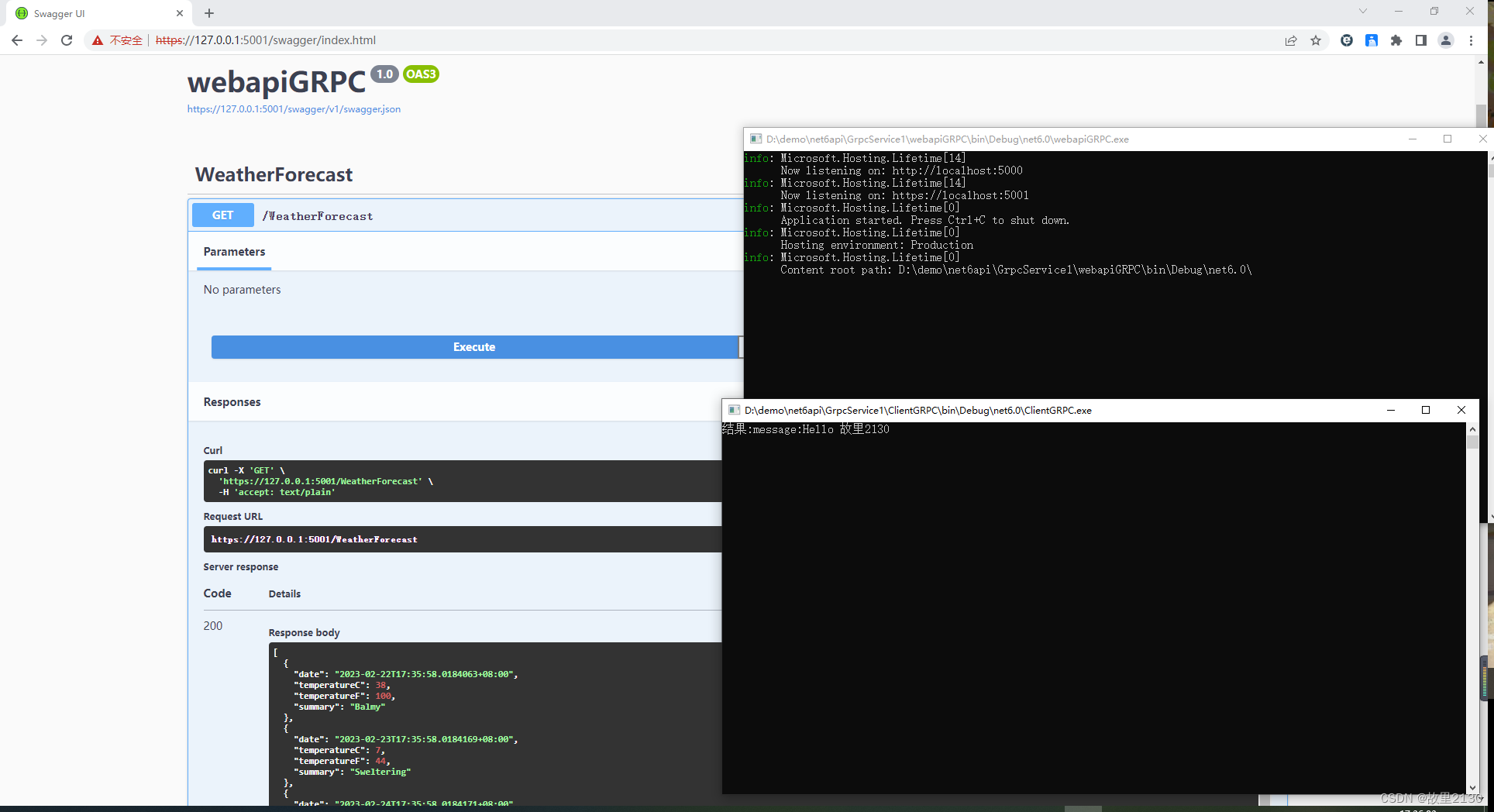
.NET6中使用GRPC详细描述
Supported languages | gRPC,官网。至于原理就不说了,可以百度原理之后,然后再结合代码,事半功倍,就能很好理解GRPC了。 目录 一、简单使用 二、实际应用 一、简单使用 1.使用vs2022创建一个grpc程序,…...

ML@矩阵微积分基础
文章目录矩阵微积分Matrix calculus记法简单Jacobi Matrix分子记法分母记法一般形式的Jacobi MatrixTypes of matrix derivative向量求导向量对标量求导标量对向量求导向量对向量求导矩阵求导矩阵对标量求导(切矩阵)标量对矩阵求导记法向量求导 向量对标量求导标量对向量求导向…...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...

ImageGlass:一个支持90+图像格式的轻量级Windows图片查看器
ImageGlass:一个支持90图像格式的轻量级Windows图片查看器 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 还在为Windows自带的图片查看器功能单一而烦恼吗&…...