HDFS 集群动态节点管理
目录
一、动态扩容、节点上线
1.1 背景
1.2 扩容步骤
1.2.1 新机器基础环境准备
1.2.2 Hadoop 配置
1.2.3 手动启动 DataNode 进程
1.2.4 Web 页面查看情况
1.2.5 DataNode 负载均衡服务
二、动态缩容、节点下线
2.1 背景
2.2 缩容步骤
2.2.1 添加退役节点
2.2.2 刷新集群
2.2.3 手动关闭 DataNode 进程
2.2.4 DataNode 负载均衡服务
三、HDFS 集群黑、白名单机制
3.1 白名单
3.2 黑名单
一、动态扩容、节点上线
1.1 背景
节点上线:已有 HDFS 集群容量已不能满足存储数据的需求,需要在原有集群基础上动态添加新的 DataNode 节点。
俗称动态扩容、节点服役。
1.2 扩容步骤
1.2.1 新机器基础环境准备
准备一台新的机器,设置好主机名、IP(192.168.170.139),做好 Hosts 映射、SSH 免密登录和时间同步,关闭防火墙以及安装 JDK 环境。
具体操作请看这篇文章:Hadoop 3.2.4 集群搭建详细图文教程_Stars.Sky的博客-CSDN博客
1.2.2 Hadoop 配置
- 修改 namenode 节点 workers 配置文件,增加新节点主机名,便于后续一键启停。
- 从 namenode 节点复制 scp hadoop 安装包到新节点,注意不包括 hadoop.tmp.dir 指定的数据存储目录。
- 新机器上配置 hadoop 环境变量(/etc/profile)。
1.2.3 手动启动 DataNode 进程
[root@hadoop04 ~]# hdfs --daemon start datanode
1.2.4 Web 页面查看情况
地址:http://hadoop01:9870/

1.2.5 DataNode 负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载不均衡。因此最后还需要对 hdfs 负载设置均衡。(在 Hadoop01 执行)
# 首先设置数据传输带宽
hdfs dfsadmin -setBalancerBandwidth 104857600# 然后启动 Balancer,等待集群自均衡完成即可
hdfs balancer -threshold 5
二、动态缩容、节点下线
2.1 背景
节点下线:服务器需要进行退役更换,需要在当下的集群中停止某些机器上 datanode 的服务。
俗称动态缩容、节点退役。
2.2 缩容步骤
2.2.1 添加退役节点
在 namenode 机器的 hdfs-site.xml 配置文件中需要提前配置 dfs.hosts.exclude 属性,该属性指向的文件就是所谓的黑名单列表,会被 namenode 排除在集群之外。如果文件内容为空,则意味着不禁止任何机器。
提前配置好的目的是让 namenode 启动的时候就能加载到该属性,只不过还没有指定任何机器。否则就需要重启 namenode 才能加载,因此这样的操作我们称之为具有前瞻性的操作。
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hdfs-site.xml
<property><name>dfs.hosts.exclude</name><value>/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/excludes</value>
</property>[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp hdfs-site.xml hadoop02:$PWD
hdfs-site.xml 100% 1256 632.5KB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp hdfs-site.xml hadoop03:$PWD
hdfs-site.xml 100% 1256 112.6KB/s 00:00
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# scp hdfs-site.xml hadoop04:$PWD
hdfs-site.xml 100% 1256 516.4KB/s 00:00编辑 dfs.hosts.exclude 属性指向的 excludes 文件,添加需要退役的主机名称。注意:如果副本数是 3,服役的节点小于等于 3,是不能退役成功的,需要修改副本数后才能退役。
# 重新启动 HDFS 集群,使配置生效
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# stop-dfs.sh
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# start-dfs.sh [root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim excludes
hadoop042.2.2 刷新集群
在 namenode 所在的机器刷新节点:hdfs dfsadmin -refreshNodes
等待退役节点状态为 decommissioned(所有块已经复制完成)。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# hdfs dfsadmin -refreshNodes
Refresh nodes successful正在退役:

退役完成:
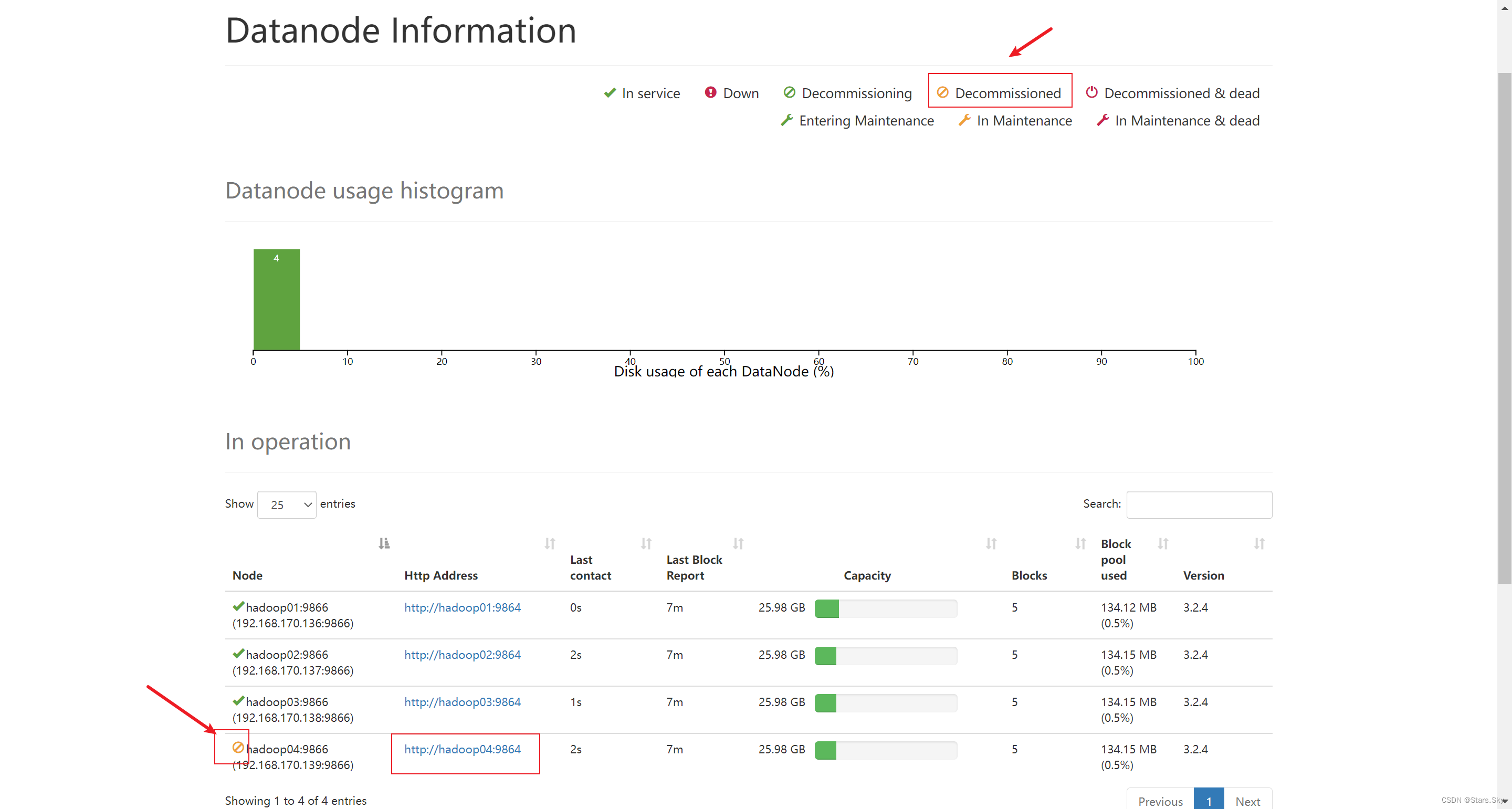
2.2.3 手动关闭 DataNode 进程
[root@hadoop04 ~]# hdfs --daemon stop datanode
[root@hadoop04 ~]# jps
20310 Jps2.2.4 DataNode 负载均衡服务
如果需要可以对已有的 HDFS 集群进行负载均衡服务:
hdfs balancer –threshold 5
三、HDFS 集群黑、白名单机制
3.1 白名单
所谓的白名单指的是允许哪些机器加入到当前的 HDFS 集群中,是一种准入机制。白名单由 dfs.hosts 参数指定,该参数位于 hdfs-site.xml。默认值为空。dfs.hosts 指向文件,该文件包含允许连接到 namenode 的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机准入。
3.2 黑名单
所谓的黑名单指的是禁止哪些机器加入到当前的 HDFS 集群中,是一种禁入机制。黑名单由dfs.hosts.exclude 参数指定,该参数位于 hdfs-site.xml。默认值为空。dfs.hosts.exclude 指向文件,该文件包含不允许连接到名称节点的主机列表。必须指定文件的完整路径名。如果该值为空,则不禁止任何主机加入。
上一篇文章:Hadoop 3.2.4 集群搭建详细图文教程_Stars.Sky的博客-CSDN博客
相关文章:
HDFS 集群动态节点管理
目录 一、动态扩容、节点上线 1.1 背景 1.2 扩容步骤 1.2.1 新机器基础环境准备 1.2.2 Hadoop 配置 1.2.3 手动启动 DataNode 进程 1.2.4 Web 页面查看情况 1.2.5 DataNode 负载均衡服务 二、动态缩容、节点下线 2.1 背景 2.2 缩容步骤 2.2.1 添加退役节点 …...
postman9.12.汉化版(附有下载链接)
想用英文版本的可以直接点击下载最新版本 这里直接付上9.12.2版本的下载链接,如果大家要下载别的版本,可以直接修改链接里面的版本号即可 ,下面是汉化包下载 链接:https://pan.baidu.com/s/1izK3HfqlfXJdq6KIYeJ2zw?pwdpetk 提…...
mysql与msql2数据驱动
mysql基本使用 数据库操作(DDL) -- 数据考操作 -- 1.查询所有数据库 SHOW DATABASES;-- 2.选择数据库 USE learn_mysql;-- 3.当前正在使用的数据库 SELECT DATABASE();-- 4.创建数据库 CREATE DATABASE IF NOT EXISTS learn_mysql;-- 5.删除数据库 DRO…...

解决微信小程序回调地狱问题
一、背景 小程序开发经常遇到根据网络请求结果,然后继续 处理下一步业务操作,代码如下: //1第一个请求 wx.request({url:"https://example.com/api/",data:data,success:function(res){//2第二个请求 wx.request({url:"http…...

cron介绍
cron表达式在线生成 在使用定时调度任务的时候,我们最常用的,就是cron表达式了。通过cron表达式来指定任务在某个时间点或者周期性的执行。 cron表达式的组成 cron表达式是一个字符串,由6到7个字段组成,用空格分隔。其中前6个字…...
mkp勒索病毒的介绍和防范,勒索病毒解密,数据恢复
mkp勒索病毒是一种新兴的电脑病毒,它会对感染的电脑进行加密,并要求用户支付一定的赎金才能解锁。这种病毒已经引起了全球范围内的关注,因为它不仅具有高危害性,而且还有很强的传播能力。本文将对mkp勒索病毒进行详细介绍…...

【面试精品】关于面试会遇到的Apache相关的面试题
1. Apache HTTP Server 基于什么协议提供网页浏览服务? 答:基于标准的http网络协议提供网页浏览服务。 2. 简述编译安装httpd软件包的基本过程? 答:解包,配置,编译,安装。 3. 编译安装httpd软…...

python对文件转md5,用于文件重复过滤
直接上代码 import hashlibdef calculate_md5(file_path):# 创建 MD5 哈希对象md5_hash hashlib.md5()# 打开文件并逐块读取,更新哈希值with open(file_path, rb) as file:while True:data file.read(8192) # 逐块读取文件,每块大小为 8192 字节if n…...

mac苹果电脑删除顽固残留软件图标
核心:删除“启动台”数据库里对应app的信息 1、打开访达(Finder),点击最顶部菜单栏的【前往》前往文件夹】,接着输入【/private/var/folders】 2、在弹出的访达(Finder)窗口搜索栏输入【com.ap…...

【jsvue】联合gtp仿写一个简单的vue框架,以此深度学习JavaScript
用 gtp 学习 Vue 生命周期的原理 lifecycle.js function Vue(options) {// 将选项保存到实例的 $options 属性中this.$options options;// 若存在 beforeCreate 钩子函数,则调用之if (typeof options.beforeCreate function) {options.beforeCreate.call(this);…...

linux centos7 系统之编程:求水仙花数
在Python编程中,有列表、元组和字典三类变量可以使用,方便数据的存储与处理,而bash中仅有字符串变量、数组、函数可用,方法运用上受到限制,这与bash基于C语言,注重语法结构的严谨有关。而Python等高级语言更…...

git中的cherry-pick和merge有些区别以及cherry-pick怎么用
git中的cherry-pick和merge在使用场景上有些区别: cherry-pick用于将另一个分支的某一次或几次commit应用到当前分支。它可以选择性地拉取代码修改。merge用于将两个分支合并成一个新分支。它会把整个分支上的所有修改都合并过来。 具体区别:cherry-pick通常用于将bug修复从发…...
【前端】CSS-Flex弹性盒模型布局
目录 一、前言二、Flex布局是什么1、任何一个容器都可以指定为Flex布局2、行内元素也可以使用Flex布局3、Webkit内核的浏览器,必须加上-webkit前缀 三、基本概念四、flex常用的两种属性1、容器属性2、项目属性 五、容器属性1、flex-direction①、定义②、语句1&…...

Android AAPT: error: resource color 异常原因处理
异常体现: Android resource linking failed ERROR:E:\software\Developer\APP\GaoDeTest2\app\src\main\res\values\themes.xml:3:5-9:13: AAPT: error: resource color/purple_500 (aka com.example.gaodetest2:color/purple_500) not found.ERROR:E:\software\De…...
的概念)
C++std::function和std::bind()的概念
std::function: 一个通用的函数封装器,它允许你存储和调用任何可以被调用的东西,例如函数、函数指针、函数对象、Lambda 表达式等。 std::bind: 用于创建函数对象。一个可调用对象的绑定版本,可以提前绑定某些参数&am…...

QT Creator工具介绍及使用
一、QT的基本概念 QT主要用于图形化界面的开发, QT是基于C编写的一套界面相关的类库,如进程线程库,网络编程的库,数据库操作的库,文件操作的库等。 如何使用这个类库:类库实例化对象(构造函数) --> 学习…...

python爬虫13:pymysql库
python爬虫13:pymysql库 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生…...

权限管理 ACL、RBAC、ABAC的学习
ACL(Access Control List:访问控制列表) 最简单的一种方式,将权限直接与用户或用户组相关联,管理员直接给用户授予某些权限即可。 这种模型适用于小型和简单系统,权限一块较为简单,并且角色和权限的变化较少。 RBAC(R…...

python的re正则表达式
一、正在表达式的方法(): re是Python中用于处理正则表达式的内置库,提供了许多有用的方法。以下是其中几个常用的方法: re.match(pattern, string): 尝试从字符串的开头匹配一个模式,如果匹配成功则返回匹…...

【算法与数据结构】700、LeetCode二叉搜索树中的搜索
文章目录 一、题目二、解法三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、题目 二、解法 思路分析:二叉搜索树的性质:左节点键值 < 中间节点键值 < 右节点键值。那么我们根据此性质&am…...

STM32H7 SPI双机通信,为什么我强烈推荐你用硬件NSS引脚?一个上电时序问题引发的血案
STM32H7 SPI双机通信中硬件NSS引脚的工程实践价值 两块STM32H7开发板通过SPI进行通信时,你是否遇到过这样的场景:明明代码逻辑正确,但通信就是不稳定,时而正常时而失败?更令人困惑的是,这种问题往往与上电顺…...

创业团队如何利用多模型聚合平台优化产品开发流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用多模型聚合平台优化产品开发流程 对于小型创业团队而言,在快速迭代产品的过程中,大模型能…...

惠普OMEN游戏本终极性能优化:OmenSuperHub开源工具完全指南
惠普OMEN游戏本终极性能优化:OmenSuperHub开源工具完全指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件的臃…...
)
告别安装报错!Windows 10/11 保姆级 MySQL 5.7.44 配置指南(含my.ini文件详解)
Windows 10/11 下 MySQL 5.7.44 终极安装指南:从避坑到精通配置 每次在Windows系统上安装MySQL,总会有那么几个"经典"错误让人抓狂——服务启动失败、初始化报错、环境变量配置无效... 作为一个经历过无数次安装折磨的老手,我决定…...

ARM Cortex-R中断处理与ECC机制详解
1. ARM Cortex-R中断处理机制深度解析在嵌入式实时系统中,中断处理机制的设计直接影响系统的响应速度和可靠性。ARM Cortex-R系列处理器作为面向实时控制应用的处理器架构,其中断处理系统经过精心设计,能够满足工业控制、汽车电子等领域的严苛…...

机器人全身控制与SLAM系统核心技术解析
1. 机器人全身控制技术解析Sprout机器人采用的全身控制策略(Whole-Body Policy)通过分层控制架构实现了稳定运动与精准操作的平衡。该系统将控制分为三个主要层级:骨盆姿态控制、上肢柔顺控制和高度调节。这种分层设计使得机器人能够在保持上…...

Flutter聊天UI组件库flutter_chat_ui:快速构建高质量聊天界面
1. 项目概述与核心价值如果你正在用Flutter开发一个聊天应用,并且不想从零开始手搓UI组件,那么flyerhq/flutter_chat_ui这个开源库,绝对值得你花时间研究一下。它不是一个完整的聊天SDK,不负责消息的发送、接收和存储,…...

Threadline MCP:基于消息协议的线程管理与任务编排框架解析
1. 项目概述:从“Threadline MCP”看现代应用架构的线程管理革新最近在GitHub上看到一个挺有意思的项目,叫“vidursharma202-del/threadline-mcp”。光看这个名字,可能有点摸不着头脑,但拆解一下,“threadline”直译是…...

初创团队如何利用Taotoken控制AI实验成本并快速迭代产品
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken控制AI实验成本并快速迭代产品 对于资源有限的初创团队而言,在开发AI功能原型时,…...

ffmpeg-static 6.1.1版本:跨平台音视频处理的终极解决方案
ffmpeg-static 6.1.1版本:跨平台音视频处理的终极解决方案 【免费下载链接】ffmpeg-static ffmpeg static binaries for Mac OSX and Linux and Windows 项目地址: https://gitcode.com/gh_mirrors/ff/ffmpeg-static 在当今多媒体处理需求日益增长的开发环境…...