【C++】-- C++11基础常用知识点(下)
上篇: 【C++】-- C++11基础常用知识点(上)_川入的博客-CSDN博客
目录
新的类功能
默认成员函数
可变参数模板
可变参数
可变参数模板
empalce
lambda表达式
C++98中的一个例子
lambda表达式
lambda表达式语法
捕获列表
lambda表达底层
包装器
function包装器
bind绑定
新的类功能
默认成员函数
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
最后重要的是前4个,后两个用处不大。默认成员函数就是我们不写编译器会生成一个默认的。 C++11 新增了两个:移动构造函数和移动赋值运算符重载。
所以到了C++11后有8个默认成员函数。
移动构造函数和移动赋值运算符重载的又来以及原理:
【C++】-- C++11 - 右值引用和移动语义(上万字详细配图配代码从执行一步步讲解)_川入的博客-CSDN博客
只有在深拷贝的情况下才会有移动构造函数和移动赋值运算符重载。可以认为:
- 拷贝构造函数与拷贝赋值重载:针对于左值的拷贝。
- 移动构造函数和移动赋值重载:针对于右值的拷贝。
移动构造函数和移动赋值重载,编译器自行生成的默认成员函数,能用的条件的复杂度与苛刻程度远远大于:构造函数、析构函数 、拷贝构造函数 、拷贝赋值重载4个默认成员函数。(由于:取地址重载 、const 取地址重载几乎不用自己写,用编译器的即可,所以忽略)

- 编译器生成默认移动构造函数的条件:
没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个。那么编译器会自动生成一个默认移动构造。
- 编译器生成默认移动构造函数的实现:
默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝。自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
- 编译器生成默认移动赋值重载函数的条件:
- 编译器生成默认移动赋值重载函数的实现:
- 如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
class Person
{
public:Person(const char *name = "", int age = 0): _name(name), _age(age){}Person(const Person &p): _name(p._name), _age(p._age){}Person(Person &&p) = default;private:bit::string _name;int _age;
};int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);return 0;
}class Person
{
public:Person(const char *name = "", int age = 0): _name(name), _age(age){}Person(const Person &p) = delete;private:bit::string _name;int _age;
};
int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);return 0;
}可以使用default关键字强行让编译器生成,但是需要注意析构函数 、拷贝构造、拷贝赋值重载也会收到影响,需要自己写或也强制生成。没有什么意义,所以一般default关键字是用于构造,因为拷贝构造也属于构造,如果写了拷贝构造就不会默认生成构造了。
#问:如何用delete关键字实现一个类,只能再堆上创建对象?
平时我们创建的类,是可以在栈区、全局数据区上创建的。
class HeapOnly
{};int main()
{HeapOnly hp1; // 栈区static HeapOnly h2; // 全局数据区return 0;
}我们可以通过delete析构函数,然后使用new开辟类。
class HeapOnly
{
public:// HeapOnly()// {// str_ = new char[10];// }// void Destroy()// {// delete[] str_;// operator delete(this); // 内存管理之重载operator delete// }~HeapOnly() = delete;
private:char* str_;
};int main()
{// HeapOnly hp1; // 栈区 -- 会调析构// static HeapOnly h2; // 全局数据区 -- 会调析构// new出来的对象会调用构造 -- 这个时候会导致资源泄漏HeapOnly *ptr = new HeapOnly;operator delete(ptr);return 0;
}
- new是c++中的操作符,malloc是c中的一个函数。
- new不止是分配内存,而且会调用类的构造函数,同理delete会调用类的析构函数
- malloc只会单纯的分配内存,不会进行初始化类成员的工作,同样free也不会调用析构函数。
#问:
class HeapOnly { public:HeapOnly(){str_ = new char[10];}~HeapOnly() = delete; private:char* str_; };对于构造函数是new空间,因为不能调用析构而不能使用delete,导致值空间泄漏怎么办?
我们可以搞一个函数,利用函数将其释放。
class HeapOnly
{
public:HeapOnly(){str_ = new char[10];}void Destroy(){delete[] str_;operator delete(this); // 内存管理之重载operator delete// 也可以使用free}~HeapOnly() = delete;
private:char* str_;
};int main()
{// HeapOnly hp1; // 栈区 -- 会调析构// static HeapOnly h2; // 全局数据区 -- 会调析构// new出来的对象会调用构造 -- 这个时候会导致资源泄漏HeapOnly *ptr = new HeapOnly;ptr->Destroy();return 0;
}继承的时候要小心,因为指针是可能出现偏移的,继承之后,切片可能成员位置发生变化,operator delete(this);的释放位置就可能不对。
可变参数模板
可变参数
可变参数最早的出现是在C语言:

以printf,不确定参数传多少个参数,后面可以传一串值,也就可变参数,可以有0 ~ n个参数。底层是用数组实现的。
可变参数模板
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
template <class ...Args>
void ShowList(Args... args)
{}// (不一定非要写作:Args、args,可以换一个名字,只是这两个常用)#include <string>// 可变参数的函数模板
template <class ...Args>
void ShowList(Args... args)
{}int main()
{std::string str("hello");ShowList();ShowList(1);ShowList(1, 'A');ShowList(1, 'A', str);return 0;
}#include <string>
#include <iostream>// 可变参数的函数模板
template <class ...Args>
void ShowList(Args... args)
{std::cout << sizeof...(args) << std::endl;
}int main()
{std::string str("hello");ShowList();ShowList(1);ShowList(1, 'A');ShowList(1, 'A', str);return 0;
}Note:for(int i = 0; i< sizeof...(args); i++) {std::cout << args[i] << " "; // error:args[i]不支持 }语法不支持使用args[i]这样方式获取可变参数,所以我们需要用一些奇招来 一一 获取参数包的值。
第一种:递归函数方式展开参数包
将参数包改一改,增加一个参数。
#include <iostream>
#include <string>// 递归终止函数
template <class T>
void ShowList()
{std::cout << std::endl;
}// 展开函数
template <class T, class... Args>
void ShowList(const T& value, Args... args) // 第一个参数传给value,剩下的传给参数包args。
{cout << value << " ";ShowList(args...); // 参数超过0个递归调自己,参数0个调递归终止函数。
}int main()
{ShowList(1);ShowList(1, 'A');ShowList(1, 'A', std::string("sort"));return 0;
}
利用递归不断地推出参数包中的内容。
第二种:逗号表达式展开参数包
这种展开参数包的方式,不需要通过递归终止函数,是直接在ShowList函数体中展开的, PrintArg不是一个递归终止函数,只是一个处理参数包中每一个参数的函数。这种就地展开参数包的方式实现的关键是逗号表达式,因为逗号表达式会按顺序执行逗号前面的表达式。
#include <iostream>
#include <string> template <class T>
void PrintArg(cosnt T t)
{std::cout << t << " ";
}// 展开函数
template <class... Args>
void ShowList(Args... args)
{// 利用逗号表达式去初始化arr,arr编译的时候就会知道要开多大,这个时候就会依次展开args参数包。// 利用逗号表达式去取右边的值0。(逗号表达式会按顺序执行逗号前面的表达式)int arr[] = {(PrintArg(args), 0)...};std::cout << std::endl;
}int main()
{ShowList(1);ShowList(1, 'A');ShowList(1, 'A', std::string("sort"));return 0;
}同理,也可以优化为不适用逗号表达式展开参数包:
#include <iostream>
#include <string> template <class T>
int PrintArg(cosnt T t)
{std::cout << t << " ";return 0;
}// 展开函数
template <class... Args>
void ShowList(Args... args)
{// arr编译的时候就会知道要开多大,这个时候就会依次展开args参数包。int arr[] = { PrintArg(args)... };std::cout << std::endl;
}int main()
{ShowList(1);ShowList(1, 'A');ShowList(1, 'A', std::string("sort"));return 0;
}empalce
分析STL容器中的empalce相关接口函数:
https://cplusplus.com/reference/vector/vector/emplace/

emplace_back是在一个函数模板里面,把一个成员函数是实现成可变参数包。其就是通过将可变参数包不断不断的往下传,传到最下面去初始化对应数据,或者是链表的话就初始化节点里的数据。
template <class... Args>
void emplace_back (Args&&... args);#问:那么相对insert和emplace系列接口的优势到底在哪里呢?
// vector::emplace_back
#include <iostream>
#include <vector>int main ()
{std::vector<int> myvector;myvector.push_back(100);myvector.emplace_back(200);return 0;
}// vector::emplace_back
#include <iostream>
#include <vector>
#include <string>
#include <utility>int main()
{std::vector<std::pair<std::string, int>> myvector;myvector.push_back(std::make_pair("sort", 1));myvector.emplace_back(std::make_pair("sort", 1));myvector.emplace_back("sort", 1);return 0;
}效率上就emplace_back更好,因为make_pair是先构造,构造了一个pair。如此push_back就传了一个pair对象。所以调push_back是:
- 左值:构造 + 拷贝构造。
- 右值:构造 + 移动构造。
emplace_back是不用着急创建pair对象,我们可将这个参数包一直向下传递,直到最后需要插入数据的时候,直接用这个数据包创建pair对象。
- 直接构造。
所以emplace系列比insert系列接口不一定高效。
通过代码凸显区别:
不一定所有容器都会出现,于源码的实现有关系,此处使用list容器,并在VS2019实现出来的:
#include <iostream> #include <list> #include <string>class Date { public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){std::cout << "Date(int year = 1, int month = 1, int day = 1)" << std::endl;}Date(const Date& d):_year(d._year), _month(d._month), _day(d._day){std::cout << "Date(const Date& d)" << std::endl;}private:int _year;int _month;int _day; };int main() {std::list<Date> lt1;lt1.push_back(Date(2022, 11, 16));std::cout << "---------------------------------" << std::endl;lt1.emplace_back(2022, 11, 16);return 0; }

所以建议:这个这种场景下直接使用emplace系列接口。
lambda表达式
lambda也叫做匿名函数。
像函数使用的对象 / 类型:
- 函数指针 -- C++不喜欢的操作,所以有了仿函数。(全局的函数)
- 仿函数 / 函数对象。(全局的类)
- lambda。(局部)
C++98中的一个例子
因为由于仿函数有诸多的不便。如果待排序元素为自定义类型,需要用户定义排序时的比较规则,对于以下的三个成员一个就要创建2个(less、greater),就是6个。
#include <string>struct Goods
{std::string _name; // 名字double _price; // 价格int _evaluate; // 评价Goods(const char* str, double price, int evaluate):_name(str), _price(price), _evaluate(evaluate){}
};lambda表达式
lambda表达式语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
- [capture-list] : 捕捉列表。该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
- (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略(无参时可以省略)
- mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
- ->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
- {statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
注意:
#include <iostream>int main()
{// 两个数相加的lambda// 没有函数名,加一个捕捉列表[]而已。因为没有名字,所以调用不好调// 但是[](int a, int b) -> int{ return a + b; }整体是一个对象,所以就可以巧用auto。auto add1 = [](int a, int b) -> int{ return a + b; };std::cout << add1(1, 2) << std::endl;// 省略返回值auto add2 = [](int a, int b){ return a + b; };std::cout << add2(1, 2) << std::endl;
}于是对于前面的三个成员一个就要创建2个(less、greater),就是6个。解决:
#include <string>
#include <vector>
#include <algorithm>struct Goods
{std::string _name; // 名字double _price; // 价格int _evaluate; // 评价//...Goods(const char *str, double price, int evaluate): _name(str), _price(price), _evaluate(evaluate){}
};int main()
{std::vector<Goods> v = {{"苹果", 2.1, 5}, {"香蕉", 3, 4}, {"橙子", 2.2, 3}, {"菠萝", 1.5, 4}};sort(v.begin(), v.end(), [](const Goods &g1, const Goods &g2){ return g1._name < g2._name; });sort(v.begin(), v.end(), [](const Goods &g1, const Goods &g2){ return g1._name > g2._name; });sort(v.begin(), v.end(), [](const Goods &g1, const Goods &g2){ return g1._price < g2._price; });sort(v.begin(), v.end(), [](const Goods &g1, const Goods &g2){ return g1._price > g2._price; });sort(v.begin(), v.end(), [](const Goods &g1, const Goods &g2){ return g1._evaluate < g2._evaluate; });sort(v.begin(), v.end(), [](const Goods &g1, const Goods &g2){ return g1._evaluate > g2._evaluate; });
}#问:如何写一个交换swap函数?
可以像上面那样写,但是会非常的难看。
#include <iostream>int main()
{// 交换变量的lambda - 行数会多int x = 0, y = 1;auto swap1 = [](int &x1, int &x2) -> void{int tmp = x1; x1 = x2; x2 = tmp; };swap1(x, y);std::cout << x << ":" << y << std::endl;
}我们可以这样写:
#include <iostream>int main()
{// 交换变量的lambda - 行数会多int x = 0, y = 1;auto swap1 = [](int &x1, int &x2) -> void{int tmp = x1; x1 = x2; x2 = tmp; };swap1(x, y);std::cout << x << ":" << y << std::endl;
}捕获列表
#问:假如我们想不传参数交换x,y呢?
利用捕捉列表实现,注意:
- 想捕捉谁就写谁,只能捕捉跟lambda表达式同一个作用域的对象。
- 默认捕捉过来的变量不能修改 —— 加mutable让捕捉过来的变量可以修改(使用mutable必须加())。
- 默认捕捉是拷贝的方式捕捉,严格意义上说是传值捕捉。(lambda还是一个函数调用,是有栈帧的 —— 可以理解为:改变形参,不会改变实参)
#include <iostream>int main()
{// 交换变量的lambda - 行数会多int x = 0, y = 1;// 可以理解为:改变形参,不会改变实参auto swap = [x, y]()mutable{int tmp = x; x = y; y = tmp; };swap();std::cout << x << ":" << y << std::endl;
}
所以mutable在实际中不起价值作用。
捕获列表说明:
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。
- [var]:表示值传递方式捕捉变量var。
- [=]:表示值传递方式捕获所有父作用域中的变量(包括this)。
- [&var]:表示引用传递捕捉变量var。
- [&]:表示引用传递捕捉所有父作用域中的变量(包括this)。
- [this]:表示值传递方式捕捉当前的this指针。
注意:
- 父作用域指包含lambda函数的语句块
- 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
- 比如:
- [=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量。
- [&, a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量。
- 比如:
- 捕捉列表不允许变量重复传递,否则就会导致编译错误。
- 比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
- 在块作用域以外的lambda函数捕捉列表必须为空。
- 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错。
- lambda表达式之间不能相互赋值,即使看起来类型相同
#include <iostream>void (*PF)();int main()
{auto f1 = []{ std::cout << "hello world" << std::endl; };auto f2 = []{ std::cout << "hello world" << std::endl; };// f1 = f2; // 编译失败--->提示找不到operator=()// 允许使用一个lambda表达式拷贝构造一个新的副本auto f3(f2);f3();// 可以将lambda表达式赋值给相同类型的函数指针PF = f2;PF();return 0;
}lambda表达底层
函数对象,又称为仿函数,即可以想函数一样使用的对象,就是在类中重载了operator()运算符的类对象,与范围for很像。
范围for:
并没有看起来这么的智能,实际上是底层运用迭代器实现的。
class Rate
{
public:Rate(double rate) : _rate(rate){}double operator()(double money, int year){return money * _rate * year;}private:double _rate;
};int main()
{// 函数对象double rate = 0.49;Rate r1(rate);r1(10000, 2);// lamberauto r2 = [=](double monty, int year) -> double{return monty * rate * year;};r2(10000, 2);return 0;
}

仿函数的名称就是:lambda_uuid。所以lambda表达式对于我们是匿名的,对于编译器而言是有名的。实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
包装器
function包装器
#include <iostream>template <class F, class T>
T useF(F f, T x)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return f(x);
}
double f(double i)
{return i / 2;
}
struct Functor
{double operator()(double d){return d / 3;}
};
int main()
{// 函数名std::cout << useF(f, 11.11) << std::endl;// 仿函数对象std::cout << useF(Functor(), 11.11) << std::endl;// lamber表达式对象std::cout << useF([](double d)->double{ return d/4; }, 11.11) << std::endl;return 0;
}因为上述的 f 的类型不同,于是会被实例化成三个。
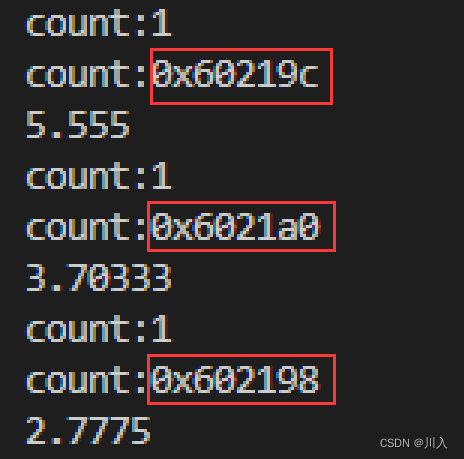
包装器可以很好的解决上面的问题,将其变为1份。
std::function在头文件<functional>// 类模板原型如下template <class T> function; // undefinedtemplate <class Ret, class... Args>class function<Ret(Args...)>;模板参数说明:Ret: 被调用函数的返回类型Args…:被调用函数的形参
// 使用方法如下:
#include <functional>
#include <iostream>int f(int a, int b)
{return a + b;
}struct Functor
{
public:int operator()(int a, int b){return a + b;}
};int main()
{// 函数名(函数指针)std::function<int(int, int)> func1 = f;std::cout << func1(1, 2) << std::endl;// 函数对象std::function<int(int, int)> func2 = Functor();std::cout << func2(1, 2) << std::endl;// lamber表达式std::function<int(int, int)> func3 = [](const int a, const int b){ return a + b; };std::cout << func3(1, 2) << std::endl;return 0;
}对于静态成员函数与非静态成员函数的不同:
//使用方法如下:
#include <functional>
#include <iostream>class Plus
{
public:static int plusi(int a, int b){return a + b;}double plusd(double a, double b){return a + b;}
};int main()
{//类的成员函数 -- 语法规定// 静态成员函数可以不用加&,可以加&。并且可以直接调用。std::function<int(int, int)> func4 = Plus::plusi; std::cout << func4(1, 2) << std::endl;// 非静态成员函数需要加&,并且不能直接调用,需要传对象,此处为Plus。(成员函数多传一个)std::function<double(Plus, double, double)> func5 = &Plus::plusd; std::cout << func5(Plus(), 1.1, 2.2) << std::endl;return 0;
}如果对于非静态成员函数,不想多传一个类对象的参数,可以通过绑定的方式解决这个问题。
所以对于上面的,因为上述的 f 的类型不同,于是会被实例化成三个,就可以解决了:
#include <iostream>
#include <functional>template <class F, class T>
T useF(F f, T x)
{static int count = 0;std::cout << "count:" << ++count << std::endl;std::cout << "count:" << &count << std::endl;return f(x);
}
double f(double i)
{return i / 2;
}
struct Functor
{double operator()(double d){return d / 3;}
};int main()
{// 函数指针std::function<double(double)> f1 = f;std::cout << useF(f1, 11.11) << std::endl;// 函数对象std::function<double(double)> f2 = Functor();std::cout << useF(f2, 11.11) << std::endl;// lamber表达式对象std::function<double(double)> f3 = [](double d)->double{ return d / 4; };std::cout << useF(f3, 11.11) << std::endl;return 0;
}

包装器的其他一些场景:
class Solution
{
public:int evalRPN(vector<string> &tokens){stack<long long> st;map<string, function<long long(long long, long long)>> opFuncMap ={{"+", [](long long i, long long j){ return i + j; }},{"-", [](long long i, long long j){ return i - j; }},{"*", [](long long i, long long j){ return i * j; }},{"/", [](long long i, long long j){ return i / j; }}};for (auto &str : tokens){if (opFuncMap.find(str) != opFuncMap.end()){long long right = st.top();st.pop();long long left = st.top();st.pop();st.push(opFuncMap[str](left, right));}else{// 1、atoi itoa// 2、sprintf scanf// 3、stoi to_string C++11st.push(stoll(str));}}return st.top();}
};bind绑定
std::bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一般而言,我们用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,返回一个接收M个(M可以大于N,但这么做没什么意义)参数的新函数。同时,使用std::bind函数还可以实现参数顺序调整等操作。
// 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);调用bind的一般形式:auto newCallable = bind(callable,arg_list);
库中就是使用了placeholders来占位:
https://legacy.cplusplus.com/reference/functional/placeholders/

其中的_1、_2、_3等,就是用来占位的。_1代表第1个参数,_2代表第2个参数……。调整的是形参的顺序。
#include <functional>
#include <iostream>int Div(int a, int b)
{return a / b;
}int main()
{int x = 10, y = 2;std::cout << Div(x, y) << std::endl;// 调整顺序 -- 鸡肋,一般用不上// _1, _2.... 定义在placeholders命名空间中,代表绑定函数对象的形参,// _1,_2... 分别代表第一个形参、第二个形参...//std::function<int(int, int)> bindFunc = bind(Div, std::placeholders::_2, std::placeholders::_1);auto bindFunc = bind(Div, std::placeholders::_2, std::placeholders::_1);// 传时候不会变std::cout << bindFunc(x, y) << std::endl;return 0;
}
可以理解为:
// x -> _1 ->a
// y -> _2 ->b。
auto bindFunc = bind(Div, _1, _2);
bindFunc(x, y);// x -> _2 ->b
// y -> _1 ->a。
auto bindFunc = bind(Div, _2, _1);
bindFunc(x, y);可以用绑定解决前面的非静态成员函数,需要传类对象(成员函数多传一个),以绑定参数解决 -> 调整个数。
#include <functional>
#include <iostream>
#include <map>int Plus(int a, int b)
{return a + b;
}int Mul(int a, int b, double rate)
{return a * b * rate;
}class Sub
{
public:int sub(int a, int b){return a - b;}
};// 11:50继续
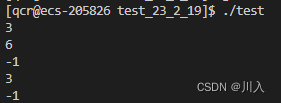
int main()
{// 调整个数, 绑定死固定参数std::function<int(int, int)> funcPlus = Plus;// 本来要传3个.// function<int(Sub, int, int)> funcSub = &Sub::sub;// 将其变为只传2个,将1个(此处Sub())固定在这个地方绑死 — 不能变。std::function<int(int, int)> funcSub = std::bind(&Sub::sub, Sub(), std::placeholders::_1, std::placeholders::_2);// 1.5就固定死了std::function<int(int, int)> funcMul = std::bind(Mul, std::placeholders::_1, std::placeholders::_2, 1.5);std::map<std::string, std::function<int(int, int)>> opFuncMap = {{ "+", Plus},{ "-", std::bind(&Sub::sub, Sub(), std::placeholders::_1, std::placeholders::_2)}};std::cout << funcPlus(1, 2) << std::endl;std::cout << funcMul(2, 2) << std::endl;std::cout << funcSub(1, 2) << std::endl;std::cout << opFuncMap["+"](1, 2) << std::endl;std::cout << opFuncMap["-"](1, 2) << std::endl;return 0;
}
相关文章:
【C++】-- C++11基础常用知识点(下)
上篇: 【C】-- C11基础常用知识点(上)_川入的博客-CSDN博客 目录 新的类功能 默认成员函数 可变参数模板 可变参数 可变参数模板 empalce lambda表达式 C98中的一个例子 lambda表达式 lambda表达式语法 捕获列表 lambda表达底层 …...
提到数字化,你想到哪些关键词
我们的生活中已经充满了数据,各种岗位例如运营、市场、营销上也都喜欢在职位要求加上一条利用数据、亦或是懂得数据分析。事实上,数据已经成为了构建现代社会的基本生产要素,并且因为不受自然环境的限制,已经成为了人们对未来社会…...

【蓝桥杯集训·每日一题】AcWing 1249. 亲戚
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴并查集一、题目 1、原题链接 1249. 亲戚 2、题目描述 或许你并不知道,你的某个朋友是你的亲戚。 他可能是你的曾祖父的外公的女婿的外甥女的表姐的孙子。 如果…...

iphone所有机型的屏幕尺寸
手机设备型号屏幕尺寸(吋)分辨率点数(pt)屏幕显示模式分辨率像素(px)屏幕比例iPhone SE4.03205682x640113616:9iPhone 6/6s/7/8/SE 24.73756672x750133416:9iPhone 6P/7P/8P5.54147363x1242220816:9iPhone XR/116.14148962x828179219.5:9iPhone X/XS/11P5.83758123x1125243619.…...
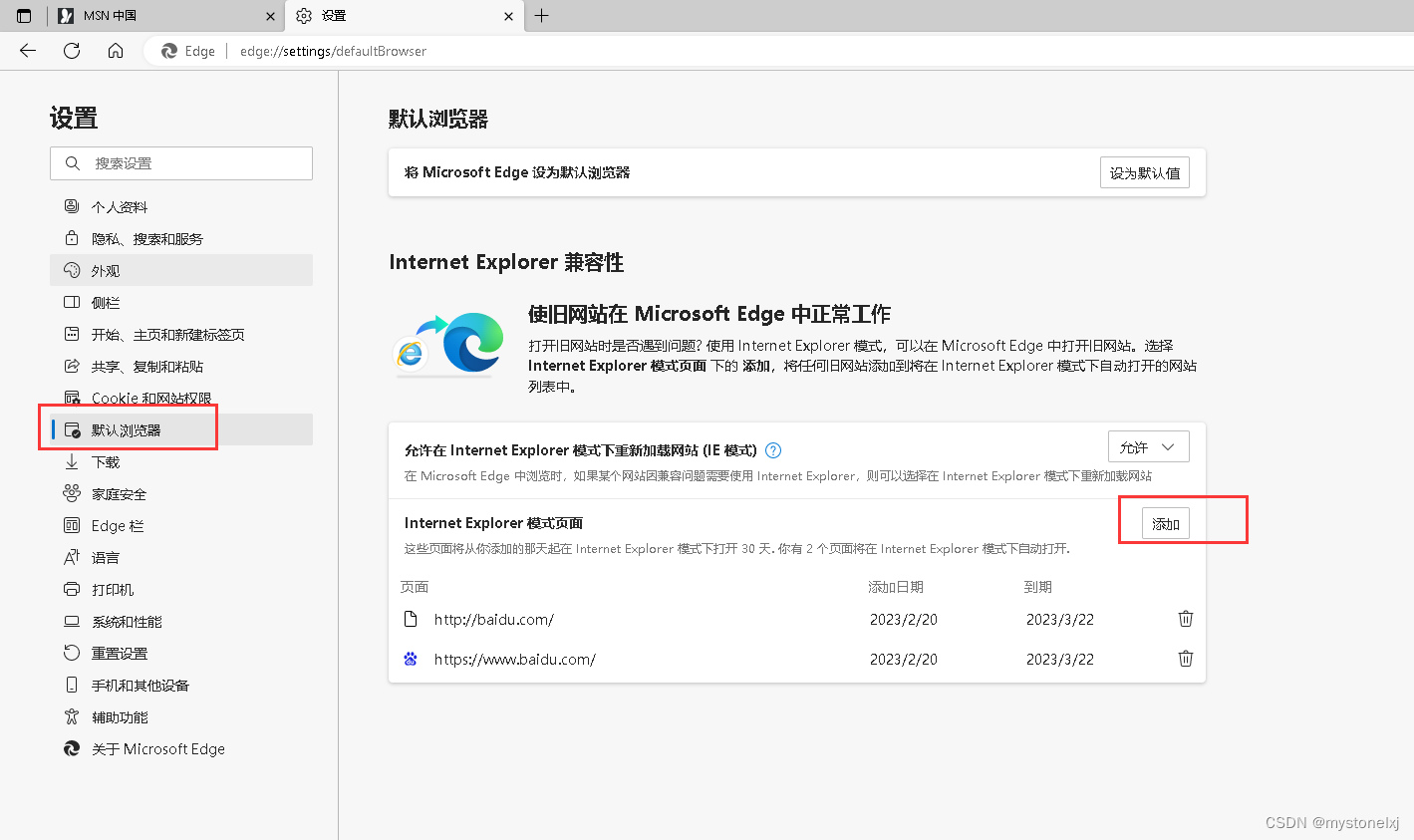
Windows10使用-处理IE自动跳转至Edge
文章目录 前言一、调整Edge二、调整Internet选项三、搜索栏的恢复总结前言 微软官方宣布,自2023年2月14日永久停止支持Internet Explorer 11浏览器。后期点击IE 图标将会自动跳转到Edge界面。对于一些网站,可能需要使用IE模式才能正常使用,这时候就需要做相应的调整,才能够…...
linux input子系统,gpio-keys,gpio中断使用
GPIO控制 嵌入式linux下应用编程会经常使用到gpio,GPIO 可以通过 sysfs 方式进行操控,进入到/sys/class/gpio 目录下,如下所示: 可以看到该目录下包含两个文件 export、 unexport 以及 5 个 gpiochipX(X 等于 0、 32、…...

分析称勒索攻击在非洲、中东与中国增长最快
Orange Cyberdefense(OCD)于 2022 年 12 月 1 日发布了最新的网络威胁年度报告。报告中指出,网络勒索仍然是头号威胁 ,也逐渐泛滥到世界各地。 报告中的网络威胁指的是企业网络中的某些资产被包括勒索软件在内的攻击进行勒索&…...

ArcPy批量合并矢量shape文件
当有大量矢量(.shp)格式文件需要合并成一个矢量文件时,可以考虑使用 ArcPy 进行批量合并,代码如下: # coding:utf-8 import os import arcpy from arcpy import envenv.workspace "C:/Users/Desktop/demo"…...

改写有序表的题目核心点
1、核心点 1)分析增加什么数据项可以支持题目 2)有序表一定要保持内部参与排序的key不重复 【补充说明:要存储重复的key值,要么将相同的key压在一起,要么将每个key再封装一层,用内存地址区分】 3&#…...
收藏这几个开源管理系统做项目,领导看了直呼牛X!
项目SCUI Admin 中后台前端解决方案Vue .NetCore 前后端分离的快速发开框架next-admin 适配移动端、pc的后台模板django-vue-admin-pro 快速开发平台Admin.NET 通用管理平台RuoYi 若依权限管理系统Vue3.2 Element-Plus 后台管理框架Pig RABC权限管理系统zheng 分布式敏捷开发…...
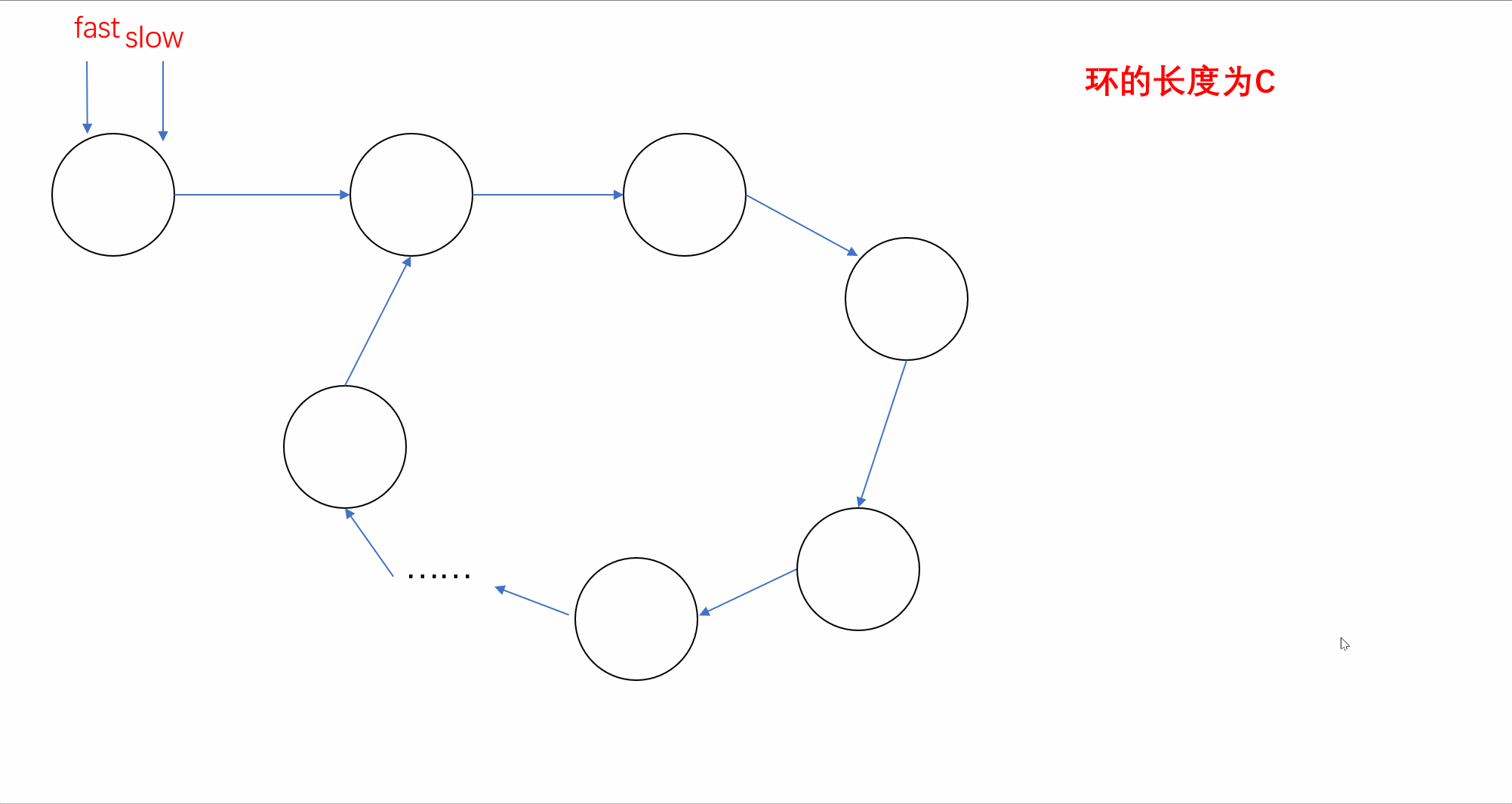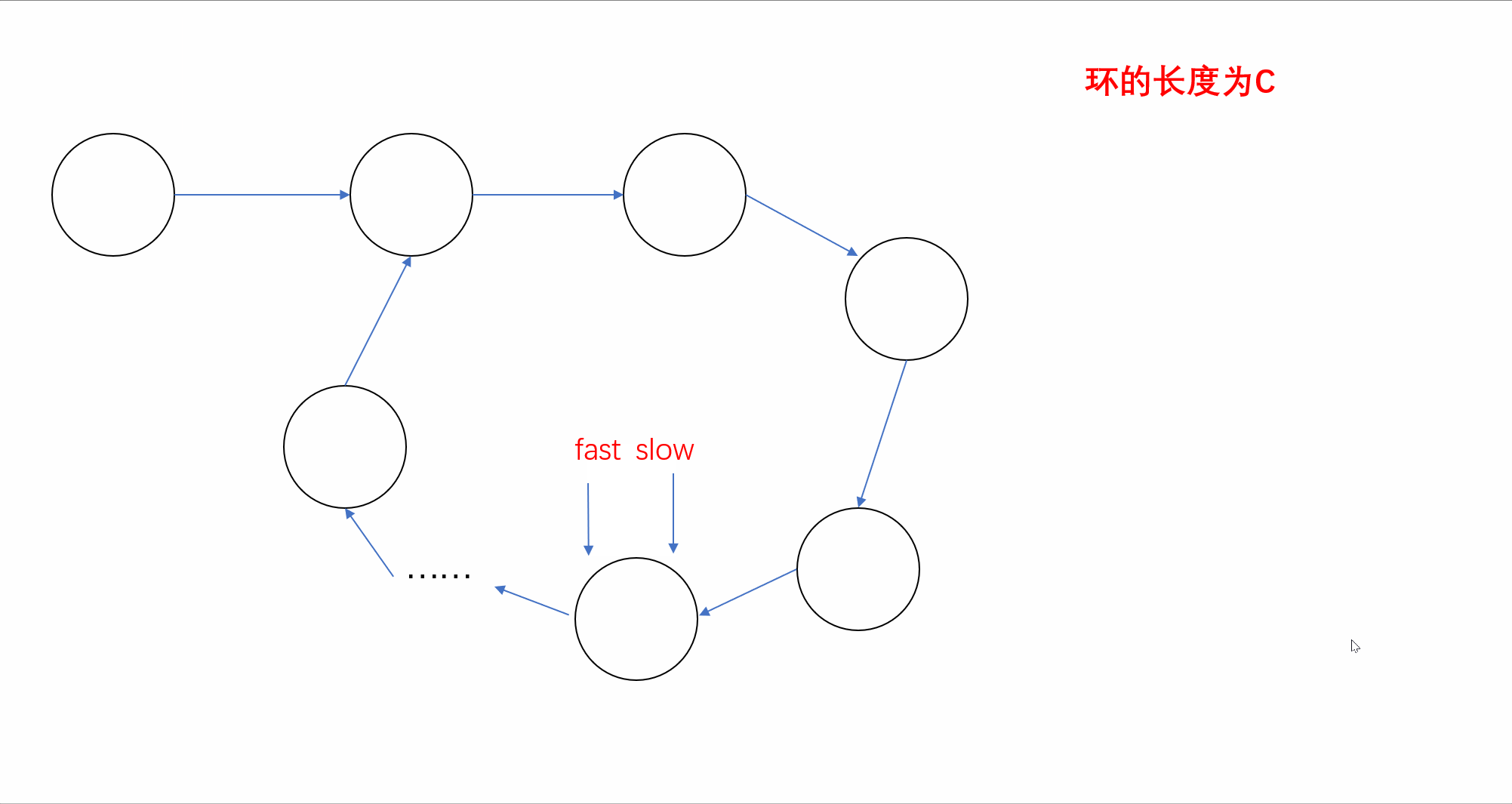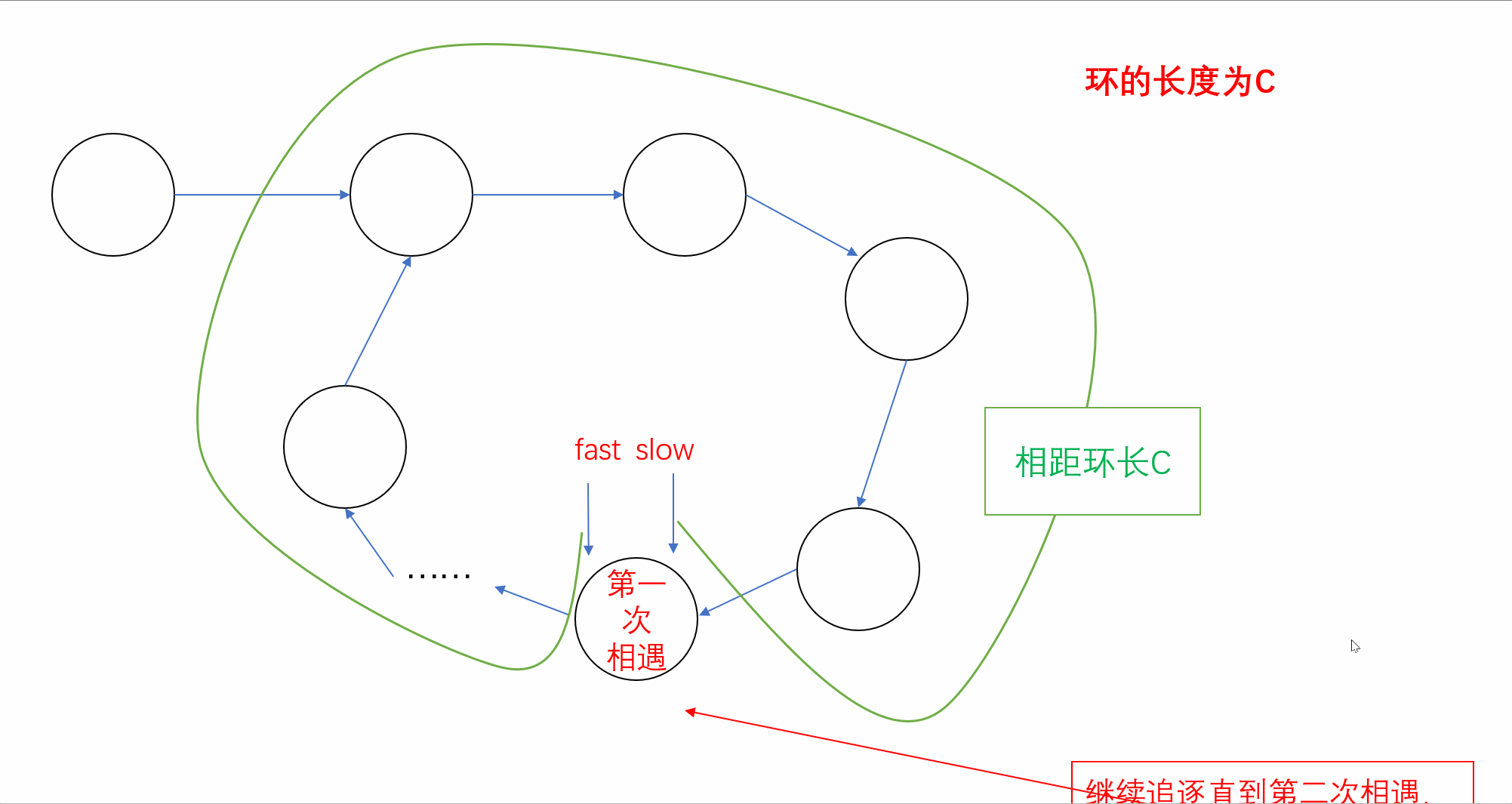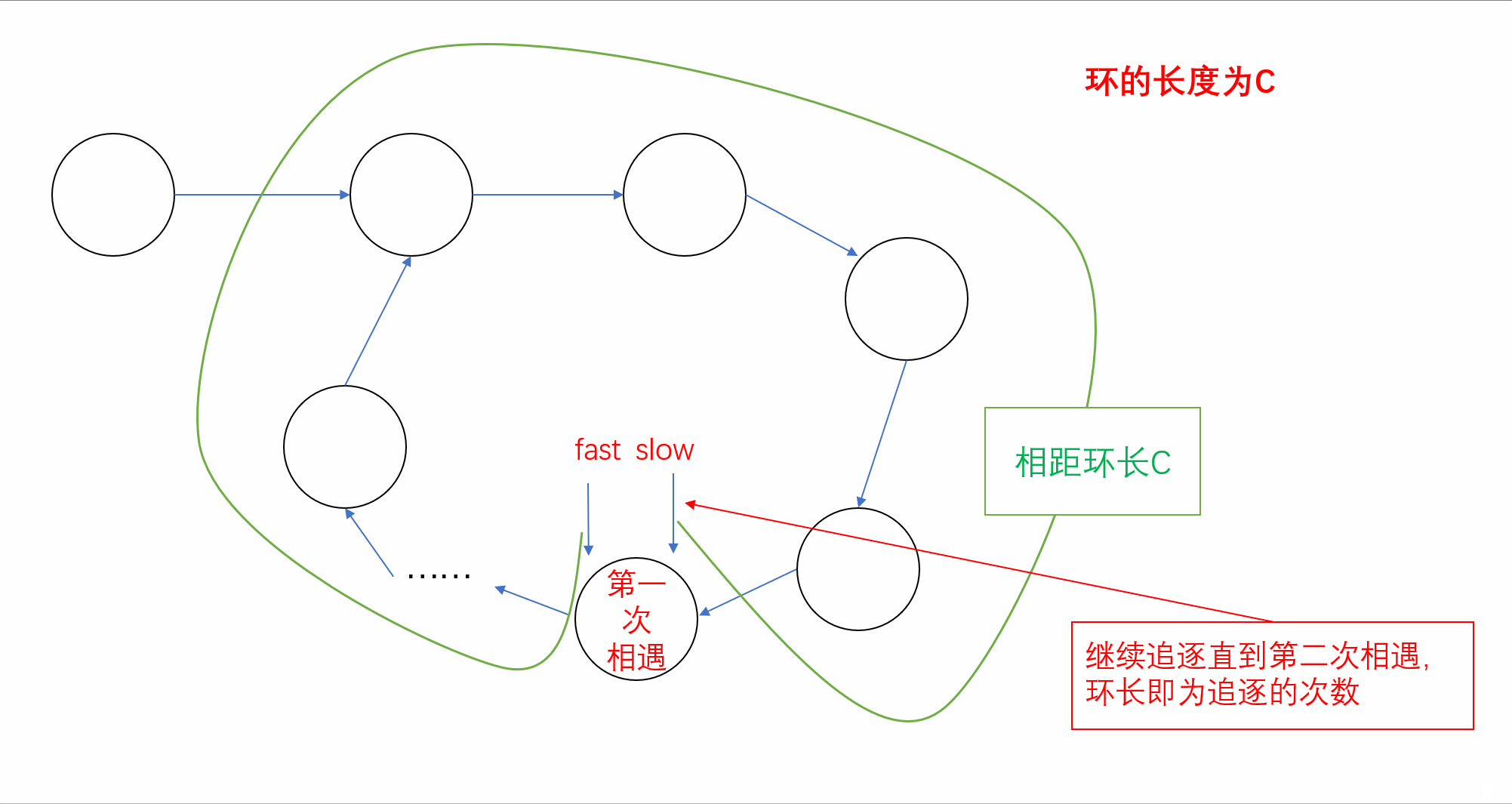
【刷题篇】链表(下)
前言🌸各位读者们好,本期我们来填填之前留下的坑,继续来讲解几道和链表相关的OJ题。但和上期单向链表不一样的是,我们今天的题目主要是于环形链表有关,下面让我们一起看看吧。💻本期的题目有:环…...
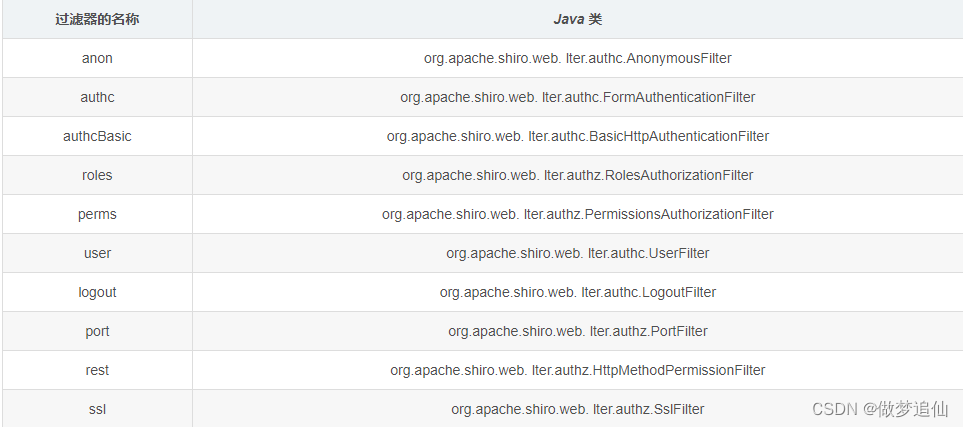
Shiro
Shiro 1.权限管理概述 2.Shiro权限框架 2.1 概念 2.2 Apache Shiro 与Spring Security区别 3.Shiro认证 3.1 基于ini认证 3.2 自定义Realm --认证 4.Shiro授权 4.1 基于ini授权 4.2 自定义realm – 授权 5.项目集成shiro 认证-授权注意点 5.1 认证…...
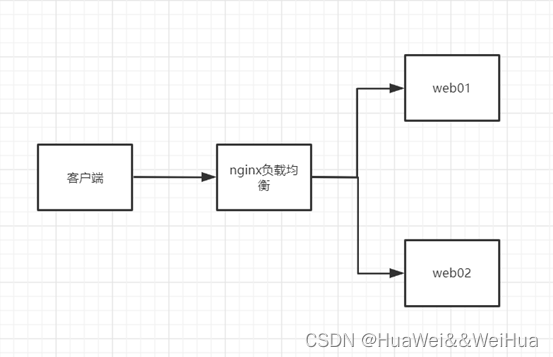
使用nginx进行负载均衡配置详细说明
使用nginx进行负载均衡 1. nginx负载均衡介绍 nginx应用场景之一就是负载均衡。在访问量较多的时候,可以通过负载均衡,将多个请求分摊到多台服务器上,相当于把一台服务器需要承担的负载量交给多台服务器处理,进而提高系统的吞吐…...

N皇后问题
#include<iostream> #include<string> #include<vector> using namespace std; #define MAX 20//最大20个皇后 int n ;//实际皇后个数 int sum ;//答案个数 vector<vector<int>> attack(MAX, vector<int>(MAX, 0));//标记攻击位置 vector&…...

强化学习DQN之俄罗斯方块
强化学习DQN之俄罗斯方块强化学习DQN之俄罗斯方块算法流程文件目录结构模型结构游戏环境训练代码测试代码结果展示强化学习DQN之俄罗斯方块 算法流程 本项目目的是训练一个基于深度强化学习的俄罗斯方块。具体来说,这个代码通过以下步骤实现训练: 首先…...

1.3总线:并行总线、串行总线、单工、半双工、全双工、总线宽度、总线带宽、总线的分类、数据总线、地址总线、控制总线
1.3总线:并行总线、串行总线、单工、半双工、全双工、总线宽度、总线带宽、总线的分类、数据总线、地址总线、控制总线总线并行总线、串行总线单工、半双工、全双工总线宽度总线带宽总线的分类数据总线(Data Bus,DB)地址总线&…...

Linux驱动开发—设备树开发详解
设备树开发详解 设备树概念 Device Tree是一种描述硬件的数据结构,以便于操作系统的内核可以管理和使用这些硬件,包括CPU或CPU,内存,总线和其他一些外设。 Linux内核从3.x版本之后开始支持使用设备树,可以实现驱动代…...

深入浅出C++ ——继承
文章目录一、继承的相关概念1. 继承的概念2. 继承格式3. 继承方式4. 访问限定符5. 继承基类成员访问方式的变化二、基类和派生类对象赋值转换三、继承中的作用域四、派生类的默认成员函数五、继承与友元六、继承与静态成员七、菱形继承及菱形虚拟继承1. 单继承2. 多继承3. 菱形…...
设计模式C++实现20: 桥接模式(Bridge)
部分内容参考大话设计模式第22章;本实验通过C语言实现。 一 基本原理 意图:将抽象部分和实现部分分离,使它们都可以独立变化。 上下文:某些类型由于自身的逻辑,具有两个或多个维度的变化。如何应对“多维度的变化”…...

Android中的Rxjava
要使用Rxjava首先要导入两个包,其中rxandroid是rxjava在android中的扩展 implementation io.reactivex:rxandroid:1.2.1implementation io.reactivex:rxjava:1.2.0observer 是一个观察者接口,泛型T为观察者观察数据的类型,里面只有三个方法&a…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...
--脚本介绍)
二十六.签名与脚本(1)--脚本介绍
1.区块链脚本介绍在之前的章节中,我们了解了签名与验证相关,但是btc的交易数据,签名和验证,不是单纯的,还有脚本深度参与其中。我们从开始来:bool SendMoney(CScript scriptPubKey, int64 nValue, CWalletT…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...