基于MediaPipe的人体摔倒检测
1 简介
1.1 研究背景及意义
现如今随着经济等各方面飞速发展,社会安全随之也成为必不可少的话题。而校园安全则是社会安全的重中之重,而在我们的校园中,湿滑的地面、楼梯等位置通常会发生摔倒,尽管有“小心脚下”的告示牌,可还是会有意外摔倒的情况发生。看似微不足道的摔倒却很有可能造成髋部和脊柱等多处骨折,根据世界卫生组织最近的一项研究,到2020年,全世界每年因跌倒而死亡的总人数达到64.6万人,显然摔倒已经成为意外死亡的最大原因之一,仅低于交通事故造成的死亡人数。实现实时、准确的异常行为检测成为视频监控的重要任务。但是,人体的异常行为通常具有无规律、突发性、不可预见性等特点,给目标的异常行为检测带来困难,研究一种自动检测视频中摔倒行为的方法很有必要。
从目前来看,跌倒行人检测的效果不够理想,识别速度和识别精度有待提高。本文将近几年最新的深度学习算法进行对比,将其应用于行人跌倒检测。当前目标检测算法的发大致分为两大流派,一类是Two-Stage算法:先产生候选区域然后再进行分类,标志性模型主要有区域卷积神经网络(regionCNN,R-CNN)、Fast R-CNN、Faster R-CNN等。另一类是One-Stage 算法:直接对输入图像应用算法并输出类别和相应的定位,其代表模型有单发多框检测器(SSD)、“你只看一次”(YOLO)系列等。针对跌倒检测,CNN系列算法在检测的实时性方面有所欠缺,SSD网络对于小目标的检测效果及精度并未超越YOLOv5,于是本文选择YOLOv5进行跌倒检测的研究。
2 YOLOV5模型简介
2.1 YOLOV5基本原理
2.1.1 YOLOV5模型结构
YOLOV5模型的结构如图1-1所示。YOLOv5按照网络的深度和宽度将网络模型由小到大分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,检测精度和速度呈现递增。本次研究考虑到模型大小,所以采用YOLOv5s作为研究对象。该模型由Input、Back Bone、Neck、predict共4个模块组成。
图1-1 YOLOV5模型结构
Fig. 1-1 YOLOV5 model structure
Input
使用了随机缩放、随机裁剪、随机排布的Mosaic数据增强方法,并在进行网络训练时自适应计算不同训练集中的最佳锚框值的技术。这种方法可以增加数据的多样性,提高模型的泛化能力,从而获得更好的检测效果。
具体地说,Mosaic数据增强方法将四张不同的图片随机裁剪并拼接成一张大图。这样做可以增加数据的多样性,使得模型对于不同尺度、姿态、光照等方面的目标有更好的识别能力。同时,随机缩放和随机排布也可以进一步增加数据的多样性。
另外,在进行网络训练时,由于不同的数据集可能存在不同大小和形状的目标,因此需要自适应地计算最佳的锚框值。这可以通过计算每个训练集中目标的平均宽度和高度来实现。然后,根据这些平均值计算每个训练集的最佳锚框值,从而获得更准确的检测结果。
Back Bone
主干层是卷积神经网络的核心部分,其作用是从原始图像中提取出具有代表性的特征,并将这些特征进行融合和降维,以便后续的处理和分类。
在主干层中,Conv2d卷积神经网络模块用于提取图像中的低级特征,例如边缘、角点等。C3网络结构如图1-2所示,用于提取更高级别的特征,例如纹理、形状等。SPPF模块则是用于减少参数量,从而增加模型的运行速度,同时还可以扩大感受野,提高特征提取的效果。
主干层的输出是将输入图像缩小至原来的1/32后所提取到的特征值形成的特征图片。这个特征图片包含了图像的各种重要特征信息,后续的处理模块可以基于这些特征进行目标检测、图像分类等任务。
图1-2 C3网络结构
Fig. 1-2 C3 network structure
Neck
Neck层的主要作用是将来自不同层的特征进行融合。在YOLOv4中,Neck层采用了FPN+PAN结构,其中FPN层网络由顶部到底部传递信息的,它主要负责传递语义特征。而PAN层则由底部到顶部传递信息的,它主要传递定位特征。YOLOv5,进一步提高了网络特征融合能力。
YOLOv5将YOLOv4中的普通卷积操作替换为C3结构,进一步提高了特征融合的能力[24],可以使得不同尺度的特征能够相互融合,从而更好地捕捉目标的特征。同时,C3结构还能够有效地减少网络参数和计算量,提高了网络的速度和效率。
Predict
包含三个检测层,分别是Neck中得到的3种不同尺寸的特征图。在进行目标检测时,YOLOv5会根据特征图的尺寸将其上划分网格,并为每个网格预设了3个不同宽高比的锚框,用来预测和回归目标。
3 Mediapipe模型简介
3.1 Mediapipe基本原理
3.1.1 Mediapipe模型结构
Mediapipe是一个开源的跨平台机器学习框架,旨在为开发人员提供构建基于视觉、语音和手势的应用程序所需的工具和组件。Mediapipe提供了一套预先构建好的模块,这些模块可以快速地实现各种机器学习任务,例如姿态识别、人脸检测、手部跟踪等。同时,Mediapipe支持多种输入源,包括摄像头、视频文件、图像序列等,为用户提供了更加灵活的选择。
图3-1 Mediapipe骨骼点检测模型
Fig. 3-1 Mediapipe bone point detection model
3.1.2 Mediapipe目标检测流程
Mediapipe检测目标需要四个步骤,如图3-2所示。
输入数据:首先,需要将待检测的图像或视频作为输入数据传入 MediaPipe 图形中。这里的 Camera 表示输入数据的来源。
目标检测:接下来,使用 Detection Tracking Object Detection 节点对输入数据进行目标检测。该节点会利用内置的快速 ML 推理和处理框架,对输入数据进行处理,并输出检测到的目标的位置和类别信息。
帧选择与合并:由于输入数据可能是连续的一段视频,因此需要对不同帧之间的检测结果进行处理,以提高检测的准确性。Frame Selection 和 Detection Merging 节点就是用来完成这一步骤的。Frame Selection 节点会选择最好的一帧作为当前时刻的检测结果,而 Detection Merging 节点则会将相邻帧的检测结果进行合并,以得到更准确的目标位置和类别信息。
结果输出:最后,将处理后的输出数据传送至 Display 节点,该节点会将结果显示出来。需要注意的是,输出结果也可以是其他形式的,比如保存到本地文件等。
图3-2 MediaPipe目标检测流程
Fig.3-2 MediaPipe object detection process
4 摔倒行为检测
4.1 实验环境及数据集
4.1.1 实验环境配置
本文基于Anaconda集成平台,Anaconda集成平台可实现对开发工具包的统一管理。利用Python语言进行程序的开发,Python语言是开源语言,具有完善的生态环境,并且集成了Pytorch、Tensorflow等主流的开源深度学习框架,并提供了函数调用接口,用户可以在任何计算机上免费安装和使用相关数据库。此外,Python语言易于学习,语法简单,代码维护便捷,拥有丰富的扩展库,可以轻松完成各种高级任务。
首先,需要在Anaconda官网下载Anaconda软件进行软件的安装,软件安装结果如图4.1所示。
图4-1 软件安装结果
Fig. 4-1 Anaconda install result
软件安装完成后,进行python和环境变量的配置,本文基于python 3.8进行程序的安装。最后,在新建的环境中安装相关依赖库,相关依赖库包括pytorch、opencv、mediapipe和yolov5等。
本文开发的实验环境为Windows系统,GPU型号为Nvidia 2080,处理器为Intel® Core™ i7-10870H CPU @ 2.20GHz 2.21GHz,32GB RAM,硬件条件可以满足程序的开发和运行需求。
4.1.2 COCO数据集
在进行跌倒检测时需要首先进行人体检测,本文基于yolov5算法进行人体检测,为了能够检测到人体,需要利用训练数据对模型进行训练,因此,采用COCO数据集进行人体识别模型和人体骨骼关键点检测模型的训练,COCO数据集如图4.2所示。
图4-2 COCO数据集
Fig. 4-2 COCO dataset
COCO数据集是由微软开发并维护的大型图像数据集,数据集集成了物体检测、关键点检测、实例分割、全景分割人体关键点、人体密度检测等任务,数据集中的图像是由实际场景中的图像所组成,图像中的物体经过精细的标注和分割,包含有超过33万张的原始图像,其中经过标注的图像超过20万张,在所有的图像中,包含有person(人)、bicycle(自行车)、car(汽车)、motorbike(摩托车)、aeroplane(飞机)、bus(公共汽车)、train(火车)、truck(卡车)、boat(船) 在内的91个类别,150万个对象实例,80个目标类别和对25万个人进行了关键点标注,因此,基于COCO数据集可同时完成人体识别和人体关键点检测两个任务,COCO数据集可执行任务如图4.3所示。
图4-3 COCO数据集任务
Fig. 4-3 Task of COCO dataset
COCO数据集包含3种标注的类型,分别为用于目标检测的实例分割,用于姿态估计的关键点检测和用于图像理解的图像文本标注。对于每一种标注类型均包括info、image和license三个字段,其中info包含year、version、description、contributor、url和data_created字段;image包含id、width、height、file_name、licence、flickr_url、coco_url和date_captured字段;license包含info、licenses、images、annotations和categories字段。除了上述三个字段外,对于实例分割任务提供了annotation字段,字段种包含id、image_id、category_id、segmentation、area、bbox和iscrowd字段。关键点检测任务中增加了keypoints字段用于存储人体的关键点信息。
4.2 实验分析
4.2.1 基于yolov5的人体识别
图像中背景复杂,复杂的背景会影响摔倒识别的准确率,为了提高模型的鲁棒性,增加摔倒识别的准确性,需要去除图像背景对摔倒识别的影响,因此,需要首先在图像中识别到人体部位,通过识别到人体从而缩小检测的范围。本文基于yolov5s进行人体识别,不同于yolov5n、yolov5m、yolov5l和yolov5x模型,yolov5s在保证推理速度的同时具有较高的识别精确率。在实际生活中对用户进行摔倒检测时,快速检测到用户是否摔倒十分重要,因此模型需要首先满足推理精度快的特点,虽然yolov5n模型的推理速度快于yolov5s,但是相比于yolov5s,yolov5n模型的识别准确率低,而对于yolov5m、yolov5l和yolov5x模型来说,虽然推理精度高,但是推理速度会随着精度的提高而损失更多的推理速度,因此,本文选择yolov5s模型进行人体的识别,yolov5s模型在大幅提高精度的同时而并未损失太大的推理速度。
图4-4 yolov5模型精度和推理速度对比结果
Fig. 4-4 Comparison of precision and speed for yolov5 model
在图像中准确检测到用户是检测摔倒的前提和保证,因此,首先对图像中的人体进行检测测试,为了提供测试的难度,选择具有复杂背景的图像进行测试。同时为了测试模型的鲁棒性,选择图像中人体并未全部出现在图像中的人体进行测试。测试结果如图4-5所示。
图4-5 yolov5s模型人体检测测试结果
Fig. 4-5 Human detection based on yolov5s
实验结果显示,yolov5s模型可在图像中准确识别到人体,即使对于并未全部出现在图像中的人体也可准确检测到人体,在检测到的人体中同时对检测到的人体标记了检测置信度。
4.2.2 基于Mediapipe的人脸识别
用户摔倒时,需要对用户进行识别,因此,需要对脸部进行检测,当检测到脸部后,将检测到的脸部图像进行保存。本文基于Mediapipe进行人脸检测,Mediapipe可支持多人脸的检测,同时可为检测到的人脸进行特征点的标记。Mediapipe提供三种人脸检测模型,分别为近景模型、密集型全范围模型和稀疏型全范围模型,其中近景模型适合于用户距离相机2米以内的人脸,密集型全范围模型和稀疏型全范围模型均适用于用户距离相机5米以内的人脸,虽然密集型全范围模型和稀疏型全范围模型具有相同的F值,但是密集型全范围模型的召回率要高于稀疏性全范围模型,而在精确度方法,稀疏型全范围模型的精确率要高于密集型全范围模型。用于摄像机往往距离用户的距离较远,因此,本文基于密集型全范围模型进行人脸的检测。
选择一张图片中具有多张人脸的图片进行人脸的检测,对于彩色图像,需要首先将图像进行灰度化处理,基于灰度图像进行人脸的检测,人脸检测结果如图4-6所示。结果显示,Mediapipe可以准确的实现人脸的检测,同时,可检测到脸部的6个特征点,6个特征点分别为左眼特征点、右眼特征点、鼻子部位特征点、嘴部特征点、左耳特征点和右耳特征点。当检测到用户的脸部区域后,可通过检测到的人脸框对脸部区域进行分割,从而保存分割结果。
图4-6 基于Mediapipe模型的人脸检测结果
Fig. 4-6 Face detection based on Mediapipe
4.2.3 基于骨骼模型的摔倒识别
最后,本文在yolov5s模型检测到的人体区域的基础上进行人体骨骼的检测,根据检测到的人体骨骼点之间的相对位置关系实现摔倒的识别。跌倒是一种突发的、不受用户控制的、非故意的体位改变,跌倒是瞬间的动作,人体的动作、高度和速度会发生快速的改变,此时人体的中心点会从较高的位置快速下降到地面或者接近地面的高度。在图三Mediapipe骨骼点检测模型中提供了人体两肩的关键点,关键点序号为11和12,用户在跌倒时,肩膀会出现着地的情况,因此本文选择两肩中点作为参考点。由于跌倒是一个持续的动作,因此需要对视频序列进行检测,本文通过对人体骨骼关键点检测返回的骨骼数据进行实时的处理,每N帧计算一次参考点的下降速度,当参考点的下降速度大于临界值时,则认为检测到了一个可能的摔倒现象。用户在摔倒时,用户距离摄像机的距离会发生变化,因此需要对摄像机中用户大小进行归一化,从而解决人体在摄像机中出现的近大远小的问题。用户在摔倒时往往会触碰到地面,因此,可通过计算双脚骨骼关键点近似地面高度,根据骨骼关键点模型可知,双脚关键点序号为29和30。一方面可通过计算参考点距离双脚关键点的距离判断用户是否摔倒,另一方面可通过下降速度与用户的近似感知高度克服人体在摄像机中近大远小的问题,此时,定义
ratio = speed/h
为用户摔倒的特征之一,其中speed为每N帧用户参考点的下降速度,本文中N为10,h为两肩中点到两脚中点之间的高度,ratio为阈值,本文ratio取值为0.25。当阈值大于0.25时,则可认为检测到了摔倒特征。关键实现代码如图4-7所示。
图4-7 摔倒特征一关键实现代码
Fig. 4-7 Code for fall detection features
当检测到摔倒特征一后,在一段时间内再次检测到该摔倒特征后,此时需要计算两髋中心点(骨骼模型23和24特征点)距离两脚中点(骨骼模型29和30特征点)的高度bh,当bh小于设定的阈值时,则可判断用户处于摔倒状态,关键实现代码如图4-8所示。
图4-8 摔倒特征二关键实现代码
Fig. 4-8 Code for fall detection features
为了测试跌倒检测算法的准确性,采用UR Fall Detection Dataset数据集进行测试,UR Fall Detection Dataset数据集结构如图4-9所示。
图4-9 UR Fall Detection Dataset数据集
Fig. 4-9 UR Fall Detection Dataset
该数据集包含70个视频序列,其中包含30个不同用户跌倒的视频序列,该数据集采用2台微软的深度摄像机和加速度计记录跌倒事件,摄像机0和摄像机1分别包含深度和彩色图像信息,由于在实际使用过程中使用的为彩色图像相机,因此,选择彩色图像视频进行算法的测试。对30个视频进行测试,均可成功检测到用户摔倒,部分测试结果如图4-10所示。
(a)用户未摔倒骨骼点检测结果
(b)用户摔倒骨骼点检测结果
图4-10 摔倒检测实验结果
Fig. 4-10 Results of fall detection
除了可检测到用户摔倒以外,还将摔倒用户的面部图像进行了保存,结果如图4-11所示。
图4-11 存储摔倒用户人脸
Fig. 4-11 Results of fall detection person face
为了进一步验证本文提出的跌倒检测算法的准确性和鲁棒性,采用查准率-查全率曲线进行测试。查准率-查全率曲线能够反映算法对目标识别的精确度和全面性。查准率-查全率曲线与坐标轴所围成的面积被定义为AP值,AP值越大算法的检测效果越好。算法的查准率-查全率结果如图4-12所示。
图4-12 P-R曲线结果
Fig. 4-12 Results of R-R
对于跌倒检测任务,可将视频中的用户状态分为站立和跌倒两个状态,因此对于这一二分类问题,可定义真正率、假正率、假负率和真负率,当算法预测视频中用户为正例时,样本实际也为正例时,称为真正率。当算法预测视频中用户为反例时,样本实际也为反例时,称为真负率。当算法预测视频中用户为反例时,样本实际为正例时,称为假负率。当算法预测视频中用户为反例,样本实际也为反例时,称为真负率。因此,我们对于本文提出的算法和mask rcnn和faster rcnn在运行时间和准确性方面进行对比,验证算法的有效性。三种算法的检测结果如表5.1所示。
表5.1 三种算法的检测结果
算法名称 总视频帧 正确检测 错误检测 查全率 查准率
Yolov5 2298 1986 312 0.872 0.864
Mask RCNN 2298 1865 433 0.837 0.812
Faster RCNN 2298 1839 459 0.821 0.800
实验结果显示,相比于Mask RCNN和Faster RCNN,Yolov5算法具有最高的查准率和查全率,检测准确率最高。除了准确率以外,算法的推理速度也会影响实际的使用效果,三种算法推理速度如表5.2所示。
表5.2 三种算法的推理速度
算法名称 耗时s
Yolov5 32.4
Mask RCNN 42.6
Faster RCNN 40.5
实验结果显示,Yolov5在CPU环境下具有更快的推理速度,预测速度更快。三种算法的检测结果如图4-13所示。
(1)Yolov5 (2)Mask RCNN (3) Faster RCNN
图4-11 Yolov5、Mask RCNN和Faster RCNN摔倒检测对比结果
Fig. 4-13 Comparison of Yolov5、Mask RCNN、Faster RCNN
最后,采用Intel oneAPI AI组件实现端到端的模型优化,使用的优化工具未英特尔神经压缩器1.12,环境配置如下图所示。
在经过优化前提下和未经过优化前提下模型每批次平均训练时间如下图所示,结果表明,经过优化后平均训练时间更短。
同一批次不同训练数据情况下,对模型优化前后的时间进行对比可以发现,模型优化后推理时间变短,并且随着单次批量数据的增加,时间变短幅度更大,优化效果更加明显。
相关文章:

基于MediaPipe的人体摔倒检测
1 简介 1.1 研究背景及意义 现如今随着经济等各方面飞速发展,社会安全随之也成为必不可少的话题。而校园安全则是社会安全的重中之重,而在我们的校园中,湿滑的地面、楼梯等位置通常会发生摔倒,尽管有“小心脚下”的告示牌…...

WebDAV之π-Disk派盘 + 无忧日记
无忧日记,生活无忧无虑。 给用户专业的手机记录工具,用户可以很轻松地通过软件进行每天发生事情的记录,可以为用户提供优质的工具与帮助,用户还可以通过软件来将地理位置,天气都记录在日记上,用户也可以通过软件来进行图片的导入,创建长图日记, 心情报表:用户写日记…...

Docker 相关操作,及其一键安装Docker脚本
一、模拟CentOS 7.5上安装Docker: 创建一个CentOS 7.5的虚拟机或使用其他方式准备一个CentOS 7.5的环境。 在CentOS 7.5上执行以下命令,以安装Docker的依赖项: sudo yum install -y yum-utils device-mapper-persistent-data lvm2 添加Doc…...
【Microsoft Edge】如何彻底卸载 Edge
目录 一、问题描述 二、卸载 Edge 2.1 卸载正式版 Edge 2.2 卸载非正式版 Edge 2.2.1 卸载通用的 WebView2 2.2.2 卸载 Canary 版 Edge 2.2.3 卸载其他版本 2.3 卸载 Edge Update 2.4 卸载 Edge 的 Appx 额外安装残留 2.5 删除日志文件 2.6 我就是想全把 Edge 都删了…...

2023-09-04力扣每日一题
链接: 449. 序列化和反序列化二叉搜索树 题意: 把一个二叉搜索树变成字符串,还要能变回来 解: 和剑指 Offer 37. 序列化二叉树差不多,那个是二叉树的序列化/反序列化-Hard 直接CV了,懒: ( 如果是二叉…...
jQuery成功之路——jQuery事件和插件概述
一、jQuery的事件 1.1常用事件 jQuery绑定事件,事件名字没有on。 事件名称事件说明blur事件源失去焦点click单击事件源change内容改变keydown接受键盘上的所有键(键盘按下)keypress接受键盘上的部分键(ctrl,alt,shift等无效)(键盘按下)key…...

Java ArrayList类详解
基本定义 ArrayList 是 Java 中的一个动态数组数据结构,属于 Java 集合框架的一部分(java.util 包中的类)。它提供了一个基于数组的可变长度列表,允许你在运行时添加、删除和访问元素,而不需要提前指定数组的大小。 简…...

快速排序学习
由于之前做有一题看到题解用了快排提升效率,就浅学了一下快速排序,还是似懂非懂。 首先快排的核心有两点,哨兵划分和递归。 哨兵划分:以数组中的某个数(一般为首位)为基准数,将数组划分为两个部…...
【Vue3 知识第二讲】Vue3新特性、vue-devtools 调试工具、脚手架搭建
文章目录 一、Vue3 新特性1.1 重写双向数据绑定1.1.1 Vue2 基于Object.defineProperty() 实现1.1.2 Vue3 基于Proxy 实现 1.2 优化 虚拟DOM1.3 Fragments1.4 Tree shaking1.5 Composition API 二、 vue-devtools 调试工具三、环境配置四、脚手架目录介绍五、SFC 语法规范解析附…...

pytorch 基于masking对元素进行替换
描述 pytorch 基于masking对元素进行替换. 代码如下. 先展平再赋值. 代码 # map.shape [64,60,128] # infill.shape [64,17,128] # mask_indices.shape [64,60]map map.reshape(map.shape[0] * map.shape[1],map.shape[2]) [mask_indices.reshape(mask_indices.shape[0]*ma…...
Cyber RT学习笔记---7、Component组件认知与实践
7、Component组件认知与实践 前言 本文是对Cyber RT的学习记录,文章可能存在不严谨、不完善、有缺漏的部分,还请大家多多指出。 课程地址: https://apollo.baidu.com/community/course/outline/329?activeId10200 更多还请参考: [1] Apollo星火计划学习笔记——第…...

常见配置文件格式INI/XML/YAML/JSON/Properties/TOML/HCL/YAML Front Matter/.env介绍及实例
1. 常见配置文件INI XML YAML JSON Properties介绍 以下是常见配置文件格式(INI、XML、YAML、JSON、Properties、TOML、HCL、YAML Front Matter、.env)的比较: 配置文件格式简介语法定义优点缺点常见使用场景常见编程语言INI简单的文本文件…...

JS 方法实现复制粘贴
背景 以前我们一涉及到复制粘贴功能,实现思路一般都是: 创建一个 textarea 标签 让这个 textarea 不可见(定位) 给这个 textarea 赋值 把这个 textarea 塞到页面中 调用 textarea 的 select 方法 调用 document.execCommand…...

后端面试话术集锦第 十六 篇:java锁面试话术
这是后端面试集锦第十六篇博文——java锁面试话术❗❗❗ 1. 介绍一下乐观锁和悲观锁 乐观锁的话就是比较乐观,每次去拿数据的时候,认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制或者CAS算法实现。 乐观…...
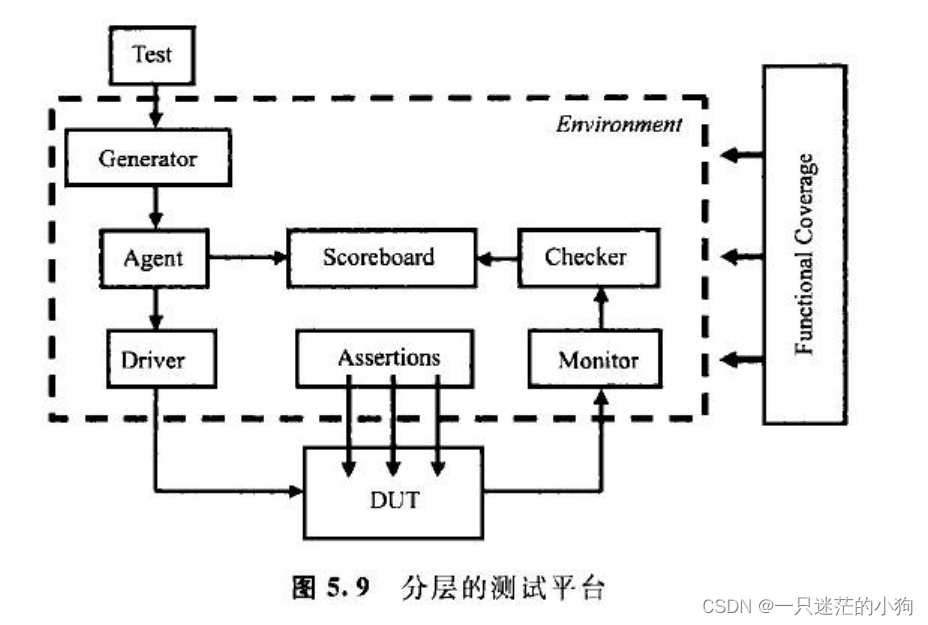
SystemVerilog 第5章 面向对象编程基础
5.1概述 对结构化编程语言,例如 Verilog和C语言来讲,它们的数据结构和使用这些数据结构的代码之间存在很大的沟壑。数据声明、数据类型与操作这些数据的算法经常放在不同的文件里,因此造成了对程序理解的困难。 Verilog程序员的境遇比C程序员更加棘手,因为Ⅴ erilog语言…...

指针进阶(1)
指针进阶 朋友们,好久不见,这次追秋给大家带来的是内容丰富精彩的指针知识的拓展内容,喜欢的朋友们三连走一波!!! 字符指针 在指针的类型中我们知道有一种指针类型为字符指针 char* ; 使用方法如…...
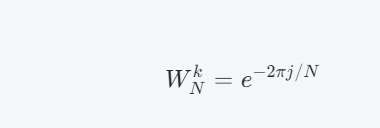
蝶形运算法
蝶形运算法是一种基于FFT(Fast Fourier Transform)算法的计算方法,其基本思想是将长度为N的DFT分解成若干个长度为N/2的DFT计算,并通过不断的合并操作得到最终的结果。该算法也称为“蝴蝶算法”,因为它的计算过程中需要…...
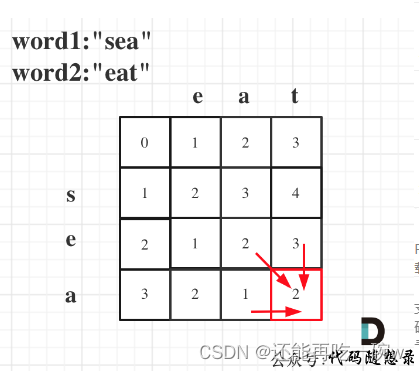
day 48|● 583. 两个字符串的删除操作 ● 72. 编辑距离
583. 两个字符串的删除操作 dp的含义:指0开头,i- 1和j - 1为结尾的两个序列的删除最小数 递推公式方面: 初始化方面:前面0行和0列的初值要赋好 func minDistance(word1 string, word2 string) int {dp : make([][]int, len(wor…...
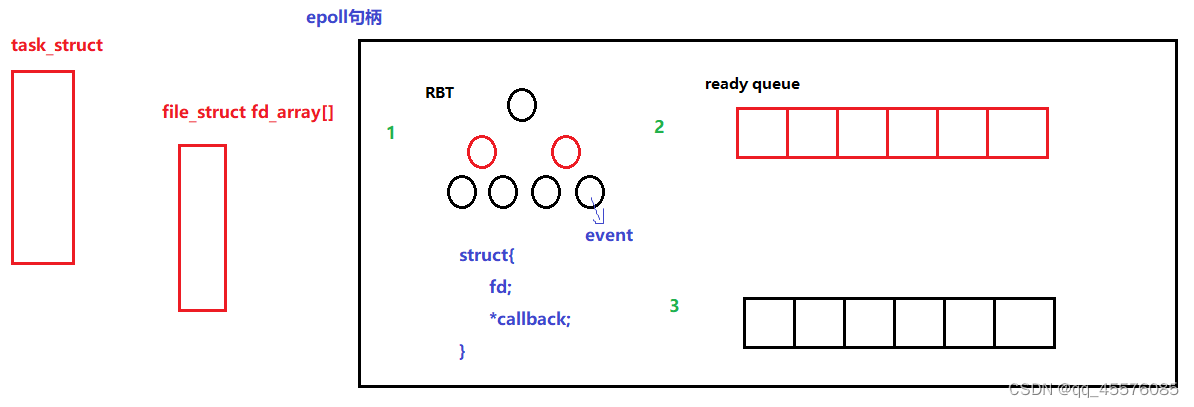
服务器(I/O)之多路转接
五种IO模型 1、阻塞等待:在内核将数据准备好之前,系统调用会一直等待。所有的套接字,默认都是阻塞方式。 2、非阻塞等待:如果内核没有将数据准备好,系统调用仍然会返回,并且会返回EWUOLDBLOCK或者EAGAIN错…...

后端面试话术集锦第 十三 篇:java集合面试话术
这是后端面试集锦第十三篇博文——java集合面试话术❗❗❗ 1. Java里常见的数据结构都有哪些以及特征 数组 数组是最常用的数据结构。 数组的特点是长度固定,可以用下标索引,并且所有的元素的类型都是一致的。 列表 列表和数组很相似,只不过它的大小可以改变。 列表一般都是…...

初创团队如何借助 Taotoken 实现低成本且灵活的大模型能力集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助 Taotoken 实现低成本且灵活的大模型能力集成 对于资源有限的初创技术团队而言,在开发新产品时集成 A…...

2025最权威的AI辅助写作助手推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI辅助写作工具正深刻改变着学术研究的传统范式,这是随着人工智能技术飞快发展而…...

ARM9E-S内存接口与中断机制深度解析
1. ARM9E-S内存接口架构解析 ARM9E-S处理器的内存接口采用高度流水线化设计,这种架构通过预广播机制显著提升了内存访问效率。在实际工程应用中,理解这一设计原理对构建高性能嵌入式系统至关重要。 1.1 流水线化数据接口工作原理 内存接口的流水线化体…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

DS3502 I2C数字电位器:从原理到Arduino/Python实战应用
1. 项目概述:告别手动旋钮,拥抱数字控制如果你和我一样,厌倦了在面包板上反复拧动电位器旋钮来调试电路,或者正在寻找一种能够通过程序精确控制电阻值的方法,那么DS3502这类I2C数字电位器绝对是你的“梦中情芯”。它本…...

详解C++作用域与生命周期
Pascal之父Nicklaus Wirth曾经提出一个公式,展示出了程序的本质:程序算法数据结构。后人又给出一个公式与之遥相呼应:软件程序文档。这两个公式可以简洁明了的为我们展示程序和软件的组成。程序的运行过程可以理解为算法对数据的加工过程&…...

陕西省ICPC省赛总结
个人反思 我个人感觉还是练的少,学的不够系统。具体反应到题上,表现在看到题没有思路,并且也不知道这道题用到什么算法思想,导致拿的书和本子几乎用不上。其次是思考不够深入,我的队友都能进行深入的思考,但…...

大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核?!
【大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核】快速阅读:大学正面临一场名为“僵尸化”的危机。当学生和教授都开始将 AI 用于替代思考、替代教学、甚至替代沟通时,高等教育正在从知识的殿堂退化为一种由算法驱动的、高度标准化的凭证工…...