离线采集普遍解决方案
简介
使用Datax每日全量相关全量表,使用Maxwell增量采集到Kafka然后到Flume然后到Hdfs。
DataX全量
生成模板Json
gen_import_config.py
# coding=utf-8
import json
import getopt
import os
import sys
import MySQLdb#MySQL相关配置,需根据实际情况作出修改
mysql_host = "master"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "root"#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "master"
hdfs_nn_port = "8020"#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/home/bigdata/datax/datax/job/pyjson"#获取mysql连接
def get_connection():return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)#获取表格的元数据 包含列名和数据类型
def get_mysql_meta(database, table):connection = get_connection()cursor = connection.cursor()sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"cursor.execute(sql, [database, table])fetchall = cursor.fetchall()cursor.close()connection.close()return fetchall#获取mysql表的列名
def get_mysql_columns(database, table):return map(lambda x: x[0], get_mysql_meta(database, table))#将获取的元数据中mysql的数据类型转换为hive的数据类型 写入到hdfswriter中
def get_hive_columns(database, table):def type_mapping(mysql_type):mappings = {"bigint": "bigint","int": "bigint","smallint": "bigint","tinyint": "bigint","decimal": "string","double": "double","float": "float","binary": "string","char": "string","varchar": "string","datetime": "string","time": "string","timestamp": "string","date": "string","text": "string"}return mappings[mysql_type]meta = get_mysql_meta(database, table)return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)#生成json文件
def generate_json(source_database, source_table):job = {"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": mysql_user,"password": mysql_passwd,"column": get_mysql_columns(source_database, source_table),"splitPk": "","connection": [{"table": [source_table],"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]}]}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,"fileType": "text","path": "${targetdir}","fileName": source_table,"column": get_hive_columns(source_database, source_table),"writeMode": "append","fieldDelimiter": "\t","compress": "gzip"}}}]}}if not os.path.exists(output_path):os.makedirs(output_path)with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:json.dump(job, f)def main(args):source_database = ""source_table = ""options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])for opt_name, opt_value in options:if opt_name in ('-d', '--sourcedb'):source_database = opt_valueif opt_name in ('-t', '--sourcetbl'):source_table = opt_valuegenerate_json(source_database, source_table)if __name__ == '__main__':main(sys.argv[1:])
脚本使用方法(执行以后就会生成表对应的json配置文件)
allfile.sh
#!/bin/bashpython gen_import_config.py -d 数据库 -t 表名
python gen_import_config.py -d 数据库 -t 表名
python gen_import_config.py -d 数据库 -t 表名
python gen_import_config.py -d 数据库 -t 表名
python gen_import_config.py -d 数据库 -t 表名全量导入到hdfs样例脚本
mysql-to-hdfs-datax.sh
#!/bin/bash
# mysql_to_hdfs_full.sh all 使用例子,改datax的home,还有改配置文件的地址就可以用了
DATAX_HOME=/home/bigdata/datax/datax# 如果传入日期则do_date等于传入的日期,否则等于前一天日期,也就是昨天
if [ -n "$2" ] ;thendo_date=$2
elsedo_date=`date -d "-1 day" +%F`
fi#处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行
handle_targetdir() {hadoop fs -test -e $1if [[ $? -eq 1 ]]; thenecho "路径$1不存在,正在创建......"hadoop fs -mkdir -p $1elseecho "路径$1已经存在"fs_count=$(hadoop fs -count $1)content_size=$(echo $fs_count | awk '{print $3}')if [[ $content_size -eq 0 ]]; thenecho "路径$1为空"elseecho "路径$1不为空,正在清空......"hadoop fs -rm -r -f $1/*fifi
}#数据同步
import_data() {
#$1 /home/bigdata/datax/datax/job/pyjson/bigdata.activity_info.json
#$2 /origin_data/bigdata/db/activity_info_full/$do_datedatax_config=$1target_dir=$2handle_targetdir $target_dirpython $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config
}case $1 in
"activity_info")
#/home/bigdata/datax/datax/job/pyjson改成自己文件生成的路径import_data /home/bigdata/datax/datax/job/pyjson/bigdata.activity_info.json /origin_data/bigdata/full_db/activity_info_full/$do_date;;
"all")import_data /home/bigdata/datax/datax/job/pyjson/bigdata.activity_info.json /origin_data/bigdata/full_db/activity_info_full/$do_date;;
esac
Maxwell增量
创建Kafka主题
createtopic.sh
#!/bin/bash
/home/bigdata/kafka/kafka_2.11-2.4.1/bin/kafka-topics.sh --bootstrap-server master:9092,node1:9092 --partitions 3 --replication-factor 3 --create --topic 表名
/home/bigdata/kafka/kafka_2.11-2.4.1/bin/kafka-topics.sh --bootstrap-server master:9092,node1:9092 --partitions 3 --replication-factor 3 --create --topic 表名
/home/bigdata/kafka/kafka_2.11-2.4.1/bin/kafka-topics.sh --bootstrap-server master:9092,node1:9092 --partitions 3 --replication-factor 3 --create --topic 表名
/home/bigdata/kafka/kafka_2.11-2.4.1/bin/kafka-topics.sh --bootstrap-server master:9092,node1:9092 --partitions 3 --replication-factor 3 --create --topic 表名
/home/bigdata/kafka/kafka_2.11-2.4.1/bin/kafka-topics.sh --bootstrap-server master:9092,node1:9092 --partitions 3 --replication-factor 3 --create --topic 表名maxwell配置文件
# tl;dr config
log_level=info
client_id=fy_client_test02
replica_server_id=12302producer=kafka
kafka.compression.type=snappy
kafka.retries=3
kafka.acks=-1
#kafka.batch.size=16384
kafka.bootstrap.servers=cdh-server:9092,agent01:9092,agent02:9092
kafka_topic=%{database}_%{table}
#元数据库
host=cdh-server
port=3306
user=maxwell
password=密码
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf-8#目标库
replication_host=
replication_user=
replication_password=
replication_port=3306
#目标库
replication_jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf-8
#jdbc_options=useSSL=false&serverTimezone=UTC&characterEncoding=utf-8
filter=exclude: *.*,include: 数据库.表,include: 数据库.表,include: 数据库.表,include: 数据库.表启动maxwell脚本
startmaxwell.sh
#!/bin/bash
#/home/bigdata/maxwell/maxwell-1.29.2/bin/maxwell --config /home/bigdata/maxwell/maxwell-1.29.2/config.properties --daemon
MAXWELL_HOME=/home/bigdata/maxwell/maxwell-1.29.2status_maxwell(){result=`ps -ef | grep maxwell | grep -v grep | wc -l`return $result
}start_maxwell(){status_maxwellif [[ $? -lt 1 ]]; thenecho "启动Maxwell"$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemonelseecho "Maxwell正在运行"fi
}stop_maxwell(){status_maxwellif [[ $? -gt 0 ]]; thenecho "停止Maxwell"ps -ef | grep maxwell | grep -v grep | awk '{print $2}' | xargs kill -9elseecho "Maxwell未在运行"fi
}case $1 in"start" )start_maxwell;;"stop" )stop_maxwell;;"restart" )stop_maxwellstart_maxwell;;
esac简单脚本
#!/bin/bash
/home/bigdata/maxwell/maxwell-1.29.2/bin/maxwell --config /home/bigdata/maxwell/maxwell-1.29.2/config.properties --daemon首日全量导入
alldatatohdfs.sh
#!/bin/bash# 该脚本的作用是初始化所有的增量表,只需执行一次MAXWELL_HOME=/home/bigdata/maxwell/maxwell-1.29.2import_data() {$MAXWELL_HOME/bin/maxwell-bootstrap --database 库名 --table $1 --config $MAXWELL_HOME/config.properties
}case $1 in
"cart_info")import_data cart_info;;
"all")import_data user_info;;
esac
Flume
获取maxwell到kafka的数据
启停脚本
#!/bin/bashcase $1 in
"start"){for i in node1doecho " --------启动 $i 采集flume-------"ssh $i "nohup /home/bigdata/flume/flume-1.9.0/bin/flume-ng agent --conf /home/bigdata/flume/flume-1.9.0/conf --conf-file /home/bigdata/shell/maxwelltoktoh/flumeconf/kafka-flume-hdfs-inc.conf --name a1 -Dflume.root.logger=INFO,console >/dev/null 2>&1 &"done
};;
"stop"){for i in node1doecho " --------停止 $i 采集flume-------"ssh $i " ps -ef | grep kafka-flume-hdfs-inc.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "done};;
esac配置文件
kafka-flume-hdfs-inc.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = master:9092,node1:9092,node2:9092
a1.sources.r1.kafka.topics = activity_info,user_info
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.flume.inter.TimestampInterceptor$Buildera1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/bigdata/shell/logtohdfs/maxwelltoktoh/data
a1.channels.c1.dataDirs = /home/bigdata/shell/logtohdfs/maxwelltoktoh/checkpoint/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1123456
a1.channels.c1.keep-alive = 6## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/inc_db/%{topic}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1配置部分说明
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://master:8020/flume/data=%Y%m%d/hour=%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 30
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0例子
a2.sources = r1
a2.channels = c1
a2.sinks = k1a2.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.r1.batchSize = 5000
a2.sources.r1.batchDurationMillis = 2000
a2.sources.r1.kafka.bootstrap.servers = 服务地址ip:9092,服务地址ip:9092
a2.sources.r1.kafka.topics = 主题,主题,主题,主题
a2.sources.r1.kafka.consumer.group.id = flume_product_05
a2.sources.r1.setTopicHeader = true
a2.sources.r1.topicHeader = topic
#零点漂移问题
a2.sources.r1.interceptors = i1
a2.sources.r1.interceptors.i1.type = com.interceptor.TimeStampInterceptor$Builder
a2.sources.r1.kafka.consumer.auto.offset.reset=latesta2.channels.c1.type = file
a2.channels.c1.checkpointDir = /data/module/flume-1.9.0/checkpoint/behavior4
a2.channels.c1.dataDirs = /data/module/flume-1.9.0/data/behavior4/
a2.channels.c1.maxFileSize = 2146435071
a2.channels.c1.capacity = 1000000
a2.channels.c1.keep-alive = 6## sink1
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = /origin_data/db/%{database}/%{topic}_inc/%Y-%m-%d
a2.sinks.k1.hdfs.filePrefix = db
a2.sinks.k1.hdfs.round = falsea2.sinks.k1.hdfs.rollInterval = 300
a2.sinks.k1.hdfs.rollSize = 134217728
a2.sinks.k1.hdfs.rollCount = 0a2.sinks.k1.hdfs.fileType = CompressedStream
a2.sinks.k1.hdfs.codeC = gzip## 拼装
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1#更具自己的要求自行修改
#a2.sources.r1.kafka.consumer.auto.offset.reset=latest
#a2.sinks.k1.hdfs.rollInterval = 300相关文章:

离线采集普遍解决方案
简介 使用Datax每日全量相关全量表,使用Maxwell增量采集到Kafka然后到Flume然后到Hdfs。 DataX全量 生成模板Json gen_import_config.py # codingutf-8 import json import getopt import os import sys import MySQLdb#MySQL相关配置,需根据实际情…...

SAP ABAP 数据类型P类型详解
ABAP中比较难以理解的是P类型的使用,P类型是一种压缩类型,主要用于存储小数,定义时要指定字节数和小数点位数,定义语法如下: DATA: name(n) TYPE P decimals m,n代表字节数,最大为16,m是小…...

应用沙盒seccomp的使用
应用沙盒原理参考https://zhuanlan.zhihu.com/p/513688516 1、什么是Seccomp? seccomp 是 secure computing 的缩写,其是 Linux kernel 从2.6.23版本引入的一种简洁的 sandboxing 机制。 系统调用: 在Linux中,将程序的运行空间分为内核与用户空间(内核态和用户态),在逻辑…...
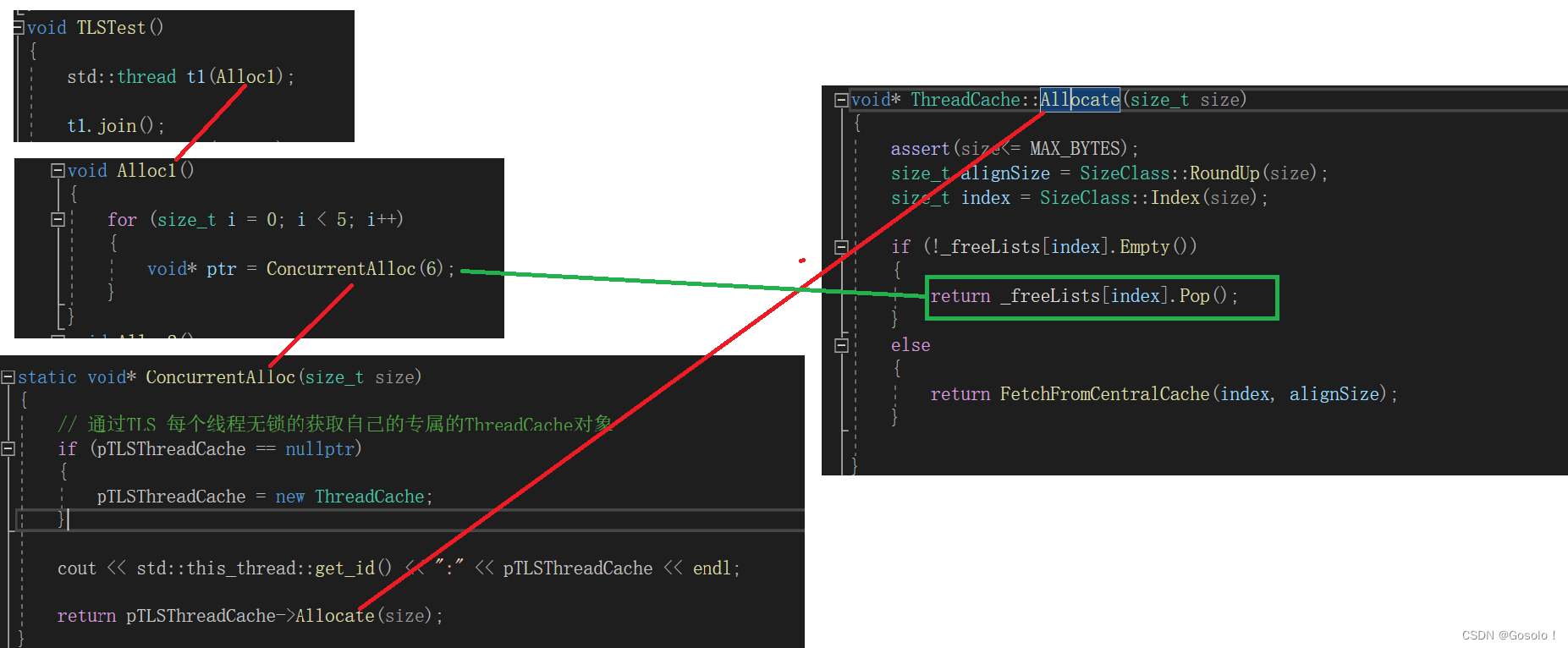
C++项目——高并发内存池(2)——thread_cache的基础功能实现
1.并发内存池concurrent memory pool 组成部分 thread cache、central cache、page cache thread cache:线程缓存是每个线程独有的,用于小于64k的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这…...
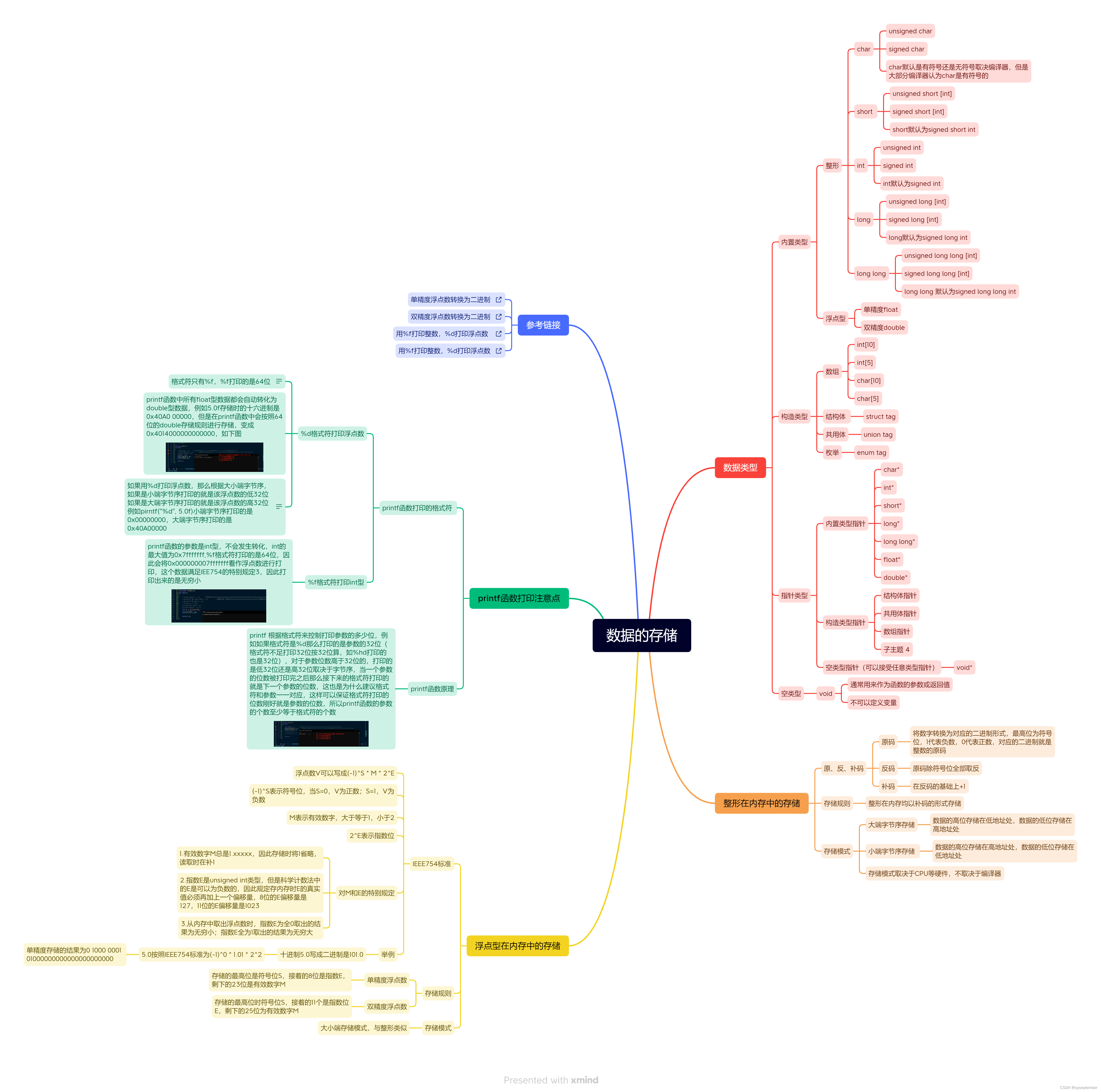
【C进阶】数据的存储
文章目录:star:1. 数据类型:star:2. 整形在内存中的存储2.1 存储规则2.2 存储模式2.3 验证大小端模式:star:3. 数据范围3.1 整形溢出3.2 数据范围的求解3.3 练习:star:4. 浮点型在内存中的存储4.1 浮点数的存储规则4.2 练习5. :star::star:总结(思维导图)⭐️1. 数据类型 在了…...
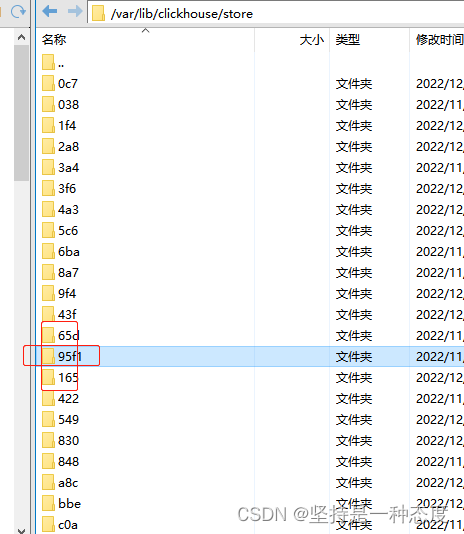
【已解决】异常断电文件损坏clickhouse启动不了:filesystem error Structure needs cleaning
问题 办公室有一台二手服务器,作为平时开发测试使用。由于机器没放在机房,会偶发断电异常断电后,文件系统是有出问题的可能的,尤其是一些不断在读写合并的文件春节后,发现clickhouse启动不了,使用systemct…...
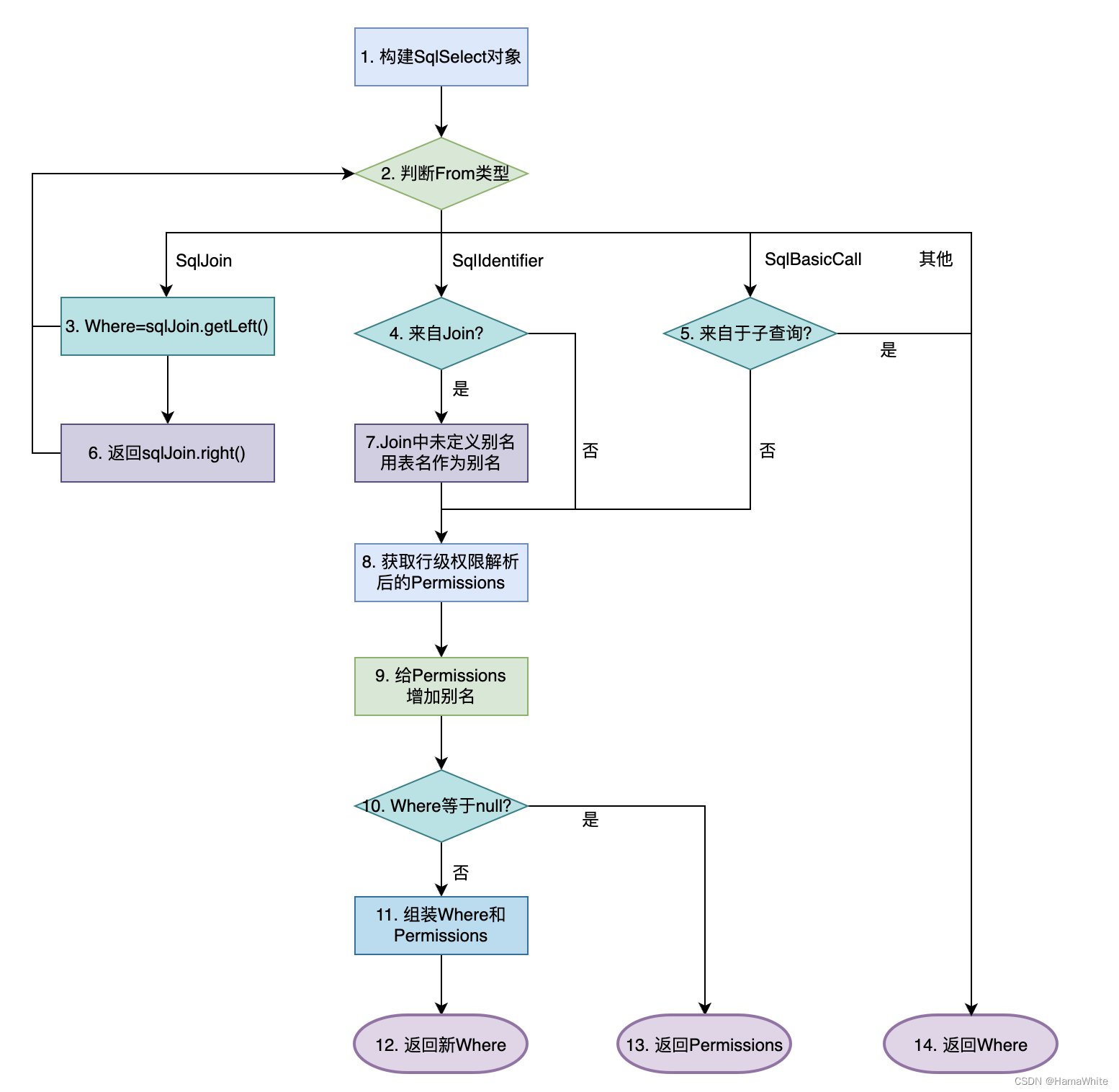
FlinkSQL行级权限解决方案及源码
FlinkSQL的行级权限解决方案及源码,支持面向用户级别的行级数据访问控制,即特定用户只能访问授权过的行,隐藏未授权的行数据。此方案是实时领域Flink的解决方案,类似离线数仓Hive中Ranger Row-level Filter方案。 源码地址: https…...

【基础篇】8 # 递归:如何避免出现堆栈溢出呢?
说明 【数据结构与算法之美】专栏学习笔记 什么是递归? 递归是一种应用非常广泛的算法(或者编程技巧),比如 DFS 深度优先搜索、前中后序二叉树遍历等等都是用到了递归。 方法或函数调用自身的方式称为递归调用,调用…...

基于微信公众号(服务号)实现扫码自动登录系统功能
微信提供了两种方法都可以实现扫描登录。 一种是基于微信公众平台的扫码登录,另一种是基于微信开放平台的扫码登录。 两者的区别: 微信开放平台需要企业认证才能注册(认证费用300元,只需要认证1次,后续不再需要进行缴费年审&#…...
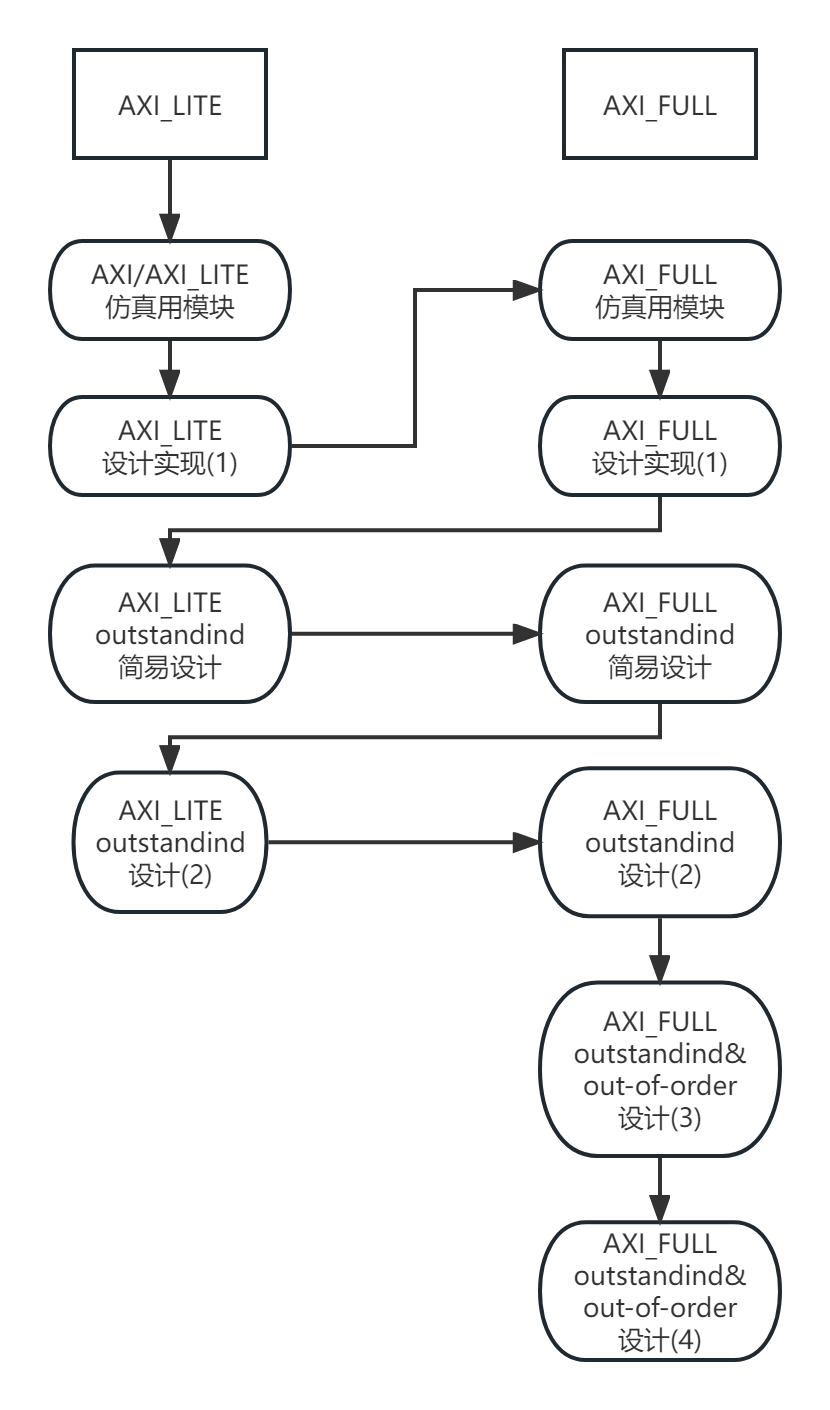
AXI实战(二)-跟着产品手册设计AXI-Lite外设(AXI-Lite转串口实现)
AXI实战(二)-跟着产品手册设计AXI-Lite 设(AXI-Lite转串口实现) 看完在本文后,你将可能拥有: 一个AXI_Lite转串口的从端(Slave)设计使用SV仿真AXI-Lite总线的完整体验实现如何在读通道中实现"等待"小何的AXI实战系列开更了,以下是初定的大纲安排: 欢迎感兴趣的…...
一周搞定模拟电路视频教程,拒绝讲PPT,仿真软件配合教学,真正一周搞定
目录1、灵魂拷问2、懦夫救星3、福利领取2、使用流程1、灵魂拷问 问:模拟电路很难吗? 答:嗯,真的很难!!! 问:模拟电路容易学吗? 答:很难学,建议放…...

高德地图获得角度
//传入两个经纬度点得到车辆角度 设置车辆Marker角度 getAngle(startPoint, endPoint) {if (!(startPoint && endPoint)) {return 0;}let dRotateAngle Math.atan2(Math.abs(startPoint.lng - endPoint.lng),Math.abs(startPoint.lat - endPoint.lat));console.log(&q…...
【C++】-- C++11基础常用知识点(下)
上篇: 【C】-- C11基础常用知识点(上)_川入的博客-CSDN博客 目录 新的类功能 默认成员函数 可变参数模板 可变参数 可变参数模板 empalce lambda表达式 C98中的一个例子 lambda表达式 lambda表达式语法 捕获列表 lambda表达底层 …...
提到数字化,你想到哪些关键词
我们的生活中已经充满了数据,各种岗位例如运营、市场、营销上也都喜欢在职位要求加上一条利用数据、亦或是懂得数据分析。事实上,数据已经成为了构建现代社会的基本生产要素,并且因为不受自然环境的限制,已经成为了人们对未来社会…...

【蓝桥杯集训·每日一题】AcWing 1249. 亲戚
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴并查集一、题目 1、原题链接 1249. 亲戚 2、题目描述 或许你并不知道,你的某个朋友是你的亲戚。 他可能是你的曾祖父的外公的女婿的外甥女的表姐的孙子。 如果…...

iphone所有机型的屏幕尺寸
手机设备型号屏幕尺寸(吋)分辨率点数(pt)屏幕显示模式分辨率像素(px)屏幕比例iPhone SE4.03205682x640113616:9iPhone 6/6s/7/8/SE 24.73756672x750133416:9iPhone 6P/7P/8P5.54147363x1242220816:9iPhone XR/116.14148962x828179219.5:9iPhone X/XS/11P5.83758123x1125243619.…...
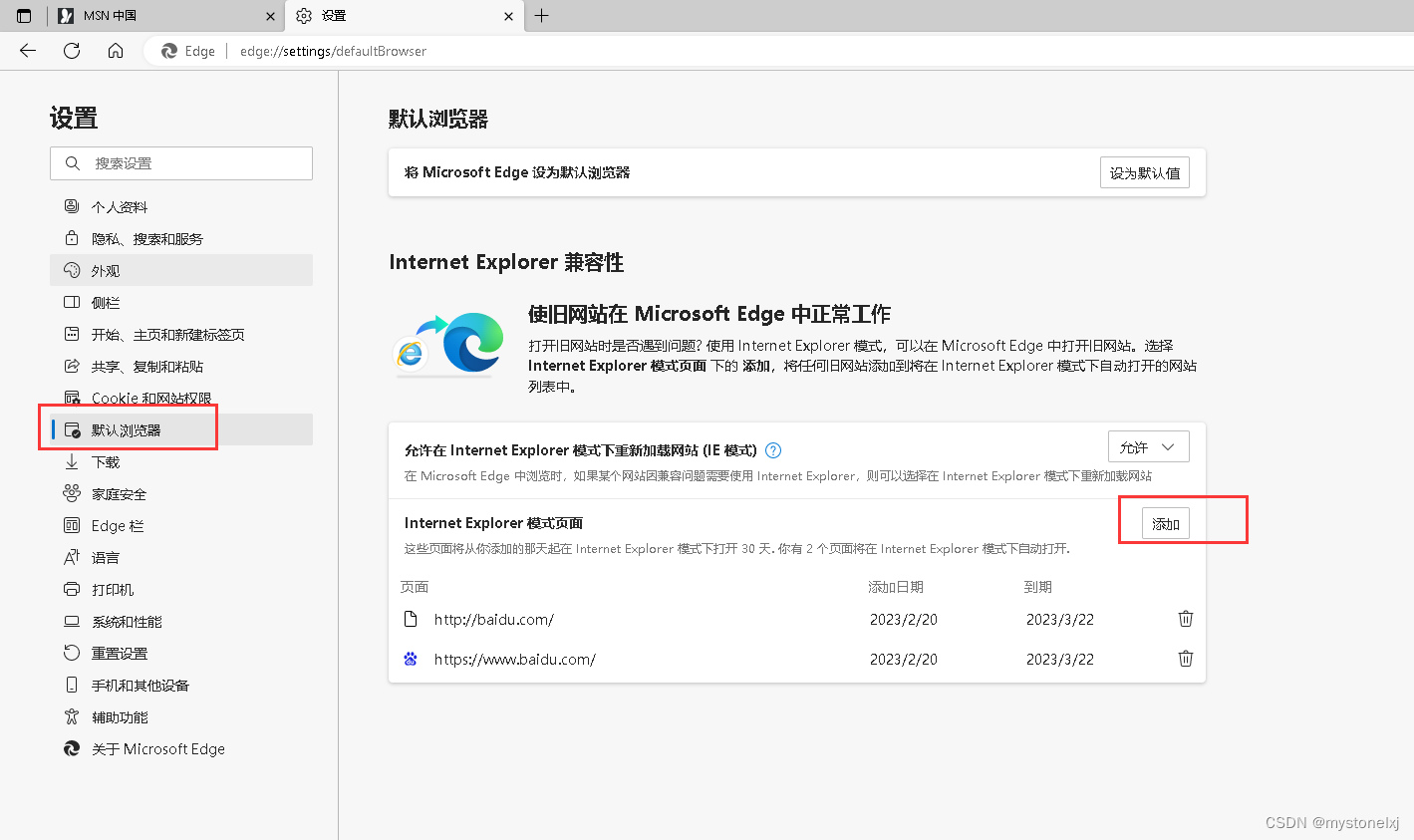
Windows10使用-处理IE自动跳转至Edge
文章目录 前言一、调整Edge二、调整Internet选项三、搜索栏的恢复总结前言 微软官方宣布,自2023年2月14日永久停止支持Internet Explorer 11浏览器。后期点击IE 图标将会自动跳转到Edge界面。对于一些网站,可能需要使用IE模式才能正常使用,这时候就需要做相应的调整,才能够…...
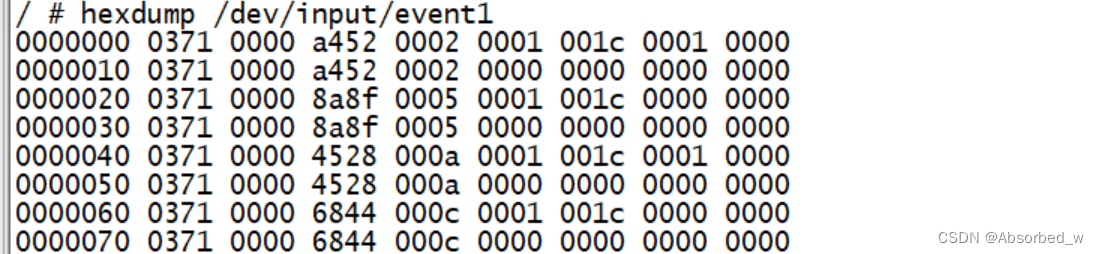
linux input子系统,gpio-keys,gpio中断使用
GPIO控制 嵌入式linux下应用编程会经常使用到gpio,GPIO 可以通过 sysfs 方式进行操控,进入到/sys/class/gpio 目录下,如下所示: 可以看到该目录下包含两个文件 export、 unexport 以及 5 个 gpiochipX(X 等于 0、 32、…...

分析称勒索攻击在非洲、中东与中国增长最快
Orange Cyberdefense(OCD)于 2022 年 12 月 1 日发布了最新的网络威胁年度报告。报告中指出,网络勒索仍然是头号威胁 ,也逐渐泛滥到世界各地。 报告中的网络威胁指的是企业网络中的某些资产被包括勒索软件在内的攻击进行勒索&…...

ArcPy批量合并矢量shape文件
当有大量矢量(.shp)格式文件需要合并成一个矢量文件时,可以考虑使用 ArcPy 进行批量合并,代码如下: # coding:utf-8 import os import arcpy from arcpy import envenv.workspace "C:/Users/Desktop/demo"…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...
)
【Sora 2 HDR生成黄金公式】:曝光补偿系数×动态范围压缩阈值×时域一致性权重=可商用HDR帧率(附Python验证脚本)
更多请点击: https://codechina.net 第一章:Sora 2 HDR视频生成黄金公式的提出与商业意义 Sora 2 的HDR视频生成能力不再依赖传统多曝光融合或后期调色管线,而是通过一个端到端可微分的物理感知渲染公式实现原生高动态范围建模。该公式被业界…...

从无人机到自动驾驶:一文读懂ROS中ENU、NED、相机坐标系到底怎么用
从无人机到自动驾驶:ROS中ENU、NED与相机坐标系实战指南 当你在无人机上安装Realsense相机时,是否遇到过相机数据与飞控数据"对不上"的情况?或者在自动驾驶项目中,GPS的北东地坐标如何与激光雷达的东北天坐标对齐&#…...

KMS智能激活工具:如何一键永久激活Windows和Office的完整指南
KMS智能激活工具:如何一键永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题而烦恼吗?每次系统重装后都要…...