FlinkSQL行级权限解决方案及源码
FlinkSQL的行级权限解决方案及源码,支持面向用户级别的行级数据访问控制,即特定用户只能访问授权过的行,隐藏未授权的行数据。此方案是实时领域Flink的解决方案,类似离线数仓Hive中Ranger Row-level Filter方案。
源码地址: https://github.com/HamaWhiteGG/flink-sql-security
注: 此方案已产品化集成到实时计算平台Dinky,欢迎试用。
一、基础知识
1.1 行级权限
行级权限即横向数据安全保护,可以解决不同人员只允许访问不同数据行的问题。例如针对订单表,用户A只能查看到北京区域的数据,用户B只能查看到杭州区域的数据。

1.2 业务流程
1.2.1 设置行级权限
管理员配置用户、表、行级权限条件,例如下面的配置。
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
| 2 | 用户B | orders | region = ‘hangzhou’ |
1.2.2 用户查询数据
用户在系统上查询orders表的数据时,系统在底层查询时会根据该用户的行级权限条件来自动过滤数据,即让行级权限生效。
当用户A和用户B在执行下面相同的SQL时,会查看到不同的结果数据。
SELECT * FROM orders;
用户A查看到的结果数据是:
| order_id | order_date | customer_name | price | product_id | order_status | region |
|---|---|---|---|---|---|---|
| 10001 | 2020-07-30 10:08:22 | Jack | 50.50 | 102 | false | beijing |
| 10002 | 2020-07-30 10:11:09 | Sally | 15.00 | 105 | false | beijing |
注: 系统底层最终执行的SQL是:
SELECT * FROM orders WHERE region = 'beijing'。
用户B查看到的结果数据是:
| order_id | order_date | customer_name | price | product_id | order_status | region |
|---|---|---|---|---|---|---|
| 10003 | 2020-07-30 12:00:30 | Edward | 25.25 | 106 | false | hangzhou |
| 10004 | 2022-12-15 12:11:09 | John | 78.00 | 103 | false | hangzhou |
注: 系统底层最终执行的SQL是:
SELECT * FROM orders WHERE region = 'hangzhou'。
1.3 组件版本
| 组件名称 | 版本 | 备注 |
|---|---|---|
| Flink | 1.16.0 | |
| Flink-connector-mysql-cdc | 2.3.0 |
二、Hive行级权限解决方案
在离线数仓工具Hive领域,由于发展多年已有Ranger来支持表数据的行级权限控制,详见参考文献[2]。下图是在Ranger里配置Hive表行级过滤条件的页面,供参考。

但由于Flink实时数仓领域发展相对较短,Ranger还不支持FlinkSQL,以及要依赖Ranger会导致系统部署和运维过重,因此开始自研实时数仓的行级权限解决工具。
三、FlinkSQL行级权限解决方案
3.1 解决方案
3.1.1 FlinkSQL执行流程
可以参考作者文章[FlinkSQL字段血缘解决方案及源码],本文根据Flink1.16修正和简化后的执行流程如下图所示。

在CalciteParser.parse()处理后会得到一个SqlNode类型的抽象语法树(Abstract Syntax Tree,简称AST),本文会在Parse阶段,通过组装行级过滤条件生成新的AST来实现行级权限控制。
3.1.2 Calcite对象继承关系
下面章节要用到Calcite中的SqlNode、SqlCall、SqlIdentifier、SqlJoin、SqlBasicCall和SqlSelect等类,此处进行简单介绍以及展示它们间继承关系,以便读者阅读本文源码。
| 序号 | 类 | 介绍 |
|---|---|---|
| 1 | SqlNode | A SqlNode is a SQL parse tree. |
| 2 | SqlCall | A SqlCall is a call to an SqlOperator operator. |
| 3 | SqlIdentifier | A SqlIdentifier is an identifier, possibly compound. |
| 4 | SqlJoin | Parse tree node representing a JOIN clause. |
| 5 | SqlBasicCall | Implementation of SqlCall that keeps its operands in an array. |
| 6 | SqlSelect | A SqlSelect is a node of a parse tree which represents a select statement. |

3.1.3 解决思路
在Parser阶段,如果执行的SQL包含对表的查询操作,则一定会构建Calcite SqlSelect对象。因此限制表的行级权限,只要在构建Calcite SqlSelect对象时对Where条件进行拦截即可,而不需要解析用户执行的各种SQL来查找配置过行级权限条件约束的表。
在SqlSelect对象构造Where条件时,要通过执行用户和表名来查找配置的行级权限条件,系统会把此条件用CalciteParser提供的parseExpression(String sqlExpression)方法解析生成一个SqlBacicCall再返回。然后结合用户执行的SQL和配置的行级权限条件重新组装Where条件,即生成新的带行级过滤条件Abstract Syntax Tree,最后基于新的AST再执行后续的Validate、Convert、Optimize和Execute阶段。

以上整个过程对执行SQL的用户都是透明和无感知的,还是调用Flink自带的TableEnvironment.executeSql(String statement)方法即可。
注: 要通过技术手段把执行用户传递到Calcite SqlSelect中。
3.2 重写SQL
主要在org.apache.calcite.sql.SqlSelect的构造方法中完成。
3.2.1 主要流程
主流程如下图所示,根据From的类型进行不同的操作,例如针对SqlJoin类型,要分别遍历其left和right节点,而且要支持递归操作以便支持三张表及以上JOIN;针对SqlIdentifier类型,要额外判断下是否来自JOIN,如果是的话且JOIN时且未定义表别名,则用表名作为别名;针对SqlBasicCall类型,如果来自于子查询,说明已在子查询中组装过行级权限条件,则直接返回当前Where即可,否则分别取出表名和别名。
然后再获取行级权限条件解析后生成SqlBacicCall类型的Permissions,并给Permissions增加别名,最后把已有Where和Permissions进行组装生成新的Where,来作为SqlSelect对象的Where约束。
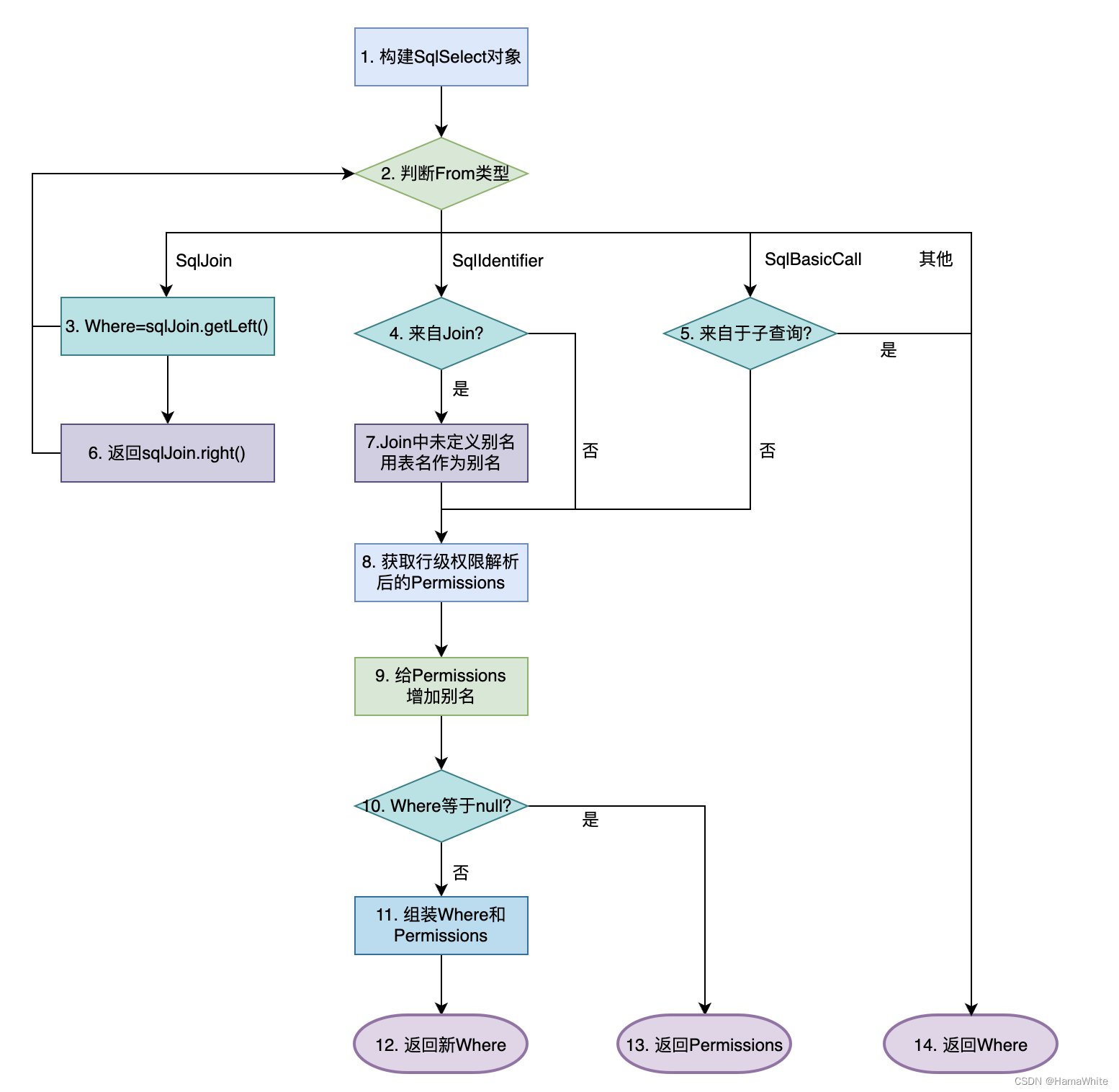
上述流程图的各个分支,都会在下面的用例测试章节中会举例说明。
3.2.2 核心源码
核心源码位于SqlSelect中新增的addCondition()、addPermission()、buildWhereClause()三个方法,下面只给出控制主流程addCondition()的源码。
/*** The main process of controlling row-level permissions*/
private SqlNode addCondition(SqlNode from, SqlNode where, boolean fromJoin) {if (from instanceof SqlIdentifier) {String tableName = from.toString();// the table name is used as an alias for joinString tableAlias = fromJoin ? tableName : null;return addPermission(where, tableName, tableAlias);} else if (from instanceof SqlJoin) {SqlJoin sqlJoin = (SqlJoin) from;// support recursive processing, such as join for three tables, process left sqlNodewhere = addCondition(sqlJoin.getLeft(), where, true);// process right sqlNodereturn addCondition(sqlJoin.getRight(), where, true);} else if (from instanceof SqlBasicCall) {// Table has an alias or comes from a subquerySqlNode[] tableNodes = ((SqlBasicCall) from).getOperands();/*** If there is a subquery in the Join, row-level filtering has been appended to the subquery.* What is returned here is the SqlSelect type, just return the original where directly*/if (!(tableNodes[0] instanceof SqlIdentifier)) {return where;}String tableName = tableNodes[0].toString();String tableAlias = tableNodes[1].toString();return addPermission(where, tableName, tableAlias);}return where;
}
四、用例测试
用例测试数据来自于CDC Connectors for Apache Flink
[6]官网,在此表示感谢。下载本文源码后,可通过Maven运行单元测试。
$ cd flink-sql-security
$ mvn test
4.1 新建Mysql表及初始化数据
Mysql新建表语句及初始化数据SQL详见源码[flink-sql-security/data/database]里面的mysql_ddl.sql和mysql_init.sql文件,本文给orders表增加一个region字段。
4.2 新建Flink表
4.2.1 新建mysql cdc类型的orders表
DROP TABLE IF EXISTS orders;CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY NOT ENFORCED,order_date TIMESTAMP(0),customer_name STRING,product_id INT,price DECIMAL(10, 5),order_status BOOLEAN,region STRING
) WITH ('connector'='mysql-cdc','hostname'='xxx.xxx.xxx.xxx','port'='3306','username'='root','password'='xxx','server-time-zone'='Asia/Shanghai','database-name'='demo','table-name'='orders'
);
4.2.2 新建mysql cdc类型的products表
DROP TABLE IF EXISTS products;CREATE TABLE IF NOT EXISTS products (id INT PRIMARY KEY NOT ENFORCED,name STRING,description STRING
) WITH ('connector'='mysql-cdc','hostname'='xxx.xxx.xxx.xxx','port'='3306','username'='root','password'='xxx','server-time-zone'='Asia/Shanghai','database-name'='demo','table-name'='products'
);
4.2.3 新建mysql cdc类型shipments表
DROP TABLE IF EXISTS shipments;CREATE TABLE IF NOT EXISTS shipments (shipment_id INT PRIMARY KEY NOT ENFORCED,order_id INT,origin STRING,destination STRING,is_arrived BOOLEAN
) WITH ('connector'='mysql-cdc','hostname'='xxx.xxx.xxx.xxx','port'='3306','username'='root','password'='xxx','server-time-zone'='Asia/Shanghai','database-name'='demo','table-name'='shipments'
);
4.2.4 新建print类型print_sink表
DROP TABLE IF EXISTS print_sink;CREATE TABLE IF NOT EXISTS print_sink (order_id INT PRIMARY KEY NOT ENFORCED,order_date TIMESTAMP(0),customer_name STRING,product_id INT,price DECIMAL(10, 5),order_status BOOLEAN,region STRING
) WITH ('connector'='print'
);
4.3 测试用例
详细测试用例可查看源码中的单测,下面只描述部分测试点。
4.3.1 简单SELECT
4.3.1.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.1.2 输入SQL
SELECT * FROM orders;
4.3.1.3 输出SQL
SELECT * FROM orders WHERE region = 'beijing';
4.3.1.4 测试小结
输入SQL中没有WHERE条件,只需要把行级过滤条件region = 'beijing'追加到WHERE后即可。
4.3.2 SELECT带复杂WHERE约束
4.3.2.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.2.2 输入SQL
SELECT * FROM orders WHERE price > 45.0 OR customer_name = 'John';
4.3.2.3 输出SQL
SELECT * FROM orders WHERE (price > 45.0 OR customer_name = 'John') AND region = 'beijing';
4.3.2.4 测试小结
输入SQL中有两个约束条件,中间用的是OR,因此在组装region = 'beijing'时,要给已有的price > 45.0 OR customer_name = 'John'增加括号。
4.3.3 两表JOIN且含子查询
4.3.3.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.3.2 输入SQL
SELECTo.*,p.name,p.description
FROM (SELECT*FROM ordersWHERE order_status = FALSE) AS o
LEFT JOIN products AS p ON o.product_id = p.id
WHEREo.price > 45.0 OR o.customer_name = 'John'
4.3.3.3 输出SQL
SELECTo.*,p.name,p.description
FROM (SELECT*FROM ordersWHERE order_status = FALSE AND region = 'beijing') AS o
LEFT JOIN products AS p ON o.product_id = p.id
WHEREo.price > 45.0 OR o.customer_name = 'John'
4.3.3.4 测试小结
针对比较复杂的SQL,例如两表在JOIN时且其中左表来自于子查询SELECT * FROM orders WHERE order_status = FALSE,行级过滤条件region = 'beijing'只会追加到子查询的里面。
4.3.4 三表JOIN
4.3.4.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
| 2 | 用户A | products | name = ‘hammer’ |
| 3 | 用户A | shipments | is_arrived = FALSE |
4.3.4.2 输入SQL
SELECTo.*,p.name,p.description,s.shipment_id,s.origin,s.destination,s.is_arrived
FROMorders AS oLEFT JOIN products AS p ON o.product_id=p.idLEFT JOIN shipments AS s ON o.order_id=s.order_id;
4.3.4.3 输出SQL
SELECTo.*,p.name,p.description,s.shipment_id,s.origin,s.destination,s.is_arrived
FROMorders AS oLEFT JOIN products AS p ON o.product_id=p.idLEFT JOIN shipments AS s ON o.order_id=s.order_id
WHEREo.region='beijing'AND p.name='hammer'AND s.is_arrived=FALSE;
4.3.4.4 测试小结
三张表进行JOIN时,会分别获取orders、products、shipments三张表的行级权限条件: region = 'beijing'、name = 'hammer'和is_arrived = FALSE,然后增加orders表的别名o、products表的别名p、shipments表的别名s,最后组装到WHERE子句后面。
4.3.5 INSERT来自带子查询的SELECT
4.3.5.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
4.3.5.2 输入SQL
INSERT INTO print_sink SELECT * FROM (SELECT * FROM orders);
4.3.5.3 输出SQL
INSERT INTO print_sink (SELECT * FROM (SELECT * FROM orders WHERE region = 'beijing'));
4.3.5.4 测试小结
无论运行SQL类型是INSERT、SELECT或者其他,只会找到查询oders表的子句,然后对其组装行级权限条件。
4.3.6 运行SQL
测试两个不同用户执行相同的SQL,两个用户的行级权限条件不一样。
4.3.6.1 行级权限条件
| 序号 | 用户名 | 表名 | 行级权限条件 |
|---|---|---|---|
| 1 | 用户A | orders | region = ‘beijing’ |
| 2 | 用户B | orders | region = ‘hangzhou’ |
4.3.6.2 输入SQL
SELECT * FROM orders;
4.3.6.3 执行SQL
用户A的真实执行SQL:
SELECT * FROM orders WHERE region = 'beijing';
用户B的真实执行SQL:
SELECT * FROM orders WHERE region = 'hangzhou';
4.3.6.4 测试小结
用户调用下面的执行方法,除传递要执行的SQL参数外,只需要额外指定执行的用户即可,便能自动按照行级权限限制来执行。
/*** Execute the single sql with user permissions*/
public TableResult execute(String username, String singleSql) {System.setProperty(EXECUTE_USERNAME, username);return tableEnv.executeSql(singleSql);
}
五、源码修改步骤
注: Flink版本1.16.0依赖的Calcite是1.26.0版本。
5.1 新增Parser和ParserImpl类
复制Flink源码中的org.apache.flink.table.delegation.Parser和org.apache.flink.table.planner.delegation.ParserImpl到项目下,新增下面两个方法及实现。
/*** Parses a SQL expression into a {@link SqlNode}. The {@link SqlNode} is not yet validated.** @param sqlExpression a SQL expression string to parse* @return a parsed SQL node* @throws SqlParserException if an exception is thrown when parsing the statement*/
@Override
public SqlNode parseExpression(String sqlExpression) {CalciteParser parser = calciteParserSupplier.get();return parser.parseExpression(sqlExpression);
}/*** Entry point for parsing SQL queries and return the abstract syntax tree** @param statement the SQL statement to evaluate* @return abstract syntax tree* @throws org.apache.flink.table.api.SqlParserException when failed to parse the statement*/
@Override
public SqlNode parseSql(String statement) {CalciteParser parser = calciteParserSupplier.get();// use parseSqlList here because we need to support statement end with ';' in sql client.SqlNodeList sqlNodeList = parser.parseSqlList(statement);List<SqlNode> parsed = sqlNodeList.getList();Preconditions.checkArgument(parsed.size() == 1, "only single statement supported");return parsed.get(0);
}
5.2 新增SqlSelect类
复制Calcite源码中的org.apache.calcite.sql.SqlSelect到项目下,新增上文提到的addCondition()、addPermission()、buildWhereClause()三个方法。
并且在构造方法中注释掉原有的this.where = where行,并添加如下代码:
// add row level filter condition for where clause
SqlNode rowFilterWhere = addCondition(from, where, false);
if (rowFilterWhere != where) {LOG.info("Rewritten SQL based on row-level privilege filtering for user [{}]", System.getProperty(EXECUTE_USERNAME));
}
this.where = rowFilterWhere;
5.3 封装SecurityContext类
新建SecurityContext类,主要添加下面三个方法:
/*** Add row-level filter conditions and return new SQL*/
public String addRowFilter(String username, String singleSql) {System.setProperty(EXECUTE_USERNAME, username);// in the modified SqlSelect, filter conditions will be added to the where clauseSqlNode parsedTree = tableEnv.getParser().parseSql(singleSql);return parsedTree.toString();
}/*** Query the configured permission point according to the user name and table name, and return* it to SqlBasicCall*/
public SqlBasicCall queryPermissions(String username, String tableName) {String permissions = rowLevelPermissions.get(username, tableName);LOG.info("username: {}, tableName: {}, permissions: {}", username, tableName, permissions);if (permissions != null) {return (SqlBasicCall) tableEnv.getParser().parseExpression(permissions);}return null;
}/*** Execute the single sql with user permissions*/
public TableResult execute(String username, String singleSql) {System.setProperty(EXECUTE_USERNAME, username);return tableEnv.executeSql(singleSql);
}六、下一步计划
- 支持数据脱敏(Data Masking)
- 开发ranger-flink-plugin
七、参考文献
- 数据管理DMS-敏感数据管理-行级管控
- Apache Ranger Row-level Filter
- OpenLooKeng的行级权限控制
- PostgreSQL中的行级权限/数据权限/行安全策略
- FlinkSQL字段血缘解决方案及源码
- 基于 Flink CDC 构建 MySQL 和 Postgres 的 Streaming ETL
相关文章:
FlinkSQL行级权限解决方案及源码
FlinkSQL的行级权限解决方案及源码,支持面向用户级别的行级数据访问控制,即特定用户只能访问授权过的行,隐藏未授权的行数据。此方案是实时领域Flink的解决方案,类似离线数仓Hive中Ranger Row-level Filter方案。 源码地址: https…...

【基础篇】8 # 递归:如何避免出现堆栈溢出呢?
说明 【数据结构与算法之美】专栏学习笔记 什么是递归? 递归是一种应用非常广泛的算法(或者编程技巧),比如 DFS 深度优先搜索、前中后序二叉树遍历等等都是用到了递归。 方法或函数调用自身的方式称为递归调用,调用…...

基于微信公众号(服务号)实现扫码自动登录系统功能
微信提供了两种方法都可以实现扫描登录。 一种是基于微信公众平台的扫码登录,另一种是基于微信开放平台的扫码登录。 两者的区别: 微信开放平台需要企业认证才能注册(认证费用300元,只需要认证1次,后续不再需要进行缴费年审&#…...
AXI实战(二)-跟着产品手册设计AXI-Lite外设(AXI-Lite转串口实现)
AXI实战(二)-跟着产品手册设计AXI-Lite 设(AXI-Lite转串口实现) 看完在本文后,你将可能拥有: 一个AXI_Lite转串口的从端(Slave)设计使用SV仿真AXI-Lite总线的完整体验实现如何在读通道中实现"等待"小何的AXI实战系列开更了,以下是初定的大纲安排: 欢迎感兴趣的…...
一周搞定模拟电路视频教程,拒绝讲PPT,仿真软件配合教学,真正一周搞定
目录1、灵魂拷问2、懦夫救星3、福利领取2、使用流程1、灵魂拷问 问:模拟电路很难吗? 答:嗯,真的很难!!! 问:模拟电路容易学吗? 答:很难学,建议放…...

高德地图获得角度
//传入两个经纬度点得到车辆角度 设置车辆Marker角度 getAngle(startPoint, endPoint) {if (!(startPoint && endPoint)) {return 0;}let dRotateAngle Math.atan2(Math.abs(startPoint.lng - endPoint.lng),Math.abs(startPoint.lat - endPoint.lat));console.log(&q…...
【C++】-- C++11基础常用知识点(下)
上篇: 【C】-- C11基础常用知识点(上)_川入的博客-CSDN博客 目录 新的类功能 默认成员函数 可变参数模板 可变参数 可变参数模板 empalce lambda表达式 C98中的一个例子 lambda表达式 lambda表达式语法 捕获列表 lambda表达底层 …...
提到数字化,你想到哪些关键词
我们的生活中已经充满了数据,各种岗位例如运营、市场、营销上也都喜欢在职位要求加上一条利用数据、亦或是懂得数据分析。事实上,数据已经成为了构建现代社会的基本生产要素,并且因为不受自然环境的限制,已经成为了人们对未来社会…...

【蓝桥杯集训·每日一题】AcWing 1249. 亲戚
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴并查集一、题目 1、原题链接 1249. 亲戚 2、题目描述 或许你并不知道,你的某个朋友是你的亲戚。 他可能是你的曾祖父的外公的女婿的外甥女的表姐的孙子。 如果…...

iphone所有机型的屏幕尺寸
手机设备型号屏幕尺寸(吋)分辨率点数(pt)屏幕显示模式分辨率像素(px)屏幕比例iPhone SE4.03205682x640113616:9iPhone 6/6s/7/8/SE 24.73756672x750133416:9iPhone 6P/7P/8P5.54147363x1242220816:9iPhone XR/116.14148962x828179219.5:9iPhone X/XS/11P5.83758123x1125243619.…...
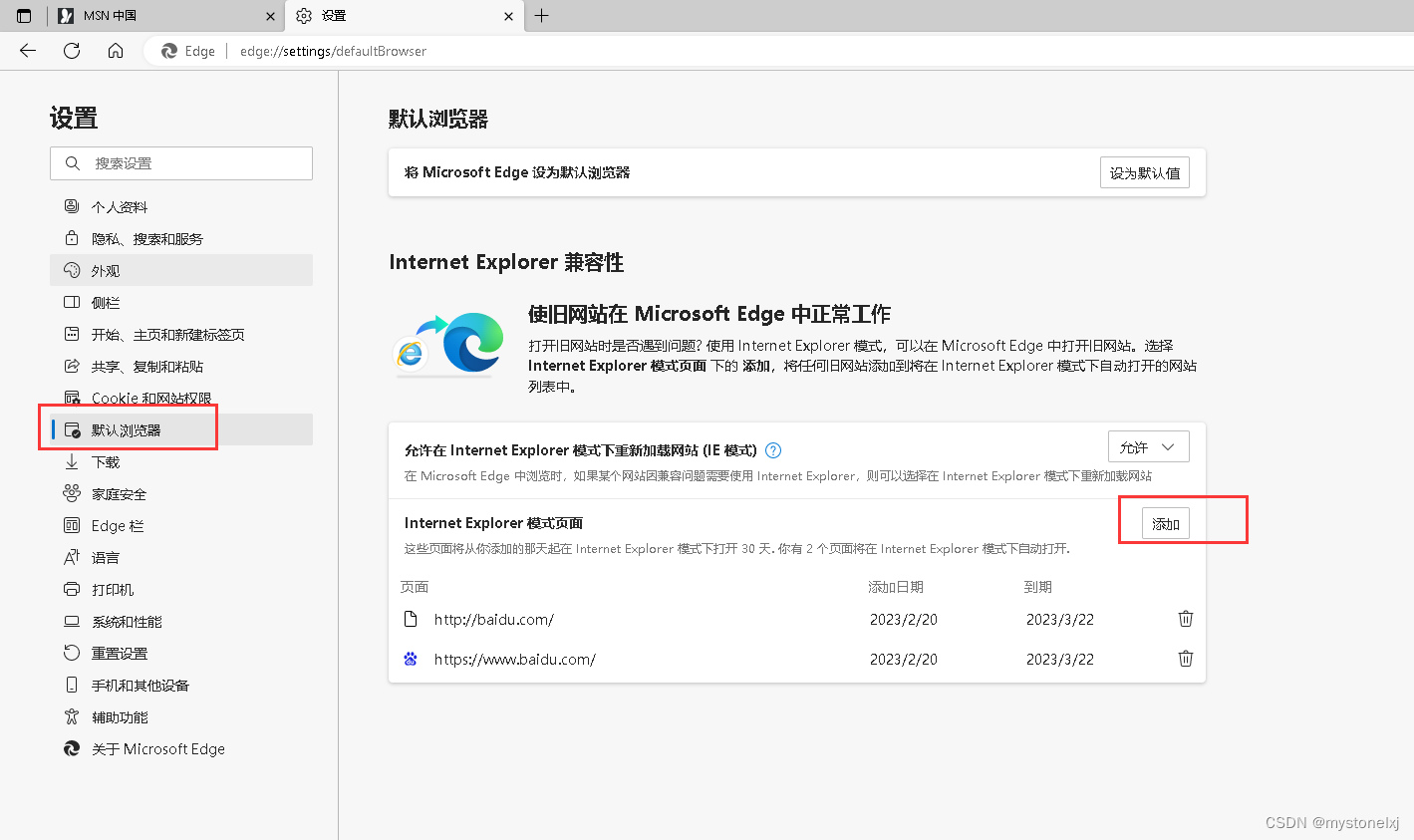
Windows10使用-处理IE自动跳转至Edge
文章目录 前言一、调整Edge二、调整Internet选项三、搜索栏的恢复总结前言 微软官方宣布,自2023年2月14日永久停止支持Internet Explorer 11浏览器。后期点击IE 图标将会自动跳转到Edge界面。对于一些网站,可能需要使用IE模式才能正常使用,这时候就需要做相应的调整,才能够…...
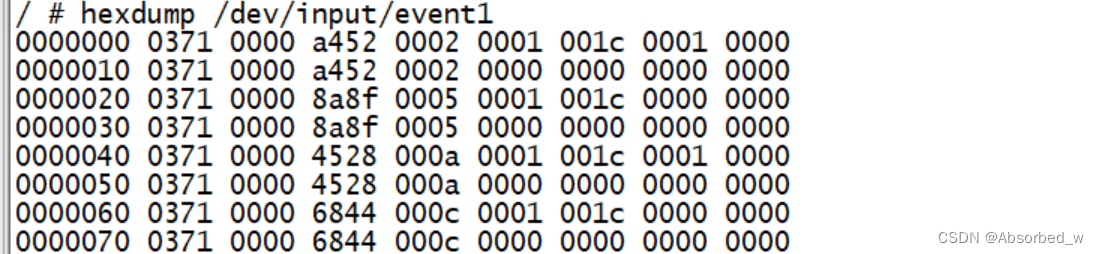
linux input子系统,gpio-keys,gpio中断使用
GPIO控制 嵌入式linux下应用编程会经常使用到gpio,GPIO 可以通过 sysfs 方式进行操控,进入到/sys/class/gpio 目录下,如下所示: 可以看到该目录下包含两个文件 export、 unexport 以及 5 个 gpiochipX(X 等于 0、 32、…...

分析称勒索攻击在非洲、中东与中国增长最快
Orange Cyberdefense(OCD)于 2022 年 12 月 1 日发布了最新的网络威胁年度报告。报告中指出,网络勒索仍然是头号威胁 ,也逐渐泛滥到世界各地。 报告中的网络威胁指的是企业网络中的某些资产被包括勒索软件在内的攻击进行勒索&…...

ArcPy批量合并矢量shape文件
当有大量矢量(.shp)格式文件需要合并成一个矢量文件时,可以考虑使用 ArcPy 进行批量合并,代码如下: # coding:utf-8 import os import arcpy from arcpy import envenv.workspace "C:/Users/Desktop/demo"…...

改写有序表的题目核心点
1、核心点 1)分析增加什么数据项可以支持题目 2)有序表一定要保持内部参与排序的key不重复 【补充说明:要存储重复的key值,要么将相同的key压在一起,要么将每个key再封装一层,用内存地址区分】 3&#…...
收藏这几个开源管理系统做项目,领导看了直呼牛X!
项目SCUI Admin 中后台前端解决方案Vue .NetCore 前后端分离的快速发开框架next-admin 适配移动端、pc的后台模板django-vue-admin-pro 快速开发平台Admin.NET 通用管理平台RuoYi 若依权限管理系统Vue3.2 Element-Plus 后台管理框架Pig RABC权限管理系统zheng 分布式敏捷开发…...
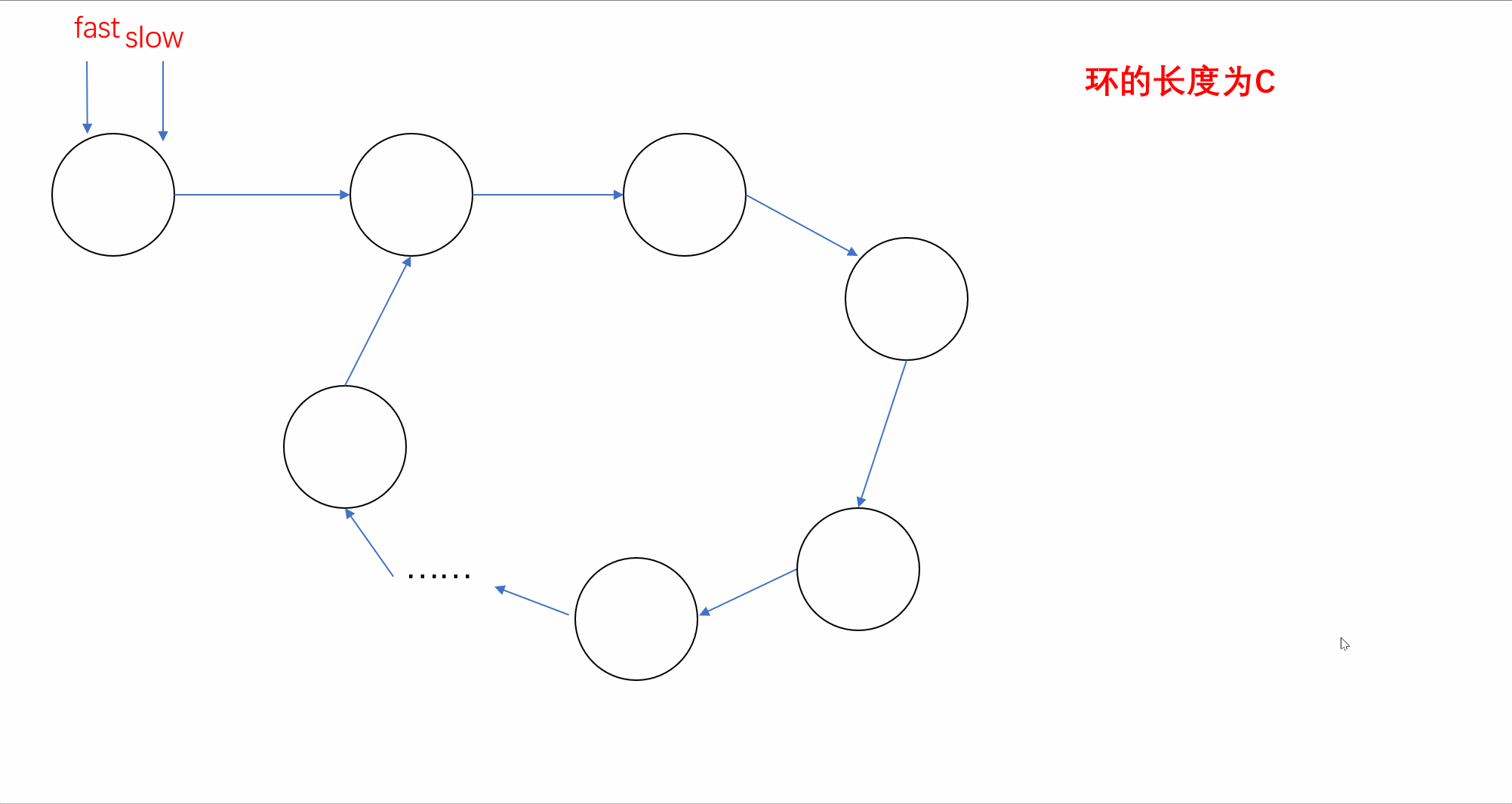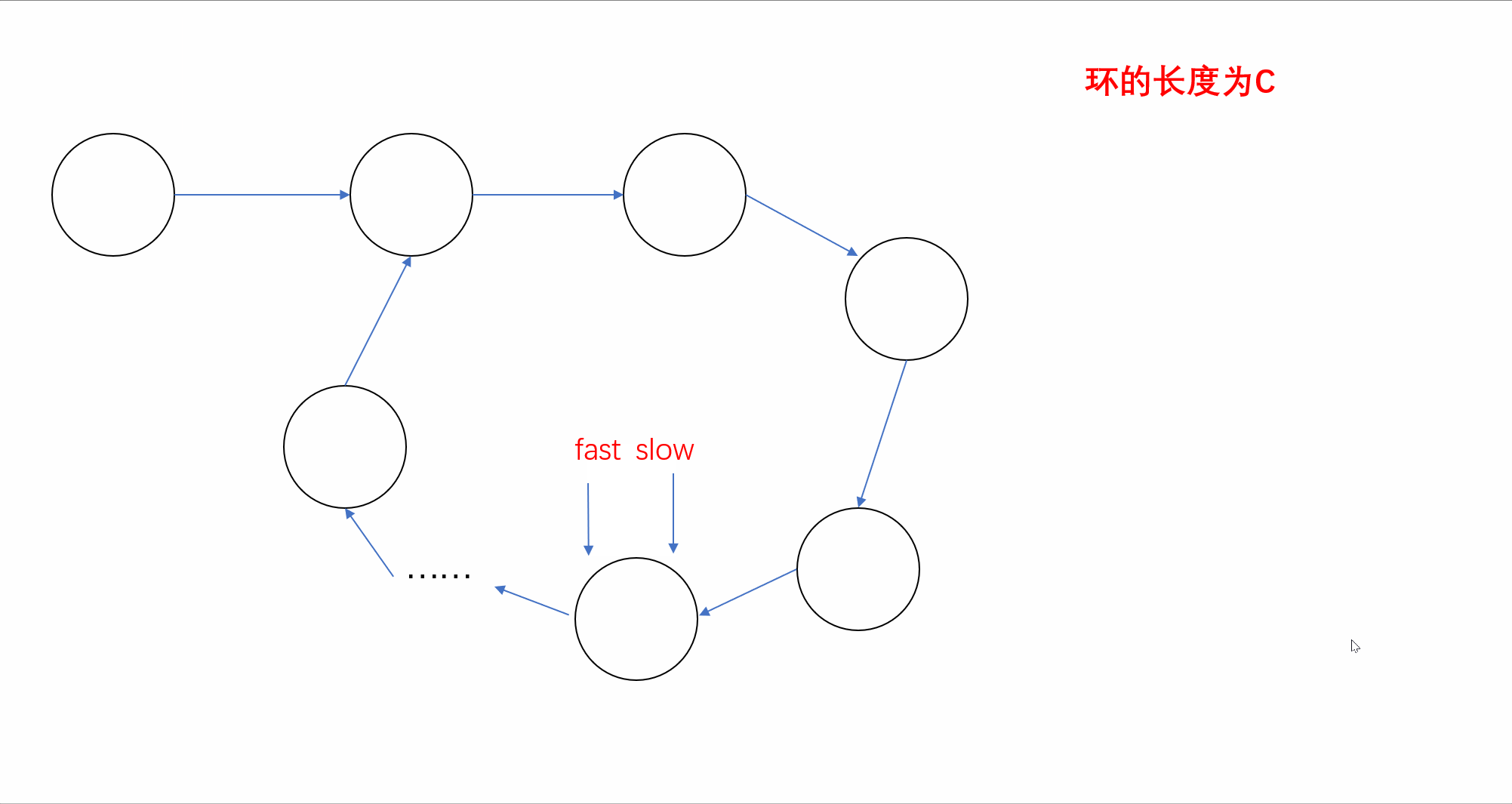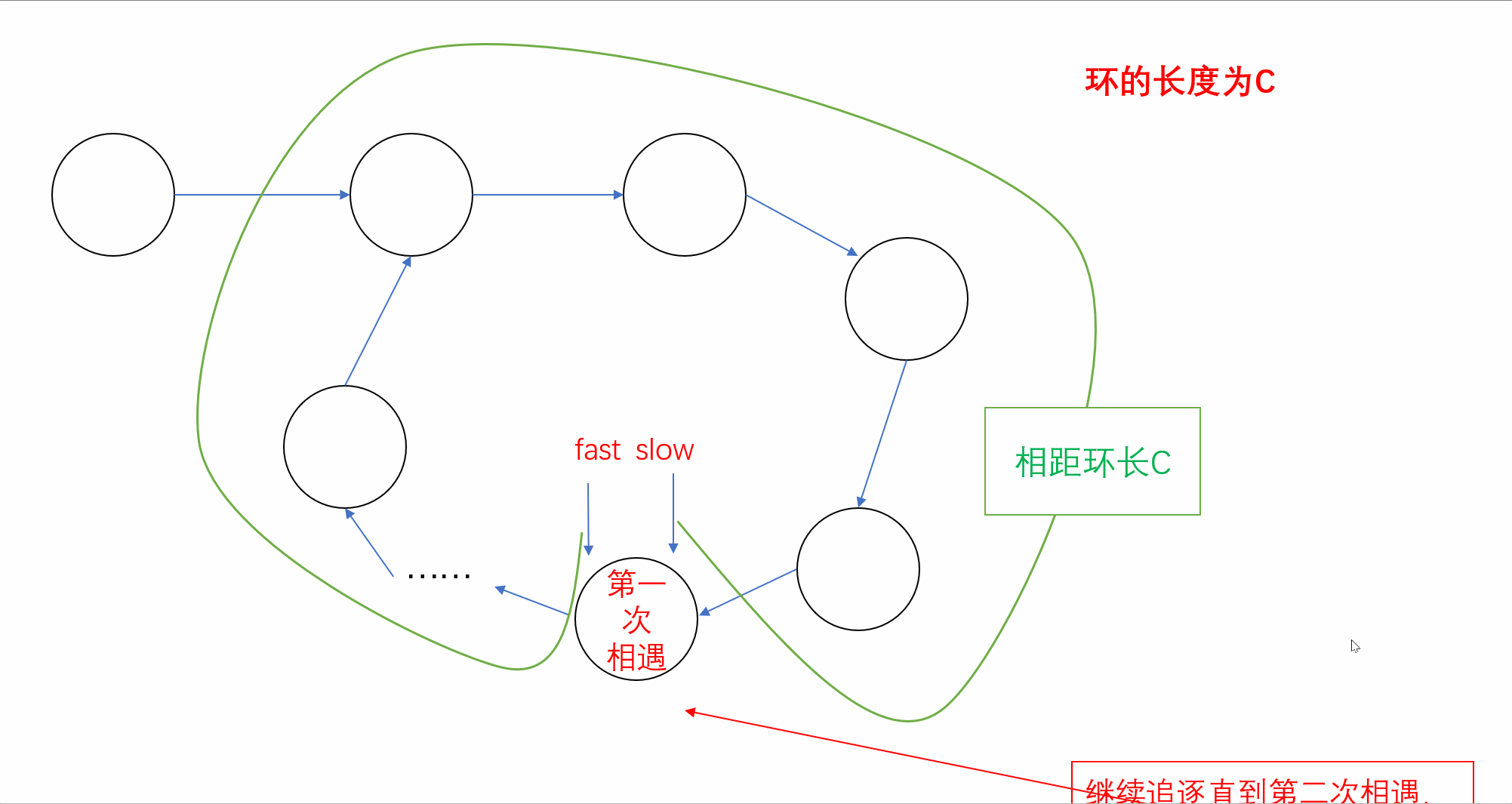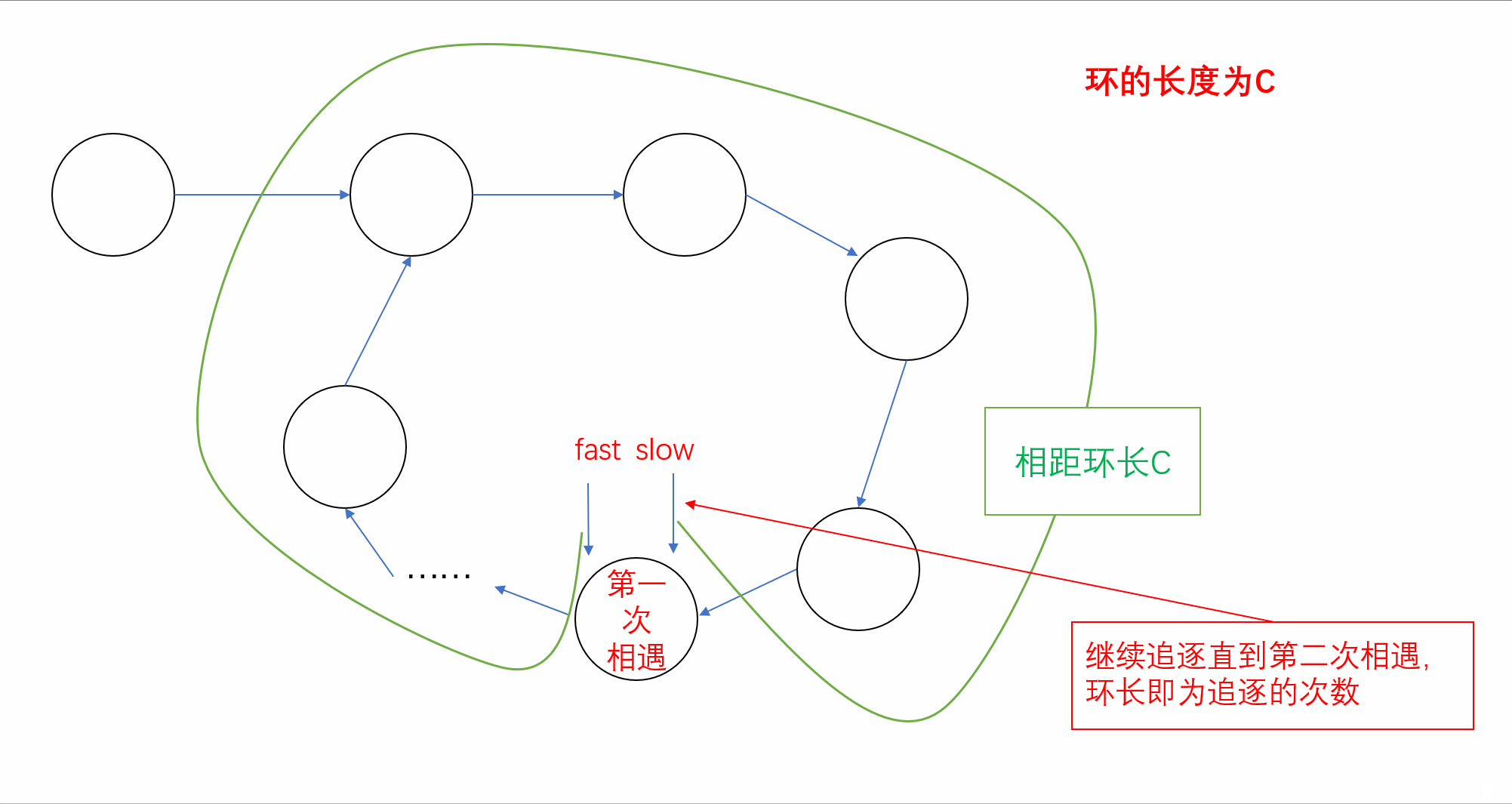
【刷题篇】链表(下)
前言🌸各位读者们好,本期我们来填填之前留下的坑,继续来讲解几道和链表相关的OJ题。但和上期单向链表不一样的是,我们今天的题目主要是于环形链表有关,下面让我们一起看看吧。💻本期的题目有:环…...
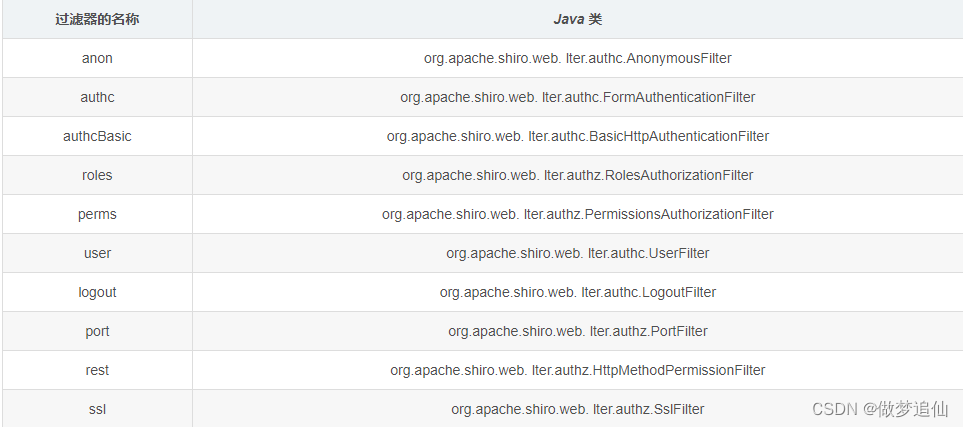
Shiro
Shiro 1.权限管理概述 2.Shiro权限框架 2.1 概念 2.2 Apache Shiro 与Spring Security区别 3.Shiro认证 3.1 基于ini认证 3.2 自定义Realm --认证 4.Shiro授权 4.1 基于ini授权 4.2 自定义realm – 授权 5.项目集成shiro 认证-授权注意点 5.1 认证…...
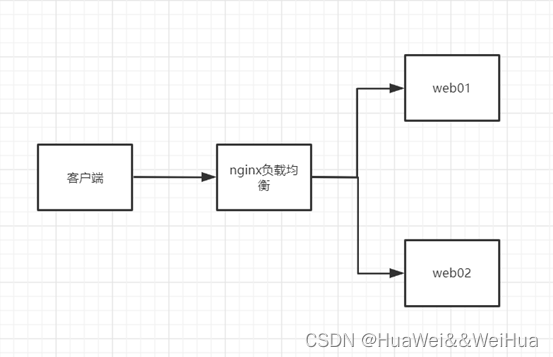
使用nginx进行负载均衡配置详细说明
使用nginx进行负载均衡 1. nginx负载均衡介绍 nginx应用场景之一就是负载均衡。在访问量较多的时候,可以通过负载均衡,将多个请求分摊到多台服务器上,相当于把一台服务器需要承担的负载量交给多台服务器处理,进而提高系统的吞吐…...

N皇后问题
#include<iostream> #include<string> #include<vector> using namespace std; #define MAX 20//最大20个皇后 int n ;//实际皇后个数 int sum ;//答案个数 vector<vector<int>> attack(MAX, vector<int>(MAX, 0));//标记攻击位置 vector&…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

JavaScript对象创建:告别繁琐,四种灵活写法一学就会
在JavaScript里,创建对象的这般方法常把刚开始学习的新手弄得困惑不已,好像无论走哪条道都行得通,可又不清楚该挑哪一条才好。我编写JavaScript都有十几年功夫了,对象创建这事差不多每天都会碰到可谓基础技能。它不像变量声明那般…...

从API调用成功率看Taotoken服务的稳定性与容灾表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用成功率看Taotoken服务的稳定性与容灾表现 在将大模型能力集成到自动化流程或日常开发工具链时,服务的稳定性和…...

为内部知识库问答机器人集成taotoken多模型能力的架构设计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人集成taotoken多模型能力的架构设计 应用场景类,探讨为企业内部知识库构建智能问答机器人时&…...

Mysql?基础语法!!!
作为程序员、数据分析从业者,甚至是产品运营,SQL都是必须掌握的核心技能。不管是后端开发对数据库增删改查,还是数据分析提取业务数据,本质都是在写SQL语句。很多新手觉得SQL难,其实是没有理清逻辑。SQL的核心逻辑非常…...