大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。
因此,该技术值得我们进行深入分析其背后的机理,本系列大体分七篇文章进行讲解。
-
大模型参数高效微调技术原理综述(一)-背景、参数高效微调简介 -
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning -
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2 -
大模型参数高效微调技术原理综述(四)-Adapter Tuning及其变体 -
大模型参数高效微调技术原理综述(五)-LoRA、AdaLoRA、QLoRA -
大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT -
大模型参数高效微调技术原理综述(七)-最佳实践、总结
本文为大模型参数高效微调技术原理综述的第二篇。
BitFit
背景
虽然对每个任务进行全量微调非常有效,但它也会为每个预训练任务生成一个独特的大型模型,这使得很难推断微调过程中发生了什么变化,也很难部署, 特别是随着任务数量的增加,很难维护。
理想状况下,我们希望有一种满足以下条件的高效微调方法:
-
到达能够匹配全量微调的效果。 -
仅更改一小部分模型参数。 -
使数据可以通过流的方式到达,而不是同时到达,便于高效的硬件部署。 -
改变的参数在不同下游任务中是一致的。
上述的问题取决于微调过程能多大程度引导新能力的学习以及暴露在预训练LM中学到的能力。
虽然,之前的高效微调方法Adapter-Tuning、Diff-Pruning也能够部分满足上述的需求。但是,作者提出了一种参数量更小的稀疏的微调方法BitFit,来满足上述的需求。
技术原理
BitFit(论文:BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models)是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。
在Bert-Base/Bert-Large这种模型里,bias参数仅占模型全部参数量的0.08%~0.09%。但是通过在Bert-Large模型上基于GLUE数据集进行了 BitFit、Adapter和Diff-Pruning的效果对比发现,BitFit在参数量远小于Adapter、Diff-Pruning的情况下,效果与Adapter、Diff-Pruning想当,甚至在某些任务上略优于Adapter、Diff-Pruning。
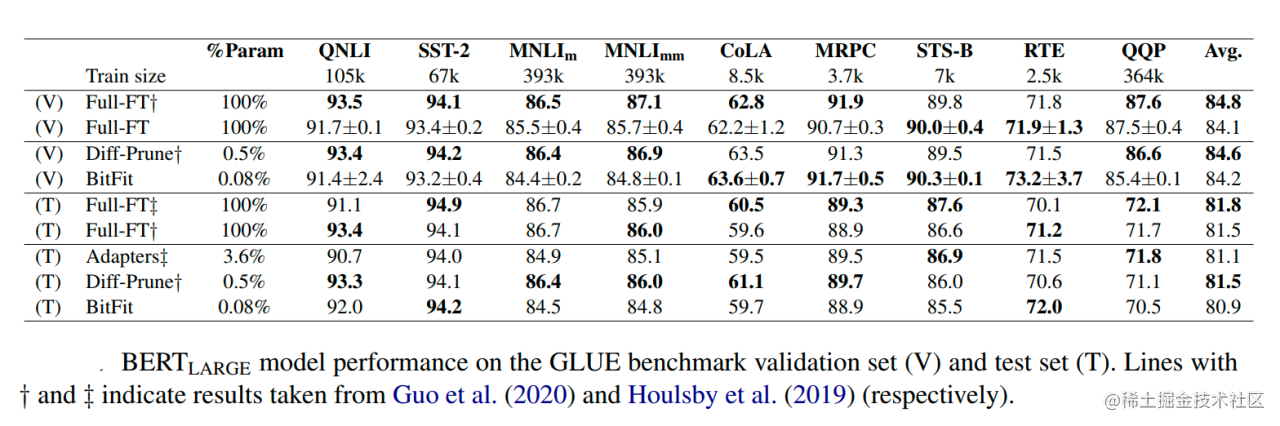
同时,通过实验结果还可以看出,BitFit微调结果相对全量参数微调而言, 只更新极少量参数的情况下,在多个数据集上都达到了不错的效果,虽不及全量参数微调,但是远超固定全部模型参数的Frozen方式。

同时,通过对比BitFit训练前后的参数,发现很多bias参数并没有太多变化(例如:跟计算key所涉及到的bias参数)。发现计算query和将特征维度从N放大到4N的FFN层(intermediate)的bias参数变化最为明显,只更新这两类bias参数也能达到不错的效果,反之,固定其中任何一者,模型的效果都有较大损失。

Prefix Tuning
背景
在Prefix Tuning之前的工作主要是人工设计离散的模版或者自动化搜索离散的模版。对于人工设计的模版,模版的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。而对于自动化搜索模版,成本也比较高;同时,以前这种离散化的token搜索出来的结果可能并不是最优的。
除此之外,传统的微调范式利用预训练模型去对不同的下游任务进行微调,对每个任务都要保存一份微调后的模型权重,一方面微调整个模型耗时长;另一方面也会占很多存储空间。
基于上述两点,Prefix Tuning提出固定预训练LM,为LM添加可训练,任务特定的前缀,这样就可以为不同任务保存不同的前缀,微调成本也小;同时,这种Prefix实际就是连续可微的Virtual Token(Soft Prompt/Continuous Prompt),相比离散的Token,更好优化,效果更好。
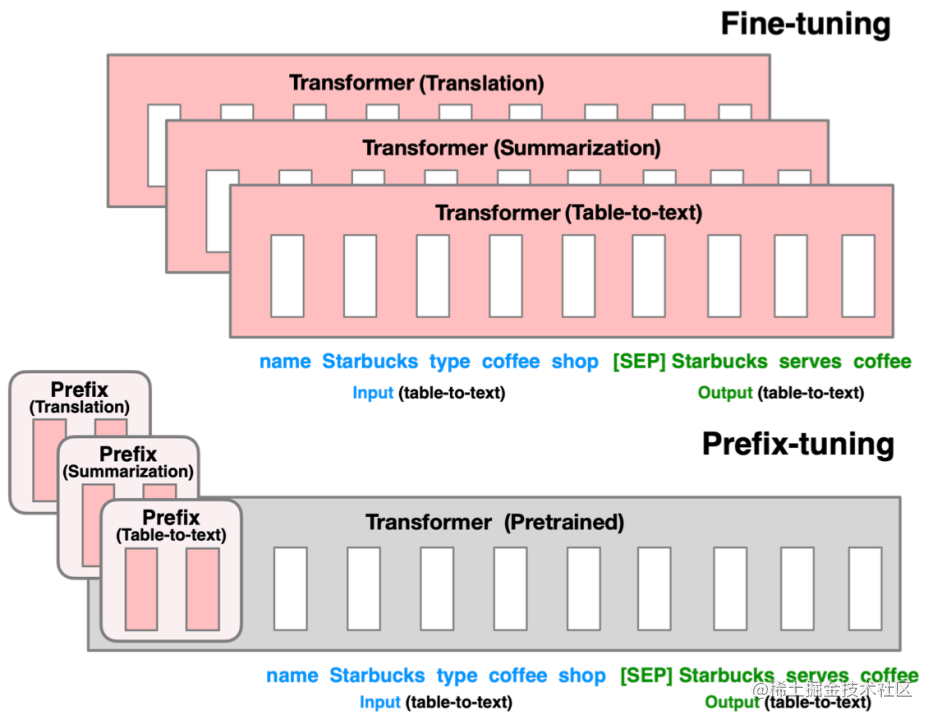
技术原理
Prefix Tuning(论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation),在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。
针对不同的模型结构,需要构造不同的Prefix。
-
针对自回归架构模型:在句子前面添加前缀,得到 z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。 -
针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到 z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。

该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
 同时,为了防止直接更新Prefix的参数导致训练不稳定和性能下降的情况,在Prefix层前面加了MLP结构,训练完成后,只保留Prefix的参数。
同时,为了防止直接更新Prefix的参数导致训练不稳定和性能下降的情况,在Prefix层前面加了MLP结构,训练完成后,只保留Prefix的参数。
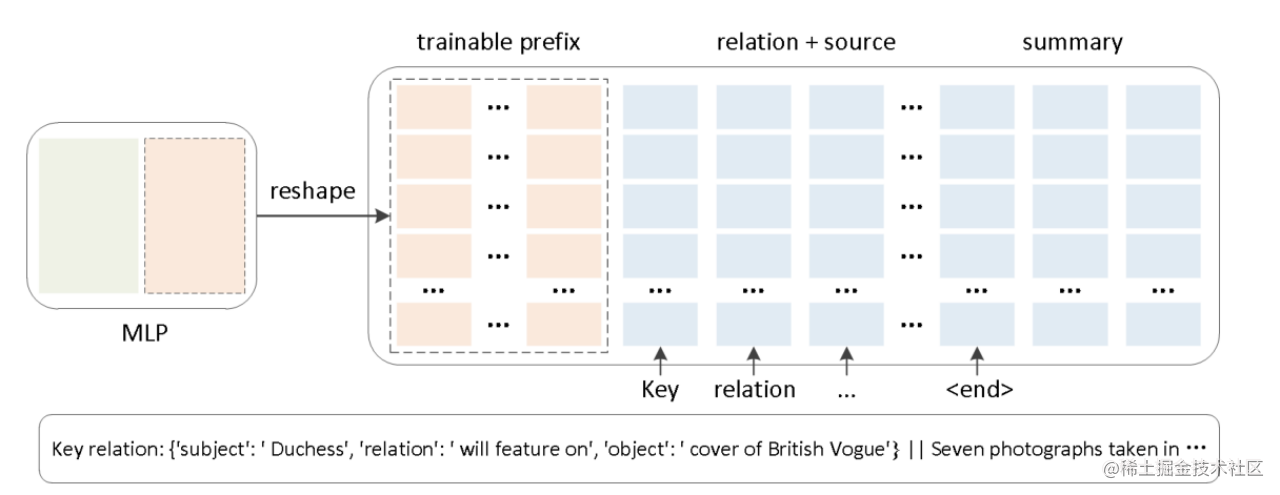
除此之外,通过消融实验证实,只调整embedding层的表现力不够,将导致性能显著下降,因此,在每层都加了prompt的参数,改动较大。

另外,实验还对比了位置对于生成效果的影响,Prefix-tuning也是要略优于Infix-tuning的。其中,Prefix-tuning形式为 [PREFIX; x; y],Infix-tuning形式为 [x; INFIX; y]。

Prompt Tuning
背景
大模型全量微调对每个任务训练一个模型,开销和部署成本都比较高。同时,离散的prompts(指人工设计prompts提示语加入到模型)方法,成本比较高,并且效果不太好。
基于此,作者提出了Prompt Tuning,通过反向传播更新参数来学习prompts,而不是人工设计prompts;同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理。
技术原理
Prompt Tuning(论文:The Power of Scale for Parameter-Efficient Prompt Tuning),该方法可以看作是Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。

通过实验发现,随着预训练模型参数量的增加,Prompt Tuning的方法会逼近全参数微调的结果。
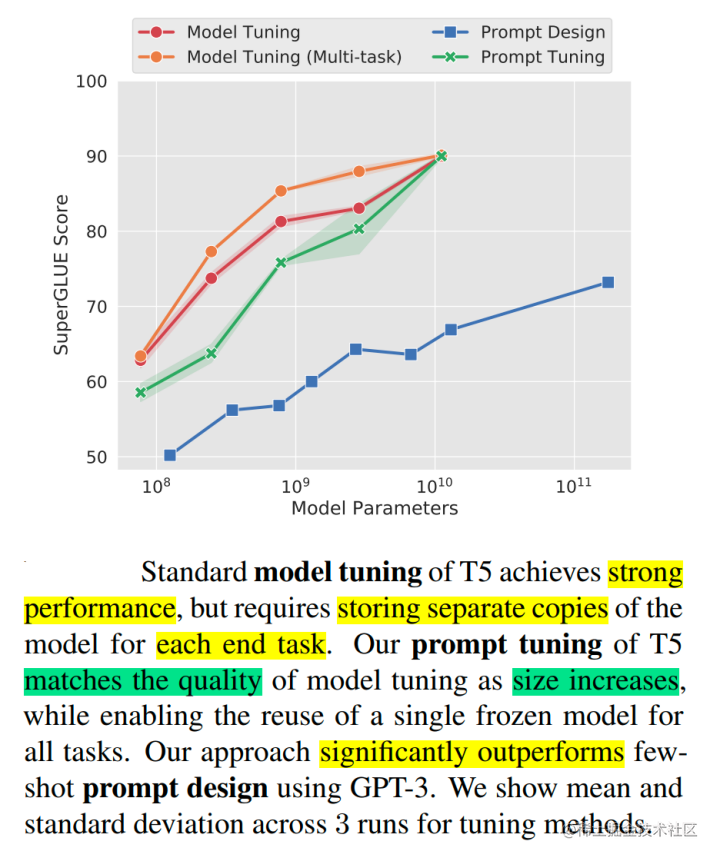
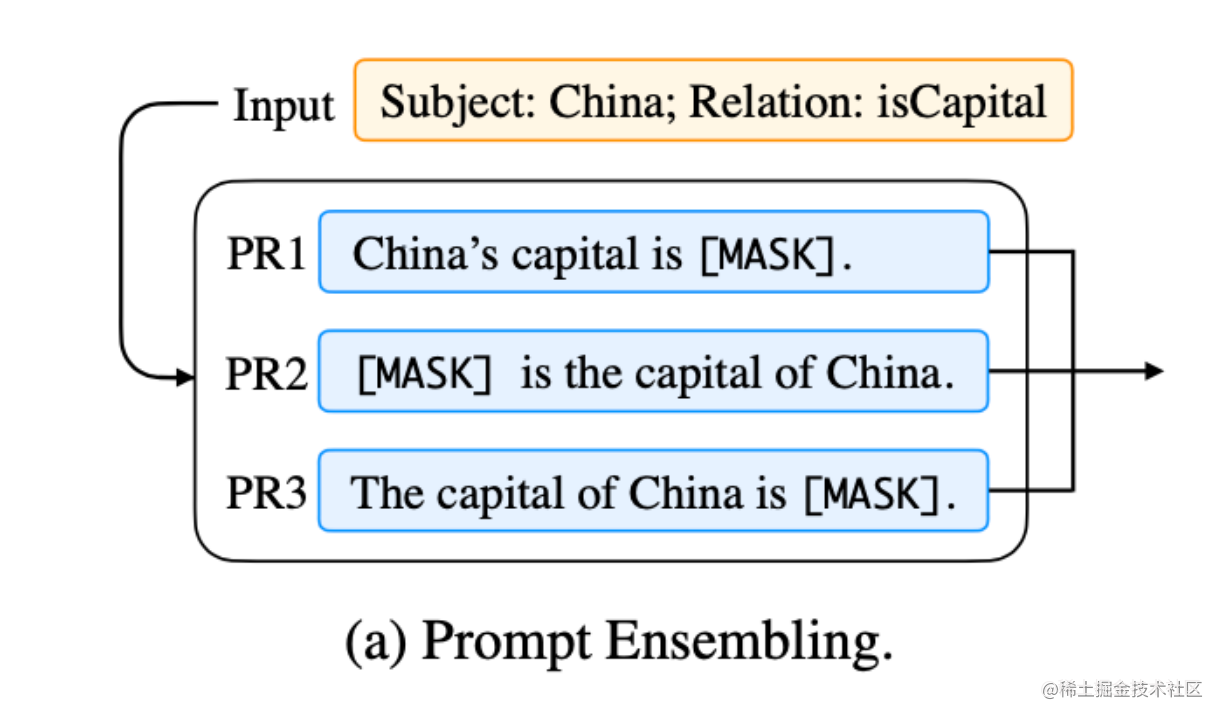
同时,Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型,比模型集成的成本小多了。
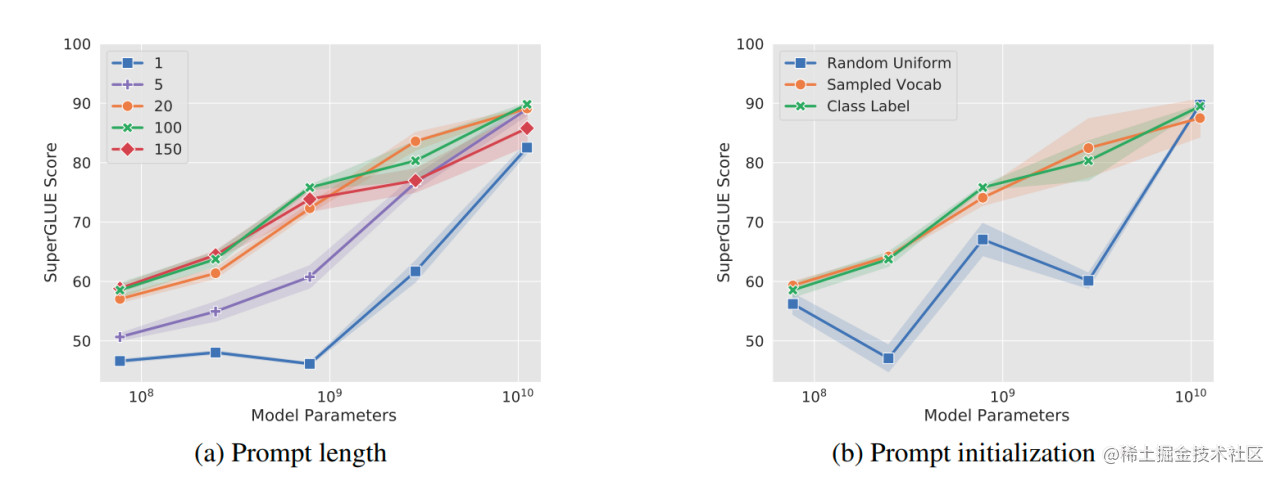
除此之外,Prompt Tuning 论文中还探讨了 Prompt token 的初始化方法和长度对于模型性能的影响。通过消融实验结果发现,与随机初始化和使用样本词汇表初始化相比,Prompt Tuning采用类标签初始化模型的效果更好。不过随着模型参数规模的提升,这种gap最终会消失。
Prompt token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了),同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使 Prompt token 长度很短,对性能也不会有太大的影响)。
结语
本文针对讲述了仅更新一部分参数高效微调方法BitFit以及通过增加额外参数的软提示高效微调方法Prefix Tuning、Prompt Tuning,下文将对高效微调方法P-Tuning、P-Tuning v2进行讲解。
如果觉得我的文章能够能够给你带来帮助,欢迎点赞收藏加关注~~
相关文章:
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。 因此,…...

将conda环境打包成docker步骤
1. 第一步,将conda环境的配置导出到environment.yml 要获取一个Conda环境的配置文件 environment.yml,你可以使用以下命令从已存在的环境中导出: conda env export --name your_env_name > environment.yml请将 your_env_name 替换为你要…...

C# 获取Json对象中指定属性的值
在C#中获取JSON对象中指定属性的值,可以使用Newtonsoft.JSON库的JObject类 using Newtonsoft.Json.Linq; using System; public class Program { public static void Main(string[] args) { string json "{ Name: John, age: 30, City: New York }"; …...
【LeetCode】202. 快乐数 - hash表 / 快慢指针
目录 2023-9-5 09:56:152023-9-6 19:40:51 202. 快乐数 2023-9-5 09:56:15 关键是怎么去判断循环: hash表: 每次生成链中的下一个数字时,我们都会检查它是否已经在哈希集合中。 如果它不在哈希集合中,我们应该添加它。如果它在…...

什么是多态性?如何在面向对象编程中实现多态性?
1、什么是多态性?如何在面向对象编程中实现多态性? 多态性(Polymorphism)是指在同一个方法调用中,由于参数类型不同,而产生不同的行为。在面向对象编程中,多态性是一种重要的特性,它…...
【目标检测】理论篇(3)YOLOv5实现
Yolov5网络构架实现 import torch import torch.nn as nnclass SiLU(nn.Module):staticmethoddef forward(x):return x * torch.sigmoid(x)def autopad(k, pNone):if p is None:p k // 2 if isinstance(k, int) else [x // 2 for x in k] return pclass Focus(nn.Module):def …...
IDEA爪哇操作数据库
少小离家老大回,乡音无改鬓毛衰 ⒈.IDEA2018设置使用主题颜色 IDEA2018主题颜色分为三种:idea原始颜色,高亮色,黑色 设置方法:Settings–Appearance&Behavior–Appearance ⒉.mysql中,没有my.ini,只有…...
一文速学-让神经网络不再神秘,一天速学神经网络基础(七)-基于误差的反向传播
前言 思索了很久到底要不要出深度学习内容,毕竟在数学建模专栏里边的机器学习内容还有一大半算法没有更新,很多坑都没有填满,而且现在深度学习的文章和学习课程都十分的多,我考虑了很久决定还是得出神经网络系列文章,…...

C++ 异常处理——学习记录007
1. 概念 程序中的错误分为编译时错误和运行时错误。编译时出现的错误包括关键字拼写出错、语句分号缺少、括号不匹配等,编译时的错误容易解决。运行时出现的错误包括无法打开文件、数组越界和无法实现指定的操作。运行时出现的错误称为异常,对异常的处理…...

【BIM+GIS】“BIM+”是什么? “BIM+”技术详解
对于我们日常生活影响最大的是信息化和网络化给我们的日常生活带来革命性的变化。“互联网+“在建筑行业里可以称为“BIM+”。“BIM+”"即是通过BIM与各类技术(互联网、大数据等)结合去完成不同的任务。将产品的全生命周期和全制造流程的数字化以及基于信息通信技术的模块…...

Flink算子如何限流
目录 使用方法 调用类图 内部源码 GuavaFlinkConnectorRateLimiter RateLimiter 使用方法 重写AbstractRichFunction中的open()方法,在处理数据前调用limiter.acquire(1); 调用limiter.open(getRuntimeContext())的源码,实际内部是RateLimiter,根据并行度算出subTask…...

垃圾分代收集的过程是怎样的?
垃圾分代收集是Java虚拟机(JVM)中一种常用的垃圾回收策略。该策略将堆内存分为不同的代(Generation),通常分为年轻代(Young Generation)和老年代(Old Generation)。不同代的对象具有不同的生命周期和回收频率。 下面是Java中垃圾分代收集的一般过程: 1…...
NPM 常用命令(四)
目录 1、npm diff 1.1 描述 1.2 过滤文件 1.3 配置 diff diff-name-only diff-unified diff-ignore-all-space diff-no-prefix diff-src-prefix diff-dst-prefix diff-text global tag workspace workspaces include-workspace-root 2、npm dist-tag 2.1 常…...
Anaconda虚拟环境下导入opencv
文章目录 解决方法测试 解决方法 1、根据自己虚拟环境对于的python版本与电脑对应的位长选择具体的版本,例如python3.9选择cp39,64位电脑选择64 下载地址:资源地址 若是不确定自己虚拟环境对应的python版本,可以输入下列命令&…...
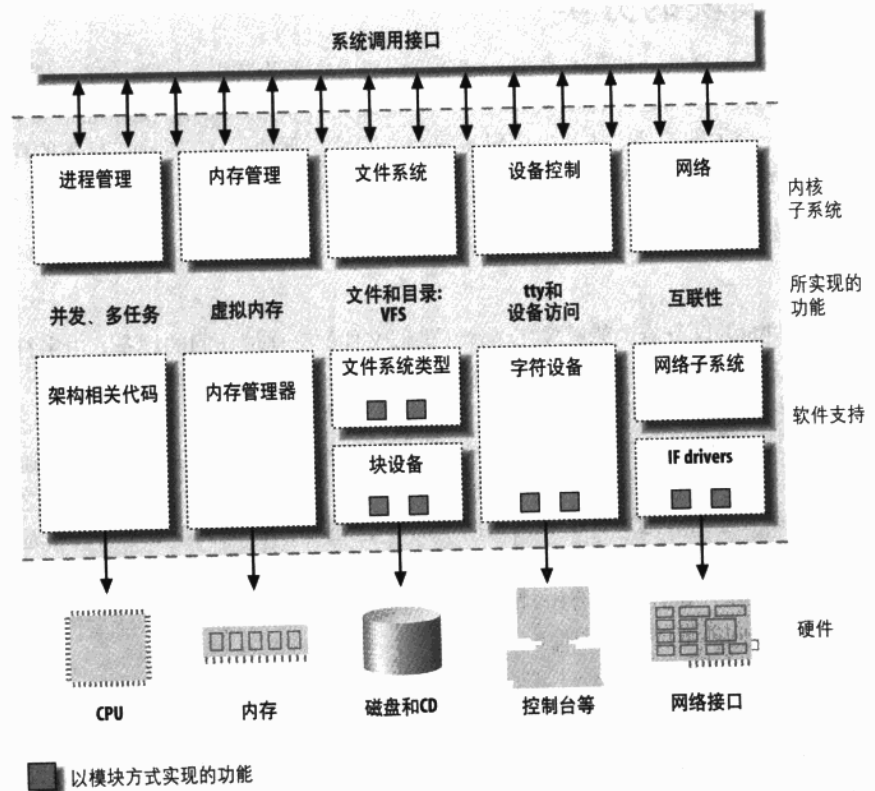
Linux设备驱动程序
一、设备驱动程序简介 图1.1 内核功能的划分 可装载模块 Linux有一个很好的特性:内核提供的特性可在运行时进行扩展。这意味着当系统启动 并运行时,我们可以向内核添加功能( 当然也可以移除功能)。 可在运行时添加到内核中的代码被称为“模块”。Linux内核支持好几…...

mybatis <if>标签判断“0“不生效
原if标签写法 <if test"type 0"><!--内部逻辑--> </if> 这种情况不生效,原因是mybatis是用OGNL表达式来解析的,在OGNL的表达式中,0’会被解析成字符(而我传入的type却是string),java是强类型的,cha…...

企业数据的存储形式与方案选择
企业数据的存储形式 DAS(直接附加存储):企业初期银行规模不大,企业的数据存储需求也比较简单,因此对企业数据存储的要求就是安全保存并可以随时调用。而DAS的之间连接可以解决单台服务器的存储空间扩展,高…...
图像处理简介
目录 基本术语 1 .图像(image) 1.1 像素(Pixel) 1.2 颜色深度(Color Depth) 1.3 分辨率(Resolution) 1.4 像素宽高比(Pixel Aspect Ratio) 1.5 帧率(FPS) 1.6 码率(BR) 1. …...
 doesn‘t match this client (41); killing.的解决办法)
adb server version (19045) doesn‘t match this client (41); killing.的解决办法
我是因为安装了360手机助手,导致adb版本冲突。卸载之后问题解决 根据这个思路,如果产生"adb server version (19045) doesn’t match this client (41); killing."的错误,检查一下是否有多个版本的adb服务。...
实验室的服务器和本地pycharm怎么做图传
提前说一个 自认为 比较重要的一点: 容器中安装opencv,可以先试试用 apt install libopencv-dev python3-opencv 我感觉在图传的时候用的不是 opencv-python 而是ubuntu的opencv库 所以用 apt install 安装试一下 参考 远程调试 qt.qpa.xcb: coul…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

高效视频帧提取终极指南:为深度学习构建专业数据集
高效视频帧提取终极指南:为深度学习构建专业数据集 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

基于Rust与Candle的AI推理引擎cria:简化大模型本地部署与优化
1. 项目概述:从“左移”到“创造”的AI推理引擎 最近在折腾AI模型本地部署和推理优化的朋友,可能都绕不开一个名字: cria 。这个由 leftmove 开源的项目,全称是“Cria: The AI Inference Engine”,直译过来就是“创…...

Docker Compose编排微服务
Docker Compose编排微服务 引言 Docker Compose是Docker官方提供的容器编排工具,用于定义和运行多容器Docker应用。通过Compose,可以使用YAML文件定义服务、网络、数据卷等资源,然后通过简单的命令启动和停止整个应用。Docker Compose特别适合…...