编写OpenCL程序的基本步骤
opencl
pyopencl
OpenCL-Headers
OpenCL(全称为Open Computing Langugae,开放运算语言)是第一个面向异构系统(此系统中可由CPU,GPU或其它类型的处理器架构组成)的并行编程的开放式标准。
它是跨平台的。
OpenCL由两部分组成,一是用于编写kernels(在OpenCL设备上运行的函数)的语言,二是用于定义并控制平台的API(函数)。
OpenCL提供了基于任务和基于数据两种并行计算机制,它极大地扩展了GPU的应用范围,使之不再局限于图形领域。
OpenCL是一种标准,intel、Nvidia、ARM、AMD、QUALCOMM、Apple都有其对应的OpenCL实现。
像NVDIA将OpenCL实现集成到它的CUDA SDK中,而AMD则将其实现后放在AMD APP (Accelerated Paral Processing)SDK中…
CUDA只支持NVIDIA自家的GPU。
CUDA C语言与OpenCL的定位不同,或者说是使用人群不同。CUDA C是一种高级语言,那些对硬件了解不多的非专业人士也能轻松上手;而OpenCL则是针对硬件的应用程序开发接口,它能给程序员更多对硬件的控制权,相应的上手及开发会比较难一些。
CUDA 与 opencl 名词比较:
Block: 相当于 opencl 中的work-group
Thread:相当于opencl 中的work-item
SP: 相当于opencl 中的PE
SM: 相当于opencl 中的CU
warp: 相当于opencl 中的wavefront(简称wave),基本的调试单位
Host端基本是串行的,CUDA和OpenCL的差别主要表现在调用Device的API的差异。
C Runtime for CUDA CUDA Driver API OpenCL API
-
Setup 环境初始化
Initialize driver Initialize plauorm Get device(s) Get devices (Choose device) Choose device Create context Create context Create command queue -
Device and host memory buffer setup内存初始化
Allocate host memory Allocate host memory Allocate host memory Allocate device memory for input Allocate device memory for input Allocate device memory for input Copy host memory to device memory Copy host memory to device memory Copy host memory to device memory Allocate device memory for result Allocate device memory for result Allocate device memory for result -
Initialize kernel 初始化内核函数程序
Load kernel module Load kernel source (Build program) Create program objectGet module function Build programCreate kernel object bound to kernel function -
Execute the kernel 执行内核函数程序
Setup execution configuration Setup kernel arguments Setup kernel arguments Invoke the kernel (directly with its parameters) Setup execution configuration Setup execution configurationInvoke the kernel Invoke the kernel -
Copy results to host 拷贝结果到主机
Copy results from device memory Copy results from device memory Copy results from device memory -
Cleanup 善后清理
Cleanup all set up above Cleanup all set up above Cleanup all set up above
框架组成
OpenCL平台API:平台API定义了宿主机程序发现OpenCL设备所用的函数以及这些函数的功能,另外还定义为OpenCL应用创建上下文(上下文表示的是程序运行时所拥有的所有软硬件资源+内存+处理器)的函数。这里的平台指的是宿主机、OpenCL设备和OpenCL框架的组合。
OpenCL运行时API:平台API主要用来创建上下文,运行时API则强调使用这个上下文满足应用需求的函数集,用来管理上下文来创建命令队列以及运行时发生的其它操作。例如,将命令提交到命令队列的函数。
OpenCL编程语言:用来编写内核代码的编程语言,基于ISO C99标准的一个扩展子集,通常称为OpenCL C编程语言。
基本概念
OpenCL程序同CUDA程序一样,也是分为两部分,一部分是在主机(以CPU为核心)上运行,一部分是在设备(以GPU为核心)上运行。设备有一个或多个计算单元,计算单元又包含一个或多个处理单元。在设备上运行的程序被称为核函数。但是对于核函数的编写,CUDA一般直接写在程序内,OpenCL是写在一个独立的文件中,并且文件后缀是.cl,由主机代码读入后执行,这一点OpenCL跟OpenGL中的渲染程序很像。
OpenCL平台由两部分组成,宿主机和OpenCL设备:
宿主机Host:宿主机一般为CPU,扮演组织者的角色。其作用包括定义kernel、为kernel指定上下文、定义NDRange和队列等;队列控制着kernel如何执行以及何时执行等细节。
设备Device:通常称为计算设备,可以是CPU、GPU、DSP或硬件提供以及OpenCL开发商支持的任何其他处理器。
SIMT(Single Instruction Multi Thread): 单指令多线程,GPU并行运算的主要方式,很多个多线程同时执行相同的运算指令,当然可能每个线程的数据有所不同,但执行的操作一致。
核函数(Kernel): 是在设备程序上执行运算的入口函数,在主机上调用。
工作项(Work-item): 跟CUDA中的线程(Threads)是同一个概念,N多个工作项(线程)执行同样的核函数,每个Work-item都有一个唯一固定的ID号,一般通过这个ID号来区分需要处理的数据。
工作组(Work-group):跟CUDA中的线程块(Block)是同一个概念,N多个工作项组成一个工作组,Work-group内的这些Work-item之间可以通信和协作。
ND-Range: 跟CUDA中的网格是同一个概念,定义了Work-group的组织形式。
上下文(Context): 定义了整个OpenCL的运行环境,包括Kernel、Device、程序对象和内存对象:
设备:OpenCL程序调用的计算设备。
Device(设备):通过cl_device来表现,使用下面的代码:
内核:在计算设备上执行的并行程序。
程序对象:内核程序的源代码(.cl文件)和可执行文件。
内存对象:计算设备执行OpenCL程序所需的变量。
编写OpenCL程序的基本步骤
0. 载入opencl库 (这种方法可使得程序在编译时脱离OpenCL库)handel = dlopen("dlOpenCL.so",其他参数); // 打开so共享库dlsym(handel,#func_name) // 注册库内部的函数
1. 检测申请计算资源 (初始化,一般只需要执行一次)1)获取平台 –> clGetPlatformIDs 先获取平台数量,再获取平台id列表2)从平台中获取设备–>clGetDeviceIDs 先获取设备数量,再获取设备id列表clGetDeviceInfo 获取设备信息(名字 版本 最大计算单元 全局内存缓冲区大小等信息)3)创建上下文–> clCreateContext4)创建命令队列–> clCreateCommandQueue前面为 平台层,后面为 运行时层5)创建缓存->clCreateBuffer
2. 拷贝主机数据到设备device clCreateBuffer
3. opencl程序编译6)读取程序文件,创建程序–>clCreateProgramWithSource7)编译程序–>clBuildProgram8)创建内核–>clCreateKernel9)为内核设置参数–>clSetKernelArg设置 NDRange
4. 运行kernel函数10)将内核发送给命令队列,执行内核–>clEnqueueNDRangeKernel
5. 拷贝设备上的计算结果到主机11)获取计算结果–>clEnqueueReadBuffer
6.释放计算资源12)释放资源–>clReleaseXX**释放kernel核, clReleaseKernel
释放program编译程序, clReleaseProgram
释放device memory设备内存, clReleaseMemObject
释放command queue指令队列, clReleaseCommandQueue
释放context上下文环境, clReleaseContext
CUDA C加速步骤:
1) 在device (也就是GPU) 上申请内存
2) 将host (也就是CPU) 上的数据拷贝到device
3) 执行CUDA kernel function
4) 将device上的计算结果传回host
5) 释放device上的内存
示例
向量相加
// c 语言版本
void vector_add_cpu (const float* src_a, // 向量a, 常量指针const float* src_b,float* res, // 结果向量const int num) // 数据数量
{for (int i = 0; i < num; i++)res[i] = src_a[i] + src_b[i]; // 一个线程在做
}// gpu kernel版本
// 在GPU上,逻辑就会有一些不同。我们使每个线程计算一个元素的方法来代替cpu程序中的循环计算。每个线程的index与要计算的向量的index相同。
__kernel void vector_add_gpu (__global const float* src_a, // gpu 上的 常量指针 数据__global const float* src_b,__global float* res,const int num)
{/* get_global_id(0) 返回正在执行的这个线程的ID。许多线程会在同一时间开始执行同一个kernel,每个线程都会收到一个不同的ID,所以必然会执行一个不同的计算。*/const int idx = get_global_id(0);/* 每个work-item都会检查自己的id是否在向量数组的区间内[0~num)。如果在,work-item就会执行相应的计算。*/if (idx < num)res[idx] = src_a[idx] + src_b[idx];
}
主机 准备工作 建立基本OpenCL运行环境
Plantform(平台):主机加上OpenCL框架管理下的若干设备构成了这个平台,通过这个平台,应用程序可以与设备共享资源并在设备上执行kernel。平台通过cl_plantform来展现,可以使用下面的代码来初始化平台:
// Returns the error code
// 获取平台ID
cl_int oclGetPlatformIDs(输入数量,cl_platform_id *platforms,平台数量指针) // Pointer to the platform object// 获取平台数量
clGetPlatformIDs(0,NULL,&plat_num);
// 获取平台id
cl_platform_id platforms[5]={0};
oclGetPlatformIDs(plat_num,platforms,NULL)
// 取第一个
cl_platform_id * plat_form = platforms[0];// 获取平台名
clGetPlatformInfo(,CL_DEVICE_NAME/CL_DEVICE_VERSION/CL_DEVICE_MAX_COMPUTE_UNITS/..,)
Device(设备):通过cl_device来表现,使用下面的代码:
// Returns the error code
// 获取设备ID
cl_int clGetDeviceIDs (cl_platform_id platform,cl_device_type device_type, // Bitfield identifying the type. For the GPU we use CL_DEVICE_TYPE_GPUcl_uint num_entries, // Number of devices, typically 1cl_device_id *devices, // Pointer to the device objectcl_uint *num_devices) // Puts here the number of devices matching the device_type// 获取平台设备数量
clGetDeviceIDs(*plat_form, CL_DEVICE_TYPE_GPU,0,NULL,&DeviceNmus);
// 获取设备
cl_device_id devices[5] = {0};
clGetDeviceIDs(*plat_form, CL_DEVICE_TYPE_GPU,DeviceNmus,devices,NULL);
// 取第一个
cl_device_id *device = devices[0];Context(上下文):定义了整个OpenCL化境,包括OpenCL kernel、设备、内存管理、命令队列等。上下文使用cl_context来表现。使用以下代码初始化:
// Returs the context
// 创建上下文 环境
cl_context clCreateContext (const cl_context_properties *properties, // 优先权 Bitwise with the properties (see specification)cl_uint num_devices, // 使用的设备数量 Number of devicesconst cl_device_id *devices, // 上面获取的设备id指针 Pointer to the devices objectvoid (*pfn_notify)(const char *errinfo, const void *private_info, size_t cb, void *user_data), //NULL指针(don't worry about this)void *user_data, // NULL 指针 (don't worry about this)cl_int *errcode_ret) // error code result
Command-Queue(指令队列):就像它的名字一样,他是一个存储需要在设备上执行的OpenCL指令的队列。“指令队列建立在一个上下文中的指定设备上。多个指令队列允许应用程序在不需要同步的情况下执行多条无关联的指令。”
// 创建指令队列
cl_command_queue clCreateCommandQueue (cl_context context, // 上面创建的 上下文环境cl_device_id device, // 设备idcl_command_queue_properties properties, // 优先权 0 Bitwise with the propertiescl_int *errcode_ret) // error code result
综合示例
cl_int error = 0; // int 类型的错误码,作为函数返回值,表示函数执行正确与否(执行状态)
cl_platform_id platform; // 平台id
cl_device_id device; // 设别id
cl_context context; // 上下文环境
cl_command_queue queue; // 指令队列
主要分为host memory和device memory。而device memory 一共有4种内存:
private memory:是每个work-item各自私有
local memory: 在work-group里的work-item共享该内存
global memory: 所有memory可访问
constant memory: 所有memory可访问,只读,host负责初始化
// Platform 获取平台id
error = oclGetPlatformID(&platform);
if (error != CL_SUCCESS) {cout << "Error getting platform id: " << errorMessage(error) << endl;exit(error);
}
// Device 获取设备ID
error = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
if (err != CL_SUCCESS) {cout << "Error getting device ids: " << errorMessage(error) << endl;exit(error);
}
// Context 创建上下文 环境
context = clCreateContext(0, 1, &device, NULL, NULL, &error);
if (error != CL_SUCCESS) {cout << "Error creating context: " << errorMessage(error) << endl;exit(error);
}
// Command-queue 创建指令队列
queue = clCreateCommandQueue(context, device, 0, &error);
if (error != CL_SUCCESS) {cout << "Error creating command queue: " << errorMessage(error) << endl;exit(error);
}变量内存分配
内存模型 Memory Model
不同平台的内存模型不一样,为了可移植性,OpenCL定义了一个抽象模型,程序的实现只需要关注抽象模型,而具体的向硬件的映射由驱动来完成。
主要分为host memory和device memory。而device memory 一共有4种内存:
private memory:是每个work-item各自私有
local memory: 在work-group里的work-item共享该内存
global memory: 所有memory可访问
constant memory: 所有memory可访问,只读,host负责初始化
Program Model
OpenCL支持数据并行,任务并行编程,同时支持两种模式的混合。
分散收集(scatter-gather):数据被分为子集,发送到不同的并行资源中,然后对结果进行组合,也就是数据并行;如两个向量相加,对于每个数据的+操作应该都可以并行完成。
分而治之(divide-and-conquer):问题被分为子问题,在并行资源中运行,也就是任务并行;比如多CPU系统,每个CPU执行不同的线程。还有一类流水线并行,也属于任务并行。流水线并行,数据从一个任务传送到另外一个任务中,同时前一个任务又处理新的数据,即同一时刻,每个任务都在同时运行。
并行编程就要考虑到数据的同步与共享问题。
in-order vs out-of-order:
创建命令队列时,如果没有为命令队列设置 CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE 属性,提交到命令队列的命令将按照 in-order 的方式执行。
OpenCL支持两种同步:
同一工作组内(work-group)工作项(work-item)的同步(实现方式barrier):
reduction的实现中,需要进行数据同步,所谓reduction就是使用多个数据生成一个数据,如tensorflow中的reduce_mean, reduce_sum等。在执行reduce之前,必须保证这些数据已经是有效的,执行过的,
命令队列中处于同一个上下文中的命令的同步(使用clWaitForEvents,clEnqueueMarker, clEnqueueBarrier 或者执行kernel时加入等待事件列表)。
有2种方式同步:
锁(Locks):在一个资源被访问的时候,禁止其他访问;
栅栏(Barriers):在一个运行点中进行等待,直到所有运行任务都完成;(典型的BSP编程模型就是这样)
数据共享:
(1)shared memory
当任务要访问同一个数据时,最简单的方法就是共享存储shared memory(很多不同层面与功能的系统都有用到这个方法),大部分多核系统都支持这一模型。shared memory可以用于任务间通信,可以用flag或者互斥锁等方法进行数据保护,它的优缺点:
优点:易于实现,编程人员不用管理数据搬移;
缺点:多个任务访问同一个存储器,控制起来就会比较复杂,降低了互联速度,扩展性也比较不好。
(2)message passing
数据同步的另外一种模型是消息传递模型,可以在同一器件中,或者多个数量的器件中进行并发任务通信,且只在需要同步时才启动。
优点:理论上可以在任意多的设备中运行,扩展性好;
缺点:程序员需要显示地控制通信,开发有一定的难度;发送和接受数据依赖于库方法,因此可移植性差。
// 主机 端 内存分配
// 主机的基本环境已经配置好了,为了可以执行我们的写的小kernel,我们需要分配3个向量的内存空间,然后至少初始化它们其中的两个。
const int size = 1234567
float* src_a_h = new float[size];
float* src_b_h = new float[size];
float* res_h = new float[size]; // 结果向量
// Initialize both vectors 初始化两个加数向量
for (int i = 0; i < size; i++)
{src_a_h = src_b_h = (float) i;
}// 设备上分配内存,我们需要使用cl_mem类型
// Returns the cl_mem object referencing the memory allocated on the device
// 调用接口
cl_mem clCreateBuffer ( cl_context context, // The context where the memory will be allocatedcl_mem_flags flags,size_t size, // The size in bytesvoid *host_ptr,cl_int *errcode_ret)
/*
flags是逐位的,选项如下:
CL_MEM_READ_WRITE // kernel 可读可写
CL_MEM_WRITE_ONLY // kernel 可写
CL_MEM_READ_ONLY // kernel 可读
CL_MEM_USE_HOST_PTR // 使用主机指针 创建 device端会对host_ptr位置内存进行缓存
CL_MEM_ALLOC_HOST_PTR// 分配 新开辟一段host端可以访问的内存
CL_MEM_COPY_HOST_PTR // 从 host_ptr处拷贝数据 在devices新开辟一段内存供device使用,并将host上的一段内存内容copy到新内存上host权限,默认为可读写:
CL_MEM_HOST_WRITE_ONLY:host 只写
CL_MEM_HOST_READ_ONLY: host只读
CL_MEM_HOST_NO_ACCESS: host没有访问权限size是buffer的大小
host_ptr只有在CL_MEM_USE_HOST_PTR, CL_MEM_COPY_HOST_PTR时才有效。一般对于kernel函数的输入参数,使用CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR可以将host memory拷贝到device memory,表示device只读,位置在device上并进行内存复制,host权限为可读写;
对于输出参数,使用CL_MEM_WRITE_ONLY表示device只写,位置在device上,host权限为可读可写。
如果进行host与device之间的内存传递,可以使用clEnqueueReadBuffer读取device上的内存到host上, clEnqueueWriteBuffer可以将host上内存写到device上。创建一个ImageBuffer:
cl_mem clCreatImage()
参数
context
flags, 同clCreateBuffer里的flags
image_format, 图像的属性,包含两个变量: image_channel_order, 指定通道数和形式,通常为RGBA;image_channel_data_type, 定义数据类型, CL_UNORM_INT8表示为unsigned规一化的INT8,CL_UNSIGNED_INT8
表示 为非规一化的unsigned int8
image_desc, 定义图像的维度大小,
host_ptr, 输入图像地址
errorce_ret, 返回状态写一个ImageBuffer:
cl_mem clEnqueueWriteImage()
参数:
command_queue
image, 目标图像
block_writing, 是否阻塞,如果TRUE,则阻塞
origin, 图像的偏移,通常为(0, 0, 0)
region, 图像的区域,(width, height, depth)
input_row_pitch,每行字节数,可能有对齐;如果设为0,则程序根据每个像素的字节数 乘以 width 计算
input_slice_pitch,3D图像的2D slice块,如果是1D或2D图像,这个值必须为0
ptr, host端输入源图像地址
num_events_in_wait_list, 需等待事件个数
evnet_wait_list, 需要等待的事件列表
event, 返回这个命令的事件,用于后续使用cl_mem clCreatImage2D()
*/// 使用const int mem_size = sizeof(float)*size; // 总子节数量
// 只读 变量 从主机的 指针 拷贝数据过来 进行创建
cl_mem src_a_d = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, mem_size, src_a_h, &error);
cl_mem src_b_d = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, mem_size, src_b_h, &error);、
// 可写变量,保存向量加法结果
cl_mem res_d = clCreateBuffer(context, CL_MEM_WRITE_ONLY, mem_size, NULL, &error);编译 程序和kernel
到现在为止,你可能会问自己一些问题,比如:我们怎么调用kernel?编译器怎么知道如何将代码放到设备上?我们怎么编译kernel?
下面是我们在对比OpenCL程序和OpenCL kernel时的一些容易混乱的概念:
Kernel:你应该已经知道了,像在上文中描述的一样,kernel本质上是一个我们可以从主机上调用的,运行在设备上的函数。你或许不知道kernel是在运行的时候编译的!更一般的讲,所有运行在设备上的代码,包括kernel和kernel调用的其他的函数,都是在运行的时候编译的。这涉及到下一个概念,Program。
Program:OpenCL Program由kernel函数、其他函数和声明组成。它通过cl_program表示。当创建一个program时,你必须指定它是由哪些文件组成的,然后编译它。
你需要用到下面的函数来建立一个Program:
// Returns the OpenCL program
cl_program clCreateProgramWithSource (cl_context context, // 上面创建的 上下文cl_uint count, // 需要编译的文件数量 number of filesconst char **strings, // 从文件读取的字符数组指针 带有\0结束符 array of strings, each one is a fileconst size_t *lengths, // 源码字符串长度 array specifying the file lengthscl_int *errcode_ret) // error code to be returned当我们创建了Program我们可以用下面的函数执行 编译 操作:
cl_int clBuildProgram (cl_program program, // 上面创建的程序cl_uint num_devices, // 使用的设备数量const cl_device_id *device_list, // 上面获取的设备id列表指针const char *options, // 编译选项 Compiler options, see the specifications for more detailsvoid (*pfn_notify)(cl_program, void *user_data), // NULL 空指针void *user_data); // NULL 空指针
查看编译log,必须使用下面的函数:
cl_int clGetProgramBuildInfo (cl_program program,cl_device_id device,cl_program_build_info param_name, // The parameter we want to knowsize_t param_value_size,void *param_value, // The answersize_t *param_value_size_ret);
最后,我们需要“提取”program的入口点。使用cl_kernel:
cl_kernel clCreateKernel (cl_program program, // clBuildProgram 编译好的程序 programconst char *kernel_name, // kernel 函数名 xxx.cl文件内cl_int *errcode_ret);
注意我们可以创建多个OpenCL program,每个program可以拥有多个kernel函数。
// 创建程序
// Uses NVIDIA helper functions to get the code string and it's size (in bytes)
size_t src_size = 0;
const char* path = shrFindFilePath("vector_add_gpu.cl", NULL);
const char* source = oclLoadProgSource(path, "", &src_size);
cl_program program = clCreateProgramWithSource(context, 1, &source, &src_size, &error);
assert(error == CL_SUCCESS);// 编译程序
error = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
assert(error == CL_SUCCESS);// 查看编译日志
char* build_log;
size_t log_size;
// First call to know the proper size
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size);
build_log = new char[log_size+1];
// Second call to get the log
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, build_log, NULL);
build_log[log_size] = '\0';
cout << build_log << endl;
delete[] build_log;// 提取编译好的kernel vector_add_gpu 是 vector_add_gpu.cl 文件中的一个函数名
cl_kernel vector_add_kernel = clCreateKernel(program, "vector_add_gpu", &error);
assert(error == CL_SUCCESS);运行 kernel
一旦我们的kernel建立好,我们就可以运行它。
首先,我们必须设置kernel的参数
cl_int clSetKernelArg (cl_kernel kernel, // clCreateKernel 创建的 kernelcl_uint arg_index, // 参数idsize_t arg_size, // sizeof(参数) 参数的大小const void *arg_value);// 参数地址
每个参数都需要调用一次这个函数。
当所有参数设置完毕,我们就可以调用这个kernel:
cl_int clEnqueueNDRangeKernel (cl_command_queue command_queue, cl_kernel kernel, cl_uint work_dim, // Choose if we are using 1D, 2D or 3D work-items and work-groupsconst size_t *global_work_offset,const size_t *global_work_size, // The total number of work-items (must have work_dim dimensions)const size_t *local_work_size, // The number of work-items per work-group (must have work_dim dimensions)cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event);
/*
参数:
command_queue,
kernel,
work_dim,使用多少维的NDRange,可以设为1, 2, 3, ..., CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS。
global_work_offset(GWO), 每个维度的偏移,如果不设置默认为0
global_work_size(GWS),每个维度的索引长度,GWS(1) * GWS(2) * ... * GWS(N) 应该大于等于需要处理的数据量
local_work_size(LWS), 每个维度work-group的大小,如果不设置,系统会自己选择一个合适的大小
num_events_in_wait_list: 执行kernel前需要等待的event个数
event_wait_list: 需要等待的event列表
event: 当前这个命令会返回一个event,以供后面的命令进行同步
返回:
函数返回执行状态。如果成功, 返回CL_SUCCESS
*/运行实例:
// 设置kernel的参数 Enqueuing parameters
// Note that we inform the size of the cl_mem object, not the size of the memory pointed by it
error = clSetKernelArg(vector_add_k, 0, sizeof(cl_mem), &src_a_d);
error |= clSetKernelArg(vector_add_k, 1, sizeof(cl_mem), &src_b_d);
error |= clSetKernelArg(vector_add_k, 2, sizeof(cl_mem), &res_d);
error |= clSetKernelArg(vector_add_k, 3, sizeof(size_t), &size);
assert(error == CL_SUCCESS);// 启动kernel Launching kernel
const size_t local_ws = 512; // Number of work-items per work-group
// shrRoundUp returns the smallest multiple of local_ws bigger than size
const size_t global_ws = shrRoundUp(local_ws, size); // Total number of work-items
error = clEnqueueNDRangeKernel(queue, vector_add_k, 1, NULL, &global_ws, &local_ws, 0, NULL, NULL);
assert(error == CL_SUCCESS);// clWaitForEvents()一个主机要使得内核运行在设备上,必须要有一个上下文来与设备进行交互。 一个上下文就是一个抽象的容器,管理在设备上的内存对象,跟踪在设备上 创建的程序和内核。
主机程序使用命令队列向设备提交命令,一个设备有一个命令队列,且与上下文 相关。命令队列对在设备上执行的命令进行调度。这些命令在主机程序和设备上 异步执行。执行时,命令间的关系有两种模式:(1)顺序执行,(2)乱序执行。
内核的执行和提交给一个队列的内存命令会生成事件对象,可以用来控制命令的执行、协调宿主机和设备的运行。
有3种命令类型:
• Kernel-enqueue commands: Enqueue a kernel for execution on a device.(执行kernel函数)
• Memory commands: Transfer data between the host and device memory, between memory objects, or map and unmap memory objects from the host address space.(内存传输)
• Synchronization commands: Explicit synchronization points that define order constraints between commands.(同步点)
命令执行经历6个状态:
Queued: 将command放到CommandQueue
Submitted: 将command从CommandQueue提交到Device
Ready: 当所有运行条件满足,放到Device的WorkPool里
Running: 命令开始执行
Ended: 命令执行结束
Complete: command以及其子command都结束执行,并设置相关的事件状态为CL_COMPLETE
Mapping work-items onto an NDRange:
与CUDA里的grid, block, thread类似,OpenCL也有自己的work组织方式NDRange。NDRange是一个N维的索引空间(N为1, 2, 3…),一个NDRange由三个长度为N的数组定义,与clEnqueueNDRangeKernel几个参数对应:
global_work_size(GWS),每个维度的索引长度,GWS(1) * GWS(2) * ... * GWS(N) 应该大于等于需要处理的数据量
global_work_offset(GWO), 每个维度的偏移,如果不设置默认为0
local_work_size(LWS), 每个维度work-group的大小,如果不设置,系统会自己选择较好的结果
如下图所示,整个索引空间的大小为
./cudavectoraddSUCCESScopyinputtime:15438.000000CUDAtime:23.000000copyoutputtime:17053.000000CPUtime:16259.000000resultisright!guruge@dl: /opencl/test
,每个work-group大小为
./cudavectoraddSUCCESScopyinputtime:59825.000000CUDAtime:36.000000copyoutputtime:67750.000000CPUtime:64550.000000resultisright!guruge@dl: /opencl/test
,全局偏移为。
对于一个work-item,有两种方式可以索引:
直接使用global id 或者使用work-group进行相关计算,设当前group索引为,group里的local id分别为(s_x, s_y),那么便有
读取结果
读取结果非常简单。与之前讲到的写入内存(设备内存)的操作相似,现在我们需要存入队列一个读取缓冲区的操作:
cl_int clEnqueueReadBuffer (cl_command_queue command_queue, cl_mem buffer, // from which buffercl_bool blocking_read, // whether is a blocking or non-blocking readsize_t offset, // offset from the beginningsize_t cb, // size to be read (in bytes)void *ptr, // pointer to the host memorycl_uint num_events_in_wait_list,const cl_event *event_wait_list, cl_event *event);cl_int clEnqueueWriteBuffer()
参数
command_queue,
buffer, 将内存写到的位置
blocking_write, 是否阻塞
offset, 从buffer的多少偏移处开始写
size, 写入buffer大小
ptr, host端buffer地址
num_events_in_wait_list, 等待事件个数
event_wait_list, 等待事件列表
event, 返回的事件创建一个ImageBuffer:
cl_mem clCreatImage()
参数
context
flags, 同clCreateBuffer里的flags
image_format, 图像的属性,包含两个变量: image_channel_order, 指定通道数和形式,通常为RGBA;image_channel_data_type, 定义数据类型, CL_UNORM_INT8表示为unsigned规一化的INT8,CL_UNSIGNED_INT8
表示 为非规一化的unsigned int8
image_desc, 定义图像的维度大小,
host_ptr, 输入图像地址
errorce_ret, 返回状态写一个ImageBuffer:
cl_mem clEnqueueWriteImage()
参数:
command_queue
image, 目标图像
block_writing, 是否阻塞,如果TRUE,则阻塞
origin, 图像的偏移,通常为(0, 0, 0)
region, 图像的区域,(width, height, depth)
input_row_pitch,每行字节数,可能有对齐;如果设为0,则程序根据每个像素的字节数 乘以 width 计算
input_slice_pitch,3D图像的2D slice块,如果是1D或2D图像,这个值必须为0
ptr, host端输入源图像地址
num_events_in_wait_list, 需等待事件个数
evnet_wait_list, 需要等待的事件列表
event, 返回这个命令的事件,用于后续使用映射 buffer
void clEnqueueMapBuffer()
参数:
command_queue
buffer, cl_mem映射的源地址
blocking_map, 是否阻塞
map_flags, CL_MAP_READ,映射的地址为只读;CL_MAP_WRITE,向映射的地址写东西;CL_MAP_WRITE_INVALIDATE_REGION, 向映射的地址为写东西,host不会使用这段地址的内容,这时返回的地址处的内容不保证是最新的
offset, cl_mem的偏移
size, 映射的内存大小
num_events_in_wait_list, 等待事件个数
event_wait_list, 等待事件列表
event, 返回事件
errorcode_ret, 返回状态
返回值是CPU可访问的指针。注意:
当flag为CL_MAP_WRITE时,如果不使用unmap进行解映射,device端无法保证可以获取到最新写的值。
如果不用unmap,那么device端无法释放这部分内存
所以写完内容后,要立马解映射。buffer
clEnqueueCopyBuffer() // 从一个cl buffer拷贝到另一个cl buffer事件:cl_int clWaitForEvents(cl_uint num_events, const cl_event *event_list)
等待事件执行完成才返回,否则会阻塞cl_int clEnqueueWaitForEvents(cl_command_queue command_queue, cl_uint num_events, const cl_event *event_list)
和 clWaitForEvents 不同的是该命令执行后会立即返回,线程可以在不阻塞的情况下接着执行其它任务。而 clWaitForEvents 会进入阻塞状态,直到事件列表 event_list 中对应的事件处于 CL_COMPLETE 状态。cl_int clFlush(cl_command_queue command_queue)
只保证command_queue中的command被commit到相应的device上,不保证当clFlush返回时这些command已经执行完。cl_int clFinish(cl_command_queue command_queue)
clFinish直到之前的队列命令都执行完才返回。clFinish is also a synchronization point.cl_int clEnqueueBarrier(cl_command_queue command_queue)
屏障命令保证在后面的命令执行之前,它前面提交到命令队列的命令已经执行完成。
和 clFinish 不同的是该命令会异步执行,在 clEnqueueBarrier 返回后,线程可以执行其它任务,例如分配内存、创建内核等。而 clFinish 会阻塞当前线程,直到命令队列为空(所有的内核执行/数据对象操作已完成)。cl_int clEnqueueMarker(cl_command_queue command_queue, cl_event *event)
将标记命令提交到命令队列 command_queue 中。当标记命令执行后,在它之前提交到命令队列的命令也执行完成。该函数返回一个事件对象 event,在它后面提交到命令队列的命令可以等待该事件。例如,随后的命令可以等待该事件以确保标记之前的命令已经执行完成。如果函数成功执行返回 CL_SUCCESS。使用方法如下:
// Reading back
float* check = new float[size];
clEnqueueReadBuffer(queue, res_d, CL_TRUE, 0, mem_size, check, 0, NULL, NULL);
清理
作为一名牛X的程序员我们肯定要考虑如何清理内存!
你需要知道最基本东西:使用clCreate申请的(缓冲区、kernel、队列)必须使用clRelease释放。
代码如下:
// cpu 上内存清理
delete[] src_a_h;
delete[] src_b_h;
delete[] res_h;
delete[] check;
// gpu上内存清理
clReleaseKernel(vector_add_k); // 有先后顺序,后创建的先释放!!!!
clReleaseCommandQueue(queue);
clReleaseContext(context);
clReleaseMemObject(src_a_d);
clReleaseMemObject(src_b_d);
clReleaseMemObject(res_d);
相关文章:

编写OpenCL程序的基本步骤
opencl pyopencl OpenCL-Headers OpenCL(全称为Open Computing Langugae,开放运算语言)是第一个面向异构系统(此系统中可由CPU,GPU或其它类型的处理器架构组成)的并行编程的开放式标准。 它是跨平台的。 OpenCL由两部分组成,一是用于编写…...

计算机网络之TCP/IP协议第一篇:网络基础知识
文章目录 写给自己的话 一:前言 1:手握金刚钻的TCP/IP 2:计算机中的协议 3:分组...
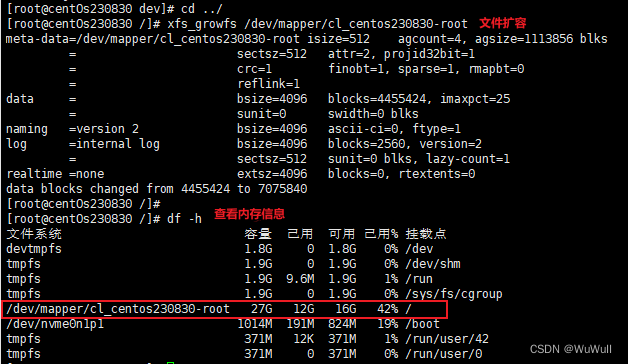
虚拟机扩容
系统环境centos8,分两步,第一步先在vmware扩容,第二部在虚拟机内部扩容 1.vmware分配磁盘空间 2.虚拟机内部扩容 查看当前磁盘信息,这个是扩容之前的,扩容完成才会显示新的 df -h查看系统分区信息 fdisk -l查看目录…...
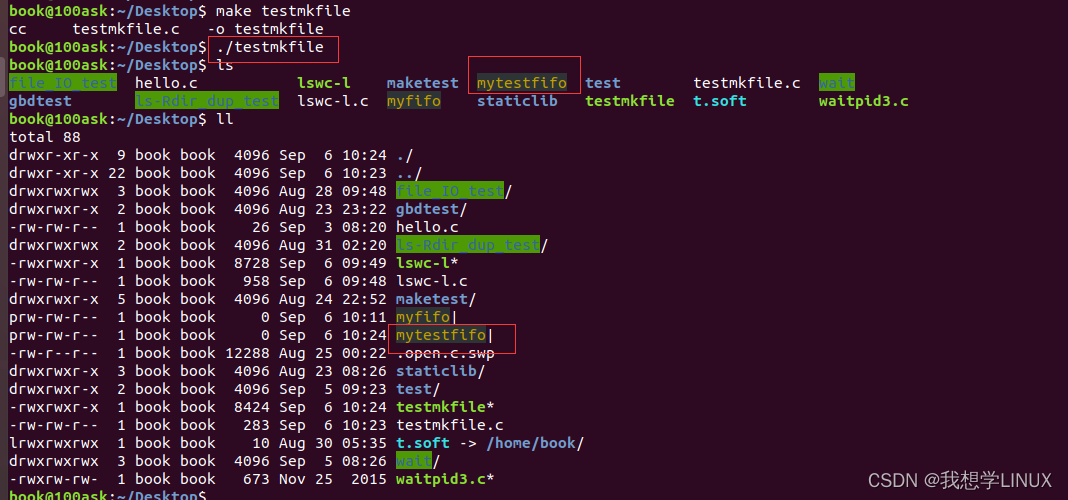
Linux下的系统编程——进程间的通信(九)
一、进程间通信常用方式 IPC方式: Linux环境下,进程地址空间相互独立,每个进程各自有不同的用户地址空间。任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能相互访问,要交换数据必须通过内核&am…...

Qt QtableWidget、QtableView表格删除选中行、删除单行、删除多行
文章目录 Qt QtableWidget表格删除选中行只能选择一行,点击按钮后,删除一行可以选择中多行,点击按钮后,删除多行选中某一列中的不同行,点击按钮后,删除多行 QTableWidgetSelectionRange介绍QTableWidget的选…...
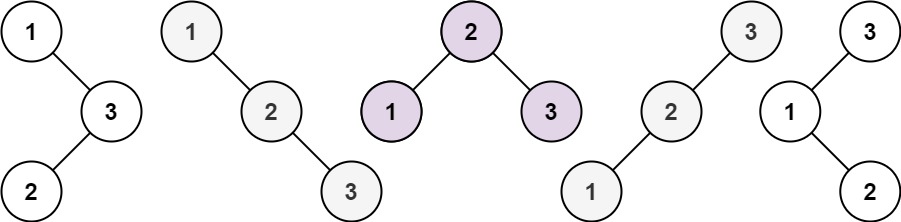
【代码随想录day24】不同的二叉搜索树
题目 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。 示例 1: 输入:n 3 输出:5示例 2: 输入:n 1 输出…...
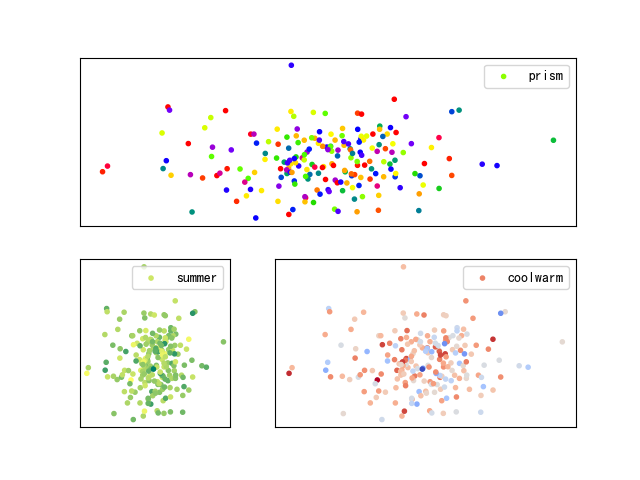
数学建模--Subplot绘图的Python实现
目录 1.Subplot函数简介 2.Subplot绘图范例1:绘制规则子图 3.Subplot绘图范例2:绘制不规则子图 4.Subplot绘图范例3:gridspec辅助实战1 5.Subplot绘图范例4:gridspec辅助实战2 1.Subplot函数简介 """ 最近在数学建模种需要绘制多张子图,发现对于subplot函…...
JMeter(三十九):selenium怪异的UI自动化测试组合
文章目录 一、背景二、JMeter+selenium使用过程三、总结一、背景 题主多年前在某社区看到有人使用jmeter+selenium做UI自动化测试的时候,感觉很是诧异、怪异,为啥?众所周知在python/java+selenium+testng/pytest这样的组合框架下,为啥要选择jmeter这个东西[本身定位是接口测…...

c++ 移动构造方法为什么要加noexcept
背景: 最近看了候捷老师的c的教程, 他说移动构造方法要加noexcept, 在vector扩容的时候, 如果有移动构造方法没有加noexcept,是不会调用的. 个人感觉有些神奇, 这就去查下一探究竟. 过程: 测试代码如下: #include <iostream> #include <vector> struct A {A(){s…...
鸿鹄工程项目管理系统 Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统
工程项目管理软件(工程项目管理系统)对建设工程项目管理组织建设、项目策划决策、规划设计、施工建设到竣工交付、总结评估、运维运营,全过程、全方位的对项目进行综合管理 工程项目各模块及其功能点清单 一、系统管理 1、数据字典&am…...
手把手教你搭建园林园艺小程序商城
现如今,随着互联网的快速发展,小程序成为了企业和个人展示产品和服务的新方式。在园林园艺行业,构建一个园林园艺小程序能够更好地推广和销售自己的产品和服务。那么,如何构建一个园林园艺小程序呢?下面我们来详细介绍…...
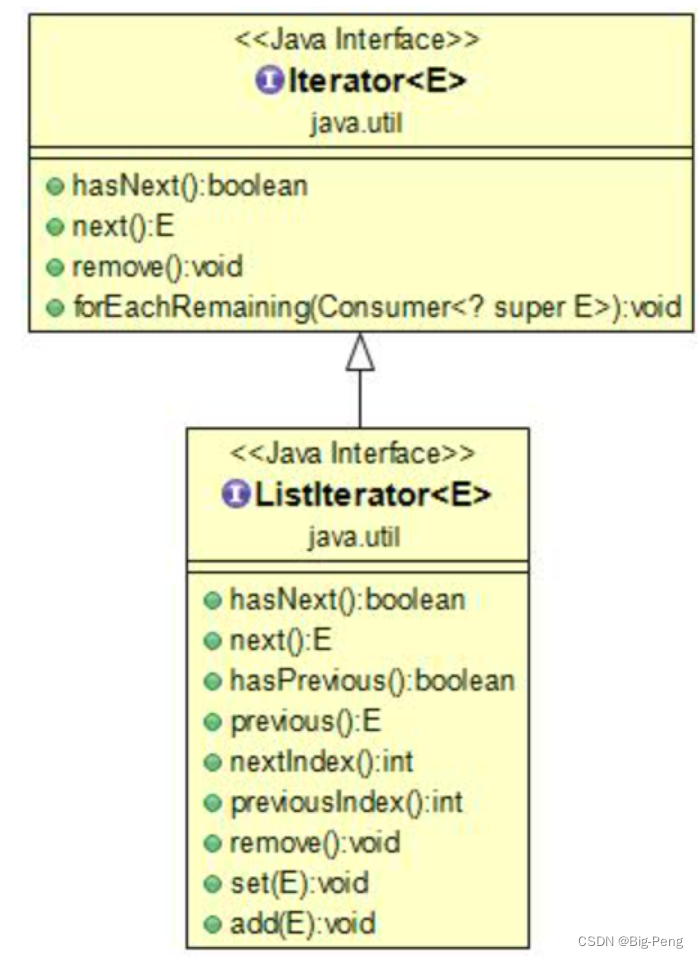
Java Iterator(迭代器)
Java迭代器(Iterator)是 Java 集合框架中的一种机制,是一种用于遍历集合(如列表、集合和映射等)的接口。 它提供了一种统一的方式来访问集合中的元素,而不需要了解底层集合的具体实现细节。 Iterator 是 …...

Logstash同步MySQL数据到ElasticSearch
当MySQL数据到一定的数量级,而且索引不能实现时,查询就会变得非常缓慢,所以使用ElasticSearch来查询数据。本篇博客介绍使用Logstash同步MySQL数据到ElasticSearch,再进行查询。 测试环境 Windows系统MySQL 5.7Logstash 7.0.1El…...

【C++】运算符重载的示例实现和应用
C运算符重载的格式: operator 运算符 比如要重载 ! 运算符 : operator ! 下面是一个例子: class DemoText{DemoText(string str, int num){m_text str; m_number num;}string m_text;int m_number; }这里来定义两个对象:…...

Kubernetes禁止调度
在Kubernetes中,您可以通过几种方式来禁止某个Pod调度到节点上。以下是一些方法: Node Selector:您可以使用Node Selector来限制Pod只能调度到带有特定标签的节点上。如果您希望完全禁止Pod调度到某些节点上,可以确保这些节点不拥…...

CocosCreator3.8研究笔记(七)CocosCreator 节点和组件的介绍
相信很多新手朋友,肯定会问,CocosCreator 中什么是节点?什么是组件? 一、什么是组件(Component)? Cocos Creator 3.8 的工作流程是以组件式开发为核心,即以组合而非继承的方式进行游…...

Ceph入门到精通-C++入门知识点
C中的双冒号(::)是作用域分解运算符(scope resolution operator)。 它主要有以下两种用法: 用于区分同名的不同成员,例如在不同类中声明了同名的成员函数或成员变量,可以使用A::B的方式来特指A类的B成员。当全局变量…...

Ansible之playbook详解和应用实例
目录 一、playbook简介 1.什么是playbook 2.playbook组成 二、应用实例 1.使用playbook安装启用httpd服务 2.使用playbook安装启用nginx服务 三、ansible-playbook其他用法 1.检查yaml文件的语法是否正确 2.检查tasks任务 3.检查指定的主机 4.指定从某个task开始运行…...

经验萃取方法
【经验萃取】 经验萃取不是简单的总结提炼归纳! 经验萃取需经过还原、复盘分析、萃取重构 一.经验萃取前三个准备 1.定主题: 萃取主题选择(阐述原因、确定级别、差距/问题是源头)->多维评分:普遍性、重要性、迫切…...

手写apply方法
<script>/** 手写apply方法 * */Function.prototype.myApply function (context, args) {console.log(this, sss)//fnconst key Symbol()context[key] thiscontext[key](...args)delete context[key]return context[key]}const obj {name: zs,age: 18}function fn …...

Git 核心操作:rebase 与 merge 的区别,以及分支管理最佳实践
Git 核心操作:rebase 与 merge 的区别,以及分支管理最佳实践 在日常开发中,Git 是不可或缺的版本控制工具。而 git merge 和 git rebase 是整合分支最常用的两个命令,很多人对它们的概念模糊,不知道何时用哪个。同时&a…...

listmonk数据库连接池监控指标解释:关键指标含义
listmonk数据库连接池监控指标解释:关键指标含义 你是否经常遇到邮件发送延迟、后台任务卡顿?这些问题可能与数据库连接池配置不当有关。本文将详细解释listmonk中数据库连接池的关键监控指标,帮助你诊断性能瓶颈,优化系统稳定性…...

nvm-windows深度实战:Windows平台Node.js版本管理的系统化解决方案
nvm-windows深度实战:Windows平台Node.js版本管理的系统化解决方案 【免费下载链接】nvm-windows A node.js version management utility for Windows. Ironically written in Go. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-windows nvm-windows是一…...

Minimax算法在技能学习中的应用:构建抗风险技术成长路径
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫justl9169/minimax-skills。光看名字,你可能会联想到“最小化-最大化”算法,也就是博弈论里那个经典的Minimax。没错,这个项目的核心灵感确实来源于此,但…...
的Physics、Math与Parameter)
Sentaurus TCAD仿真避坑指南:手把手教你配置非局域隧穿模型(NLM)的Physics、Math与Parameter
Sentaurus TCAD仿真实战:非局域隧穿模型配置的七个关键陷阱与解决方案 在微电子器件仿真领域,非局域隧穿模型(Non-Local Tunneling Model, NLM)的准确配置常常成为新手工程师的第一道技术门槛。许多研究生在首次尝试铁电隧穿结(FTJ)仿真时,往…...

Threadline MCP:基于消息协议的线程管理与任务编排框架解析
1. 项目概述:从“Threadline MCP”看现代应用架构的线程管理革新最近在GitHub上看到一个挺有意思的项目,叫“vidursharma202-del/threadline-mcp”。光看这个名字,可能有点摸不着头脑,但拆解一下,“threadline”直译是…...

初创团队如何借助 Taotoken 实现低成本且灵活的大模型能力集成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助 Taotoken 实现低成本且灵活的大模型能力集成 对于资源有限的初创技术团队而言,在开发新产品时集成 A…...

ZYNQ PS-PL协同实战:如何设计一个带触发与延时的多通道数据采集卡?
ZYNQ PS-PL协同实战:工业级多通道数据采集卡架构设计精要 在工业自动化与测试测量领域,数据采集系统的性能直接决定了整个系统的可靠性与精度。Xilinx ZYNQ系列SoC凭借其独特的ARM处理器(PS)与可编程逻辑(PL)协同架构,成为构建高性能数据采集…...

点支承幕墙玻璃破裂故障分析
点支承幕墙玻璃破裂故障分析 【作 者】:龙文志 【摘 要】:本文从点支承幕墙玻璃破裂故瘴出发,系统阐述了点支承幕墙玻璃破裂故障多于其它玻璃幕墙的原因,提出了点支承玻璃幕墙设计时,除对玻璃面板的大面应力进行计算分析外,同时也应该对玻璃孔边应力进行设计分析;为了…...

Visual C++运行库终极指南:如何3分钟解决Windows软件启动失败问题
Visual C运行库终极指南:如何3分钟解决Windows软件启动失败问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的场景…...