SmoothNLP新词发现算法的改进实现
SmoothNLP新词发现算法的改进实现
背景介绍
新词发现也叫未登录词提取,依据 《统计自然语言处理》(宗成庆),中文分词有98%的错误来自"未登录词"。即便早就火遍大江南北的Bert也不能解决"未登录词"的Encoding问题,便索性使用‘字’作为最小单元。
未登录词除了来自各行各业的专有名词、缩略语外,还有与时俱进的流行词、新生词,所以通过有监督大量标注的方式性价比过低。
一个行业的词库构建往往都是从0开始的,迁移使用也就是治标不治本。而且没有几个专业人员敢保证坐在那里就能滔滔不绝的把行业内所有词汇撰写下来,所以新词发现也是构建词库的重要辅助工具。
另外最近遇到的热词提取的需求越来越多,热词首先要定位好词,对于新出现的词,即便大量出现也会由于分词器不能正确识别的缘故难以上榜。
和其他AI算法一样,新词发现也有基于BiLSTM+CRF进行序列化标注的有监督算法,也有不需要标注的无监督算法。我个人看来,与其倾注时间在有监督的预训练标注,不如多花花心思在无监督结果确认上。无监督的新词发现,不管是轻量易用的Jieba、丰富工业API的HanLP、还是高校自研的LTP、Thulac、Pkuseg都有实现无监督的新词发现(有的叫关键短语提取)。这些新词发现基本都是基于TFIDF、自由度、凝聚度(部分引入HMM),接下来我就介绍一下业界常用到的NLP工具SmoothNLP中的新词发现——基于自由度和凝聚度的新词发现。
基于自由度和凝聚度的新词发现
一些简单的名词
- 词元(gram): 定义语料中文字存在最小单位,可以是字可以是分词结果的词。由N个词元组成的新词元叫N词元(NGram),比如规定每个字都是一个词元,则‘华宇信息’就是一个4词元。以下对词元均简称G。
- 自由度 : 何为自由度,指的就是如果一个或几个词元组合可以成新词nG,它应当出现在丰富的语境中,换句话说就是这个新词比较自由,没有什么特定的和其他词元Gi一起出现的规则,因为如果有,就说明有可能nG应该和Gi组成新词(n+1)G
- 凝聚度 : 何为凝聚度,就是指组成新词nG的各个词元(G1,…,Gi)应该展现出一定的关联性,或者规律性。
SmoothNLP的定义
- 以每个字作为词元,这样的好处是避免了分词器的干扰,比如语句‘随着芈月传播出 ’分词结果是['随着 ','芈月 ','传播 ','出 '],如果基于这个生成新词,那么永远不可出现‘芈月传 ’,所以用字作为词元
- 在SmoothNLP中将自由度用左右临近信息熵(Left and Right Entropy,LRE)来表示。
- 在SmoothNLP中将凝聚度用平均互信息(Average Mutual Information,AMI)来表示。
左右临近信息熵
信息熵
信息熵是对信息量多少的度量,信息熵越高,表示信息量越丰富、不确定性越大。相反越小则纯度越高。对于集合D有N个样本di,定义每个样本概率为Pdi,则集合D的信息熵为:
EntropyD=−∑(di∈D)P(di)log2P(di)\mathbf{Entropy}_{D}=-\sum_{({d}_{i}\in{D})}{P({d}_{i})\log_2{P({d}_{i})}} EntropyD=−(di∈D)∑P(di)log2P(di)
临近词元信息熵
SmoothNLP将候选词nG的临近字(SmoothNLP定义的词元是字)两两组合构成集合,并定义每个样本概率为nG与临近字Gi的条件概率,计算该集合的信息熵。由左临近字构成的集合信息熵就是左临近信息熵,由右临近字构成的集合信息熵就是右临近信息熵,具体公式为
LEnG=−∑(Gi∈Gleft−neighbor)P(Gi∣nG)log2P(Gi∣nG)\mathbf{LE}_{nG} = -\sum_{({G}_{i}\in{G}_{left-neighbor})}{P({G}_{i}|{nG})\log_2{P({G}_{i}|nG)}} LEnG=−(Gi∈Gleft−neighbor)∑P(Gi∣nG)log2P(Gi∣nG)
LEnG=−∑(Gj∈Gright−neighbor)P(Gj∣nG)log2P(Gj∣nG)\mathbf{LE}_{nG} = -\sum_{({G}_{j}\in{G}_{right-neighbor})}{P({G}_{j}|{nG})\log_2{P({G}_{j}|nG)}} LEnG=−(Gj∈Gright−neighbor)∑P(Gj∣nG)log2P(Gj∣nG)
综合左右临近信息熵
左右单侧的信息熵高并不能说明问题,要将左右信息熵综合考虑,这里SmoothNLP的做法是对左右临近信息熵取对数平均值:
LRE=logLE∗eRE+RE∗eLE∣LE−RE∣\mathbf{LRE} = \log{\frac{{LE}*{e}^{RE}+{RE}*{e}^{LE}}{|LE-RE|}} LRE=log∣LE−RE∣LE∗eRE+RE∗eLE
Tire
为了实现上述逻辑,方便查询N词元的左右临近字,选取字典树Tire存储。
举个栗子
以市场监督管理局数据2W条留言标题为测试样例为例。

很明显‘混凝’只有跟‘土’,‘凝土’前面只有‘混’,而‘混凝土’前后的就多了去了,所以‘混凝土’大概率是个词。
平均互信息
互信息
互信息是衡量随机变量之间相互依赖程度的度量,假如看见一个背电脑包戴帽子的小伙子,那么‘他职业是程序猿 ’是个随机事件,‘他帽子下是秃头 ’同样是个随机事件,那么这两个随机事件互相依赖的程度是‘已知他职业是程序猿的情况下,他帽子下是秃头的可能性 ’与‘已知帽子下是秃头的情况下,他职业是程序猿的可能性 ’之差,具体公式是:
MI=∑y∈Y∑x∈XP(x,y)logP(x,y)P(x)P(y)\mathbf{MI} = \sum_{{y}\in{Y}}{\sum_{{x}\in{X}}{P(x,y)\log\frac{P(x,y)}{P(x)P(y)}}} MI=y∈Y∑x∈X∑P(x,y)logP(x)P(y)P(x,y)
N词元互信息
SmoothNLP并没有严格按照互信息公式,而是使用点间互信息(point-wise mutual information,PMI),假设新词nG由N个词元Gi构成,则该新词PMI为
PMI=log2P(G1,...,Gi)∏Gi∈nGP(Gi)\mathbf{PMI} = \log_{2}{\frac{P({G}_1,...,{G}_i)}{\prod_{{G}_i\in{nG}}{P({G}_i)}}} PMI=log2∏Gi∈nGP(Gi)P(G1,...,Gi)
N词元平均互信息
由于点间互信息的值会受到候选词长度的影响——候选词越长,互信息取值偏大,所以使用平均互信息:
AMI=1nPMI\mathbf{AMI} = \frac{1}{n}\mathbf{PMI} AMI=n1PMI
在SmoothNLP的实现上做优化
SmoothNLP调皮了
不知什么原因,SmoothNLP很调皮并没有按照上述公式一板一眼的实现,而是加入一些论文中没有提到的‘个人想法’。
# 语料分批读取chunk_size
for corpus_batch in corpus:# 删除非中文、非英文、非数字字符del_unused_char()# 遍历处理后语料for line in corpus_batch :# 遍历1词元以及min到max+1词元for n in [1]+[min,max+1]:# 构建N词元词频字典n_gram_freq_dict[n] = build_n_gram_freq_dict()# 删除频率低于min_freq的N词元del_low_freq_n_gram()for n in [min,max]:# 利用N+1词元词频字典构建N词元左右Tireleft_tire,right_tire = build_tire_from_up(n_gram_freq_dict[n+1])# 计算N词元左右信息熵gram_n_lre_dict[n] = cal_lre(left_tire,right_tire)# 计算1词元频率总和
gram_1_total = cal_gram_1_total(n_gram_freq_dict[1])for n in [min,max]:# 计算N词元总和gram_n_total = cal_gram_n_total(n_gram_freq_dict[n])# 计算N词元平均互信息gram_n_pmi_dict[n] = cal_pmi(n_gram_freq_dict[1],gram_1_total,n_gram_freq_dict[n],gram_n_total)# 计算N词元评分gram_n_score_dict[n] = cal_score(gram_n_pmi_dict[n],gram_n_lre_dict[n])# 统计所有词元首词元,统计所有词元尾词元
start_gram_freq,end_gram_freq = build_start_end_gram_freq(gram_n_score_dict)# 移除包含频率高于阈值 首尾词元的词元
result = drop_some_gram(gram_n_score_dict,start_gram_freq,end_gram_freq)# 排序
result.sort()
单从算法逻辑上可以发现以下几个问题:
- 语料是分批读取的,而且删除频率低于min_freq的N词元是在一个批内执行的,这样会误删一些‘单批内词频低,但总体词频高于min_freq’的候选词
- 他是根据N+1词元频率构建的N词元左右Tire,这样考虑是因为他是以字为词元的,那么N+1词元就可以拆分成‘首字词元+N词元’或‘N词元+尾字词元’。但其实大可不必浪费时间额外统计一次max+1词元频率。
- 另外好多统计操作其实是可以在一个预语料循环里完成的。
- 还有好多中间变量是应该回收的
总体优化
针对以上问题我做了以下调整【Smoothnlp为左图,我实现的右图】

删除频率低于min_freq的N词元我拿到了计算评分时做。
可以发现在我的算法没有提及[min,max]的遍历,是因为我写的只是一个n词元,没错我也调皮了,不过我调皮一下使算法多线程成为可能。
这里我们再看一下SmoothNLP在多线程方面的尝试:

看来这个todo要我们来写了,其实他不写也是有原因的,对比看一下简化的逻辑图便知,先看SmoothNLP。

每元计算都是在词频上关联的,多线程就要一个等一个
再看看我们的

移除不必要的max+1词元计算,我们在第一次遍历语料时就顺带创建左右临近树的元素列表了。省了一次计算并使得每元计算解耦,这样就使得多线程成为可能。
细节优化
再具体公式实现上,Smoothnlp也并没有严格实现以及一些牺牲一部分精度:
- 公式中常量值或对数底数采取了取近似值
- 定义高频首末词元的阈值很小,比例在小数据集上效果不会太好
- 保留数字和英文,这方面的新词还是比较少的,但出现的自由度越普遍很高。
- 由于分批读取的缘故在频率字典融合时使用Update反而会覆盖原本有的,而不是与原本的相加。
既然我们能多线程了,就不近似了也不牺牲精度了,也解决巴拉巴拉的问题。
另外这里详细说一下我们是怎么实现‘第一次遍历语料时就顺带创建左右临近树的元素列表’的。
Smoothnlp遍历语料生成词元其实就是返回N长的字符串子串,而我们定义了一种数据结构,一种元组。
Tuple[Tuple[],Tuple[],Tuple[]]
这元组里有三个元素:
- 第一个是左临近词元元组,只有一个元素,左临近词元
- 第二个是N词元元组,是组成N词元的每个词元
- 第一个是右临近词元元组,只有一个元素,右临近词元
之后使用Python的Counter就轻松实现Tire树的数据字典的构建。
这种实现又方便了基于分词结果的新词发现。
另外SmoothNLP是直接将‘无效字符’替换成掉,这样会带来一个问题,比如例句。
“根据《劳动法》规定能保护…”
我们希望看到的肯定是【‘根据’ ‘劳动法’ ‘规定’ ‘能’ ‘保护’】,但是由于直接替换掉,变成了 “根据劳动法规定能保护…”,那么在计算2次元结果就变成了【‘根据’ ‘劳动’ ‘法规’ ‘定能’ ‘保护’】,这是对提出‘劳动法’这个词的干扰。
优化效果
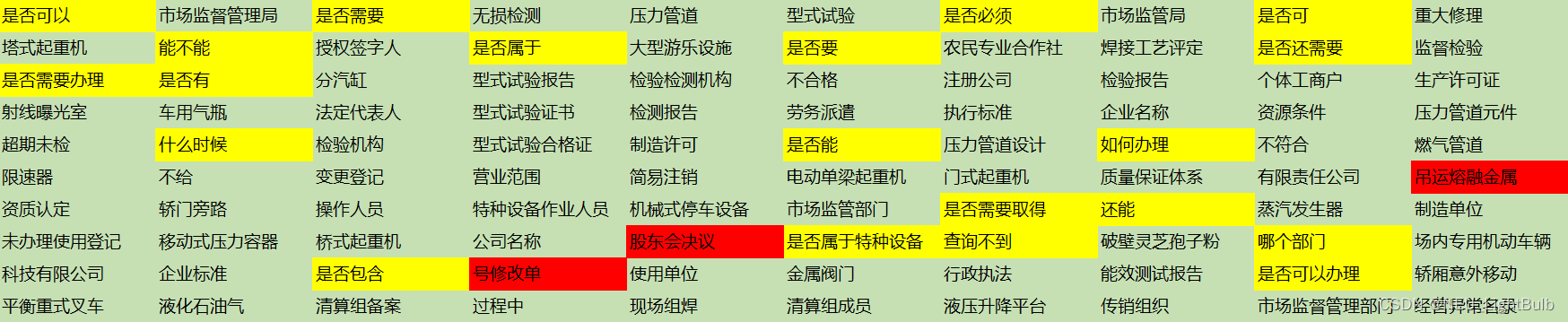
看下效果,都是基于【某政府机关网站2W条留言标题数据】的新词发现,最小2词元,最多5词元,最小词元频率5 。smoothnlp效果如下,绿色是正常有效词,黄色是正常无效词,红色是不正常的词:

我的优化效果如下:

基于分词结果的新词发现
虽然Smoothnlp依靠‘芈月传’的例子摒弃了,基于分词结果的新词发现,但是不可否认的是,基于字的新词发现往往都是分词词典里已经有了的短词,换句话说基于分词结果的新词发现并不是没有意义,相反他的效率也许更高。
所以我实现了基于字和基于分词两种新词发现,后者是使用jieba默认词典分词的。
基于【某政府机关网站2W条留言标题数据】,最小2词元,最多3词元,最小词元频率5效果如下:
一点点想法
我计划基于这个制作一个根据语料构建行业词典的辅助服务。
本文多是个人的一些理解欢迎交流、欢迎批评指正。
相关文章:
SmoothNLP新词发现算法的改进实现
SmoothNLP新词发现算法的改进实现 背景介绍 新词发现也叫未登录词提取,依据 《统计自然语言处理》(宗成庆),中文分词有98%的错误来自"未登录词"。即便早就火遍大江南北的Bert也不能解决"未登录词"的Encoding问题,便索性…...

实时渲染为什么快,能不能局域网部署点量云
提到渲染很多有相关从业经验的人员可能会想起,自己曾经在电脑上渲染一个模型半天或者更长的 时间才能完成的经历。尤其是在项目比较着急的时候,这种煎熬更是难受。但现在随着实时渲染和云渲染行业的发展,通过很多方式可以提升渲染的时间和效率…...

网络游戏该如何防护ddos/cc攻击
现在做网络游戏的企业都知道服务器的安全对于我们来说很重要!互联网上面的 DDoS 攻击和 CC 攻击等等无处不在,而游戏服务器对服务器的防御能力和处理能力要求更高,普通的服务器则是比较注重各方面能力的均衡。随着游戏行业的壮大,…...

项目管理体系1-4练习题1-10答案
题目1 每周一次的项目会议上,一位团队成员表示在修订一项可交付成果时,一名销售经理对客户服务过程想出一项变更讨论,影响到整个项目,项目经理对销售参与到项目可交付成果感到吃惊,经理事先应该怎么做去阻止这些情况&…...

sHMIctrl智能屏幕使用记录
手上有个案子,“按压机器人”,功能是恒定一个力按下一定时间。 屏幕选型使用“sHMIctrl”,一下记录使用过程中遇到的问题以及解决方法。 目录 问题1:按键控件做定时触发,模拟运行时触发不了。 问题2:厂家…...
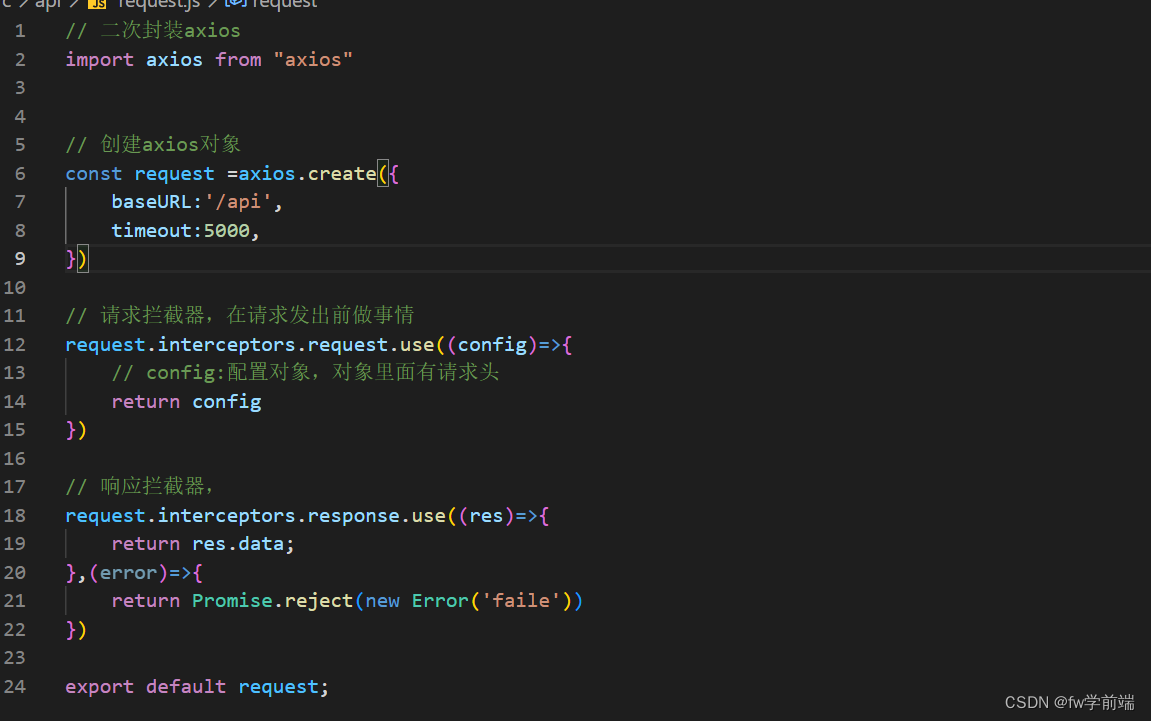
2.20 crm day01 配置路由router less使用 axios二次封装
需求: 目录 1.配置路由 2.less使用 vue2使用以下版本 3.axios二次封装 1.配置路由 1.1.1 官方链接:安装 | Vue Router npm i vue-router3.6.5 注意:vue2项目不能用vue-router四版本以上 1.2.1.创建router/index.js 在该文件中 //1.引…...
【LeetCode】剑指 Offer 10- I. 斐波那契数列 p74 -- Java Version
题目链接: 1. 题目介绍() 写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下: F(0) 0, F(1) 1F(N) F(N - 1) F…...
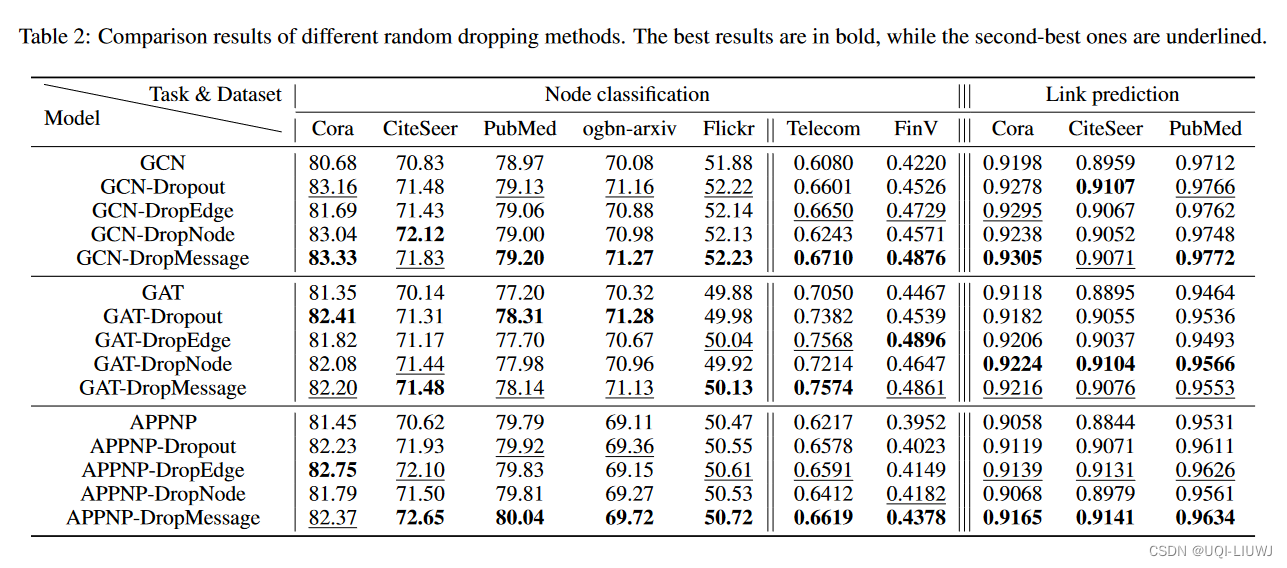
论文笔记:DropMessage: Unifying Random Dropping for Graph Neural Networks
(AAAI 23 优秀论文) 1 intro GNN的一个普遍思路是,每一层卷积层中,从邻居处聚合信息 尽管GNN有显著的进步,但是在大规模图中训练GNN会遇到各种问题: 过拟合 过拟合之后,GNN的泛化能力就被限制…...
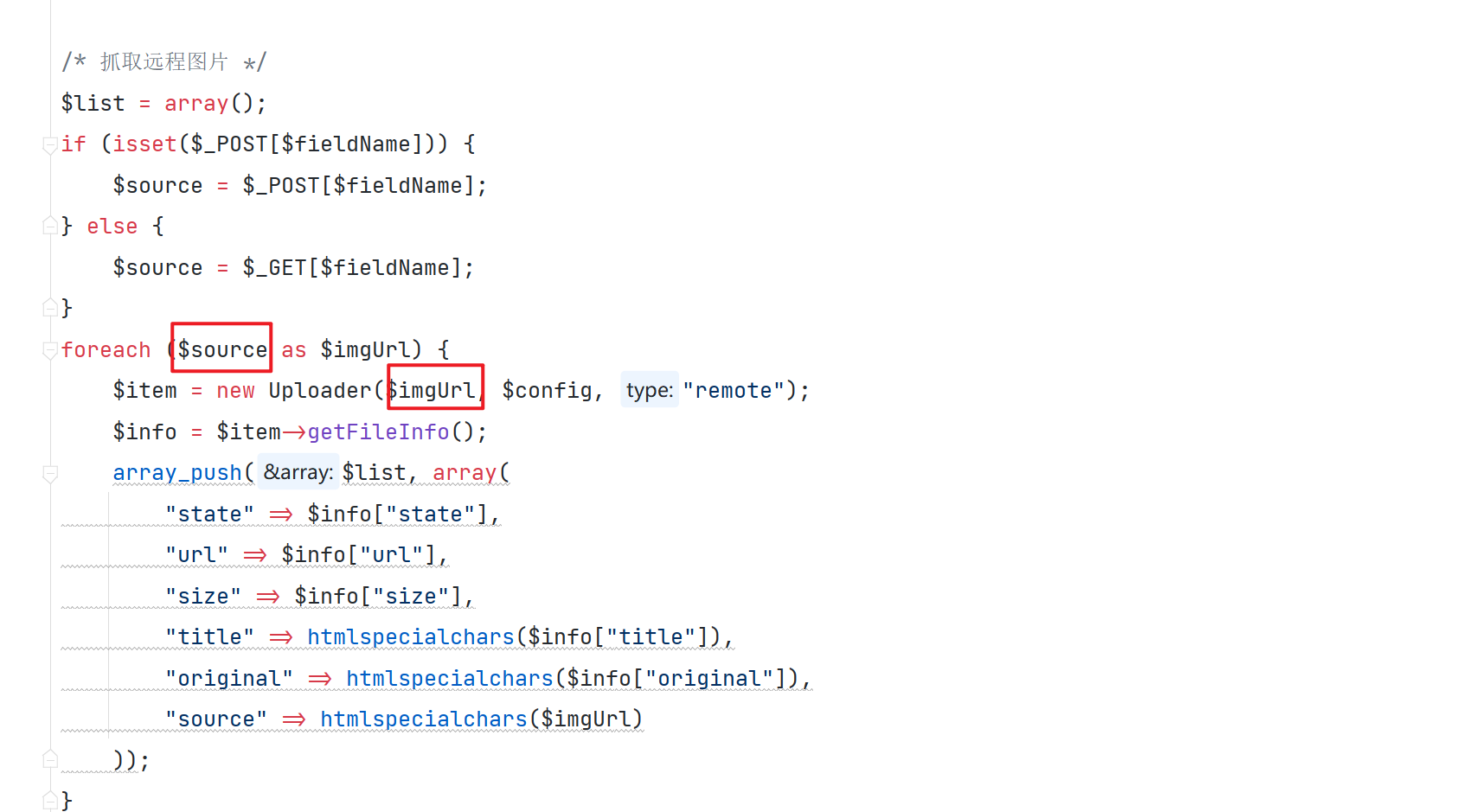
木鱼cms系统审计小结
MuYuCMS基于Thinkphp开发的一套轻量级开源内容管理系统,专注为公司企业、个人站长提供快速建站提供解决方案。 环境搭建 我们利用 phpstudy 来搭建环境,选择 Apache2.4.39 MySQL5.7.26 php5.6.9 ,同时利用 PhpStorm 来实现对项目的调试 …...

软件测试面试-一线大厂必问的测试思维面试题
五、测试思维5.1 打电话功能怎么去测?我们会从几个方面去测试:界面、功能、兼容性、易用性、安全、性能、异常。1)界面我们会测试下是否跟界面原型图一致,考虑浏览器不同显示比例,屏幕分辨率。2)功能&#…...
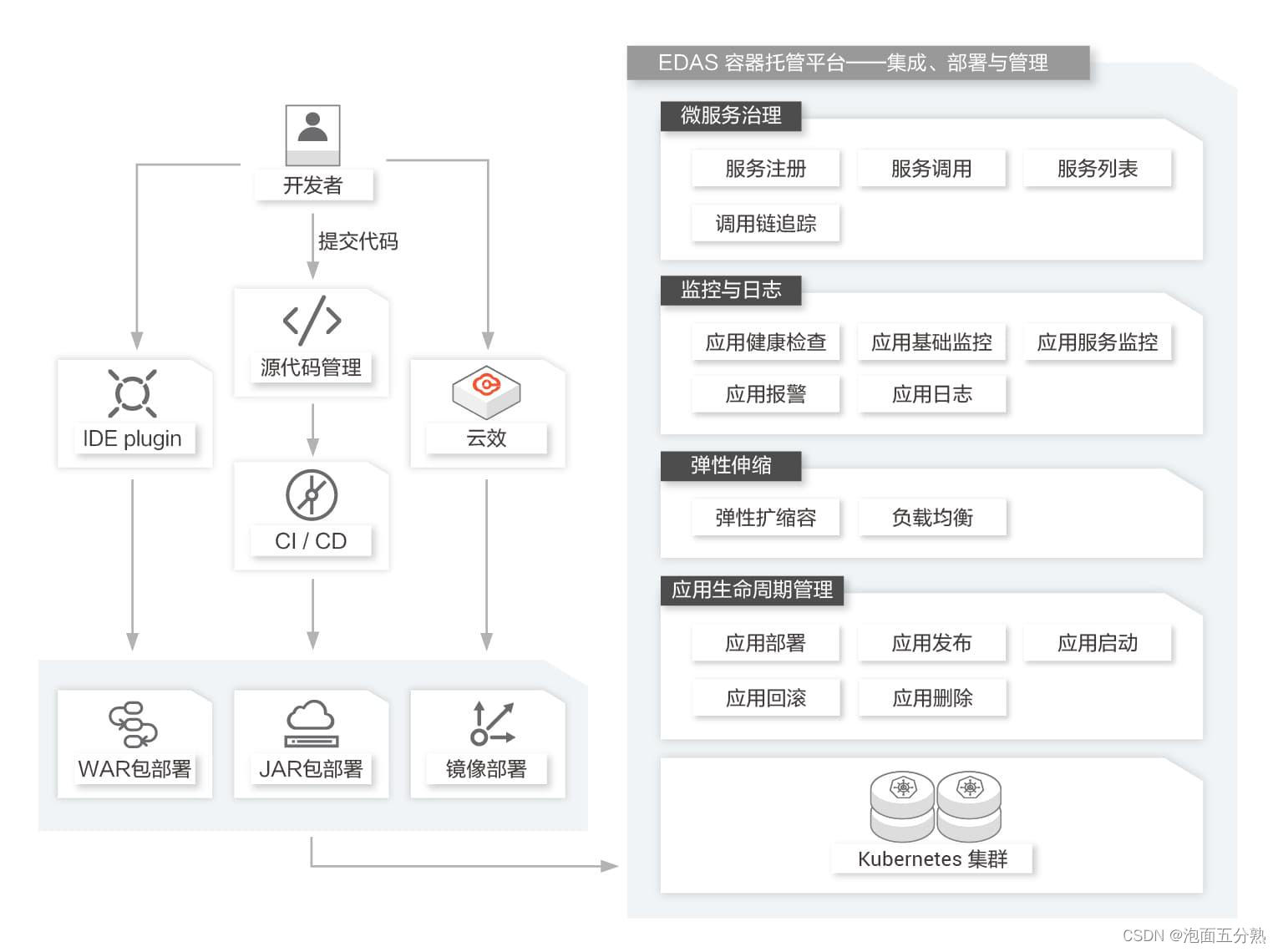
企业级分布式应用服务 EDAS
什么是企业级分布式应用服务EDAS企业级分布式应用服务EDAS(Enterprise Distributed Application Service)是一个应用托管和微服务管理的云原生PaaS平台,提供应用开发、部署、监控、运维等全栈式解决方案,同时支持Spring Cloud和Ap…...
弄懂 Websocket 你得知道的这 3 点
1. WebSocket原理 WebSocket同HTTP一样也是应用层的协议,但是它是一种双向通信协议,是建立在TCP之上的。 WebSocket是一种在单个TCP连接上进行全双工通信的协议。WebSocket API也被W3C定为标准。 WebSocket使得客户端和服务器之间的数据交换变得更加简…...

Appium构架及工作原理
一、appium结构简单来说appium充当一个中间服务器的功能,接收来自我们代码的请求,然后发送到手机上进行执行。二、初步认识appium工作过程1.appium是c/s模式的2.appium是基于webdriver协议添加对移动设备自动化api扩展而成的,所以具有和webdr…...

软件架构中“弹性”的多种含义
在软件架构领域的中文文档、书籍中,经常可以看到“弹性”这个专业术语,但在不同的语境下含义可能会不同。 在英语中,elastic 和 resilient 两个单词都可以翻译为“弹性的”,但是它们在软件架构中代表的含义却完全不同,…...

JAVA练习57- 罗马数字转整数、位1的个数
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目1-罗马数字转整数 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 二、题目2-位1的个数 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 …...
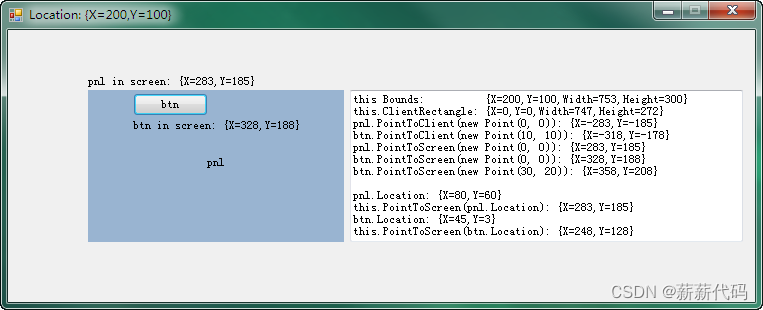
C#把图片放到picturebox上的指定位置,PointToClient与PointToScreen解读
1、C#中如何把图片放到picturebox上的指定位置 构造一个跟picturebox1一样大小的Bitmap, 设置给picturebox1, 然后在上面画图 Bitmap image new Bitmap(picturebox1.Size.Width, picturebox1.Size.Height); Graphics device Graphics.FromImage(imag…...
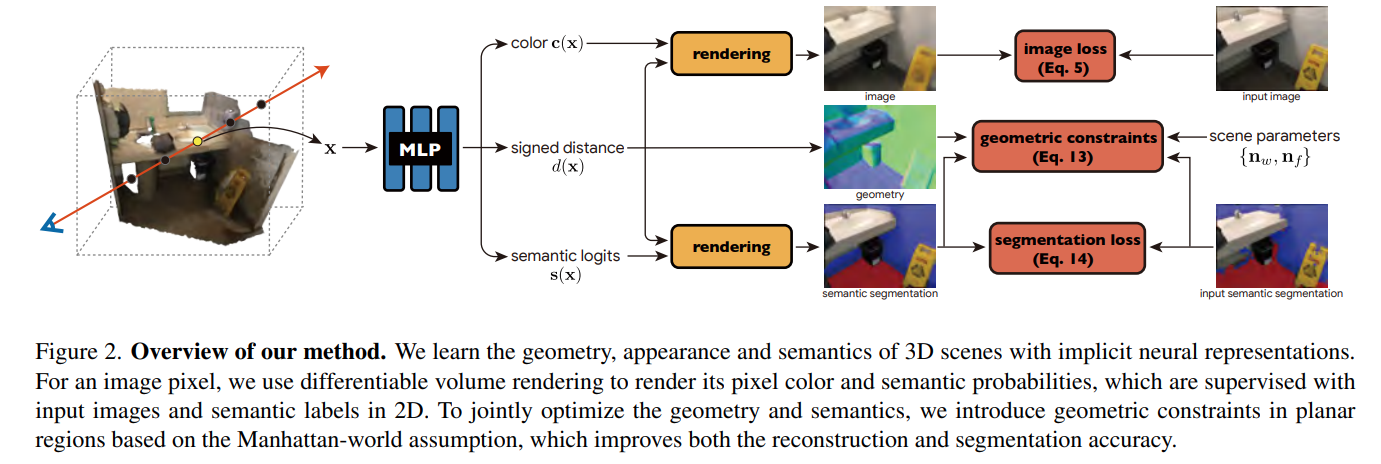
【论文笔记】Manhattan-SDF==ZJU==CVPR‘2022 Oral
Neural 3D Scene Reconstruction with the Manhattan-world Assumption 本文工作:基于曼哈顿世界假设,重建室内场景三维模型。 1.1 曼哈顿世界假设 参考阅读文献:Structure-SLAM: Low-Drift Monocular SLAM in Indoor EnvironmentsIEEE IR…...

环翠区中小学生编程挑战赛题解中学组T4:免费超市
题目描述 OITV电视台最近开设了名为“免费超市”的真人电视节目,在节目中,抽奖选拔的民间志愿者们将随机匹配进行两两对抗赛。每场比赛上,节目组设置 n n n件商品排成一排供选手挑选,两名选手将交替出手选中并拿走商品,每件商品有着不同的价值 a i a_i a...
的学习笔记)
关于Oracle树形查询(connect by)的学习笔记
1.查找员工 FORD的上级 Note:在查找时,应当注意树形是倒过来的。(自下而上),故此父亲节点是MGR ,而儿子节点是EMPNO –PRIOR MGREMPNO也是可以的。 以下两种方式均可以实现查找FORD的上级。 SQL> SQ…...

观看课程领奖品!Imagination中国区技术总监全面解读 IMG DXT GPU
此前,我们发布了一系列关于 IMG DXT GPU 的介绍,为了让更多读者了解其背后的技术及应用方向,我们特别邀请 Imagination 中国区技术总监艾克录制全新在线课程,为大家全面解读IMG DXT GPU。 点击这里,马上注册观看&…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

Unity动态自然系统:Forest Environment-Dynamic Nature深度解析
1. 这不是“贴图堆砌”,而是自然系统级建模:Forest Environment-Dynamic Nature 的真实定位你有没有试过在Unity里拖进几棵树、铺点草、加个天空盒,然后发现场景像一张静止的风景明信片——风不动、叶不摇、雨不落、雾不散?我做过…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...

Redis在线工具终极指南:3分钟学会数据库操作,无需安装配置
Redis在线工具终极指南:3分钟学会数据库操作,无需安装配置 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 还在为Redis环境配置而烦恼吗?还在为测试一个…...

深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构
深度解析zenodo_get路径处理机制:如何优雅处理科研数据下载的目录结构 【免费下载链接】zenodo_get Zenodo_get: Downloader for Zenodo records 项目地址: https://gitcode.com/gh_mirrors/ze/zenodo_get 在科研数据管理领域,高效的数据下载工具…...

如何将B站缓存视频从m4s格式无损转换为通用MP4?
如何将B站缓存视频从m4s格式无损转换为通用MP4? 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾遇到过这样的情况࿱…...

后端开发者体验 AI 前端:用 TinyVue 做一个智能业务表单 Demo
摘要 作为 Java 后端开发者,我平时更多关注接口、SQL 和业务逻辑,但后台系统里也绕不开表单、列表和报表页面。本文结合 OpenTiny NEXT 学习体验,用 TinyVue 做一个智能业务表单 Demo,聊聊 AI 前端对后端开发者到底有没有实际帮助…...