使用 ElasticSearch 作为知识库,存储向量及相似性搜索
一、ElasticSearch 向量存储及相似性搜索
在当今大数据时代,快速有效地搜索和分析海量数据成为了许多企业和组织的重要需求。Elasticsearch 作为一款功能强大的分布式搜索和分析引擎,为我们提供了一种优秀的解决方案。除了传统的文本搜索,Elasticsearch 还引入了向量存储的概念,以实现更精确、更高效的相似性搜索。
在 Elasticsearch 中,我们可以将文档或数据转换为数值化向量的方法存入。每个文档被表示为一个向量,其中每个维度对应于文档中的一个特征或属性。这种向量化的表示使得文档之间的相似性计算变得可能。
使用场景:
-
相似文档搜索:通过将文档转换为向量,并使用向量相似性函数,如
dot product或cosine similarity,可以快速找到与查询文档最相似的文档,从而实现精确且高效的相似文档搜索。 -
推荐系统:将用户和商品等表示为向量,可以根据用户的喜好和行为,推荐与其兴趣相似的商品。
-
图像搜索:将图像转换为向量表示,并使用相似性度量,可以在图像库中快速找到与查询图像相似的图像。
下面基于上篇文章使用到的 Chinese-medical-dialogue-data 中文医疗对话数据作为知识内容进行实验。
本篇实验使用 ES 版本为:7.14.0
二、Chinese-medical-dialogue-data 数据集
GitHub 地址如下:
https://github.com/Toyhom/Chinese-medical-dialogue-data
数据分了 6 个科目类型:
数据格式如下所示:

其中 ask 为病症的问题描述,answer 为病症的回答。
由于数据较多,本次实验仅使用 IM_内科 数据的前 5000 条数据进行测试。
三、Embedding 模型
Embedding 模型使用开源的 chinese-roberta-wwm-ext-large ,该模型输出为 1024 维。
huggingface 地址:
https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
基本使用如下:
from transformers import BertTokenizer, BertModel
import torch# 模型下载的地址
model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'def embeddings(docs, max_length=300):tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# 对文本进行分词、编码和填充input_ids = []attention_masks = []for doc in docs:encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_ids.append(encoded_dict['input_ids'])attention_masks.append(encoded_dict['attention_mask'])input_ids = torch.cat(input_ids, dim=0)attention_masks = torch.cat(attention_masks, dim=0)# 前向传播with torch.no_grad():outputs = model(input_ids, attention_mask=attention_masks)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddingsif __name__ == '__main__':res = embeddings(["你好,你叫什么名字"])print(res)print(len(res))print(len(res[0]))
运行后可以看到如下日志:

四、ElasticSearch 存储向量
创建向量索引
PUT http://127.0.0.1:9200/medical_index
{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"ask_vector": { "type": "dense_vector", "dims": 1024 },"ask": { "type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"answer": { "type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}
}
其中 dims 为向量的长度。
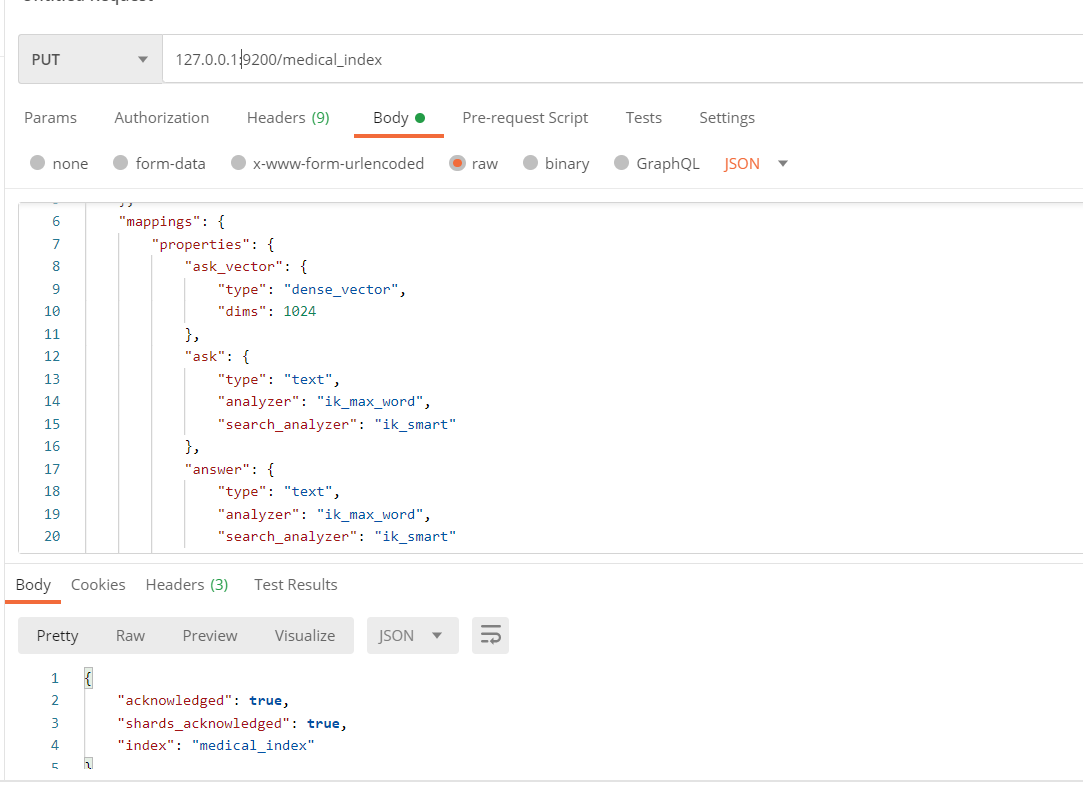
查看创建的索引:
GET http://127.0.0.1:9200/medical_index
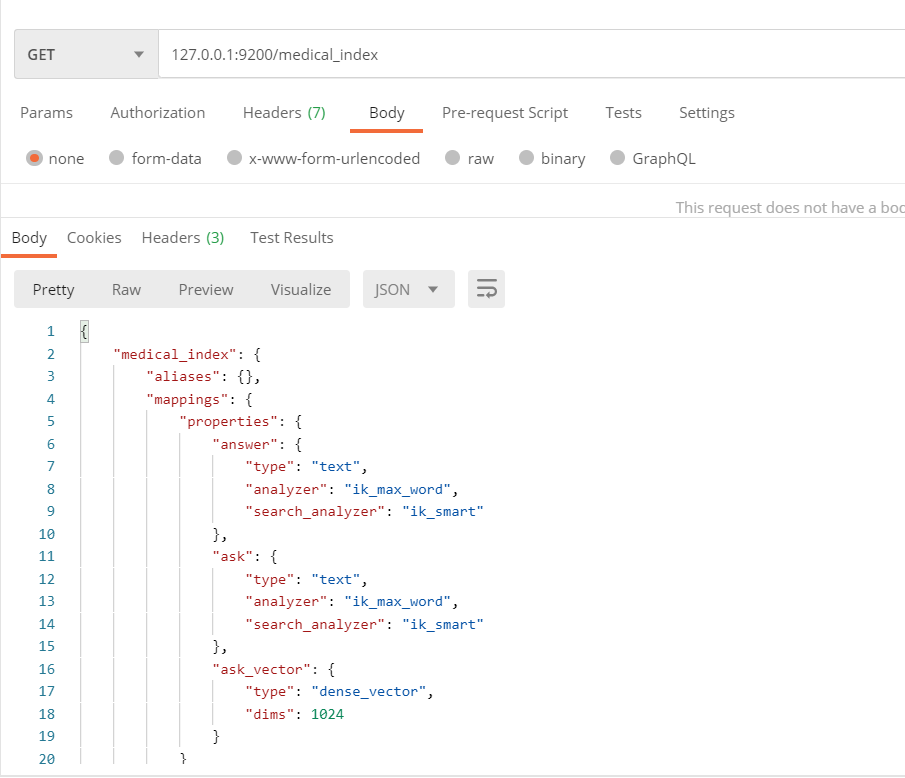
数据存入 ElasticSearch
引入 ElasticSearch 依赖库:
pip install elasticsearch -i https://pypi.tuna.tsinghua.edu.cn/simple
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torch
import pandas as pddef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def add_doc(index_name, id, embedding_ask, ask, answer, es):body = {"ask_vector": embedding_ask.tolist(),"ask": ask,"answer": answer}result = es.create(index=index_name, id=id, doc_type="_doc", body=body)return resultdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 数据地址path = "D:\\AIGC\\dataset\\Chinese-medical-dialogue-data\\Chinese-medical-dialogue-data\\Data_数据\\IM_内科\\内科5000-33000.csv"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))# 读取数据写入ESdata = pd.read_csv(path, encoding='ANSI')for index, row in data.iterrows():# 写入前 5000 条进行测试if index >= 500:breakask = row["ask"]answer = row["answer"]# 文本转向量embedding_ask = embeddings_doc(ask, tokenizer, model)result = add_doc(index_name, index, embedding_ask, ask, answer, es)print(result)if __name__ == '__main__':main()
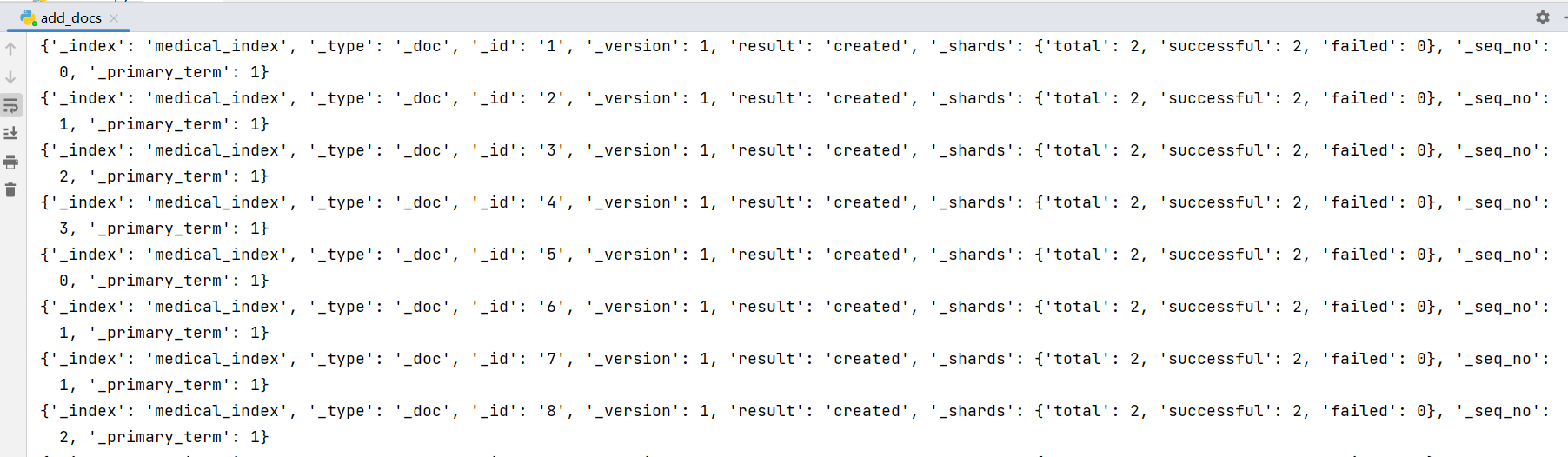
五、相似性搜索
1. 余弦相似度算法:cosineSimilarity
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "cosineSimilarity(params.queryVector, 'ask_vector') + 1.0","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()打印日志如下:

================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
2. 点积算法:dotProduct
计算给定查询向量和文档向量之间的点积度量。
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "dotProduct(params.queryVector, 'ask_vector')+1.0","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()
================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
3. L1曼哈顿距离:l1norm
计算给定查询向量和文档向量之间的L1距离。
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "1 / (1 + l1norm(params.queryVector, doc['ask_vector']))","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()
================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
4. l2 欧几里得距离:l2norm
计算给定查询向量和文档向量之间的欧几里德距离。
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "1 / (1 + l2norm(params.queryVector, doc['ask_vector']))","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()
================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
相关文章:
使用 ElasticSearch 作为知识库,存储向量及相似性搜索
一、ElasticSearch 向量存储及相似性搜索 在当今大数据时代,快速有效地搜索和分析海量数据成为了许多企业和组织的重要需求。Elasticsearch 作为一款功能强大的分布式搜索和分析引擎,为我们提供了一种优秀的解决方案。除了传统的文本搜索,El…...

视频图像处理算法opencv在esp32及esp32s3上面的移植,也可以移植openmv
opencv在esp32及esp32s3上面的移植 Opencv简介 OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上,它轻量级而且高效——由一系列 C 函数和少量…...
2. postgresql并行扫描(1)——pg强制走并行扫描建表及参数配置
转载自:https://developer.aliyun.com/article/700370 1. 参数设置 1.1 postgresql.conf中修改 # 1、总的可开启的WORKER足够大 max_worker_processes 128# 2、所有会话同时执行并行计算的并行度足够大 max_parallel_workers64# 3、单个QUERY中并行计算NODE开…...
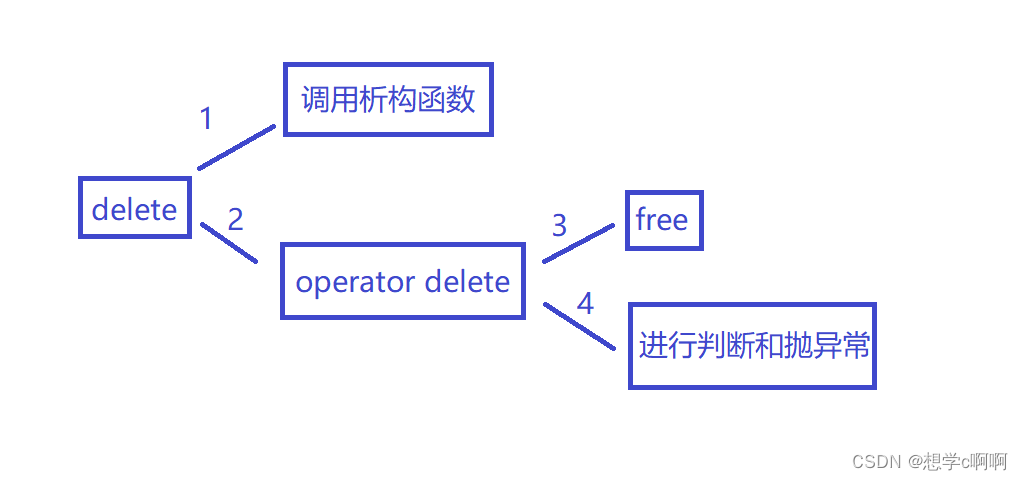
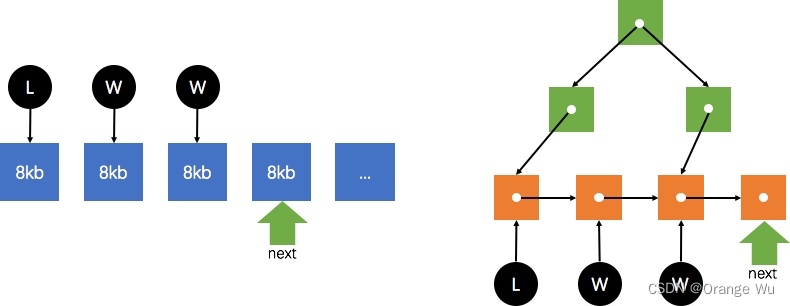
【C++】动态内存管理
【C】动态内存管理 new和delete用法内置类型自定义类型抛异常定位new 刨析new和delete的执行与实现逻辑功能执行顺序newdelete 功能实现operator new与operator delete malloc free与new delete的总结 在我们学习C之前 在C语言中常用的动态内存管理的函数为: mallo…...

MATLAB R2023a完美激活版(附激活补丁)
MATLAB R2023a是一款面向科学和工程领域的高级数学计算和数据分析软件,它为Mac用户提供了强大的工具和功能,用于解决各种复杂的数学和科学问题。以下是MATLAB R2023a Mac的一些主要特点和功能: 软件下载:MATLAB R2023a完美激活版 …...
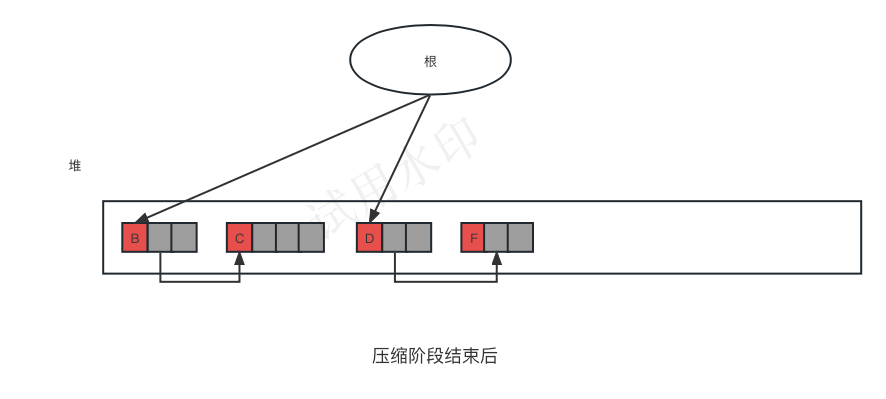
垃圾回收 - 标记压缩算法
压缩算法是将标记清除算法与复制算法相结合的产物。 1、什么是标记压缩算法 标记压缩算法是由标记阶段和压缩阶段构成。 首先,这里的标记阶段和标记清除算法时提到的标记阶段完全一样。 接下来我们要搜索数次堆来进行压缩。压缩阶段通过数次搜索堆来重新填充活动对…...

Vue中过滤器如何使用?
过滤器是对即将显示的数据做进⼀步的筛选处理,然后进⾏显示,值得注意的是过滤器并没有改变原来 的数据,只是在原数据的基础上产⽣新的数据。过滤器分全局过滤器和本地过滤器(局部过滤器)。 目录 全局过滤器 本地过滤器…...

【爬虫】7.4. 字体反爬案例分析与爬取实战
字体反爬案例分析与爬取实战 文章目录 字体反爬案例分析与爬取实战1. 案例介绍2. 案例分析3. 爬取 本节来分析一个反爬案例,该案例将真实的数据隐藏到字体文件里,即使我们获取了页面源代码,也无法直接提取数据的真实值。 1. 案例介绍 案例网…...

Linux cat 的作用
Linux中的cat命令用于连接文件并打印到标准输出设备(通常是终端)。 它的主要作用有以下几点: 查看文件内容:cat命令可用于查看文本文件的内容,将文件的内容从第一行到最后一行打印到终端。 合并文件:cat命…...

Windows中的命令行提示符里的Start命令执行路径包含空格时的问题
转载:电脑知识收藏夹 Blog Archive Windows中的命令行提示符里的Start命令执行路径包含空格时的问题 当使用Windows 中的命令行提示符执行这段指令时(测试Start命令执行带空格的路径的程序或文件问题),第一行Start会成功执行,跳出记事本程…...
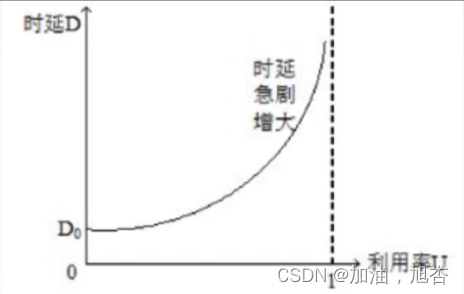
【基础计算机网络1】认识计算机网络体系结构,了解计算机网络的大致模型(上)
前言 今天,小编我也要进入计算机网络的整个内容,虽然这个计算机网络的内容在考研部分中占比比较小,有些人不把这一部分当成重点,这种想法是错误的。我觉得考研的这四个内容都是非常重要的,我们需要进行全力以赴的对待每…...

学校宿舍智能水电表管理系统:为节约资源保驾护航
随着科技的不断发展,越来越多的学校开始重视宿舍管理的智能化。其中,智能水电表管理系统作为一项重要的基础设施,已经逐渐被各大高校引入。本文将围绕学校宿舍智能水电表管理系统展开详细介绍,让我们一起来了解一下这个节约资源、…...

EasyFalsh移植使用方法
参考:https://blog.csdn.net/Mculover666/article/details/105510837 注意: 这里说的修改默认环境变量后修改环境变量版本号就自动重新写入到flash这句话是有问题的,要开启上面【#define EF_ENV_AUTO_UODATE】宏定义后才会实现该功能&#…...
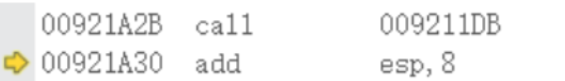
函数栈帧(详解)
一、前言: 环境:X86Vs2013 我们C语言学习过程中是否遇到过如下问题或者疑惑: 1、局部变量是如何创建的? 2、为什么局部变量的值是随机值? 3、函数是怎么传参的?传参的顺序是怎样的? 4、形…...

【面试题总结1】-Static、Const、QT中基于TCP的通信服务器/客户端端操作
1、在C和C中static关键字的用法 在C语言和C中, ① static修饰未初始化的全局变量,结果默认为0 ; ② 当static修饰局部变量时,只是延长了这个变量的生命周期,并没有改变其作用域。 比如说,这个变量是在哪个函…...

镜像的基本命令(docker)
文章目录 前言一、docker命令介绍1、帮助命令2、显示镜像3、搜索镜像4、下载镜像5、删除镜像 总结 前言 本文主要介绍docker中与镜像相关的一些命令,是对狂神课程的一些总结,作为一个手册帮助博主和使用docker的同学们来查找和回忆。 实验环境…...
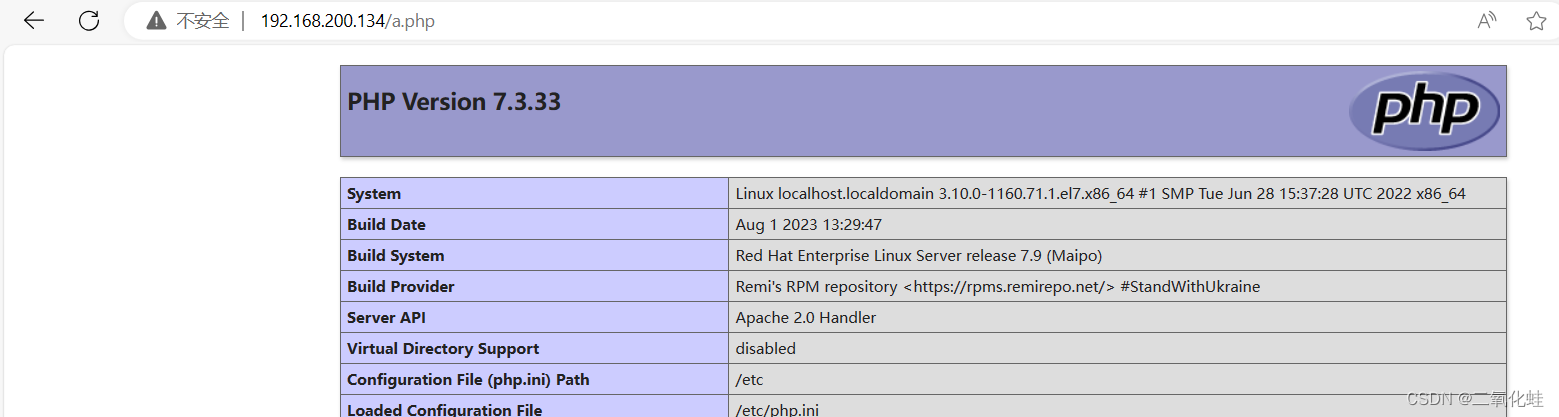
Liunx远程调试
1、Vscode中使用xdebug调试php 2、工具的下载 3、debug的配置 1、Vscode中使用xdebug调试php 1,在phpstudy中启用xdebug扩展 2,打开php.ini,修改配置 [Xdebug] zend_extensionD:/PHP/Extensions/php/php5.6.9nts/ext/php_xdebug.dll xdebug…...
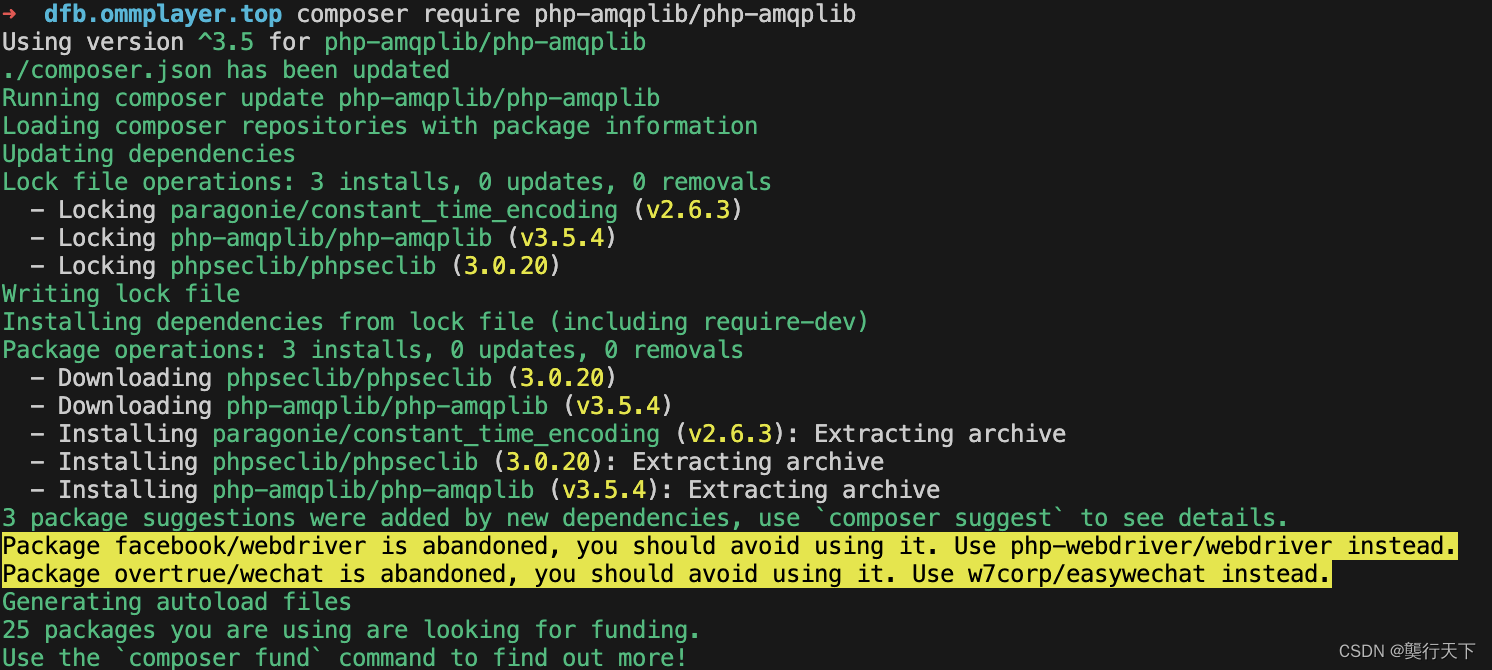
Mac m1 安装rabbitmq+php-amqplib
rabbitmq 官方地址 https://www.rabbitmq.com mac 软件包 Downloading and Installing RabbitMQ — RabbitMQ 一.这里我选择 homebrew brew updatebrew install rabbitmq二.php代码 用composer 安装 10年软件开发经验,结交朋友! 分销商城系统开发,App商城开发 商务合作 s…...
如何实现软件的快速交付与部署?
一、低代码开发 微服务、平台化、云计算作为当前的IT技术热点,主要强调共享重用,它们促进了软件快速交付和部署。 但现实的痛点却是,大多数软件即使采用了微服务技术或者平台化思路,也难以做到通过软件共享重用来快速满足业务需求…...
c语言每日一练(14)【加强版】
前言:每日一练系列,每一期都包含5道选择题,2道编程题,博主会尽可能详细地进行讲解,令初学者也能听的清晰。博主有时会将一些难题综合成每日一练加强版,加强版是特殊的,它仅包含5道选择题&#x…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...

VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具
VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,VHDL转Verilog是许多工程师面临的共同挑战。手动转换不仅耗时费力,还容…...

完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题
完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

开源自动驾驶系统终极指南:从入门到精通
开源自动驾驶系统终极指南:从入门到精通 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/op/openpilo…...

UEFITool解析指南:三步骤掌握固件逆向分析的核心技术
UEFITool解析指南:三步骤掌握固件逆向分析的核心技术 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款功能强大的UEFI固件分析工具,能够帮助你深入探索计…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

Arm CoreLink PCK-600电源管理架构与寄存器编程详解
1. Arm CoreLink PCK-600电源控制架构解析在嵌入式系统设计中,电源管理单元(PMU)是实现高效能耗控制的核心组件。Arm CoreLink PCK-600作为业界领先的电源控制解决方案,其架构设计体现了现代SoC电源管理的先进理念。PCK-600系列采…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...

MacOS光标增强工具:命令行驱动,实现自动化与个性化配置
1. 项目概述:当光标成为生产力工具如果你是一名长期在macOS上工作的开发者、设计师或者文字工作者,你肯定对系统自带的光标功能又爱又恨。爱的是它简洁流畅,恨的是它在某些高强度、多任务场景下显得力不从心。比如,当你需要在多个…...