【1++的数据结构】之哈希(一)
👍作者主页:进击的1++
🤩 专栏链接:【1++的数据结构】
文章目录
- 一,什么是哈希?
- 二,哈希冲突
- 哈希函数
- 哈希冲突解决
- unordered_map与unordered_set
一,什么是哈希?
首先我们要知道的是哈希是一种思想----一 一映射。在以前我们讲过的容器中,查找效率最高的就是二叉平衡搜索树,由于其关键码与存储位置之间没有对应的关系,而是通过多次比较关键码的大小来查找,查找的效率取决于比较次数,查找的时间复杂度可以达到O(logN) 。最理想的查找便是不经过任何的比较,直接能够锁定查找值的位置,因此,如果能够构建一种结构,通过某种函数能够使得关键码与存储位置之间一一映射,便能够快速的找到要查找的值。其实,有点类似与通信中的调制与解调哈。

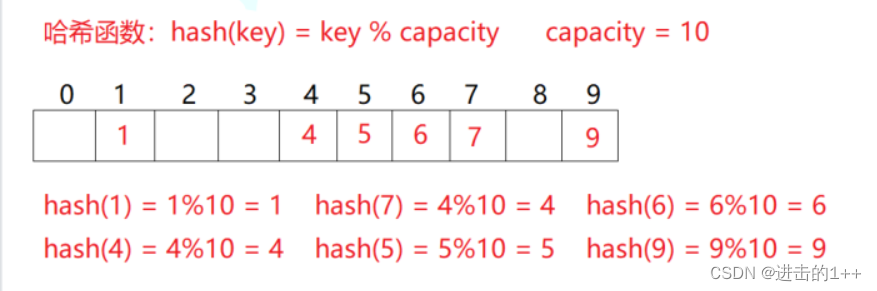
如上图:
我们根据插入元素的关键码,将其通过哈希函数的计算后,便可以得到该元素的存储位置。
其是一一映射的关系。
当我们要查找某元素时,我们便可以根据该元素的关键码,再通过哈希函数的计算后,得出该元素的位置。效率是不是感觉高的起飞!!!!!!
我们将该方法称为哈希方法,将转换函数称为哈希函数,将该结构称为哈希表。
这么牛逼的想法,我怎么现在才知道???难道就仅仅这么简单吗???

哈哈哈哈哈哈!!!当然不会这么容易。一刚才的图为例,当我们插入44,11这样的值后,我们就会发现其产生了冲突,位置被占用了(我们把这种冲突称为哈希冲突)!!!这该怎么办呢? 我们下一节来进行讲解。
二,哈希冲突
我们把不同关键字通过哈希函数计算得出相同的地址的这种现象称为哈希冲突。
既然元素的存储地址是通过哈希函数的计算得出的,那么哈希冲突当然也与哈希函数的设计有关,好的哈希函数,可以减少哈希冲突的发生。
哈希函数
哈希函数的设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见的几种哈希函数:
直接定址法: 取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B。
其优点是简单,均匀;缺点是要提前知道关键字的分布情况。
除留余数法: 设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。
那为什么最好要是质数呢?
有以下结论:
如果有一个数列s,间隔为1,那么不管模数为几,都是均匀分布的,因为间隔为1是最小单位
如果一个数列s,间隔为模本身,那么在哈希表中的分布仅占有其中的一列,也就是处处冲突
数列的冲突分布间隔为因子大小,同样的随机数列,因子越多,冲突的可能性就越大。
具体验证过程大家可以看下面这篇文章:
除留余数法为什么选择质数取模
平方取中法:
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况。
折叠法:
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况。
随机数法:
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
通常应用于关键字长度不等时采用此法。
哈希函数设计的越好,冲突就越少,但冲突无法避免。
哈希冲突解决
最常见的两种解决方法:闭散列与开散列。
我们先来说闭散列:
当发生哈希冲突时,若哈希表未满,则将元素放到下一个空位置。
寻找空位置,也有两种方法:线性探测和二次探测。
什么叫线性探测呢?从冲突的位置开始,一次向后找,知道找到下一个空位置。
哈希表中元素的删除:
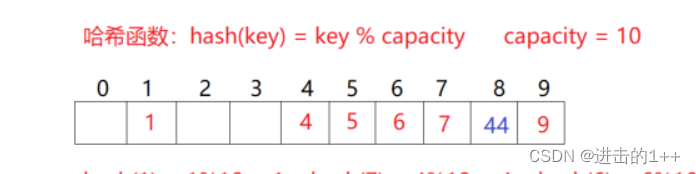
如上图所示,我们采用线性探测法来寻找空位置,当我们要删除元素4时,便会出现一个问题,若我们直接将4从表中物理删除后,当再去查找44时,就会出现找不到的情况。因此我们采用伪删除来解决。就是我们给哈希表中的每个位置给一个标记:EMPTY / FILLED / DELETE。这样就可以避免上面的问题了。
为了使冲突尽可能的少,我们哈希表的空间会被插入的元素个数要大。我们将 插入的元素个数/哈希表的大小 之比称为载荷因子。
enum State{EMPTY,DELETE,FILL};template<class K, class V>struct Hash_Node{pair<K, V> _kv;State _state = EMPTY;};bool Insert(const pair<K, V>& kv){//查找if (Find(kv)){return false;}//扩容if (_size == 0 ||(_size * 10)/ _table.size() >= 7){size_t newsize = _table.size() == 0 ? 5 : _table.size() * 2;Hash_table<K, V> tmp;tmp._table.resize(newsize);for (auto& e : _table){if (e._state == FILL){tmp.Insert(e._kv);}}_table.swap(tmp._table);}Hash _hash;size_t tablei = _hash(kv.first) % _table.size();while (_table[tablei]._state == FILL){++tablei;tablei %= _table.size();}_table[tablei]._kv = kv;_table[tablei]._state = FILL;++_size;return true;}
当超过载荷因子后,要进行扩容,在扩容时我们申请一个容量更大的哈希表,然后将旧表的数据移到新表中,这里我们采用了一个相对较聪明的写法,我们将旧表遍历一遍,调用插入函数进行插入。最后,哈希表的底层是vector,我们再调用vector的交换函数,可以将两个指向不同vector对象的指针进行交换。这样就扩容完成了。
线性探测的缺点:当多个哈希冲突集中在一起,会发生数据堆积,这样在查找时比较的次数就会增多,影响效率。而二次探测就可以避免这样的问题。
二次探测在这里我们就简单了解:
当我们发生冲突时,(设发生冲突的位置为x)我们去找(x+1^2)%表长 这个位置,若还是冲突则找(x-1^2)%表长 这个位置,若仍冲突则找(x+2^2)%表长 这个位置…直到没有冲突。
开散列:
开散列是指:将关键码集合通过哈希函数计算后得出地址,将具有相同地址的关键码集中在一个子集合。每一个子集合称为桶。桶中的元素通过链表链接起来,哈希表中存储的是链表的头结点。
代码如下:
template<class K,class V,class Hash=HashFunc<K>>class Hash_Bucket{typedef Hash_Node<K,V> Node;public:bool Insert(const pair<K, V>& kv){Hash hash;//查找if (Find(kv)){return false;}//扩容if (_size == _Bucket.size())//这里有点小问题:当桶的数量等于元素数量时就扩容,这样冲突小。{if (_size == 0){_Bucket.resize(5);}else{vector<Node*> tmp;tmp.resize(_Bucket.size() * 2);size_t i = 0;for (i = 0; i < _Bucket.size(); i++){Node* cur = _Bucket[i];while (cur){size_t tmpi = hash(cur->_kv.first) % tmp.size();Node* next = cur->_next;cur->_next = tmp[tmpi];tmp[tmpi]=cur;cur = next;}//_Bucket[i] = nullptr;}_Bucket.swap(tmp);}}//插入size_t Bucketi = hash(kv.first) % _Bucket.size();Node* cur = new Node(kv);cur->_next = _Bucket[Bucketi];_Bucket[Bucketi]=cur;_size++;return true;}bool Find(const pair<K, V>& kv){if (_size == 0){return false;}Hash hash;size_t Bucketi = hash(kv.first) % _Bucket.size();Node* cur = _Bucket[Bucketi];while (cur){if (cur->_kv == kv){return true;}else{cur = cur->_next;}}return false;}private:vector<Hash_Node<K, V>*> _Bucket;size_t _size=0;};
这里我们重点讲一下开散列的扩容!!!
首先就是什么时候扩容比较好,开散列性能最好当然就是一个桶直挂一个元素的时候是最好的,因此当桶的数量等于元素的数量时扩容是比较好的。接着我们讲一下扩容的具体操作。与闭散列不同的是,闭散列是直接再实例化了一个哈希表对象,再进行插入操作,最后交换了两个指向vector的指针。而我们的开散列这样做会比较浪费空间,因为我们的元素存储再一个一个的结点中,因此我们不妨将这些结点再利用起来,让其插入再新的哈希表中,再将指向新旧哈希表的指针进行交换。
我们的哈希表只能存储key为整型的元素,那么如何存储其他元素呢?
我们可以提供一个能够将key转化为整型的仿函数。
template<class K>struct HashFunc{size_t operator() (const K& key){return (size_t)key;}};template<>struct HashFunc<string>//特化{size_t operator() (const string& key){size_t ret = 0;for (auto e : key){ret += e;}return ret;}};
unordered_map与unordered_set
unordered_map与unordered_set的底层结构为哈希表,其封装过程及其对哈希表的改造与map与set相似这里我们就不过多阐述,我们直接看代码:
改造后的哈希表
template<class T>struct Hash_Node{Hash_Node* _next;T _data;Hash_Node(const T& data):_data(data), _next(nullptr){}};template<class K, class T, class Hash, class KeyOfT>class Hash_Bucket;template<class K,class T,class Hash,class KeyOfT>struct _Iterator{typedef Hash_Node<T> Node;typedef _Iterator Self;typedef Hash_Bucket<K, T, Hash, KeyOfT> _Ht;Node* _node;_Ht* _pht;Hash hash;KeyOfT kot;_Iterator(Node* node,_Ht* pht):_node(node),_pht(pht){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const Self& s)const{return _node != s._node;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{size_t i = hash(kot(_node->_data)) % _pht->_Bucket.size();++i;for (; i < _pht->_Bucket.size(); i++){if (_pht->_Bucket[i]){_node = _pht->_Bucket[i];break;}}if (i == _pht->_Bucket.size()){_node = nullptr;}}return *this;}};template<class K,class T,class Hash,class KeyOfT>class Hash_Bucket{typedef Hash_Node<T> Node;template<class K, class T, class Hash, class KeyOfT>friend struct _Iterator;public:typedef typename _Iterator<K, T, Hash, KeyOfT> iterator;inline size_t __stl_next_prime(size_t n){static const size_t __stl_num_primes = 28;static const size_t __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};for (size_t i = 0; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > n){return __stl_prime_list[i];}}return -1;}pair<iterator,bool> Insert(const T& data){KeyOfT kot;Hash hash;//查找if (Find(kot(data)).second){return Find(kot(data));}//扩容if (_size ==_Bucket.size()){vector<Node*> tmp;tmp.resize(__stl_next_prime(_Bucket.size()),nullptr);size_t i = 0;for (i = 0; i < _Bucket.size(); i++){Node* cur = _Bucket[i];while (cur){size_t tmpi = hash(kot(cur->_data)) % tmp.size();Node* next = cur->_next;cur->_next = tmp[tmpi];tmp[tmpi]=cur;cur = next;}//_Bucket[i] = nullptr;}_Bucket.swap(tmp);}//插入size_t Bucketi = hash(kot(data)) % _Bucket.size();Node* cur = new Node(data);cur->_next = _Bucket[Bucketi];_Bucket[Bucketi]=cur;_size++;return make_pair(iterator(cur,this),true);}size_t Erase(const K& key){Hash hash;KeyOfT kot;size_t Bucketi = hash(key) % _Bucket.size();Node* cur = _Bucket[Bucketi];Node* prev = nullptr;while (cur){if (kot(cur->_data) == key){//可能为头结点,也可能为中间结点if (kot(_Bucket[Bucketi]->_data) == key){_Bucket[Bucketi]=cur->_next;delete cur;_size--;return 1;}else{prev->_next=cur->_next;delete cur;_size--;return 1;}}else{prev = cur;cur = cur->_next;}}return 0;}pair<iterator,bool> Find(const K& key){KeyOfT kot;if (_size == 0){return make_pair(iterator(nullptr,this),false);}Hash hash;size_t Bucketi = hash(key) % _Bucket.size();Node* cur = _Bucket[Bucketi];while (cur){if (kot(cur->_data) == key){return make_pair(iterator(cur, this), true);}else{cur = cur->_next;}}return make_pair(iterator(nullptr, this), false);}iterator begin(){for (size_t i = 0; i < _Bucket.size(); i++){if (_Bucket[i]){return iterator(_Bucket[i], this);}}return end();}iterator end(){return iterator(nullptr, this);}private:vector<Hash_Node<T>*> _Bucket;size_t _size=0;};
封装的unordered_map
template<class K>struct HashFunc{size_t operator() (const K& key){return (size_t)key;}};template<>struct HashFunc<string>{size_t operator() (const string& key){size_t ret = 0;for (auto e : key){ret += e;}return ret;}};template<class K, class V,class Hash= HashFunc<K>>class unordered_map{struct KeyOfM{const K& operator() (const pair<K, V>& kv){return kv.first;}};public:typedef typename Hash_Bucket<K, pair<K, V>, Hash, KeyOfM>::iterator iterator;pair<iterator,bool> Insert(const pair<K, V>& kv){return _ht.Insert(kv);}size_t Erase(const K& key){return _ht.Erase(key);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}private:Hash_Bucket<K, pair<K,V>,Hash, KeyOfM> _ht;};
封装的unordered_set
template<class K, class Hash=HashFunc<K>>class unordered_set{ struct KeyOfS{const K& operator() (const K& key){return key;}};public:typedef typename Hash_Bucket<K,K,Hash,KeyOfS>::iterator iterator;pair<iterator, bool> Insert(const K& key){return _ht.Insert(key);}size_t Erase(const K& key){return _ht.Erase(key);}iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}private:Hash_Bucket<K, K, Hash, KeyOfS> _ht;};
相关文章:
【1++的数据结构】之哈希(一)
👍作者主页:进击的1 🤩 专栏链接:【1的数据结构】 文章目录 一,什么是哈希?二,哈希冲突哈希函数哈希冲突解决 unordered_map与unordered_set 一,什么是哈希? 首先我们要…...
【网络编程】深入了解UDP协议:快速数据传输的利器
(꒪ꇴ꒪ ),Hello我是祐言QAQ我的博客主页:C/C语言,数据结构,Linux基础,ARM开发板,网络编程等领域UP🌍快上🚘,一起学习,让我们成为一个强大的攻城狮࿰…...
WordPress(5)在主题中添加文章字数和预计阅读时间
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 样式图一、添加位置二、找到主题文件样式图 提示:以下是本篇文章正文内容,下面案例可供参考 一、添加位置 二、找到主题文件 在主题目录下functions.php文件把下面的代码添加进去: // 文章字数…...
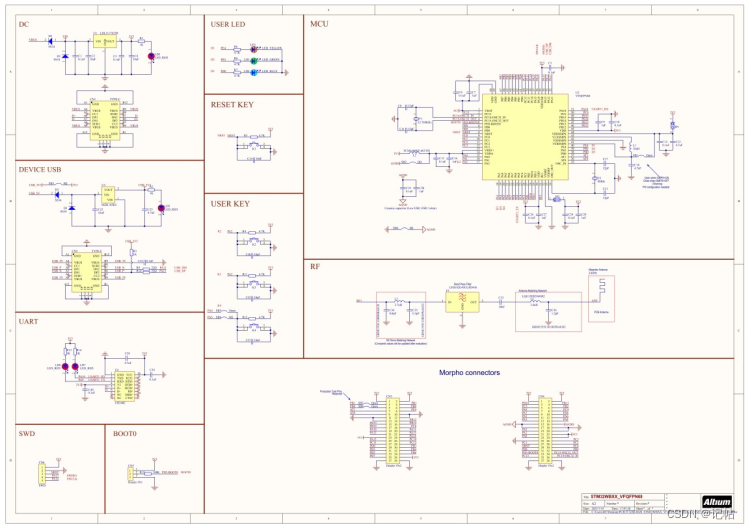
STM32WB55开发(1)----套件概述
STM32WB55开发----1.套件概述 所用器件视频教学样品申请优势支持协议系统控制和生态系统访问功能示意图系统框图跳线设置开发板原理图 所用器件 所使用的器件是我们自行设计的开发板,该开发板是基于 STM32WB55 系列微控制器所构建。STM32WBXX_VFQFPN68 不仅是一款评…...

CUDA相关知识科普
显卡 显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。就像电脑联网需要网卡,主机里的数据要显示在屏幕上就需要显卡。因此,显卡是电脑进…...

恒运资本:总市值和总资产区别?
总市值和总财物是财政术语中经常被提到的两个概念,很多人会将它们混淆。在金融领域中,了解这两个概念的差异十分重要。本文将从多个视点深入分析总市值和总财物的差异。 1.定义 总市值是指公司发行的一切股票的商场总价值。所谓商场总价值…...

CTF安全竞赛介绍
目录 一、赛事简介 二、CTF方向简介 1.Web(Web安全) (1)简介 (2)涉及主要知识 2.MISC(安全杂项) (1)介绍 (2)涉及主要知识 3…...

DC/DC开关电源学习笔记(四)开关电源电路主要器件及技术动态
(四)开关电源电路主要器件及技术动态 1.半导体器件2.变压器3.电容器4.功率二极管5.其他常用元件5.1 电阻5.2 电容5.3 电感5.4 变压器5.5 二极管5.6 整流桥5.7 稳压管5.8 绝缘栅-双极性晶体管1.半导体器件 功率半导体器件仍然是电力电子技术发展的龙头, 电力电子技术的进步必…...
数据可视化与数字孪生:理解两者的区别
在数字化时代,数据技术正在引领创新,其中数据可视化和数字孪生是两个备受关注的概念。尽管它们都涉及数据的应用,但在本质和应用方面存在显著区别。本文带大探讨数据可视化与数字孪生的差异。 概念 数据可视化: 数据可视化是将复…...
)
C++ socket编程(TCP)
服务端保持监听客户端, 服务端采用select实现,可以监听多个客户端 客户端源码 在这里插入代码片 #include <iostream> //#include <windows.h> #include <WinSock2.h> #include <WS2tcpip.h> using namespace std; #pragma co…...

ldd用于打印程序或库文件所依赖的共享库列表
这是一个Linux命令行指令,将两个常用的命令 ldd 和 grep 组合使用。我来逐一为您解释: ldd: 这是一个Linux工具,用于打印程序或库文件所依赖的共享库列表。通常,当你有一个可执行文件并且想知道它链接到哪些动态库时,你…...
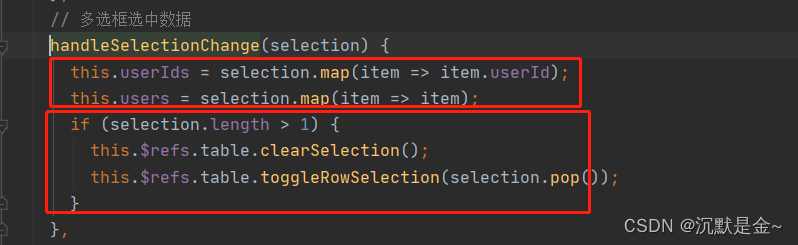
vue+elementUI el-table实现单选
if (selection.length > 1) {this.$refs.table.clearSelection();this.$refs.table.toggleRowSelection(selection.pop());}...
前端组件库造轮子——Message组件开发教程
前端组件库造轮子——Message组件开发教程 前言 本系列旨在记录前端组件库开发经验,我们的组件库项目目前已在Github开源,下面是项目的部分组件。文章会详细介绍一些造组件库轮子的技巧并且最后会给出完整的演示demo。 文章旨在总结经验,开…...
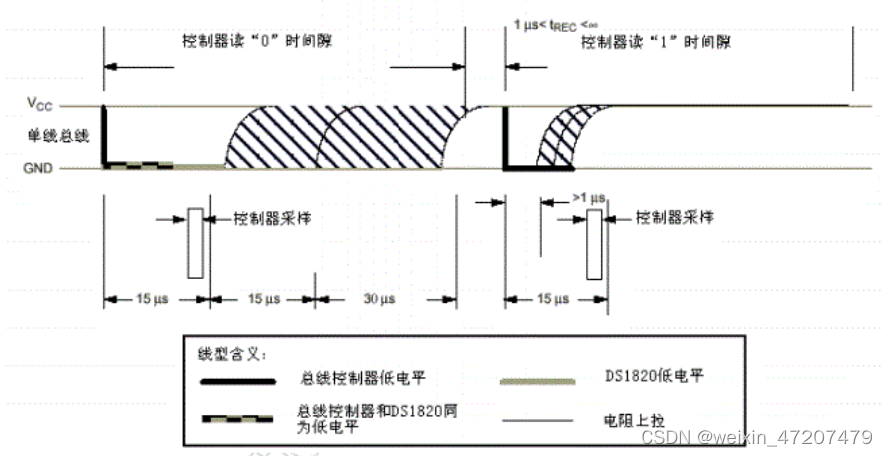
单片机第二季:温度传感器DS18B20
目录 1,DS18B20介绍 2,DS18B20数据手册 2.1,初始化时序 2.2,读写时序 3,DS18B20工作流程 4,代码 1,DS18B20介绍 DS18B20的基本特征: (1)内置集成ADC,外部数字接…...

抓包工具fiddler的基础知识
目录 简介 1、作用 2、使用场景 3、http报文分析 3.1、请求报文 3.2、响应报文 4、介绍fiddler界面功能 4.1、AutoResponder(自动响应器) 4.2、Composer(设计请求) 4.3、断点 4.4、弱网测试 5、app抓包 简介 fiddler是位于客户端和服务端之间的http代理 1、作用 监控浏…...

监控基本概念
监控:这个词在不同的上下文中有不同的含义,在讲到监控MySQL或者监控Redis时,这里只涉及数据采集和可视化,不涉及告警引擎和事件处理。要是监控系统的话,不但包括数据采集和可视化,而且也包括告警和事件发送…...

【数据结构】 七大排序详解(壹)——直接插入排序、希尔排序、选择排序、堆排序
文章目录 🍀排序的概念及引用🐱👤排序的概念🐱👓排序运用🐱🐉常见的排序算法 🌴插入排序🎋基本思想:🛫直接插入排序📌算法步骤&…...
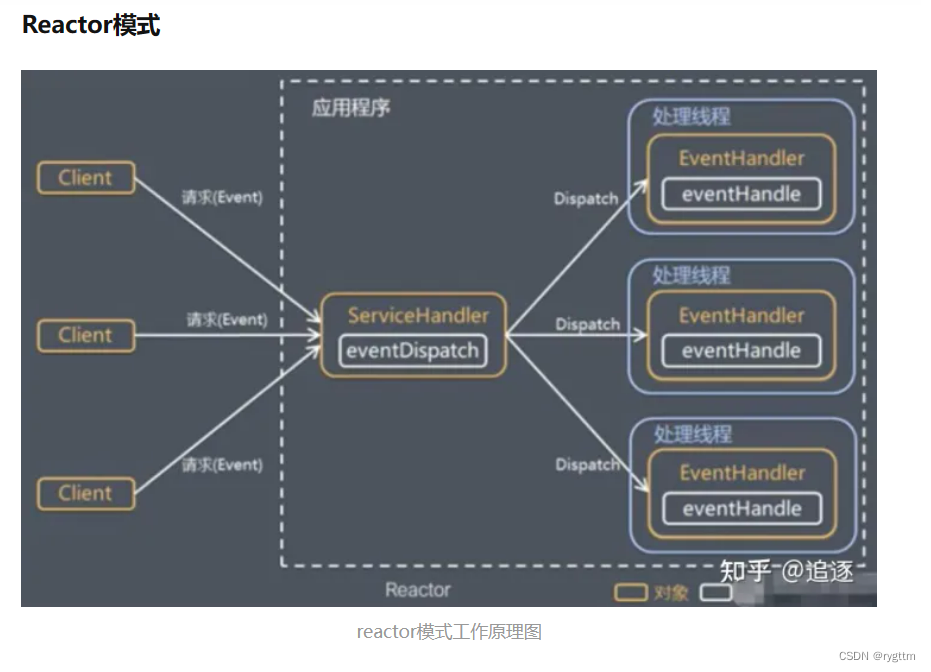
【Linux】高级IO --- Reactor网络IO设计模式
人其实很难抵制诱惑,人只能远离诱惑,所以千万不要高看自己的定力。 文章目录 一、LT和ET模式1.理解LT和ET的工作原理2.通过代码来观察LT和ET工作模式的不同3.ET模式高效的原因(fd必须是非阻塞的)4.LT和ET模式使用时的读取方式 二…...
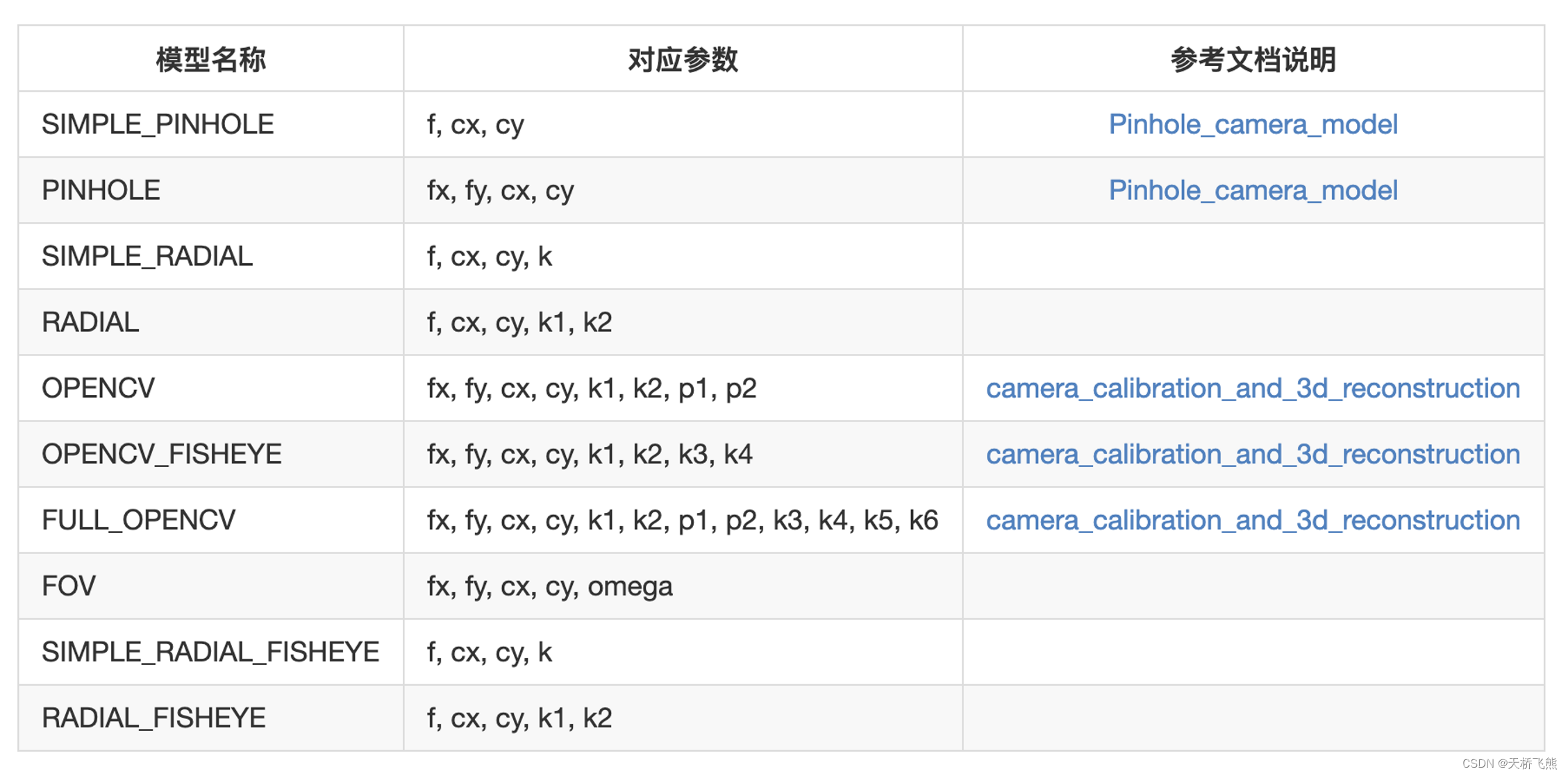
Agisoft Metashape相机标定笔记
Lens Calibration(镜头标定) 使用Metashape进行自动相机标定是可能的。Metashape使用LCD显示屏作为标定目标(可选:使用打印的棋盘格图案,但需保证它是平坦的且单元格是正方形)。 相机标定步骤支持全相机标定矩阵的估计ÿ…...

vue-cropper在ie11下选择本地图片后,无显示、拒绝访问的问题
问题:vue-cropper在ie11下选择本地图片后,网页上并未显示出图片,打开F12有报错:拒绝访问blabla的。但是在chrome下一切正常。 开发环境:node14.17.5 , vue2 , vue-cropper0.6.2 , macOS big sur 11.4(M1). 解决办法&…...

041二叉树的层序遍历
二叉树的层序遍历 题目链接:https://leetcode.cn/problems/binary-tree-level-order-traversal/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public List<List<Integer>> levelOrder(TreeNode root) {List<Lis…...
Transformer与NLP资源全指南:从原理到工程实践的高效学习路径
1. 项目概述:为什么我们需要一个Transformer与NLP的“Awesome”清单?如果你在过去几年里深度参与过自然语言处理(NLP)领域的工作或学习,那么“Transformer”这个词对你来说,可能已经从一种新颖的架构&#…...

透明背景图片制作方法全解析:2026年最实用的免费抠图工具推荐
最近有个朋友问我,怎样快速把商品照片的背景去掉,做电商上传用。我才意识到,很多人其实都被"透明背景图片制作方法"这个问题困扰着——无论是证件照换底色、商品图去背景,还是做设计素材,都需要一个趁手的抠…...

使用Python快速接入Taotoken并切换不同模型进行对话测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Python快速接入Taotoken并切换不同模型进行对话测试 本文面向希望快速上手Taotoken平台的Python开发者。我们将通过一份最小化…...

为内部工具集成AI能力时下载Taotoken作为统一接口层的方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成AI能力时采用Taotoken作为统一接口层的方案 在为企业内部工具(如数据分析平台、客服辅助系统或内容生成…...

虚拟机开发环境中如何通过Taotoken管理多个项目的API Key与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 虚拟机开发环境中如何通过Taotoken管理多个项目的API Key与用量 应用场景类,开发者在同一虚拟机中维护多个不同项目&am…...

ARIS:基于技能化工作流的AI自主研究系统设计与实践
1. 项目概述:ARIS,一个让AI在你睡觉时做研究的自主工作流 如果你是一名机器学习或计算机科学领域的研究者,我猜你肯定有过这样的体验:一个绝妙的想法在深夜闪现,你兴奋地爬起来记下几行潦草的笔记,然后第二…...

热销榜单:2026年深圳App开发公司推荐,揪出大众推荐的五大高口碑产品
在2026年、深圳的App开发公司凭借其创新能力逐渐崭露头角。在这个市场中解决方案、从电商到物联网设计美学赢得了用户信任;而本凡码农科技则专注于小程序定制、满足市场对便捷应用的追求。还有、云码科技伴随着创新技术提供了更高等灵活性,而晨曦科技结合…...
)
别再手动数脉冲了!用STM32定时器编码器模式搞定增量编码器(附CubeMX配置)
STM32硬件编码器模式实战:精准捕获增量编码器信号的工程指南 在电机控制、机器人关节定位和精密测量系统中,增量式编码器作为核心反馈元件,其信号处理质量直接影响整个系统的控制精度。传统的中断计数方式在高速脉冲场景下往往捉襟见肘&#…...

Boss-Key终极指南:5分钟掌握办公隐私保护神器的一键隐藏窗口技巧
Boss-Key终极指南:5分钟掌握办公隐私保护神器的一键隐藏窗口技巧 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办公…...