【100天精通Python】Day57:Python 数据分析_Pandas数据描述性统计,分组聚合,数据透视表和相关性分析
目录
1 描述性统计(Descriptive Statistics)
2 数据分组和聚合
3 数据透视表
4 相关性分析
1 描述性统计(Descriptive Statistics)
描述性统计是一种用于汇总和理解数据集的方法,它提供了关于数据分布、集中趋势和离散度的信息。Pandas 提供了 describe() 方法,它可以生成各种描述性统计信息,包括均值、标准差、最小值、最大值、四分位数等。以下是详细的描述性统计示例:
首先,假设你有一个包含一些学生考试成绩的 DataFrame:
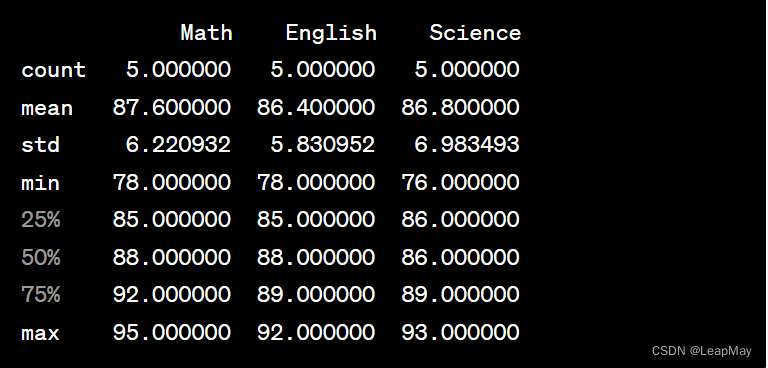
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],'Math': [85, 92, 78, 88, 95],'English': [78, 85, 89, 92, 88],'Science': [90, 86, 76, 93, 89]}df = pd.DataFrame(data)# 使用 describe() 方法生成描述性统计信息
description = df.describe()# 输出结果
print(description)输出结果将会是:
2 数据分组和聚合
数据分组和聚合是数据分析中常用的操作,用于根据某些特征将数据分组,并对每个分组应用聚合函数,以便获得有关每个组的统计信息。在 Pandas 中,你可以使用 groupby() 方法来实现数据分组,然后使用各种聚合函数对分组后的数据进行计算。以下是详细的示例和解释:
假设你有一个包含不同城市销售数据的 DataFrame:
import pandas as pddata = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Los Angeles'],'Sales': [1000, 750, 800, 1200, 900, 850]}df = pd.DataFrame(data)# 使用 groupby() 方法按城市分组
grouped = df.groupby('City')# 对每个组应用聚合函数(例如,计算平均销售额)
result = grouped['Sales'].mean()# 输出结果
print(result)使用 groupby() 方法将数据按城市分组,并对每个城市的销售数据进行聚合:
输出结果:

在这个示例中,我们首先使用
groupby()方法按城市分组,然后对每个城市的销售数据应用了mean()聚合函数。结果中包含了每个城市的平均销售额。
你还可以应用其他聚合函数,如 sum()、max()、min() 等,以获取更多信息。例如,你可以计算每个城市的总销售额:
total_sales = grouped['Sales'].sum()
除了单个聚合函数外,你还可以同时应用多个聚合函数,并将结果合并到一个 DataFrame 中。这可以通过 agg() 方法来实现:
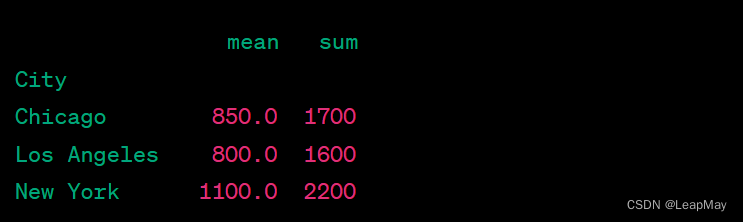
import pandas as pddata = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Los Angeles'],'Sales': [1000, 750, 800, 1200, 900, 850]}df = pd.DataFrame(data)# 使用 groupby() 方法按城市分组
grouped = df.groupby('City')# 同时计算平均销售额和总销售额,并将结果合并到一个 DataFrame 中
result = grouped['Sales'].agg(['mean', 'sum'])# 输出结果
print(result)
输出结果:
3 数据透视表
数据透视表是一种用于对数据进行多维度汇总和分析的工具。在 Pandas 中,你可以使用 pivot_table() 函数来创建数据透视表。下面是一个详细的数据透视表示例:
假设你有一个包含销售数据的 DataFrame:
import pandas as pddata = {'Date': ['2023-09-01', '2023-09-01', '2023-09-02', '2023-09-02', '2023-09-03'],'Product': ['A', 'B', 'A', 'B', 'A'],'Sales': [1000, 750, 1200, 800, 900]}df = pd.DataFrame(data)
现在,假设你想要创建一个数据透视表,以便查看每个产品每天的总销售额。你可以使用 pivot_table() 来实现这个目标:
# 创建数据透视表,以Date为行索引,Product为列,计算总销售额
pivot = df.pivot_table(index='Date', columns='Product', values='Sales', aggfunc='sum')# 输出结果
print(pivot)
输出结果:

在这个示例中,我们使用了
pivot_table()函数,将 "Date" 列作为行索引,"Product" 列作为列,并计算了每个组合的销售额之和。结果是一个数据透视表,它以日期为行,以产品为列,每个单元格中包含了对应日期和产品的销售额。如果某个日期没有某个产品的销售数据,相应的单元格将显示为 NaN(Not a Number)。你还可以在
aggfunc参数中指定其他聚合函数,例如 'mean'、'max'、'min' 等,以根据你的需求生成不同类型的数据透视表。
4 相关性分析
相关性分析是用来确定两个或多个变量之间关系的统计方法,通常用于了解它们之间的相关程度和方向。在 Pandas 中,你可以使用 corr() 方法来计算相关性系数(如 Pearson 相关系数)来衡量两个数值列之间的相关性。以下是相关性分析的详细示例和解释:
假设你有一个包含两个数值列的 DataFrame,表示学生的数学和英语成绩:
import pandas as pddata = {'Math': [85, 92, 78, 88, 95],'English': [78, 85, 89, 92, 88]}df = pd.DataFrame(data)
接下来,你可以使用 corr() 方法来计算这两个列之间的相关性:
# 使用 corr() 方法计算数学和英语成绩之间的相关性
correlation = df['Math'].corr(df['English'])# 输出结果
print("Correlation between Math and English scores:", correlation)
输出结果:

在这个示例中,我们使用了
corr()方法计算了数学和英语成绩之间的相关性系数。相关性系数的值范围从 -1 到 1,其中:
- 1 表示完全正相关:当一个变量增加时,另一个变量也增加,变化方向相同。
- 0 表示无相关性:两个变量之间没有线性关系。
- -1 表示完全负相关:当一个变量增加时,另一个变量减少,变化方向相反。
相关文章:
【100天精通Python】Day57:Python 数据分析_Pandas数据描述性统计,分组聚合,数据透视表和相关性分析
目录 1 描述性统计(Descriptive Statistics) 2 数据分组和聚合 3 数据透视表 4 相关性分析 1 描述性统计(Descriptive Statistics) 描述性统计是一种用于汇总和理解数据集的方法,它提供了关于数据分布、集中趋势和…...

Unity 切换场景后场景变暗
问题 Unity版本:2019.4.34f1c1 主场景只有UI,没有灯光,天空盒;其他场景有灯光和天空盒所有场景不烘焙主场景作为启动场景运行,切换到其他场景,场景变暗某一个场景作为启动场景运行,光影效果正…...
RabbitMQ学习笔记
1、什么是MQ? MQ全称message queue(消息队列),本质是一个队列,FIFO先进先出,是消息传送过程中保存消息的容器,多 用于分布式系统之间进行通信。 在互联网架构中,MQ是一种非常常见的…...

【C# Programming】类、构造器、静态成员
一、类 1、类的概念 类是现实世界概念的抽象:封装、继承、多态数据成员: 类中存储数据的变量成员方法: 类中操纵数据成员的函数称为成员方法对象:类的实例类定义 class X {…} var instance new X(…); 2、实例字段 C#中…...

软件层面缓存基本概念与分类
缓存 缓存基本概念(百度百科) 缓存(cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快…...

单片机有哪些分类?
单片机有哪些分类? 1.AVR单片机-----速度快,一个时钟周期执行一条指令,而普通的51单片机需要12个时钟周期执行一条指令。当然,Atmel公司出品的AT89LP系列单片机也是一个时钟执行一条指令,但目前还未普及。AVR单片机比51单片机多…...

高阶数据结构-----三种平衡树的实现以及原理(未完成)
TreeMap和TreeSet的底层实现原理就是红黑树 一)AVL树: 1)必须是一棵搜索树:前提是二叉树,任取一个节点,它的左孩子的Key小于父亲节点的Key小于右孩子节点的Key,中序遍历是有序的,按照Key的大小进行排列,高度平衡的二叉…...

北斗高精度组合导航终端
UWB(Ultra-Wideband)、卫星定位(GNSS),以及IMU(Inertial Measurement Unit)的组合定位系统结合了多种传感器和定位技术,以提供高精度、高可靠性的位置估计。这种组合定位系统在各种应…...

低代码平台是否能替代电子表格?
在计算机技术普及之前,会计、助理或者是销售人员,都需要用纸和笔来记录和维护每一笔交易。计算机技术兴起之后,一项技术发明——电子表格的出现改变了低效的状况。电子表格的第一个版本出现在1977年,一个名为“VisiCalc”的程序。…...

qt多个信号如何关联一并处理
主要方法: 首先,需要创建一个包含自定义信号和槽的Qt类。假设要创建一个名为MyObject的类,并在其中定义一个自定义信号和一个槽。这个类的头文件可能如下所示: #ifndef MYOBJECT_H #define MYOBJECT_H#include <QObject>c…...
【python爬虫】12.建立你的爬虫大军
文章目录 前言协程是什么多协程的用法gevent库queue模块 拓展复习复习 前言 照旧来回顾上一关的知识点!上一关我们学习如何将爬虫的结果发送邮件,和定时执行爬虫。 关于邮件,它是这样一种流程: 我们要用到的模块是smtplib和emai…...

2023数学建模国赛C题思路--蔬菜类商品的自动定价与补货决策
C 题 蔬菜类商品的自动定价与补货决策 在生鲜商超中,一般蔬菜类商品的保鲜期都比较短,且品相随销售时间的增加而变差, 大部分品种如当日未售出,隔日就无法再售。因此,商超通常会根据各商品的历史销售和需 求情况每天进…...

vue2与vue3的使用区别
1. 脚手架创建项目的区别: vue2: vue init webpack “项目名称”vue3: vue create “项目名称” 或者vue3一般与vite结合使用: npm create vitelatest yarn create vite2. template中结构 vue2: template下只有一个元素节点 <template><div><div…...
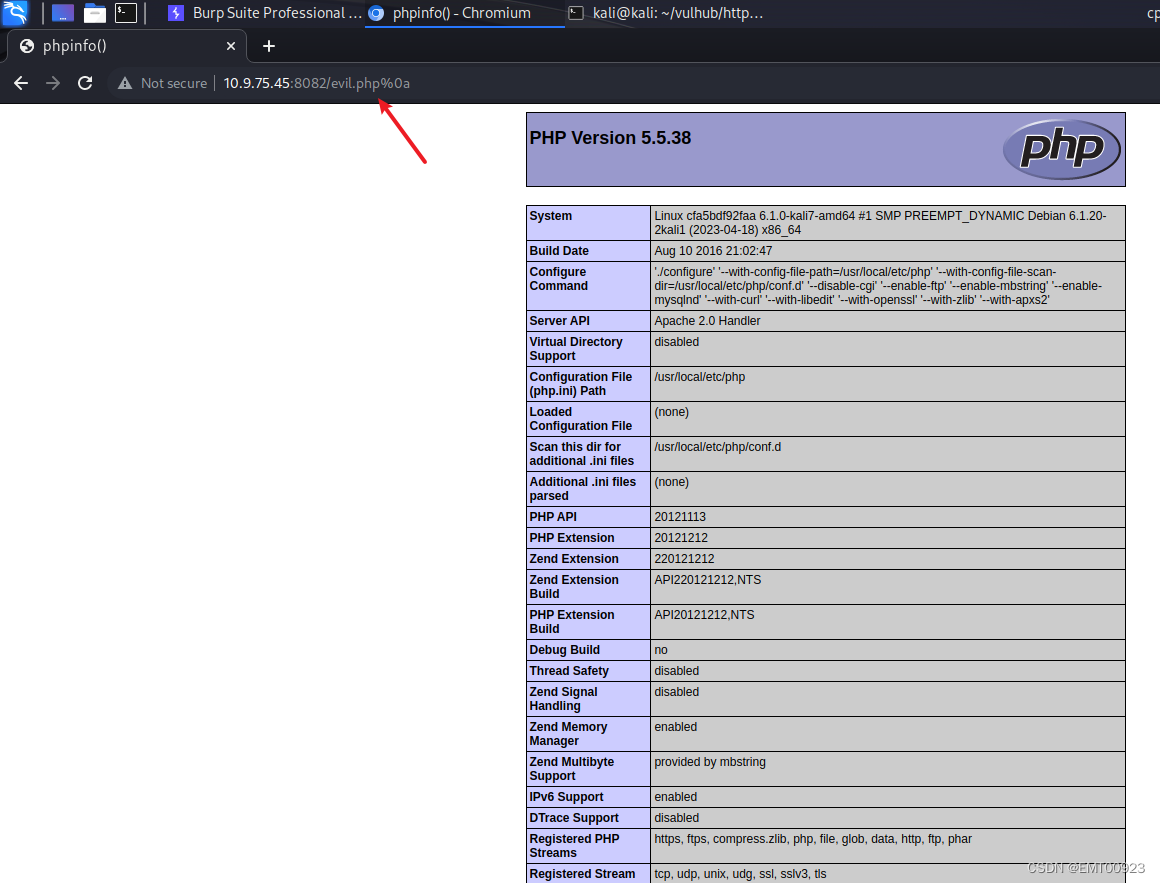
Apache httpd漏洞复现
文章目录 未知后缀名解析漏洞多后缀名解析漏洞启动环境漏洞复现 换行解析漏洞启动环境漏洞复现 未知后缀名解析漏洞 该漏洞与Apache、php版本无关,属于用户配置不当造成的解析漏洞。在有多个后缀的情况下,只要一个文件含有.php后缀的文件即将被识别成PHP…...
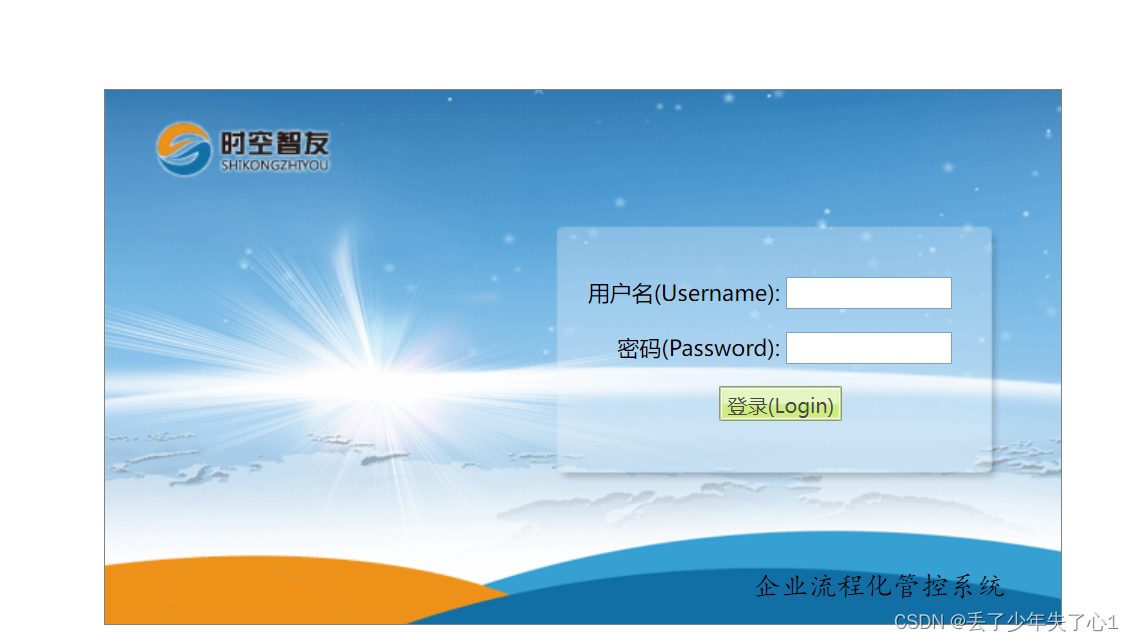
【漏洞复现】时空智友企业流程化管控系统文件上传
漏洞描述 通过时空智友该系统,可让企业实现流程的自动化、协同上提升、数据得洞察及决策得优化,来提高工作效率、管理水平及企业的竞争力。时空智友企业流程化 formservice接口处存有任意文件上传漏洞,未经认证得攻击者可利用此接口上传后门程序,可导致服务器失陷。 免责…...
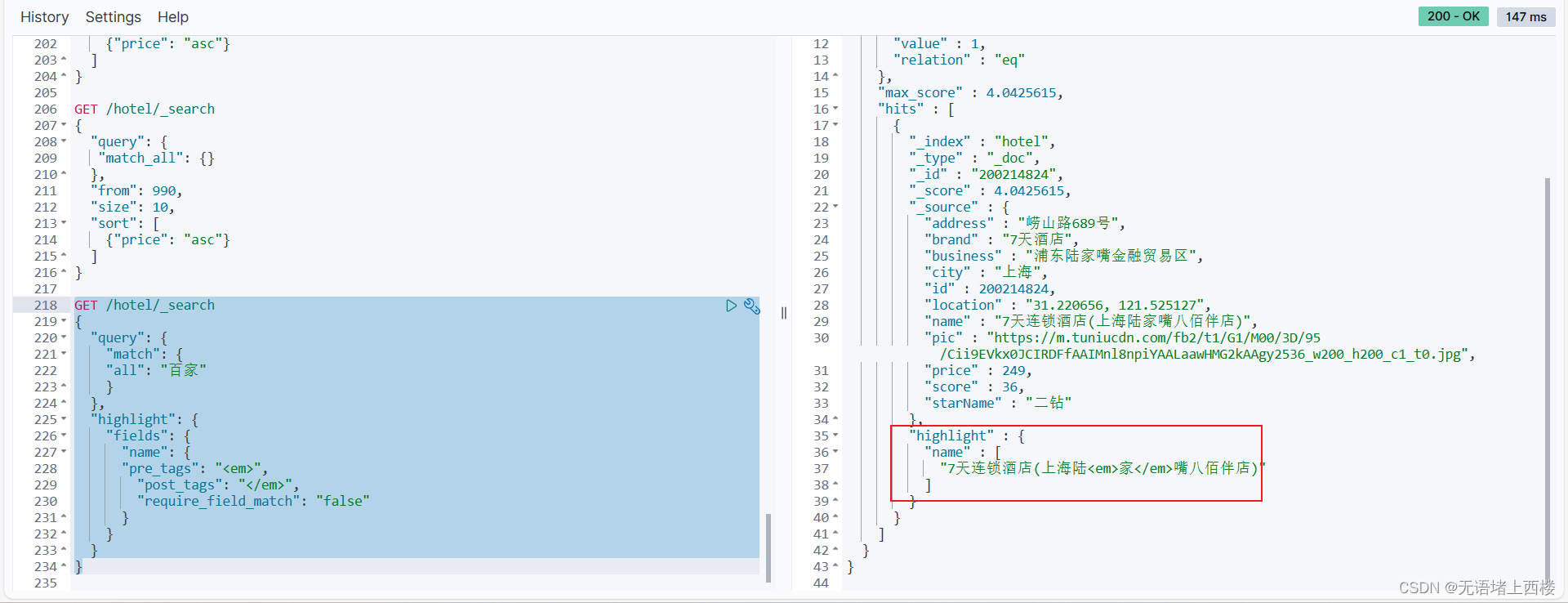
elasticsearch的DSL查询文档
DSL查询分类 查询所有:查询出所有数据,一般测试用。例如:match_all 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如: match_query multi_ma…...
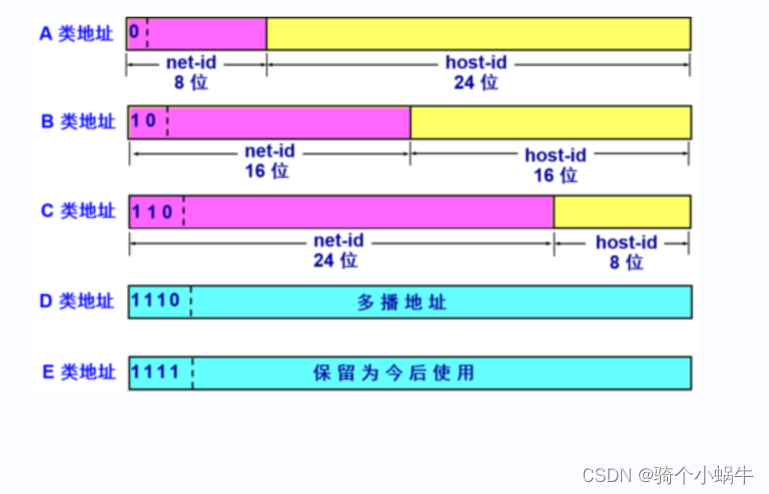
IP地址、子网掩码、网络地址、广播地址、IP网段
文章目录 IP地址IP地址分类子网掩码网络地址广播地址IP网段 本文主要讨论iPv4地址。 IP地址 实际的 IP 地址是一串32 比特的数字,按照 8 比特(1 字节)为一组分成 4 组,分别用十进制表示然后再用圆点隔开,这就是我们平…...
ffmpeg-android studio创建jni项目
一、创建native项目 1.1、选择Native C 1.2、命名项目名称 1.3、选择C标准 1.4、项目结构 1.5、app的build.gradle plugins {id com.android.application }android {compileSdk 32defaultConfig {applicationId "com.anniljing.ffmpegnative"minSdk 25targetSdk 32…...

智慧公厕是将数据、技术、业务深度融合的公共厕所敏捷化“操作系统”
文明社会的进步离不开公共设施的不断创新和提升。而在这些公共设施中,公共厕所一直是一个备受关注和改善的领域。近年来,随着智慧城市建设的推进,智慧公厕成为了城市管理的重要一环。智慧公厕不仅仅是为公众提供方便和舒适的便利设施…...
JVM中JAVA对象和数组内存布局
对象 数组 在Java中,所有的对象都是一种特殊的数组,它们的元素可以是基本数据类型、其他对象引用或者其他任何类型。Java对象和数组的内存布局包含以下部分: 1.对象头(Object Header) 每个Java对象都有一个对象头&am…...

VideoDownloadHelper:打破视频下载壁垒的智能浏览器插件
VideoDownloadHelper:打破视频下载壁垒的智能浏览器插件 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 在信息爆炸的时代&#x…...

5分钟快速上手:Akagi麻将AI助手完整实战指南
5分钟快速上手:Akagi麻将AI助手完整实战指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City, Amatsuki, with…...

终极指南:如何用Edgar-Unity打造无限变化的2D地牢世界
终极指南:如何用Edgar-Unity打造无限变化的2D地牢世界 【免费下载链接】Edgar-Unity Unity Procedural Level Generator 项目地址: https://gitcode.com/gh_mirrors/ed/Edgar-Unity 还在为每个关卡的手工设计而烦恼吗?是否梦想着让你的游戏地图能…...

Docker 入门完全指南
Docker 入门完全指南 容器这东西,用上了就回不去了。比虚拟机轻,比装环境快,一套走天下。 先搞清楚几个概念 镜像(Image):只读模板,类似装系统的ISO容器(Container)&…...

二维紧束缚模型与量子电路映射技术详解
1. 二维紧束缚模型基础理论 紧束缚模型(Tight-Binding Model)是描述电子在周期性晶体场中运动行为的核心理论框架。这个模型的基本物理图像是:电子大部分时间被束缚在原子核附近,只有少量时间会隧穿到相邻原子轨道。在二维系统中&…...
)
STM32CubeMX配置SPI驱动W25Q128实战:从硬件连接到DMA优化(附完整代码)
STM32CubeMX配置SPI驱动W25Q128实战:从硬件连接到DMA优化 在嵌入式开发中,SPI接口的Flash存储器因其高速、简单和可靠的特点,成为存储配置数据、日志和固件的理想选择。W25Q128作为Winbond公司推出的128Mbit串行Flash存储器,广泛…...

2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解
2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解 智能侦查赛道概述 2025 睿抗机器人大赛智能侦察赛道是 CAIR 工程竞技赛道下的专业国防装备赛项,以无人侦察车为载体、模拟巷战环境开展军事侦察任务,核心培养学生国防意识与科技创新能力且核心硬件…...

视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单
视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含…...

2026 大模型企业画像梳理技术解析:混乱画像规范方法深度测评
引言随着 AI 搜索成为商业信息获取的主要渠道,大模型生成的企业画像准确性直接影响企业品牌形象和获客效果。据中国 GEO 行业协会 2026 年调研数据显示,超过 76% 的企业反映大模型生成的企业画像存在信息混乱、错误遗漏、业务不匹配等问题,其…...

嵌入式核心板选型与开发实战:M28x-T与M6G2C硬件设计及AWorks平台应用
1. 项目概述:为什么我们需要“一体化”核心板?在嵌入式产品开发,尤其是工业控制、数据采集这类对稳定性和开发效率要求极高的领域,很多工程师都经历过一个痛苦的过程:选型一颗主控MCU,然后围绕它去设计DDR内…...