python-爬虫-xpath方法-批量爬取王者皮肤图片
import requests
from lxml import etree
获取NBA成员信息
# 发送的地址
url = 'https://nba.hupu.com/stats/players'
# UA 伪装 google
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}
r = requests.get(url)
# print(r.text) # jupyter 打印可以看到格式化的html数据
# 将HTML文本解析成Element对象
e = etree.HTML(r.text)
players = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[2]/a/text()')
teams = e.xpath('//*[@id="data_js"]/div[4]/div/table/tbody/tr/td[3]/a/text()')
# 保存到txt文件
with open('nba.txt','w',encoding='utf-8') as f:for player,team in zip(players,teams):f.write(f'球员:{player} - - - 球队:{team}\n')
球员:乔尔-恩比德 - - - 球队:76人
球员:卢卡-东契奇 - - - 球队:独行侠
球员:达米安-利拉德 - - - 球队:开拓者
批量爬取王者荣耀皮肤图片
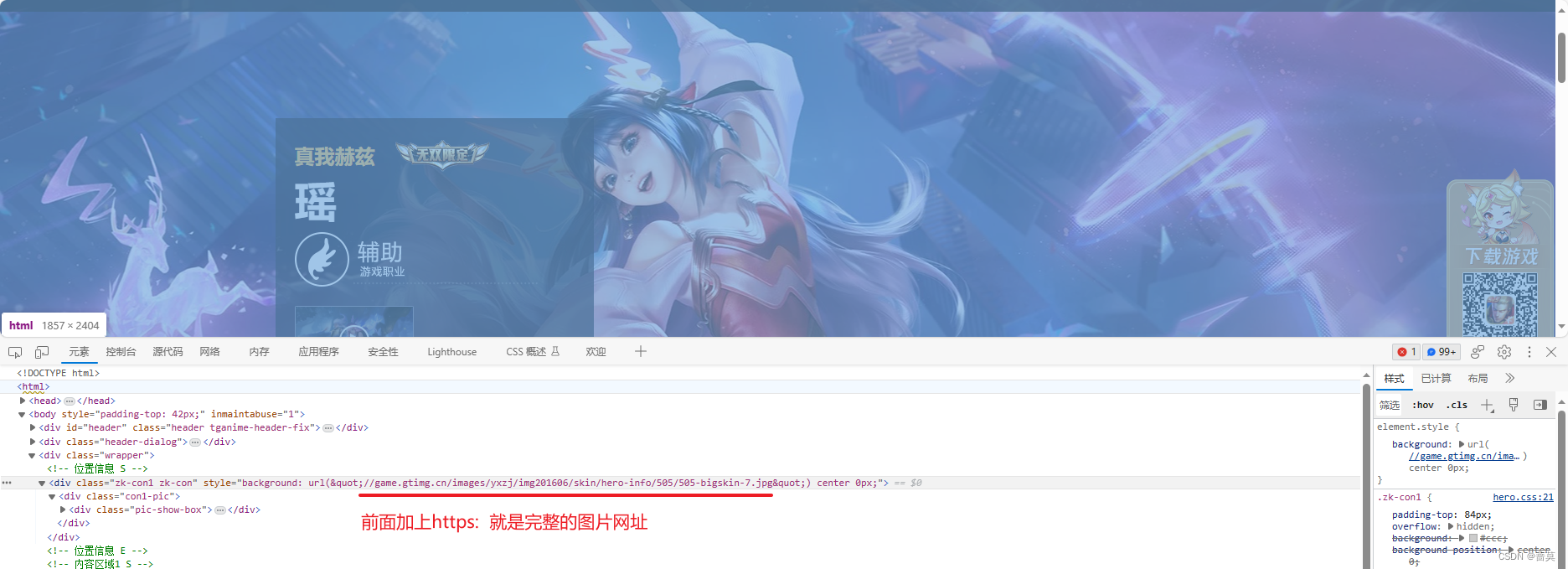
- 爬取一张图片
url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/505/505-bigskin-7.jpg'
r = requests.get(url)
# 保存图片
# w write b 二进制
with open('a.jpg','wb') as f:f.write(r.content)

- 该角色有7个皮肤 爬取7个图片
for i in range(1,8):url = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/505/505-bigskin-{i}.jpg'r = requests.get(url)with open(f'{i}.jpg','wb') as f:f.write(r.content)
- 获取这7个皮肤的名字 保存图片
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'
}
url = 'https://pvp.qq.com/web201605/herodetail/505.shtml'
r = requests.get(url,headers=headers)
r.encoding='gbk'
e = etree.HTML(r.text)
# e.xpath 返回一个列表 使用索引[0]变为str
names = e.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0] # '鹿灵守心&0|森&0|遇见神鹿&71|时之祈愿&94|时之愿境&42|山海·碧波行&109|真我赫兹&117'
# names.split('|') # split只能用于str,不能用于list # ['鹿灵守心&0', '森&0', '遇见神鹿&71', '时之祈愿&94', '时之愿境&42', '山海·碧波行&109', '真我赫兹&117']
names = [name[0:name.index('&')] for name in names.split('|')] # ['鹿灵守心', '森', '遇见神鹿', '时之祈愿', '时之愿境', '山海·碧波行', '真我赫兹']
for i,n in enumerate(names):url = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/505/505-bigskin-{i+1}.jpg'r = requests.get(url)with open(f'{n}.jpg','wb') as f:f.write(r.content)

- 获取所有英雄皮肤
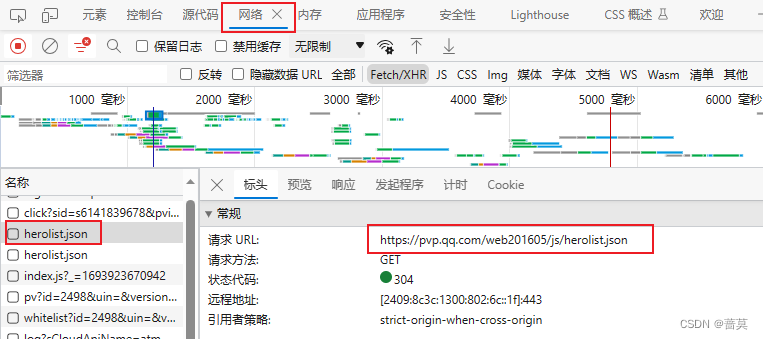
把该行网址复制到网址栏,会自动下载该文件
https://pvp.qq.com/web201605/js/herolist.json
该文件内容如下,有英雄的各种信息
每个花括号 { } 是一个json数据

import requests
from lxml import etree
import os
from time import sleepheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'
}
url = 'https://pvp.qq.com/web201605/js/herolist.json'
r = requests.get(url,headers=headers)
for x in r.json():ename = x.get('ename') # 数字 url里面变化的那个数字cname = x.get('cname') # 英雄的名字if not os.path.exists(cname):os.makedirs(cname)urlone = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'r = requests.get(url=urlone,headers=headers)r.encoding='gbk'e = etree.HTML(r.text)# e.xpath 返回一个列表 使用索引[0]变为strnames = e.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0] # '鹿灵守心&0|森&0|遇见神鹿&71|时之祈愿&94|时之愿境&42|山海·碧波行&109|真我赫兹&117'# names.split('|') # split只能用于str,不能用于list # ['鹿灵守心&0', '森&0', '遇见神鹿&71', '时之祈愿&94', '时之愿境&42', '山海·碧波行&109', '真我赫兹&117']names = [name[0:name.index('&')] for name in names.split('|')] # ['鹿灵守心', '森', '遇见神鹿', '时之祈愿', '时之愿境', '山海·碧波行', '真我赫兹']for i,n in enumerate(names):url = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{i+1}.jpg'r = requests.get(url)with open(f'{cname}/{n}.jpg','wb') as f:f.write(r.content) print(f'{n}已下载')sleep(1)
部分图片展示
xpath分析

//ul[@class=“pic-pf-list pic-pf-list3”]/@data-imgname
asd = '鹿灵守心&0'
asd.index('心') # 3 # 心在index3的位置
<generator object at 0x0000029394AFACF0> 迭代器 在最左和最右加上方括号[ ]就会变成str
os.makedirs and os.mkdir
os.makedirs和os.mkdir都是用于创建目录的函数,但有以下区别:
-
os.mkdir只能创建一级目录,而os.makedirs可以同时创建多级目录。
-
如果要创建的目录已经存在,os.mkdir会抛出FileExistsError异常,而os.makedirs不会抛出异常。
-
os.makedirs还可以通过设置exist_ok参数来控制是否抛出异常。如果exist_ok为True,表示即使目录已经存在也不会抛出异常,如果为False,则会抛出异常。
示例代码:
import os# 创建单级目录
os.mkdir('dir1')
# 创建多级目录
os.makedirs('dir2/subdir1/subdir2')# 创建已存在的目录
os.mkdir('dir1') # 会抛出异常
os.makedirs('dir2/subdir1/subdir2') # 不会抛出异常# 创建已存在的目录时,设置exist_ok参数
os.makedirs('dir2/subdir1/subdir2', exist_ok=True) # 不会抛出异常
os.makedirs('dir2/subdir1/subdir2', exist_ok=False) # 会抛出异常
xpath工具
# 将HTML文档加载进来
html = etree.parse('demo.html')# 将HTML文档解析成Element对象
root = html.getroot()
Python爬虫中,使用xpath提取HTML或XML文档中的元素是非常常见的操作。下面是etree库中xpath常用的方法:
-
xpath():在文档中使用xpath表达式进行查找,返回匹配的元素列表。 -
find():在文档中查找匹配xpath表达式的第一个元素,返回元素对象。 -
findall():在文档中查找匹配xpath表达式的所有元素,返回元素对象列表。 -
text属性:获取元素的文本内容。 -
attrib属性:获取元素的属性。 -
get()方法:获取指定属性的值。 -
iter()方法:获取文档中所有匹配xpath表达式的元素,返回迭代器对象。 -
Element()方法:创建一个新的元素对象。 -
SubElement()方法:在指定元素下创建一个新的子元素。 -
ElementTree()方法:创建一个新的XML文档树对象。
以上这些方法是在使用xpath提取HTML或XML文档中的元素时经常使用的方法,掌握了这些方法,就可以方便地对文档进行操作了。
相关文章:
python-爬虫-xpath方法-批量爬取王者皮肤图片
import requests from lxml import etree获取NBA成员信息 # 发送的地址 url https://nba.hupu.com/stats/players # UA 伪装 google header {User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.3…...
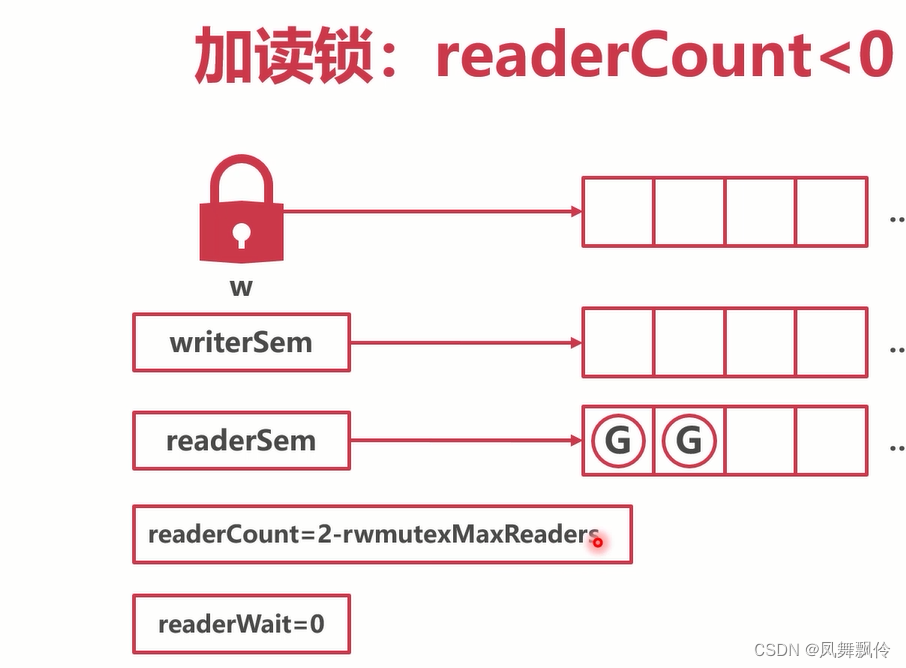
go锁--读写锁
每个锁分为读锁和写锁,写锁互斥 没有加写锁时,多个协程都可以加读锁 加了写锁时,无法加读锁,读协程排队等待 加了读锁,写锁排队等待 Mutex用来写协程之间互斥等待 读协程使用readerSem等待写锁的释放 写协程使用writer…...

Unity中Shader的屏幕坐标
文章目录 前言一、屏幕坐标1、屏幕像素的坐标2、屏幕坐标归一化 二、在Unity中获取 当前屏幕像素 和 总像素1、获取屏幕总像素,使用_ScreenParams参数2、获取当前片段上的像素怎么使用:在片元着色器传入参数时使用 前言 Unity中Shader的屏幕坐标 一、屏幕坐标 1、屏幕像素的坐…...

springboot MongoDB 主从 多数据源
上一篇,我写了关于用一个map管理mongodb多个数据源(每个数据源,只有单例)的内容。 springboot mongodb 配置多数据源 临到部署到阿里云的测试环境,发现还需要考虑一下主从的问题,阿里云买的数据库&#x…...

【100天精通Python】Day57:Python 数据分析_Pandas数据描述性统计,分组聚合,数据透视表和相关性分析
目录 1 描述性统计(Descriptive Statistics) 2 数据分组和聚合 3 数据透视表 4 相关性分析 1 描述性统计(Descriptive Statistics) 描述性统计是一种用于汇总和理解数据集的方法,它提供了关于数据分布、集中趋势和…...

Unity 切换场景后场景变暗
问题 Unity版本:2019.4.34f1c1 主场景只有UI,没有灯光,天空盒;其他场景有灯光和天空盒所有场景不烘焙主场景作为启动场景运行,切换到其他场景,场景变暗某一个场景作为启动场景运行,光影效果正…...
RabbitMQ学习笔记
1、什么是MQ? MQ全称message queue(消息队列),本质是一个队列,FIFO先进先出,是消息传送过程中保存消息的容器,多 用于分布式系统之间进行通信。 在互联网架构中,MQ是一种非常常见的…...

【C# Programming】类、构造器、静态成员
一、类 1、类的概念 类是现实世界概念的抽象:封装、继承、多态数据成员: 类中存储数据的变量成员方法: 类中操纵数据成员的函数称为成员方法对象:类的实例类定义 class X {…} var instance new X(…); 2、实例字段 C#中…...

软件层面缓存基本概念与分类
缓存 缓存基本概念(百度百科) 缓存(cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快…...

单片机有哪些分类?
单片机有哪些分类? 1.AVR单片机-----速度快,一个时钟周期执行一条指令,而普通的51单片机需要12个时钟周期执行一条指令。当然,Atmel公司出品的AT89LP系列单片机也是一个时钟执行一条指令,但目前还未普及。AVR单片机比51单片机多…...

高阶数据结构-----三种平衡树的实现以及原理(未完成)
TreeMap和TreeSet的底层实现原理就是红黑树 一)AVL树: 1)必须是一棵搜索树:前提是二叉树,任取一个节点,它的左孩子的Key小于父亲节点的Key小于右孩子节点的Key,中序遍历是有序的,按照Key的大小进行排列,高度平衡的二叉…...

北斗高精度组合导航终端
UWB(Ultra-Wideband)、卫星定位(GNSS),以及IMU(Inertial Measurement Unit)的组合定位系统结合了多种传感器和定位技术,以提供高精度、高可靠性的位置估计。这种组合定位系统在各种应…...

低代码平台是否能替代电子表格?
在计算机技术普及之前,会计、助理或者是销售人员,都需要用纸和笔来记录和维护每一笔交易。计算机技术兴起之后,一项技术发明——电子表格的出现改变了低效的状况。电子表格的第一个版本出现在1977年,一个名为“VisiCalc”的程序。…...

qt多个信号如何关联一并处理
主要方法: 首先,需要创建一个包含自定义信号和槽的Qt类。假设要创建一个名为MyObject的类,并在其中定义一个自定义信号和一个槽。这个类的头文件可能如下所示: #ifndef MYOBJECT_H #define MYOBJECT_H#include <QObject>c…...
【python爬虫】12.建立你的爬虫大军
文章目录 前言协程是什么多协程的用法gevent库queue模块 拓展复习复习 前言 照旧来回顾上一关的知识点!上一关我们学习如何将爬虫的结果发送邮件,和定时执行爬虫。 关于邮件,它是这样一种流程: 我们要用到的模块是smtplib和emai…...

2023数学建模国赛C题思路--蔬菜类商品的自动定价与补货决策
C 题 蔬菜类商品的自动定价与补货决策 在生鲜商超中,一般蔬菜类商品的保鲜期都比较短,且品相随销售时间的增加而变差, 大部分品种如当日未售出,隔日就无法再售。因此,商超通常会根据各商品的历史销售和需 求情况每天进…...

vue2与vue3的使用区别
1. 脚手架创建项目的区别: vue2: vue init webpack “项目名称”vue3: vue create “项目名称” 或者vue3一般与vite结合使用: npm create vitelatest yarn create vite2. template中结构 vue2: template下只有一个元素节点 <template><div><div…...
Apache httpd漏洞复现
文章目录 未知后缀名解析漏洞多后缀名解析漏洞启动环境漏洞复现 换行解析漏洞启动环境漏洞复现 未知后缀名解析漏洞 该漏洞与Apache、php版本无关,属于用户配置不当造成的解析漏洞。在有多个后缀的情况下,只要一个文件含有.php后缀的文件即将被识别成PHP…...
【漏洞复现】时空智友企业流程化管控系统文件上传
漏洞描述 通过时空智友该系统,可让企业实现流程的自动化、协同上提升、数据得洞察及决策得优化,来提高工作效率、管理水平及企业的竞争力。时空智友企业流程化 formservice接口处存有任意文件上传漏洞,未经认证得攻击者可利用此接口上传后门程序,可导致服务器失陷。 免责…...
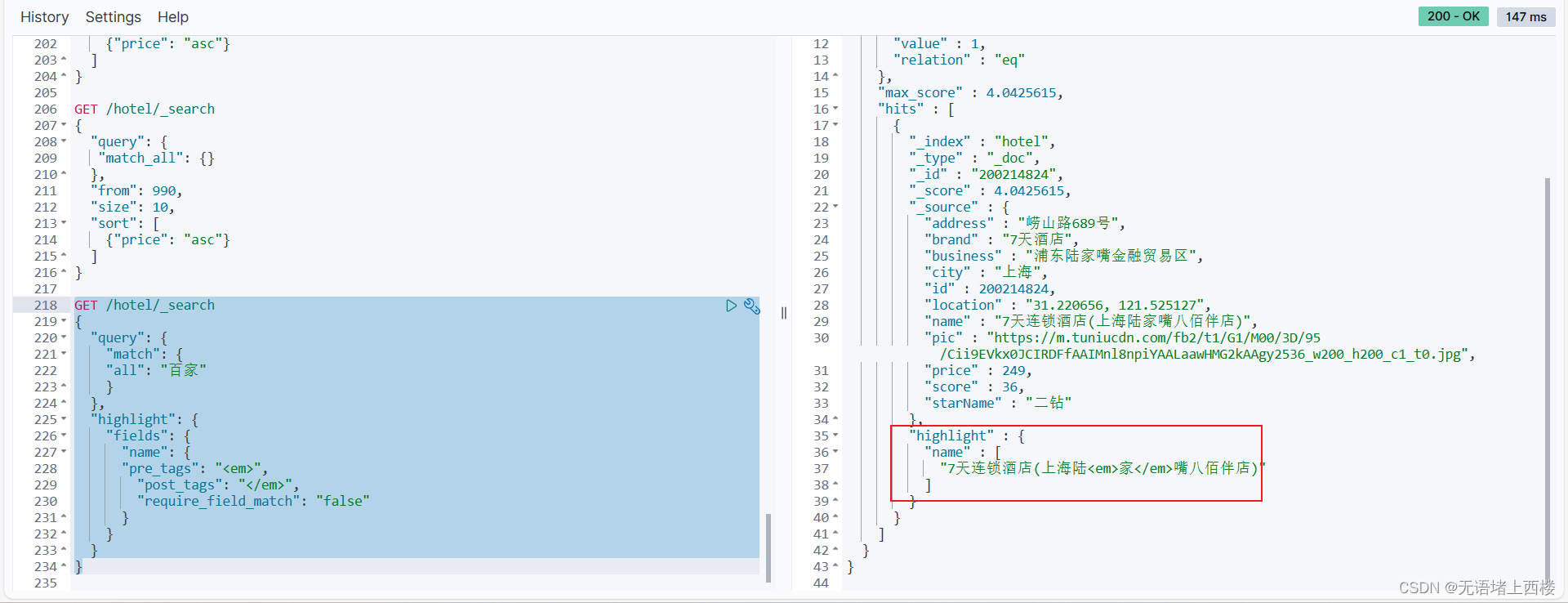
elasticsearch的DSL查询文档
DSL查询分类 查询所有:查询出所有数据,一般测试用。例如:match_all 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如: match_query multi_ma…...

emWin GUIBuilder按钮样式修改问题解决方案
1. 问题现象与背景解析在Keil MDK开发环境中使用emWin的GUIBuilder工具时,许多开发者会遇到一个典型问题:创建按钮(Button)等控件后无法修改其外观设计。具体表现为:在GUI设计界面选中按钮控件,尝试调整颜色…...

Unity图表性能优化:从折线图到饼图的底层实现与避坑指南
1. 为什么Unity里做图表不是“加个UI控件”就完事了? 在Unity项目里,当策划甩来一句“这个数据面板加个折线图展示用户留存率”,或者美术提出“战斗结算页需要动态饼图显示伤害来源分布”,很多开发者第一反应是:去Asse…...

Unity中PNG贴图内存暴增真相:ASTC压缩原理与工业级落地
1. 为什么一张PNG贴图在Unity里会“胖”三倍,而ASTC却能把它按进手机内存里? 你有没有遇到过这样的情况:美术同事发来一张20482048的PNG贴图,文件大小才3.2MB,可一拖进Unity编辑器,Inspector里赫然显示“Te…...

150块淘来的Nvidia Grid K2,如何在ESXi 6.7上稳定分配vGPU?我的翻车与修复实录
150元Nvidia Grid K2显卡的ESXi 6.7虚拟化实战:从硬件检测到vGPU稳定分配全指南 在虚拟化环境中部署专业显卡一直是技术爱好者和小型实验室的热门话题。当预算有限时,二手市场上的老款专业显卡如Nvidia Grid K2就成为了极具吸引力的选择。这款发布于2013…...

Atom CMS v2.0 SQL注入漏洞深度剖析与三层加固方案
1. 这不是“又一个SQL注入”,而是CMS底层架构失守的典型切片Atom CMS v2.0在2022年被公开披露的CVE-2022-24223漏洞,表面看是一处参数未过滤导致的SQL注入,但实际复现和分析后你会发现:它根本不是开发人员随手漏掉了一个mysql_rea…...

让Office界面真正属于你:Office RibbonX Editor的个性化定制之道
让Office界面真正属于你:Office RibbonX Editor的个性化定制之道 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribb…...

28 岁大专逆袭转行网络安全 资深前辈避坑忠告
网络安全行业 “人才缺口 300 万 、平均年薪超 25 万” 的红利,让无数职场人动了转行心思。尤其是学历普通(如大专)的群体,既面临原有岗位的天花板,又渴望通过技术转型实现薪资跃迁。但网安行业看似门槛低,…...

3步快速清理Windows驱动存储:DriverStore Explorer终极使用指南
3步快速清理Windows驱动存储:DriverStore Explorer终极使用指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统盘空间不断减少,却找不到原…...
)
2026年第十八届“中国电机工程学会杯”全国大学生电工数学建模竞赛A题绿电直连型电氢氨园区优化运行参考仿真及论文(仿真代码+论文)
2026年第十八届“中国电机工程学会杯”全国大学生电工数学建模竞赛A题绿电直连型电氢氨园区优化运行参考仿真及论文。www.bilibili.com/video/BV1Q7Li6hE27/?vd_source6ea1beb17174384a0b3d09d6d35580f6 摘 要 本文针对绿电直连型电氢氨园区的优化运行问题,在题目…...

深度学习 标注 训练一体化解决方案 | 深度学习AI平台
标注 & 训练一体化解决方案 | 深度学习AI平台|自研【核心功能】1、训练任务:支持目标检测、语义分割、图像分类、旋转目标、实例分割五类任务 2、可视化训练 一键开启模型训练实时查看训练进度和效果过漏检数据自动保存实时查看模型在测试图像上的可…...